深度学习-tensorflow 使用keras进行深度神经网络训练
概要
深度学习网络的训练可能会很慢、也可能无法收敛,本文介绍使用keras进行深度神经网络训练的加速技巧,包括解决梯度消失和爆炸问题的策略(参数初始化策略、激活函数策略、批量归一化、梯度裁剪)、重用预训练层方法、更快的优化器算法,以及使用正则化避免过拟合的算法。
目录
一、梯度消失或者梯度爆炸
解法方案一:权重参数初始化
解决方案二:非饱和激活函数
解决方案三:批量归一化(Batch Normalization)
解决方案四:梯度裁剪
二、重用预训练层
例子:使用Keras进行迁移学习
三、更快的优化器
1. 动量优化
原始Momentum算法
Nesterov加速梯度
2. 自适应学习率算法
3. 学习率调度
四、通过正则化避免过拟合
L1和L2正则化
Dropout
最大范数正则化
五、实用指南
一、梯度消失或者梯度爆炸
梯度向下传播到较低层是,梯度通常会越来越小,结果是提督下降的更新导致较低层连接权重不变,训练不能收敛到一个良好的解,称为梯度消失;相反的情况是提督越来越大,各层需要更新很大的权重,直到算法发散,称为梯度爆炸。
梯度消失或者梯度爆炸是2000年代初期深度神经网络被抛弃的原因之一。
解法方案一:权重参数初始化
理论:每层大输出方差等于输入方差;反方向流经某层的之前和之后的梯度具有相同的方差,实际上很难满足,只能采取折中方案
主要有3种初始化策略:Xavier初始化或Glorot初始化、LeCun初始化、He初始化

默认情况下,Keras使用均匀分布的Xavier初始化,通过kernel_initializer进行设置
keras.layers.Dense(10, activation="relu", kernel_initializer="he_normal")解决方案二:非饱和激活函数
sigmoid函数存在饱和区,容易导致梯度消失问题
ReLU函数通常比sigmoid函数表现要好,但在输入小于0时,梯度是0,输出一直是0,导致这些神经元“死亡”了,严重的情况可能出现一般的神经元“死亡”。
ReLU变体LeakyReLU,在输入小于0时,为一个小斜率直线,LeakyReLU=max(az,z)。
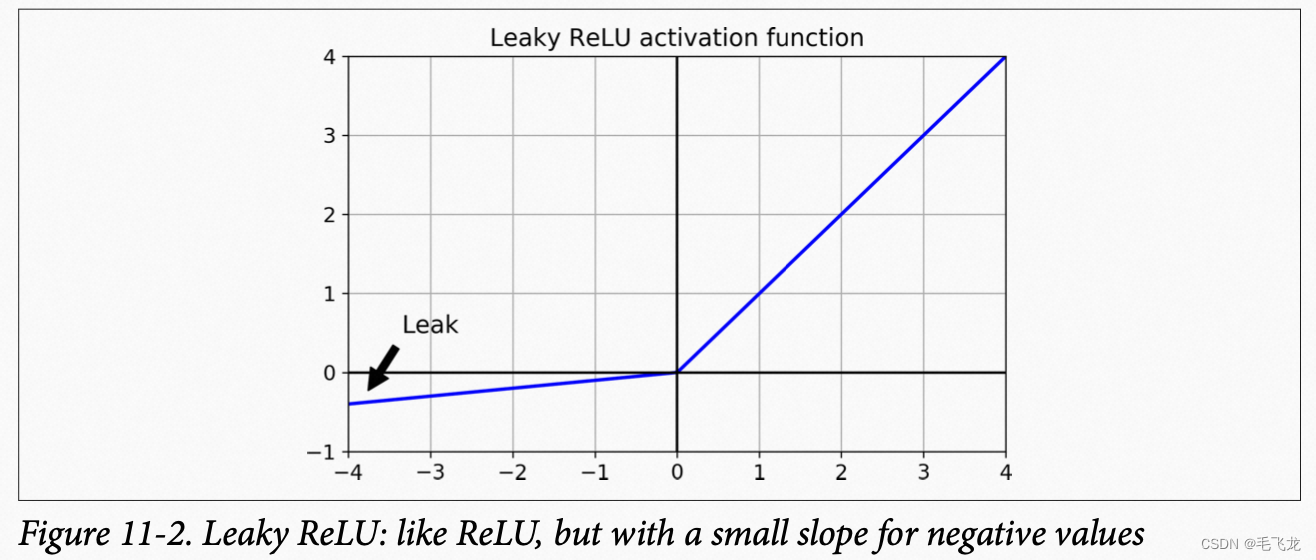
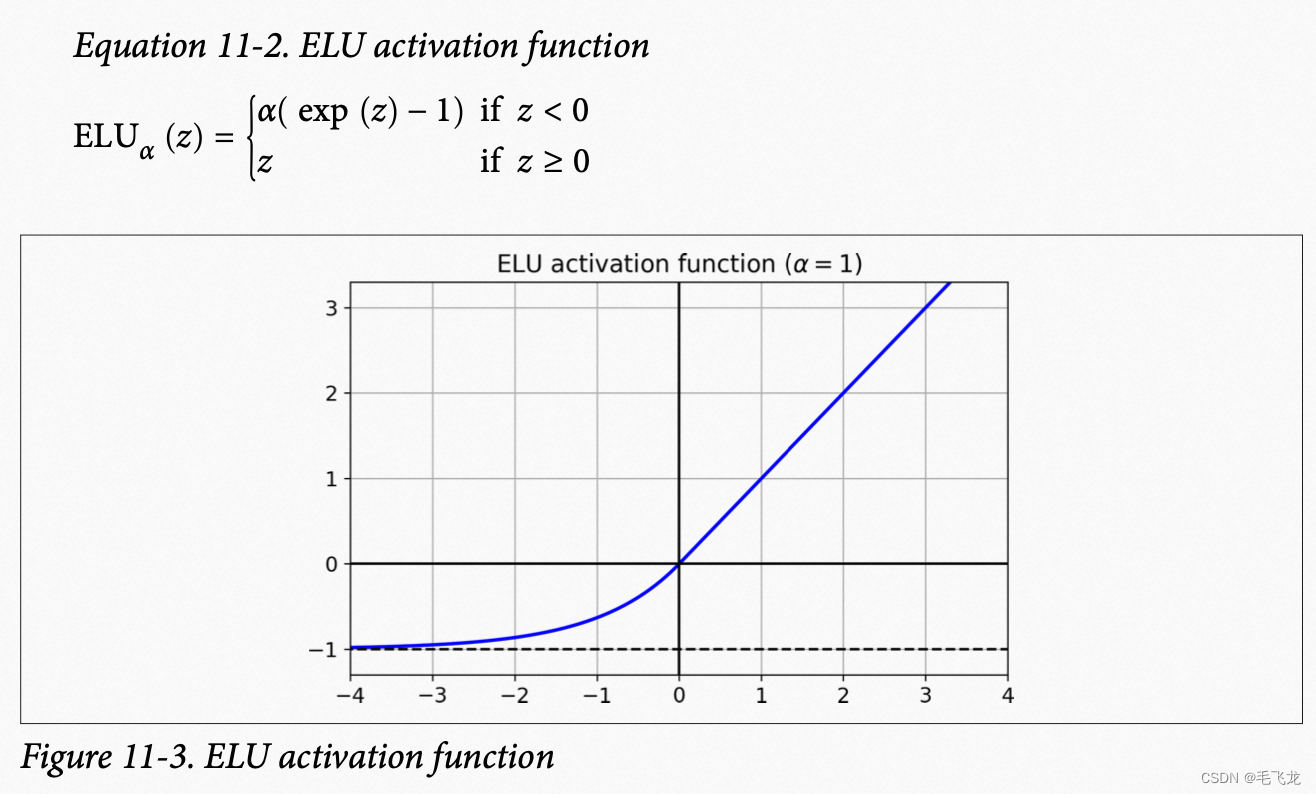
ReLU函数变体 ELU(Exponential Linear Unit,指数线型单位)
SELU(Scaled ELU)为ELU的变体,即加入一个参数lamda,使得使用该激活函数,网络时自动归一化的 :
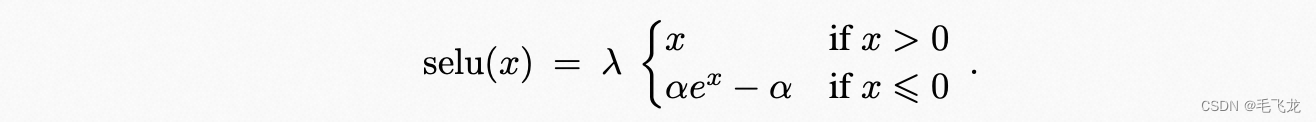
相比ReLU函数,ELU的主要问题是计算速度较慢
解决方案三:批量归一化(Batch Normalization)
尽管权重参数初始化策略和激活函数策略可以缓解梯度消失和爆炸问题,但仍然会出现,这个时候,通过BN可以减少这个问题,且使得可以使用饱和激活函数。
BN层对于浅层网络可能效果不明显,但对于深层网络非常有用


解决方案四:梯度裁剪
对于梯度在反向传播期间设定一个阈值,使得梯度不超过该阈值,称为梯度裁剪,可缓解梯度爆炸问题,通常用在RNN中,原因是RNN中难以使用BN。
实现方法为在创建优化器是设置clipvalue或者clipnorm。
optimizer = keras.optimizers.SGD(clipvalue=1.0) model.compile(loss="mse", optimizer=optimizer)上述代码将限制所有的梯度再-1到1之间,这种设置可能会改变梯度的方向,比如原始梯度向量为[0.9,100.0],梯度主要指向第二个轴方向,按梯度裁剪后,得到[0.9,1.0],基本指向两个轴对角线。要想不改变梯度方向,则应该使用clipnorm进行裁剪,比如clipnorm=1.0,则得到梯度向量为[0.009,0.999]
二、重用预训练层
从头开始训练非常大的DNN通常不是一个好的主意,试图找到一个与现有问题类似的神经网络,然后用该网络的较低层,此技术称为迁移学习。它能够大大的加快训练速度,减少对训练数据的要求。
假设你可以访问一个经过训练的DNN,将图片分为100个不同类别,其中包括动物、植物和车辆。现在需要训练DNN来对特质类型的车辆进行分类,这些任务非常相似,因此应该尝试利用第一个网络中的一部分。
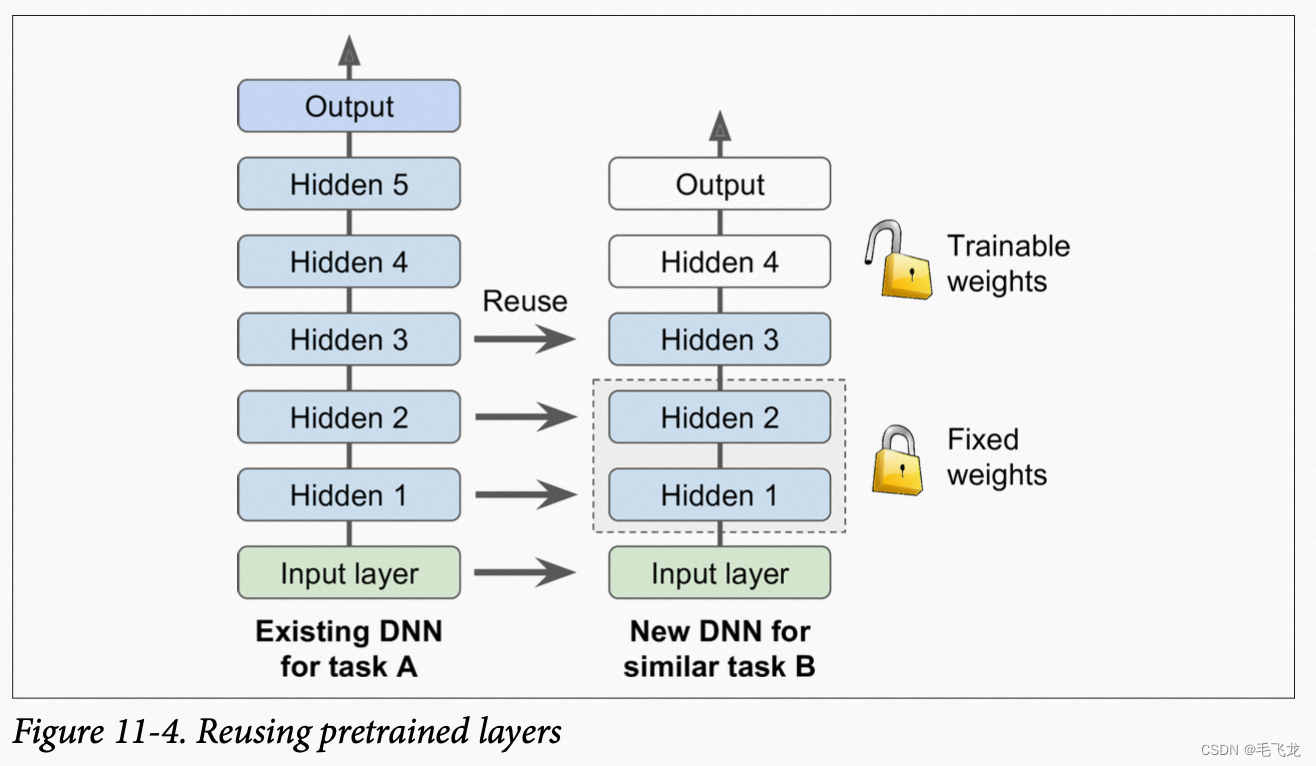
通常应该替换掉原始模型的输出层而保留较底层,因为对于新的任务有用的高级特征可能与原始任务存在很大的区别,甚至对于新的任务,没有正确数量的输出,任务约相似,保留的隐藏层就越多。
例子:使用Keras进行迁移学习
假设Fashion MNIST数据集仅仅包括8个类别(除了凉鞋和衬衫之外的所有类别),有人在该数据集上训练了Keras模型,并且获得了相当不错的性能(精度>90%),我们称此模型为A。
现在需要处理另外一项任务,要训练一个二分类器(正例=衬衫,负例=凉鞋),但数据集非常小,只有200张图片。你意识到新任务和任务A非常相似,也许可以通过迁移学习会有所帮助,让我们看看该怎么做。
首先,我们需要加载模型A并基于该模型层创建一个新模型,我们重用除输出层之外的所有层。
# 对模型A进行克隆,这样在训练模型B_on_A的时候,不回对模型的参数进行修改
model_A_clone = keras.models.clone_model(model_A)
model_A_clone.set_weights(model_A.get_weights())model_B_on_A = keras.models.Sequential(model_A_clone.layers[:-1]) # 去除模型A的输出层
model_B_on_A.add(keras.layers.Dense(1, activation="sigmoid")) # 增加新模型的输出层# 由于新的输出层是随机初始化的,在最初的几个轮次中会产生较大的错误,存在较大的错误梯度,这会破坏重用的权重。为避免这种情况,在前几个轮次的训练时,冻结重用层,给新层一些时间来学习合理权重,为此将重用层的训练属性设置为False。for layer in model_B_on_A.layers[:-1]: layer.trainable = Falsemodel_B_on_A.compile(loss="binary_crossentropy",optimizer=keras.optimizers.SGD(learning_rate=1e-3),metrics=["accuracy"])history = model_B_on_A.fit(X_train_B, y_train_B, epochs=4,validation_data=(X_valid_B, y_valid_B))# 几轮训练后,可以对重用层进行解冻,参数可以更新for layer in model_B_on_A.layers[:-1]:layer.trainable = Truemodel_B_on_A.compile(loss="binary_crossentropy",optimizer=keras.optimizers.SGD(learning_rate=1e-3),metrics=["accuracy"])
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=16,validation_data=(X_valid_B, y_valid_B))三、更快的优化器
训练一个非常大的神经网络可能会非常缓慢,前面已经知道了五种加速训练的方法:
- 权重参数初始化
- 使用良好的激活函数
- 批量归一化
- 梯度裁剪
- 重用预训练网络中的一部分
与常规的梯度下降相比,使用更快的有花期也可以带来巨大的速度提升,包括动量优化算法:原始动量优化和Nesterov加速梯度,以及自适应学习率优化:AdaGrad、RMSProp、Adam、Nadam。
1. 动量优化
参考这两篇文章:机器学习 | 优化——动量优化法(更新方向优化) - 简书
优化算法Optimizer比较和总结 - 知乎
momentum算法思想:权重参数更新时在一定程度上保留之前更新的方向,同时又利用当前batch的梯度微调最终的更新方向,简言之就是通过积累之前的动量来加速当前的梯度。
原始Momentum算法
下面一张图可以很直观地表达Momentum算法的思想。举个简单例子,假设上次更新时梯度是往前走的,这次更新的梯度算出来是往左走,这变化太剧烈了,所以我们来做个折中,往左前方走。感觉上,像是上次更新还带有一定的惯性。

具体算法如下:

Momentum算法的优点:
当某个参数在最近一段时间内的梯度方向不一致时,其真实的参数更新幅度变小;相反,当在最近一段时间内的梯度方向都一致时,其真实的参数更新幅度变大,起到加速作用。
一般而言,在迭代初期,梯度方向都比较一致,动量法会起到加速作用,可以更快地到达最优点。在迭代后期,梯度方向会取决不一致,在收敛值附近震荡,动量法会起到减速作用,增加稳定性。从某种角度来说,当前梯度叠加上部分的上次梯度,一定程度上可以近似看作二阶梯度。
——参考:邱锡鹏:《神经网络与深度学习》
Nesterov加速梯度
Nesterov 加速梯度(Nesterov Accelerated Gradient,NAG),也叫 Nesterov 动量法(Nesterov Momentum),是对Momentum算法的一种改进,可以看成是Momentum算法的一种 变体。
动量法每下降一步都是由前面下降方向的一个累积和当前点的梯度方向组合而成。于是一位大神(Nesterov)就开始思考,既然每一步都要将两个梯度方向(历史梯度、当前梯度)做一个合并再下降,那为什么不先按照历史梯度往前走那么一小步,按照前面一小步位置的“超前梯度”来做梯度合并呢?
如此一来,小球就可以先不管三七二十一先往前走一步,在靠前一点的位置看到梯度,然后按照那个位置再来修正这一步的梯度方向。
2. 自适应学习率算法
学习率是一个非常重要的超参数,但是学习率是非常难确定的,虽然可以通过多次训练来确定合适的学习率,但是一般也不太确定多少次训练能够得到最优的学习率,玄学事件,对人为的经验要求比较高,所以是否存在一些策略自适应地调节学习率的大小,从而提高训练速度。 目前的自适应学习率优化算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法。
AdaGrad(Adaptive Gradient)算法:梯度更新时,要除以“梯度的累积平方和根”,因此梯度前期更新较快,中后期,分母上梯度累加的平方和会越来越大,使得参数更新量趋近于0,使得训练提前结束。
RMSProp(Root Mean Square Propagation)算法:梯度更新时,“梯度的累积平方和根”会进行衰减,最近一步“梯度平方和根”有一定权重。
Adam(Adaptive Moment estimation) 算法:结合了动量优化和RMSProp思想,像动量优化一样,跟踪梯度指数衰减,像RMSProp一样,关注梯度平方和根的衰减。

3. 学习率调度
一般可以先设置较大的学习率,然后逐步降低学习率,以使得模型快速收敛。主要有幂调度、指数调度、分段恒定调度、性能调度、周期调度几种方法。
幂调度:将学习率设置为lr = lr0 / (1 + steps / s)**c(,Keras uses )
c=1,经过s个步骤之后,学习率下降为原来的1/2,在keras实现幂调度非常简单
initial_learning_rate = 0.1
decay_steps = 10.0
decay_rate = 0.5
learning_rate_fn = keras.optimizers.schedules.InverseTimeDecay(initial_learning_rate, decay_steps, decay_rate)
optimizer = tf.keras.optimizers.SGD(learning_rate = learning_rate_fn)指数调度:
分段恒定调度:对于一定的轮次使用一个固定的学习率,比如前5个轮次使用0.1,6-20轮次使用0.05,21轮次以后使用0.01,以此类推。可以使用keras.optimizers.schedules.PiecewiseConstantDecay
step = tf.Variable(0, trainable=False)
boundaries = [5, 20]
values = [0.1, 0.05, 0.1]
learning_rate_fn = keras.optimizers.schedules.PiecewiseConstantDecay(boundaries, values)# Later, whenever we perform an optimization step, we pass in the step.
learning_rate = learning_rate_fn(step)性能调度:每N步测量一次验证误差,并且当误差停止下降时,讲学习率降低lamda倍。
四、通过正则化避免过拟合
L1和L2正则化
keras可以使用keras.regularizers.l1()、keras.regularizers.l2()、keras.regularizers.l1-l2()来分别实现l1、l2、以及l1+l2正则化。
model = keras.models.Sequential([keras.layers.Flatten(input_shape=[28, 28]),keras.layers.Dense(300, activation="elu",kernel_initializer="he_normal",kernel_regularizer=keras.regularizers.l2(0.01)),keras.layers.Dense(100, activation="elu",kernel_initializer="he_normal",kernel_regularizer=keras.regularizers.l2(0.01)),keras.layers.Dense(10, activation="softmax",kernel_regularizer=keras.regularizers.l2(0.01))
])由于通常需要将相同的正则化应用于网络中的所有层,上述方法重复了相同的参数切容易出错,可以考虑使用python 的functools.partial()函数
from functools import partialRegularizedDense = partial(keras.layers.Dense,activation="elu",kernel_initializer="he_normal",kernel_regularizer=keras.regularizers.l2(0.01))model = keras.models.Sequential([keras.layers.Flatten(input_shape=[28, 28]),RegularizedDense(300),RegularizedDense(100),RegularizedDense(10, activation="softmax")
])Dropout
对深度学习,dropout是最受欢迎的正则化技术之一,由Geoffrey Hinton在2012年提出。在每个训练步骤中,每个神经元(不包括输出神经元)都有暂时被“删除”的概率p,但在下一步骤中可能处于激活状态,超参数p称为dropout率,一般设置为10%到50%。dropout只能用于训练,不会用于预测,因此在悬链完后,我们需要将每个输入权重乘以保留概率1-p。
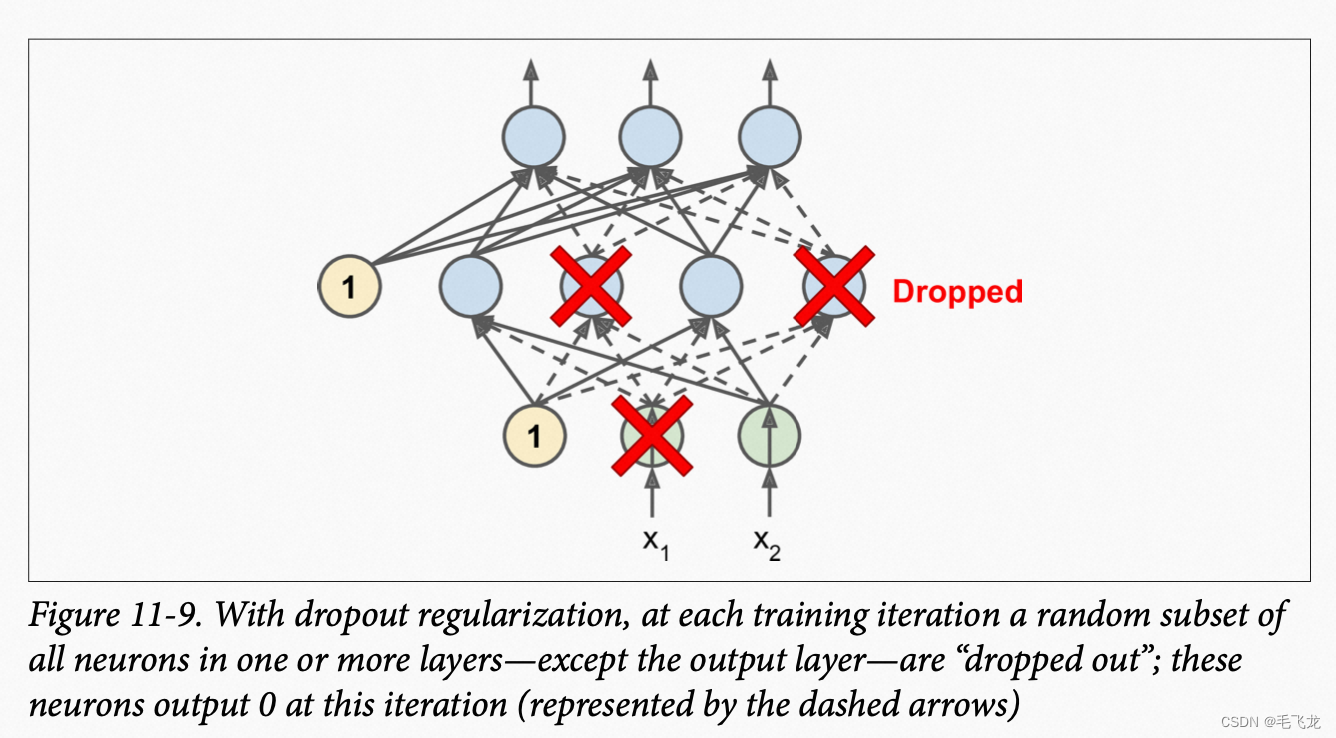
model = keras.models.Sequential([keras.layers.Flatten(input_shape=[28, 28]),keras.layers.Dropout(rate=0.2),keras.layers.Dense(300, activation="elu", kernel_initializer="he_normal"),keras.layers.Dropout(rate=0.2),keras.layers.Dense(100, activation="elu", kernel_initializer="he_normal"),keras.layers.Dropout(rate=0.2),keras.layers.Dense(10, activation="softmax")
])
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam", metrics=["accuracy"])
n_epochs = 2
history = model.fit(X_train_scaled, y_train, epochs=n_epochs,validation_data=(X_valid_scaled, y_valid))最大范数正则化
对每个神经元,限制传入链接的权重W,使得, r称为最大范数超参数。最大范数正则化不会正则化损失添加到总体损失中,而是在每个训练步骤后,计算
,如果大于r,则进行缩放。
五、实用指南
默认DNN超参数配置

如果网络时密集层的简单堆叠,可以使用自归一化,可以使用下表的参数配置
自归一化网络的DNN配置

相关文章:
深度学习-tensorflow 使用keras进行深度神经网络训练
概要 深度学习网络的训练可能会很慢、也可能无法收敛,本文介绍使用keras进行深度神经网络训练的加速技巧,包括解决梯度消失和爆炸问题的策略(参数初始化策略、激活函数策略、批量归一化、梯度裁剪)、重用预训练层方法、更快的优化…...

【NLP开发】Python实现聊天机器人(ChatterBot,集成前端页面)
🍺NLP开发系列相关文章编写如下🍺: 🎈【NLP开发】Python实现词云图🎈🎈【NLP开发】Python实现图片文字识别🎈🎈【NLP开发】Python实现中文、英文分词🎈🎈【N…...
Python 操作 Excel,如何又快又好?
➤数据处理是 Python 的一大应用场景,而 Excel 则是最流行的数据处理软件。因此用 Python 进行数据相关的工作时,难免要和 Excel 打交道。Python处理Excel 常用的系列库有:xlrd、xlwt、xlutils、openpyxl ◈xlrd - 用于读取 Exce…...
Spring Redis 启用TLS配置支持(踩坑解决)
由于线上Redis要启用TLS,搜遍了google百度也没一个标准的解决方案,要不这个方法没有,要不那个类找不到...要不就是配置了还是一直连不上redis.... 本文基于 spring-data-redis-2.1.9.RELEASE 版本来提供一个解决方案: 1.运维那边提供过来三个文件,分别是redis.crt redis.key …...

centOS7忘记登录密码该如何重新修改登录密码
文章目录 前言一、重新修改登录密码1.1、第一步1.2、第二步1.3、第三步1.4、第四步1.5、第五步1.6、第六步1.7、第七步1.8、第八步 前言 忘记密码并不可怕,只要学会方法,密码随时都可以找回。 一、重新修改登录密码 1.1、第一步 当打开centOS7之后忘记…...

揭开基于 AI 的推荐系统的神秘面纱:深入分析
人工智能 (AI) 以多种方式渗透到我们的生活中,使日常任务更轻松、更高效、更个性化。人工智能最重要的应用之一是推荐系统,它已成为我们数字体验不可或缺的一部分。从在流媒体平台上推荐电影到在电子商务网站上推荐产品࿰…...

MySQL的事务特性、事务特性保证和事务隔离级别
事务是指要么所有的操作都成功执行,要么所有的操作都不执行的一组数据库操作。 一、MySQL提供了四个事务特性,即ACID: 1. 原子性(Atomicity):一个事务中的所有操作要么全部提交成功,要么全部回…...
shell脚本----函数
文章目录 一、函数的定义1.1 shell函数:1.2函数如何定义 二、函数的返回值三、函数的传参四、函数变量的作用范围五、函数的递归六、函数库 一、函数的定义 1.1 shell函数: 使用函数可以避免代码重复使用函数可以将大的工程分割为若干小的功能模块,代码的可读性更…...

( 位运算 ) 693. 交替位二进制数 ——【Leetcode每日一题】
❓693. 交替位二进制数 难度:简单 给定一个正整数,检查它的二进制表示是否总是 0、1 交替出现:换句话说,就是二进制表示中相邻两位的数字永不相同。 示例 1: 输入:n 5 输出:true 解释&#…...

http简述
HTTP(Hypertext Transfer Protocol)是一种用于在Web上传输数据的协议。它是Web的基础,使得我们能够在互联网上访问和共享信息。本文将介绍HTTP的基本概念、工作原理、请求和响应、状态码、安全性和未来发展等方面。 一、HTTP的基本概念 HTT…...

一顿饭的事儿,搞懂了Linux5种IO模型
大家好,我是老三,人生有三大难题,事业、爱情,和 ——这顿吃什么! 人在家中躺,肚子饿得响,又到了不得不吃的时候,这顿饭该怎么吃?吃什么呢? Linux里有五种I…...

C#面向对象的概念
C#面向对象的概念 C#是一种面向对象的编程语言,面向对象编程的核心是将程序中的数据和操作封装在一个对象中。下面是一些面向对象的概念: 类(Class):类是用来描述一类对象的属性和方法的模板或蓝图,它定义…...

探索学习和入门使用GitHub Copilot:提升代码开发的新利器
目录 引言1. 什么是GitHub Copilot?2. 入门使用GitHub Copilot3. GitHub Copilot的基础知识4. GitHub Copilot的应用场景结论 在最近的开发工作中,发现了一个比较实用的工具,github copilot,这是一款基于人工智能的代码助手工具&a…...
在字节跳动做了6年软件测试,4月无情被辞,想给划水的兄弟提个醒
先简单交代一下背景吧,某不知名 985 的本硕,17 年毕业加入字节,以“人员优化”的名义无情被裁员,之后跳槽到了有赞,一直从事软件测试的工作。之前没有实习经历,算是6年的工作经验吧。 这6年之间完成了一次…...
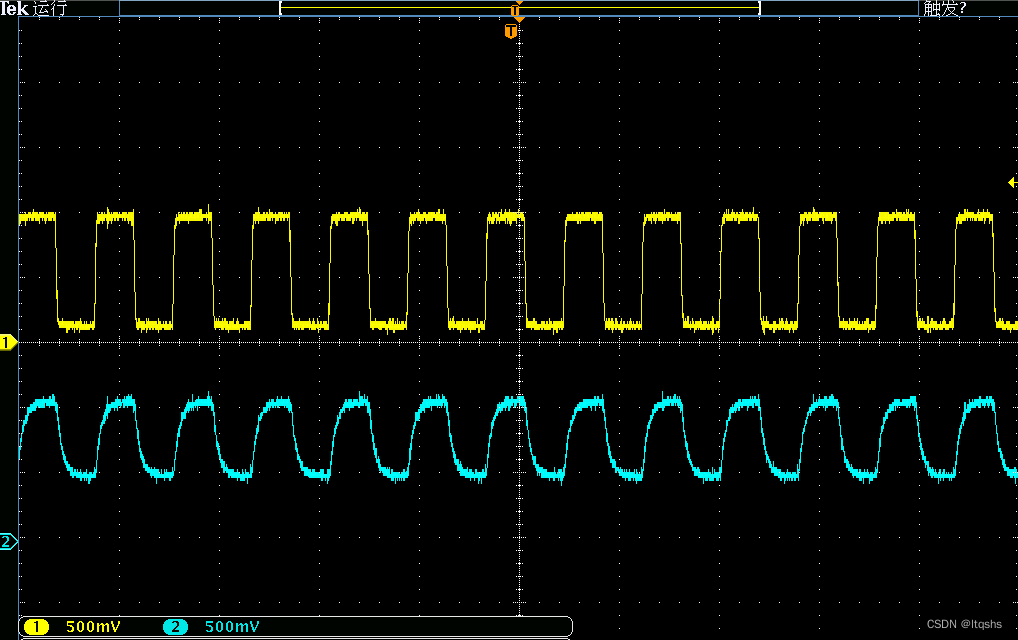
常见信号质量问题、危害及其解决方法-信号完整性-过冲、噪声、回勾、边沿缓慢
概述 在电路设计中,“信号”始终是工程师无法绕开的一个知识点。不管是在设计之初,还是在测试环节中,信号质量问题都值得关注。在本文中,主要介绍信号相关的四类问题:信号过冲、毛刺(噪声)、回…...

Java 自定义注解及使用
目录 一、自定义注解1.使用 interface 来定义你的注解2.使用 Retention 注解来声明自定义注解的生命周期3.使用 Target 注解来声明注解的使用范围4.添加注解的属性 二、使用自定义的注解1.将注解注在其允许的使用范围2.使用反射获取类成员变量上的所有注解3.反射获取成员变量上…...
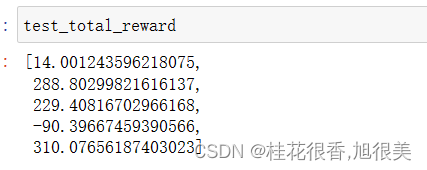
ChatGPT的强化学习部分介绍——PPO算法实战LunarLander-v2
PPO算法 近线策略优化算法(Proximal Policy Optimization Algorithms) 即属于AC框架下的算法,在采样策略梯度算法训练方法的同时,重复利用历史采样的数据进行网络参数更新,提升了策略梯度方法的学习效率。 PPO重要的突…...

JavaWeb ( 八 ) 过滤器与监听器
2.6.过滤器 Filter Filter过滤器能够对匹配的请求到达目标之前或返回响应之后增加一些处理代码 常用来做 全局转码 ,session有效性判断 2.6.1.过滤器声明 在 web.xml 中声明Filter的匹配过滤特征及对应的类路径 , 3.0版本后可以在类上使用 WebFilter 注解来声明 filter-cla…...
Notion Ai中文指令使用技巧
Notion AI 是一种智能技术,可以自动处理大量数据,并从中提取有用的信息。它能够 智能搜索:通过搜索文本和查询结果进行快速访问 自动归档:可以根据关键字和日期自动将内容归档 内容分类:可以根据内容的标签和内容的…...
Linux一学就会——编写自己的shell
编写自己的shell 进程程序替换 替换原理 用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数 以执行另一个程序。当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动 例程开始执行…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...