【Java基础】集合
一、集合概述
为了方便对多个对象进行存储和操作,集合是一种Java容器,可以动态地把多个对象引用放入容器中
数组存储的特点
- 一旦初始化后,长度不可改变,元素类型不可改变
- 提供的方法很少,对于添加、删除、获取实际元素个数等操作非常不便
- 有序、可重复
集合的两种体系
- Collection接口:单列数据,定义了存取一组对象的方法的集合。
- List:有序、可重复的集合
- Set:无序、不可重复的集合
- Map接口:双列数据,保存具有映射关系的“key-value”键值对集合


二、Collection接口
常用方法
public class CollectionTest {@Testpublic void test1(){Collection col1 = new ArrayList();// add(Object o) 添加元素col1.add("wanfeng");col1.add("jingyu");col1.add(123);// size() 元素个数System.out.println("col size = "+col1.size());// addAll(Collection c) 添加集合中的所有元素Collection col2 = new ArrayList();col2.add(false);col2.add(34.56);col2.add(29);col2.add("wanwan");Student s1 = new Student("wanfeng", 12);col2.add(s1);col1.addAll(col2);System.out.println(col1);// isEmpty() 判断集合是否有元素System.out.println(col1.isEmpty());// clear() 清空所有元素col1.clear();System.out.println(col1);// contains() 元素是否存在,ArrayList源码中调用的是Object类的equals方法(==比较地址值),// 若要比较内容需要在类中重写equals方法System.out.println(col2.contains(34.56));System.out.println(col2.contains("wanfeng"));System.out.println(col2.contains(s1));System.out.println(col2.contains(new Student("wanfeng", 12)));// containsAll() 集合中的元素是否全部存在Collection col3 = new ArrayList();col3.add("wanwan");col3.add(false);System.out.println(col2.containsAll(col3));// remove(Object o) 删除指定元素 若为自定义类也需要重写equals方法System.out.println(col2.remove("fengfeng"));System.out.println(col2.remove(new Student("wanfeng", 12)));// removeAll(Collection c) 删除c中包含的所有元素System.out.println(col2.removeAll(col3));System.out.println(col2);//retainAll(Collection c) 取交集Collection col4 = new ArrayList();col4.add(34.56);col4.add(true);col2.retainAll(col4);System.out.println(col2);// equals(Object o) 比较两个集合是否相同col2.add(true);Collection col5 = new ArrayList();col5.add(true);col5.add(34.56);System.out.println(col2.equals(col5));// hashCode() 返回哈希值System.out.println(col2.hashCode());// toArray() 转换为数组Object[] arr = col2.toArray();for(int i=0; i<arr.length; i++){if(i > 0) System.out.print(" ");System.out.print(arr[i]);}System.out.println();// Arrays.asList()数组转换为集合List<Object> list = Arrays.asList(arr);System.out.println(list);// iterator() 返回迭代器,用于集合遍历}}class Student{private String name;private int id;public Student() {}public Student(String name, int id) {this.name = name;this.id = id;}@Overridepublic boolean equals(Object o) {System.out.println("Student.equals([o]): 执行成功~");if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;if (id != student.id) return false;return name != null ? name.equals(student.name) : student.name == null;}
}
iterator迭代器
Iterator对象称为迭代器,主要用于遍历Collection集合中的元素。Iterator提供一种方法访问一个容器对象中各个元素,而又不需要暴露该对象的内部细节。迭代器模式,就是为容器而生。
/*
iterator() 返回迭代器,用于集合遍历iterator.next() 迭代器后移,并返回当前指向元素(未开始遍历时指向第一个元素的前面)iterator.hasNext() 后面是否存在元素
*/
Iterator iterator = col2.iterator();
while (iterator.hasNext()){System.out.println(iterator.next());
}
foreach遍历
Collection col2 = new ArrayList();
col2.add(false);
col2.add(34.56);
col2.add(29);
col2.add("wanwan");
col2.add("jingyu");//本质也是用了iterator
//item是元素的拷贝,而不是元素本身
for(Object item : col2){System.out.println(item);
}
三、List接口
List接口存储有序、可重复的元素。
List接口实现类
相同点:三个类都实现了List接口,存储数据的特点都是有序的、可重复的
不同点:
- ArrayList:List的主要实现类。线程不安全,效率高。底层使用Object[]存储
- LinkedList:频繁使用插入、删除操作时效率高,底层使用双向链表存储。
- Vector:List的古老实现类(JDK1.0)。线程安全,效率低。底层使用Object[]存储
四、ArrayList
源码分析:使用空参构造器ArrayList()时,底层Object[] elementData初始化为{ },在第一次添加进行扩容调用grow。(JDK8)
public class ListTest {@Testpublic void test1(){ArrayList list = new ArrayList(10);System.out.println(list.size());list.add(11);list.add(22);list.add(33);list.add("wanfeng");list.add(new Student("jingyu", 13));System.out.println(list);// add(int index, Object o) 将元素添加到索引位置list.add(1, "feng");System.out.println(list);// addAll(int index, Collection c) 将集合c中的所有元素添加到索引位置Collection col2 = new ArrayList();col2.add(false);col2.add(34.56);col2.add(22);col2.add("wanwan");col2.add("jingyu");list.addAll(2, col2);System.out.println(list);// size() 元素个数System.out.println(list.size());// get(int index) 获取索引位置的元素System.out.println(list.get(7));// indexOf(Object o) 元素首次出现的索引位置,找不到返回-1System.out.println(list.indexOf(22));System.out.println(list.indexOf(999));// lastIndexOf(Object o) 元素最后一次出现的索引位置System.out.println(list.lastIndexOf(22));// remove(int index) / remove(Object o) 删除元素Object remove = list.remove(1);list.remove(new Integer(22));System.out.println(list);// set(int index, Object o) 修改指定位置的元素为olist.set(1, new Integer(987));System.out.println(list);// subList(int start, int end) 返回指定范围的子集合,左闭右开List sub = list.subList(2, 8);System.out.println(sub);// iterator迭代器遍历Iterator iterator = list.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}// foreach 增强for循环for(Object item : list){System.out.println(item);}}
}
五、LinkedList
源码分析:使用空参构造器LinkedList()时,底层声明了Node类型的first和last属性,默认值为null
常用方法与ArrayList基本一致
六、Set接口
存储无序、不可重复的数据。无序不等于随机,以HashSet为例,数据添加时并非按照索引顺序添加,而是根据数据的hash值顺序添加。不可重复性是指添加的元素按照equals判断时,不能返回true,即只能添加一个。
Set接口中没有新的方法,都是Collection中的方法
在实际应用中,Set常用来过滤重复数据
Set接口实现类
- HashSet:Set主要实现类,线程不安全,可以存储null
- LinkedHashSet:HashSet的子类。遍历时可按照添加顺序遍历
- TreeSet:底层使用红黑树存储。存储的数据必须是同一个类型,可以按照添加对象的指定属性进行排序
七、HashSet
底层是一个数组(默认长度为16)。
HashSet添加元素的机制
当添加数据时,取得hash值,根据hash函数放入数组指定的位置。若该位置上已有元素,则比较二者hashCode(若类中没有重写调用Object类中的hashCode,这个方法生成的hasCode是随机的),若不同则添加成功,以链表形式和已有元素连接。若hash值相同则调用equals方法比较,若为false代表不重复,添加成功,否则添加失败。

在Set中添加数据需要注意的规则
-
添加的数据所在类一定要重写hashCode()和equals()
-
equals里用到的属性和hashCode里用到的属性相同
IDEA工具中对hashCode()的重写为什么常出现31这个数字?
选择系数应尽量选择较大的系数,增加hash地址,减少冲突,提高查找效率。31只占用5bit,相乘造成数据溢出的概率较小。i * 31 == (i<<5) - 1,很多虚拟机里都有相关优化。31是一个素数,其他数和31相乘的结果只能被素数本身和这个其他数整除,减少冲突.
八、LinkedHashSet
底层结构与HashSet相同,都是数组,但是添加了双向链表结构,遍历时以链表形式遍历而不是数组,因此可以以添加顺序遍历
九、TreeSet
添加的数据必须是相同类的对象,添加后自动排序,需要实现Comaprable接口,同时实现的ComapreTo方法也用来判断两个元素是否重复
- 自然排序:实现Comaprable接口,比较两个对象是否重复的标准是compareTo()是否返回0
- 定制排序:声明一个Comparator接口的匿名子类的对象(实现compare方法),将该对象作为TreeSet构造器参数时,TreeSet将会以compare方法比较两个对象是否重复
public class SetTest {// Tree自然排序@Testpublic void test3(){TreeSet set1 = new TreeSet();set1.add(10);set1.add(34);set1.add(6);set1.add(18);set1.add(-9);for(Iterator iterator= set1.iterator(); iterator.hasNext(); ){System.out.println(iterator.next());}TreeSet studentSet = new TreeSet();// Student需要实现Comparable接口studentSet.add(new Student("wanfeng", 12));studentSet.add(new Student("jingyu", 20));studentSet.add(new Student("wanwan", 15));studentSet.add(new Student("jingjing", 13));studentSet.add(new Student("jingjing", 34));for(Iterator iterator= studentSet.iterator(); iterator.hasNext(); ){System.out.println(iterator.next());}}// TreeSet定制排序@Testpublic void test4(){Comparator comparator = new Comparator() {@Overridepublic int compare(Object o1, Object o2) {if(o1 instanceof Student && o2 instanceof Student){Student s1 = (Student) o1;Student s2 = (Student) o2;return s1.getId() - s2.getId();}else{throw new RuntimeException("类型不一致");}}};// 以comparator比较器作为比较标准TreeSet studentSet = new TreeSet(comparator);studentSet.add(new Student("wanfeng", 12));studentSet.add(new Student("jingyu", 20));studentSet.add(new Student("wanwan", 15));studentSet.add(new Student("jingjing", 13));studentSet.add(new Student("jingjing", 34));for(Iterator it=studentSet.iterator(); it.hasNext(); ){System.out.println(it.next());}}
}
十、Map接口
存储键值对(key-value)
Map接口实现类
- HashMap:Map接口的主要实现类;线程不安全,效率高;可以存储null
- LinkedHashMap:HashMap的子类。在HashMap基础上增加了链表结构,按添加顺序遍历。对于频繁遍历操作,效率优于HashMap
- TreeMap:添加键值对时进行排序(按key排序的自然排序、定制排序)。底层使用红黑树
- Hashtable:Map接口的古老实现类;线程安全,效率低;不能存储null
- Properties:处理配置文件,key-value都是String类型
Map常用方法(HashMap)
@Test
public void test2(){Map map1 = new HashMap();// put(Object key, Object value) 添加键值对map1.put("BB", 12);map1.put("AA", 23);map1.put("CC", 34);System.out.println(map1);// putAll(Map m) 将m中的键值对全部添加Map map2 = new HashMap();map2.put("wanfeng", 23);map2.put("jingyu", 21);map1.putAll(map2);System.out.println(map1);// remove(Object key) 根据key删除键值对,返回valueObject remove_value = map1.remove("AA");System.out.println("remove_value: "+remove_value);System.out.println(map1);// clear() 删除所有键值对map2.clear();System.out.println("map2 size: "+map2.size());System.out.println(map2);// get(Object key) 获取key对应的valueObject get_value = map1.get("wanfeng");System.out.println("get_value: "+get_value);// containsKey(Object key) 是否包含keySystem.out.println(map1.containsKey("jingyu"));// containsValue(Object value) 是否包含valueSystem.out.println(map1.containsValue(23));// size() 获取键值对个数System.out.println("map1 size: "+map1.size());// isEmpty() map是否为空System.out.println(map1.isEmpty());System.out.println(map2.isEmpty());// equals(Map m) 判断两个map是否相同System.out.println(map1.equals(map2));
}
Map遍历(HashMap)
@Test
public void test3(){Map map1 = new HashMap();map1.put("BB", 12);map1.put("AA", 23);map1.put("CC", 34);System.out.println(map1);// 遍历key:拿到keySet再用iterator遍历Set keyset = map1.keySet();for(Iterator it=keyset.iterator(); it.hasNext(); ){System.out.println(it.next());}// 遍历value,拿到Collection,再用iterator或增强for循环遍历Collection values = map1.values();for(Object value : values){System.out.println(value);}// 第一种方式:遍历key-value拿到EntrySet,使用iterator遍历,// 每一个Entry调用 getKey() 和 getValue() 获取。// 第二种方式,遍历key的时候调用get(Object key)同时遍历valueSet entrySet = map1.entrySet();for(Iterator it=entrySet.iterator(); it.hasNext(); ){Object o = it.next();Map.Entry entry = (Map.Entry) o;System.out.println(entry.getKey() + " --> " + entry.getValue());}}
十一、HashMap
JDK7以前底层结构为数组+链表,JDK8以后增加了红黑树
Map的结构
- key:无序、不可重复,用Set存储所有key(key所在类要重写hashCode和equals)
- value:无序、可重复,用Collection存储所有key
- key-value:一个Entry对象,无序、不可重复,用Set存储所有Entry

HashMap底层实现原理
JDK7
- 创建HashMap对象后,底层创建了长度为16的数组Entry[] table
- put(key1, value1) 添加键值对时,调用key1所在类的hashCode获取hash值并经过indexFor(和数组长度-1的与运算)得到这个Entry的存放位置,如果此位置没有数据则添加成功。如果此位置已有数据,比较key1的hash值和已有数据的hash值
- 若hash值不相同,则添加成功(链表存储)
- 若hash值相同,调用equals进行比较
- 若返回false,添加成功(链表存储)
- 若为true,用value1替换已有数据的value
- 在不断添加过程中,当超过临界值(threshold)且添加的位置已有元素时,扩容为原来的2倍
JDK8
- 创建HashMap对象后,底层没有创建长度16的数组
- 数组的类型是Node[],而不是Entry[]
- 首次调用put方法时,底层创建长度为16的数组
- 当数组某个索引位置(链表)上的元素个数 > 8 且当前数组长度 > 64时,此索引位置上的链表改为红黑树存储
- HashMap中的常量和变量
- DEFAULT_INITIAL_CAPACITY = 16:默认容量
- DEFAULT_LOAD_FACTOR = 0.75:默认加载因子
- threshold:扩容临界值 = 容量 * 加载因子
- TREEIFY_THRESHOLD = 8:Bucket中链表长度大于默认值时,转化为红黑树
- MIN_TREEIFY_CAPACITY = 64:链表转化为红黑树时的最小hash表容量

十二、LinkedHashMap
在添加数据时与HashMap不同,将键值对添加进数组或链表时,创建了新的Entry对象(重写了HashMap的newNode方法),这个Entry类是带有before和after两个指针指向前后的元素,形成双向链表。

十三、TreeMap
向TreeMap中添加key-value,要求key必须都是同一个类的对象,因为要按照key排序(自然排序、定制排序)
void showTreeMap(TreeMap tm){if(tm == null) return;Set keyset = tm.keySet();for(Iterator it=keyset.iterator(); it.hasNext(); ){Student key = (Student) it.next();System.out.println(key + " --> " + tm.get(key));}
}@Test
public void TreeMapTest(){//自然排序TreeMap map1 = new TreeMap();map1.put(new Student("wanfeng", 23), 11);map1.put(new Student("jingyu", 21), 55);map1.put(new Student("wanwan", 25), 44);map1.put(new Student("fengfeng", 18), 22);showTreeMap(map1);//定制排序(与TreeSet原理相同,此处用的是Comparator接口的匿名实现类的匿名对象)TreeMap map2 = new TreeMap(new Comparator() {@Overridepublic int compare(Object o1, Object o2) {if(o1 instanceof Student && o2 instanceof Student){Student s1 = (Student) o1;Student s2 = (Student) o2;// name倒序return -s1.getName().compareTo(s2.getName());}throw new RuntimeException("类型不匹配");}});map2.put(new Student("wanfeng", 23), 11);map2.put(new Student("jingyu", 21), 55);map2.put(new Student("wanwan", 25), 44);map2.put(new Student("fengfeng", 18), 22);showTreeMap(map2);
}
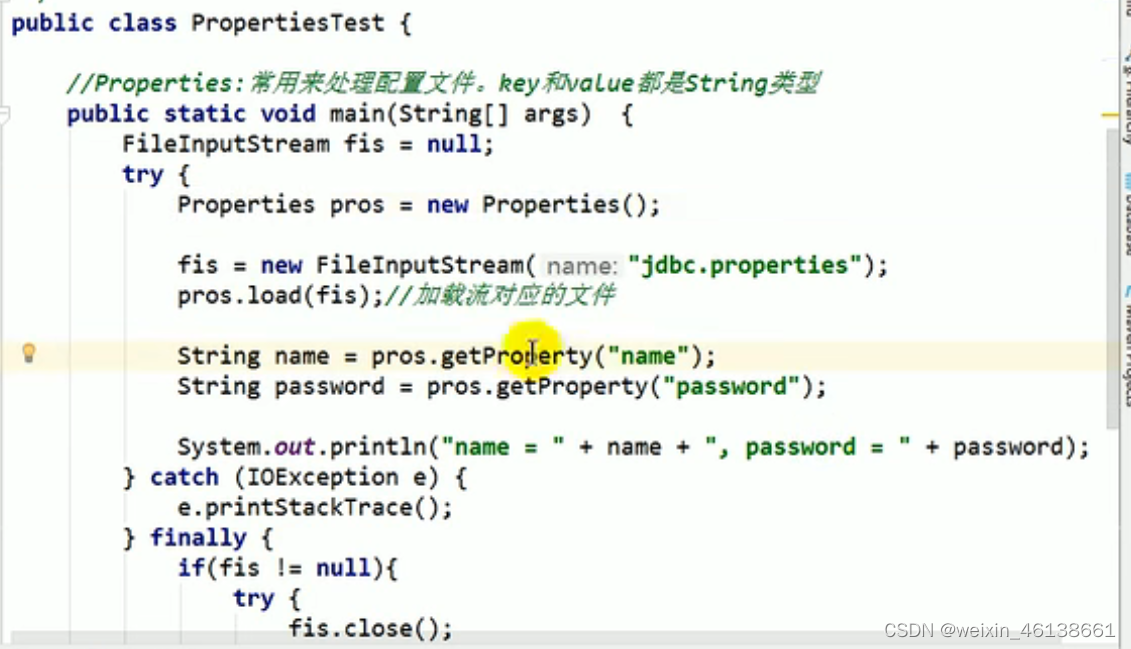
十四、Properties
Hashtable的子类,处理属性文件。键值对都是String类型
@Test
public void propertiesTest(){FileInputStream fis = null;FileOutputStream fos = null;try {Properties properties = new Properties();// 得到文件输入流fis = new FileInputStream("src/com/lzh/Map/mypro.properties");// 将文件输入流加载进Properties对象中properties.load(fis);// 获取属性System.out.println(properties.getProperty("username"));System.out.println(properties.getProperty("password"));//设置属性properties.setProperty("id", "27");fos = new FileOutputStream("src/com/lzh/Map/mypro.properties");properties.store(fos, "comment");} catch (IOException e) {e.printStackTrace();} finally {try {if(fis != null) fis.close();if(fos != null) fos.close();} catch (IOException e) {e.printStackTrace();}}
}
十五、Collections工具类
@Test
public void test1(){ArrayList list = new ArrayList(10);list.add("wanfeng");list.add("zhipeng");list.add("jingyu");list.add("xinxin");System.out.println(list.size());System.out.println(list);//reverse(list) 反转ListCollections.reverse(list);System.out.println("reverse: " + list);// shuffle(list) 随机排序ListCollections.shuffle(list);System.out.println("shuffle: "+ list);// sort(list) 自然排序,升序Collections.sort(list);System.out.println("自然排序:"+list);// sort(list, Comparator c) 定制排序Collections.sort(list, new Comparator<Object>() {@Overridepublic int compare(Object o1, Object o2) {if(o1 instanceof String && o2 instanceof String){String s1 = (String) o1;String s2 = (String) o2;return -s1.compareTo(s2);}throw new RuntimeException("类型不匹配");}});System.out.println("定制排序:"+list);// swap(index1, index2) 交换两个索引位置的元素Collections.swap(list, 0, 2);System.out.println("swap:"+list);// max(Collection) 获取最大值(自然排序)// max(Collection, Comparator) 获取最大值(定制排序)// min(Collection) 获取最小值(自然排序)// min(Collection, Comparator) 获取最小值(定制排序)//frequency(Collection, Object) 返回集合中指定元素的出现次数System.out.println(Collections.frequency(list, "wanfeng"));// copy(List list1, List list2) 将list2对应索引位置的元素复制到list1中// list2.size() > list1.size() 抛出IndexOutOfBoundsExceptionArrayList list2 = new ArrayList();list2.add("345");list2.add("111");Collections.copy(list, list2);System.out.println(list);// replaceAll(List list, Object oldVal, Object newVal) 将list中的所有旧值改为新值Collections.replaceAll(list, "zhipeng", "newval");System.out.println(list);// Collection同步控制// synchronizedCollection(Collection)// synchronizedList(List) ArrayList线程不安全// synchronizedMap(Map) HashMap线程不安全List syncList = Collections.synchronizedList(list); //返回线程安全的List
}
相关文章:
【Java基础】集合
一、集合概述 为了方便对多个对象进行存储和操作,集合是一种Java容器,可以动态地把多个对象引用放入容器中 数组存储的特点 一旦初始化后,长度不可改变,元素类型不可改变提供的方法很少,对于添加、删除、获取实际元…...

【Android入门到项目实战-- 9.1】—— 传感器的使用教程
目录 传感器的定义 三大类型传感器 1、运动传感器 2、环境传感器 3、位置传感器 传感器开发框架 1、SensorManager 2、Sensor 3、SensorEvent 4、SensorEventListener 一、使用传感器开发步骤 1、获取传感器信息 1)、获取传感器管理器 2)、获取设备的传感器对象列…...
yolov8 浅记
目录 Pre: 1. YOLOv8 概述 2. 模型结构设计 3. Loss 计算 4.训练数据增强 5. 训练策略 6、部署推理 End Pre: yolo系列发布时间: 先贴一下yolo各系列的发布时间(说出来很丢人,我以为 yolox是 最新的): yoloX 2…...

前端009_类别模块_修改功能
第九章 1、需求分析2、Mock添加查询数据3、Mock修改数据4、Api调用回显数据5、提交修改后的数据6、效果1、需求分析 需求分析 当点击 编辑 按钮后,弹出编辑窗口,并查询出分类相关信息进行渲染。修改后点击 确定 提交修改后的数据。 2、Mock添加查询数据 请求URL: /article/…...

2022级吉林大学面向对象第一次上机测试
【注:解答全部为本人所写,仅供同学们学习时参考使用,请勿照搬抄袭!】 1、 1)略 2)如果main,f1,g1,g2或更多的函数之间有更为复杂的调用关系,头文件一般按怎样的规律写呢? 一般情况下…...
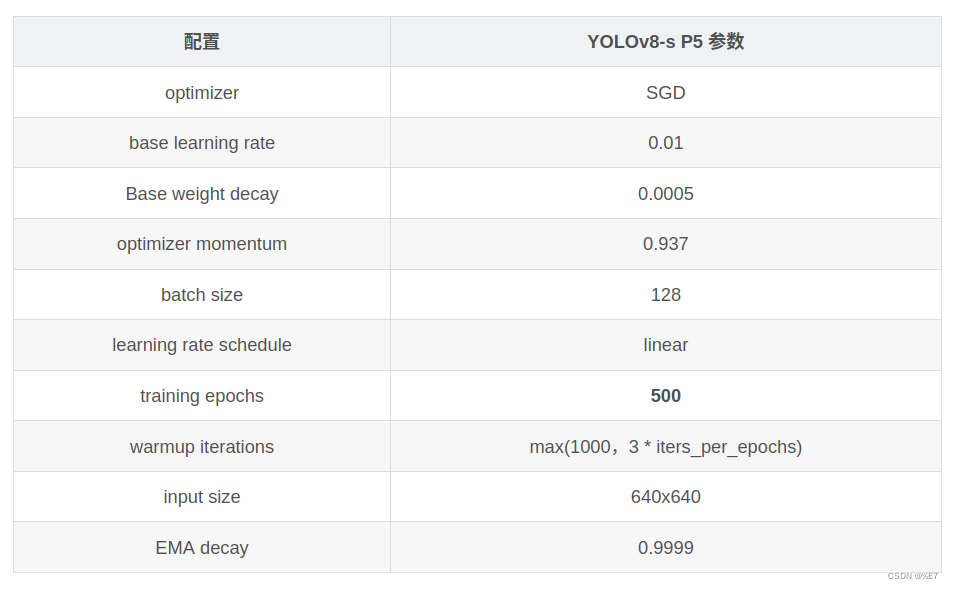
计算机体系结构总结:内存一致性模型 Memory consistency Model
存储一致性是为了保证多线程背景下的访存顺序,多线程的语句是可以交错执行,使得顺序不同产生不同的执行结果。 下面P2的输出结果可能是什么? P1, P2两个线程的语句是可以交叉执行的,比如1a, 2a, 2b, 1b;一个线程内的语…...
介绍)
高速列车运行控制系统(CTCS)介绍
1、CTCS功能 安全防护 在任何情况下防止列车无行车许可运行防止列车超速运行防止列车超过进路允许速度防止列车超过线路结构规定的速度防止列车超过机车车辆构造速度防止列车超过临时限速及紧急限速防止列车超过铁路有关运行设备的限速防止列车溜逸 人机界面 以字符、数字及…...

C#“System.Threading.ThreadStateException”类型的未经处理的异常
备忘 最近做一个功能,从主界面进入另一个界面时,数据量较大,处理信息较多,程序宕机。而且点击程序还会提示程序无响应。不得已用另一个线程显示界面。但在界面中使用控件时,报错:“System.Threading.Thread…...

为什么要交叉编译?
一、什么是交叉编译、为什么要交叉编译 1、什么是交叉编译? 交叉编译:是在一个平台上生成另一个平台上的可执行代码。比如我们在 x86 平台上,编写程序并编译成能运行在 ARM 平台的程序,编译得到的程序在 x86 平台上是不能运行的…...
java版本电子招标采购系统源码—企业战略布局下的采购
智慧寻源 多策略、多场景寻源,多种看板让寻源过程全程可监控,根据不同采购场景,采取不同寻源策略, 实现采购寻源线上化管控;同时支持公域和私域寻源。 询价比价 全程线上询比价,信息公开透明࿰…...
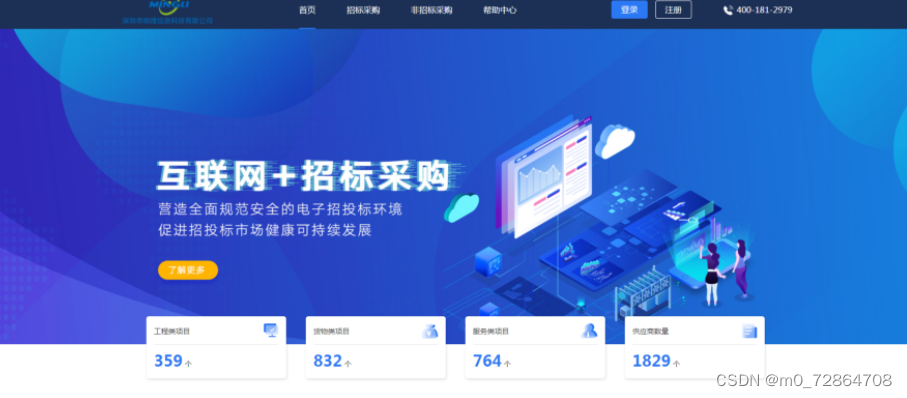
【MATLAB数据处理实用案例详解(17)】——利用概念神经网络实现柴油机故障诊断
目录 一、问题描述二、利用概念神经网络实现柴油机故障诊断原理三、算法步骤3.1 定义样本3.2 样本归一化3.3 创建网络模型3.4 测试3.5 显示结果 四、运行结果五、完整代码 一、问题描述 柴油机的结构较为复杂,工作状况非常恶劣,因此发生故障的可能性较大…...

神奇字符串、密钥格式化----2023/5/6
神奇字符串----2023/5/6 神奇字符串 s 仅由 ‘1’ 和 ‘2’ 组成,并需要遵守下面的规则: 神奇字符串 s 的神奇之处在于,串联字符串中 ‘1’ 和 ‘2’ 的连续出现次数可以生成该字符串。 s 的前几个元素是 s “1221121221221121122……” 。…...

STM32F4_十进制和BCD码的转换
目录 前言 1. BCD码 2. BCD码和十进制转换的算法 前言 最近在学习STM32单片机(不仅仅是32)的RTC实时时钟系统的过程中,需要配置时钟的时间、日期;这些都需要实现BCD码和十进制之间进行转换。这里和大家一起学习BCD码和十进制之…...
)
random — 伪随机数生成器(史上总结最全)
目的:实现几种类型的伪随机数生成器。 random 模块基于 Mersenne Twister 算法提供了一个快速的伪随机数生成器。Mersenne Twister 最初开发用于为蒙特卡洛模拟器生成输入,可生成具有分布均匀,大周期的数字,使其可以广泛用于各种…...
基于VBA实现成绩排序的最佳方法-解放老师的双手
作为一名老师,每到期末就要面对一件让人头疼的事情——成绩表统计。 首先,要收集每个学生的考试成绩。这需要花费大量的时间和精力,因为每个学生都有多门科目的成绩需要统计。 其次,要将每个学生的成绩录入到电子表格中。这看起来…...

OCAF如何实现引用关系和拓扑关系
在 OpenCASCADE 中,TDF_Label 是用来保存对象及其属性的基本单元。TDF_Label 可以通过添加不同类型的属性来保存不同的数据类型。属性是继承自 TDF_Attribute 类的对象,每个属性都有一个唯一的标识符(GUID)来识别其类型。TDF_Label是OpenCASCADE中用来管理数据的标签类,它…...

自动创建设备节点
在成功加载驱动模块之后,还需要使用 mknod命令创建设备节点,才能在/dev目录下创建对应的设备文件。自动创建设备节点的功能需要依赖 mdev 设备管理机制,在使用 buildroot 构建 rootfs 的时候,会默认构建 mdev 的功能,m…...

JavaWeb ( 六 ) JSP
2.4.JSP JSP (Java Server Pages) : 一种在服务器端生成动态页面的技术,本质上就是Servlet。将HTML代码嵌入到Java代码中, 通过Java逻辑控制HTML代码的结构从而生成页面。在MVC中通常担任视图层(view),负责信息的展示与收集。 2…...
2023世界超高清视频产业发展大会博冠8K明星展品介绍
2023世界超高清视频产业发展大会博冠8K明星展品介绍: 一、博冠8K全画幅摄像机B1 这是一款面向广电应用的机型,可适配外场ENG制作轻量化需求,应用于8K单边机位、新闻、专题的拍摄工作,也可应用于体育转播、文艺节目等特殊机位及各…...
Map接口以及Collections工具类
文章目录 1.Map接口概述1.1 Map的实现类的结构1.2 Map中存储的key-value结构的理解1.3 HashMap的底层实现原理(以JDK7为例)1.4 Map接口的常用方法1.5 TreeMap1.6 Map实现类之五: Properties 1.Collections工具类1.1方法1.1.1 排序操作(均为static方法)1.1.2 查找、替换 1.Map接…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...

DBLP数据库是什么?
DBLP(Digital Bibliography & Library Project)Computer Science Bibliography是全球著名的计算机科学出版物的开放书目数据库。DBLP所收录的期刊和会议论文质量较高,数据库文献更新速度很快,很好地反映了国际计算机科学学术研…...