OpenAI 实战进阶教程 - 第七节: 与数据库集成 - 生成 SQL 查询与优化
内容目标
- 学习如何使用 OpenAI 辅助生成和优化多表 SQL 查询
- 了解如何获取数据库结构信息并与 OpenAI 结合使用
实操步骤
1. 创建 SQLite 数据库示例
创建数据库及表结构:
import sqlite3# 连接 SQLite 数据库(如果不存在则创建)
conn = sqlite3.connect("company_data.db")
cursor = conn.cursor()# 创建 employees 表
cursor.execute('''
CREATE TABLE IF NOT EXISTS employees (id INTEGER PRIMARY KEY,name TEXT,department_id INTEGER,salary REAL,hire_date TEXT
)
''')# 创建 departments 表
cursor.execute('''
CREATE TABLE IF NOT EXISTS departments (id INTEGER PRIMARY KEY,name TEXT,budget REAL
)
''')# 插入示例数据
cursor.executemany('''
INSERT OR IGNORE INTO employees (id, name, department_id, salary, hire_date)
VALUES (?, ?, ?, ?, ?)
''', [(1, "Alice", 1, 8500, "2022-03-15"),(2, "Bob", 2, 6200, "2023-05-01"),(3, "Charlie", 1, 9300, "2021-11-12"),
])cursor.executemany('''
INSERT OR IGNORE INTO departments (id, name, budget)
VALUES (?, ?, ?)
''', [(1, "Engineering", 500000),(2, "HR", 150000)
])conn.commit()
conn.close()
print("Database setup complete.")
2. 自动读取数据库结构信息
使用 PRAGMA table_info() 查询元信息,以便将表结构传递给 OpenAI:
def get_table_info(db_name):conn = sqlite3.connect(db_name)cursor = conn.cursor()# 获取所有表名cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")tables = cursor.fetchall()table_info = {}for table_name in tables:table_name = table_name[0]cursor.execute(f"PRAGMA table_info({table_name});")columns = cursor.fetchall()table_info[table_name] = [column[1] for column in columns]conn.close()return table_infodb_name = "company_data.db"
table_structure = get_table_info(db_name)
print("Database Structure:", table_structure)
3. 生成两表关联查询
将数据库结构作为上下文传入 OpenAI,请求生成 SQL 查询:
import openai# 设置 API 密钥
openai.api_key = "your-api-key"# 构建提示信息
table_info_prompt = f"""
The database has the following structure:
Table `employees`: id, name, department_id, salary, hire_date
Table `departments`: id, name, budget
Write an SQL query to find the names of employees in the 'Engineering' department whose salary exceeds 8000.
The query should join the employees and departments tables.
"""# 调用 OpenAI 生成 SQL 查询
response = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=[{"role": "user", "content": table_info_prompt}],max_tokens=150
)sql_query = response['choices'][0]['message']['content']
print("Generated SQL Query:")
print(sql_query)
4. 示例生成结果
SELECT e.name
FROM employees e
JOIN departments d ON e.department_id = d.id
WHERE d.name = 'Engineering' AND e.salary > 8000;
小结
- 元信息读取:通过
PRAGMA table_info()获取数据库表结构 - 查询生成:将表名、字段及业务规则传递给 OpenAI,可以生成跨表关联查询
- 应用场景:适用于复杂业务查询,如员工信息与部门预算的联动分析
练习题
-
实践查询生成:
修改查询条件,让 OpenAI 生成一个查询语句,找出预算大于 300,000 且部门中员工平均工资超过 7000 的部门名称。 -
优化查询:
使用 OpenAI 请求优化生成的 SQL 查询,确保执行效率更高。
相关文章:

OpenAI 实战进阶教程 - 第七节: 与数据库集成 - 生成 SQL 查询与优化
内容目标 学习如何使用 OpenAI 辅助生成和优化多表 SQL 查询了解如何获取数据库结构信息并与 OpenAI 结合使用 实操步骤 1. 创建 SQLite 数据库示例 创建数据库及表结构: import sqlite3# 连接 SQLite 数据库(如果不存在则创建) conn sq…...

Apache Iceberg数据湖技术在海量实时数据处理、实时特征工程和模型训练的应用技术方案和具体实施步骤及代码
Apache Iceberg在处理海量实时数据、支持实时特征工程和模型训练方面的强大能力。Iceberg支持实时特征工程和模型训练,特别适用于需要处理海量实时数据的机器学习工作流。 Iceberg作为数据湖,以支持其机器学习平台中的特征存储。Iceberg的分层结构、快照…...
QT交叉编译环境搭建(Cmake和qmake)
介绍一共有两种方法(基于qmake和cmake): 1.直接调用虚拟机中的交叉编译工具编译 2.在QT中新建编译套件kits camke和qmake的区别:CMake 和 qmake 都是自动化构建工具,用于简化构建过程,管理编译设置&…...
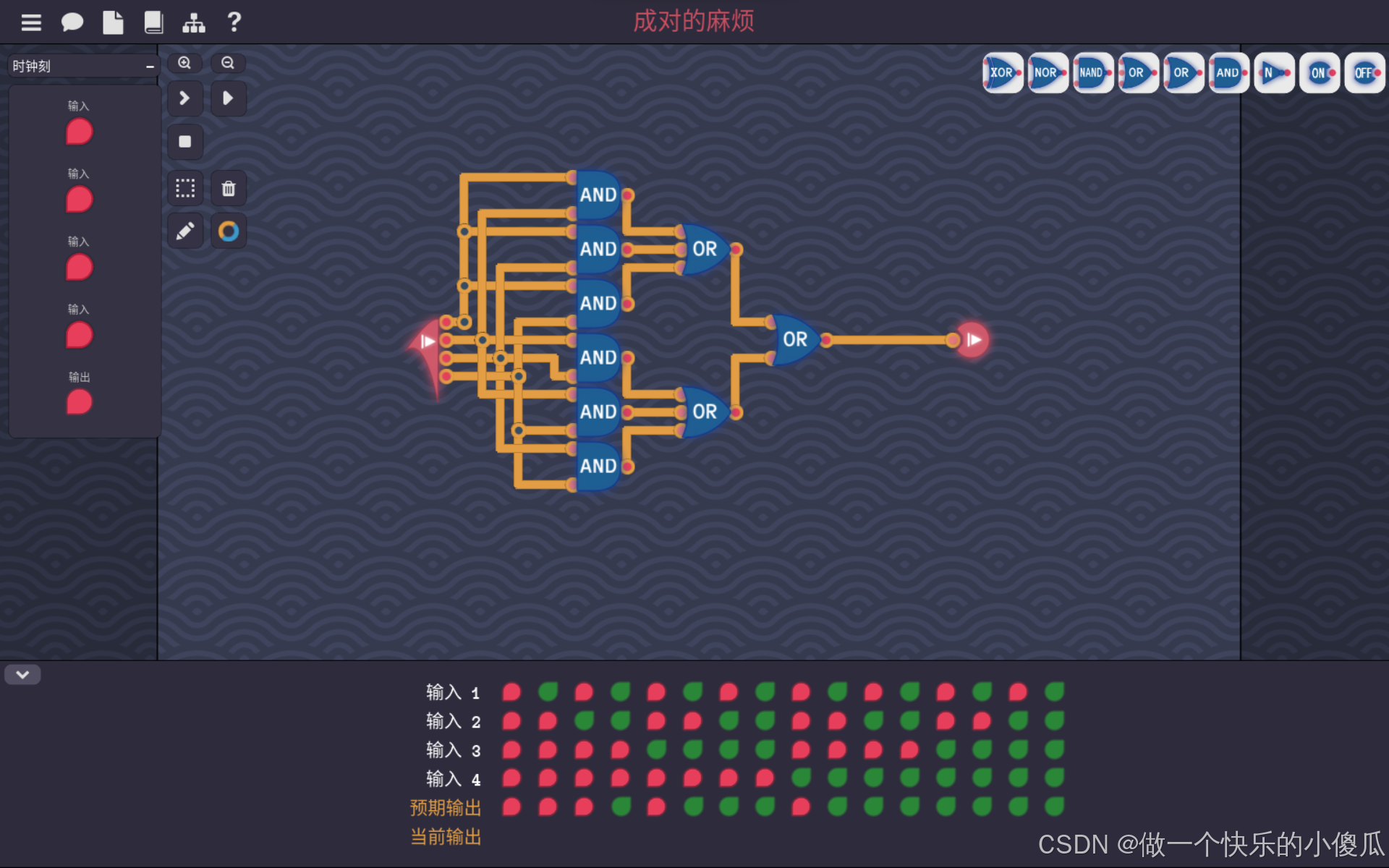
Turing Complete-成对的麻烦
这一关是4个输入,当输入中1的个数大于等于2时,输出1。 那么首先用个与门来检测4个输入中,1的个数是否大于等于2,当大于等于2时,至少会有一个与门输出1,所以再用两级或门讲6个与门的输出取或,得…...

寒假刷题Day20
一、80. 删除有序数组中的重复项 II class Solution { public:int removeDuplicates(vector<int>& nums) {int n nums.size();int stackSize 2;for(int i 2; i < n; i){if(nums[i] ! nums[stackSize - 2]){nums[stackSize] nums[i];}}return min(stackSize, …...
deepseek 本地化部署和小模型微调
安装ollama 因为本人gpu卡的机器系统是centos 7, 直接使用ollama会报 所以ollama使用镜像方式进行部署, 拉取镜像ollama/ollama 启动命令 docker run -d --privileged -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama 查看ollama 是否启动…...

【Java异步编程】基于任务类型创建不同的线程池
文章目录 一. 按照任务类型对线程池进行分类1. IO密集型任务的线程数2. CPU密集型任务的线程数3. 混合型任务的线程数 二. 线程数越多越好吗三. Redis 单线程的高效性 使用线程池的好处主要有以下三点: 降低资源消耗:线程是稀缺资源,如果无限…...

makailio-alias_db模块详解
ALIAS_DB 模块 作者 Daniel-Constantin Mierla micondagmail.com Elena-Ramona Modroiu ramonaasipto.com 编辑 Daniel-Constantin Mierla micondagmail.com 版权 © 2005 Voice Sistem SRL © 2008 asipto.com 目录 管理员指南 概述依赖 2.1 Kamailio 模块 2.2 外…...
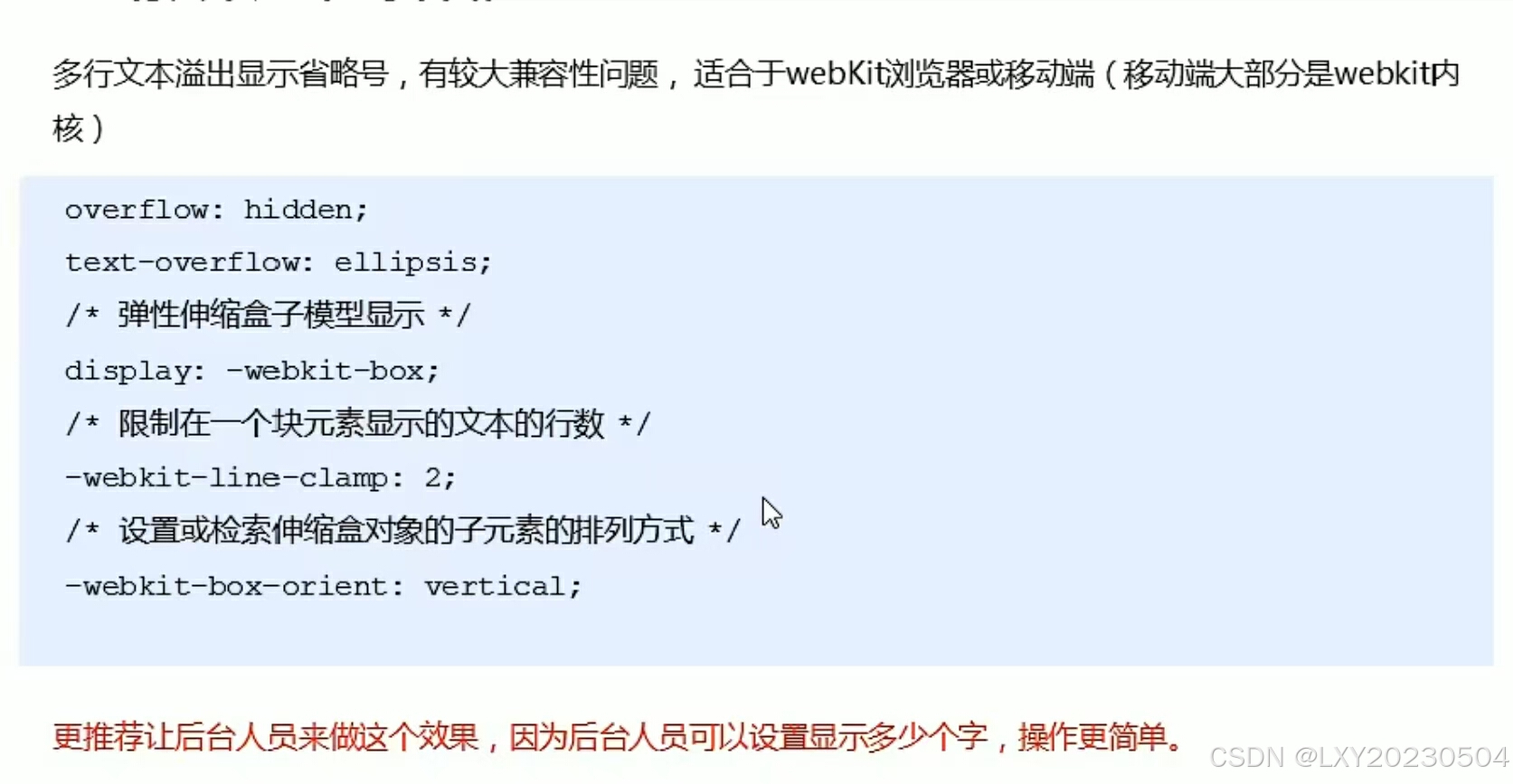
文字显示省略号
多行文本溢出显示省略号...

[LeetCode] 字符串完整版 — 双指针法 | KMP
字符串 基础知识双指针法344# 反转字符串541# 反转字符串II54K 替换数字151# 反转字符串中的单词55K 右旋字符串 KMP 字符串匹配算法28# 找出字符串中第一个匹配项的下标#459 重复的子字符串 基础知识 字符串的结尾:空终止字符00 char* name "hello"; …...

从零开始部署Dify:后端与前端服务完整指南
从零开始部署Dify:后端与前端服务完整指南 一、环境准备1. 系统要求2. 项目结构 二、后端服务部署1. 中间件启动(Docker Compose)2. 后端环境配置3. 依赖安装与数据库迁移4. 服务启动 三、前端界面搭建1. 环境配置2. 服务启动 四、常见问题排…...

springboot中路径默认配置与重定向/转发所存在的域对象
Spring Boot 是一种简化 Spring 应用开发的框架,它提供了多种默认配置和方便的开发特性。在 Web 开发中,路径配置和请求的重定向/转发是常见操作。本文将详细介绍 Spring Boot 中的路径默认配置,并解释重定向和转发过程中存在的域对象。 一、…...

二叉树——429,515,116
今天继续做关于二叉树层序遍历的相关题目,一共有三道题,思路都借鉴于最基础的二叉树的层序遍历。 LeetCode429.N叉树的层序遍历 这道题不再是二叉树了,变成了N叉树,也就是该树每一个节点的子节点数量不确定,可能为2&a…...

Leetcode 3444. Minimum Increments for Target Multiples in an Array
Leetcode 3444. Minimum Increments for Target Multiples in an Array 1. 解题思路2. 代码实现 题目链接:3444. Minimum Increments for Target Multiples in an Array 1. 解题思路 这一题我的思路上就是一个深度优先遍历,考察target数组当中的每一个…...
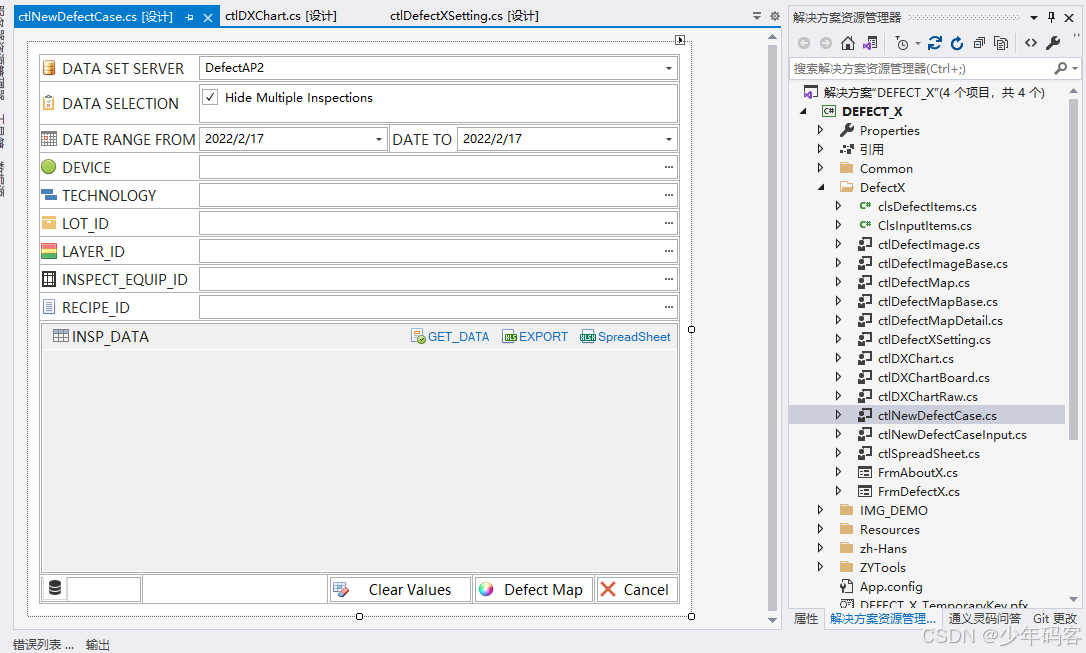
分享半导体Fab 缺陷查看系统,平替klarity defect系统
分享半导体Fab 缺陷查看系统,平替klarity defect系统;开发了半年有余。 查看Defect Map,Defect image,分析Defect size,defect count trend. 不用再采用klarity defect系统(license 太贵) 也可以…...
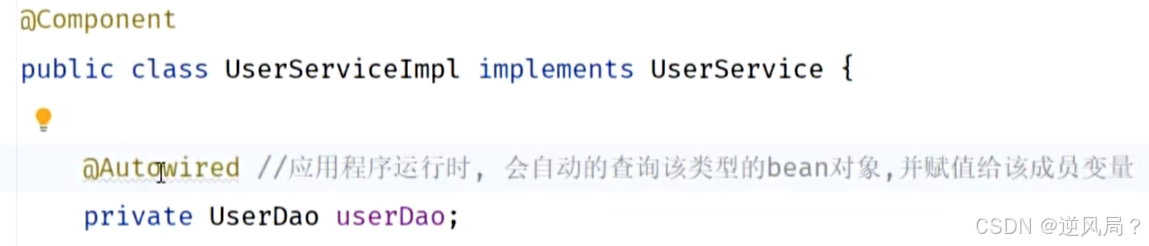
Java基础——分层解耦——IOC和DI入门
目录 三层架构 Controller Service Dao 编辑 调用过程 面向接口编程 分层解耦 耦合 内聚 软件设计原则 控制反转 依赖注入 Bean对象 如何将类产生的对象交给IOC容器管理? 容器怎样才能提供依赖的bean对象呢? 三层架构 Controller 控制…...
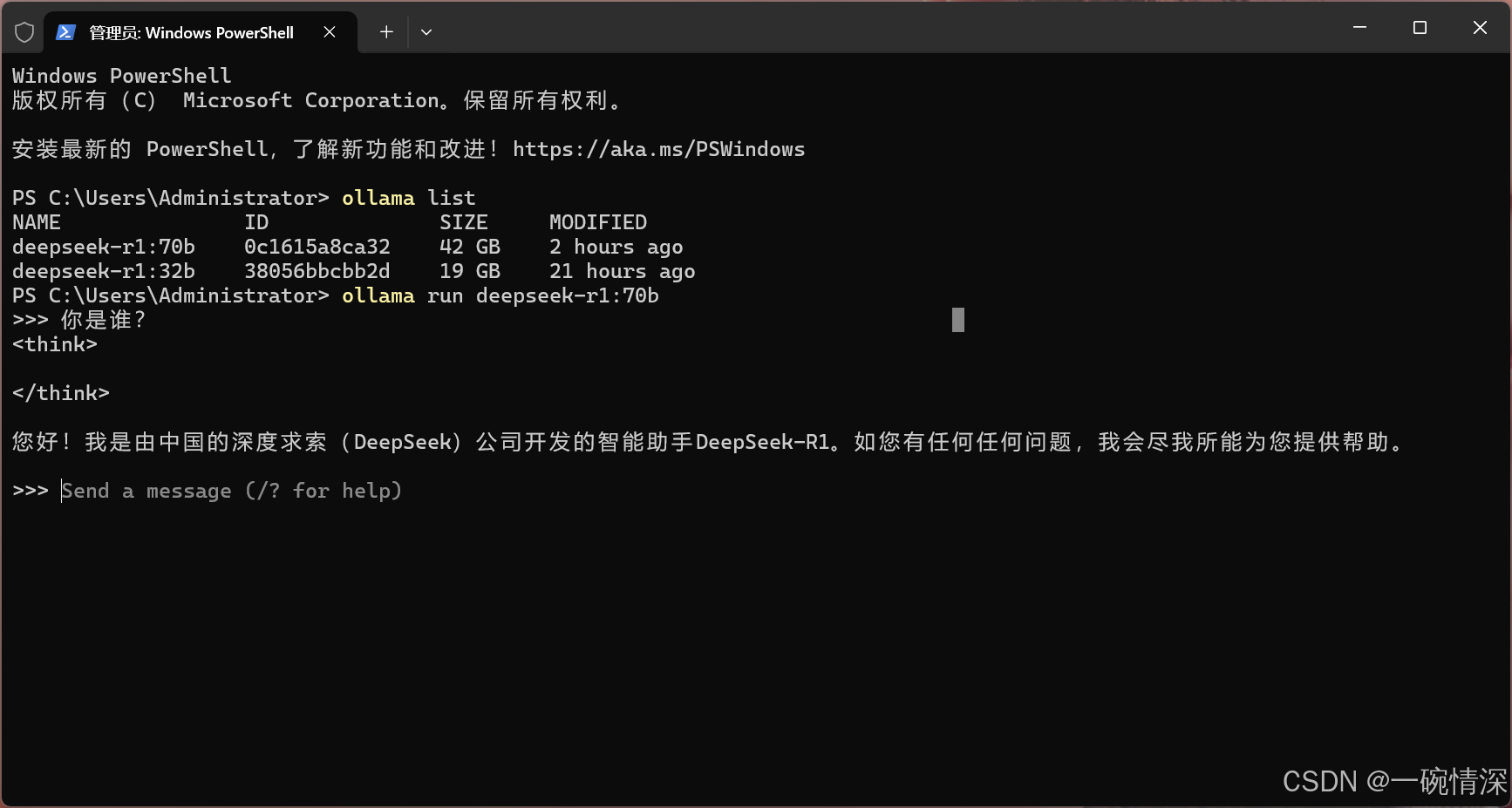
DeepSeek-R1 本地部署教程(超简版)
文章目录 一、DeepSeek相关网站二、DeepSeek-R1硬件要求三、本地部署DeepSeek-R11. 安装Ollama1.1 Windows1.2 Linux1.3 macOS 2. 下载和运行DeepSeek模型3. 列出本地已下载的模型 四、Ollama命令大全五、常见问题解决附:DeepSeek模型资源 一、DeepSeek相关网站 官…...
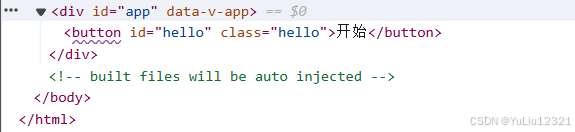
Vue3学习笔记-模板语法和属性绑定-2
一、文本插值 使用{ {val}}放入变量,在JS代码中可以设置变量的值 <template><p>{{msg}}</p> </template> <script> export default {data(){return {msg: 文本插值}} } </script> 文本值可以是字符串,可以是布尔…...

csapp笔记3.6节——控制(1)
本节解决了x86-64如何实现条件语句、循环语句和分支语句的问题 条件码 除了整数寄存器外,cpu还维护着一组单个位的条件码寄存器,用来描述最近的算数和逻辑运算的某些属性。可检测这些寄存器来执行条件分支指令。 CF(Carry Flag)…...

PYH与MAC的桥梁MII/MIIM
在学习车载互联网时,看到了一句话,Processor通过DMA直接存储访问与MAC之间进行数据的交互,MAC通过MII介质无关接口与PHY之间进行数据的交互。常见的以太网硬件结构是,将MAC集成进Processor芯片,将PHY留在Processor片外…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...

微服务通信安全:深入解析mTLS的原理与实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、引言:微服务时代的通信安全挑战 随着云原生和微服务架构的普及,服务间的通信安全成为系统设计的核心议题。传统的单体架构中&…...