深入了解决策树---机器学习中的经典算法
引言
决策树(Decision Tree)是一种重要的机器学习模型,以直观的分层决策方式和简单高效的特点成为分类和回归任务中广泛应用的工具。作为解释性和透明性强的算法,决策树不仅适用于小规模数据,也可作为复杂模型的基石(例如随机森林、梯度提升树)。本文深入探讨决策树的数学原理、构建方法及高级应用,并通过Python示例展示如何优化决策树的性能。
决策树的数学原理
决策树是一种递归的分治算法,其核心思想是通过最优分裂策略将数据划分为尽可能“纯”的子集。以下是决策树的构建逻辑背后的数学基础:
1. 信息增益(Information Gain)
信息增益衡量的是在某个特征的基础上划分数据集后,信息的不确定性减少的程度。定义如下:
-
数据集的熵(Entropy):
[
H(D) = - \sum_{i=1}^k P_i \log_2 P_i
]其中 ( P_i ) 是第 ( i ) 类的概率,( k ) 是类别数。
-
特征 ( A ) 对数据集 ( D ) 的信息增益:
[
IG(D, A) = H(D) - \sum_{v \in Values(A)} \frac{|D_v|}{|D|} H(D_v)
]信息增益选择值最大的特征进行分裂。
2. 基尼不纯度(Gini Impurity)
基尼不纯度衡量数据被随机分类的概率。其定义为:
[
Gini(D) = 1 - \sum_{i=1}^k P_i^2
]
特征分裂的目标是最小化加权后的基尼不纯度。
3. 均方误差(MSE, Mean Squared Error)
在回归任务中,常用均方误差作为划分标准。定义为:
[
MSE = \frac{1}{N} \sum_{i=1}^N (y_i - \hat{y})^2
]
4. 停止条件
树的递归分裂直到以下任一条件成立:
- 所有样本属于同一类别;
- 特征不足以进一步分裂;
- 达到预设的最大深度。
决策树的构建与优化
特征选择的重要性
特征选择直接影响决策树的表现。比如,多值特征可能产生偏差,使得决策树倾向选择该特征。为应对这种情况,可以引入以下技术:
- 特征权重调整:通过正则化约束高维特征对分裂的影响。
- 均衡分裂策略:避免决策树倾向于某些特征值较多的特征。
剪枝技术的深入剖析
剪枝是解决过拟合问题的关键措施,分为以下两种方法:
- 预剪枝:通过限制树的最大深度、最小样本分裂数等条件,避免树过度生长。
- 后剪枝:在生成完整的决策树后,通过验证集逐层剪去无贡献的节点,以优化模型的泛化能力。
剪枝的数学依据通常基于代价复杂度剪枝(Cost-Complexity Pruning),其目标是最小化以下损失函数:
[
C_\alpha(T) = R(T) + \alpha \cdot |T|
]
其中,( R(T) ) 表示树的误差,( |T| ) 表示树的叶子节点数量,( \alpha ) 是惩罚参数。
决策树与集成学习的结合
单一决策树在面对高维度数据和复杂任务时可能表现受限,集成学习方法通过结合多棵决策树显著提升模型性能:
-
随机森林(Random Forest):
- 随机森林是多个决策树的集成,采用袋装法(Bagging)构建。
- 每棵树在随机子集上训练,预测时取多数投票。
-
梯度提升树(Gradient Boosting Decision Tree,GBDT):
- GBDT通过迭代优化多个弱决策树的误差进行提升。
- 使用梯度信息调整每棵树的贡献,适用于复杂非线性关系。
-
XGBoost 和 LightGBM:
- 这些方法是GBDT的高效变种,提供了更强大的并行化能力和对大规模数据的支持。
高级Python实现与案例
以下代码展示了如何使用超参数调整和剪枝技术构建优化的决策树。
数据准备与分割
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import pandas as pd# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
决策树模型训练与评估
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score# 初始化模型
clf = DecisionTreeClassifier(random_state=42, max_depth=5, min_samples_split=10)
clf.fit(X_train, y_train)# 预测并评估
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.2f}")
可视化
from sklearn.tree import plot_tree
import matplotlib.pyplot as pltplt.figure(figsize=(12, 8))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.title("优化后的决策树")
plt.show()
使用网格搜索优化超参数
from sklearn.model_selection import GridSearchCVparam_grid = {'max_depth': [3, 5, 7, None],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4]
}grid_search = GridSearchCV(DecisionTreeClassifier(random_state=42), param_grid, cv=5)
grid_search.fit(X_train, y_train)best_clf = grid_search.best_estimator_
print("最佳参数:", grid_search.best_params_)
决策树的实际应用
- 医疗领域:通过决策树预测疾病风险,提高诊断效率。
- 金融行业:在信用评分和欺诈检测中的应用广泛。
- 电子商务:优化推荐系统和客户分类。
- 生产管理:通过决策树进行质量控制和生产优化。
引言
在机器学习领域,决策树(Decision Tree)是一种经典且基础的算法,以其直观性、易解释性和广泛的适用性,成为分类与回归任务中的常用工具。通过将数据分裂成多个决策路径,决策树以树状结构为核心,通过一系列判断条件生成最终的预测结果。本文将深入探讨决策树的原理、数学基础、构建方法、优缺点以及实际应用场景,并通过代码实例演示如何在实践中构建高效的决策树模型。
决策树的基本概念
决策树是一种监督学习模型,其核心思想是利用特征分裂来最大化目标变量的可分性。整个过程构建了一棵树结构,其中:
- 根节点:表示整体数据集。
- 内部节点:表示基于某个特征的分裂点。
- 叶子节点:表示最终的分类标签或回归预测值。
决策树的构建过程
- 特征选择:选择最优的特征进行数据分裂。
- 数据划分:按照选定特征的不同取值将数据划分成多个子集。
- 递归构建:对每个子集重复以上步骤,直到满足停止条件。
- 剪枝:通过预剪枝或后剪枝避免过拟合。
决策树的数学基础
1. 信息增益
信息增益衡量特征对分类结果的不确定性减少程度。公式如下:
[
IG(D, A) = H(D) - \sum_{v \in Values(A)} \frac{|D_v|}{|D|} H(D_v)
]
其中,( H(D) ) 是数据集的熵,表示信息的不确定性。
2. 基尼不纯度
用于衡量节点纯度的指标,公式为:
[
Gini(D) = 1 - \sum_{i=1}^k P_i^2
]
值越小,节点越纯。
3. 均方误差
在回归任务中,均方误差(MSE)用于选择分裂特征,其定义为:
[
MSE = \frac{1}{N} \sum_{i=1}^N (y_i - \hat{y})^2
]
4. 停止条件
- 达到最大深度。
- 数据量不足以继续分裂。
- 节点内数据完全一致。
决策树的优缺点
优点
- 可解释性强:易于直观展示决策过程。
- 无需特征工程:对数值型和类别型数据均可直接处理。
- 适应非线性关系:可处理复杂的非线性数据。
缺点
- 易过拟合:在噪声较大的数据集上容易生成过于复杂的模型。
- 不稳定性:对数据的微小变化敏感。
- 偏向多值特征:可能更倾向选择取值较多的特征。
决策树的构建与实现
以下以Python实现一个简单的决策树分类模型,使用鸢尾花数据集(Iris Dataset)作为示例。
1. 数据加载与准备
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import pandas as pd# 加载数据
iris = load_iris()
X, y = iris.data, iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2. 构建决策树模型
from sklearn.tree import DecisionTreeClassifier# 初始化模型
clf = DecisionTreeClassifier(max_depth=3, random_state=42)
clf.fit(X_train, y_train)
3. 模型评估
from sklearn.metrics import accuracy_score# 预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.2f}")
4. 决策树可视化
from sklearn.tree import plot_tree
import matplotlib.pyplot as pltplt.figure(figsize=(12, 8))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.title("决策树可视化")
plt.show()
5. 优化与剪枝
# 创建剪枝后的决策树
clf_pruned = DecisionTreeClassifier(max_depth=2, min_samples_split=10, random_state=42)
clf_pruned.fit(X_train, y_train)# 可视化剪枝后的决策树
plt.figure(figsize=(12, 8))
plot_tree(clf_pruned, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.title("剪枝后的决策树")
plt.show()
决策树的高级应用
1. 随机森林与集成学习
决策树在单独使用时可能存在一定局限性,随机森林和梯度提升树通过集成多个决策树模型,显著提升了预测性能。
2. 信用风险评估
银行和金融机构常用决策树评估客户的信用风险,通过分析财务数据和信用记录,判断是否批准贷款。
3. 疾病诊断
在医疗领域,决策树能依据病人症状和检查结果预测疾病风险,为医生提供决策支持。
4. 推荐系统
通过分析用户的行为数据,决策树可实现精准的商品推荐,提升用户体验。
决策树的未来发展
随着机器学习的不断进步,决策树在以下方面有望进一步优化:
- 自动化参数调整:结合深度学习和强化学习,提高模型优化的自动化水平。
- 大规模数据处理:通过改进并行化算法,使决策树在大数据环境下高效运行。
- 结合深度模型:探索决策树与神经网络的混合模型,实现更强大的学习能力。
总结
作为机器学习的经典算法,决策树以其直观性和易用性在实际应用中占据重要地位。从分类到回归、从单一模型到集成学习,决策树展现了广阔的适用场景。通过结合剪枝、超参数优化和集成学习,决策树的性能得到了极大提升。未来,随着数据规模和计算能力的增长,决策树仍将是机器学习领域不可或缺的核心技术。
总结与展望
决策树是一种兼具可解释性和灵活性的机器学习模型,虽然在面对高维度和复杂数据时表现有限,但其作为集成学习的基础仍然是不可或缺的工具。未来,结合深度学习和自动化超参数调整的技术,将为决策树的应用提供更多可能性。
相关文章:

深入了解决策树---机器学习中的经典算法
引言 决策树(Decision Tree)是一种重要的机器学习模型,以直观的分层决策方式和简单高效的特点成为分类和回归任务中广泛应用的工具。作为解释性和透明性强的算法,决策树不仅适用于小规模数据,也可作为复杂模型的基石&…...

Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
大家好,我是锋哥。今天分享关于【Elasticsearch对于大数据量(上亿量级)的聚合如何实现?】面试题。希望对大家有帮助; Elasticsearch对于大数据量(上亿量级)的聚合如何实现? 1000道 …...

深度学习模型:循环神经网络(RNN)
一、引言 在深度学习的浩瀚海洋里,循环神经网络(RNN)宛如一颗独特的明珠,专门用于剖析序列数据,如文本、语音、时间序列等。无论是预测股票走势,还是理解自然语言,RNN 都发挥着举足轻重的作用。…...

前端---HTML(一)
HTML_网络的三大基石和html普通文本标签 1.我们要访问网络,需不需要知道,网络上的东西在哪? 为什么我们写,www.baidu.com就能找到百度了呢? 我一拼ping www.baidu.com 就拼到了ip地址: [119.75.218.70]…...

SQL 复杂查询
目录 复杂查询 一、目的和要求 二、实验内容 (1)查询出所有水果产品的类别及详情。 查询出编号为“00000001”的消费者用户的姓名及其所下订单。(分别采用子查询和连接方式实现) 查询出每个订单的消费者姓名及联系方式。 在…...

银河麒麟桌面系统——桌面鼠标变成x,窗口无关闭按钮的解决办法
银河麒麟桌面系统——桌面鼠标变成x,窗口无关闭按钮的解决办法 1、支持环境2、详细操作说明步骤1:用root账户登录电脑步骤2:导航到kylin-wm-chooser目录步骤3:编辑default.conf文件步骤4:重启电脑 3、结语 Ὁ…...

抓包之使用chrome的network面板
写在前面 本文看下工作中非常非常常用的chrome的network面板功能。 官方介绍:地址。 1:前置 1.1:打开 右键-》检查,或者F12。 1.2:组成部分 2:控制器常用功能 详细如下图: 接着我们挑选其…...

避坑ffmpeg直接获取视频fps不准确
最近在做视频相关的任务,调试代码发现一个非常坑的点,就是直接用ffmpeg获取fps是有很大误差的,如下: # GPT4o generated import ffmpegprobe ffmpeg.probe(video_path, v"error", select_streams"v:0", sho…...

大数据新视界 -- 大数据大厂之 Hive 函数库:丰富函数助力数据处理(上)(11/ 30)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

深入解析 Django 中数据删除的最佳实践:以动态管理镜像版本为例
文章目录 引言场景与模型设计场景描述 删除操作详解1. 删除单个 Tag2. 批量删除 Tags3. 删除前确认4. 日志记录 高阶优化与问题分析1. 外键约束与误删保护2. 并发删除的冲突处理3. 使用软删除 结合 Django Admin 的实现总结与实践思考 引言 在现代应用开发中,服务和…...

【java】sdkman-java多环境切换工具
#java #env #sdk #lcshand 首先我们来复习一下,可参考我原来的文章: python多个版本的切换可用pyenv nodejs多个版本的切换可用nvm 同样,java多个版本的切换可用sdkman和jenv,我偏重于使用sdkman,因为有时候我也需要…...

11.25c++继承、多态
练习: 编写一个 武器类 class Weapon{int atk; }编写3个武器派生类:短剑,斧头,长剑 class knife{int spd; }class axe{int hp; }class sword{int def; }编写一个英雄类 class Hero{int atk;int def;int spd;int hp; public:所有的…...
STM32F103外部中断配置
一、外部中断 在上一节我们介绍了STM32f103的嵌套向量中断控制器,其中包括中断的使能、失能、中断优先级分组以及中断优先级配置等内容。 1.1 外部中断/事件控制器 在STM32f103支持的60个可屏蔽中断中,有一些比较特殊的中断: 中断编号13 EXTI…...

阿里电商大整合,驶向价值竞争新航道
阿里一出手就是王炸。11月21日,阿里公布了最新动作:将国内和海外电商业务整合,成立新的电商事业群。这是阿里首次将所有电商业务整合到一起,也对电商行业未来发展有着借鉴意义。阿里为何要这么干?未来又将给行业带来哪…...

等保测评在云计算方面的应用讲解
等保测评(信息安全等级保护测评)在云计算方面的应用主要聚焦于如何满足等级保护相关要求,并确保云计算平台及其上运行的业务系统的安全性。以下是主要内容的讲解: 1. 云计算中的等保测评概述 等保测评是在我国网络安全等级保护制…...
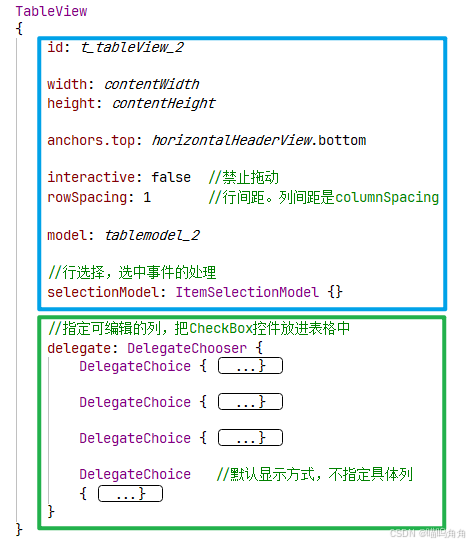
QML TableView 实例演示 + 可能遇到的一些问题(Qt_6_5_3)
一、可能遇到的一些问题 Q1:如何禁用拖动? 在TableView下加一句代码即可: interactive: false 补充:这个属性并不专属于TableView,而是一个通用属性。很多Controls下的控件都可以使用,其主要作用就是控…...
SpringBoot集成RabbitMQ实现流量削峰添谷)
SpringBoot(三十九)SpringBoot集成RabbitMQ实现流量削峰添谷
前边我们有具体的学习过RabbitMQ的安装和基本使用的情况。 但是呢,没有演示具体应用到项目中的实例。 这里使用RabbitMQ来实现流量的削峰添谷。 一:添加pom依赖 <!--rabbitmq-需要的 AMQP 依赖--> <dependency><groupId>org.springfr…...

前端 Vue 3 后端 Node.js 和Express 结合cursor常见提示词结构
cursor 提示词 后端提示词 请为我开发一个基于 Node.js 和Express 框架的 Todo List 后端项目。项目需要实现以下四个 RESTful API 接口: 查询所有待办事项 接口名: GET /api/get-todo功能: 从数据库的’list’集合中查询并返回所有待办事项参数: 无返回: 包含所…...

类和对象(下):点亮编程星河的类与对象进阶之光
再探构造函数 在实现构造函数时,对成员变量进行初始化主要有两种方式: 一种是常见的在函数体内赋值进行初始化;另一种则是通过初始化列表来完成初始化。 之前我们在构造函数中经常采用在函数体内对成员变量赋值的方式来给予它们初始值。例如&…...

42.接雨水
目录 题目过程解法 题目 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 过程 发现有特殊情况就是,最高峰的地方,如果右边小于他,然后再右边也都很小的话,…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...