Debezium日常分享系列之:Debezium3版本Debezium connector for JDBC
Debezium日常分享系列之:Debezium3版本Debezium connector for JDBC
- 概述
- JDBC连接器的工作原理
- 消费复杂的Debezium变更事件
- 至少一次的传递
- 多个任务
- 数据和列类型映射
- 主键处理
- 删除模式
- 幂等写入
- 模式演化
- 引用和大小写敏感性
- 连接空闲超时
- 数据类型映射
- 部署
- Debezium JDBC连接器配置
- JDBC连接器hibernate.*透传属性
- 常见问题
- 更多Debezium技术内容
概述
Debezium JDBC连接器是一个Kafka Connect接收器连接器实现,可以从多个源主题消费事件,然后通过使用JDBC驱动程序将这些事件写入关系型数据库。该连接器支持各种数据库方言,包括Db2、MySQL、Oracle、PostgreSQL和SQL Server。
JDBC连接器的工作原理
Debezium JDBC连接器是一个Kafka Connect接收器连接器,因此需要Kafka Connect运行时。该连接器定期轮询其订阅的Kafka主题,从这些主题中消费事件,然后将事件写入配置的关系型数据库。该连接器通过使用upsert语义和基本模式演化来支持幂等写操作。
Debezium JDBC连接器提供以下功能:
- 支持从多个源主题消费事件并写入关系型数据库。
- 支持各种数据库方言,包括Db2、MySQL、Oracle、PostgreSQL和SQL Server。
- 支持幂等写操作,通过使用upsert语义和基本模式演化。
- 可以定期轮询Kafka主题并消费事件。
- 提供基于JDBC驱动程序的可靠数据传输和写入。
- 可以配置数据的格式和映射规则。
- 支持监视和跟踪变更事件。
- 可以处理大规模和高吞吐量的数据。
- 具有可扩展性和容错性,可以处理故障和重启情况。
- 提供详细的日志记录和监控功能。
消费复杂的Debezium变更事件
默认情况下,Debezium源连接器生成复杂的分层变更事件。当将Debezium连接器与其他JDBC接收器连接器实现一起使用时,您可能需要应用ExtractNewRecordState单个消息转换(SMT)来展平变更事件的有效载荷,以便可以由接收器实现消费。如果运行Debezium JDBC接收器连接器,则无需部署SMT,因为Debezium接收器连接器可以直接消费原生的Debezium变更事件,无需使用转换。
当JDBC接收器连接器从Debezium源连接器消费复杂变更事件时,它从原始插入或更新事件的after部分提取值。当接收器消费删除事件时,不会查看事件的有效负载的任何部分。
重要:
Debezium JDBC接收器连接器未设计用于从模式更改主题读取。如果您的源连接器配置为捕获模式更改,请在JDBC连接器配置中设置topics或topics.regex属性,以便连接器不从模式更改主题消费。
至少一次的传递
Debezium JDBC接收器连接器保证从Kafka主题消费的事件至少被处理一次。
多个任务
您可以在多个Kafka Connect任务上运行Debezium JDBC接收器连接器。要在多个任务上运行连接器,请将tasks.max配置属性设置为您希望连接器使用的任务数量。Kafka Connect运行时会启动指定数量的任务,并在每个任务上运行一个连接器实例。多个任务可以通过并行读取和处理来自多个源主题的更改,从而提高性能。
数据和列类型映射
为了使Debezium JDBC接收器连接器能够正确地将入站消息字段的数据类型映射到出站消息字段,连接器需要有关源事件中每个字段的数据类型的信息。该连接器支持不同数据库方言之间的广泛的列类型映射。为了正确地将事件字段中的类型元数据转换为目标列类型,连接器应用了为源数据库定义的数据类型映射。您可以通过在源连接器配置中设置column.propagate.source.type或datatype.propagate.source.type选项来改进连接器解析列的数据类型的方式。启用这些选项时,Debezium会包含额外的参数元数据,帮助JDBC接收器连接器更准确地解析目标列的数据类型。
为了使Debezium JDBC接收器连接器能够处理来自Kafka主题的事件,Kafka主题消息键(如果存在)必须是原始数据类型或Struct。此外,源消息的有效负载必须是一个具有没有嵌套结构类型的扁平结构,或者符合Debezium复杂的分层结构的嵌套结构布局。
如果Kafka主题中的事件结构不符合这些规则,您必须实现自定义的单个消息转换,将源事件的结构转换为可用的格式。
主键处理
默认情况下,Debezium JDBC接收器连接器不会将源事件中的任何字段转换为事件的主键。不幸的是,缺乏稳定的主键可能会根据您的业务需求或接收器使用upsert语义而使事件处理复杂化。为了定义一致的主键,您可以配置连接器使用以下表格中描述的一种主键模式:
| 模式 | 描述 |
|---|---|
| none | 创建表时未指定主键字段。 |
| kafka | 主键由以下三列组成:__connect_topic、__connect_partition、__connect_offset这些列的值来自 Kafka 事件的坐标。 |
| record_key | 主键由 Kafka 事件的键组成。如果主键是原始类型,请通过设置 primary.key.fields 属性指定要使用的列的名称。 如果主键是结构类型,则结构中的字段将映射为主键的列。 您可以使用 primary.key.fields 属性将主键限制为列的子集。 |
| record_value | 主键由 Kafka 事件的值组成。由于 Kafka 事件的值始终是结构体,因此默认情况下,值中的所有字段都将成为主键的列。要使用主键中的字段子集,请设置 primary.key.fields 属性以指定要从中派生主键列的值中的字段的逗号分隔列表。 |
| record_header | 主键由 Kafka 事件的标头组成。Kafka 事件的标头可能包含多个标头,每个标头可以是结构或原始数据类型,连接器会将这些标头组成一个结构。因此,此结构中的所有字段都将成为主键的列。要使用主键中的字段子集,请设置 primary.key.fields 属性以指定要从中派生主键列的值中的字段的逗号分隔列表。 |
重要:
某些数据库方言可能会在将primary.key.mode设置为kafka并将schema.evolution设置为basic时抛出异常。当方言将STRING数据类型映射到可变长度字符串数据类型(如TEXT或CLOB),并且方言不允许主键列具有无限长度时,会出现此异常。为了避免这个问题,请在您的环境中应用以下设置:
- 不要将schema.evolution设置为basic。
- 提前创建数据库表和主键映射。
如果某个列映射到目标数据库中不允许作为主键的数据类型,那么在primary.key.fields中需要明确列出这些列。
删除模式
当消费DELETE或tombstone事件时,Debezium JDBC接收器连接器可以在目标数据库中删除行。默认情况下,JDBC接收器连接器不启用删除模式。
如果您想让连接器删除行,必须在连接器配置中显式设置delete.enabled=true。为了使用此模式,您还必须将primary.key.fields设置为非none的值。之前的配置是必要的,因为删除操作是基于主键映射执行的,所以如果目标表没有主键映射,连接器将无法删除行。
幂等写入
Debezium JDBC接收器连接器可以执行幂等写入,使其能够重复播放相同的记录而不改变最终的数据库状态。
要使连接器执行幂等写入,必须显式设置连接器的insert.mode为upsert。upsert操作将根据指定的主键是否已存在,应用为更新或插入操作。
如果主键值已经存在,则操作将更新行中的值。如果指定的主键值不存在,则插入操作将添加新行。
每个数据库方言对幂等写入的处理方式不同,因为没有针对upsert操作的SQL标准。下表显示了Debezium支持的数据库方言的upsert DML语法:
| Dialect | Upsert 语法 |
|---|---|
| Db2 | MERGE … |
| MySQL | INSERT … ON DUPLICATE KEY UPDATE … |
| Oracle | MERGE … |
| PostgreSQL | INSERT … ON CONFLICT … DO UPDATE SET … |
| SQL Server | MERGE … |
模式演化
您可以将以下模式演化模式与 Debezium JDBC 接收器连接器结合使用:
| 模式 | 描述 |
|---|---|
| none | 连接器不执行任何 DDL 模式演变。 |
| basic | 连接器会自动检测事件负载中存在但目标表中不存在的字段。连接器会修改目标表以添加新字段。 |
当将schema.evolution设置为basic时,连接器根据传入事件的结构自动创建或更改目标数据库表。
当首次从主题接收到事件,并且目标表尚不存在时,Debezium JDBC接收器连接器使用事件的键或记录的模式结构来解析表的列结构。如果启用了模式演化,连接器会在将DML事件应用于目标表之前准备并执行CREATE TABLE SQL语句。
当Debezium JDBC连接器从主题接收到事件时,如果记录的模式结构与目标表的模式结构不同,连接器将使用事件的键或其模式结构来识别哪些列是新添加的,并必须添加到数据库表中。如果启用了模式演化,连接器会在将DML事件应用于目标表之前准备并执行ALTER TABLE SQL语句。由于更改列数据类型、删除列和调整主键可能被认为是危险操作,连接器禁止执行这些操作。
每个字段的模式确定列是否为NULL或NOT NULL。模式还定义了每个列的默认值。如果连接器尝试创建具有不希望的nullability设置或默认值的表,则必须提前手动创建表,或在接收器连接器处理事件之前调整关联字段的模式。要调整nullability设置或默认值,可以引入自定义的单个消息转换,在管道中应用更改,或修改源数据库中定义的列状态。
字段的数据类型是根据预定义的映射集解析的。
重要:
当您向已存在于目标数据库中的表的事件结构中引入新字段时,必须将新字段定义为可选的,或者这些字段必须在数据库模式中指定默认值。如果您想从目标表中删除一个字段,可以使用以下选项之一:
- 手动删除该字段。
- 删除该列。
- 为该字段分配默认值。
- 将该字段定义为可空。
引用和大小写敏感性
Debezium JDBC接收器连接器通过构建在目标数据库上执行的DDL(模式更改)或DML(数据更改)SQL语句来消费Kafka消息。默认情况下,连接器使用源主题和事件字段的名称作为目标表和列名称的基础。构建的SQL语句不会自动使用引号引用标识符以保留原始字符串的大小写。因此,默认情况下,目标数据库中表或列名称的大小写取决于数据库在未指定大小写时如何处理名称字符串。
例如,如果目标数据库方言是Oracle,事件的主题是orders,那么目标表将被创建为ORDERS,因为Oracle在未使用引号引用时默认使用大写名称。类似地,如果目标数据库方言是PostgreSQL,事件的主题是ORDERS,那么目标表将被创建为orders,因为PostgreSQL在未使用引号引用时默认使用小写名称。
为了显式保留Kafka事件中存在的表和字段名称的大小写,在连接器配置中将quote.identifiers属性的值设置为true。当设置了此选项时,当传入的事件属于名为orders的主题,并且目标数据库方言是Oracle时,连接器将创建一个名为orders的表,因为构建的SQL将表名定义为"orders"。启用引号引用时,连接器创建列名时会产生相同的行为。
连接空闲超时
Debezium的JDBC接收器连接器利用连接池来提高性能。连接池被设计用于建立初始一组连接,保持指定数量的连接,并根据需要有效地为应用程序分配连接。然而,当连接在连接池中闲置时,可能会出现一个挑战,如果它们在数据库配置的空闲超时阈值之后仍处于非活动状态,可能会触发超时。
为了减轻空闲连接线程触发超时的潜在问题,连接池提供了定期验证每个连接活动性的机制。这个验证确保连接保持活动,并防止数据库将其标记为闲置。在网络中断的情况下,如果Debezium尝试使用已终止的连接,连接器会提示连接池生成一个新的连接。
默认情况下,Debezium的JDBC接收器连接器不进行空闲超时测试。然而,您可以通过设置hibernate.c3p0.idle_test_period属性来配置连接器以指定的间隔请求连接池执行超时测试。例如:
{"hibernate.c3p0.idle_test_period": "300"
}
Debezium的JDBC接收器连接器使用Hibernate C3P0连接池。您可以通过设置hibernate.c3p0.*配置名称空间中的属性来自定义CP30连接池。在前面的示例中,设置hibernate.c3p0.idle_test_period属性将配置连接池每300秒执行一次空闲超时测试。在应用配置后,连接池将开始每五分钟评估未使用的连接。
数据类型映射
Debezium的JDBC接收器连接器通过使用逻辑或基本类型映射系统来解析列的数据类型。基本类型包括整数、浮点数、布尔值、字符串和字节等值。通常,这些类型仅使用特定的Kafka Connect Schema类型代码表示。逻辑数据类型更常见地是复杂类型,包括具有固定字段名称和模式的基于结构的类型,或者使用特定编码表示的值,例如自纪元以来的天数。
以下示例显示了基本和逻辑数据类型的代表结构:
基本字段模式
{"schema": {"type": "INT64"}
}
逻辑字段架构
["schema": {"type": "INT64","name": "org.apache.kafka.connect.data.Date"}
]
Kafka Connect并不是这些复杂逻辑类型的唯一数据源。实际上,Debezium源连接器生成的更改事件具有具有类似逻辑类型的字段,用于表示各种不同的数据类型,包括但不限于时间戳、日期甚至JSON数据。
Debezium的JDBC接收器连接器使用这些基本和逻辑类型来将列的类型解析为JDBC SQL代码,该代码表示列的类型。然后,底层的Hibernate持久化框架使用这些JDBC SQL代码将列的类型解析为正在使用的方言的逻辑数据类型。以下表格说明了Kafka Connect和JDBC SQL类型之间以及Debezium和JDBC SQL类型之间的基本和逻辑映射。实际的最终列类型因每个数据库类型而异。
- Kafka Connect 基元与列数据类型之间的映射
- Kafka Connect 逻辑类型与列数据类型之间的映射
- Debezium 逻辑类型与列数据类型之间的映射
- Debezium 方言特定逻辑类型与列数据类型之间的映射
表 1. Kafka Connect 原语和列数据类型之间的映射
| Primitive Type | JDBC SQL Type |
|---|---|
| INT8 | Types.TINYINT |
| INT16 | Types.SMALLINT |
| INT32 | Types.INTEGER |
| INT64 | Types.BIGINT |
| FLOAT32 | Types.FLOAT |
| FLOAT64 | Types.DOUBLE |
| BOOLEAN | Types.BOOLEAN |
| STRING | Types.CHAR, Types.NCHAR, Types.VARCHAR, Types.NVARCHAR |
| BYTES | Types.VARBINARY |
表 2. Kafka Connect 逻辑类型和列数据类型之间的映射
| Primitive Type | JDBC SQL Type |
|---|---|
| org.apache.kafka.connect.data.Decimal | Types.DECIMAL |
| org.apache.kafka.connect.data.Date | Types.DATE |
| org.apache.kafka.connect.data.Time | Types.TIMESTAMP |
| org.apache.kafka.connect.data.Timestamp | Types.TIMESTAMP |
表 3. Debezium 逻辑类型和列数据类型之间的映射
| Primitive Type | JDBC SQL Type |
|---|---|
| io.debezium.time.Date | Types.DATE |
| io.debezium.time.Time | Types.TIMESTAMP |
| io.debezium.time.MicroTime | Types.TIMESTAMP |
| io.debezium.time.NanoTime | Types.TIMESTAMP |
| io.debezium.time.ZonedTime | Types.TIME_WITH_TIMEZONE |
| io.debezium.time.Timestamp | Types.TIMESTAMP |
| io.debezium.time.MicroTimestamp | Types.TIMESTAMP |
| io.debezium.time.NanoTimestamp | Types.TIMESTAMP |
| io.debezium.time.ZonedTimestamp | Types.TIMESTAMP_WITH_TIMEZONE |
| io.debezium.data.VariableScaleDecimal | Types.DOUBLE |
重要的:
如果数据库不支持时间或带有时区的时间戳,则映射将解析为没有时区的等效时间戳。
表 4. Debezium 方言特定逻辑类型与列数据类型之间的映射

除了上面的原始和逻辑映射外,如果变更事件的源是Debezium源连接器,则可以通过启用列或数据类型传播进一步影响列类型的分辨率,以及其长度、精度和比例。要强制传播,必须在源连接器配置中设置以下属性之一:
- column.propagate.source.type
- datatype.propagate.source.type
Debezium JDBC sink连接器应用具有更高优先级的值。例如,假设变更事件中包含以下字段架构:
Debezium 启用列或数据类型传播来更改事件字段架构
{"schema": {"type": "INT8","parameters": {"__debezium.source.column.type": "TINYINT","__debezium.source.column.length": "1"}}
}
在上述示例中,如果没有设置模式参数,Debezium JDBC sink连接器将此字段映射为Types.SMALLINT列类型。Types.SMALLINT可以根据数据库方言的不同而具有不同的逻辑数据库类型。对于MySQL,在示例中,列类型转换为未指定长度的TINYINT列类型。如果为源连接器启用了列或数据类型传播,则Debezium JDBC sink连接器使用映射信息来细化数据类型映射过程,并创建一个类型为TINYINT(1)的列。
注意:
通常情况下,当源数据库和目标数据库使用相同类型的数据库时,使用列或数据类型传播的效果会更显著。我们一直在努力改进跨异构数据库的映射方式,当前的类型系统允许我们根据反馈不断完善这些映射。
部署
要部署Debezium JDBC连接器,您需要安装Debezium JDBC连接器归档文件,配置连接器,并通过将其配置添加到Kafka Connect来启动连接器。
先决条件
- 已安装和配置Kafka Connect、Kafka和Zookeeper。
- 已安装并配置了一个目标数据库以接受JDBC连接。
步骤
- 下载Debezium。
- 将文件提取到您的Kafka Connect环境中。
- 可选地,从Maven Central下载JDBC驱动程序,并将下载的驱动程序文件提取到包含JDBC sink连接器JAR文件的目录中。
- 注意:Oracle和Db2的驱动程序未包含在JDBC sink连接器中。您必须手动下载驱动程序并安装它们。
- 将驱动程序JAR文件添加到已安装JDBC sink连接器的路径中。
- 确保您安装JDBC sink连接器的路径是CLASSPATH的一部分。
- 重新启动Kafka Connect进程以获取新的JAR文件。
Debezium JDBC连接器配置
通常情况下,您可以通过提交一个JSON请求来注册Debezium JDBC连接器,该请求指定了连接器的配置属性。以下示例显示了一个JSON请求,用于注册一个Debezium JDBC sink连接器实例,该实例从名为orders的主题中消费事件,并具有最常见的配置设置:
示例:Debezium JDBC连接器配置
{"name": "jdbc-connector", "config": {"connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector", "tasks.max": "1", "connection.url": "jdbc:postgresql://localhost/db", "connection.username": "pguser", "connection.password": "pgpassword", "insert.mode": "upsert", "delete.enabled": "true", "primary.key.mode": "record_key", "schema.evolution": "basic", "database.time_zone": "UTC", "topics": "orders" }
}
JDBC 连接器配置设置描述
- 使用 Kafka Connect 服务注册连接器时分配给连接器的名称。
- JDBC 接收器连接器类的名称。
- 为此连接器创建的最大任务数。
- 连接器用于连接到其写入的接收器数据库的 JDBC URL。
- 用于身份验证的数据库用户的名称。
- 用于身份验证的数据库用户的密码。
- 连接器使用的 insert.mode。
- 启用数据库中记录的删除。有关更多信息,请参阅 delete.enabled 配置属性。
- 指定用于解析主键列的方法。有关更多信息,请参阅 primary.key.mode 配置属性。
- 使连接器能够演变目标数据库的架构。有关更多信息,请参阅 schema.evolution 配置属性。
- 指定写入时间字段类型时使用的时区。
- 要使用的主题列表,以逗号分隔。
您可以通过POST命令将此配置发送到正在运行的Kafka Connect服务。服务记录配置并启动一个或多个sink连接器任务,执行以下操作:
- 连接到数据库。
- 从订阅的Kafka主题消费事件。
- 将事件写入配置的数据库。
JDBC连接器hibernate.*透传属性
Kafka Connect支持透传配置,使您能够通过从连接器配置直接传递某些属性来修改底层系统的行为。默认情况下,一些Hibernate属性通过JDBC连接器的连接属性(例如connection.url、connection.username和connection.pool.*_size)以及连接器的运行时属性(例如database.time_zone、quote.identifiers)进行公开。
如果您想自定义其他Hibernate行为,可以利用透传机制,将使用hibernate.*命名空间的属性添加到连接器配置中。例如,为了帮助Hibernate解析目标数据库的类型和版本,可以添加hibernate.dialect属性,并将其设置为数据库的完全限定类名,例如org.hibernate.dialect.MariaDBDialect。
常见问题
是否需要使用ExtractNewRecordState单一消息转换?
不需要,这实际上是Debezium JDBC连接器与其他实现的区别之一。虽然连接器能够摄取类似竞争对手的扁平化事件,但它还可以本地地摄取Debezium的复杂变更事件结构,而无需任何特定类型的转换。
如果更改列的类型,或者重命名或删除列,是否由模式演变处理?
不,Debezium JDBC连接器不会对现有列进行任何更改。连接器支持的模式演变非常基础。它只是将事件结构中的字段与表的列列表进行比较,然后添加尚未在表中定义为列的字段。如果列的类型或默认值发生更改,连接器不会在目标数据库中进行调整。如果列被重命名,旧列保持不变,连接器将在表中追加一个具有新名称的列;但是,旧列中的现有数据行保持不变。此类模式更改应手动处理。
如果列的类型未解析为我想要的类型,如何强制映射到不同的数据类型?
Debezium JDBC连接器使用复杂的类型系统来解析列的数据类型。有关此类型系统如何将特定字段的模式定义解析为JDBC类型的详细信息,请参阅数据和列类型映射部分。如果要应用不同的数据类型映射,请手动定义表以明确获取首选的列类型。
如何在不更改Kafka主题名称的情况下指定表名的前缀或后缀?
为了向目标表名添加前缀或后缀,调整table.name.format连接器配置属性以应用所需的前缀或后缀。例如,要为所有表名添加jdbc_前缀,将table.name.format配置属性的值设置为jdbc_${topic}。如果连接器订阅了一个名为orders的主题,那么生成的表将被创建为jdbc_orders。
为什么有些列会自动加引号,即使没有启用标识符引用?
在某些情况下,即使没有启用quote.identifiers,特定的列或表名可能仍会被显式引用。这通常是在列或表名以特定约定开头或使用特定约定时,否则会被视为非法语法。例如,当primary.key.mode设置为kafka时,某些数据库只允许以下划线开头的列名在列名被引用时才有效。引用行为是特定于方言的,并在不同类型的数据库之间有所不同。
更多Debezium技术内容
更多Debezium技术请参考:
- Debezium技术专栏
相关文章:
Debezium日常分享系列之:Debezium3版本Debezium connector for JDBC
Debezium日常分享系列之:Debezium3版本Debezium connector for JDBC 概述JDBC连接器的工作原理消费复杂的Debezium变更事件至少一次的传递多个任务数据和列类型映射主键处理删除模式幂等写入模式演化引用和大小写敏感性连接空闲超时数据类型映射部署Debezium JDBC连…...

「Mac玩转仓颉内测版24」基础篇4 - 浮点类型详解
本篇将详细介绍 Cangjie 中的浮点类型,包括浮点数的表示方法、精度、舍入与溢出处理、科学计数法表示、字面量的进制表示、常用运算、类型转换及应用场景,帮助开发者掌握浮点数的使用方法。 关键词 浮点类型表示精度与舍入溢出与下溢科学计数法类型转换…...

【UGUI】Unity 背包系统实现02:道具信息提示与显示
在游戏开发中,背包系统是一个常见的功能模块,用于管理玩家拾取的物品。本文将详细介绍如何在 Unity 中实现一个简单的背包系统,包括道具信息的提示和显示功能。我们将通过代码和场景搭建来逐步实现这一功能。 1. 功能需求清单 在实现背包系…...

掌握移动端性能测试利器:深入JMeter手机录制功能
引言 在当今移动互联网时代,应用程序的性能和用户体验至关重要。为了确保应用程序在不同设备和网络环境下都能稳定运行,性能测试成为了不可或缺的一环。Apache JMeter作为一款强大的开源性能测试工具,不仅支持传统的PC端性能测试,…...

springboot010大学生入学审核系统的设计与实现(源码+包运行+LW+技术指导)
项目描述 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本站是一个B/S模式系统,采用Spring Boot框架,MYSQL数据库设计开发,充分保证系统的稳定性。系统具有界面清晰、操作简单,…...

Qt/C++离线地图的加载和交互/可以离线使用/百度和天地图离线/支持手机上运行
一、前言说明 在地图应用中,有很多时候是需要断网环境中离线使用的,一般会采用两种做法,一种是只下载好离线瓦片地图,然后根据不同的缩放和经纬度坐标绘制瓦片。这种方式优点是任何地图都支持,只需要拿到瓦片即可&…...

从繁琐到优雅:用 PyTorch Lightning 简化深度学习项目开发
从繁琐到优雅:用 PyTorch Lightning 简化深度学习项目开发 在深度学习开发中,尤其是使用 PyTorch 时,我们常常需要编写大量样板代码来管理训练循环、验证流程和模型保存等任务。PyTorch Lightning 作为 PyTorch 的高级封装库,帮助…...

UE5 第一人称射击项目学习(完结)
这个项目几乎完结了。 也算我上手的第一个纯蓝图小项目。 现在只剩下缝缝补补了。 之前把子弹设计为蓝图,这里要引入C的面向对象思想,建立成员函数。 首先双击打开子弹的蓝图 这边就可以构造成员函数 写一个print your name 在这里生成成员函数后&am…...

Banana Pi BPI-CanMV-K230D-Zero 采用嘉楠科技 K230D RISC-V芯片设计
概述 Banana Pi BPI-CanMV-K230D-Zero 采用嘉楠科技 K230D RISC-V芯片设计,探索 RISC-V Vector1.0 的前沿技术,选择嘉楠科技的 Canmv K230D Zero 开发板。这款创新的开发板是由嘉楠科技与香蕉派开源社区联合设计研发,搭载了先进的勘智 K230D 芯片。 K230…...

【vim】使用 gn 组合命令实现搜索选中功能
gn是Vim 7.4新增的一个操作(motion),作用是跳到并选中下一个搜索匹配项。 具体说,Vim里执行搜索后,执行n操作只会跳转到下一个匹配项,而不选中它。但是我们往往需要对匹配项执行一些修改操作,例…...

【Python刷题】广度优先搜索相关问题
题目描述 小A与小B 算法思路 小A一次移动一步,但有八个方向,小B一次移动两步,只有四个方向,要求小A和小B最早的相遇时间。用两个队列分别记录下小A和小B每一步可以走到的位置,通过一个简单的bfs就能找到这些位置并…...

竞赛思享会 | 2024年第十届数维杯国际数学建模挑战赛D题【代码+演示】
Hello,这里是Easy数模!以下idea仅供参考,无偿分享! 题目背景 本题旨在通过对中国特定城市的房产、人口、经济、服务设施等数据进行分析,评估其在应对人口老龄化、负增长趋势和极端气候事件中的韧性与可持续发展能力。…...
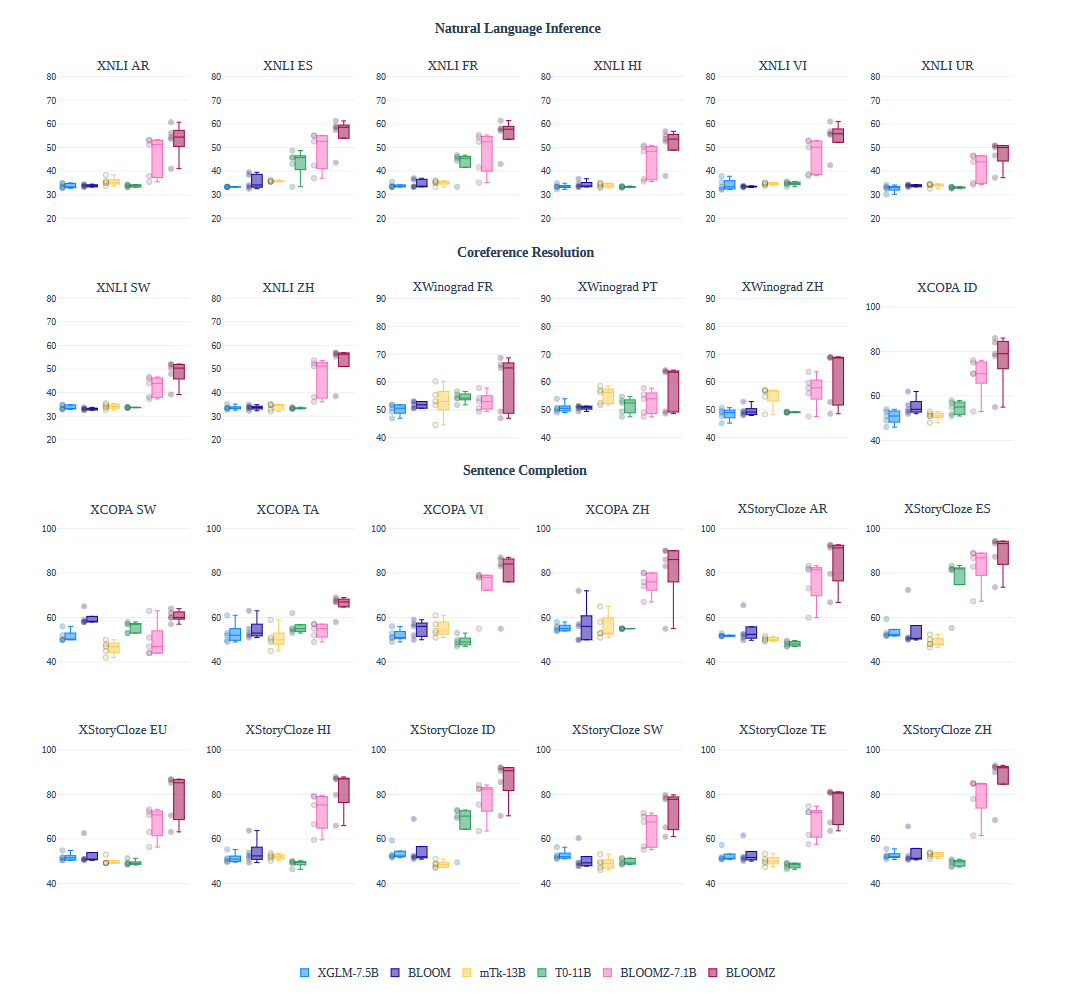
早期超大规模语言模型的尝试——BLOOM模型论文解读,附使用MindSpore和MindNLP的模型和实验复现
背景 预训练语言模型已经成为了现代自然语言处理pipeline中的基石,因为其在少量的标注数据上产生更好的结果。随着ELMo、ULMFiT、GPT和BERT的开发,使用预训练模型在下游任务上微调的范式被广泛使用。随后发现预训练语言模型在没有任何额外训练的情况下任…...

二分查找题目:有序数组中的单一元素
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法一思路和算法代码复杂度分析 解法二思路和算法代码复杂度分析 题目 标题和出处 标题:有序数组中的单一元素 出处:540. 有序数组中的单一元素 难度 4 级 题目描述 要求 给定一个仅由整数…...

springboot基于Android的华蓥山旅游导航系统
摘 要 华蓥山旅游导航系统是一款专为华蓥山景区设计的智能导览应用,旨在为用户提供便捷的旅游信息服务。该系统通过整合华蓥山的地理信息、景点介绍、交通状况等数据,实现了对景区的全面覆盖。用户可以通过该系统获取实时的旅游资讯、交流论坛、地图等。…...

面向对象编程(OOP)深度解析:思想、原则与应用
🚀 作者 :“码上有前” 🚀 文章简介 :Java 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 面向对象编程(OOP)深度解析:思想、原则与应用 一、面向对象编程的基本…...

iPhone 17 Air看点汇总:薄至6mm 刷新苹果轻薄纪录
我们姑且将这款iPhone 17序列的超薄SKU称为“iPhone 17 Air”,Jeff Pu在报告中提到,我同意最近关于 iPhone 17超薄机型采用6 毫米厚度超薄设计的传言。 如果这一测量结果被证明是准确的,那么将有几个值得注意的方面。 首先,iPhone…...

「OpenCV交叉编译」ubuntu to arm64
Ubuntu x86_64 交叉编译OpenCV 为 arm64OpenCV4.5.5、cmake version 3.16.3交叉编译器 gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu 可在arm或linaro官网下载所需版本,本文的交叉编译器可点击链接跳转下载 Downloads | GNU-A Downloads – Arm Developer L…...
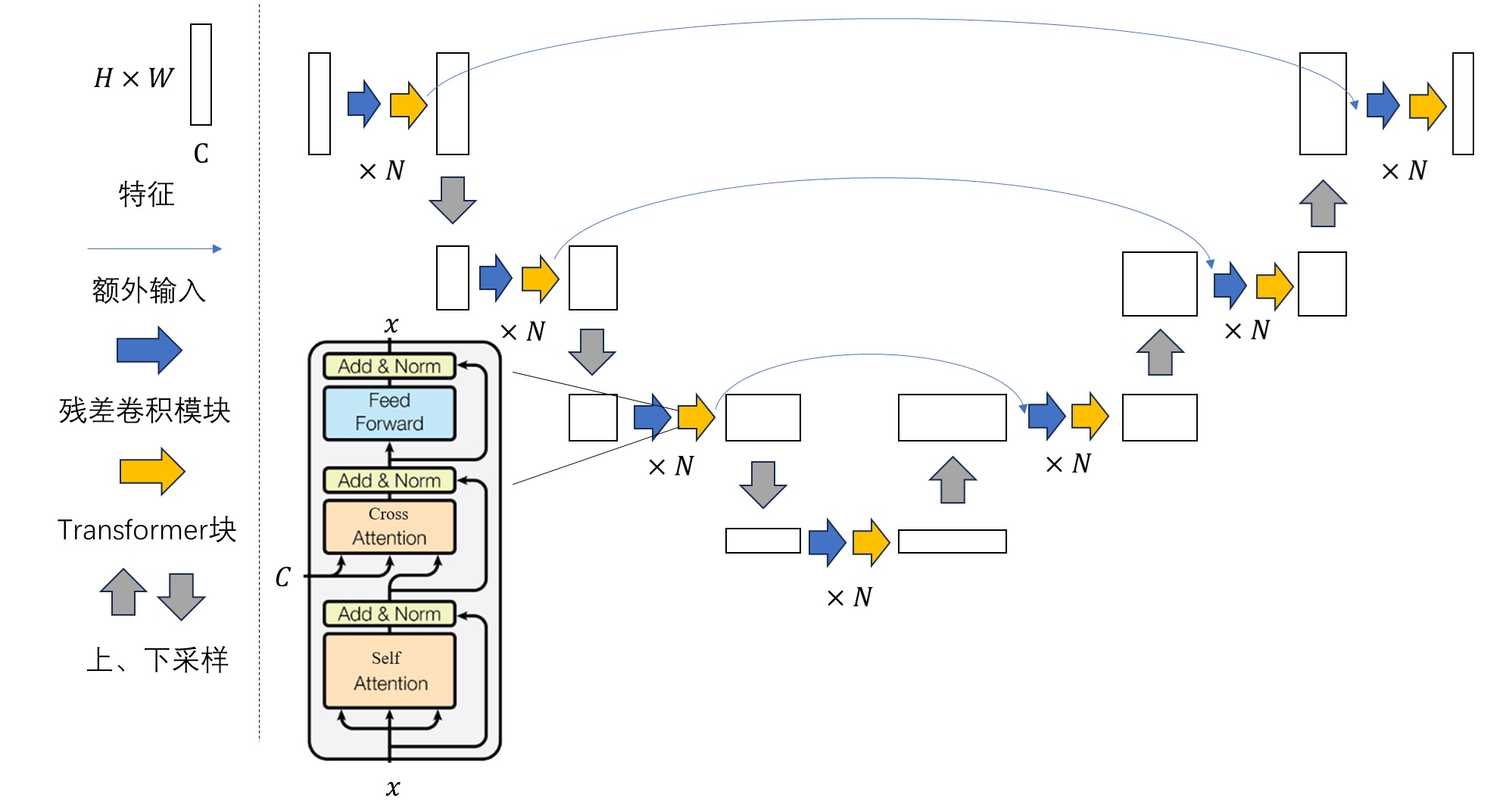
Stable Diffusion的解读(二)
Stable Diffusion的解读(二) 文章目录 Stable Diffusion的解读(二)摘要Abstract一、机器学习部分1. 算法梳理1.1 LDM采样算法1.2 U-Net结构组成 2. Stable Diffusion 官方 GitHub 仓库2.1 安装2.2 主函数2.3 DDIM采样器2.4 Unet 3…...

amd显卡和nVidia显卡哪个好 amd和英伟达的区别介绍
AMD和英伟达是目前市场上最主要的两大显卡品牌,它们各有自己的特点和优势,也有不同的适用场景和用户群体。那么,AMD显卡和英伟达显卡到底哪个好?它们之间有什么区别?我们又该如何选择呢?本文将从以下几个方…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...

Matlab实现任意伪彩色图像可视化显示
Matlab实现任意伪彩色图像可视化显示 1、灰度原始图像2、RGB彩色原始图像 在科研研究中,如何展示好看的实验结果图像非常重要!!! 1、灰度原始图像 灰度图像每个像素点只有一个数值,代表该点的亮度(或…...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...

数据库正常,但后端收不到数据原因及解决
从代码和日志来看,后端SQL查询确实返回了数据,但最终user对象却为null。这表明查询结果没有正确映射到User对象上。 在前后端分离,并且ai辅助开发的时候,很容易出现前后端变量名不一致情况,还不报错,只是单…...
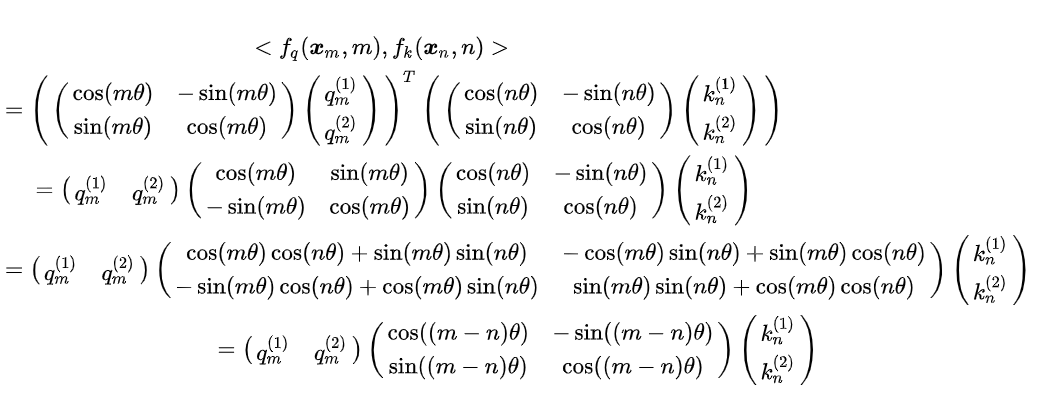
多模态学习路线(2)——DL基础系列
目录 前言 一、归一化 1. Layer Normalization (LN) 2. Batch Normalization (BN) 3. Instance Normalization (IN) 4. Group Normalization (GN) 5. Root Mean Square Normalization(RMSNorm) 二、激活函数 1. Sigmoid激活函数(二分类&…...