MySQL系列三(定位慢SQL、SQL优化与索引优化)Using filesort
文章目录
- 1. 慢SQL
- 1.1 定位慢SQL(慢查询日志)
- 1.2 慢SQL优化整体思路
- 2. 索引优化
- 3. SQL语句优化
- 回表
- Using filesort
1. 慢SQL
1.1 定位慢SQL(慢查询日志)
在mysql 配置文件中 (my.conf),进行下面配置,修改配置后重启mysql生效。
# 开启或关闭慢查询日志
slow_query_log = ON
# 慢查询记录时间阈值,SQL执行超过此时间则会被记录到日志(单位:秒,默认10秒)。
long_query_time = 5
# 指定生成的慢查询日志路径(未设置则和默认和数据文件放一起)
slow_query_log_file = /opt/soft/mysql/log/slow.log
# 是否记录未使用索引的SQL。
log_queries_not_using_indexes=on
设置全局变量(MySQL重启后失效,不建议)
set global slow_query_log = on;
set global log_output = 'FILE,TABLE';
set global long_query_time = 0.001;
1.2 慢SQL优化整体思路
- 找出对业务影响大的(调用次数多的)、扫描行数多的SQL进行优化,查看执行计划explain,SQL使用到的表的结构、查看其是否使用索引、是否有冗余索引;
- 对响应时间长但调用次数少的SQL,评估其对业务的影响,是否存在短时间批量执行的可能,因为一旦批量执行可能会在短时间内让数据库挂掉;
慢SQL优化办法:
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引,查询条件多时可加联合索引;
创建联合索引时列的选择原则
- 经常用的列优先(最左匹配原则)
- 离散度高的列优先(离散度高原则)
- 宽度小的列优先(最少空间原则)
- select的查询结果中尽量避免使用*,只查询用到的字段;
- 尽量避免使用in和not in,能用between就不用in,in和not in会导致数据库进行全表扫描,增加运行时间。例如查询学号为8,9的人的学号和成绩
select 学号,成绩 from 成绩表 where 学号 in(8,9);
优化后:
select 学号,成绩 from 成绩表 where 学号 between 8 and 9;
- 尽量避免使用or,or会导致数据库进行全表扫描。可以使用union代替or*;例如从成绩表中选出成绩是88分或89分学生的学号:
select 学号 from 成绩表 where 成绩=88 or 成绩=89;
优化后:
select 学号 from 成绩表 where 成绩=88
union
select 学号 from 成绩表 where 成绩=89
- where子句比较符号左侧避免函数,尽量避免在比较符号的左侧出现表达式、函数等操作,因为会导致全表扫描,增加运行时间。所以,为了提高效率,可以把where子句中遇到函数或加减乘除的运算移到比较符号的右侧;
- 用limit子句限制返回的数据行数,如果前台只需要显示15行数据而查询结果返回了1万行,那么最好使用limit子句来限制查询返回的数据行数。
2. 索引优化
like查询以%开头时索引失效:
select * from doc where title like ‘%XX’; --不能使用索引
select * from doc where title like ‘XX%’; --非前导模糊查询,可以使用索引
反向条件不走索引:负向条件有:!=、<>、not in、not exists、not like 等
select * from doc where status != 1 and status != 2; --不能使用索引
select * from doc where status in (0,3,4); --优化为 in 查询,可以使用索引
IS NULL、IS NOT NULL 在无法使用索引,不过在mysql的高版本已经做了优化,允许使用索引
在索引列做任何操作(计算、函数、表达式)会导致索引失效而转向全表扫描
select * from doc where YEAR(create_time) <= ‘2016’; – 不能使用索引
select * from doc where create_time<= ‘2016-01-01’; – 可以使用索引
select * from order where date < = CURDATE(); – 不能使用索引
select * from order where date < = ‘2018-01-2412:00:00’; – 可以使用索引
select id from t where substring(name,1,3)=’abc’ – 不能使用索引
select id from t where name like ‘abc%’ – 可以使用索引
select id from t where num/2=100 – 不能使用索引
select id from t where num=100*2 – 可以使用索引
强制类型转换会导致全表扫描 :字符串类型不加单引号会导致索引失效,因为mysql会自己做类型转换,相当于在索引列上进行了操作。
select * from user where phone=13800001234; – 不能使用索引
select * from user where phone=‘13800001234’; – 可以使用索引
使用组合索引时,要符合最左前缀原则: :组合索引的字段数不允许超过5个。如果在a,b,c三个字段上建立联合索引 index(a,b,c),那么他会自动建立 a、(a,b)、(a,b,c) 三组索引。
- 建立联合索引的时候,区分度最高的字段在最左边:
- 存在等号和非等号混合判断条件时,在建立索引时,把等号条件的列前置,如 where a > ? and b= ?,那么即使 a 的区分度更高,也必须把 b 放在索引的最前列。
- 最左前缀查询时,并不是指SQL语句的where顺序要和联合索引一致,但还是建议 where 条件的顺序和联合索引一致。
- 假如index(a,b,c), where a=3 and b like ‘abc%’ and c=4,a能用,b能用,c不能用。
利用覆盖索引来进行查询操作,避免回表,减少select * 的使用
更新十分频繁、数据区分度不高的列不宜建立索引: 数据更新会变更 B+ 树,在更新频繁的字段建立索引会大大降低数据库性能。类似于“性别”这种区分度不大的属性,建立索引是没有什么意义的,不能有效过滤数据,性能与全表扫描类似。一般区分度在80%以上的时候就可以建立索引,区分度可以使用 count(distinct(列名))/count(*) 来计算。
单表索引建议控制在5个以内:索引不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,同时也会暂用空间。一个表的索引数较好不要超过5个。
SQL 性能优化 explain 中的 type:至少要达到 range 级别,要求是 ref 级别,如果可以是 consts 最好。
consts:单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
ref:使用普通的索引
range:对索引进行范围检索。
当 type=index 时,索引物理文件全扫,速度非常慢。
进行join联表查询的字段需要建立索引,join最好不要超过三个表,需要 join 的字段,数据类型必须一致: 多表关联查询时,保证被关联的字段需要有索引。left join是由左边决定的,左边的数据一定都有,所以右边是我们的关键点,建立索引要建右边的。当然如果索引在左边,可以用right join。
索引失效情况总结:
全值匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
Like百分写最右,覆盖索引不写星;
不等空值还有or,索引失效要少用。
3. SQL语句优化
减少请求的数据量:
- 只返回必要的列,用具体的字段列表代替 select * 语句
- 只返回必要的行,使用 Limit 语句来限制返回的数据。如果不使用 Limit 的话,MySQL将会一行一行的将全部结果按照顺序查找,最后返回结果,借助 Limit 可以实现当找到指定行数时,直接返回查询结果,提高效率
优化深度分页的场景:利用延迟关联或者子查询:对于 limit m, n 的分页查询,越往后面翻页(即m越大的情况下)SQL的耗时会越来越长,对于这种应该先取出主键id,然后通过主键id跟原表进行Join关联查询。因为MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后放弃前 offset 行,返回 N 行,那当 offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行 SQL 改写。延迟关联示例如下,先快速定位需要获取的 id 段,然后再关联:
延迟关联:通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据
覆盖索引:select的数据列只用从索引中就能够得到,不用回表查询
select a.* from 表1 a,(select id from 表1 where 条件 limit 100000,20) b where a.id=b.id;
避免在使用or来连接查询条件:如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描。
小表驱动大表,即小的数据集驱动大的数据集:
回表
MySQL规定,在使用InnoDB存储引擎的时候,必须且仅有一个聚集索引,非聚集索引也就是普通索引就看自己设置的有多少个了。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,如下图
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。
如主键索引,如果一条 SQL 需要查询主键,那么正好根据主键索引就可以查到主键。
再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引, 那么直接根据这个索引就可以查到数据,也无需回表。
Using filesort
在使用 explain 命令优化SQL语句的时候常常会在Extra列的描述中发现 Using filesort 选项,,其实这个名字很容易造成误解,一开始我以为是“文件排序”的意思,进一步说可能就是使用了磁盘空间来进行排序,但是这个理解是错误的,Using filesort 真正含义其实只有 sort 这一个单词,和 file 没有什么关系,Mysql一般是通过内存进行排序的,不过,要是超过了配置中的限制,应该会生成临时表。
分析
Using filesort 的含义很简单,就是使用了排序操作,出现这个选项的常见情况就是 Where 条件和 order by 子句作用在了不同的列上,这种情况还有优化的余地,有些场景由于数据量太小或者语句的简单性可能都不需要优化,既然说Using filesort是使用了排序的意思,那么是不是包含了 order by 子句的查询语句都会有这个选项呢?其实这个排序操作有时是可以避免的。
如果你想把一个表中的所有数据按照指定顺序输出,那么整个排序几乎是不可避免的,比如这个语句select * from a order by id,即使在id列上建立了索引,为了生成指定顺序的数据,那么整个数据的排序也是需要,不过个别时候这个排序还是可以省略的,比如id是该表的主键,并且是自增长的,数据本身就是有序的,那么直接返回数据就行了,相当于 order by id 这一部分被忽略了。
上面提到的常见情况,SQL语句通常写成这样select * from a where type = 5 order by id,这类语句一般会产生 Using filesort 这个选项,即使你在 type 和 id 上分别添加了索引。我们想一下它的工作过程,先根据type的索引从所有数据信息中挑选出满足 type = 5 条件的,然后根据id列的索引信息对挑选的数据进行排序,所以产生了Using filesort选项,想想怎样可以把后面排序的这个步骤省略掉?联合索引可以解决这个问题。
可以在 type, id 两列上建立一个联合索引,索引类型一般是 BTREE,根据Mysql索引的最左原则,可以知道一共建立了type_index和type_id_index两条索引,由于有了 type_id_index 这个联合索引,后面的排序步骤就可以省略了,在按照type = 5 条件挑选数据时,挂在type = 5 节点下的数据,其实按照id列的值也是有顺序的,我们只需要在挑选数据的同时,按照id从小到大的顺序挑选即可,最后得到的数据就是有序的,直接返回就行了,从这一点可以看出,“排序”操作并不是不存在了,只是隐含在了前面必要的步骤中,不需要单独操作了而已,下面举个简单例子,看看具体的效果。
总结
- 当Where 条件和 order by 子句作用在不同的列上,建立联合索引可以避免Using filesort的产生
- 针对当前的例子实际上删除掉type列和id列上的单独索引,只保留联合索引也是可以达到相同效果的
- 通过比较时间发现去掉了Using filesort情况,耗时少了一点点,实际操作中是不稳定的,但是平均时间可能会有一点提升
相关文章:
Using filesort)
MySQL系列三(定位慢SQL、SQL优化与索引优化)Using filesort
文章目录 1. 慢SQL1.1 定位慢SQL(慢查询日志)1.2 慢SQL优化整体思路 2. 索引优化3. SQL语句优化回表Using filesort 1. 慢SQL 1.1 定位慢SQL(慢查询日志) 在mysql 配置文件中 (my.conf),进行下面配置&…...
免费使用GPT-4.0?【AI聊天 | GPT4教学】 —— 微软 New Bing GPT4 申请与使用保姆级教程
目录 认识 New Bing 2. 注册并登录 Microsoft 账号 3. 如何免科学上网使用 New Bing? 4. 加入 WaitList 候补名单 5. 使用 New Bing! 6. 使用 Skype 免科学上网访问 New Bing! 7. 在 Chrome 浏览器中使用 New Bing! 8. 总…...

渲染对电脑伤害大吗_如何减少渲染伤机?
虽然说摄影穷三代,但想要自己的本地配置跟上自己的创作速度,高昂的硬件配置支出也可以让自己穷一段时间。CG制作过程中,渲染是必不可少的一步,而且这一步也是很吃“机器”的,那很多人也会担心,如果经常用自…...

非线性最小二乘
非线性最小二乘 目录 文章目录 非线性最小二乘目录 [toc]1 非线性最小二乘估计3 非线性最小二乘的实现 1 非线性最小二乘估计 在经典最小二乘法估计中,假定被解释变量的条件期望是关于参数的线性函数,例如 E ( y ∣ x ) a b x E(y|x) abx E(y∣x)a…...

23.5.7总结(学习通项目思路)
项目: 1.登录修改:删除数据库中的状态,通过使用 ConcurrentHashMap来作为是否在线的判断,通过设定一个退出的按钮,发消息给服务端主动移除对应的值。 2.注册:增加了手机号的填写,正则判断&…...

如何生成api接口获取宝贝商品详情,商品详情接口,产品详情
API (Application Programming Interface)是指应用程序接口,它是一种通过编写一组统一的规则,开发一个软件来与其他应用程序进行通讯的技术。API可以方便应用程序之间的交流和数据共享,以及增强应用程序的功能。 在现代应用程序中࿰…...
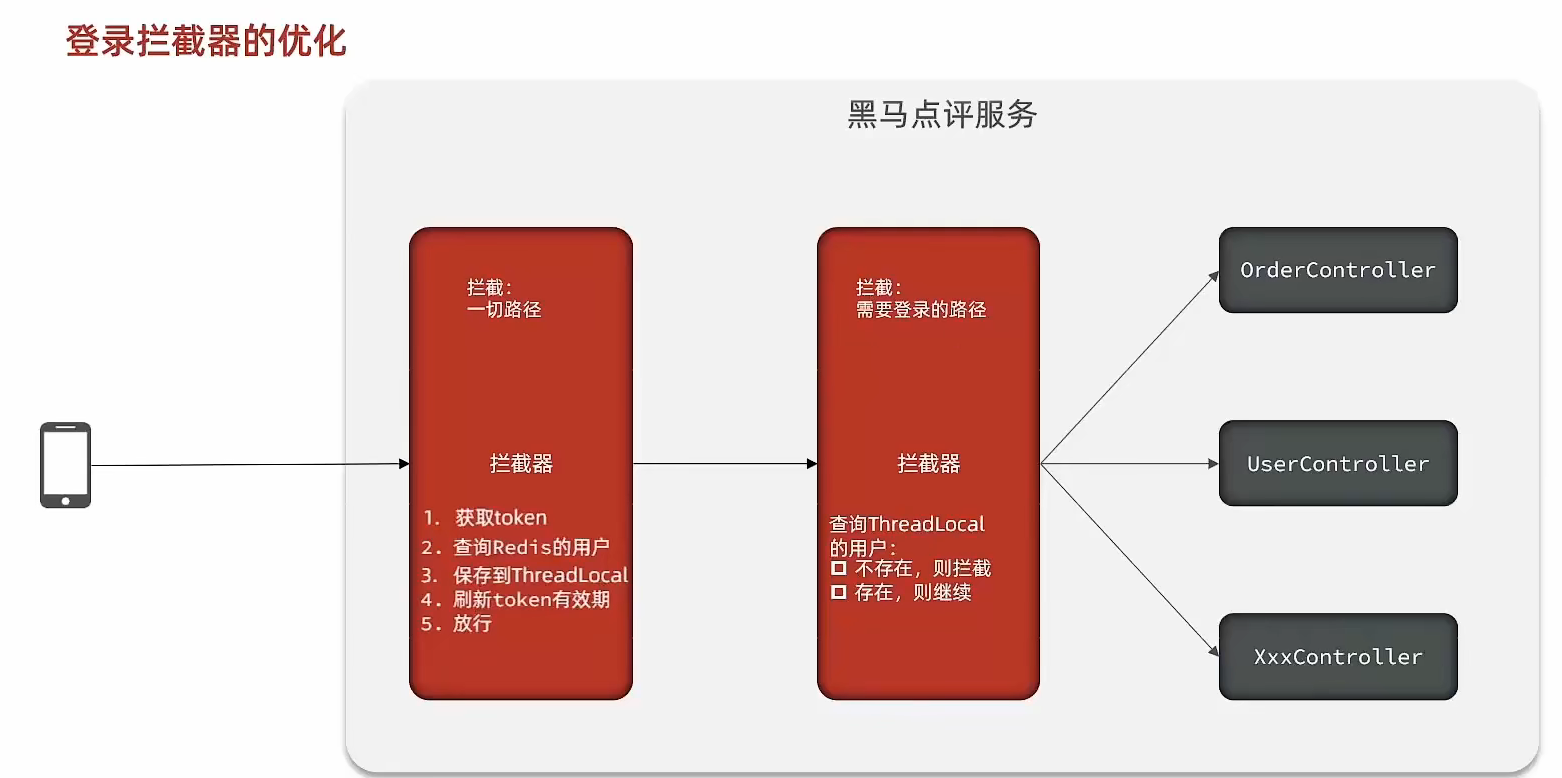
微服务---Redis实用篇-黑马头条项目-登录功能(短信验证缓存,用户信息缓存)
黑马头条项目-登录功能(短信验证缓存,用户信息缓存) 1、短信登录 1.1、导入黑马点评项目 1.1.1 、导入SQL 1.1.2、有关当前模型 手机或者app端发起请求,请求我们的nginx服务器,nginx基于七层模型走的事HTTP协议,可以实现基于Lua直接绕开t…...

美国纽扣电池的包装电池盒必须附带警告标签16 CFR 第 1700.20
美国纽扣电池及硬币电池的包装、电池盒必须附带警告标签16 CFR 第 1700.20 美国要求在纽扣电池或硬币电池的包装上、电池盒上以及包含纽扣电池或硬币电池的消费品附带说明和手册上贴上警告标签。 商品法规、标准和要求纽扣电池和硬币电池以下所有项: 16 CFR 第 17…...
AcWing——方格迷宫(有点不一样的迷宫问题)
4943. 方格迷宫 - AcWing题库 1、题目 给定一个 n 行 m 列的方格矩阵。 行从上到下依次编号为 1∼n,列从左到右依次编号为 1∼m。 第 i 行第 j 列的方格表示为 (i,j)。 矩阵中的方格要么是空地(用 . 表示),要么是陷阱…...

《常规脉搏传输时间作为人体血压变化标志》阅读笔记
目录 一、论文摘要 二、论文十问 Q1: 论文试图解决什么问题? Q2: 这是否是一个新的问题? Q3: 这篇文章要验证一个什么科学假设? Q4: 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员? …...

java学习之异常三
目录 一、throws 一、基本说明 二、使用细节 二、自定义异常 一、 基本概念 编辑二、自定义异常的步骤 三、实例 四、练习 三、throw和throws的区别 四、本章作业 第一道 第二题 第三题 第四题 一、throws 一、基本说明 package com.hspedu.throws_;import java.i…...

生产者向 Kafka 发送消息的执行流程
(1)生产者要往 Kafka 发送消息时,需要创建 ProducerRecoder,代码如下: ProducerRecord<String,String> record new ProducerRecoder<>("CostomerCountry","Precision Products","Fr…...

Linux命令·netstat
netstat命令用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。netstat是在内核中访问网络及相关信息的程序,它能提供TCP连接,TCP和UDP监听,进程内存管理的相关报告。 如果你的计算机有时候…...

《心安即是归处》读书笔记
目录 作者简介 经典摘录 一个人活在世界上,必须处理好三个关系 什么叫人生呢? 谈一下人性的问题 了解人生的意义与价值 人生之美 评断一本书的好与坏有什么标准呢? 知足知不足 作者简介 季羡林,随便查询一下作者简介&…...
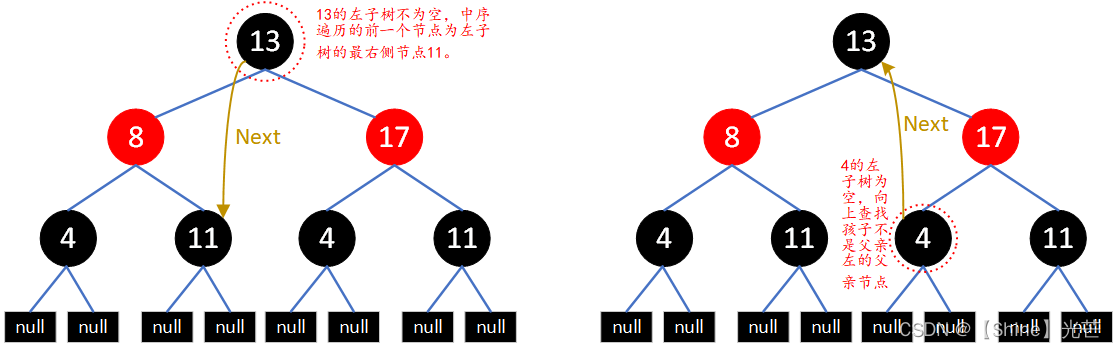
C++:使用红黑树封装map和set
目录 一. 如何使用一颗红黑树同时实现map和set 二. 红黑树的节点插入操作 三. 红黑树迭代器的实现 3.1 begin()和end() 3.2 operator和operator-- 3.3 红黑树迭代器实现完整版代码 四. map和set的封装 附录:用红黑树封装map和set完整版代码 1. RBTree.h文件…...

Go 命令
目录 文章目录 go buildgo cleango fmtgo getgo installgo testgo toolgo generategodoc其它命令 go build 这个命令主要用于编译代码。在包的编译过程中,若有必要,会同时编译与之相关联的包。 如果是普通包,就像我们在1.2节中编写的mymath包…...

LEO、HW、LSO、LW 分别代表什么?
LEO :是 LogEndOffset 的简称,代表当前日志文件中下一条。HW:水位或水印一词,也可称为高水位 (high watermark) ,通常被用在流式处理领域 (flink、spark) ,以表征元素…...
(二分答案))
问题 B: 跳石头(C++)(二分答案)
目录 1.题目描述 2.AC 1.题目描述 问题 B: 跳石头 时间限制: 1.000 Sec 内存限制: 128 MB提交 状态 题目描述 一年一度的“跳石头”比赛又要开始了! 这项比赛将在一条笔直的河道中进行,河道中分布着一些巨大岩石。组委会已经选择好了两块岩石作为比赛起点和终点。在起点…...

bugku——变量1
拿到题目后是一串PHP代码,给到提示是flag在变量中,接下来进行代码审计 error_reporting(0):关闭错误报告 include “flag1.php”:包含flag1.php文件 highlight_file(_file_):页面进行语法高亮显示 isset($_GET[‘args’])…...

网络数据包丢失监控
什么是网络数据包 数据包或网络数据包是通过网络传输的小数据单元。顾名思义,这些是小的、离散的数据单元。单独来看,这些单位不一定有多大意义。它们只是正在传输的整体消息的一部分,这些消息已被组装成多个层。但是,当组合在一…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...