YouTubeDNN
这个youTubeDNN主要是工程导向,对于推荐方向的业界人士真的是必须读的一篇文章。它从召回到排序整个流程都做了描述,真正是在工业界应用的经典介绍。
作者首先说了在工业上YouTube视频推荐系统主要面临的三大挑战:
1.Scale(规模):视频数量非常庞大,大规模数据下需要分布时学习算法以及高效的线上服务系统。文中体现这一点的是召回模型线下训练的时候,采用了负采样的思路,线上服务的时候,采用了hash映射,然后近邻检索的方式来满足实时性的需求。
2.Freshness(新鲜度):YouTube上的视频是一个动态的,用户实时上传,且实时访问,那么这时候,最新的视频往往就容易博得用户的眼球,用户一般都比较喜欢看比较新的视频,而不管是不是真和用户相关,这时候,就需要模型有建模新上传内容以及用户最新发生的行为能力。为了让模型学习用户对新视频有偏好,后面策略里面加了一个"example age"作为体现。我们说的“探索与利用”中的探索,其实也是对新鲜度的把握。
3.Noise(噪声):由于数据的稀疏和不可见的其他原因,数据里面的噪声非常之多,这时候,就需要让这个推荐系统变得鲁棒。这个涉及到召回和排序两块,召回上需要考虑更多实际因素,比如非对称消费特性,高活用户因素,时间因素,序列因素等,并采取了相应的措施,而排序上做更加细致的特征工程,尽量的刻画出用户兴趣以及视频的特征 优化训练目标,使用加权的逻辑回归等。而召回和排序模型上,都采用了深度神经网络,通过特征的相互交叉,有了更强大的建模能力,相比于之前的MF(矩阵分解),建模能力上有了很大的提升,这些都有助于帮助减少噪声,使得推荐结果更加准确。
知道了挑战,那么下面就看看YouTubeDNN的整体推荐系统架构。
1. YouTubeDNN推荐系统架构
整个推荐架构图如下:

这个系统主要有两大部分组成:召回和排序。召回的目的是根据用户部分特征,从海量物品库,快速找到小部分用户潜在感兴趣的物品交给精排,重点强调快,精排主要是融入更多特征,使用复杂模型,来做个性化推荐,强调准。
对召回侧和精排侧再做一个具体描述:
1.召回侧:召回侧模型的输入一般是用户的点击历史,因为我们认为这些历史能更好的代表用户的兴趣,另外还有一些人口统计学特征,比如性别,年龄,地域等,都可以作为召回侧模型的输入。而最终模型的输出,就是与该用户相关的一个候选视频集合,量级的话一般是几百。
召回侧,大致上有两大类召回方式,一类是策略规则,一类是监督模型+embedding,其中策略规则,往往和真实场景有关,比如热度,历史重定向等等,不同场景会有不同的召回方式,这种属于"特异性"知识。监督模型+embedding思路是一种“普适”方法,目前主流的方法大致成几个系列,比如FM系列(FM,FFM等),用户行为序列,基于图和知识图谱系列,经典双塔系列等,这些方法看似很多很复杂,其实本质上还是给用户或者物品打embedding而已,只不过考虑的角度方式不同。这里的YouTubeDNN召回模型,也是这里的一种方式而已。
2.精排侧:召回那边对于每个用户,给出了几百个比较相关的候选视频,把几百万的规模降到了几百,当然,召回那边利用的特征信息有限,并不能很好的刻画用户和视频特点,所以,,在精排侧,主要是想利用更多的用户,视频特征,刻画特点更加准确些,从这几百个选出几个或者十几个推荐给用户。而涉及到准,主要的发力点一般有三个:特征工程,模型设计以及训练方法。这三个点本篇文章几乎都有涉及,除了模型设计有些审时度势之外,特征工程以及训练方法的处理上非常漂亮。
精排侧,这一块的大致发展趋势,从ctr预估到多目标,而模型演化上,从人工特征工程到特征工程自动化。主要有三大块,CTR预估主要分为了传统的LR,FM大家族,以及后面自动特征交叉的DNN家族,而多目标优化,目前是很多大公司的研究现状,更是未来的一大发展趋势,如何能让模型在各个目标上面的学习都能“游刃有余”是一件非常有挑战的事情,毕竟不同的目标可能会互相冲突,互相影响。
这两阶段的方法,就能保证我们从大规模视频库中实时推荐,又能保证个性化,吸引用户。当然,随着时间的发展,可能数据量非常非常大了,此时召回结果规模精排依然无法处理,所以现在一般还会再召回和精排之间,加一个粗排进一步筛选作为过渡,而随着场景越来越复杂,精排产生的结果也不能直接给到用户,而是会再后面家伙是那个一个重排后处理下。所以如今的漏斗,如下所示。

论文里面还提到了对模型的评估方面,线下评估的时候,主要是采用一些常用的评估指标(精确率,召回率,排序损失或者auc这种),但是最终看算法和模型的有效性,是通过A/B实验,再A/B实验中会观察用户真实行为,比如点击率,观看时长,留存率等,这些才是我们终极目标,而有时候,A/B实验的结果和线下我们用户的这些指标并不总是相关,这也是推荐系统这个场景的复杂性。我们往往也会用一些策略,比如修改模型的优化目标,损失函数这种,让线下的目标尽量和A/B衡量的这种指标相关性大一些。这篇文章也有提及,真的,想了解工业上的推荐系统,这篇paper必须读。
2. YouTubeDNN的召回模型细节剖析
召回模型的目的是在大量youtube视频中检索处数百个和用户相关的视频来。这个问题,我们可以看成一个多分类问题,即用户在某一个时刻点击了某个视频,可以建模成输入一个用户向量,从海量视频中预测出被点击的那个视频的概率。
换成比较准确的数学语言描述,在时刻t下,用户U在背景C下对每个视频i的观看行为建模成下面的公式:

2.1 召回模型结构
召回模型的网络结构图如下所示

它的输入主要是用户侧的特征,包括用户观看的历史video序列,用户搜索的历史tokens,然后就是用户的人文特征,比如地理位置,性别,年龄这些。这些特征处理上,和之前那些模型的也比较类似:
- 用户历史序列,用户搜索tokens这种序列性的特征:一般长这样[item_id5,item_id2,item_id3,...],这种id特征是高维稀疏,首先会通过一个embedding层,转成低维稠密的embedding特征,即历史序列里面的每个id都会对应一个embedding向量,这样历史序列就变成了多个embedding向量的形式,这些向量一般会进行融合,常见的是average pooling,即每一维求平均得到一个最终向量来表示用户的历史兴趣或搜索兴趣。
这里的embedding向量得到的方式,论文中通过word2vec得到的,也就是每个item事先通过w2v方式算好了的embedding,直接作为了输入,
然后进行pooling融合。除了这种算好embedding方式之外,还可以过embedding层,跟上面的DNN一起训练。- 用户人文特征,这种特征处理方式就是离散型的依然是labelencoder,然后embedding转成低维稠密,而连续型特征,一般是先归一化操作,然后直接输入。还有一波操作值得注意,就是连续型特征处理本身之外,还用了x^2,logx这种,可以加入更多非线性,增加模型表达能力
- 这里有一个比较特色的特征example age,这个后面单独整理。
这些特征处理好了之后,拼接起来,就成了一个非常长的向量,然后就是过DNN,这里用了一个三层的DNN,得到了输出,这个输出也是向量。
到这里,前向传播大致就说完了。最后这一步,就是多分类问题,然后求损失,这就是training做的事情。
再详细说training之前,我们放上word2vec里面的skip-gram model(中心词预测上下文词)的理解图

word2vec的核心思想是共现频率高的词相关性越大,所以skip-gram采用中心词预测上下文词的方式去训练词向量,用softmax操作将中心词与上下文词的相似程度转成概率。训练完成之后就可以得到中心词和上下文词的词向量。
有了word2vec的理解,再看youtubeDNN顶部就非常容易了。
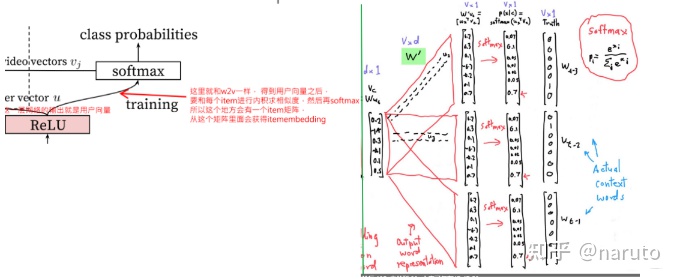
只看这里的过程,其实就是上面skip-gram过程,不一样的是右边这个中心词向量v_c是直接过了一个embedding层得到的,而左边这个用户向量u是用户的各个特征先拼接成一个大的向量,然后过一个DNN降维。训练方式上,这两个也是一样的,无非是左边的召回模型,多了几层全连接而已。
这样,也就很容易的理解,模型训练好了之后,用户向量和item向量到底哪里去了把。
--用户向量,其实就是全连接的DNN网络的输出向量,其实即使没有全连接,原始的用户各个特征拼接起来的那个长向量也能用,不过维度
可能太大了,所以DNN再这里的作用一个是特征交叉,另一个还有降维的功效。
--item向量,这个其实和skip-gram那个一样,每个item其实是有两个embedding向量的,比如skip-gram那里就有一个作为中心词时候的
embedding矩阵W和作为上下文词时候胡的embedding矩阵W',一般去的时候会取前面那个W作为每个词的词向量。这里其实一个道理,只不过
这里最前面的那个item向量矩阵是通过了w2v的方式训练好了直接作为DNN的输入,如果不事先计算好,对应的是embedding层得到的那个
矩阵。后面的item向量矩阵,就是这里得到用户向量之后,后面进行softmax之前的这个矩阵,YouTubeDNN最终是从这个矩阵里面拿item
向量(这句话 重要 重要 重要)。这就是知识串联的魅力,其实熟悉了word2vec,这个召回模型理解就非常简单。
这其实就是这个模型训练阶段最原始的剖析,实际训练的时候,依然是采用了优化方法,这个和word2vec也是一样,采用了负采样的方式,因为视频的数量太大,每次做多分类,最终那个概率分母上的加和就非常可怕了,所以就把多分类问题转成了多个二分类问题。也就是不用全部的视频,而是随机选择了一些没点的视频,标记为0,点了的视频标记为1,这样就成了二分类问题。

召回模型训练部分的基本操作就整理完了。但是再训练召回模型过程中,还有一些经验性的知识也是非常重要。
2.2 训练数据的选取和生成
模型训练的时候,为了计算更加高效,采用了负采样方法,但正负样本的选取,以及训练样本的来源,还有一些注意事项。
首先,训练样本来源于全部的youtube观看记录,而不仅仅是被推荐的观看记录。否则对于新视频会难以被曝光,会使得最终推荐结果有偏;同时系列也会采集用户从其他渠道观看的视频,从而可以快速应用到协同过滤中;
其次,是训练数据来源于用户的隐式数据,且用户看完了的视频作为正样本,注意这里式看完了,有一定的时长限制,而不仅仅曝光点击,有可能式误点的。而负样本,是从视频库里面随机选取,或者在曝光过的里面随机选取用户没看过的作为负样本。
这里的一个经验是训练数据中对于每个用户选取相同的样本数,保证用户在损失函数等权重,因为这样可以减少高度活跃用户对于loss的影响。可以改进线上A/B测试的效果。
这里的另一个经验是避免让模型知道不该知道的信息。这里作者举例一个例子如果模型知道用户最后的行为是搜索了"taylor swift",那么模型可能会倾向于推荐搜索页面搜"taylor swift"时搜索的视频,这个不是推荐模型期望的行为。解决方法时扔掉时序信息(把用户的历史行为等同看待),历史搜索tokens随机打乱,使用无序的搜索tokens来表示搜索queryies(average pooling)
还有一个信息泄露的问题,本文模型的测试集,用的是用户最近一次观看行为,后面的实验中,把用户最后一次点击放到了测试集里面,这样可以防止信息穿越。
2.3 Example Age 特征
这个特征是和场景比较相关的特征,也是作者的经验传授,有必要来认识一下。我们知道,视频有明显的生命周期,例如刚上传的视频比之后更受欢迎,也就是用户往往喜欢看最新的东西,而不管它是不是和用户相关,所以视频的流行度随着时间的分布是高度非稳态变化的(下图中的绿色曲线)

但是我们模型训练的时候,是基于历史数据训练的(历史观看记录的平均),所以模型对播放某个视频预测值的期望会倾向于其在训练时间内的平均播放概率(平均热度),上图中蓝色线。但如上面绿色线,实际上该视频在训练数据时间窗口内热度很可能不均与,用户本身就喜欢新上传的内容。所以,为了让模型学习到用户这种对新颖内容的bias,,作者引入了"example age"这个特征来捕捉视频的生命周期。
"example age"定义为t_max-t,其中t_max是训练数据中所有样本的时间最大值,而t是当前样本的时间。线上预测时,直接把example age全部设为0或者一个小的负值,这样就不依赖于各个视频的上传时间了。
关于这个特征更多维度的分析 可以看下其他大佬的分析。
其实这个操作, 现在常用的是位置上的除偏, 比如商品推荐的时候, 用户往往喜欢点击最上面位置的商品或广告, 但这个bias模型
依然是不知道, 为了让模型学习到这个东西, 也可以把商品或者广告的位置信息做成一个feature, 训练的时候告诉模型。 而线上
推理的那些商品, 这个feature也都用一样的。 异曲同工的意思有没有。那么这样的操作为啥会work呢? example age这个我理解,是有了这个特征, 就可以把某视频的热度分布信息传递给模型了, 比如某个
example age时间段该视频播放较多, 而另外的时间段播放较少, 这样模型就能发现用户的这种新颖偏好, 消除热度偏见。我这里理解是类似让模型消除位置偏见那样, 这里消除一种热度偏见。我理解是这样,假设没有这样一个example age特征表示视频新颖
信息,或者一个位置特征表示商品的位置信息,那模型训练的样本,可能是用户点击了这个item,就是正样本, 但此时有可能是用户真的
喜欢这个item, 也有可能是因为一些bias, 比如用户本身喜欢新颖, 用户本身喜欢点击上面位置的item等, 但模型推理的时候,都会
误认为是用户真的喜欢这个item。 所以,为了让模型了解到可能是存在后面这种bias, 我们就把item的新颖信息, item的位置信息等
做成特征, 在模型训练的时候就告诉模型,用户点了这个东西可能是它比较新或者位置比较靠上面等,这样模型在训练的时候, 就了解
到了这些bias,等到模型在线推理的时候呢, 我们把这些bias特征都弄成一样的,这样每个样品在模型看来,就没有了新颖信息和位置
信息bias(一视同仁了),只能靠着相关性去推理, 这样才能推到用户真正感兴趣的东西吧。2.4 线上服务
线上服务的时候,youtube采用了一种最近邻搜索的方法去完成topK的推荐,这其实时工程和学术的trade-off的结果,model serving过程中对几百万个候选集一一跑模型显然不现实,所有通过召回模型得到用户和video的embedding之后,用最近邻搜索的效率会快很多。
我们甚至不用把任何model inference的过程搬上服务器,只需要把user embedding和video embedding存到redis或者内存中就好了。like this:
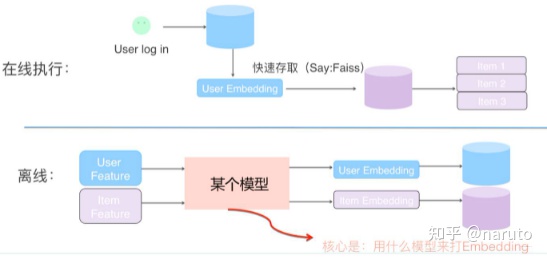
在线上,可以根据用户兴趣embedding,采用类似Faiss等高效Embedding检索工具,快速找出和用户兴趣匹配的物品,高效embedding检索工具,目前有接触两个:一个是Faiss,一个是annoy。具体参考我后面的参考文章。
我们做线上召回的时候,其实可以有两种:
- item_2_item:因为我们有了所有item的embedding了,那么就可以进行物品和物品之间相似度计算,每个物品得到近似的K个,这时候,就和协同过滤原理一样,之前通过用户观看过的历史item,就能进行相似找回了,工程实现上,一般会每个item建立一个相似度倒排表
- user_2_item:将item用faiss或者annoy组织成index,然后用user embedding去查相近item
召回环节基本介绍这些内容。接下来进入到排序环节。
3. YouTubeDNN排序模型细节剖析
排序模型面对的只是来自检索的数百候选视频,所以可以使用更多精细的特征,重点是精准预测。
检索出的数百候选视频可能来自于不同的检索模型,他们的检索得分无法直接对比。排序模型的另一个作用是融合这些来自不同检索模型的候选视频。
排序模型这块的特色,第一个是特征工程,第二个是优化目标。
3.1 模型结构

模型结构图如上,网络图很好理解。特色操作就是特征工程和优化目标了,具体看特色操作。
3.2 特征工程
排序模型用的特征主要分为两大类,一类是展示(impression)相关特征,如视频属性等,另一类是query相关属性,如user/context属性。
- impression video id embedding:当前要计算的video的embedding
- watched video ids:用户观看过的最近N个视频embedding,然后求pooling
- language embedding:用户语言embedding和视频embedding
这三个,就是上面两大类的代表,当然,还可以加入更多刻画视频和用户特点的特征,用户的年龄,性别,职业,位置等,视频的类别,上传时间,关键词等。
这种特征的处理方式很常规理论,类别特征需要embedding,连续特征需要归一化。但这里面提到的两个新的很有意思:
1.类别特征embedding的维度选择:建议选择与item物料库大小的对数比例,即embed dim正比于log(vocab size).如果某个类别的取值特别多,可以限定一个值,长尾的值对应的表示为全0的向量(这个也是一个工程和学术的trade-off,低频item的embedding学不好,干脆截断它)
2.作者发现对连续特征的归一化处理方式很影响训练的收敛性,但是作者在这里采用了一种累积分布归一化的方式,对于连续变量x,假设它的取值分布为f,通过以下公式把x归一化为 �~∈[0,1):�~=∫−∞��� ,就是 �~ 在x整体取值中的百分比排序位置。

但如果仅仅这种特征的话,那就没必要说了,后面这两个特征才是作者花大功夫做的。
- time since last watch:自上次观看同channel视频的时间
- #previous impressions:该视频已经被曝光给该用户的次数
这是作者提到的重要的特征,即能描述用户历史上与待评分视频,或类似视频已有的交互行为信息的特征,例如用户与待评分视频所在频道的交互历史:用户观看了次频道多少视频?用户最后一次观看同主题视频时什么时候?这些特征的泛化性很好,对待评分视频的预测很有帮助。
time since last watch这个特征来反映用户看同类视频的间隔时间。从用户的角度想一想,假如我们刚看过"DOTA 经典回顾"这个channel的视频,我们很大概率是会继续看这个channel的视频的,那么该特征就很好的捕捉到了这一用户行为。
另外一点经验,把召回模型的信息以特征形式传入排序模型也很有帮助。例如,哪些召回模型召回了这个候选视频?它们都给出了什么分数?
描述视频历史展示频率的特征对于在推荐中引入“流失”也很关键(连续的请求不会返回相同的列表)。如果最近给用户推荐了一个视频但用户没看,那么模型会在下一次页面加载时自动降低这个视频的展示可能。这个其实就是#previous impressions.#previous impressions一定程度上引入exploration的思想,避免同一个视频持续对同一用户进行无效曝光。尽量增加用户没看过的新视频的曝光可能性。
3.3 建模目标-用户观看时长
这里精排模型训练的目标函数和我们之前看到的不太一样。模型优化的目标时每次展示的平均观看时间。作者认为按点击率排序会倾向于诱惑用户点击(用户未必真感兴趣)的视频排前面,而观看时间能更好的反映出用户对视频的兴趣。并增加用户的watch time也更符合一个视频网站的长期利益和用户粘性。
王喆老师:这个问题看似很小,实则非常重要,objective的设定应该时一个算法模型的根本性问题,而且是算法模型部分跟其他部门
接口性的工作,从这个角度说,youtube的推荐模型符合其根本的商业模型,非常好的经验把训练看成一个二分类问题,其中训练数中的正样本是曝光点击的视频数据,负样本是曝光未点击的数据,优化目标是点击率,这是我们之前排序模型常用的目标。而这里想把目标变成优化平均观看时长,那么如何变化呢?
这里采用了加权的逻辑回归,将用户的watch time作为正样本的权重,线上serving的时候e^(wx+b)做预测,就能直接得到expected watch time 的近似。
那这究竟是怎么做的,为啥这么做可行,背后的原因是啥。
首先解决怎么做的:如何把目标变成优化平局怒观看时长呢?关键在于训练样本的权重,paper做的时候,是所有负样本的权重的都是1,而正样本的权重是点击后的视频观看时长T_i,模型最后计算损失的时候,是使用了加权交叉熵:

这里的T_i是观看时长。由于逻辑回归的表达式:

线上使用的时候,选取了值e^(f(xi))最大的那些视频进行推荐。
那么为什么优化这样的加权loss,就是近似优化平均观看时长呢?简单做下解释:
首先,我们熟知的大名鼎鼎的sigmoid函数并不是无脑拍出来的,而是由对数线性模型推导出来的。



采用e^(Wx+b)这个形式预测就近似用户观看视频时长的期望,用该指标排序后推荐,符合youtube推荐场景和以观看时长为优化目标
youtubeDNN模型的内容就整理这么多。
AI上推荐 之 YouTubeDNN模型(工业界推荐系统的灯火阑珊)
王喆:重读Youtube深度学习推荐系统论文,字字珠玑,惊为神文
相关文章:
YouTubeDNN
这个youTubeDNN主要是工程导向,对于推荐方向的业界人士真的是必须读的一篇文章。它从召回到排序整个流程都做了描述,真正是在工业界应用的经典介绍。 作者首先说了在工业上YouTube视频推荐系统主要面临的三大挑战: 1.Scale(规模)࿱…...
面向对象的介绍和内存
学习面向对象内容的三条主线 • Java 类及类的成员:(重点)属性、方法、构造器;(熟悉)代码块、内部类 • 面向对象的特征:封装、继承、多态、(抽象) • 其他关键字的使用…...

【数据可视化】Plotly Express绘图库使用
Plotly Express是一个基于Plotly库的高级Python可视化库。它旨在使绘图变得简单且直观,无需繁琐的设置和配置。通过使用Plotly Express,您可以使用少量的代码创建具有丰富交互性和专业外观的各种图表。以下是Plotly Express的一些主要特点和优势…...

小红书企业号限流原因有哪些,限流因素
作为企业、品牌在小红书都有官方账号,很多人将注册小红书企业号看作是获取品牌宣推“特权”的必行之举。事实真的如此吗,那为什么小红书企业号限流频发,小红书企业号限流原因有哪些,限流因素。 一、小红书企业号限流真的存在吗 首…...

1.6C++双目运算符重载
C双目运算符重载 C中的双目运算符重载指的是重载二元运算符,即有两个操作数的运算符,如加减乘除运算符“”、“-”、“*”和“/”等。 通过重载双目运算符,可以实现自定义类型的运算符操作。 比如可以通过重载加减运算符实现自定义类型的向…...

CDD诊断数据库的简单介绍
1. 什么是数据库? 数据库是以结构化方式组织的一个数据集合。 比如DBC数据库: Network nodes Display Rx Messages EngineState(0x123) 通过结构化的方式把网络节点Display里Rx报文EngineState(0x123)层层展开。这种方 式的好处是:层次清晰,结构分明,易于查找。 2. 什么…...

【笔试强训选择题】Day25.习题(错题)解析
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:笔试强训选择题 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!ÿ…...

Python心经(6)
目录 callable super type()获取对应类型 isinstance判断对象是否是某个类或者子类的实例 issubclass,判断对象是不是类的子孙类 python3的异常处理 反射: 心经第三节和第五节都写了些面向对象的,这一节补充一…...

MMPose安装记录
参考:GitHub - open-mmlab/mmpose: OpenMMLab Pose Estimation Toolbox and Benchmark. 一、依赖环境 MMPose 适用于 Linux、Windows 和 macOS。它需要 Python 3.7、CUDA 9.2 和 PyTorch 1.6。我的环境: Windows 11 Python 3.9 CUDA 11.6 PyTorch 1.13 …...

梯度下降优化
二阶梯度优化 1.无约束优化算法1.1最小二乘法1.2梯度下降法1.3牛顿法/拟牛顿法 2.一阶梯度优化2.1梯度的数学原理2.2梯度下降算法 3.二阶梯度优化梯度优化3.1 牛顿法3.2 拟牛顿法 1.无约束优化算法 在机器学习中的无约束优化算法中,除了梯度下降以外,还…...

一起看 I/O | 将 Kotlin 引入 Web
作者 / 产品经理 Vivek Sekhar 我们将在本文为您介绍 JetBrains 和 Google 的早期实验性工作。您可以观看今年 Google I/O 大会中的 WebAssembly 相关演讲,了解更多详情: https://youtu.be/RcHER-3gFXI?t604 应用开发者想要尽可能地在更多平台上最大限度地吸引用户…...
极致呈现系列之:Echarts地图的浩瀚视野(一)
目录 Echarts中的地图组件地图组件初体验下载地图数据准备Echarts的基本结构导入地图数据并注册展示地图数据结合visualMap展示地图数据 Echarts中的地图组件 Echarts中的地图组件是一种用于展示地理数据的可视化组件。它可以显示全国、各省市和各城市的地图,并支持…...
第四章 模型篇:模型训练与示例
文章目录 SummaryAutogradFunctions ()GradientBackward() OptimizationOptimization loopOptimizerLearning Rate SchedulesTime-dependent schedulesPerformance-dependent schedulesTraining with MomentumAdaptive learning rates optim.lr_scheluder Summary 在pytorch_t…...
利用人工智能模型学习Python爬虫
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 网络爬虫(又称为网页蜘蛛,网络机器人)是其中一种类型。 爬虫可以自动化浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则进行,这些规则我们称之为网络…...

.Net泛型详解
引言 在我们使用.Net进行编程的过程中经常遇到这样的场景:对于几乎相同的处理,由于入参的不同,我们需要写N多个重载,而执行过程几乎是相同的。更或者,对于几乎完成相同功能的类,由于其内部元素类型的不同&…...
——存储类)
C++ 教程(10)——存储类
存储类定义 C 程序中变量/函数的范围(可见性)和生命周期。这些说明符放置在它们所修饰的类型之前。下面列出 C 程序中可用的存储类: autoregisterstaticexternmutablethread_local (C11) 从 C 17 开始,auto 关键字不再是 C 存储…...

vue3+vite+element-plus创建项目,修改主题色
element-plus按需引入,修改项目的主题色 根据官方文档安装依赖 npm install -D unplugin-vue-components unplugin-auto-import vite.config.js配置 // vite.config.ts import { defineConfig } from vite import AutoImport from unplugin-auto-import/vite …...

mysql select是如何一步步执行的呢?
mysql select执行流程如图所示 server侧 在8.0之前server存在查询语句对应数据的缓存,不过在实际使用中比较鸡肋,对于更新比较频繁、稍微改点查询语句都会导致缓存无法用到 解析 解析sql语句为mysql能够直接执行的形式。通过词法分析识别表名、字段名等…...

找到距离最近的点,性能最好的方法
要找到距离最近的点并且性能最好,一种常用的方法是使用空间数据结构来加速搜索过程。以下是两个常见的数据结构和它们的应用: KD树(KD-Tree):KD树是一种二叉树数据结构,用于对k维空间中的点进行分割和组织…...

vue基础--重点
!1、vue的特性 !2、v-model 双向数据绑定指令 (data数据源变化,页面变化; 页面变化,data数据源也变化) 1、v-model 会感知到 框中数据变化 2、v-model 只有在表单元素中使用,才能…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。 尽管 VLMs 取得了显著进展,机器人仍难以胜任复杂的长时程任务(如家具装配),主要受限于人…...

yaml读取写入常见错误 (‘cannot represent an object‘, 117)
错误一:yaml.representer.RepresenterError: (‘cannot represent an object’, 117) 出现这个问题一直没找到原因,后面把yaml.safe_dump直接替换成yaml.dump,确实能保存,但出现乱码: 放弃yaml.dump,又切…...
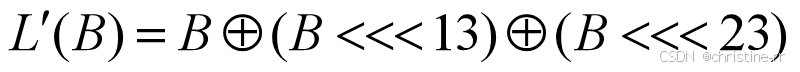
密码学基础——SM4算法
博客主页:christine-rr-CSDN博客 专栏主页:密码学 📌 【今日更新】📌 对称密码算法——SM4 目录 一、国密SM系列算法概述 二、SM4算法 2.1算法背景 2.2算法特点 2.3 基本部件 2.3.1 S盒 2.3.2 非线性变换 编辑…...

从实验室到产业:IndexTTS 在六大核心场景的落地实践
一、内容创作:重构数字内容生产范式 在短视频创作领域,IndexTTS 的语音克隆技术彻底改变了配音流程。B 站 UP 主通过 5 秒参考音频即可克隆出郭老师音色,生成的 “各位吴彦祖们大家好” 语音相似度达 97%,单条视频播放量突破百万…...