【机器学习chp3】判别式分类器:线性判别函数、线性分类器、广义线性分类器、分段线性分类器
前言:
本文遗留问题:(1)对最小平方误差分类器的理解不清晰.(2)分段线性判别函数的局部训练法理解不清晰。
推荐文章1,其中有关于感知机的分析
【王木头·从感知机到神经网络】-CSDN博客
推荐文章2,其中包含关于梯度下降优化的各种方式:随机梯度下降、牛顿法等
【王木头·梯度下降法优化】随机梯度下降、牛顿法、动量法、Nesterov、AdaGrad、RMSprop、Adam-CSDN博客
目录
一、线性判别函数
1、线性判别函数的定义
2、线性判别函数扩展
3、线性判别函数在多分类情况下的应用
(1)第一种方法:《一对其他》
(2)第二种方法:《一对一》
(3)两种构建线性判别函数的方法对比
(4)第三种方法:《改进版一对一》
二、线性分类器的构造
1、线性分类器介绍
2、Fisher线性判别
(1)Fisher线性判别的意义和目标
(2)Fisher线性判别步骤
(3)广义Rayleigh商问题的求解
(4)Fisher线性判别的例子(PPT上的例子)
(5)Fisher线性判别 vs 高斯判别分析(待思考)
(6)多类分类的Fisher判别分析
3、感知器
(1)模型结构
(2)线性判别函数
(3)感知器算法的准则函数
(4)优化求解
4、最小平方误差分类器
(1)概述
(2)基本原理
(3)分类问题的矩阵表示
(4)最小二乘解法
(5)对 的迭代求解
三、广义线性判别函数
1、广义线性判别函数理论介绍
2、广义线性判别函数实现方法
(1)一阶多项式
(2)二阶多项式
(3)r 阶多项式
3、高阶多项式带来的计算问题
4、例子——点击率预估中的因子分解机
(1)点击率(CTR)预估问题
(2)因子分解机
四、分段线性判别函数
1、基于距离的分段线性函数
2、错误修正算法
(1)算法的核心思想
(2)问题的已知条件
(3)算法步骤
3、局部训练法(难懂)
4、决策树
(1)决策树的基本概念
(2)决策树的结构
(3)粗略概括决策树的构建过程
(4)关键问题——熵和经验熵
(5)关键问题——条件熵和经验条件熵
(6)关键问题——信息增益
(7)关键问题——Gini指数
(8)例子——分类回归树
(9)停止划分条件
(10)关键问题——剪枝
(11)决策树模型的优缺点
五、⭐⭐全文总结⭐⭐
1、对于线性判别函数
2、对于线性分类器的构造
3、对于广义线性判别函数
4、对于分段线性判别函数
附录
1、类内散度矩阵和协方差矩阵的关系
(1)定义
(2)关系
2、分类回归树离散型特征建模
步骤一、初始化决策树
步骤二、计算根节点的Gini指数
步骤三、对每个特征计算划分后的Gini指数并得到第二层节点
步骤四、计算Gini指数并得到第三层节点
步骤五、计算Gini指数并得到第四层节点
步骤六、整个模型,即最终决策树判断
一、线性判别函数
1、线性判别函数的定义
在线性分类问题中,我们可以通过一个线性判别函数 来划分样本属于不同的类别。对于一个二维空间的两类分类问题,线性判别函数可以表示为:
其中, 是样本的特征向量,
和
是特征的权重,
是偏置项。通过对
的符号来划分类别:
i、如果 ,则分类为
ii、如果 ,则分类为
2、线性判别函数扩展
对于 维样本的两类分类问题,线性判别函数可以推广为:
其中 为权重向量,
为偏置项。
为简化表示,可以将特征向量扩展为 ,将偏置项合并进权重向量
,则判别函数可以写成
。
3、线性判别函数在多分类情况下的应用
对于多类分类问题,有两种常用的方法来构建线性判别函数:
(1)第一种方法:《一对其他》
将 类分类问题转化为
个两类分类问题。对于每一类构建一个判别函数
,将第
类与其他类分开,即:
判别准则为:若
,则
;否则不属于第
类。分类所有类别共需要C个判别函数。
判别函数为:
(2)第二种方法:《一对一》
对于每两类分别构建一个判别函数,共需要 个判别函数。对于
类分类问题,通过每个判别函数进行投票,最终获得分类结果。
判别函数为:
(3)两种构建线性判别函数的方法对比
i、多类情况下,《一对其他方法》需要 个判别函数,而《一对一方法》需要
个判别函数。(《一对一方法》的缺点)
ii、《一对其他方法》中,每一个判别函数将一种类别的模式与其余 种类别的模式分开,而不是将一种类别的模式仅与另一种类别的模式分开。由于一种模式的分布要比
种模式的分布更为聚集,因此《一对一方法》对模式是线性可分的可能性比《一对其他方法》更大一些。(《一对一方法》的优点)
iii、在实际训练时,如果每个类别的样本数目相近,《一对一方法》模型训练时,两个类别的样本数据相近;而此时《一对其他方法》需综合其余 种类别的样本,这些样本的数目比第
类一个类别的样本数目会多得多。样本数目不均衡会给模型训练带来困难。
iv、对于上面的《一对一方法》,存在不确定区域,例如:如果三分类,那么会有三个判别函数,三个判别函数计算后最终投票结果是三类各有一票,这样就无法区分目标样本属于哪一类了。如图:

(4)第三种方法:《改进版一对一》
在上面那个《一对一方法》中,存在不确定区域,所以可做如下改进:
对每一对类别 ,我们构建一个线性判别函数
,其形式为:
其中 和
分别是类别
和类别
的权重向量。
对于给定的样本 ,我们计算所有类别之间的判别函数
。如果对于类别
,存在
对所有
成立,那么我们将样本分类为类别
。也就是说,如果对于某个类别
,它的判别函数在与其他所有类别的比较中都胜出,那么我们就判定该样本属于类别
。
这种思想的精髓为:
,其中
二、线性分类器的构造
1、线性分类器介绍
线性分类器是一种用于将数据样本分为不同类别的分类模型,其目标是在样本空间中找到一个超平面,将不同类别的数据分开。具体来说,对于给定的样本集 ,线性分类器试图确定一个线性判别函数:
其中, 是输入特征向量,
是待求的参数向量。
线性分类器的设计步骤
i、确定准则函数 :线性分类器设计的核心在于定义一个准则函数
,它反映了分类器的性能。通常,准则函数与分类的准确率、误差率或其他性能指标相关。我们通过最大化或最小化该准则函数来优化分类器。
ii、优化准则函数: 通过求解准则函数 的极值来找到最优参数
。这可以通过以下两种方式来实现:
· 最大化准则函数:
· 最小化准则函数:
具体的优化目标(最大化或最小化)取决于准则函数的定义。例如,如果准则函数表示分类误差,则需要最小化该函数;如果准则函数表示分类准确率,则需要最大化该函数。一般情况下都是解决最小化问题,最大化某函数等于最小化负的某函数。
线性分类器的“最佳决策”
通过求得的最优参数 ,线性分类器可以对新的样本进行分类,即根据判别函数
的符号或阈值,将样本分为不同类别。这一过程中的“最佳决策”即为根据最优参数所实现的分类。
2、Fisher线性判别
(1)Fisher线性判别的意义和目标
(2)Fisher线性判别步骤
i、计算样本在 空间(原始高维空间)中的统计描述量
类均值向量 :
表示第 类样本的平均值。
类内散度矩阵 :
表示第 类样本的类内散度。类内散度矩阵和协方差矩阵之间的关系见《本文附录1》。
总类内散度 :
其中 和
分别表示两个类别的类内散度矩阵。
类间散度矩阵 :
其中 和
是两个类别的均值向量。类间散度矩阵
用来衡量不同类别均值之间的差 异。
ii、计算样本在投影后的 空间中的统计描述量
当我们将样本投影到一维空间 后,可以重新计算类均值和类内散度,这些描述量如下:
类均值向量 :
其中 是样本在方向
上的投影。
类内散度 :
总类内散度 :
类间散度 :
iii、从 空间投影到
空间
从 空间投影到
空间,
小于
,需要给
中的向量乘上一个秩为
的矩阵,如果
等于1,即投影到一维空间时,给
乘上一个秩为1的矩阵即向量。

iv、在投影后的 空间与原空间
中的统计描述量之间的关系
根据投影方向 的性质,投影后的类内和类间散度可以用原空间的散度表示:
投影后的类内散度 :
观察散度的定义,其与样本 的平方成正比,
映射过去是乘一个
,所以散度映射 过去就要乘两个
。所以其形式才是这样的,下面的类内散度和类间散度同理。
总类内散度 :
投影后的类间散度 :
v、Fisher准则函数和最优投影方向
Fisher线性判别的核心思想是:找到一个最优的投影方向 ,使得:
投影后的总类内散度 最小:同类样本在投影方向上尽量聚集。
投影后的类间散度最大:不同类别的样本在投影方向上尽量远离。
显然满足以上两个条件可以使得投影后的一维空间上,不同类别的投影点尽可能分开, 而同类别的投影点尽量聚集。
即使得
最大。被称为Fisher准则函数。
我们希望找到一个投影方向 ,使得
最大,即最大化类间散度和类内散度的比值。
因此,最优的投影方向 可以通过如下优化问题获得:
这个优化问题通常称为广义Rayleigh商问题,可以通过特征值分解来解决,本文下面一节有 详细解答。计算后得到最优投影方向为。
vi、解出最优投影方向 后寻找决策面
投影后的 空间中的决策面
最优投影方向为 。决策面要满足两个条件:
i、与 正交
ii、向量 的终点在在决策面上,
高维空间 中的决策面
最优投影方向为 。决策面要满足两个条件:
i、与 正交
ii、向量 的终点在在决策面上,
(3)广义Rayleigh商问题的求解
上面Fisher线性判别步骤中写道最优投影方向为,这个问题还没有解决。下面解决这个问题,即求问题
,其中
,该类问题被称为广义Rayleigh商问题。
为了更具一般性,这里用代替
。
即解决问题:
,其中
为了解决最优投影问题,我们的目标是找到一个向量 ,使得广义Rayleigh商
最大化。需要对分母进行归一化,因为不做归一的话,
扩大任何倍,
不变,我们无法确定
。
通常选择的归一化方式是:
这样可以确保优化问题的解是唯一的。
使用拉格朗日乘子法解优化问题
即问题变为解优化问题:
为求解这个约束优化问题,采用拉格朗日乘子法。定义拉格朗日函数:
其中 是拉格朗日乘子。通过对
关于
求偏导并设为零,可以得到最优解的条件。
对 关于
求导,得到:
可以简化为:
求解特征值问题
(4)Fisher线性判别的例子(PPT上的例子)
i、给定数据的均值向量
- 类别1的均值向量
:
- 类别2的均值向量
:
ii、类内散度矩阵 和
- 类别1的类内散度矩阵
:
- 类别2的类内散度矩阵
:
iii、总的类内散度矩阵
- 计算总类内散度矩阵
:
iv、Fisher准则计算投影方向
- 通过Fisher准则计算投影方向
:
v、判别函数和判别面方程
判别面方程为:
即:
判别函数为:,即当
,属于某类;当
,属于另一类。
这个例子展示了通过Fisher准则得到最佳投影方向 ,并在此方向上计算判别面,用于区分两类样本。

(5)Fisher线性判别 vs 高斯判别分析(待思考)

(6)多类分类的Fisher判别分析
假设我们有 类,目标是找到一个投影矩阵
,将原始的
维特征降维到
维(
)。投影后的样本表示为:
其中, 是
维向量,
为
的投影矩阵。
i、投影前的统计量
第 类样本均值向量:
其中, 是指示函数,当样本
属于第
类时取值为1,否则为0。
第 类样本的类内散度矩阵:
该矩阵反映了第 类样本在其均值
周围的分布情况。
总类内散度矩阵:
是所有类别的类内散度矩阵之和,描述了各类样本内部的总体分散情况。
总散度矩阵:
其中,整体均值 表示为:
总散度矩阵 表示所有样本相对于整体均值
的散布情况。
类间散度矩阵:
类间散度矩阵 表示各类别均值之间的散布情况,用于度量类别之间的可分离性。
类间散度矩阵与两类情形略有不同:原来度量的是两个均值点的散列情况,现在度量的是每 类均值点相对于样本中心的散列情况。
ii、投影后的统计量(和两类情形同理)
投影后第 类样本的均值:
投影后第 类的均值
是原均值
在投影方向上的映射。
投影后第 类样本的类内散度:
投影后第 类的类内散度
是原始类内散度矩阵
在
上的投影。
投影后的总类内散度矩阵:
投影后的总类内散度矩阵 是所有类别类内散度矩阵之和在
上的表现。
投影后的类间散度矩阵:
类间散度矩阵 表示投影后各类别均值之间的分布情况。
iii、多类情况下Fisher准则函数
Fisher准则的目标是最大化类间散度,同时最小化类内散度,以保证投影后类别间的区 分度。 Fisher准则函数可以表示为:
这里使用了矩阵行列式的比值来衡量类间和类内的散布情况。这个准则的优化目标是找 到一个投影矩阵 ,使得
最大化。
iv、最佳投影方向的求解
最佳投影方向 满足以下广义特征值问题:
我们选择 的前
个最大的非零广义特征值对应的特征向量组成矩阵
,作为 最佳投影方向。
3、感知器
本篇开头的《推荐文章1》中也有对感知机的分析,《推荐文章2》中有对梯度下降法的优化。
(1)模型结构
输入:特征向量 。
输出:分类结果 ,其中
代表正类,
代表负类。
(2)线性判别函数
感知器使用一个线性判别函数来表示输入数据的分类: 其中,
是权重向量,
是偏置项(bias),表示模型的决策面。写成增广形式为:
判别规则为:依据 的符号来判断样本的类别:
(3)感知器算法的准则函数
样本分类准则:对于样本 ,当
时,样本分类正确;若
,则分类错误。
准则函数:分错的样本越少越好,令 为所有错分类样本的集合,则准则函数可以表示为:
目标:通过优化,使得权重 和偏置
的组合最小化准则函数
。
思考准则函数:这个准则函数是因为判别规则而凑出来的形式,我认为没有它没有物理意义。
(4)优化求解
目标函数 可以通过优化算法求解。感知器模型通常采用随机梯度下降法(Stochastic Gradient Descent,SGD)来更新模型参数
和
:
将目标函数表示为增广向量形式的判别函数:
然后目标函数为:
通过迭代更新权重向量 和偏置
,感知器模型逐渐优化以满足准则函数的最小化需求。
对于梯度下降的超详细分析在王木头是视频中有非常清晰的讲解:从梯度下降原理及几何直观(下面链接中的视频)到梯度下降的优化(本文开头推荐文章2)。
如何理解“梯度下降法”?什么是“反向传播”?通过一个视频,一步一步全部搞明白_哔哩哔哩_bilibili
4、最小平方误差分类器
(1)概述
最小平方误差分类器是一种基于最小二乘准则的分类方法,主要用于处理二类或多类分类问题。与感知器算法不同,最小平方误差分类器能够在模型不可分的情况下也达到一定的收敛效果。
(2)基本原理
在二类分类的情况下,设输入特征向量为 ,标签
为 +1(代表正类)或 -1(代表负类)。该分类器的基本思想是通过线性判别函数:
实现分类,其中 为权重向量,
为偏置项。
线性判别函数写成增广形式为:
判别条件为:对于每个样本 ,当满足
时,样本被正确分类。
(3)分类问题的矩阵表示
从上面的判别条件可得到,目标是让每个样本满足 ,即
写成矩阵形式为
其中 , 式
(4)最小二乘解法
当不等式解不存在或无法收敛时,可以通过最小二乘方法解决。将不等式转化为超定方程 (这里的
和判别函数中的
不是同一个,判别函数中的
的信息已经通过增广进入了
中),其中
且
。目标是找到最小二乘解,使得:
其中 的梯度可以通过微分求得,最终求解为
。
(5)对 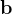 的迭代求解
的迭代求解
对 求梯度:
的迭代更新公式为:
得到:
收敛条件
当 的所有分量都为正时,说明所有样本都正确分类,迭代过程结束;如果
中的分量有负,说明该问题不可分。
实际问题中将迭代到最小后,
中有一部分分量小于0,表示分类错误的样本。这时根据
计算出
仍是最优解,只不过因为原问题不可分,一部分样本会被分错。
(这部分我认为PPT上的有问题或者我没理解PPT上的方法)
三、广义线性判别函数
1、广义线性判别函数理论介绍
线性判别函数假设模式是线性可分的,因此可以通过简单的线性分割实现分类。然而,在实际应用中,许多场合下模式不是线性可分的,因此单纯的线性判别函数难以满足需求。广义线性判别函数的解决思路是通过非线性变换将非线性判别问题转化为线性判别问题,从而达到分类目的。
基本思想:
样本集合 在原始的
维特征空间中是线性不可分的,将样本从
维空间映射到
维空间(
),使得样本在这个新的高维空间中模式可以线性可分。 样本集合映射到
维空间后为集合
。
新的模式空间的样本向量 的每个分量是原始向量
的单值实函数,可以表示为:
在这个新的空间 中,可以使用线性判别函数
来进行分类。
2、广义线性判别函数实现方法
(1)一阶多项式
如果 ,则
,广义线性化后的判别函数形式与原始空间的线性判别一致,即:
(2)二阶多项式
以二维向量 为例,二次项、一次项和常数项的变换可以写为:
设权重向量
则转换后的线性判别函数可以表示为:
一般情况下,对于 维向量
,可以计算
的二次项(共
个)、一次项(共
个)和常数项(1 个),转换后的线性判别函数为:
其中 的一般形式可以写为:
(其中
,
)
(3)r 阶多项式
对于 维的
,可以计算
的
阶多项式项,这些项可以表示为:
其中
表示选择的维度,
表示该维度的次幂(
且
)。
此时,转换后的线性判别函数可以通过以下方式递归地给出:
一直递归到 。
的总项数为:
3、高阶多项式带来的计算问题
的项数随着
和
的增加而迅速增加。即使原始模式
的维数不高,若采用高次的多项式变换,则转换后的模式
的维数会迅速增加,导致计算和存储困难。
实际应用中的取值:在实际应用中,一般选择 或
,避免过高的维数。如果
,可以只取二次项并忽略一次项,以减少
的维数,从而在保证效果的同时降低计算复杂度。
4、例子——点击率预估中的因子分解机
(1)点击率(CTR)预估问题
点击率(CTR)预估中的因子分解机(FM)模型用于解决CTR预估中大规模稀疏数据的问题。CTR预估是一个典型的二分类任务,预测用户是否会点击展示的广告。因子分解机通过对离散型特征的组合进行有效表示,降低了计算复杂度,以下是FM模型的详细分析。
i、CTR预估中的挑战
数据量巨大:CTR预估需要处理亿级的特征和样本数据。
样本不均衡:正负样本数量不均衡,点击的样本占比通常很小。
特征稀疏:特征多为独热编码(One-Hot Encoding),大量特征是稀疏的。

在CTR预估中,许多离散型特征(如国家、节日)需要转换为独热编码。稀疏性的问题在于,每个样本的特征向量非常高维且大部分是零。为了减少稀疏特征对模型的影响,FM引入了因子分解机制。
ii、CTR预测模型
考虑二阶特征组合,基本模型包括了线性部分和二次特征交互部分:
其中:
是全局偏置。
是特征
的一阶权重。
是特征
的交互权重,表示二阶特征交互。
(2)因子分解机
iii、因子分解与低维隐向量表示
的交互矩阵
,其中每个元素
表示第
个和第
个特征之间的交互关系。FM 使用低秩分解来近似这个矩阵
:
其中 是一个
的矩阵,
是隐空间的维度,通常远小于
。
形式为:
其中:
是一个
的矩阵。
是一个
的矩阵,其中
,表示降维后的隐向量矩阵。
是
交互矩阵是对称矩阵,也是对称矩阵。
相当于
的第
行和第
行的点积。
所以有:
其中:
是特征
的
维隐向量。
是隐向量的维度,通常
,这大大减少了参数数量。
因此,FM的模型可以简化为:
通过这种分解,原本 交叉项个参数将为
个,使得模型可以高效地计算特征之间的交互项。
iv、FM的计算优化(不懂)

FM模型的二阶项可以进一步优化计算:
这样,计算复杂度进一步降低,只需要 的时间复杂度完成预测计算。
v、FM模型的训练
FM模型为:
计算每个参数的梯度:
对偏置项 的梯度为 1
对一阶特征权重 的梯度为
。
对隐向量 的梯度为:
通过预计算,可以在 的时间复杂度下完成所有梯度的计算,进而更新参数。
四、分段线性判别函数
对于分类问题,通常希望找到一个判别函数 ,能够将样本数据分成不同的类。对于线性可分的问题,可以用线性判别函数解决:
其中 是权重向量,
是偏置项。如果
,则分类为类 1,否则为类 2。
然而,实际中常常遇到非线性可分的问题,比如数据分布呈现复杂的曲线模式。在这种情况下,简单的线性判别函数无法实现有效分类。因此,提出了广义线性判别函数和分段线性判别函数的概念,以解决此类问题。然而,高维映射的代价较高,计算复杂性显著增加,这时分段线性判别函数成为一种更经济的替代方案。
分段线性判别函数:
分段线性判别函数的思想是将特征空间划分为若干部分,在每个部分内使用一个线性判别函数。假设空间分为 个分段区域,每个区域使用一个线性函数
表示:
每个区域 内的分类决策由相应的线性判别函数
决定。这种分段的好处在于,每个区域的分类可以用较简单的线性函数近似,而整体的非线性分类需求则由多个线性片段的组合实现。
分段数量的确定:
分段数目过少:无法很好地逼近原数据的分布,分类效果差。
分段数目过多:计算复杂性增加,决策过程变得繁琐。
在实际应用中,一种合理的方法是根据数据的分布确定分段数目。可以通过聚类分析将数据划分为若干子集,每个子集可以视为一个分段区域,然后对每个子集拟合线性判别函数。
示例:
假设我们有 3 类数据 、
和
,我们可以通过以下三种方式实现分类:
二次判别函数:直接用一个二次判别函数实现,但计算较复杂。
分段线性判别函数:在每个分段区域内使用线性判别函数来逼近二次曲线。

如图所示,分段线性判别函数通过三个不同的线性区域 I、II 和 III 分别实现分类,组合起来逼近了二次曲线,从而有效地完成了分类任务。
最小距离分类器
最小距离分类器是一种特殊情况下的分类方法,其假设各类别服从正态分布,且具有相同的协方差矩阵和相等的先验概率。决策规则为,将测试样本归类为距离其最近的类别中心。
假设两类样本的中心分别为 和
,则决策面为两类中心连线的垂直平分面:
分段判别函数的形式定义(这种形式确实很符合直觉,待感想)
i、每个类 可以分成多个子类:
。
ii、对每个子类定义一个线性判别函数 。
iii、每类的判别函数定义为该类所有子类判别函数的最大值:
iv、最终的分类决策为:
决策规则可以根据相邻的决策面定义,例如如果第 类的第
个子类与第
类的第
个子类相邻,则可以共享决策面
。
1、基于距离的分段线性函数
该方法将样本划分成多个子类,每个子类由其均值(即质心)代表,然后应用最小距离分类器。对于每个类别 ,定义其判别函数为样本到该类别所有子类中心点的最小距离:
最终的分类规则为:
这种方法通过多个最小距离分类器的组合,形成了分段线性决策面。这种组合的决策面适合非线性可分的数据分布。
局限性:
样本划分成多个子类,判断样本属于哪个子类时,用到了最小距离分类器,所以只在当每个子类是协方差相等高斯分布时才能使用基于距离的分段线性函数。
2、错误修正算法
(1)算法的核心思想
错误修正法的核心思想是利用多类线性判别函数的感知器算法(本文1.3中的第三种方法:改进版一对一),通过逐步修正权向量来减少分类错误,直到分类达到收敛条件。
(2)问题的已知条件
每个类的子类数量 已知,但子类划分未知。
需要根据训练样本中的错误信息来逐步修正每个子类的线性判别函数。
(3)算法步骤
初始条件
假设初始的权向量为 ,其中
,
。
训练过程
i、计算样本的归属子类
对于属于第 类的样本
,其中
,计算该样本与第
类所有权向量的内积:
找到最大值对应的子类 ,即:
ii、错误检测与修正
- 检测无误的情况,无需修正:
如果满足 (对于所有
的
和
),则说明样本
已经被正确分类,无需修改。
- 检测有误的情况,迭代参数(参数确定的是决策面,也就是迭代决策面)
如果样本 被错误分类,即存在某个
的
和
使得:
则应对权向量进行修正:
- 找到误分类样本对应的最大内积:
- 更新权向量:
其中 是学习率。
iii、收敛性
- 如果样本集能被分段线性判别函数正确划分,则该迭代算法是收敛的。
- 当条件不满足时,可以考虑逐步减小学习率,以实现“近似收敛”,但可能增加分类错误率。
- 可以设置最大迭代次数来限制算法执行的步数。
iv、未知子类数目的情况
树状分段线性分类器
- 该方法用于在子类数量未知的情况下,将样本分成多个子类。
- 先设计一个线性分类器,将所有样本分成两个子类。
- 若子类中有错误,则在子类中再分… 直到所有样本被正确分类。
初始权向量选择
- 初始权向量的选择对算法结果敏感。通常选择分属两类的欧氏距离最小的样本,取其垂直平分面的法向作为权重初始值。
v、直观理解
- 错误修正算法通过逐步更新权向量,根据错误分类的样本 “推动” 分类面,一步步得调整分类面到最正确得位置。
- 在收敛条件下,所有样本被正确分类;在不收敛的条件下,通过学习率调节或步数限制,可以实现部分分类或近似分类。

3、局部训练法(难懂)
在分类问题中,贝叶斯决策面通常能实现最小的分类错误率。然而,当两类样本非线性不可分时,直接用线性判别函数难以准确逼近贝叶斯决策面。这时,可以通过局部训练法来提升分类性能。局部训练法的核心思想是,通过识别并利用样本中的交遇区,在这些局部区域上构造逼近的分段线性判别函数,从而更好地逼近贝叶斯决策面。
(1)交遇区的定义
- 交遇区:在贝叶斯决策面附近,两类样本通常非线性接近或交叉。这些区域称为交遇区。在这些交遇区内,样本分布表现出更复杂的模式,不易被简单的线性判别函数划分。
- 局部训练法的目的:通过在交遇区内的样本来训练出多个分段的线性判别函数,使得组合的分段线性决策面能更准确地逼近贝叶斯决策面。
(2)局部训练法的核心步骤
i、找到交遇区并生成局部判别函数
- 在交遇区内,选择相对密集的样本构成局部样本集,这些样本称为交遇区样本。
- 用这些交遇区样本训练线性判别函数,从而生成分段线性决策面。
ii、 局部训练法的执行
- 对交遇区中的样本构造新的训练集,通过这些样本生成分段的线性判别函数。
- 得到的判别面为分段线性分界面,可以更好地逼近贝叶斯分界面。
iii、 需要解决的关键问题
- 如何从样本集中找到交遇区:通过样本的分布密度或相互距离来确定交遇区样本。
- 如何利用交遇区中的样本设计线性分类器:对交遇区内的样本进行局部线性分类训练。
- 如何进行分类决策:通过多个局部的线性判别函数的组合来对测试样本分类。
(3)紧互对原型与交遇区
在实际操作中,通过对样本聚类将其划分为多个簇(原型区),然后选取每个簇的中心点作为原型。紧互对原型的生成是局部训练法中重要的一步。
紧互对原型的定义与寻找方法
- 划分原型区:对每个类别的样本进行聚类,得到多个原型,每个原型可以用其中心点或最具代表性的样本表示。
- 寻找紧互对原型:对于不同类的样本,计算它们之间的欧氏距离,找到两类样本中距离最近的原型对(即紧互对原型)。紧互对原型定义了两个类之间的“接触点”,是交遇区的代表性样本。
通过紧互对原型的集合,可以形成交遇区的样本集,后续的分类判别将在这些区域内展开。
(4)生成初始分离超平面
通过紧互对原型生成初始的分类决策面:
-
初始分离超平面公式:假设最紧互对的两个原型分别为
和
,则初始的分类超平面
的方程可以写作:
该平面以紧互对原型对的中点为平面中心,以这两个原型的方向向量为法向量。
-
分离超平面的作用:生成的初始分离超平面
(5)生成新的分离超平面
生成新的分离超平面
在生成初始超平面 后,逐步生成更多的分离超平面以形成完整的分段决策面。
- 移除已正确分类的样本对:将被
- 生成新的超平面:在剩下的样本中,找到下一个最紧互对原型对,生成新的分离超平面
。
- 重复该过程:继续寻找新的紧互对原型对并生成超平面,直到所有交遇区的样本对都得到处理。
最终得到一系列超平面 ,构成完整的分段线性分类器。
(6)决策规则
在完成所有分段超平面的生成后,定义样本的分类决策规则。决策规则通过超平面来分割样本空间,从而实现分类。
- 计算每个超平面与样本的关系:对每个测试样本
,计算其与各个超平面
的内积,得到判别函数
。
- 定义决策变量:对
进行符号判定,定义二值决策变量
:
这样,每个样本 可以通过决策变量
表示其分类状态。
(7)具体的决策规则
根据决策变量的取值,对测试样本进行分类。设 的取值范围为
,统计各类样本在各个
取值下的出现次数,分别记为
和
。
定义比值函数 表示取值
中第一类样本所占比例:
根据比值 来确定样本的类别:
- 若
,则该样本属于第1类;
- 若
,则该样本属于第2类;
- 若
,且
和
都较小,则无法做出决定;
- 若
4、决策树
(1)决策树的基本概念
决策树是多级分类器,尤其适合多类别任务和多峰分布数据。分级思想:将复杂问题分解为多个简单的子问题,通过一系列二元或多元决策逐步划分数据空间。决策树的路径互斥且完备,确保从根节点到叶子节点的每条路径都表示一种决策规则。
(2)决策树的结构
- 根节点:包含所有样本的数据点,表示决策树的起点。
- 中间节点:表示划分后的不同决策分支。
- 叶子节点:对应每个分类结果,样本数占比最高的类别被赋予最终预测值。
(3)粗略概括决策树的构建过程
i、初始步骤
- 构建根节点,将所有训练样本数据分配到根节点。
- 将根节点加入叶子节点列表。
- 设定终止条件(如样本纯净度、树深度等)。
ii、核心算法流程
- 判断终止条件
- 若当前节点的样本集已经“足够纯净”(即几乎所有样本都属于同一类别),则停止划分,将该节点转为叶子节点,并从叶子节点列表中删除(不再划分)。
- 划分样本集
- 若样本集不纯净,尝试用特征进行划分。每次尝试不同的特征和特征值分割点,计算分割后的 纯净度(如基尼指数、信息增益等)。
- 选择最优分割特征及分割点,并将样本分成两个或多个子集。
- 创建子节点,将子节点加入叶子节点列表,同时将当前节点从叶子节点列表中移除。
- 递归划分
- 对每个新的叶子节点重复上述过程,直到满足终止条件。
iii、决策树构建中的关键问题
- 选择特征及划分点
- 目标:找到能使得数据集划分后纯净度提升最多的特征及其划分点。
- 评价指标:信息增益、基尼指数、增益率、带正则的基尼指数等。
- 终止条件
- 纯净度阈值:当某个节点样本的纯净度达到设定值(如熵接近0)时,停止分割。
- 树的最大深度:限制决策树的最大层数,避免过拟合。
- 叶子节点最小样本数:限制每个叶子节点包含的最小样本数,避免树结构过于复杂。
iv、决策树优化:剪枝
- 预剪枝
- 在构建过程中对每次分割进行评估,若分割不能显著提升泛化性能,则提前终止分割。
- 优点:降低计算复杂度。
- 缺点:可能过早终止分割,导致模型欠拟合。
- 后剪枝
- 先构建完整的决策树,然后通过遍历去除冗余分支。
- 方法:
- 交叉验证:去除分支后验证模型性能,选择最优子树。
- 误差复杂度剪枝:通过增加惩罚项优化叶子节点数量。
(4)关键问题——熵和经验熵
i、熵
在概率分布 下,熵的公式为:
熵反映了一个系统中所有可能状态的不确定性,如果系统状态分布完全均匀,熵达到最大值,表示不确定性最高。如果系统状态是完全确定的,熵为 0,表示没有不确定性。
熵的本质是对 平均信息量 的刻画,信息量是随机事件发生后带来的“惊讶度”。罕见事件(低概率)携带更多信息,因此其信息量更大。
ii、经验熵
用在实际样本数据估计出的经验概率(在王木头视频 “从最大熵推导softmax” 中多次提到经验概率)代替概率,计算出来的熵即是经验熵。经验熵是熵在数据样本上的一种具体化,反映的是 样本分布的不确定性。
定义为:
给定一个数据集 ,其中类别
,
是
类在
中出现的频率(即最大似然估计出的概率),经验熵定义为:
其中:
是
类样本的经验概率。
(5)关键问题——条件熵和经验条件熵
i、条件熵
条件熵 表示在已知
的情况下,
的不确定性。
条件熵的定义为:
如果 完全决定
,则
(无不确定性)。
如果 和
独立,则
(
无助于减少
的不确定性)。
所以有 的熵
一定大于等于
已知的情况下
的条件熵
,即
条件熵的本质
- 衡量 给定条件变量后剩余的不确定性。
的值刻画了
对
提供的信息量有多大,即条件信息对系统不确定性减少的程度。
几何上,可以将条件熵理解为 信息空间中在已知某些条件后的剩余分布的不均匀性。
ii、经验条件熵
同上面的经验熵,经验条件熵是基于数据的经验熵,即通过从实际样本数据中最大似然估计出的经验概率计算出来的条件熵为经验条件熵。
(6)关键问题——信息增益
从条件熵的本质可知,原来的熵为
,给定条件
后熵变为条件熵
,即系统的不确定性变低了。所以给定条件
的过程相当于给系统填充了信息,即系统的不确定性变小了。所以给定条件
的过程使得信息发生了增益,即:
信息增益
: 数据集
的 经验熵,表示未划分数据前的整体不确定性。
: 特征
的 经验条件熵,表示按照

信息增益是用来衡量某个特征 对数据集
的分类效果的指标。
信息增益衡量的是 特征 带来的不确定性减少的程度。信息增益越大,说明特征
对分类的贡献越大,分类效果越好。
i、本质:
- 划分前的整体类别分布(高混乱度)。
- 划分后各子集的类别分布(低混乱度)。
- 通过特征
ii、划分质量的衡量:
- 如果特征
- 信息增益衡量特征
iii、信息增益的几何直观:
从几何角度,信息增益可以理解为:
- 原数据集中类别分布的熵
- 划分后,每个子集内点的分布复杂度降低,类别更加集中,熵减少。
通过特征 划分数据,可以看作将复杂的空间划分为多个更加“整齐”的区域。
iv、信息增益的优缺点:
优点
- 直观:直接衡量划分前后的不确定性变化。
- 易于计算:公式简单,可直接应用在决策树等模型中。
缺点
偏向多值特征:
- 如果特征
- 解决办法:引入信息增益率。
v、信息增益率
- 定义
信息增益率是在信息增益的基础上,修正了信息增益对特征取值数目(即特征分裂值较多)可能产生的偏向。信息增益率的定义为:

其中:
固有值:
:特征
:数据集总样本数。
固有值衡量了特征 的取值带来的分裂复杂度。如果
有较多的不同取值,则固有值会较大。
- 信息增益率的意义
信息增益率反映了信息增益的“有效性”,通过对信息增益进行归一化,削弱了信息增益对取值多的特征的偏好。固有值越大,表示特征的分裂越复杂,信息增益率会被减小。信息增益率有效地平衡了信息增益的大小与特征取值的复杂度之间的关系。
(7)关键问题——Gini指数
Gini指数是衡量数据集纯度的重要工具,其本质在于评估类别分布的混乱程度。
Gini指数的公式:
:类别的总数。
:类别
的样本比例,即类别
:表示所有类别的占比平方的总和,反映了数据集的纯度。
- 如果数据集中样本均分布于
较大。
- 如果数据集中所有样本均属于一个类别(即数据集非常纯),则
,
。
i、Gini指数和熵的区别
相同点:
- Gini指数和熵都是衡量数据纯度的指标,且他们的方向性一致即数据越混乱数值越大,数据越纯净数值越小。
- 如果一个特征有较多类别值,可能会因为划分更细而显得 Gini指数(或熵)较低,但这些特征未必有实际分类意义。
不同点:
- 与熵相比,Gini指数的计算没有对数运算,计算复杂度较低。
- Gini指数更关注主要类别的分布,对小概率事件的关注不够,更关注于少数几个类别。
- 熵相对于Gini指数更关注小类别的分布:下面从数学角度解释为什么:
熵对于较小的类别概率(如 ),
取值趋近于0,但此时它的斜率趋近于无穷大,所以当
增大少许,熵就可以显著增加,从而使模型更关注小类别的分布。
由于平方运算对大概率值( 较大)更加敏感,而对小概率值(
)的变化不敏感,因此 Gini 指数更关注主导类别的分布。
下图展现了Gini指数和熵随混乱度的变换,可见,熵的变换更剧烈。

ii、Gini指数在划分中的应用
- 定义
数据集 ,用某个特征
将其划分成
个子集
。划分后数据集的加权 Gini 指数为:
这个公式与条件熵的公式想对应。
-
个子集。
:第
:子集
- 例子
假设数据集 包含 10 个样本,分属于 2 个类别
和
,类别分布如下:
-
:4 个样本。
-
:6 个样本。
我们有一个特征 ,取值范围为
。基于特征
将数据集
划分为两个子集
和
:
- 子集
:包含 5 个样本,其中
- 子集
:包含 5 个样本,其中
步骤 1:计算原始数据集的 Gini 指数
步骤 2:计算划分后每个子集的 Gini 指数
子集 的 Gini 指数:
子集 的 Gini 指数:
步骤 3:计算划分后的加权 Gini 指数
步骤 4:比较划分前后的 Gini 指数
划分前的 Gini 指数:。
划分后的加权 Gini 指数:。
由于划分后的 Gini 指数降低,说明特征 的这一划分提高了数据的纯度。
(8)例子——分类回归树
CART树:一种二分递归划分的决策树,每次将样本集划分为两个子集,最终生成二叉树。
分为两种类型:
- 离散型特征处理:
- 将所有可能取值组合为两部分,测试划分的纯净度(如Gini指数)选取最优划分。
- 连续型特征处理:
- 根据特征值的排序,选择所有可能的分割点(如两相邻值的中点)进行测试,选取分割后Gini指数最低的点。
i、分类回归树离散型特征建模的例子:
见附录2
ii、分类回归树连续型特征建模的例子:
连续型特征的划分是决策树建模的一个关键环节。针对连续型特征:
- 必须找到一个分割点(阈值),将连续特征的值分成两个子区域(左分支和右分支)。
- 为了找到最优分割点,通常需要遍历所有可能的分割点,并计算每个分割点的 Gini 指数 或其他衡量标准,选择 Gini 指数最小的分割点作为最终的划分。
找到分割点后问题就变成了离散型特征建模。
(9)停止划分条件
- 划分带来的损失的减小太小
- 树的深度超过了最大深度
- 叶子结点数目超过了最大数目
- 左/右分支的样本分布足够纯净
- 左/右分支中样本数目足够少
(10)关键问题——剪枝
剪枝是决策树构建中的一种重要技术,用于控制模型复杂度,防止过拟合。剪枝可以分为预剪枝和后剪枝,
i、预剪枝
核心思想:在构建决策树的过程中,提前终止分裂,避免过于复杂的结构。
操作步骤
-
设定停止分裂条件:
- 最大深度:限制树的深度,例如不超过某个固定值。
- 最小样本数:如果当前节点的样本数低于设定的最小样本数,则停止分裂。
- 信息增益阈值:如果某一划分的增益(信息增益、Gini 指数减少量等)小于设定阈值,则停止分裂。
-
在每次分裂时检查停止条件:
- 如果分裂满足停止条件,则不再继续分裂,将当前节点视为叶子节点。
- 如果不满足条件,则继续分裂并递归执行下一步。
优缺点
- 优点:直接限制树的生长,计算速度快,避免过拟合。
- 缺点:可能过早终止分裂,导致模型拟合不足(欠拟合)。
ii、后剪枝
核心思想:先完全生成一棵树,然后从叶子节点逐步向上合并或移除子树,简化模型结构。
操作步骤
-
生成完全决策树:
- 构建一棵不剪枝的完全决策树,使其充分拟合训练数据。
-
定义剪枝准则:
- 误差率:计算剪枝前后验证集或交叉验证集的分类误差率。
- 损失函数:定义损失函数
误差(T)+
复杂度(T)
其中 是正则化参数。
-
从下至上剪枝:
- 依次遍历子树,从叶节点开始,计算:
- 剪枝前的误差:使用当前子树预测验证集的误差。
- 剪枝后的误差:将当前子树替换为叶子节点后的误差。
- 如果剪枝后的误差小于剪枝前,则执行剪枝操作。
- 依次遍历子树,从叶节点开始,计算:
-
重复剪枝:
- 直到剪枝操作不再降低验证误差,或者达到设定的复杂度阈值。
优缺点
- 优点:利用验证集或交叉验证,剪枝效果更准确,可以有效降低过拟合。
- 缺点:需要构建完整的决策树,计算量较大。
后剪枝是将最后一个节点和两个叶子用一个叶子代替,这个叶子的标签用代替那两个叶子的标签分别试验,计算损失函数,看看变小了没,没变小的话就放弃此次剪枝操作,变小的话就成功剪枝。
(11)决策树模型的优缺点
优点:

缺点:

五、⭐⭐全文总结⭐⭐
1、对于线性判别函数
本文第一部分主要介绍了线性判别函数,使用线性判别函数进行二分类时只需要一个判别函数,使用线性判别函数进行多分类时介绍了两种方法,一种是每两个之间就会有一个判别函数,所以判别函数总数为 个,判断完后进行投票最终决定样本的归属类,但这种方法可能会有无法判断的区域出现。所以又介绍了改进版的多分类,改进版多分类给每个类一个判别函数,所以判别函数共有C个,说是判别函数不如说是特征函数,形式和判别函数形式一样,为:
,样本带入每个类的特征函数再比较各个映射值的大小,最后决定样本得归属类。
2、对于线性分类器的构造
这个部分主要介绍了线性分类器得构造。
详细介绍了Fisher线性分类器,Fisher线性分类器得核心是找到一个最优投影向量,将高维的样本分类降维,在低维进行分类。最优投影向量为,其满足两个条件,投影后的类间散度最大,类内总散度最小。
详细介绍了感知器分类器,这个模型比较简单,分类准则是:对于样本 ,当
时,样本分类正确;若
,则分类错误。其准则函数也就是损失函数为:
,所以目标是求
,通过梯度下降法进行求解。
详细介绍了最小平方误差分类器,我对这部分的思想仍有漏洞,暂停
3、对于广义线性判别函数
核心是在原来 “基” 的基础上加入新的一组 “ 基 ” ,原来的一组基的维度与向量的维度一样,但无法在原空间进行分类,所以加入了高次的基,从而实现升维,进而样本变得可分。但同样也带来了计算复杂的问题。
4、对于分段线性判别函数
它的引入是为了克服广义线性判别函数计算复杂度过大的问题。最简单是分段判别函数是本文《一》中的线性判别函数实现多分类,这种方法是基于距离的分类,即样本距离哪个类的核心最近,那么该样本就属于哪个类。这样可以实现分类的前提的不同类的协方差要相同,即不同类的离散程度要一致。要不然误差就会很大。
对于不符合协方差相等的两个类要想把他们分开,可以先把每个类都分成若个子类,那么子类之间的协方差就比较接近了,再使用基于距离的分类,这里要分开的两个类是一个类的某个子类与在另一个类中与它距离最近的子类,这样一来,就会出现很多的分类面,结合到一起就形成了两个大类的分段的分类面。
分类完成后,还可以对分类面进行修正,修正的过程是:找到任意一个样本,找到他所属类,找到他在大类中所属的子类,看看他与这个子类的距离是否是他距离所有大类的所有子类最近的。如果是最近的,那么就不需要修正,如果其他大类中某个子类距离样本的距离更近,那么修正相关子类的权重参数,这个权重参数是什么意思?是因为这里的样本距离子类的距离是用子类的特征函数值来表示的,也就是《一》中线性判别函数改进版实现多分类中的那种函数:。
随后又介绍了局部训练法,这里引出了交遇区的概念,也就是在两类交叉的区域,这里是对交遇区的样本再进行寻找分离超平面,找到一个新的分离超平面后对于仍分错的样本,再找第二个分离超平面,依次进行找到n个分离超平面,这些超平面取个交集得到了一个分辨率较高的分段超平面。用这个代替交遇区的超平面。
最后介绍了决策树,文章举了一个非常详细的分类回归树的例子,在附录2,对理解很有帮助。
附录
1、类内散度矩阵和协方差矩阵的关系
(1)定义
协方差矩阵的定义为:
其中 是类
的均值向量。
类内散度矩阵的定义为:
和协方差矩阵的定义相似,但没有除以样本数量 。
(2)关系
表面上:类内散度矩阵是协方差矩阵的一个放大版,放大倍数为该类的样本数量 。
本质上:
协方差矩阵 是类
内样本点偏离均值的均方偏差,反映了每个维度的方差及维度之间的协方差。
类内散度矩阵 则是该偏离的累积(未归一化),反映了类内样本的总分布范围,而不关注样本数量的归一化影响。
2、分类回归树离散型特征建模
目标:用这些特征 (L, F, H) 建立分类模型,预测账号是否真实。
数据如下:
| 日志密度 (L) | 好友密度 (F) | 是否使用真实头像 (H) | 账号是否真实 (R) | |
|---|---|---|---|---|
| s | s | no | no | |
| s | l | yes | yes | |
| l | m | yes | yes | |
| m | m | yes | yes | |
| l | m | yes | yes | |
| m | m | yes | no | |
| s | m | no | no | |
| l | s | no | no |
步骤一、初始化决策树
决策树的构建以根节点为起点,首先考虑在当前训练数据集上,所有特征进行划分的最佳分裂点(基于Gini指数)。
步骤二、计算根节点的Gini指数
根节点包含所有8个样本,类别分布如下:
no: 4个yes: 4个
根节点的Gini指数计算为:
其中:表示类别
在所有样本中所占的比例。
因此:
步骤三、对每个特征计算划分后的Gini指数并得到第二层节点
(1)对日志密度 (L) 的划分
有3种划分方式:
划分方式1,左子集 L=s,右子集 L={m, l}
则
- 左子集分布:2个
no,1个yes - 右子集分布:2个
no,3个yes
子集Gini指数计算:
划分后的总Gini指数:
划分方式2,左子集 L=m,右子集 L={s, l}
则
- 左子集分布:1个
no,1个yes - 右子集分布:3个
no,3个yes
子集Gini指数计算:
划分后的总Gini指数:
划分方式3,左子集 L=l,右子集 L={m, s}
则
- 左子集分布:1个
no,2个yes - 右子集分布:3个
no,2个yes
经计算划分后的总Gini指数:
(2)对特征 F 的划分
有3种划分方式
划分方式1,左子集 F=s,右子集 F={m, l},计算后 :
划分方式2,左子集 F=m,右子集 F={s, l},计算后 :
划分方式3,左子集 F=l,右子集 F={m, s},计算后 :
(3)对特征 H 的划分
有1种划分方式
划分方式1,左子集 H=yes,右子集 H=no,计算后 :
通过计算可见共有7种划分方式,Gini指数最小的划分是:
左子集 H=yes,右子集 H=no,
所以第二层节点为:左节点 H=yes,右节点 H=no
- 左节点分布:1个
no,4个yes - 右节点分布:3个
no,0个yes
所以右节点是纯净的,不需要再分解,标签为 “ no ”
左节点需要继续分解:
步骤四、计算Gini指数并得到第三层节点
该过程为第二层左节点分解的过程。
第二层左节点的初始Gini指数为
(1)对日志密度 (L) 的划分
有3种划分方式:
划分方式1,左子集 L=s,右子集 L={m, l}
则
- 左子集分布:0个
no,1个yes - 右子集分布:1个
no,3个yes
子集Gini指数计算:
划分后的总Gini指数:
划分方式2,左子集 L=m,右子集 L={s, l}
则
- 左子集分布:1个
no,1个yes - 右子集分布:0个
no,3个yes
子集Gini指数计算:
划分后的总Gini指数:
划分方式3,左子集 L=l,右子集 L={m, s}
则
- 左子集分布:0个
no,2个yes - 右子集分布:1个
no,2个yes
经计算划分后的总Gini指数:
(2)对特征 F 的划分
有3种划分方式
划分方式1,左子集 F=s,右子集 F={m, l},计算后 :
划分方式2,左子集 F=m,右子集 F={s, l},计算后 :
划分方式3,左子集 F=l,右子集 F={m, s},计算后 :
由于第二层左节点H=yes中已经没有F=s的样本了,所以划分方式1并没有优化Gini指数。
通过计算可见共有6种划分方式,Gini指数最小的划分是:
左子集 H=yes,右子集 H=no,
所以第二层节点为:左子集 L=m,右子集 L={s, l}
- 左节点分布:1个
no,1个yes - 右节点分布:0个
no,3个yes
所以右节点是纯净的,不需要再分解,标签为 “ yes ”
左节点需要继续分解:
步骤五、计算Gini指数并得到第四层节点
该过程为第三层左节点分解的过程。
第三层左节点的初始Gini指数为
(2)对特征 F 的划分
有3种划分方式
划分方式1,左子集 F=s,右子集 F={m, l},计算后 :
划分方式2,左子集 F=m,右子集 F={s, l},计算后 :
划分方式3,左子集 F=l,右子集 F={m, s},计算后 :
可见,共有3种划分方式,都没有让Gini指数减小,此时只有两个样本没有区分开,两个样本为:
L=m,F=m,H=yes,类别=1
L=m,F=m,H=yes,类别=0
显而易见,这两个样本仅从数据集提供的特征是不能区分开的。
步骤六、整个模型,即最终决策树判断
我们增加第三层,更新 F=m 节点:
-
根节点,根据特征 H 分裂到第二层
- 如果 H=no,分类为
no。 - 如果 H=yes,进入下一层。
- 如果 H=no,分类为
-
第二层,根据特征 L分裂到第三层
- 如果 L=m,进入第三层。
- 如果 L={s,l},分类为
yes。
-
第三层(只剩下了 H=yes、L=m、F=m的样本)
无法分辩类别。
相关文章:
【机器学习chp3】判别式分类器:线性判别函数、线性分类器、广义线性分类器、分段线性分类器
前言: 本文遗留问题:(1)对最小平方误差分类器的理解不清晰.(2)分段线性判别函数的局部训练法理解不清晰。 推荐文章1,其中有关于感知机的分析 【王木头从感知机到神经网络】-CSDN博客 推荐文…...

【学习】【HTML】HTML、XML、XHTML
HTML 什么是 HTML? HTML (HyperText Markup Language) 是一种用于创建和展示网页的标准标记语言。它由一系列的元素组成,这些元素通过标签的形式来告诉浏览器如何显示内容。 HTML 的基本结构是什么? <!DOCTYPE html> <html> …...

ARM中ZI-data段和RW-data段
ARM中ZI-data段和RW-data段 1、只定义全局变量,不使用,不占用内存空间2、 定义并初始化全局变量为0 占用ZI-Data区域3、定义并初始化全局变量非0 占用RW-Data区域4、增加的是一个int8的数据为什么,size增加不是15、定义的全局变量为0…...
、GM(1,1)残差模型——基于Python实现)
关联度分析、灰色预测GM(1,1)、GM(1,1)残差模型——基于Python实现
关联度分析 import numpy as np import pandas as pd #关联度分析 #参考序列 Y_0[170,174,197,216.4,235.8] #被比较序列 Y_1[195.4,189.9,187.2,205,222.7] Y_2[308,310,295,346,367]#初始化序列 X_0np.array(Y_0)/Y_0[0] X_1np.array(Y_1)/Y_1[0] X_2np.array(Y_2)/Y_2[0]#计…...
)
linux常用命令(网络相关)
目录 1. ping - 检查网络连通性 参数 示例 2. ifconfig - 配置网络接口 参数 示例 3. ip - 显示和操作路由、网络设备、接口等 参数 示例 4. netstat - 显示网络连接、路由表、接口统计等信息 参数 示例 5. ss - 更快的netstat替代品 参数 示例 6. nslookup - …...

【uni-app多端】修复stmopjs下plus-websocket无心跳的问题
从这篇文章接着向下看: uniapp plus-websocket 和stompjs连接教程 安卓ios手机端有效 - 简书 按照文章的方式,能够实现APP下stmopjs长连接。但是有一个问题,就是会频繁输出 res-创建连接-1- 跟踪连接,会发现连接都会在大约40s后…...

VScode学习前端-01
小问题合集: vscode按!有时候没反应,有时候出来,是因为------>必须在英文状态下输入! 把鼠标放在函数、变量等上面,会自动弹出提示,但挡住视线,有点不习惯。 打开file->pre…...

Java-05 深入浅出 MyBatis - 配置深入 动态 SQL 参数、循环、片段
点一下关注吧!!!非常感谢!!持续更新!!! 大数据篇正在更新!https://blog.csdn.net/w776341482/category_12713819.html 目前已经更新到了: MyBatisÿ…...

突破自动驾驶瓶颈!KoMA:多智能体与大模型的完美融合
0.简介 本推文主要介绍了由来自北京航空航天大学的姜克谋、蔡轩和崔智勇教授等共同提出的一种名为KoMA的知识驱动的多智能体框架。论文《KoMA: Knowledge-driven Multi-agent Framework for Autonomous Driving with Large Language Models》提出了KoMA框架,通过结…...

YOLO入门教程(三)——训练自己YOLO11实例分割模型并预测【含教程源码+一键分类数据集 + 故障排查】
目录 引言前期准备Step0 环境部署1.安装OpenCV2.安装Pytorch3.安装Ultralytics Step1 打标训练Step2 格式转换Step3 整理训练集Step4 训练数据集4.1创建yaml文件4.2训练4.3预测4.4故障排查4.4.1OpenCV版本故障,把OpenCV版本升级到4.0以上4.4.2NumPy版本故障…...

【加入默语老师的私域】C#面试题
什么是依赖注入,如何实现? 依赖注入是一种设计模式。我们不是直接在另一个类(依赖类)中创建一个类的对象,而是将对象作为参数传递给依赖类的构造函数。它有助于编写松散耦合的代码,并有助于使代码更加模块…...
称重传感器指示器行业全面且深入的分析
称重传感器指示器是一种用于显示和解释称重传感器输出信号的设备,用于测量力、重量或压力。称重传感器是将物理力(如重量)转换为电信号的传感器,称重传感器指示器将该电信号转换为可读格式,通常以磅、公斤或牛顿等单位…...

NAT网络地址转换——Easy IP
NAT网络地址转换 Tip: EasylP没有地址池的概念,使用接口地址作为NAT转换的公有地址。EasylP适用于不具备固定公网IP地址的场景:如通过DHCP, PPPOE拨号获取地址的私有网络出口,可以直接使用获取到的动态地址进行转换。 本次实验模拟nat协议配置 AR1配置如下&…...
【Visual Studio系列教程】如何在 VS 上编程?
上一篇博客中,我们介绍了《什么是 Visual Studio?》。本文,我们来看第2篇《如何在 VS 上编程?》。阅读本文大约10 分钟。我们会向文件中添加代码,了解 Visual Studio 编写、导航和了解代码的简便方法。 本文假定&…...

Mybatis-Plus 多租户插件属性自动赋值
文章目录 1、Mybatis-Plus 多租户插件1.1、属性介绍1.2、使用多租户插件mavenymlThreadLocalUtil实现 定义,注入租户处理器插件测试domianservice & ServiceImplmapper 测试mapper.xml 方式 1.3、不使用多租户插件 2、实体对象的属性自动赋值使用1. 定义实体类2. 实现 Meta…...

AWTK-WIDGET-WEB-VIEW 实现笔记 (4) - Ubuntu
Ubuntu 上实现 AWTK-WIDGET-WEB-VIEW 开始以为很简单,后来发现是最麻烦的。因为 Ubuntu 上的 webview 库是 基于 GTK 的,而 AWTK 是基于 X11 的,两者的窗口系统不同,所以期间踩了几个大坑。 1. 编译 AWTK 在使用 Linux 的输入法时…...
--高级函数特性详解)
Python入门(7)--高级函数特性详解
Python高级函数特性详解 🚀 目录 匿名函数(Lambda)装饰器的使用生成器与迭代器递归函数应用实战案例:文件批处理工具 1. 匿名函数(Lambda)深入解析 🎯 1.1 Lambda函数基础与进阶 1.1.1 基本…...

【数据库原理】理解数据库,基础知识
第一代:网状数据库;第二代:关系数据库;第三代:新一代数据库系统BigData 一、理解数据库 什么是数据:信息,对事物的存在方方式、运动状态及特征的描述。数据,记录信息的识别方式有数…...

VConsole——(H5调试工具)前端开发使用于手机端查看控制台和请求发送
因为开发钉钉H5微应用在手机上一直查看不到日志等,出现安卓和苹果上传图片一边是成功的,一边是失败的,所以找了这个,之前在开发微信小程序进行调试的时候能看到,之前没想到过,这次被人提点发现可以单独使用…...

论文分享 | FuzzLLM:一种用于发现大语言模型中越狱漏洞的通用模糊测试框架
大语言模型是当前人工智能领域的前沿研究方向,在安全性方面大语言模型存在一些挑战和问题。分享一篇发表于2024年ICASSP会议的论文FuzzLLM,它设计了一种模糊测试框架,利用模型的能力去测试模型对越狱攻击的防护水平。 论文摘要 大语言模型中…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...