深入理解mysql的内核查询成本计算
MySql系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】深入理解mysql索引本质 | https://blog.csdn.net/zhenghuishengq/article/details/121027025 |
| 【二】深入理解mysql索引优化以及explain关键字 | https://blog.csdn.net/zhenghuishengq/article/details/124552080 |
| 【三】深入理解mysql的索引分类,覆盖索引(失效),回表,MRR | https://blog.csdn.net/zhenghuishengq/article/details/128273593 |
| 【四】深入理解mysql事务本质 | https://blog.csdn.net/zhenghuishengq/article/details/127753772 |
| 【五】深入理解mvcc机制 | https://blog.csdn.net/zhenghuishengq/article/details/127889365 |
| 【六】深入理解mysql的内核查询成本计算 | https://blog.csdn.net/zhenghuishengq/article/details/128820477 |
| 【七】深入理解mysql性能优化以及解决慢查询问题 | https://blog.csdn.net/zhenghuishengq/article/details/128854433 |
| 【八】深入理解innodb和buffer pool底层结构和原理 | https://blog.csdn.net/zhenghuishengq/article/details/128993871 |
| 【九】深入理解mysql执行的底层机制 | https://blog.csdn.net/zhenghuishengq/article/details/128100377 |
| 【十】深入理解mysql集群的高可用机制 | https://blog.csdn.net/zhenghuishengq/article/details/126239652 |
深入理解mysql的内核查询成本计算
- 一,mysql的内核查询成本
- 1,mysql单表查询成本计算
- 1.1,建表
- 1.2,Optimizer Trace
- 1.3,单表成本优化思路
- 1.3.1,找出所有可能使用到的索引
- 1.3.2,计算全表扫描的代价
- 1.3.3,分别计算其他索引的查询代价
- 1.3.4,对比全部扫描的代价和其他单个索引的代价
- 2,in查询内核成本分析
- 3,连接查询成本计算
一,mysql的内核查询成本
1,mysql单表查询成本计算
在mysql中,无论是innodb存储引擎还是MyIsam存储引擎,主要是由两种时间成本组成,分别是io成本 和 CPU成本 。io成本就是数据从磁盘加载到内存时,需要花费的时间成本;cpu成本就是需要去判定里面的where语句,或者其他的范围查询,in查询等是否符合要求所需要的时间成本。
在mysql中,IO成本默认需要花费1个单位的成本,CPU成本默认需要花费0.2个单位成本(不管是否存在需要过滤的条件)。因此在计算一个成本时,其基本公式如下,然后mysql内部会考虑一些微调值,这里暂不考虑。
T(i/o) : 总页数 * 1.0
T(cpu) : 总条数 * 0.2
T(总) = T(i/o) + T(cpu)
这些都是默认值,mysql也可以对这些值进行调整。这里的1个单位指的是:innodb存储引擎读取一页数据所花费的时间
1.1,建表
接下来新建一张订单表,其各个字段如下
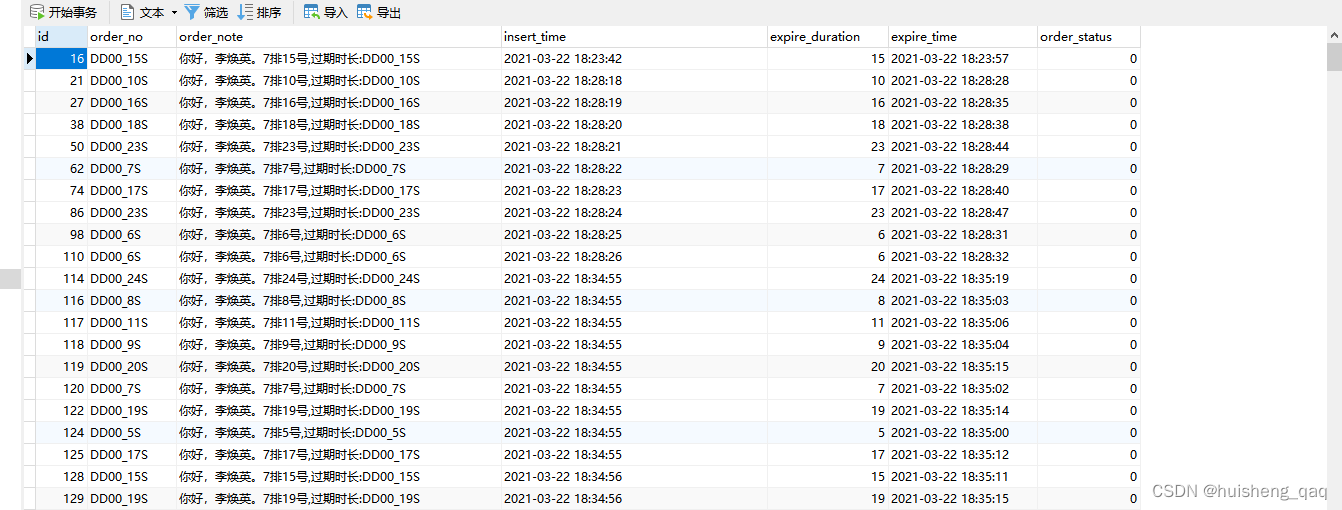
CREATE TABLE `order_exp` (`id` bigint(22) NOT NULL AUTO_INCREMENT COMMENT '订单的主键',`order_no` varchar(50) NOT NULL COMMENT '订单的编号',`order_note` varchar(100) NOT NULL COMMENT '订单的说明',`insert_time` datetime(0) NOT NULL COMMENT '插入订单的时间',`expire_duration` bigint(22) NOT NULL COMMENT '订单的过期时长,单位秒',`expire_time` datetime(0) NOT NULL COMMENT '订单的过期时间',`order_status` smallint(6) NOT NULL DEFAULT 0 COMMENT '订单的状态,0:未支付;1:已支付;-1:已过期,关闭',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 10819 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
需要里面的表结构以及数据的话,可以直接在百度网盘下载即可,提取码为1234:https://pan.baidu.com/s/12Py6QwzlZ7CXGuwNKp_bsA
接下来分析下面这句简单的sql语句
SELECT * FROM order_exp WHERE order_no IN ('DD00_6S', 'DD00_9S', 'DD00_10S') AND expire_time> '2021-03-22 18:28:28' AND expire_time<= '2021-03-22 18:35:09' AND insert_time> expire_time AND order_note LIKE '%7排1%' AND order_status = 0;
因此通过分析可知,可以给order_no字段添加一个索引,expire_time字段添加一个索引,这两个字段都缩小了范围,符合之前所说的一星索引;而这个like由于%在前面,根据B+树的原则,like添加索引的话会失效,因此order_note字段不添加索引;order_status这个字段只有0,1和 -1,离散性太低,肯定不走索引,因此也不添加索引;这个insert_time由于和这个expire_time都是变量,而索引是一个变量跟常量进行比较的,因此这里肯定也不走索引,因此不在这个字段上加索引。
alter table order_exp add index idx_order_no (order_no);
alter table idx_expire_time add index idx_expire_time (expire_time);
可以通过以下命令来查看当前表中存在的所有索引
show keys from order_exp;
1.2,Optimizer Trace
在获取底层如何是优化这个sql语句之前,需要先了解一个工具,就是这个 Optimizer Trace 。可以通过开启这个 Optimizer Trace 指令,来查看底层优化器的执行过程,可以查看mysql是如何选择的最佳的优化路线的。Trace工具可以从细节上分析MySQL是如何选择索引。
其开启的命令如下
SET optimizer_trace="enabled=on";
开启完之后,就可以输入需要查询的sql语句,再输入具体需要查询的sql语句,如下
SELECT * FROM order_exp WHERE order_no IN ('DD00_6S', 'DD00_9S', 'DD00_10S') AND expire_time> '2021-03-22 18:28:28' AND expire_time<= '2021-03-22 18:35:09' AND insert_time> expire_time AND order_note LIKE '%7排1%' AND order_status = 0;
可以再通过输入以下的命令,就可以看到底层分析的过程以及结果了。
SELECT * FROM information_schema.OPTIMIZER_TRACE\G
最后就可以出现一下的一大堆东西的界面,有了这个结果之后,就可以通过上面的结果来验证,innodb底层的这个成本优化思路了。
1.3,单表成本优化思路
基于成本的优化步骤主要由四个步骤组成。一是根据搜索条件,找出所有可能使用到的索引;二是先计算全表扫描的代价;三是使用不同索引执行查询的代价;四是对比各种执行的方案代价,找出成本最低的那个
1.3.1,找出所有可能使用到的索引
一条sql语句中找出全部可能使用到的索引,主要是使用关键字 explain ,在查询的sql语句之前加上explain这个关键字即可分析出可能会使用哪些索引
explain SELECT * FROM order_exp WHERE order_no IN ('DD00_6S', 'DD00_9S', 'DD00_10S') AND expire_time> '2021-03-22 18:28:28' AND expire_time<= '2021-03-22 18:35:09' AND insert_time> expire_time AND order_note LIKE '%7排1%' AND order_status = 0;
其具体分析结果如下,type类型是range的范围查询,然后可能使用到的key就是建立的那两个索引。

1.3.2,计算全表扫描的代价
接下来就是先计算这个全表扫描的代价。全表扫描就是直接扫描聚簇索引的叶子结点,由于所有的数据都在聚簇索引的叶子结点上,因此就会通过这个遍历上面的每一个结点,然后对每一个结点进行匹配,看是否满足这个全部的要求
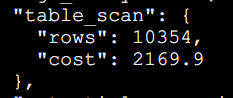
接下来就通过这个Optimizer Trace 工具获取到的里面的数据分析(上面已打开),然后找到全表扫描所花费的这个单位。如下,全表扫描大概10354行,并且通过这个Trace工具得知的,大概需要花费2169.9个页单位。
由于这里计算的是全表扫描,那么就需要知道总行数以及总页数,因此可以使用下面这个命令
SHOW TABLE STATUS LIKE 'order_exp'\G
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vnB1kKLN-1675155949965)(img/1672906699366.png)]](https://img-blog.csdnimg.cn/37c842c48bd7476883b6e38a3695ae12.png)
其结果如上图,从图中可知 data_length 的长度为 1589248,因此可以得知总页数为97,这个长度就是数据的总字节数。
1589248 ÷ 16 ÷ 1024 = 97
总条数为Rows 10343,因此可以利用这个成本计算的公式,这里会涉及到一个微调数,这里的微调数是mysql底层的硬编码,因此是必加的。因此和上面的这个全表扫描的成本对上了。
T(I/O) : 97 * 1.0 + 1.1(微调数) = 98.1
T(CPU) : 10354 * 0.2 + 1.0(微调数) = 2071.8
T(总) = T(I/O) + T(CPU) = 2169.9
1.3.3,分别计算其他索引的查询代价
在使用完主键索引之后,那么就会计算二级索引的代价,唯一索引会优先普通索引。接下来可以先查看这个 order_note 列所对应的索引,这个索引是一个普通索引。
order_note 索引
由于这个 order_note 字段总涉及到三个范围,那么在二级索引查询时,需要查询三次,那么只需要三次IO,由于在使用该字段时查询的结果只有58行,那么需要进行58次的cpu的判断;最后涉及到回表,在聚簇索引中也要花费一定的时间,则整体成本代价如下
T(I/O二级索引) : 3 * 1.0 = 3
T(I/O回表) : 58 * 1.0 = 58
T(CPU) : 58 * 0.2 + 0.01(微调数) = 11.61
T(CPU回表) : 58 * 0.2 = 11.6
T(总) = T(I/O二级索引) + T(I/O回表) + T(CPU) + T(CPU回表) = 84.21
如下图可知这个cost花费的成本是84.21,那是因为在mysql内部,将这个回表时的CPU所花费的这个时间成本给省去了,如果84.21 - 11.6 ,那么刚好就是这个72.61这个值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dvpxjVLQ-1675155949966)(img/1675128067751.png)]](https://img-blog.csdnimg.cn/0fc70cc722ed4ea1945e45bae3fce4f0.png)
expire_time索引
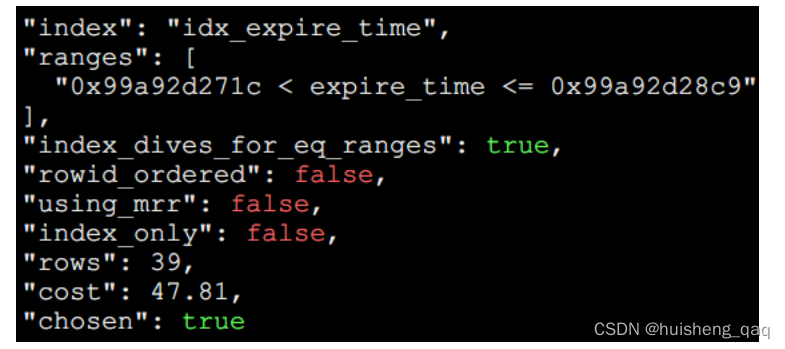
再计算这个expire_time这列索引的成本代价,这里由于就一个范围时间,因此只需要一次IO,在单独使用这个字段作为索引时,发现只涉及到39行数据,因此这个需要进行39次cpu的判断;同时在这个二级索引结束之后,需要回表到一级索引里面,通过一级索引去找到对应的值,因此一级索引也需要一定的IO和CPU,由于二级索引找到的值有39行数据,那么需要回表39次,其IO和CPU成本如下
T(I/O二级索引) : 1 * 1.0 = 1
T(I/O回表) : 39 * 1 = 39
T(CPU) : 39 * 0.2 + 0.01(微调数) = 7.81
T(CPU回表) : 39 * 0.2 = 7.8
T(总) = T(I/O二级索引) + T(I/O回表) + T(CPU) + T(CPU回表) = 55.61
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-82krlCGh-1675155949966)(img/1675128183273.png)]
系统显示是47.81,而实际计算是 55.61 ,那是由于在进行这个比较计算的时候,mysql内部会扣掉这个CPU回表的时间,即55.61 - 7.8 = 47.81 ,那么就对上了。
1.3.4,对比全部扫描的代价和其他单个索引的代价
因此在极端完上面这几个成本之后,就可以进行一个最终的比较了,通过这个cost成本比较得知,这个expire_time索引花费的时间最小,因此最终选择的是使用这个 expire_time 字段作为最终的选择的索引。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kxwO6Is7-1675155949967)(img/1672901244598.png)]](https://img-blog.csdnimg.cn/66a299d07e0748edb3c680624ac18eee.png)
2,in查询内核成本分析
在mysql中,其内部对in这个关键字也做了相应的优化
select * from user where user_no in ('123',xxx,xxx,...);
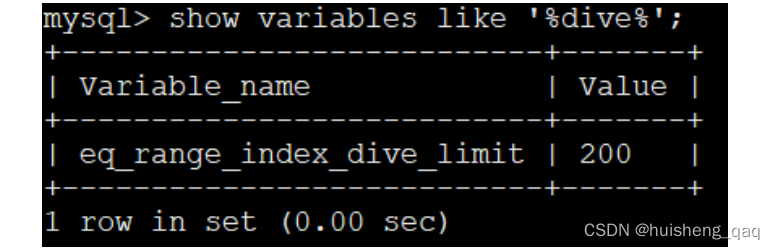
在使用这个in查询时,如果出现很多的这个单点区间的时候,那么就会触发这个 index dive,就是会有一个最大值去控制,可以发现这个默认的最大值为200,如果括号中的值是小于200的话,就会进行一个精确的计算,如果值大于200的话,就会进行一个估算。
show variables like '%dive%'
3,连接查询成本计算
在使用这个连接查询时,需要遵循一个原则就是:小表驱动大表。其主要通过这个嵌套循环连接算法实现这个连接查询,即驱动表查询一次,被驱动表则需要查询多次。 而多次查询被驱动表的成本,主要是取决于对驱动表查询的结果集中有多少条记录,即驱动表看的不是表中有多少数据,而是看查出来的结果集中的数据条数,谁的结果集的数据小则用哪张表作为结果集。
如果是使用这个左连接右连接,mysql内部很少做优化的东西,如果是内连接,那么mysql内部会做一个计算,去统计结果集的数据,然后区分谁做这个驱动表。
其成本计算的方式就是:表1的成本 + 表2的扇出 x 表1的成本 。因此这个优化手段就是两个部分,分别是 尽量减少驱动表的扇出,对被驱动表的访问成本尽量低。 并且在这个《阿里最新Java编程规范泰山版》的规定当中,
规定其超过三个表禁止join,需要join的字段,其数据类型保持绝对的一致,在多表关联查询时,保证被关联的字段走索引。
相关文章:
深入理解mysql的内核查询成本计算
MySql系列整体栏目 内容链接地址【一】深入理解mysql索引本质https://blog.csdn.net/zhenghuishengq/article/details/121027025【二】深入理解mysql索引优化以及explain关键字https://blog.csdn.net/zhenghuishengq/article/details/124552080【三】深入理解mysql的索引分类&a…...

LeetCode 141. 环形链表
原题链接 难度:easy\color{Green}{easy}easy 题目描述 给你一个链表的头节点 headheadhead ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 nextnextnext 指针再次到达,则链表中存在环。 为了表示给定链表中的…...
git提交
文章目录关于数据库:桌面/vue-admin/vue_shop_api 的 git 输入 打开 phpStudy ->mySQL管理器 导入文件同时输入密码,和文件名 node app.js 错误区: $ git branch // git branch 查看分支 只有一个main分支不见master解决: gi…...

Java中常见的编码集问题
收录于热门专栏Java基础教程系列(进阶篇) 一、遇到一个问题 1、读取CSV文件 package com.guor.demo.charset;import java.io.BufferedReader; import java.io.FileReader; import java.util.ArrayList; import java.util.HashMap; import java.util.L…...

数据结构与算法(Java版) | 就让我们来看看几个实际编程中遇到的问题吧!
上一讲,我给大家简单介绍了一下数据结构,以及数据结构与算法之间的关系,照理来说,接下来我就应该要给大家详细介绍线性结构和非线性结构了,但是在此之前,我决定还是先带着大家看几个实际编程中遇到的问题&a…...
【C++算法】dfs深度优先搜索(上) ——【全面深度剖析+经典例题展示】
💃🏼 本人简介:男 👶🏼 年龄:18 📕 ps:七八天没更新了欸,这几天刚搞完元宇宙,上午一直练🚗,下午背四级单词和刷题来着,还在忙一些学弟…...
总结高频率Vue面试题
目录 什么是三次握手? 什么是四次挥手?(close触发) 什么是VUEX? 什么是同源----跨域? 什么是Promise? 什么是fexl布局? 数据类型 什么是深浅拷贝? 什么是懒加载&…...
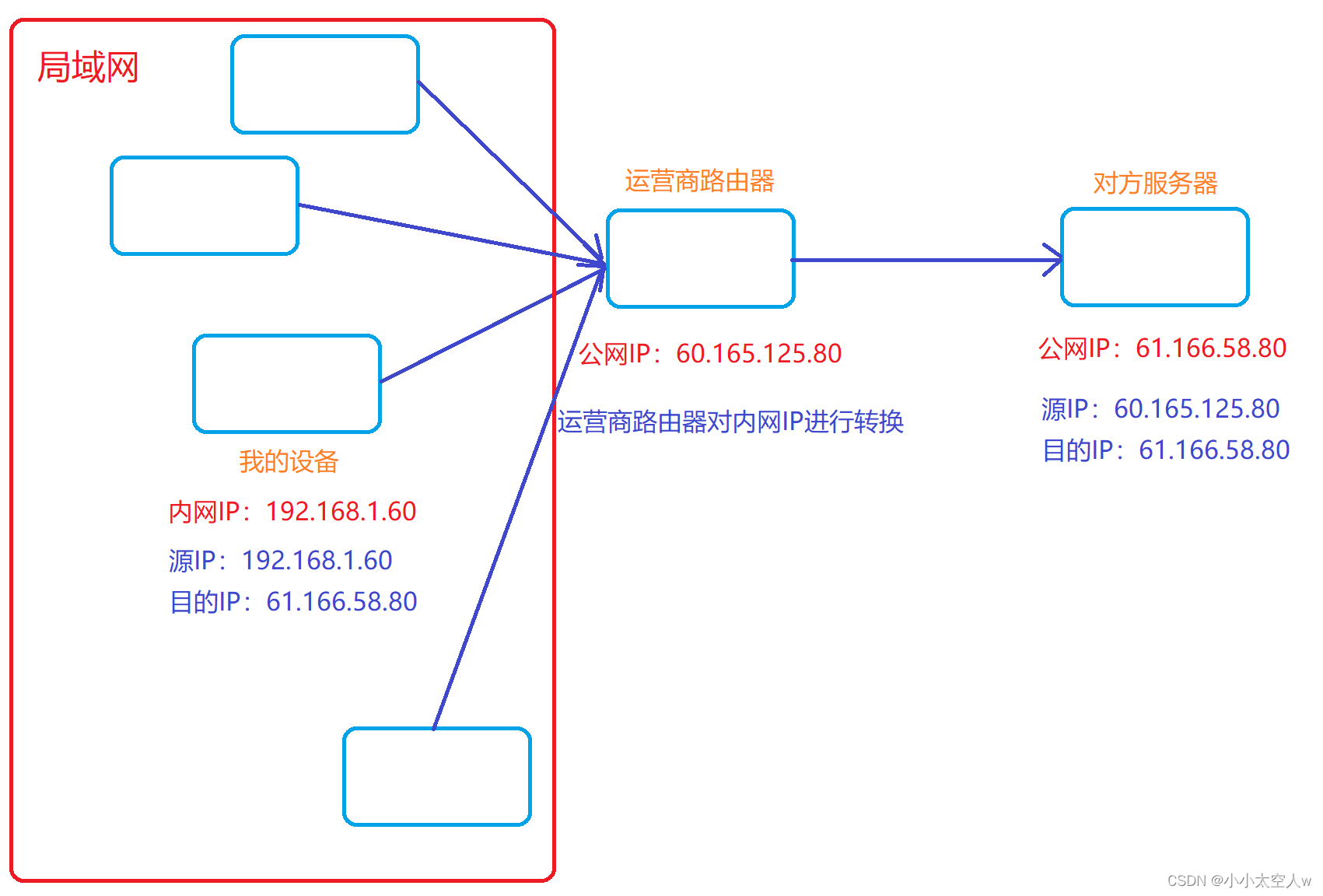
IP协议详解
目录 前言: IP协议 提出问题 解决方案 地址管理 子网掩码 路由选择 小结: 前言: IP协议作为网络层知名协议。当数据经过传输层使用TCP或者UDP对数据进行封装,然后当数据到达网络层,基于TCP或UDP数据包继续进行…...
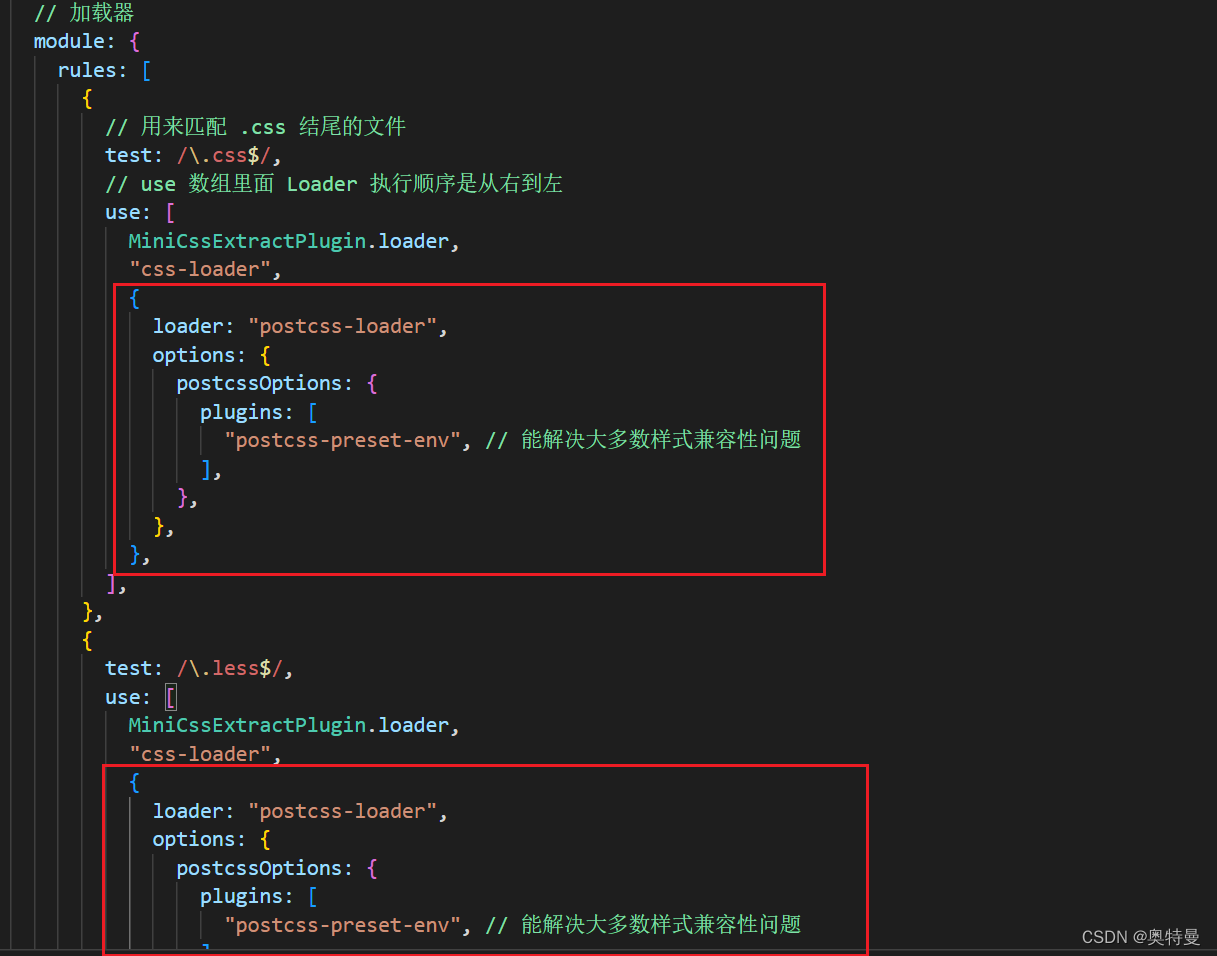
webpack5 基础配置
在开发中,我们会使用 vue、react、less、scss等语法进行开发项目,但是浏览器只能识别 js、css,或者说在js中使用了es6中的import 导入 这时候也需要打包工具去转换成浏览器可以识别的语句。 一、使用webpack 1.初始化package.json npm i…...
IDEA入门安装使用教程
一、背景 作为一个Java开发者,有非常多编辑工具供我们选择,比如Eclipse、IntelliJ IDEA、NetBeans、Visual Studio Code、Sublime Text等等,这些有免费也有收费的,但是就目前市场占比来说普遍使用Eclipse和IntelliJ IDEA这两款主…...

Lambda表达式使用及详解
一 Lambda表达式的简介 Lambda表达式(闭包):java8的新特性,lambda运行将函数作为一个方法的参数,也就是函数作为参数传递到方法中。使用lambda表达式可以让代码更加简洁。 Lambda表达式的使用场景:用以简…...

JAVA练习52-打家劫舍
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、题目-打家劫舍 1.题目描述 2.思路与代码 2.1 思路 2.2 代码 总结 前言 提示:这里可以添加本文要记录的大概内容: 2月16日练习内容 提…...

简单谈一谈幂等测试
1、什么是幂等测试 幂等是一个抽象的概念,在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同,即多次调用方法或者接口不会改变业务状态,可以保证重复调用的结果和单次调用的结果一致。幂等测试,则主…...

typescript复习笔记
数组类型-限定每一项的类型 //写法一 const arrNumber: number[] [1, 2, 3] const arrString: string[] [a, b, c] //写法二 const arrNumber2: Array<number> [1, 2, 3] const arrString2: Array<string> [a, b, c]联合类型 符号是 | //数组可以存放字符串或…...
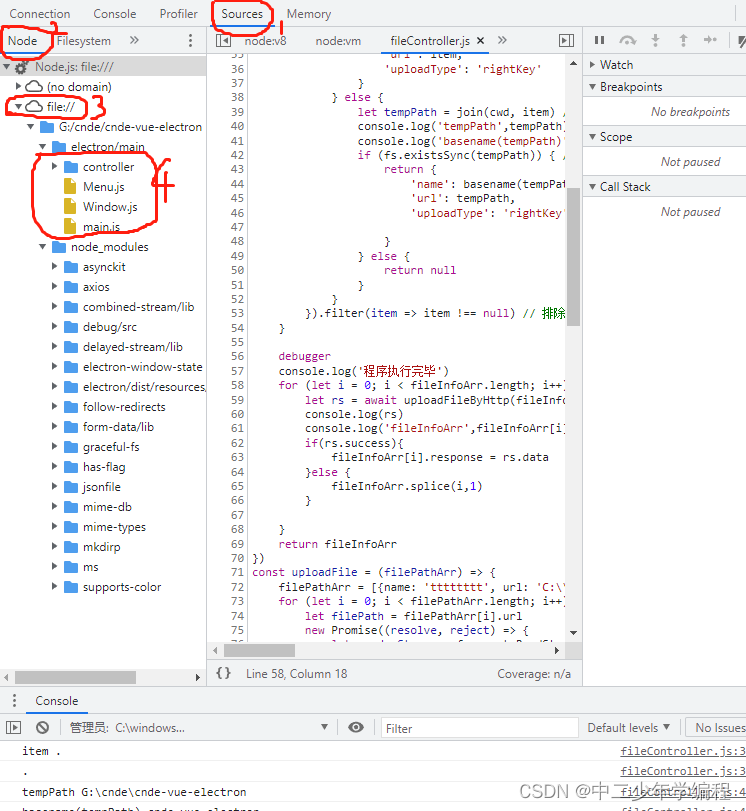
webstorm开发electron,调试主进程方案
官网教程地址:https://www.electronjs.org/zh/docs/latest/tutorial/debugging-main-process 我只能说官网太看得起人了,整这么简易的教程…… 命令行开关 第一步还是要按要求在我们的package.json里加上端口监听:–inspect5858 我的命令…...
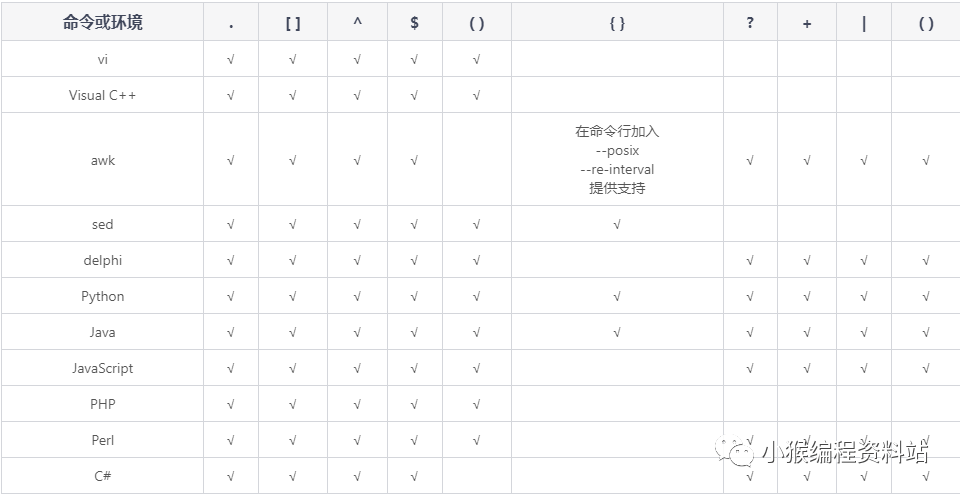
2W字正则表达式基础知识总结,这一篇就够了!!(含前端常用案例,建议收藏)
正则表达式 (Regular Expression,简称 RE 或 regexp ) 是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")正则表达式使用单个字符串来描述、匹配一系列匹…...
自学web前端觉得好难,可能你遇到了这些困境
好多人跟我说上学的时候也学过前端,毕业了想从事web前端开发的工作,但自学起来好难,快要放弃了,所以我总结了一些大家遇到的困境,希望对你会有所帮助。 目录 1. 意志是否坚定 2. 没有找到合适自己的老师 3. 为了找…...

ASEMI中低压MOS管18N20参数,18N20封装,18N20尺寸
编辑-Z ASEMI中低压MOS管18N20参数: 型号:18N20 漏极-源极电压(VDS):200V 栅源电压(VGS):30V 漏极电流(ID):18A 功耗(PD&#x…...

[NetBackup]客户端安装后server无法连通client
client name处填写客户端主机名,server to use for backups and restores处填写server端名字,与hosts文件内保持一致;source client for restores处填写client主机名,与server端hosts文件中保持一致,与主机实际名称保持…...

黑马Java后端项目实战--在线聊天交友
【课程简介】 越来越多的系统都有消息推送的功能,如聊天室、邮件推送、系统消息推送等; 要实现消息推送就需要服务端在数据有变化时主动推送消息给客户端,本次课程将带大家使用websocket实现消息推送。 【主讲内容】 1.方法:如…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...