数据库面试题
第一范式(1NF)
第一范式是指数据库的每一列都是不可分割的基本数据项,而下面这样的就存在可分割的情况:
- 学生(姓名,电话号码)
电话号码实际上包括了家用座机电话和移动电话,因此它可以被拆分为:
- 学生(姓名,座机号码,手机号码)
满足第一范式是关系型数据库最基本的要求!
第二范式(2NF)
第二范式要求表中必须存在主键,且其他的属性必须完全依赖于主键,比如:
- 学生(学号,姓名,性别)
学号是每个学生的唯一标识,每个学生都有着不同的学号,因此此表中存在一个主键,并且每个学生的所有属性都依赖于学号,学号发生改变就代表学生发生改变,姓名和性别都会因此发生改变,所有此表满足第二范式。
第三范式(3NF)
在满足第二范式的情况下,所有的属性都不传递依赖于主键,满足第三范式。
- 学生借书情况(借阅编号,学生学号,书籍编号,书籍名称,书籍作者)
实际上书籍编号依赖于借阅编号,而书籍名称和书籍作者依赖于书籍编号,因此存在传递依赖的情况,我们可以将书籍信息进行单独拆分为另一张表:
- 学生借书情况(借阅编号,学生学号,书籍编号)
- 书籍(书籍编号,书籍名称,书籍作者)
这样就消除了传递依赖,从而满足第三范式。
BCNF
BCNF作为第三范式的补充,假设仓库管理关系表为StorehouseManage(仓库ID, 存储物品ID, 管理员ID, 数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID, 存储物品ID) →(管理员ID, 数量)
(管理员ID, 存储物品ID) → (仓库ID, 数量)
所以,(仓库ID, 存储物品ID)和(管理员ID, 存储物品ID)都是StorehouseManage的候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
即存在关键字段决定关键字段的情况,如果修改管理员ID,那么就必须逐一进行修改,所以其不符合BCNF范式。
事务
当我们要进行的操作非常多时,比如要依次删除很多个表的数据,我们就需要执行大量的SQL语句来完成,这些数据库操作语句就可以构成一个事务!只有Innodb引擎支持事务,我们可以这样来查看支持的引擎:
SHOW ENGINES;
MySQL默认采用的是Innodb引擎,我们也可以去修改为其他的引擎。
事务具有以下特性:
- 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- 隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
存储引擎
存储引擎就像我们电脑中的CPU,它是整个MySQL最核心的部分,数据库中的数据如何存储,数据库能够支持哪些功能,我们的增删改查请求如何执行,都是由存储引擎来决定的。
我们可以大致了解一下以下三种存储引擎:
-
MyISAM:MySQL5.5之前的默认存储引擎,在插入和查询的情况下性能很高,但是它不支持事务,只能添加表级锁。
-
InnoDB:MySQL5.5之后的默认存储引擎,它支持ACID事务、行级锁、外键,但是性能比不过MyISAM,更加消耗资源。
-
Memory:数据都存放在内存中,数据库重启或发生崩溃,表中的数据都将消失。
我们可以使用下面的命令来查看MySQL支持的存储引擎:
show engines;
在创建表时,我们也可以为表指定其存储引擎。
我们还可以在配置文件中修改默认的存储引擎,在Windows 11系统下,MySQL的配置文件默认放在C:\ProgramData\MySQL\MySQL Server 5.7中,注意ProgramData是个隐藏文件夹。
索引
注意:本小节会涉及数据结构与算法相关知识。
索引就好像我们书的目录,每本书都有一个目录用于我们快速定位我们想要的内容在哪一页,索引也是,通过建立索引,我们就可以根据索引来快速找到想要的一条记录,大大提高查询效率。
本版块我们会详细介绍索引的几种类型,以及索引的底层存储原理。
单列索引
单列索引只针对于某一列数据创建索引,单列索引有以下几种类型:
-
NORMAL:普通的索引类型,完完全全相当于一本书的目录。
-
UNIQUE:唯一索引,我们之前已经用过了,一旦建立唯一索引,那么整个列中将不允许出现重复数据。每个表的主键列,都有一个特殊的唯一索引,叫做Primary Key,它不仅仅要求不允许出现重复,还要求不能为NULL,它还可以自动递增。每张表可以有多个唯一索引,但是只能有一个Primary索引。
-
SPATIAL:空间索引,空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON,不是很常用,这里不做介绍。
-
FULLTEXT:全文索引(MySQL 5.6 之后InnoDB才支持),它是模糊匹配的一种更好的解决方案,它的效率要比使用
like %更高,并且它还支持多种匹配方式,灵活性也更加强大。只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
我们来看看如何使用全文索引,首先创建一张用于测试全文索引的表:
CREATE TABLE articles (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,title VARCHAR(200),body TEXT,FULLTEXT (body));
INSERT INTO articles VALUES(NULL,'MySQL Tutorial', 'DBMS stands for DataBase ...'),(NULL,'How To Use MySQL Efficiently', 'After you went through a ...'),(NULL,'Optimising MySQL','In this tutorial we will show ...'),(NULL,'1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),(NULL,'MySQL vs. YourSQL', 'In the following database comparison ...'),(NULL,'MySQL Security', 'When configured properly, MySQL ...');
最后我们使用全文索引进行模糊匹配:
SELECT * FROM articles WHERE MATCH (body) AGAINST ('database');
注意全文索引如何定义字段的,match中就必须是哪些字段,against中定义需要模糊匹配的字符串,我们用作查找的字符串实际上是被分词之后的结果,如果进行模糊匹配的不是一个词语,那么会查找失败,但是它的效率远高于以下这种写法:
SELECT * FROM articles WHERE body like '%database%';
组合索引
组合索引实际上就是将多行捆绑在一起,作为一个索引,它同样支持以上几种索引类型,我们可以在Navicat中进行演示。
注意组合索引在进行匹配时,遵循最左原则。
我们可以使用explain语句(它可以用于分析select语句的执行计划,也就是MySQL到底是如何在执行某条select语句的)来分析查询语句到底有没有通过索引进行匹配。
explain select * from student where name = '小王';
得到的结果如下:
-
select_type:查询类型,上面的就是简单查询(SIMPLE)
-
table:查询的表
-
type:MySQL决定如何查找对应的记录,效率从高到低:system > const > eq_ref > ref > range > index > all
-
possible_keys:执行查询时可能会用到的索引
-
key:实际使用的索引
-
key_len:Mysql在索引里使用的字节数,字段的最大可能长度
-
rows:扫描的行数
-
extra:附加说明
索引底层原理
在了解完了索引的类型之后,我们接着来看看索引是如何实现的。
既然我们要通过索引来快速查找内容,那么如何设计索引就是我们的重点内容,因为索引是存储在硬盘上的,跟我们之前使用的HashMap之类的不同,它们都是在内存中的,但是硬盘的读取速度远小于内存的速度,每一次IO操作都会耗费大量的时间,我们也不可能把整个磁盘上的索引全部导入内存,因此我们需要考虑尽可能多的减少IO次数,索引的实现可以依靠两种数据结构,一种是我们在JavaSE阶段已经学习过的Hash表,还有一种就是B-Tree。
我们首先来看看哈希表,实际上就是计算Hash值来快速定位:

通过对Key进行散列值计算,我们可以直接得到对应数据的存放位置,它的查询效率能够达到O(1),但是它也存在一定的缺陷:
-
Hash索引仅仅能满足“=”,“in”查询条件,不能使用范围查询。
-
Hash碰撞问题。
-
不能用部分索引键来搜索,因为组合索引在计算哈希值的时候是一起计算的。
那么,既然要解决这些问题,我们还有一种方案就是使用类似于二叉树那样的数据结构来存储索引,但是这样相比使用Hash索引,会牺牲一定的读取速度。
但是这里并没有使用二叉树,而是使用了BTree,它是专门为磁盘数据读取设计的一种度为n的查找树:
-
树中每个结点最多含有m个孩子(m >= 2)
-
除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子。
-
若根结点不是叶子结点,则至少有2个孩子。
-
所有叶子结点都出现在同一层。
-
每个非终端结点中包含有n个键值信息: (P1,K1,P2,K2,P3,......,Kn,Pn+1)。其中:
-
Ki (i=1...n)为键值,且键值按顺序升序排序K(i-1)< Ki。
-
Pi为指向子树根的结点,且指针P(i)指向的子树中所有结点的键值均小于Ki,但都大于K(i-1)。
-
键值的个数n必须满足: [ceil(m / 2)-1] <= n <= m-1。
-
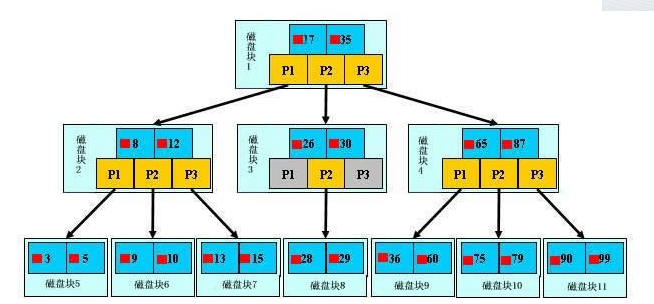
比如现在我们要对键值为10的记录进行查找,过程如下:
-
读取根节点数据(目前进行了一次IO操作)
-
根据根节点数据进行判断得到10<17,因为P1指向的子树中所有值都是小于17的,所以这时我们将P1指向的节点读取(目前进行了两次IO操作)
-
再次进行判断,得到8<10<12,因为P2指向的子树中所有的值都是小于12大于8的,所以这时读取P2指向的节点(目前进行了三次IO操作)
-
成功找到。
我们接着来看,虽然BTree能够很好地利用二叉查找树的思想大幅度减少查找次数,但是它的查找效率还是很低,因此它的优化版本B+Tree诞生了,它拥有更稳定的查询效率和更低的IO读取次数:
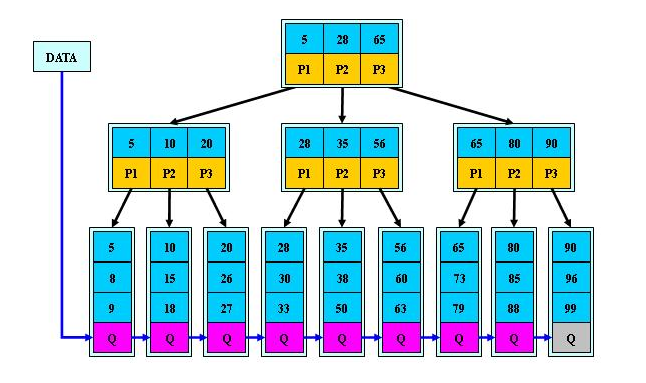
我们可以发现,它和BTree有一定的区别:
-
有n棵子树的结点中含有n个键值,BTree只有n-1个。
-
所有的键值信息只在叶子节点中包含,非叶子节点仅仅保存子节点的最小(或最大)值,和指向叶子节点的指针,这样相比BTree每一个节点在硬盘中存放了更少的内容(没有键值信息了)
-
所有叶子节点都有一个根据大小顺序指向下一个叶子节点的指针Q,本质上数据就是一个链表。
这样,读取IO的时间相比BTree就减少了很多,并且查询任何键值信息都需要完整地走到叶子节点,保证了查询的IO读取次数一致。因此MySQL默认选择B+Tree作为索引的存储数据结构。
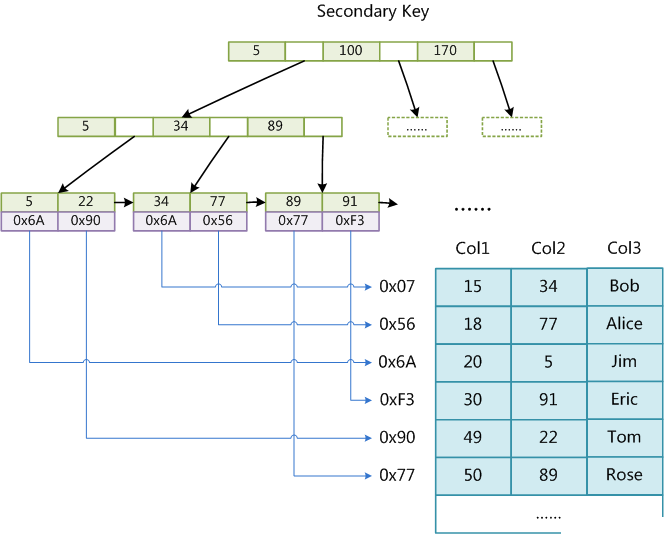
这是MyISAM存储引擎下的B+Tree实现:
这是InnoDB存储引擎下的B+Tree实现:
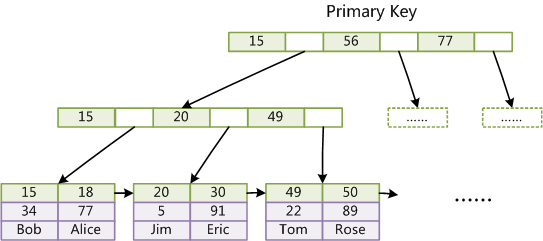
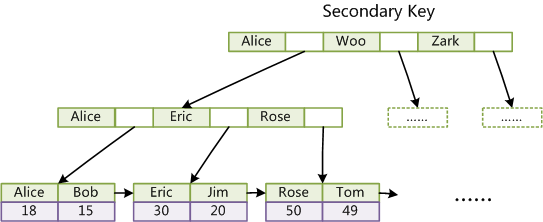
InnoDB与MyISAM实现的不同之处:
-
数据本身就是索引的一部分(所以这里建议主键使用自增)
-
非主键索引的数据实际上存储的是对应记录的主键值(因此InnoDB必须有主键,若没有也会自动查找替代)
锁机制
在JavaSE的学习中,我们在多线程板块首次用到了锁机制,当我们对某个方法或是某个代码块加锁后,除非锁的持有者释放当前的锁,否则其他线程无法进入此方法或是代码块,我们可以利用锁机制来保证多线程之间的安全性。
在MySQL中,就很容易出现多线程同时操作表中数据的情况,如果要避免潜在的并发问题,那么我们可以使用之前讲解的事务隔离级别来处理,而事务隔离中利用了锁机制。
-
读未提交(Read Uncommitted):能够读取到其他事务中未提交的内容,存在脏读问题。
-
读已提交(Read Committed RC):只能读取其他事务已经提交的内容,存在不可重复读问题。
-
可重复读(Repeated Read RR):在读取某行后不允许其他事务操作此行,直到事务结束,但是依然存在幻读问题。
-
串行读(Serializable):一个事务的开始必须等待另一个事务的完成。
我们可以切换隔离级别分别演示一下:
set session transaction isolation level read uncommitted;
在RR级别下,MySQL在一定程度上解决了幻读问题:
-
在快照读(不加锁)读情况下,mysql通过mvcc来避免幻读。
-
在当前读(加锁)读情况下,mysql通过next-key来避免幻读。
MVCC,全称Multi-Version Concurrency Control,即多版本并发控制。MVCC 是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
快照读 即:snapshot read,官方叫法是:Consistent Nonlocking Reads,即:一致性非锁定读
快照读 是: InnoDB 通过 MVCC(多版本控制)将数据库在过去某个时刻的快照应用在查询上,使得:这次查询 只能看到 别的事务生成快照前提交的数据,而不能看到 别的事务生成快照后提交的数据或者未提交的数据。
存在的问题
即 快照读 的问题在于:在同一个事务中,能够读取到之前提交的数据。表现为:
- 如果在同一个事务中,先更新了表中的一些行,然后进行查询,读到了更新后的数据,应该是读到未更新的数据。即:产生了
不可重复读的问题。 - 如果在同一个事务中,先更新了表(
drop tablealter table),然后进行查询,会发现表的状态已经不是快照时的状态了。
好处
快照读是repeatable-read和read-committed级别下,默认的查询模式,好处是:读不加锁,读写不冲突,这个对于 MySQL 并发访问提升很大。
隔离级别
- 在
read-committed隔离级别下,事务中的快照读,总是以最新的快照为基准进行查询的。 - 在
repeatable-read隔离级别下,快照读是以事务开始时的快照为基准进行查询的,如果想以最新的快照为基准进行查询,可以先把事务提交完再进行查询。 - 在
repeatable-read隔离级别下,别的事务在你生成快照后进行的删除、更新、新增,快照读是看不到的。
5. 特别注意-1
字面意思:在事务中,为查询创建的快照,并不适用与 DML 语句。
也就是说:如果事务 A 开始时创建的快照,查询不到数据 col1=1,但此时事务 B 刚刚提交 insert col1=1 和 insert col1=1,此时如果事务 A 执行,delete col1=1,是能将事务 B 生成的数据删除的。
| 时刻 | 事务 A | 事务 B |
|---|---|---|
| t0 | start transaction; | start transaction; |
| t1 | select * from t where col1=1;# return: 0 rows found... | |
| t2 | insert into t(col1) values (1);# return: insert success... | |
| t3 | update t set col1=1 where col1=2;# return: 1 rows updated... | |
| t4 | commit; | |
| t5 | delete from t where col1=1;# return: 2 rows deleted... |
6. 特别注意-2
Session A sees the row inserted by B only when B has committed the insert and A has committed as well, so that the timepoint is advanced past the commit of B.
字面意思:即使事务 A 的快照是在事务 B 提交之前创建的,但事务 A 也只有在事务 A 和事务 B 都提交后,才能看到事务 B 新增的数据。
| 时刻 | 事务 A | 事务 B |
|---|---|---|
| t0 | start transaction; | start transaction; |
| t1 | select * from t; #empty | |
| t2 | insert into t values (1); | |
| t3 | select * from t; #empty | |
| t4 | commit; | |
| t5 | select * from t; #empty | |
| t6 | commit; | |
| t7 | select * from t; # 1 rows found |
读锁和写锁
从对数据的操作类型上来说,锁分为读锁和写锁:
-
读锁:也叫共享锁,当一个事务添加了读锁后,其他的事务也可以添加读锁或是读取数据,但是不能进行写操作,只能等到所有的读锁全部释放。
-
写锁:也叫排他锁,当一个事务添加了写锁后,其他事务不能读不能写也不能添加任何锁,只能等待当前事务释放锁。
全局锁、表锁和行锁
从锁的作用范围上划分,分为全局锁、表锁和行锁:
-
全局锁:锁作用于全局,整个数据库的所有操作全部受到锁限制。
-
表锁:锁作用于整个表,所有对表的操作都会收到锁限制。
-
行锁:锁作用于表中的某一行,只会通过锁限制对某一行的操作(仅InnoDB支持)
全局锁
我们首先来看全局锁,它作用于整个数据库,我们可以使用以下命令来开启读全局锁:
flush tables with read lock;
开启后,整个数据库被上读锁,我们只能去读取数据,但是不允许进行写操作(包括更新、插入、删除等)一旦执行写操作,会被阻塞,直到锁被释放,我们可以使用以下命令来解锁:
unlock tables;
除了手动释放锁之外,当我们的会话结束后,锁也会被自动释放。
表锁
表锁作用于某一张表,也是MyISAM和InnoDB存储引擎支持的方式,我们可以使用以下命令来为表添加锁:
lock table 表名称 read/write;
在我们为表添加写锁后,我们发现其他地方是无法访问此表的,一律都被阻塞。
行锁
表锁的作用范围太广了,如果我们仅仅只是对某一行进行操作,那么大可不必对整个表进行加锁,因此InnoDB支持了行锁,我们可以使用以下命令来对某一行进行加锁:
-- 添加读锁(共享锁) select * from ... lock in share mode; -- 添加写锁(排他锁) select * from ... for update;
使用InnoDB的情况下,在执行更新、删除、插入操作时,数据库也会自动为所涉及的行添加写锁(排他锁),直到事务提交时,才会释放锁,执行普通的查询操作时,不会添加任何锁。使用MyISAM的情况下,在执行更新、删除、插入操作时,数据库会对涉及的表添加写锁,在执行查询操作时,数据库会对涉及的表添加读锁。
提问:当我们不使用id进行选择,行锁会发生什么变化?(行锁升级)
记录锁、间隙锁和临键锁
我们知道InnoDB支持使用行锁,但是行锁比较复杂,它可以继续分为多个类型。
记录锁
(Record Locks)记录锁, 仅仅锁住索引记录的一行,在单条索引记录上加锁。Record lock锁住的永远是索引,而非记录本身,即使该表上没有任何索引,那么innodb会在后台创建一个隐藏的聚集主键索引,那么锁住的就是这个隐藏的聚集主键索引。所以说当一条sql没有走任何索引时,那么将会在每一条聚合索引后面加写锁,这个类似于表锁,但原理上和表锁应该是完全不同的。
间隙锁
(Gap Locks)仅仅锁住一个索引区间(开区间,不包括双端端点)。在索引记录之间的间隙中加锁,或者是在某一条索引记录之前或者之后加锁,并不包括该索引记录本身。比如在 1、2中,间隙锁的可能值有 (-∞, 1),(1, 2),(2, +∞),间隙锁可用于防止幻读,保证索引间的不会被插入数据。
临键锁
(Next-Key Locks)Record lock + Gap lock,左开右闭区间。默认情况下,InnoDB正是使用Next-key Locks来锁定记录(如select … for update语句)它还会根据场景进行灵活变换:
| 场景 | 转换 |
|---|---|
| 使用唯一索引进行精确匹配,但表中不存在记录 | 自动转换为 Gap Locks |
| 使用唯一索引进行精确匹配,且表中存在记录 | 自动转换为 Record Locks |
| 使用非唯一索引进行精确匹配 | 不转换 |
| 使用唯一索引进行范围匹配 | 不转换,但是只锁上界,不锁下界 |
在Oracle,SqlServer中都是选择读已提交(Read Commited)作为默认的隔离级别,为什么Mysql不选择读已提交(Read Commited)作为默认隔离级别,而选择可重复读(Repeatable Read)作为默认的隔离级别呢?
主从复制,是基于什么复制的?
是基于binlog复制的!这里不想去搬binlog的概念了,就简单理解为binlog是一个记录数据库更改的文件吧~
binlog有几种格式?
OK,三种,分别是
- statement:记录的是修改SQL语句
- row:记录的是每行实际数据的变更
- mixed:statement和row模式的混合
那Mysql在5.0这个版本以前,binlog只支持STATEMENT这种格式!而这种格式在读已提交(Read Commited)这个隔离级别下主从复制是有bug的,因此Mysql将可重复读(Repeatable Read)作为默认的隔离级别!
接下来,就要说说当binlog为STATEMENT格式,且隔离级别为读已提交(Read Commited)时,有什么bug呢?如下图所示,在主(master)上执行如下事务
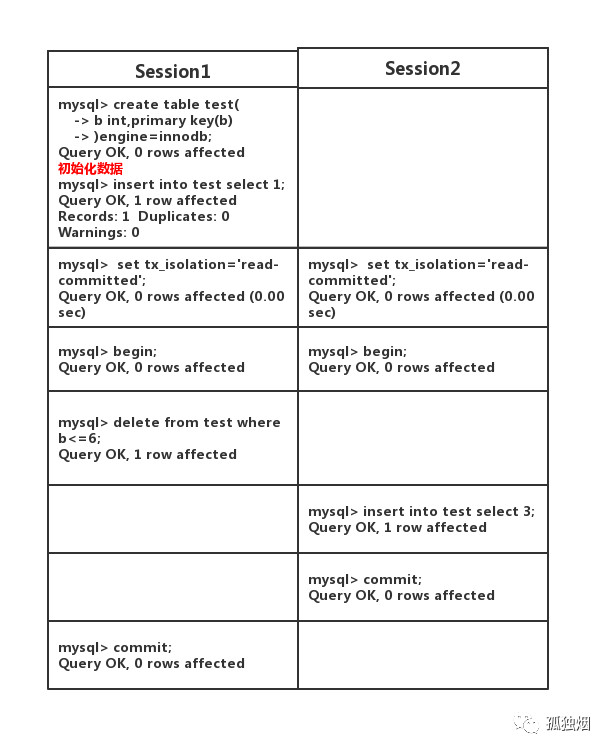
此时在主(master)上执行下列语句
select * from test;输出如下
+---+
| b |
+---+
| 3 |
+---+
1 row in set但是,你在此时在从(slave)上执行该语句,得出输出如下
Empty set这样,你就出现了主从不一致性的问题!原因其实很简单,就是在master上执行的顺序为先删后插!而此时binlog为STATEMENT格式,它记录的顺序为先插后删!从(slave)同步的是binglog,因此从机执行的顺序和主机不一致!就会出现主从不一致!
如何解决?
解决方案有两种!
(1)隔离级别设为可重复读(Repeatable Read),在该隔离级别下引入间隙锁。当Session 1执行delete语句时,会锁住间隙。那么,Ssession 2执行插入语句就会阻塞住!
(2)将binglog的格式修改为row格式,此时是基于行的复制,自然就不会出现sql执行顺序不一样的问题!奈何这个格式在mysql5.1版本开始才引入。因此由于历史原因,mysql将默认的隔离级别设为可重复读(Repeatable Read),保证主从复制不出问题!
脏读、不可重复读、幻读
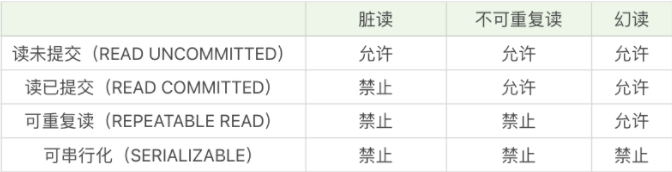
- 幻读:说的是存不存在的问题:原来不存在的,现在存在了,则是幻读 ( 对应:Insert 、Delete )
- 不可重复读:说的是变没变化的问题:原来是A,现在却变为了B,则为不可重复读( 对应:Update )
相关文章:
数据库面试题
第一范式(1NF) 第一范式是指数据库的每一列都是不可分割的基本数据项,而下面这样的就存在可分割的情况: 学生(姓名,电话号码) 电话号码实际上包括了家用座机电话和移动电话,因此它…...

[USACO2022-DEC-Bronze] T2 Feeding the Cows 题解
一、题目描述Farmer John has N (1≤N≤10^5) cows, the breed of each being either a Guernsey or a Holstein. They have lined up horizontally with the cows occupying positions labeled from 1…N.Farmer John 有 N(1≤N≤105)头奶牛,…...

Unity法线贴图原理理解(为什么存在切线空间?存的值是什么?)
Unity法线贴图原理理解(为什么存在切线空间?存的值是什么?)写在前面1、为什么用法线贴图?2、用什么存法线?3、法线向量为什么存在切线空间?法线贴图存得是什么?4、法线贴图为什么会偏蓝…...
【JavaWeb】传输层协议——UDP + TCP
目录 UDP协议 UDP协议结构 UDP的特点 TCP协议 TCP协议结构 TCP的特点 TCP的十个核心机制 确认应答 超时重传 连接管理 滑动窗口 流量控制 阻塞控制 延迟应答 捎带应答 粘包问题 异常处理 UDP协议 UDP协议结构 源端口:存储的是发送方的端口号。 目的…...

C++ 中是用来修饰:内置类型变量、自定义对象、成员函数、返回值、函数参数
const 是 constant 的缩写,本意是不变的,不易改变的意思。在 C 中是用来修饰内置类型变量,自定义对象,成员函数,返回值,函数参数。 一. const修饰 普通类型的变量 const int a 7; int b a; // 正确 …...

av 146 002
61. 一个新的敏捷项目经理正试图确定团队该如何执行一个发布计划的进度。哪种工具可以更深入地了解团队的进展? A. 发布计划系统 B. 产品路线图。 C. 看板。 D. 燃尽图 62. 你的项目发起人找到你,让你知道他正在考虑给你项目中的一位高级工程师颁发1000美元的现…...

小红书用户画像 | 小红书数据平台
小红书的用户画像是小红书品牌营销的必备技能,也是小红书推广种草的一个重要前提。通过对小红书用户画像进行分析,对品牌进行精准营销,实现更高的流量转化。 2022小红书粉丝人群画像 千瓜数据在2022年发布的千瓜活跃用户画像趋势报告中分析了…...
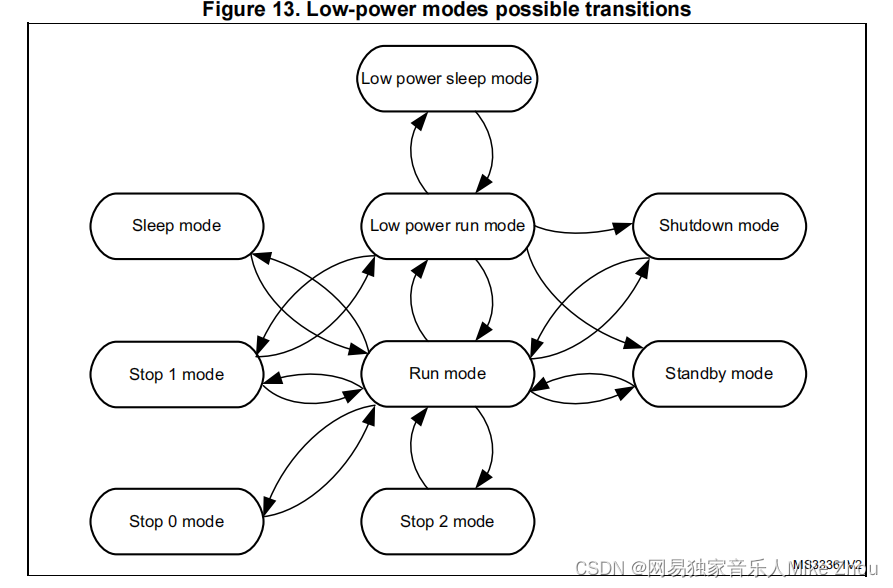
【STM32笔记】低功耗模式下GPIO、外设、时钟省电配置避坑
【STM32笔记】低功耗模式下GPIO、外设、时钟省电配置避坑 前文: blog.csdn.net/weixin_53403301/article/details/128216064 【STM32笔记】HAL库低功耗模式配置(ADC唤醒无法使用、低功耗模式无法烧录解决方案) blog.csdn.net/weixin_534033…...

Linux内存分区(swap)
目录 1、使用物理分区创建内存交换分区 2、使用文件创建内存交换文件 当硬件的设备资源充足的话,那么swap是不会被我们的系统所使用到的,所以swap会被利用到的时刻通常就是物理内存不足的情况 我们知道CPU所读取的数据都来自于内存,那么当…...

第六章——抽样分布
文章目录1、统计量的定义2、常用的统计量3、经验分布函数4、正态总体常用统计量的分布4.1、卡方分布4.1.1、卡方分布的定义4.1.2、卡方分布的性质4.2、t分布4.2.1、t分布的定义4.2.2、t分布的性质4.3、F分布4.3.1、F分布的定义4.3.2、F分布的性质5、正态总体的样本均值与样本方…...
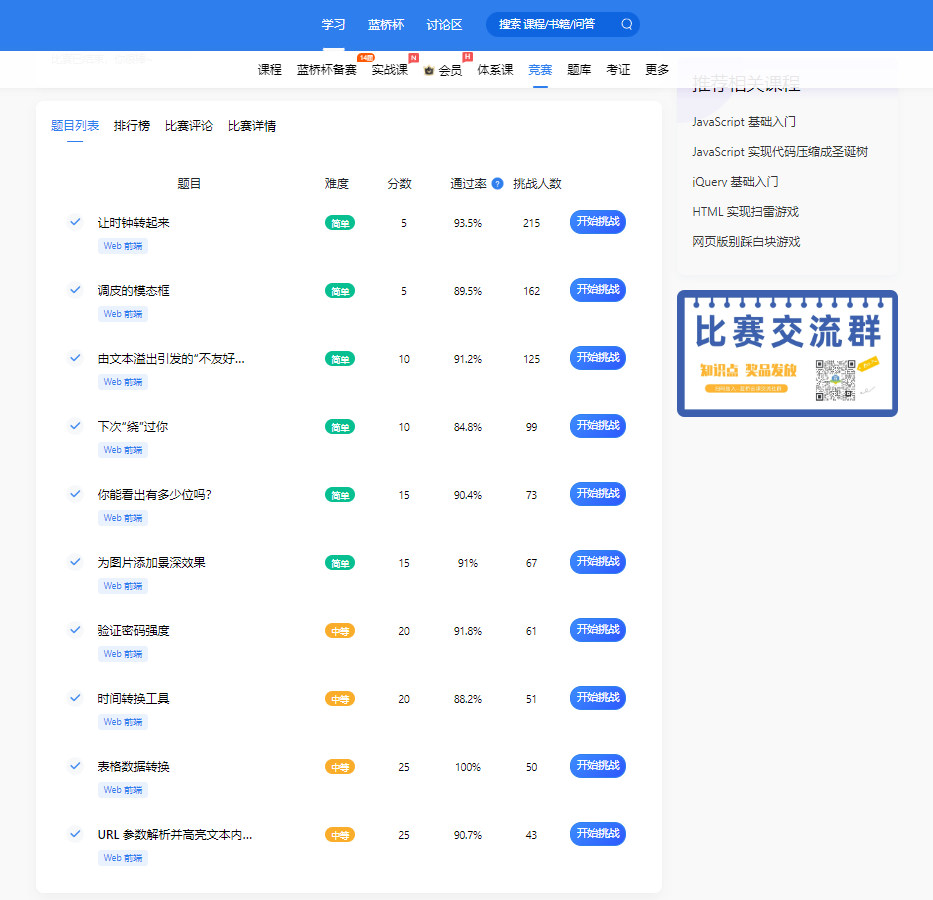
蓝桥云课-声网编程赛(声网编程竞赛7月专场)题解
比赛题目快速链接:https://www.lanqiao.cn/contests/lqENT02/challenges/ 让时钟转起来(考点:css:transform) // index.js function main() {// 题解前理解一个东西:// 时针每过一小时,转30 原…...
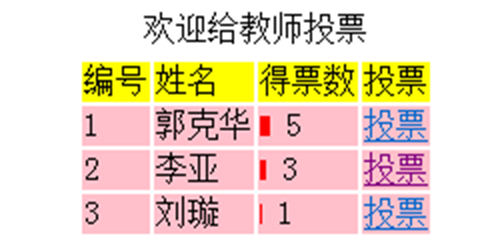
Java高手速成 | Java web 实训之投票系统
01、投票系统的案例需求 在本篇中,我们将制作一个投票系统,让学生给自己喜爱的老师投票。该系统由1个界面组成,系统运行,出现投票界面,如图所示: ▍显示效果 在这个界面中,标题为:“欢迎给教师投票”;在界面上有一个表格,显示了各位教师的编号、姓名、得票数;其中…...

排序的基本概念
按数据存储介质:内部排序和外部排序按比较器个数:串行排序和并行排序按主要操作:比较排序和基数排序插入排序:基本思想:每步将一个待排序的对象,按其关键码大小,插入到前面已经排好序的一组对象…...

面试笔试资料--Java
这里写自定义目录标题1.同步和异步有何异同?在什么情况下分别使用他们?举例说明1.同步和异步有何异同?在什么情况下分别使用他们?举例说明 1.1概念 Java中交互方式分为同步和异步两种: 同步交互:指发送…...

基于TC377的MACL-ADC General配置解读
目录标题一、MACL-ADC General1.Config Variant与AdcConfigSet2. AdcGeneral3.AdcPublishedInformation二、最终对应达芬奇生成内容一、MACL-ADC General 1.Config Variant与AdcConfigSet Config Variant :变体配置,默认选择VariantPostBuild就好了&…...

error: src refspec master does not match any.处理方案
问题描述 在使用git bash指令将项目上传到github时,总是遇到一些错误无法解决。 下面是我遇到的一个问题 error: src refspec master does not match any. error: failed to push some refs to XXXX.git 原因分析: 错误:SRC ReFSPEC主控器不…...

防火墙有关iptables的知识点
基本概念 什么是防火墙 在计算中,防火墙是基于预定安全规则来监视和控制传入和传出网络流量的网络安全系统。该计算机流入流出的所有网络通信均要经过此防火墙。防火墙对流经它的网络通信进行扫描,这样能够过滤掉一些攻击,以免其在目标计算机…...

路肩石水渠机在施工公路项目中工艺特点的匹配
新建公路路肩项目在目前公路项目中的技术手段和实现方式,大多数依靠机械设备来机械来进行,还有一部分通过人工传统的预制作业和安装模式来进行,两种工艺特点的对比来说对于补充完善建设手段和效果实现有很重要的意义. 其中采用了机械设备进行一次成型制作的过程,按照设计需求匹…...

JS 动态爱心(HTML+CSS+JS)
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
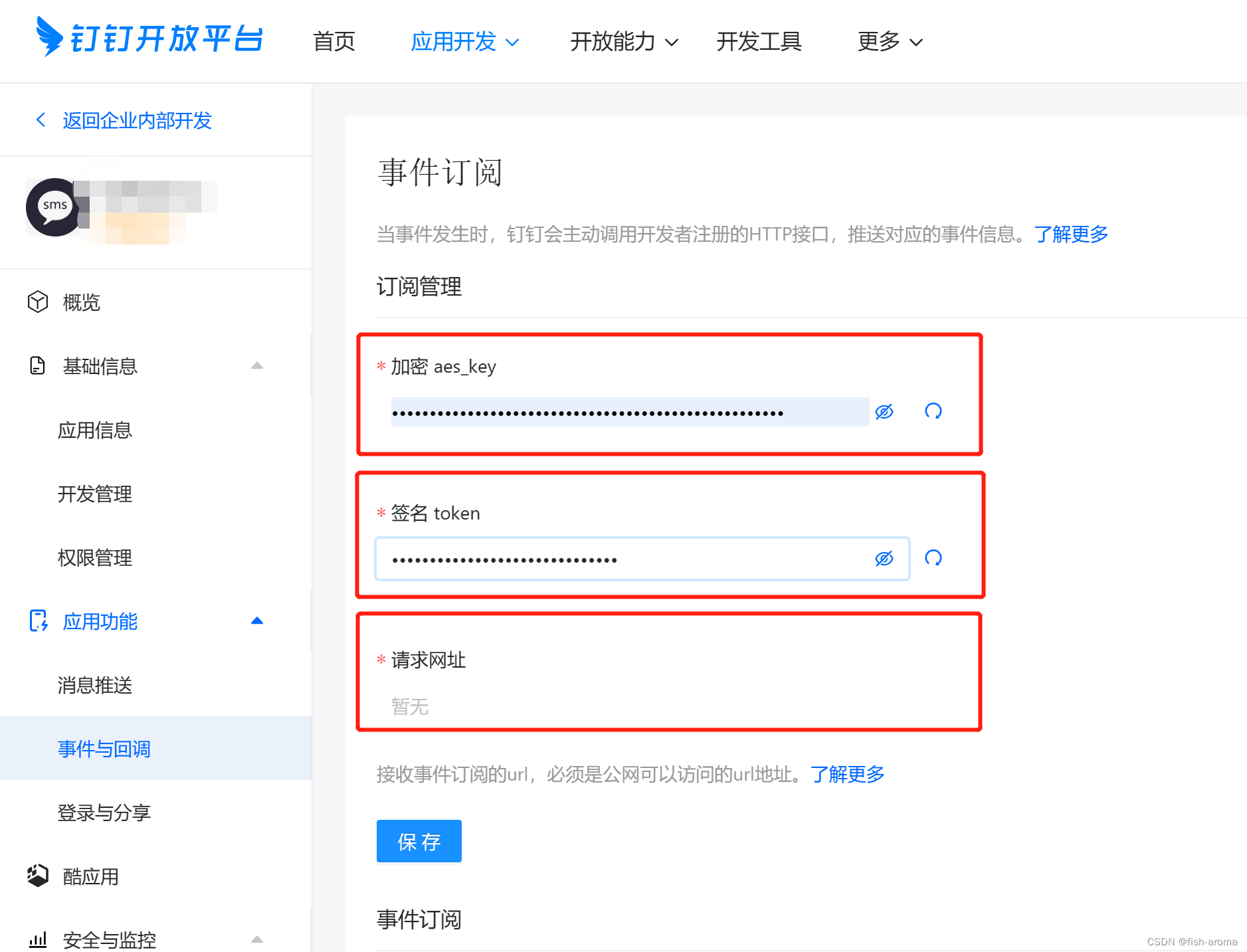
钉钉配置事件订阅(Python)
钉钉配置事件订阅 0.需求分析 需要实现钉钉企业通讯录同步至企业微信通讯录,这就需要用到钉钉的事件与回调 1.配置应用 登陆开放平台 https://open-dev.dingtalk.com/去企业内部开发里面,先创建个应用,后面都借用这个应用来调接口 创建完…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...