牛客网Python篇数据分析习题(六)
1.某公司计划举办一场运动会,现有运动会项目数据集items.csv。 包含以下字段:
item_id:项目编号;
item_name:项目名称;
location:比赛场地。
有员工报名情况数据集signup.csv。包含以下字段:
employee_id:员工编号;
name:员工姓名;
sex:性别;
department:所属部门;
item_id:报名项目id
请你统计职能部门(functional)中报名标枪(javenlin)的所有员工的员工编号(employee_id)、姓名(name)及性别(sex)。
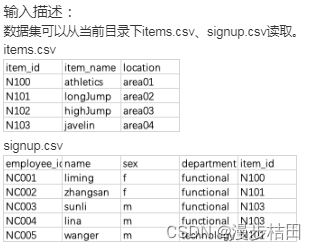
import pandas as pditems = pd.read_csv("items.csv", sep=",")
signup = pd.read_csv("signup.csv", sep=",")
pd.set_option("display.unicode.east_asian_width", True)
data = pd.merge(items, signup, how="inner", on="item_id")print(data[(data.department == "functional") & (data.item_name == "javelin")][["employee_id", "name", "sex"]].reset_index(drop=True))2.某公司计划举办一场运动会,现有运动会项目数据集items.csv。 包含以下字段:
item_id:项目编号;
item_name:项目名称;
location:比赛场地。
有员工报名情况数据集signup.csv。包含以下字段:
employee_id:员工编号;
name:员工姓名;
sex:性别;
department:所属部门;
item_id:报名项目id
请你输出报名的各个项目情况(不包含没人报名的项目)对应的透视表。
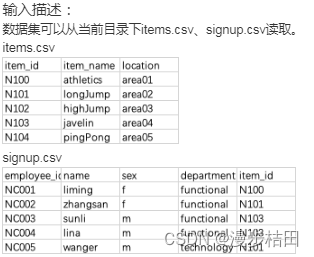
import pandas as pdsignup = pd.read_csv("signup.csv")
items = pd.read_csv("items.csv")
x = pd.merge(signup, items, on="item_id")
y = x.pivot_table(index=["sex", "department"],columns="item_name",aggfunc={"employee_id": "size"},fill_value=0,)print(y)3.现有一个Nowcoder1.csv文件,记录了牛客网的部分用户的个人信息,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Name:用户名
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
另外一个Nowcoder2.csv文件记录了用户的活跃情况,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
两张表分开查看对于运营同学太困难了,请帮助他通过用户ID将两张表合并输出。
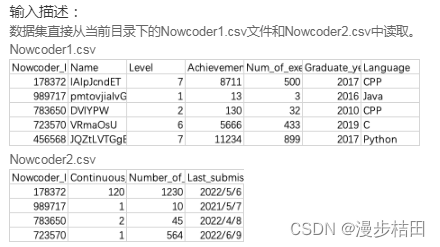
import pandas as pdpd.set_option("display.width", 300)
pd.set_option("display.max_rows", None)
pd.set_option("display.max_columns", None)
nd1 = pd.read_csv("Nowcoder1.csv")
nd2 = pd.read_csv("Nowcoder2.csv")
df = pd.merge(nd1, nd2, on="Nowcoder_ID")print(df)4.现有一个Nowcoder1.csv文件,记录了牛客网的部分用户的个人信息,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Name:用户名
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
另外一个Nowcoder2.csv文件记录了用户的活跃情况,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
如果你想要的信息各自在两个csv文件中,你该怎么输出?同时输出用户的名字、刷题量和代码提交次数。
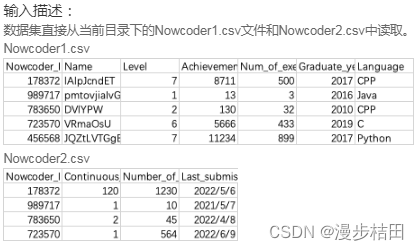
import pandas as pdpd.set_option("display.width", 300)
pd.set_option("display.max_rows", None)
pd.set_option("display.max_columns", None)
nd1 = pd.read_csv("Nowcoder1.csv")
nd2 = pd.read_csv("Nowcoder2.csv")
df = pd.merge(nd1, nd2, on="Nowcoder_ID")print(df[["Name", "Num_of_exercise", "Number_of_submissions"]])5.现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
请你统计消费金额最多的前3名用户。
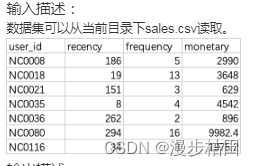
import pandas as pdsales = pd.read_csv("sales.csv")print(sales.sort_values(by="monetary", ascending=False).reset_index(drop=True).head(3))6.现有一个Nowcoder.csv文件,记录了牛客网的部分用户的个人信息,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Name:用户名
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
牛牛在查看这些数据的时候,等级都是混乱的,他想按照1-7级的递增序查看这些用户数据,你能帮他输出一下吗?
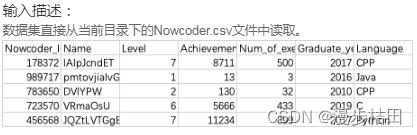
import pandas as pdpd.set_option("display.width", 300)
pd.set_option("display.max_rows", None)
pd.set_option("display.max_columns", None)nd = pd.read_csv("Nowcoder.csv")print(nd.sort_values(by="Level"))7.现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
请你分别对每个用户的每个消费特征进行评分。
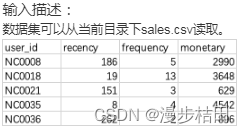
import pandas as pddata = pd.read_csv("sales.csv")data["R_Quartile"] = pd.qcut(data["recency"], [0, 0.25, 0.5, 0.75, 1], ["4", "3", "2", "1"]
).astype("int")
data["F_Quartile"] = pd.qcut(data["frequency"], [0, 0.25, 0.5, 0.75, 1], ["1", "2", "3", "4"]
).astype("int")
data["M_Quartile"] = pd.qcut(data["monetary"], [0, 0.25, 0.5, 0.75, 1], ["1", "2", "3", "4"]
).astype("int")print(data.head())8.现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
请你统计最有价值的用户中消费金额最多的前5名用户。
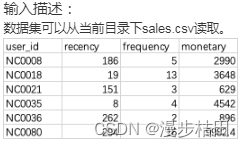
import pandas as pddata = pd.read_csv("sales.csv")R = pd.qcut(data["recency"], [0, 0.25, 0.5, 0.75, 1.0], ["4", "3", "2", "1"]).astype(str)
F = pd.qcut(data["frequency"], [0, 0.25, 0.5, 0.75, 1.0], ["1", "2", "3", "4"]).astype(str)
M = pd.qcut(data["monetary"], [0, 0.25, 0.5, 0.75, 1.0], ["1", "2", "3", "4"]).astype(str)
data["RFMClass"] = R + F + Mprint(data.head())
print(data[data["RFMClass"] == "444"].sort_values("monetary", ascending=False))相关文章:
牛客网Python篇数据分析习题(六)
1.某公司计划举办一场运动会,现有运动会项目数据集items.csv。 包含以下字段: item_id:项目编号; item_name:项目名称; location:比赛场地。 有员工报名情况数据集signup.csv。包含以下字段: employee_id&a…...

Ansible的安装及部署
目录 一、Ansible对于企业运维的重大意义 二、Ansible的安装 三、构建Ansible清单 1.直接书写受管主机名或ip,每行一个 2.设定受管主机的组[组名称] 四、Ansible配置文件参数详解 1、配置文件的分类与优先级 2.配置新用户的Ansible配置 3.生成免密认证 本章…...
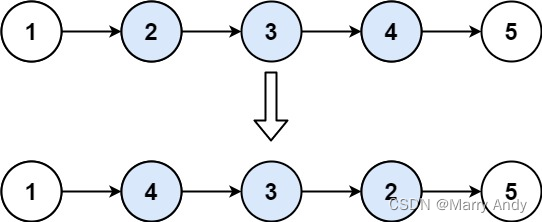
链表题目总结 -- 递归
目录一. 递归反转整个链表1. 思路简述2. 代码3. 总结二. 反转链表前 N 个节点1. 思路简述2. 代码3. 总结三、反转链表的一部分1. 思路简述2. 代码3.总结四、从节点M开始反转后面的链表1. 思路简述2. 代码3.总结一. 递归反转整个链表 题目链接:https://leetcode.cn/…...
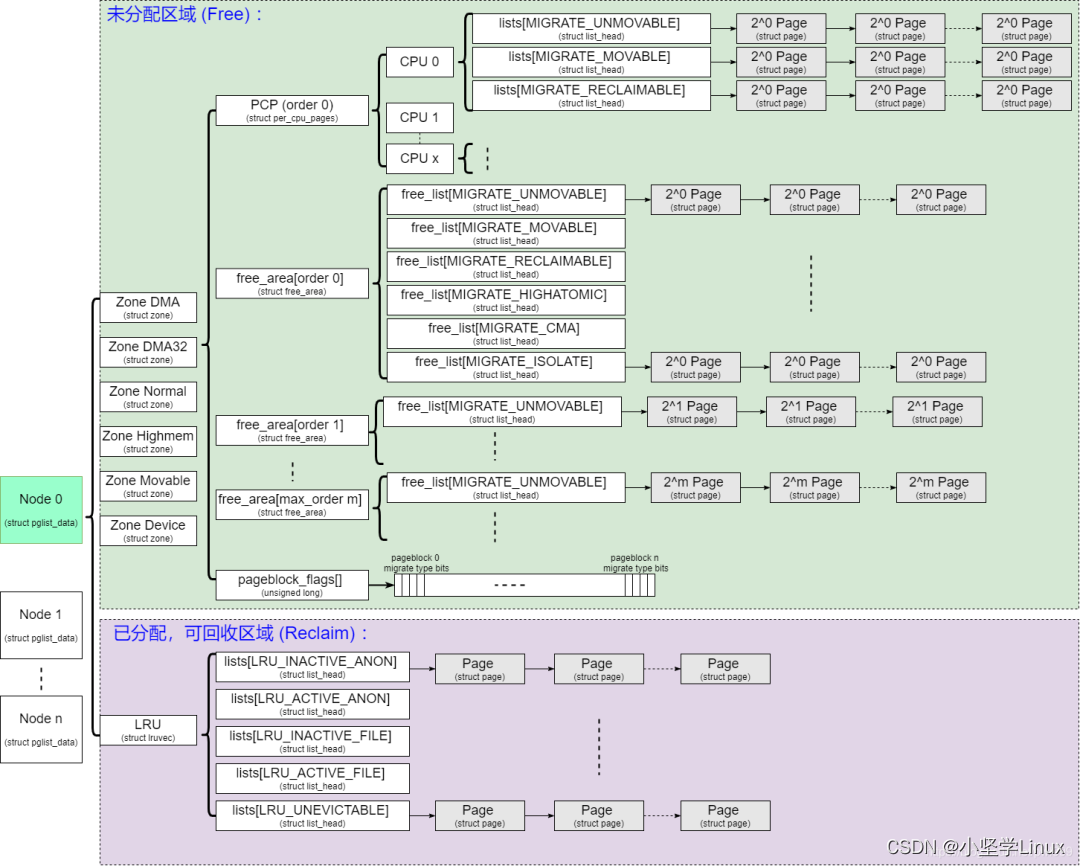
重写-linux内存管理-伙伴分配器(一)
文章目录一、伙伴系统的结构二、初始化三、分配内存3.1 prepare_alloc_pages3.2 get_page_from_freelist3.2.1 zone_watermark_fast3.2.2 zone_watermark_ok3.2.3 rmqueue3.2.3.1 rmqueue_pcplist3.2.3.2 __rmqueue3.2.3.2.1 __rmqueue_smallest3.2.3.2.2 __rmqueue_fallback3.…...
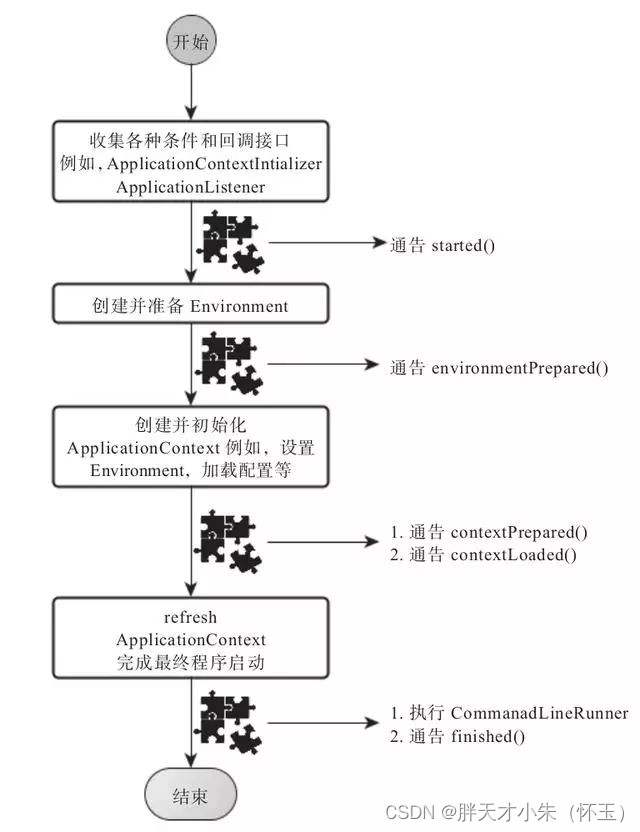
为什么要用springboot进行开发呢?
文章目录前言1、那么Springboot是怎么实现自动配置的1.1 启动类1.2 SpringBootApplication1.3 Configuration1.4 ComponentScan1.5 EnableAutoConfiguration1.6 两个重要注解1.7 AutoConfigurationPackage注解1.8 Import(AutoConfigurationImportSelector.class)注解1.9自动配置…...

设备树信息解析相关函数
一。可以通过三种不同的方式解析设备树节点: 1.根据设备树节点的名字解析设备树节点 struct device_node *of_find_node_by_name(struct device_node *from, const char *name); 参数: from:当前节点父节点首地址 name:设备树节点名字 …...

LeetCode-1124. 表现良好的最长时间段【哈希表,前缀和,单调栈】
LeetCode-1124. 表现良好的最长时间段【哈希表,前缀和,单调栈】题目描述:解题思路一:查字典。cur是当前的前缀和(劳累与不劳累天数之差),向前遍历。有两种情况。情况一,若cur大于0则是[0,i]的劳累与不劳累天…...
vue-router路由配置
介绍:路由配置主要是用来确定网站访问路径对应哪个文件代码显示的,这里主要描述路由的配置、子路由、动态路由(运行中添加删除路由) 1、npm添加 npm install vue-router // 执行完后会自动在package.json中添加 "vue-router…...

中国计算机设计大赛来啦!用飞桨驱动智慧救援机器狗
中国大学生计算机设计大赛是我国高校面向本科生最早的赛事之一,自2008年开赛至今,一直由教育部高校与计算机相关教指委等或独立或联合主办。大赛的目的是以赛促学、以赛促教、以赛促创,为国家培养德智体美劳全面发展的创新型、复合型、应…...

嘉定区2022年高新技术企业认定资助申报指南
各镇人民政府,街道办事处,嘉定工业区、菊园新区管委会,各相关企业: 为推进实施创新驱动发展战略,加快建设具有全球影响力的科技创新中心,根据《嘉定区关于加快本区高新技术企业发展的实施方案(…...

【C++】关键字、命名空间、输入和输出、缺省参数、函数重载
C关键字(C98)命名空间产生背景命名空间定义命名空间使用输入&输出缺省参数什么叫缺省参数缺省参数分类函数重载函数重载概念C支持函数重载的原理--名字修饰C关键字(C98) C总计63个关键字,C语言32个关键字。 下面我们先看一下C有多少关键字,不对关键…...

【一道面试题】关于HashMap的一系列问题
HashMap底层数据结构在1.7与1.8的变化 1.7是基于数组链表实现的,1.8是基于数组链表红黑树实现的,链表长度达到8时会树化 使用哈希表的好处 使用hash表是为了提升查找效率,比如我现在要在数组中查找一个A对象,在这种情况下是无法…...

论文笔记: Monocular Depth Estimation: a Review of the 2022 State of the Art
中文标题:单目深度估计:回顾2022年最先进技术 本文对比了物种最近的基于深度学习的单目深度估计方法: GPLDepth(2022)[15]: Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepthAdabins(2021)[1]: Adabins:…...
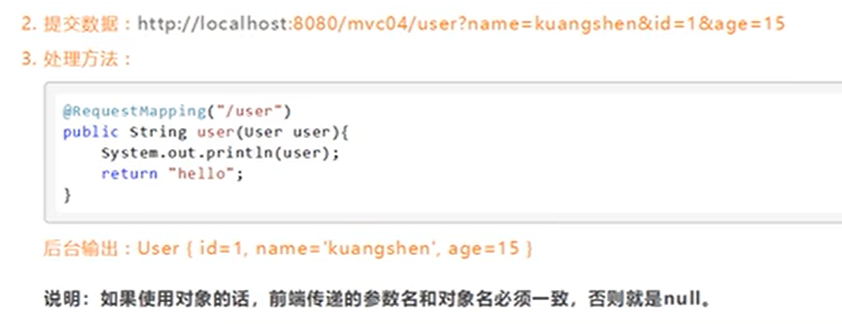
Springmvc补充配置
Controller配置总结 控制器通常通过接口定义或注解定义两种方法实现 在用接口定义写控制器时,需要去Spring配置文件中注册请求的bean;name对应请求路径,class对应处理请求的类。 <bean id"/hello" class"com.demo.Controller.HelloCo…...

MySQL 的 datetime等日期和时间处理SQL函数及格式化显示
MySQL 的 datetime等日期和时间处理SQL函数及格式化显示MySQL 时间相关的SQL函数:MySQL的SQL DATE_FORMAT函数:用于以不同的格式显示日期/时间数据。DATE_FORMAT(date, format) 根据格式串 format 格式化日期或日期和时间值 date,返回结果串。…...

基于微信云开发的防诈反诈宣传教育答题小程序
基于微信云开发的防诈反诈宣传教育答题小程序一、前言介绍作为当代大学生,诈骗事件的发生屡见不鲜,但却未能引起大家的重视。高校以线上宣传、阵地展示为主,线下学习、实地送法为辅,从而构筑立体化反诈骗防线。在线答题考试是一种…...
Map和Set
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。数据的一般查找方式有两种:直接遍历和二分查找。但这两种查找方式都有很大的局限性,也不便于对数据进行增删查改等操作。对于这一类数据的查找&…...
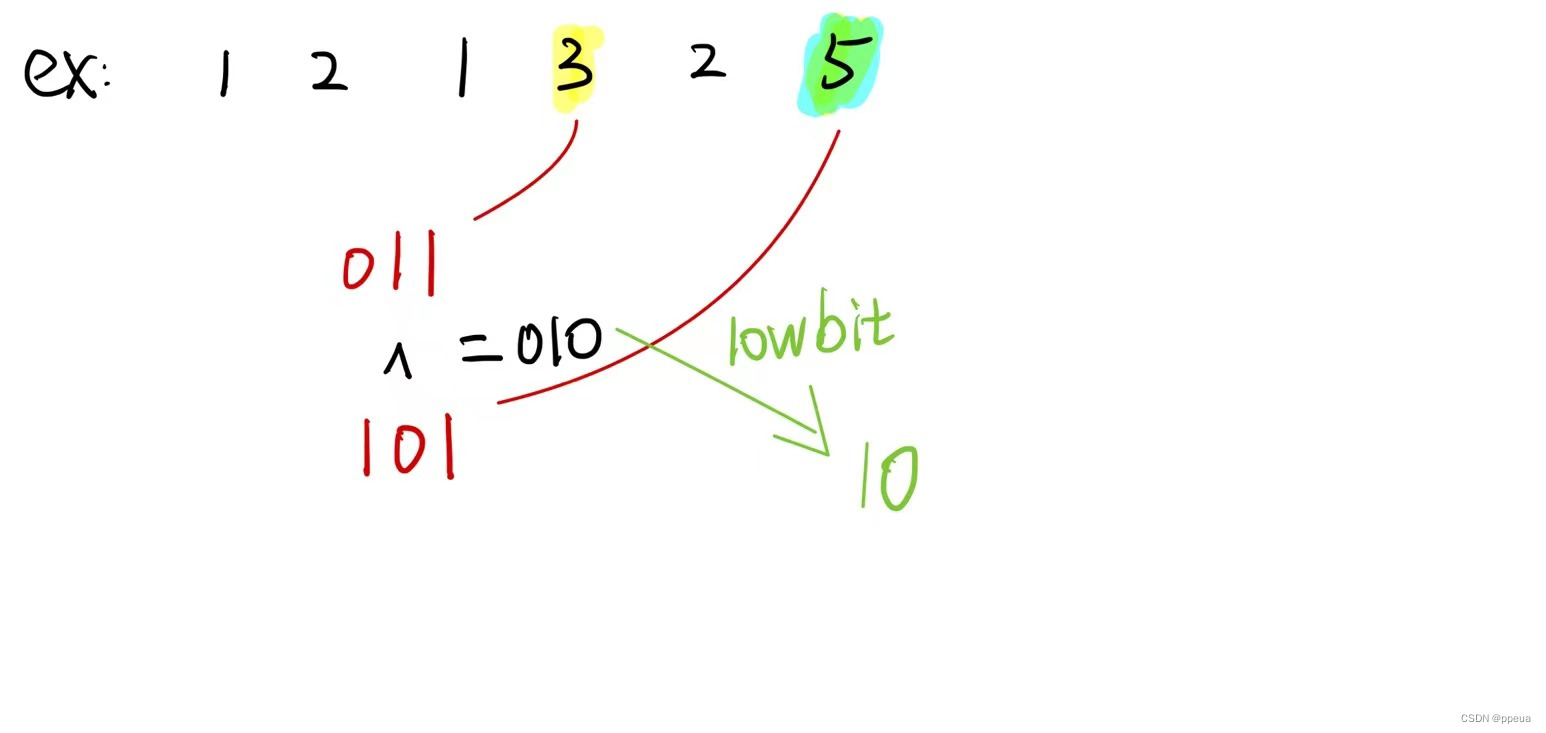
【位运算问题】Leetcode 136、137、260问题详解及代码实现
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

同花顺2023届春招内推
同花顺2023届春招开始啦! 同花顺是国内首家上市的互联网金融信息服务平台,如果你对互联网金融感兴趣,如果你有志向在人工智能方向发挥所长,如果你也是一个激情澎湃的小伙伴,欢迎加入我们!岗位类别…...
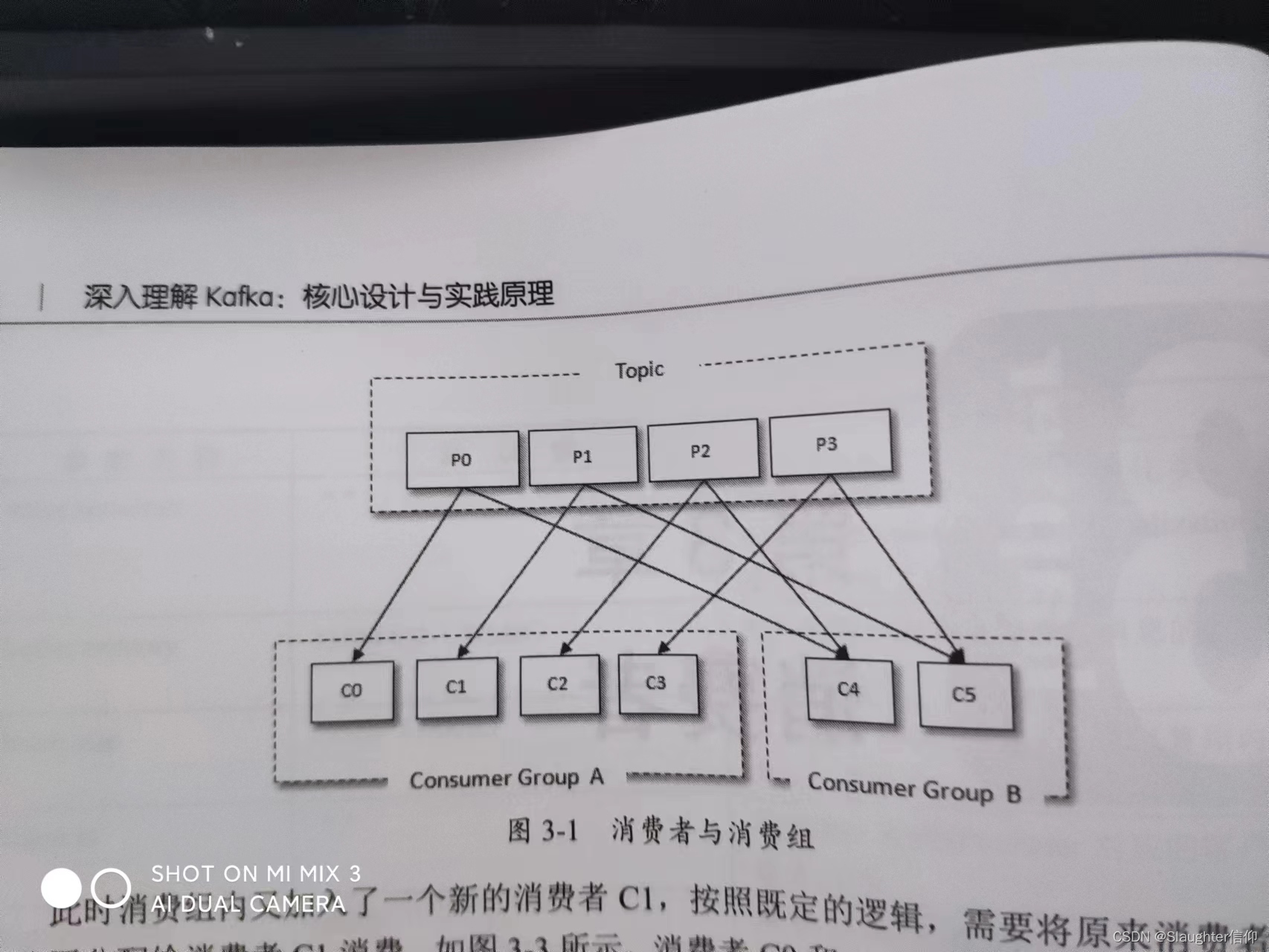
深入Kafka核心设计与实践原理读书笔记第三章消费者
消费者 消费者与消费组 消费者Consumer负责定于kafka中的主题Topic,并且从订阅的主题上拉取消息。与其他消息中间件不同的在于它有一个消费组。每个消费者对应一个消费组,当消息发布到主题后,只会被投递给订阅它的消费组的一个消费者。 如…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...