【数据结构】哈希应用
目录
一、位图
1、位图概念
2、位图实现
2.1、位图结构
2.2、比特位置1
2.3、比特位置0
2.4、检测位图中比特位
3、位图例题
3.1、找到只出现一次的整数
3.2、找到两个文件交集
3.3、找到出现次数不超过2次的所有整数
二、布隆过滤器
1、布隆过滤器提出
2、布隆过滤器概念
3、布隆过滤器实现
3.1、布隆过滤器的插入
3.2、布隆过滤器的查找
3.3、布隆过滤器删除
4、布隆过滤器例题
4.1、找到两个存贮query的文件的交集
4.2、哈希切割
一、位图
1、位图概念
所谓位图,就是用每一个比特位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。
位图的优点:
- 速度快
- 节省空间
位图的缺点:
- 只能映射整型 ,其他类型如:浮点数、string等等不能存储映射。
2、位图实现
2.1、位图结构
位图类的结构如下:
template<size_t N>
class bitset
{
public:bitset(){_bits.resize(N / 8 + 1, 0);}//将某个比特位置1void set(size_t x){}//将某个比特位置0void reset(size_t x){}//检查位图中某个比特位是否为1bool test(size_t x){}private:vector<char> _bits;
};2.2、比特位置1
实现代码:
void set(size_t x){size_t i = x / 8;size_t j = x % 8;_bits[i] |= (1 << j);}用除法计算 x 映射的位在数组的第 i 个 char 类型内。 用取模计算 x 映射的位在第 i 个 char 类型的第 j 个比特位。然后用按位或运算把指定比特位置1。
需要注意的是在进行按位或运算时,使用的是 1 左移 j 位,而不是右移。这是因为在我们人类的主观认识上,数位的排列是下面这样的:

但实际上,在计算机的虚拟层储存逻辑上,数位的保存是这样的:

我们所说的左移与右移,并不是向左移动或者向右移动,而是向高位移动与向低位移动。因此为了找到目标位置,需要使用左移,而不是右移。
2.3、比特位置0
实现代码:
void reset(){size_t i = x / 8;size_t j = x % 8;_bits[i] &= ~(1 << j);}用除法计算 x 映射的位在数组的第 i 个 char 类型内。 用取模计算 x 映射的位在第 i 个 char 类型的第 j 个比特位。然后用按位非与运算把指定比特位置1。
2.4、检测位图中比特位
实现代码:
bool test(size_t x){size_t i = x / 8;size_t j = x % 8;return _bits[i] & (1 << j);}3、位图例题
3.1、找到只出现一次的整数
设置状态:出现 0 次,状态是 00 。出现 1 次,状态是 01 。出现 2 次及以上,状态是 10 。
template<size_t N>
class twobitset
{
public:void set(size_t x){// 00->01if (_bs1.test(x) == false&& _bs2.test(x) == false){_bs2.set(x);}// 01->10else if (_bs1.test(x) == false&& _bs2.test(x) == true){_bs1.set(x);_bs2.reset(x);}//10}void Print(){for (size_t i = 0; i < N; ++i){if (_bs2.test(i)){cout << i << endl;}}}
public:bitset<N> _bs1;bitset<N> _bs2;
};
测试结果如下:

3.2、找到两个文件交集
方法一:把其中一个文件的值读取到位图中,再读取另一个文件,判断在不在上面的位图中,在就是交集,取出该值,并把对应位图置0。
方法二:创建两个位图,读取文件1的数据映射到位图1,读取文件2的数据映射到位图2。然后让位图1与位图2按位与。最终结果是交集。
3.3、找到出现次数不超过2次的所有整数
设置状态:出现 0 次,状态是 00 。出现 1 次,状态是 01 。出现 2 次,状态是 10 。出现 3 次及以上,状态是 11 。
实现代码与 3.1 中类似。
二、布隆过滤器
1、布隆过滤器提出
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。 如何快速查找呢?
- 用哈希表存储用户记录,缺点:浪费空间。
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理了。
- 将哈希与位图结合,即布隆过滤器。
2、布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。

布隆过滤器可以降低冲突的概率。一个值映射到一个位置,容易误判,映射到多个位置,就可以降低误判率。
布隆过滤器的优点:
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关。
- 哈希函数相互之间没有关系,方便硬件并行运算。
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势。
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势。
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能。
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算。
布隆过滤器的缺点:
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)。
- 不能获取元素本身。
- 一般情况下不能从布隆过滤器中删除元素。
- 如果采用计数方式删除,可能会存在计数回绕问题。
3、布隆过滤器实现
3.1、布隆过滤器的插入

向布隆过滤器中插入:"baidu":

向布隆过滤器中插入:"tencent":

实现代码:
struct BKDRHash
{size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash += ch;hash *= 31;}return hash;}
};struct DJBHash
{size_t operator()(const string& s){size_t hash = 5381;for (auto ch : s){hash += (hash << 5) + ch;}return hash;}
};struct APHash
{size_t operator()(const string& s){size_t hash = 0;for (long i = 0; i < s.size(); i++){if ((i & 1) == 0){hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));}}return hash;}
};template<size_t N, class K = string, class Hash1 = BKDRHash, class Hash2 = APHash, class Hash3 = DJBHash>
class BloomFilter
{
public:void set(const K& key){size_t len = N * _X;size_t hash1 = Hash1()(key) % len;_bs.set(hash1);size_t hash2 = Hash2()(key) % len;_bs.set(hash2);size_t hash3 = Hash3()(key) % len;_bs.set(hash3);}
private:static const size_t _X = 4; // 布隆过滤器的长度与数据数量的倍数关系bitset<N*_X> _bs; //这样可以有效的减少不同数据间的冲突
};3.2、布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
实现代码:
bool test(const K& key)
{size_t len = N * _X;size_t hash1 = Hash1()(key) % len;if (!_bs.test(hash1))return false;size_t hash2 = Hash2()(key) % len;if (!_bs.test(hash2))return false;size_t hash3 = Hash3()(key) % len;if (!_bs.test(hash3))return false;return true;//依然存在误判,有可能把不在的判断成在
}需要注意的是,即使使用了三个哈希函数进行判断,仍然存在误判的可能性。如果判断该数据不存在,则该数据一定不存在。如果判断该数据存在,则该数据有一定的可能性其实不存在。
因此,布隆过滤器只能运用于能够容忍误判的场景,比如视频推送等等。而对于一些不容忍误判的场景下,布隆过滤器也有相应的解决方法:如果判断出数据存在,就到数据库中进行二次确认,依然存在就返回存在,不存在就返回不存在。
哈希函数个数,代表一个值映射几个位,哈希函数越多,误判率越低,但是哈希函数越多,平均占的空间就越大。
3.3、布隆过滤器删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
缺陷:
- 无法确认元素是否真正在布隆过滤器中。
- 存在计数回绕。
4、布隆过滤器例题
4.1、找到两个存贮query的文件的交集
使用哈希切分,把一个大文件分割成多个小文件,再让小文件之间取交集:

使用这种方法,因为不是平均切分,可能会出现冲突多,某一个Ai、Bi小文件过大的问题。出现这种问题无非两种情况:
- 单个文件中,有某个大量重复的query。
- 单个文件中,有大量不同的query。
可以直接使用一个unordered_set/set,依次读取文件query,插入set中:
- 如果读取了整个小文件的query,都可以成功插入set,说明是情况一。
- 如果读取了整个小文件的query,插入过程中出现抛异常,说明是情况二。换成其他哈希函数,再次分割,再求交集。
说明:set插入key,如果已经有了,返回false。如果内存用完了就会抛bad_alloc异常,剩下的都会成功。
4.2、哈希切割
给一个超过100G大小的log file,log中存着IP地址,设计算法找到出现次数最多的IP地址。
依然使用哈希切割的方法:

依次处理每一个小文件,使用unordered_map 或 map 统计ip出现的次数。
- 如果统计过程中,没有抛异常则正常统计。统计完一个小文件,记录最多的那一个。clear内存,再统计下一个小文件。
- 如果统计过程中,出现抛异常现象,说明单个文件过大,冲突太多。换成其他哈希函数,再次分割。
建立一个k个数据的小堆,每统计一次,就插入小堆,转换成topK问题,最终可以解决。
相关文章:
【数据结构】哈希应用
目录 一、位图 1、位图概念 2、位图实现 2.1、位图结构 2.2、比特位置1 2.3、比特位置0 2.4、检测位图中比特位 3、位图例题 3.1、找到只出现一次的整数 3.2、找到两个文件交集 3.3、找到出现次数不超过2次的所有整数 二、布隆过滤器 1、布隆过滤器提出 2、布隆过…...
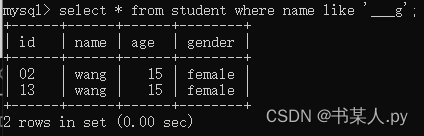
【 Python 全栈开发 - WEB开发篇 - 31 】where条件查询
文章目录 一、where条件查询1.关系运算符查询2.IN关键字查询3.BETWEEN AND关键字查询4.空值查询5.AND关键字查询6.OR关键字查询7.LIKE关键字查询普通字符串含有%通配的字符串含有_通配的字符串 一、where条件查询 MySQL 的 where 条件查询是指在查询数据时,通过 wh…...

Android系统的Ashmem匿名共享内存子系统分析(5)- 实现共享的原理
声明 其实对于Android系统的Ashmem匿名共享内存系统早就有分析的想法,记得2019年6、7月份Mr.Deng离职期间约定一起对其进行研究的,但因为我个人问题没能实施这个计划,留下些许遗憾…文中参考了很多书籍及博客内容,可能涉及的比较…...

谈一谈冷门的C语言爬虫
C语言可以用来编写爬虫程序,但是相对于其他编程语言,C语言的爬虫开发可能会更加复杂和繁琐。因为C语言本身并没有提供现成的爬虫框架和库,需要自己编写网络请求、HTML解析等功能。 不过,如果你对C语言比较熟悉,也可以…...

基于状态的维护(CBM)如何推动设备效率提高?
基于状态的维护(Condition-Based Maintenance,CBM)是一种先进的维护策略,通过实时监测和分析设备的状态数据,预测设备故障并采取相应的维护措施。CBM基于数据驱动的方法,能够提高设备的可用性、降低维修成本…...
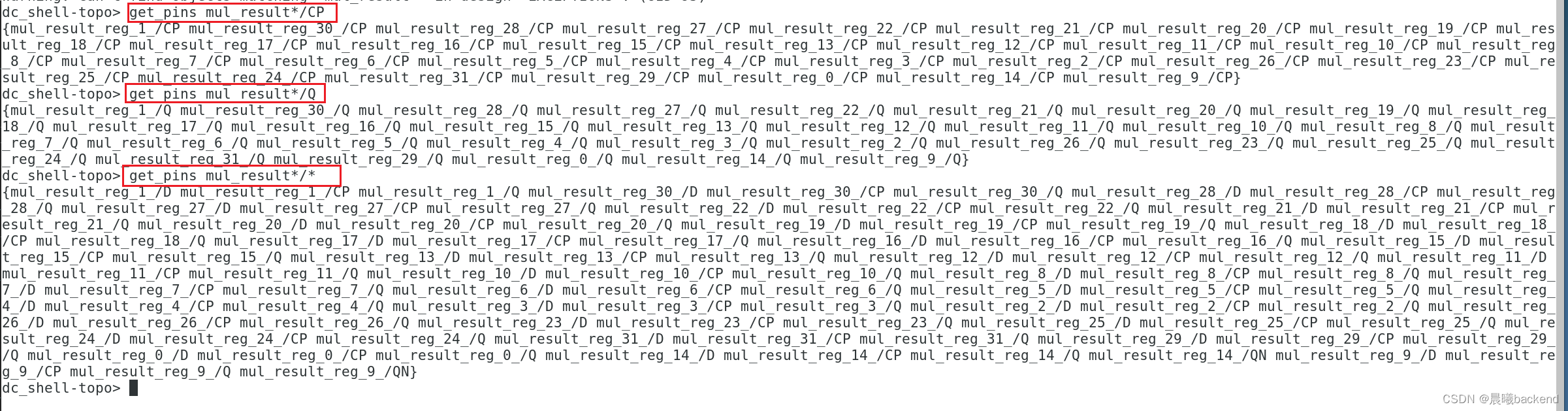
DC LAB8SDC约束四种时序路径分析
DC LAB 1.启动DC2.读入设计3. 查看所有违例的约束报告3.1 report_constraint -all_violators (alias rc)3.2 view report_constraint -all_violators -verbose -significant_digits 4 (打印详细报告) 4.查看时序报告 report_timing -significant_digits 45. 约束组合逻辑(adr_i…...

学生考试作弊检测系统 yolov8
学生考试作弊检测系统采用yolov8网络模型人工智能技术,学生考试作弊检测系统过在考场中安装监控设备,对学生的作弊行为进行实时监测。当学生出现作弊行为时,学生考试作弊检测系统将自动识别并记录信息。YOLOv8 算法的核心特性和改动可以归结为…...

【基于容器的部署、扩展和管理】 3.2 基于容器的应用程序部署和升级
往期回顾: 第一章:【云原生概念和技术】 第二章:【容器化应用程序设计和开发】 第三章:【3.1 容器编排系统和Kubernetes集群的构建】 3.2 基于容器的应用程序部署和升级 3.2 基于容器的应用程序部署和升级 3.2 基于容器的应用程…...

Jmeter 实现 grpc服务 压测
一、Jmeter安装与配置 网上有很多安装与配置文章,在此不做赘述 二、Jmeter gRPC Request 插件安装 插件下载地址:JMeter Plugins :: JMeter-Plugins.org 将下载文件解压后放到Jmeter安装目录下 /lib/ext 然后在终端输入Jmeter即可打开 Jmeter GUI界面…...
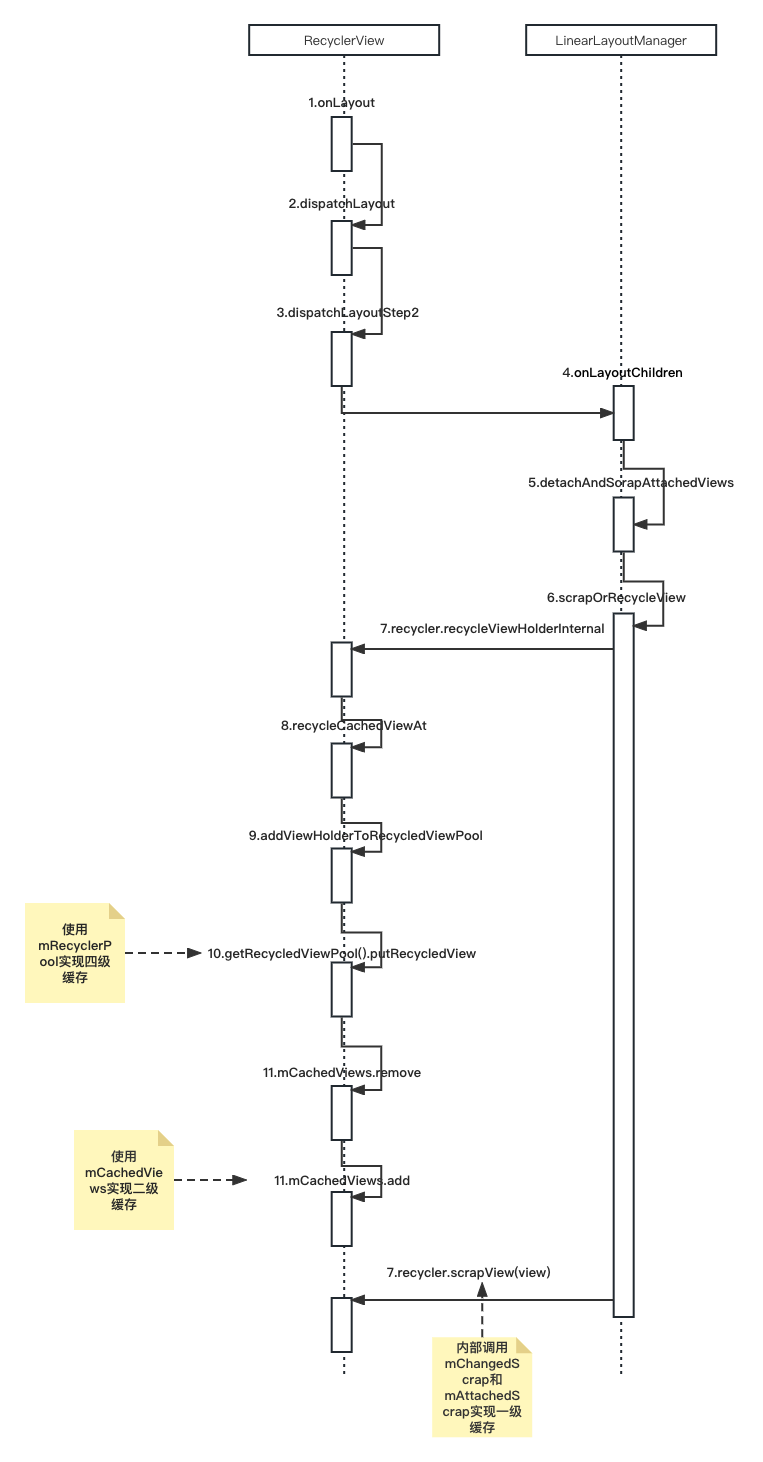
深入源码分析RecyclerView缓存复用原理
文章目录 前言四级缓存 源码分析缓存一级缓存(mChangedScrap和mChangedScrap)二级缓存(mCachedViews)三级缓存(ViewCacheExtension)四级缓存(mRecyclerPool)缓存池mRecyclerPool结构…...

内网隧道代理技术(一)之内网隧道代理概述
内网隧道代理技术 内网转发 在渗透测试中,当我们获得了外网服务器(如web服务器,ftp服务器,mali服务器等等)的一定权限后发现这台服务器可以直接或者间接的访问内网。此时渗透测试进入后渗透阶段,一般情况…...

设计图形用户界面的原则
1) 一般性原则:界面要具有一致性、常用操作要有快捷方式、 提供简单的错误处理、对操作人员的重要操作要有信息反馈、操作可 逆、设计良好的联机帮助、合理划分并高效地使用显示屏、保证信息 显示方式与数据输入方式的协调一致 2) 颜色的使用:颜色…...

1:操作系统导论
1.1操作系统的定义 •Anoperatingsystemactsanintermediarybetweenuserofacomputerandthecomputer hardware. ◦ 操作系统充当计算机⽤⼾和计算机硬件之间的中介 •Thepurposeofanoperatingsystemistoprovideanenvironmentinwhichausercanexecute programsinaconvenientandeff…...

什么是微软的 Application Framework?
我是荔园微风,作为一名在IT界整整25年的老兵,今天来看一下什么是微软的 Application Framework? 到底什么是 Application Framework? 还没有真正掌握任何一套Application Framework的使用之前,就来研究这个真的不是很…...

一个关于宏定义的问题,我和ChatGPT、NewBing、Google Bard、文心一言 居然全军覆没?
文章目录 一、问题重述二、AI 解题2.1 ChatGPT2.2 NewBing2.3 Google Bard2.4 文心一言2.5 小结 一、问题重述 今天在问答模块回答了一道问题,要睡觉的时候,又去看了一眼,发现回答错了。 问题描述:下面的z的值是多少。 #define…...

【服务器数据恢复】断电导致RAID无法找到存储设备的数据恢复案例
服务器数据恢复环境: HP EVA存储,6块SAS硬盘组建的raid5磁盘阵列。上层操作系统是WINDOWS SERVER。该存储为公司内部文件服务器使用。 服务器故障&分析: 在遭遇两次意外断电后,设备重启时raid提示“无法找到存储设备”。管理员…...
Windows上不可或缺的5款宝藏软件,工作效率拉满!
职场小白与大牛的区别:小白需要耗费大半天琢磨的事情,而大牛可以只花5分钟就能处理。 “牛人”,即拥有过人之处,专业、经验、技术等等,学会灵活运用高效率的工具也是关键的一点。工具找得好,运用得快&#…...
链表内指定区间反转
题目: 将一个节点数为 size 链表 m 位置到 n 位置之间的区间反转,要求时间复杂度 O(n),空间复杂度 O(1)。 例如: 给出的链表为 1→2→3→4→5→NULL,m2,n4 返回 1→4→3→2→5→NULL 数据范围ÿ…...

Vue中如何进行地图展示与交互(如百度地图、高德地图)?
Vue中如何进行地图展示与交互 随着移动互联网的普及,地图应用已经成为人们生活中不可或缺的一部分。在Vue.js中,我们可以使用第三方地图库(如百度地图、高德地图)来实现地图的展示和交互。本文将介绍如何在Vue.js中使用百度地图和…...

uni-app组件概述
1、组件 1.1、组件的含义 组件是视图层的基本组成单元。 组件是一个单独且可复用的功能模块的封装。 组件,包括:以组件名称为标记的开始标签和结束标签、组件内容、组件属性、组件属性值。 <component-name>是开始标签,</compon…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...