Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
大家好,我是锋哥。今天分享关于【Elasticsearch对于大数据量(上亿量级)的聚合如何实现?】面试题。希望对大家有帮助;

Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
1000道 互联网大厂Java工程师 精选面试题-Java资源分享网
在Elasticsearch中,对于大数据量(例如上亿量级的文档)的聚合操作,性能优化和高效实现是关键。聚合操作(aggregation)在数据量大的情况下可能会对系统性能造成较大的压力,因此需要采取多种优化措施来确保聚合操作能够高效地执行。下面是一些常见的优化方法和实现策略。
1. 合理设计索引和映射
索引设计对聚合性能有很大影响。以下是一些最佳实践:
-
字段类型优化:确保用于聚合的字段类型适当。例如,如果要做数值聚合,确保该字段使用数值类型(如
long、double等),而不是text类型。对于关键词聚合,确保字段使用keyword类型而非text类型,这样可以避免不必要的全文索引。 -
减少字段数目:避免在每个文档中存储不必要的字段,尤其是那些不会用于查询或聚合的字段。可以通过 Elasticsearch 的 source filtering 来减少返回文档的字段。
-
分片设计:为了提高聚合性能,合理的分片数设置非常重要。如果分片数过多,聚合操作可能会变得低效;如果分片数过少,可能导致每个分片的数据量过大,影响性能。常见的做法是根据数据量调整分片数和副本数,以保证数据均衡分布。
2. 使用 Doc Values 进行聚合
Doc Values 是Elasticsearch为字段提供的优化存储结构,用于高效地执行排序、聚合和脚本计算。对于聚合操作,应该确保聚合字段启用了 doc_values(默认启用)。例如,对于 keyword 和数值字段,doc_values 可以显著提高性能。
对于 text 类型字段,Elasticsearch会自动为其创建 keyword 类型的 doc_values,但如果需要对该字段进行聚合,应该显式地为其定义 keyword 类型映射。
3. 利用分布式聚合
Elasticsearch是分布式的,聚合操作会在多个分片上并行执行。为了更好地处理大数据量,Elasticsearch采用了“分布式聚合”的策略:
-
聚合结果的局部计算:Elasticsearch首先在每个分片内进行局部聚合,然后将这些结果汇总到协调节点进行最终计算。局部聚合减少了数据传输量,尤其是在大量分片的情况下。
-
聚合结果的合并:当聚合涉及多个分片时,Elasticsearch会在每个分片内进行局部聚合,然后将所有分片的结果合并成最终的聚合结果。需要注意的是,
terms聚合通常会消耗大量内存,因此如果字段的基数很大,可能需要其他优化手段。
4. 分步聚合与桶排序
对于大数据量的聚合,尤其是涉及大量不同值的字段(如 terms 聚合),可能会消耗大量内存。可以采用以下策略:
-
分步聚合(composite aggregation):
composite聚合是一个分页式的聚合,可以避免一次性返回大量的桶。在多层次的聚合中,当结果集较大时,可以通过分页查询来逐步获取数据。这种方式可以减少每次聚合的内存消耗。示例:
{"aggs": {"composite_agg": {"composite": {"sources": [{ "region": { "terms": { "field": "region.keyword" } } },{ "product": { "terms": { "field": "product.keyword" } } }]}}} }这种方式可以避免一次性返回所有的聚合结果,而是逐步分页获取每个桶的数据。
-
桶排序(bucket_sort aggregation):在有大量桶的情况下,可以使用桶排序聚合来限制返回的桶数。通过设置排序条件和分页,减少不必要的数据加载。
5. 优化内存和资源配置
大数据量聚合操作通常需要大量的内存和计算资源,因此合理配置内存和资源也是至关重要的:
-
JVM 堆内存调整:聚合操作消耗大量的内存,特别是在涉及大量桶(如
terms聚合)的情况下。因此,需要根据节点的硬件资源调整 JVM 堆内存(-Xmx和-Xms)。 -
Elasticsearch 内存配置:增加 Elasticsearch 节点的内存可以提升聚合操作的效率,但需要保证物理内存足够。通过合理的节点资源分配,避免节点因内存不足而导致 GC 问题或 OOM(OutOfMemoryError)错误。
-
避免频繁的 Full GC:确保 JVM 配置和垃圾回收机制能够高效地处理大量内存分配,以减少停顿时间。使用 G1 GC 或 ZGC 等适合大数据量的垃圾回收器。
6. 聚合结果的缓存
对于频繁查询的聚合结果,可以利用 Elasticsearch 的缓存机制来提升查询速度。例如,terms 聚合可以通过适当的缓存策略减少重复计算。在某些情况下,可以考虑使用 caching 来加速查询,尤其是对于某些长期不变的数据。
7. 避免使用过多的聚合层次
嵌套聚合可能会导致计算开销增加,特别是在数据量非常大的情况下。避免过深的聚合嵌套,尽量简化聚合结构。如果需要进行多层次的聚合,可以考虑分批执行聚合,分解为多个查询进行处理。
8. 调优查询并行度
Elasticsearch 的聚合操作会在多个分片上并行执行。在资源允许的情况下,可以适当增加 搜索线程池 的大小,以提高聚合计算的并行度。然而,这也可能导致高 CPU 占用和资源瓶颈,因此需要进行合理配置和调优。
总结
对于大数据量的聚合操作,Elasticsearch提供了多种方式来优化性能,包括合理的索引设计、分布式聚合、分步聚合、内存优化和资源调配等。通过这些手段,可以高效地处理上亿量级的数据聚合请求。具体的优化方案需要根据实际的数据量、硬件配置和查询需求来制定。
相关文章:
Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
大家好,我是锋哥。今天分享关于【Elasticsearch对于大数据量(上亿量级)的聚合如何实现?】面试题。希望对大家有帮助; Elasticsearch对于大数据量(上亿量级)的聚合如何实现? 1000道 …...

深度学习模型:循环神经网络(RNN)
一、引言 在深度学习的浩瀚海洋里,循环神经网络(RNN)宛如一颗独特的明珠,专门用于剖析序列数据,如文本、语音、时间序列等。无论是预测股票走势,还是理解自然语言,RNN 都发挥着举足轻重的作用。…...

前端---HTML(一)
HTML_网络的三大基石和html普通文本标签 1.我们要访问网络,需不需要知道,网络上的东西在哪? 为什么我们写,www.baidu.com就能找到百度了呢? 我一拼ping www.baidu.com 就拼到了ip地址: [119.75.218.70]…...

SQL 复杂查询
目录 复杂查询 一、目的和要求 二、实验内容 (1)查询出所有水果产品的类别及详情。 查询出编号为“00000001”的消费者用户的姓名及其所下订单。(分别采用子查询和连接方式实现) 查询出每个订单的消费者姓名及联系方式。 在…...

银河麒麟桌面系统——桌面鼠标变成x,窗口无关闭按钮的解决办法
银河麒麟桌面系统——桌面鼠标变成x,窗口无关闭按钮的解决办法 1、支持环境2、详细操作说明步骤1:用root账户登录电脑步骤2:导航到kylin-wm-chooser目录步骤3:编辑default.conf文件步骤4:重启电脑 3、结语 Ὁ…...

抓包之使用chrome的network面板
写在前面 本文看下工作中非常非常常用的chrome的network面板功能。 官方介绍:地址。 1:前置 1.1:打开 右键-》检查,或者F12。 1.2:组成部分 2:控制器常用功能 详细如下图: 接着我们挑选其…...

避坑ffmpeg直接获取视频fps不准确
最近在做视频相关的任务,调试代码发现一个非常坑的点,就是直接用ffmpeg获取fps是有很大误差的,如下: # GPT4o generated import ffmpegprobe ffmpeg.probe(video_path, v"error", select_streams"v:0", sho…...

大数据新视界 -- 大数据大厂之 Hive 函数库:丰富函数助力数据处理(上)(11/ 30)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

深入解析 Django 中数据删除的最佳实践:以动态管理镜像版本为例
文章目录 引言场景与模型设计场景描述 删除操作详解1. 删除单个 Tag2. 批量删除 Tags3. 删除前确认4. 日志记录 高阶优化与问题分析1. 外键约束与误删保护2. 并发删除的冲突处理3. 使用软删除 结合 Django Admin 的实现总结与实践思考 引言 在现代应用开发中,服务和…...

【java】sdkman-java多环境切换工具
#java #env #sdk #lcshand 首先我们来复习一下,可参考我原来的文章: python多个版本的切换可用pyenv nodejs多个版本的切换可用nvm 同样,java多个版本的切换可用sdkman和jenv,我偏重于使用sdkman,因为有时候我也需要…...

11.25c++继承、多态
练习: 编写一个 武器类 class Weapon{int atk; }编写3个武器派生类:短剑,斧头,长剑 class knife{int spd; }class axe{int hp; }class sword{int def; }编写一个英雄类 class Hero{int atk;int def;int spd;int hp; public:所有的…...
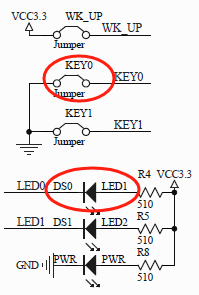
STM32F103外部中断配置
一、外部中断 在上一节我们介绍了STM32f103的嵌套向量中断控制器,其中包括中断的使能、失能、中断优先级分组以及中断优先级配置等内容。 1.1 外部中断/事件控制器 在STM32f103支持的60个可屏蔽中断中,有一些比较特殊的中断: 中断编号13 EXTI…...

阿里电商大整合,驶向价值竞争新航道
阿里一出手就是王炸。11月21日,阿里公布了最新动作:将国内和海外电商业务整合,成立新的电商事业群。这是阿里首次将所有电商业务整合到一起,也对电商行业未来发展有着借鉴意义。阿里为何要这么干?未来又将给行业带来哪…...

等保测评在云计算方面的应用讲解
等保测评(信息安全等级保护测评)在云计算方面的应用主要聚焦于如何满足等级保护相关要求,并确保云计算平台及其上运行的业务系统的安全性。以下是主要内容的讲解: 1. 云计算中的等保测评概述 等保测评是在我国网络安全等级保护制…...
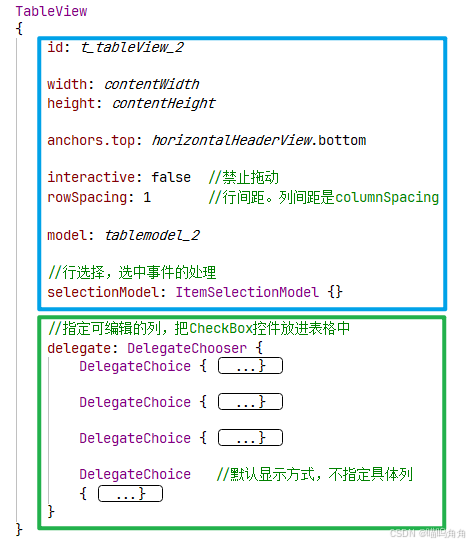
QML TableView 实例演示 + 可能遇到的一些问题(Qt_6_5_3)
一、可能遇到的一些问题 Q1:如何禁用拖动? 在TableView下加一句代码即可: interactive: false 补充:这个属性并不专属于TableView,而是一个通用属性。很多Controls下的控件都可以使用,其主要作用就是控…...
SpringBoot集成RabbitMQ实现流量削峰添谷)
SpringBoot(三十九)SpringBoot集成RabbitMQ实现流量削峰添谷
前边我们有具体的学习过RabbitMQ的安装和基本使用的情况。 但是呢,没有演示具体应用到项目中的实例。 这里使用RabbitMQ来实现流量的削峰添谷。 一:添加pom依赖 <!--rabbitmq-需要的 AMQP 依赖--> <dependency><groupId>org.springfr…...

前端 Vue 3 后端 Node.js 和Express 结合cursor常见提示词结构
cursor 提示词 后端提示词 请为我开发一个基于 Node.js 和Express 框架的 Todo List 后端项目。项目需要实现以下四个 RESTful API 接口: 查询所有待办事项 接口名: GET /api/get-todo功能: 从数据库的’list’集合中查询并返回所有待办事项参数: 无返回: 包含所…...

类和对象(下):点亮编程星河的类与对象进阶之光
再探构造函数 在实现构造函数时,对成员变量进行初始化主要有两种方式: 一种是常见的在函数体内赋值进行初始化;另一种则是通过初始化列表来完成初始化。 之前我们在构造函数中经常采用在函数体内对成员变量赋值的方式来给予它们初始值。例如&…...

42.接雨水
目录 题目过程解法 题目 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 过程 发现有特殊情况就是,最高峰的地方,如果右边小于他,然后再右边也都很小的话,…...
:Kafka消费 offset API,包含指定 Offset 消费以及指定时间消费)
使用Java代码操作Kafka(五):Kafka消费 offset API,包含指定 Offset 消费以及指定时间消费
文章目录 1、指定 Offset 消费2、指定时间消费 1、指定 Offset 消费 auto.offset.reset earliest | latest | none 默认是 latest (1)earliest:自动将偏移量重置为最早的偏移量,–from-beginning (2)lates…...
)
图神经网络终于能“上生产”了?SITS 2026发布首个支持实时增量训练的AI原生图引擎(附Benchmark对比:吞吐提升6.8×,延迟压至12ms)
更多请点击: https://intelliparadigm.com 第一章:AI原生图计算应用:SITS 2026图神经网络工程化方案 SITS 2026 是面向大规模动态图场景的AI原生图计算框架,深度融合GNN训练、图拓扑实时更新与边缘-云协同推理能力。其核心设计摒…...

GitHub中文化插件完整指南:3分钟让GitHub界面变中文的终极方案
GitHub中文化插件完整指南:3分钟让GitHub界面变中文的终极方案 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 还在为GitH…...

3个步骤解决经典游戏无法联网:IPXWrapper终极兼容方案
3个步骤解决经典游戏无法联网:IPXWrapper终极兼容方案 【免费下载链接】ipxwrapper 项目地址: https://gitcode.com/gh_mirrors/ip/ipxwrapper 你是否曾在Windows 10或11系统上试图重温《红色警戒2》、《帝国时代》或《星际争霸》的局域网对战,却…...

iOS 27 开放 AI 生态,长距高清传输新引擎 @ACP#GSV5800 筑牢 iPhone AI 显示后端底座
一、iOS 27 开放 AI:引爆高清长距传输与多接口扩展刚需苹果 iOS 27 系统全面开放第三方 AI 模型自由切换,支持 Claude、Gemini、DeepSeek 等主流大模型深度接入,iPhone/iPad 一跃成为全球最大 AI 交互与视觉输出入口。这一变革直接引爆AI 扩展…...

开源AI教练Sage Coach:基于提示词工程的认知引导系统设计与实践
1. 项目概述:当AI成为你的专属人生教练凌晨三点,创业第三年,账上资金只够撑两个月,合伙人刚刚离开。这不是电影情节,而是许多创业者、职场人乃至普通人可能遭遇的真实困境。在那个时刻,打开终端,…...

Docker Maven Plugin 最佳实践:企业级Docker化部署的完整解决方案 [特殊字符]
Docker Maven Plugin 最佳实践:企业级Docker化部署的完整解决方案 🚀 【免费下载链接】docker-maven-plugin Maven plugin for running and creating Docker images 项目地址: https://gitcode.com/gh_mirrors/doc/docker-maven-plugin 想要快速实…...
实战指南:从原理到选型与应用)
示波器有效位数(ENOB)实战指南:从原理到选型与应用
1. 从“看见”到“看清”:示波器有效位数(ENOB)的实战解读在电子工程师的日常里,示波器就是我们观察电路世界的“眼睛”。它能让我们直观地看到信号在连接器、线缆、PCB走线和元器件之间穿梭的模样。但就像视力有1.0和1.5的区别一…...

crawdad-openclaw:构建高韧性智能爬虫的模块化框架实战
1. 项目概述:一个为数据抓取而生的开源“机械爪”如果你和我一样,在数据工程或网络爬虫领域摸爬滚打过几年,那你一定经历过这样的时刻:面对一个结构复杂、反爬机制严密的网站,你精心编写的爬虫脚本在运行了几个小时后&…...

带式输送机托辊移动集声故障诊断与多普勒校正【附仿真】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)锥麦移动集声采集策略与声学仿真分析: 针…...

从示波器到数据记录仪:基于STM32H7+AD7606+J-Scope的实时波形采集系统搭建全流程
基于STM32H7与AD7606的高性能数据采集系统设计与实战 1. 系统架构设计理念 现代工业监测和实验室数据采集对信号采集系统提出了更高要求——需要同步捕获多通道模拟信号,并实现实时可视化分析。基于STM32H7高性能微控制器与AD7606 ADC模块的组合,配合J-S…...