Python网络爬虫基础进阶到实战教程
文章目录
- 认识网络爬虫
- HTML页面组成
- Requests模块get请求与实战
- 效果图
- 代码解析
- Post请求与实战
- 代码解析
- 发送JSON格式的POST请求
- 使用代理服务器发送POST请求
- 发送带文件的POST请求
- Xpath解析
- XPath语法的规则集:
- XPath解析的代码案例及其详细讲解:
- 使用XPath解析HTML文档
- 使用XPath解析XML文档
- 处理命名空间的XPath解析
- BeautifulSoup详讲与实战
- 创建BeautifulSoup对象
- 遍历文档树
- 搜索文档树
- 获取节点属性和文本内容
- BeautifulSoup 代码案例讲解。
- 解析HTML文档并获取标题
- 遍历文档树并获取所有段落内容
- 使用CSS选择器搜索文档树
- 使用正则表达式搜索文档树
- 解析XML文档并获取节点信息
- 修改节点属性
- 正则表达式
- 正则表达式知识点
- 正则表达式案例
- 正则表达式实战
- 字体反爬
- Scrapy入门
- Scrapy实例
- 完结
认识网络爬虫

网络爬虫是指一种程序自动获取网页信息的方式,它能够自动化地获取互联网上的数据。通过使用网络爬虫,我们可以方便地获取到网络上的各种数据,例如网页链接、文本、图片、音频、视频等等。
HTML页面组成

网页是由HTML标签和内容组成,HTML标签通过标签属性可以定位到需要的内容。网页中的样式由CSS控制,JavaScript可以实现网页动态效果。
HTML标签是一种用于构建Web页面的标记语言,它描述了页面的结构和元素。HTML标签通常包含一个起始标签和一个结束标签,例如<div>和</div>。HTML标签也可以包含属性,属性用于提供有关元素的额外信息。例如,<a>元素的href属性指定了链接目标的URL地址,而<img>元素的src属性指定了要显示的图像文件的URL地址。
CSS是一种用于控制Web页面样式的样式表语言,它可以为HTML元素提供样式和布局。通过CSS,我们可以控制文本的字体、颜色、大小和样式,以及元素的大小、位置、边框和背景等。
JavaScript是用于实现Web页面动态效果的一种编程语言,它可以实现网页上的各种交互效果,例如弹出窗口、表单验证、动画效果等。
Requests模块get请求与实战
Requests是Python中的HTTP库,提供了简洁易用的接口进行HTTP请求。其中,GET请求常用于获取静态网页信息。
我们通过requests.get()方法来发送一个GET请求.
import requestsurl = 'https://www.baidu.com'
response = requests.get(url)
print(response.text)
效果图

代码解析
第一行导入了requests模块,第二行指定了要请求的URL地址,在本例中我们使用百度首页作为示例。第三行使用requests库的get()方法来获取该URL的响应对象。响应对象包含了服务器返回的所有信息,包括Header(头部)和Body(主体)两部分。其中Header包含了很多信息,如日期、内容类型、服务器版本等,而Body包含了页面HTML源代码等具体信息。
第四行使用print()函数打印出响应内容的文本形式。运行这段代码,我们就可以在终端中看到百度首页的HTML源代码。
在实际爬虫中,我们可以利用requests模块的一些属性或者方法来解析响应内容,提取需要的数据。例如,可以使用response.status_code属性来获取HTTP状态码,使用response.headers属性来获取HTTP头部信息等。此外,我们还可以使用response.json()方法来解析JSON格式的响应内容,使用response.content方法来获取字节形式的响应内容等。
Post请求与实战
POST请求与GET请求的区别在于,POST请求会将请求参数放在请求体中,而GET请求则将请求参数放在URL中。通常情况下,POST请求比GET请求更安全,因为它可以隐藏请求参数。
我们通过requests.post()方法来发送一个POST请求,下面是详细的代码分析:
import requestsurl = 'http://xxxx.org/post' # 这里使用xxxx.org来演示POST请求
data = {'key1': 'value1', 'key2': 'value2'}
response = requests.post(url, data=data)
print(response.text)
代码解析
第一行导入了requests模块,
第二行指定了要请求的URL地址 。
第三行定义了请求参数data,这个字典中包含了两个键值对,分别表示key1和key2这两个参数的值。第四行使用requests库的post()方法来发送POST请求并获取响应对象。
我们通过data参数将请求参数放在请求体中,这里使用了字典类型作为请求参数。第五行使用print()函数打印出响应内容的文本形式。运行这段代码,我们就可以在终端中看到xxxx.org返回的响应内容,其中包括了我们发送的请求参数。
在实际爬虫中,我们可以利用requests模块的一些属性或者方法来解析响应内容,提取需要的数据。
发送JSON格式的POST请求
import requests
import jsonurl = 'http://xxxx.org/post' # 这里使用xxxx.org来演示POST请求
data = {'key1': 'value1', 'key2': 'value2'}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json.dumps(data), headers=headers)
print(response.text)
在这个案例中,我们将请求参数data转换成JSON格式,并使用headers来指定Content-Type为application/json。然后,我们通过requests库的post()方法来发送POST请求。
使用代理服务器发送POST请求
import requestsproxy = {'http': 'http://10.10.1.10:3128','https': 'https://10.10.1.10:1080'
}
url = 'http://xxxx.org/post' # 这里使用xxxx.org来演示POST请求
data = {'key1': 'value1', 'key2': 'value2'}
response = requests.post(url, data=data, proxies=proxy)
print(response.text)
在这个案例中,我们通过proxy字典来指定代理服务器的地址和端口号。然后,我们通过requests库的post()方法来发送POST请求。
发送带文件的POST请求
import requestsurl = 'http://xxxx.org/post' # 这里使用xxxx.org来演示POST请求
files = {'file': open('myfile.txt', 'rb')}
response = requests.post(url, files=files)
print(response.text)
在这个案例中,我们通过files参数来指定要上传的文件。
open()函数打开文件,第一个参数是文件名,第二个参数是打开方式(rb表示二进制只读模式)。然后,我们通过requests库的post()方法来发送POST请求。
Xpath解析

XPath是一种用于选择XML文档中某些部分的语言。在Python中,我们可以使用lxml库来解析XML文档并使用XPath进行选择。
XPath语法主要由路径表达式和基本表达式构成。其中,路径表达式用于选择节点或者节点集合,而基本表达式用于指定某个元素、属性或者其他内容。
XPath语法的规则集:
| 表达式 | 描述 |
|---|---|
| nodename | 选择所有名为nodename的元素 |
| / | 从当前节点选取根节点 |
| // | 从当前节点选取任意节点 |
| . | 选择当前节点 |
| … | 选择当前节点的父节点 |
| @ | 选择属性 |
| * | 匹配任何元素节点 |
| [@attrib] | 选择具有给定属性的所有元素 |
| [@attrib=‘value’] | 选择具有给定属性值的所有元素 |
| tagname[text() = ‘text’] | 选择具有给定文本的所有tagname元素 |
XPath解析的代码案例及其详细讲解:
使用XPath解析HTML文档
from lxml import etree
import requestsurl = 'https://www.baidu.com'
html = requests.get(url).text
selector = etree.HTML(html)
result = selector.xpath('//title/text()')
print(result[0])
案例中,我们首先发送了一个GET请求获取百度首页的HTML源代码。然后,我们使用lxml库中的etree模块来构建一个XPath解析器,并将HTML源代码传给它进行解析。接着,我们使用XPath表达式’//title/text()'来选择HTML文档中title标签的内容。最后,我们打印出XPath语句返回的结果。
使用XPath解析XML文档
from lxml import etreexml = '''
<bookstore><book category="cooking"><title lang="en">Everyday Italian</title><author>Giammarco Tomaselli</author><year>2010</year><price>30.00</price></book><book category="children"><title lang="en">Harry Potter</title><author>J.K. Rowling</author><year>2005</year><price>29.99</price></book>
</bookstore>
'''selector = etree.XML(xml)
result = selector.xpath('//book[1]/title/text()')
print(result[0])
案例中,我们定义了一个XML字符串,并使用etree.XML()方法来创建一个XPath解析器。然后,我们使用XPath表达式’//book[1]/title/text()'来选择XML文档中第一个book元素的title元素的内容。最后,我们打印出XPath语句返回的结果。
处理命名空间的XPath解析
from lxml import etreexml = '''
<ns:bookstore xmlns:ns="http://www.example.com"><ns:book category="cooking"><ns:title lang="en">Everyday Italian</ns:title><ns:author>Giammarco Tomaselli</ns:author><ns:year>2010</ns:year><ns:price>30.00</ns:price></ns:book><ns:book category="children"><ns:title lang="en">Harry Potter</ns:title><ns:author>J.K. Rowling</ns:author><ns:year>2005</ns:year><ns:price>29.99</ns:price></ns:book>
</ns:bookstore>
'''selector = etree.XML(xml)
ns = {'ns': 'http://www.example.com'}
result = selector.xpath('//ns:book[1]/ns:title/text()', namespaces=ns)
print(result[0])
案例中,我们定义了一个带有命名空间的XML字符串,并使用etree.XML()方法来创建一个XPath解析器。然后,我们通过传递一个namespaces参数来指定命名空间的前缀和URI。最后,我们使用XPath表达式’//ns:book[1]/ns:title/text()'来选择第一个book元素的title元素的内容。最后,我们打印出XPath语句返回的结果。
BeautifulSoup详讲与实战
BeautifulSoup是常用的Python第三方库,它提供了解析HTML和XML文档的函数和工具。使用BeautifulSoup可以方便地遍历和搜索文档树中的节点,获取节点属性和文本内容等信息
创建BeautifulSoup对象
首先我们需要导入BeautifulSoup模块:
from bs4 import BeautifulSoup
使用BeautifulSoup对HTML文档进行解析,可以通过以下两种方式:
(1) 传递一个HTML字符串作为参数:
html_doc = """
<html>
<head><title>这是标题</title></head>
<body>
<p class="para1">第一段落</p>
<p class="para2">第二段落</p>
</body>
</html>
"""soup = BeautifulSoup(html_doc, 'html.parser')
(2) 传递一个文件路径或文件对象作为参数:
with open('example.html', 'r') as f:soup = BeautifulSoup(f, 'html.parser')
遍历文档树
很多时候,我们需要遍历整个文档树来查找特定的节点,或者获取节点的属性和文本内容。BeautifulSoup提供了多种遍历文档树的方法,包括:
(1) .contents:返回一个包含所有子节点的列表。
for child in soup.body.contents:print(child)
(2) .children:返回一个包含所有子节点的迭代器。
for child in soup.body.children:print(child)
(3) .descendants:返回一个包含文档树中所有子孙节点的迭代器。
for element in soup.descendants:print(element)
(4) .parent:返回一个节点的父节点。
p = soup.body.p
print(p.parent)
(5) .parents:返回一个包含节点所有祖先节点的迭代器。
p = soup.body.p
for parent in p.parents:print(parent.name)
搜索文档树
搜索文档树是BeautifulSoup的另一个重点。BeautifulSoup提供了几个搜索方法
(1) .find_all():返回一个满足条件的节点列表。
soup.find_all('p', class_='para1')
soup.find_all('p', {'class': 'para1'}, string='第一段落')
(2) .find():返回第一个满足条件的节点。
soup.find('p', class_='para1')
soup.find('p', {'class': 'para1'}, string='第一段落')
(3) .select():使用CSS选择器语法返回满足条件的节点列表。
soup.select('p.para1')
soup.select('p[class="para1"]')
获取节点属性和文本内容
获取节点的属性和文本内容也是常用的操作。BeautifulSoup提供了下面这些方法:
(1) .get():获取节点的指定属性。
p = soup.find('p', class_='para1')
print(p.get('class'))
(2) .text:获取节点的文本内容。
p = soup.find('p', class_='para1')
print(p.text)
(3) .string:获取节点的文本内容(如果节点只有一个子节点且该子节点是字符串类型)。
p = soup.find('p', class_='para1')
print(p.string)
BeautifulSoup 代码案例讲解。
解析HTML文档并获取标题
from bs4 import BeautifulSoup
import requestsurl = 'https://www.baidu.com'
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
title = soup.title.string
print(title)
案例中,我们首先发送了一个GET请求获取百度首页的HTML源代码。然后,我们使用BeautifulSoup来创建一个HTML解析器,并将HTML源代码传给它进行解析。接着,我们通过soup.title.string获取HTML文档中title标签的内容,并打印出结果。
遍历文档树并获取所有段落内容
from bs4 import BeautifulSouphtml_doc = """
<html>
<head><title>这是标题</title></head>
<body>
<p class="para1">第一段落</p>
<p class="para2">第二段落</p>
</body>
</html>
"""soup = BeautifulSoup(html_doc, 'html.parser')
for p in soup.body.children:if p.name == 'p':print(p.string)
案例中,我们创建了一个HTML字符串,并使用BeautifulSoup来创建一个HTML解析器。然后,我们通过soup.body.children遍历整个文档树,查找所有的p标签,并打印出每个标签的文本内容。
使用CSS选择器搜索文档树
from bs4 import BeautifulSouphtml_doc = """
<html>
<head><title>这是标题</title></head>
<body>
<p class="para1">第一段落</p>
<p class="para2">第二段落</p>
</body>
</html>
"""soup = BeautifulSoup(html_doc, 'html.parser')
p_list = soup.select('p.para1')
for p in p_list:print(p.text)
案例中,我们创建了一个HTML字符串,并使用BeautifulSoup来创建一个HTML解析器。然后,我们使用CSS选择器’p.para1’搜索文档树,并获取所有满足条件的p标签。最后,我们遍历p列表,并打印出每个标签的文本内容。
好的,接下来我再给出三个代码案例。
使用正则表达式搜索文档树
import re
from bs4 import BeautifulSouphtml_doc = """
<html>
<head><title>这是标题</title></head>
<body>
<p class="para1">第一段落</p>
<p class="para2">第二段落</p>
</body>
</html>
"""soup = BeautifulSoup(html_doc, 'html.parser')
pattern = re.compile('^p.*?1$') # 匹配所有以p开头并且以1结尾的类名
p_list = soup.find_all(class_=pattern)
for p in p_list:print(p.text)
案例中,我们使用了Python的re模块来创建了一个正则表达式pattern。然后,我们使用soup.find_all(class_=pattern)来搜索文档树,获取所有满足条件的标签,并遍历列表打印出每个标签的文本内容。
解析XML文档并获取节点信息
from bs4 import BeautifulSoupxml_doc = """
<?xml version="1.0" encoding="UTF-8"?>
<data><country name="Liechtenstein"><rank>1</rank><year>2008</year><gdppc>141100</gdppc><neighbor name="Austria" direction="E"/><neighbor name="Switzerland" direction="W"/></country><country name="Singapore"><rank>4</rank><year>2011</year><gdppc>59900</gdppc><neighbor name="Malaysia" direction="N"/></country>
</data>
"""soup = BeautifulSoup(xml_doc, 'xml')
for country in soup.find_all('country'):print(country['name'])print(country.rank.text)print(country.year.text)print(country.gdppc.text)for neighbor in country.find_all('neighbor'):print(neighbor['name'], neighbor['direction'])
案例中,我们创建了一个XML字符串,并使用BeautifulSoup来创建一个XML解析器。然后,我们使用soup.find_all()方法搜索文档树,获取所有满足条件的标签,并遍历它们打印出相关信息。
修改节点属性
from bs4 import BeautifulSouphtml_doc = """
<html>
<head><title>这是标题</title></head>
<body>
<p class="para1">第一段落</p>
<p class="para2">第二段落</p>
</body>
</html>
"""soup = BeautifulSoup(html_doc, 'html.parser')
p = soup.find('p', class_='para1')
p['class'] = 'new_class'
print(p)
案例中,我们创建了一个HTML字符串,并使用BeautifulSoup来创建一个HTML解析器。然后,我们使用soup.find()方法搜索文档树,获取第一个满足条件的p标签。接着,我们通过p[‘class’]操作修改了标签的class属性,并打印出修改后的标签。
正则表达式
正则表达式知识点
正则表达式是一种用于匹配字符串的模式。它通过字符组成规则定义了搜索文本中特定模式的方法。Python中的re模块提供了使用正则表达式的功能。
常用的正则表达式元字符:
- . 表示任意字符。
- \d表示数字,\D表示非数字。
- \w表示单词字符,即az、AZ、0~9和下划线。
- \W表示非单词字符。
- \s表示空白符,包括空格、制表符、换行符等。
- \S表示非空白符。
- ^表示匹配行首。
- $表示匹配行尾。
- *表示匹配前面的字符零次或多次。
- +表示匹配前面的字符一次或多次。
- ?表示匹配前面的字符零次或一次。
- {m}表示匹配前面的字符m次。
- {m,n}表示匹配前面的字符m到n次。
- […]表示匹配方括号中任意一个字符。
- [^…]表示匹配除了方括号中给出的字符以外的任意一个字符。
- (…)表示匹配括号中的表达式。
re模块中常用的函数:
- re.match():从字符串的开头开始匹配,只匹配一次。
- re.search():在字符串中匹配第一个符合条件的内容。
- re.findall():在字符串中匹配所有符合条件的内容并以列表的形式返回。
- re.sub():用一个新的字符串替换掉匹配到的所有内容。
- re.compile():将正则表达式转化为一个正则表达式对象,以便于复用。
正则表达式案例
(1) 匹配手机号码
import rephone_nums = ['13912345678', '13812345678', '13512345678', '13612345678', '13712345678']pattern = r'^1[3-9]\d{9}$'
for phone_num in phone_nums:if re.match(pattern, phone_num):print(f'{phone_num}是一个合法的手机号码')else:print(f'{phone_num}不是一个合法的手机号码')
代码演示了如何使用正则表达式匹配手机号码。
首先,我们定义了一个包含多个手机号码的列表,并创建了一个正则表达式对象pattern。该正则表达式匹配以1开头的11位数字字符串,其中第二位数字介于3和9之间。然后,我们使用re.match()方法对每个手机号码进行匹配,并打印结果。
(2) 替换HTML文档中的标签
import rehtml_doc = """
<html>
<head><title>这是标题</title></head>
<body>
<p class="para1">第一段落</p>
<p class="para2">第二段落</p>
</body>
</html>
"""pattern = r'<.*?>'
new_doc = re.sub(pattern, '', html_doc)
print(new_doc)
代码演示了如何使用正则表达式替换HTML文档中的标签。
首先,我们定义了一个包含HTML标签的字符串,并创建了一个正则表达式对象pattern。该正则表达式匹配任意HTML标签,并将其替换为空字符串。然后,我们使用re.sub()方法对HTML文档进行替换,并打印结果。
(3) 提取金融数据
import retext = '2019年GDP增速为7.5%,同比增长0.3个百分点;CPI同比上涨2.5%,环比上涨0.3%。'pattern1 = r'\d+.\d+%'
pattern2 = r'[A-Z]+'
num_list = re.findall(pattern1, text)
unit_list = re.findall(pattern2, text)
for i in range(len(num_list)):print(f'{num_list[i]} {unit_list[i]}')
代码演示了如何使用正则表达式提取金融数据。
首先,我们定义了一个包含金融数据的字符串,并创建了两个正则表达式对象pattern1和pattern2。其中,pattern1匹配百分数,pattern2匹配单位符号。然后,我们使用re.findall()方法分别提取百分数和单位符号,并以列表的形式返回。最后,我们使用for循环遍历两个列表,并将相同位置上的元素打印在一起。
正则表达式实战
代码是一个简单的Python脚本,可以用于统计某个文件夹下所有文本文件中各个单词的出现频率,并输出前十个出现频率最高的单词及其出现次数。在代码中,我们将使用正则表达式来去除标点符号、换行符等非单词字符,以便于单词的准确统计。
import os
import re
from collections import Counterdef get_word_counts(folder_path):"""统计指定文件夹中所有文本文件中各个单词的出现频率,并返回一个Counter对象。"""word_counter = Counter()for root, dirs, files in os.walk(folder_path):for file in files:if file.endswith('.txt'):file_path = os.path.join(root, file)# 读取文本文件内容with open(file_path, 'r', encoding='utf-8') as f:text = f.read()# 使用正则表达式去除标点符号、换行符等非单词字符pattern = r'\b\w+\b'words = re.findall(pattern, text)# 对单词列表进行计数,并将结果更新到Counter对象中word_counter.update(words)return word_counterif __name__ == '__main__':folder_path = 'test'word_counter = get_word_counts(folder_path)# 输出前十个出现频率最高的单词及其出现次数top_n = 10print(f'Top {top_n} words:')for word, count in word_counter.most_common(top_n):print(f'{word:<10} {count}')
代码中的
get_word_counts()函数用于统计指定文件夹中所有文本文件中各个单词的出现频率,并返回一个Counter对象。在函数中,我们使用了Python内置的os和collections模块,以便于对文件和单词计数进行操作。
os.walk()方法可以遍历指定文件夹下所有子文件夹中的文件,比如我们指定的folder_path文件夹。然后,我们对每个文本文件进行读取,并使用正则表达式去除标点符号、换行符等非单词字符,以便于单词的准确统计。最后,我们使用Counter对象来对单词列表进行计数,并将结果更新到该对象中。
在主程序中,我们调用
get_word_counts()函数来获取单词计数结果,并输出前十个出现频率最高的单词及其出现次数。在这里,我们使用了most_common()方法来获取前N个出现频率最高的单词及其出现次数,并使用字符串格式化输出结果。
字体反爬
字体反爬是一种常见的网站反爬手段,即将大部分文本内容通过特定的字体进行加密混淆,以防止爬虫直接抓取数据。通常情况下,爬虫需要先解密字体,然后才能正常获取到文本内容。
常用的字体反爬解密方法有以下几种:
- 解析woff文件
很多网站会使用woff格式的字体文件来渲染文本内容,爬虫需要先下载这些字体文件,并解析出字符与字形之间的对应关系,然后才能正常解密文本内容。
- 使用fontTools库
Python中有一个非常优秀的字体解析库叫做fontTools,可以帮助我们轻松地解析字体文件,并生成字形对应表。使用该库可以避免自行解析字体文件所遇到的各种问题。
- 使用在线字体解密工具
有些网站提供了在线字体解密工具,如FontSpider、字体反爬插件等,可以帮助我们快速地解密字体。不过,使用这种方法需要注意隐私安全问题。
(1) 解析woff文件
import base64
from fontTools.ttLib import TTFont# 下载字体文件并保存为base64编码字符串
font_url = 'http://example.com/font.woff'
font_base64 = '...'# 将base64编码字符串解码并保存到本地
with open('font.woff', 'wb') as f:font_data = base64.b64decode(font_base64)f.write(font_data)# 解析字体文件并获取字形对应表
font = TTFont('font.woff')
cmap = font.getBestCmap()# 定义替换规则
replace_dict = {'连': '0','': '1','﫵': '2','': '3','': '4','': '5','': '6','': '7','倫': '8','': '9',
}# 替换文本内容
text = ''
for key, value in replace_dict.items():text = text.replace(key, value)# 输出结果
print(text)
代码演示了如何解析woff文件,并使用字形对应表来解密文本内容。首先,我们将从网站上下载字体文件,并保存为base64编码字符串。然后,我们将该编码字符串解码并保存到本地。接下来,我们使用fontTools库读取字体文件,并获取其中的字形对应表。需要注意的是,不同字体文件对应的字形对应表可能不同,因此需要根据具体情况来确定使用哪个表。
我们定义了一个替换规则字典replace_dict,其中包含了从未解密的字符到明文字符的映射关系。最后,我们使用字符串的replace()方法将未解密的文本内容替换为明文,从而得到结果。
(2) 使用fontTools库
import requests
from io import BytesIO
from fontTools.ttLib import TTFont# 下载字体文件并用fontTools库读取
font_url = 'http://example.com/font.woff'
font_data = requests.get(font_url).content
font = TTFont(BytesIO(font_data))# 获取字形对应表
cmap = font.getBestCmap()# 定义替换规则
replace_dict = {'连': '0','': '1','﫵': '2','': '3','': '4','': '5','': '6','': '7','倫': '8','': '9',
}# 解密文本内容
text = ''
for key, value in replace_dict.items():glyph_id = cmap[int(key[3:-1], 16)]text = text.replace(key, value)# 输出结果
print(text)
代码演示了如何使用fontTools库解析字体文件,并生成字形对应表。首先,我们使用requests库从网站上下载字体文件,并使用BytesIO将字节流转换为文件。然后,我们使用fontTools库读取该文件,并获取其中的字形对应表。需要注意的是,通过这种方式获取到的字形对应表可能与其他方式获取到的表略有不同,因此需要进行实验来确定使用哪个表。
我们定义了一个替换规则字典replace_dict,并使用字符串的replace()方法将未解密的文本内容替换为明文,从而得到结果。
(3) 使用在线字体解密工具
import requests
from fontSpider import FontSpider# 下载字体文件并保存为base64编码字符串
font_url = 'http://example.com/font.woff'
r = requests.get(font_url)
font_base64 = FontSpider(r.content).to_base64()# 使用在线字体解密工具解密文本内容
text = ''
response = requests.post('http://font-spider.com/api/v1/decrypt', data={'font': font_base64, 'text': text})
result = response.json()# 输出结果
print(result['data'])
代码演示了如何使用在线字体解密工具来解密文本内容。首先,我们从网站上下载字体文件,并使用FontSpider库将其转换为base64编码字符串。然后,我们使用requests库向在线字体解密工具发送POST请求,并将字体文件和未解密的文本内容作为参数传递。该工具会自动解密文本内容,并返回解密后的结果。最后,我们从响应结果中提取出解密后的文本内容,并输出结果。
需要注意的是,使用在线字体解密工具可能存在隐私安全问题,因此尽量避免在生产环境中使用。
Scrapy入门
Scrapy是一个基于Python的快速、高效的Web爬虫框架,可用于数据抓取、信息处理以及存储的开发。它是一个专业的爬虫框架,提供了许多必要的功能,如请求调度、数据解析,以及数据存储等。Scrapy可以自动下载网页,并提供了XPath以及CSS选择器等多种方法,支持多线程和分布式爬取,并可以通过插件扩展其功能。
- 工程结构
Scrapy的工程具有标准的项目结构,通常包含以下几个文件:
- scrapy.cfg:Scrapy项目配置文件。
- items.py:定义爬取的数据结构。
- middlewares.py:管理请求和响应,例如User-Agent、代理等。
- pipelines.py:配置到底怎么样后续处理item。
- settings.py:保存爬虫的参数设置。
- spiders/:保存爬虫代码的目录。
- 爬虫流程
Scrapy的爬虫流程如下:
- 发起请求:通过定义好的URL地址来发送HTTP请求。
- 下载页面:Scrapy会自动下载对应的页面,或使用第三方库,如requests、Selenium等。
- 解析页面:使用XPath或CSS选择器解析网页内容。
- 保存数据:将解析得到的数据保存到本地或数据库中。
- Scrapy组件
Scrapy具有以下几个重要组件:
- Spider:定义如何抓取某个站点,包括如何跟进链接、如何分析页面内容等。
- Item:定义爬取的数据结构。
- Pipeline:负责处理Item,如清理、过滤、存储到数据库等。
- Downloader:负责下载网页,并将结果传递给Spider。
- Scheduler:负责调度Spider发起请求,并将结果传递给Downloader。
Scrapy实例
- 爬取豆瓣电影TOP250的数据
import scrapyclass DoubanMovieSpider(scrapy.Spider):name = 'douban_movie'allowed_domains = ['movie.douban.com']start_urls = ['https://movie.douban.com/top250']def parse(self, response):for info in response.xpath('//div[@class="info"]'):yield {'title': info.xpath('div[@class="hd"]/a/span/text()').extract_first(),'score': info.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract_first(),'director': info.xpath('div[@class="bd"]/p/text()')[0].strip() if len(info.xpath('div[@class="bd"]/p')) == 2 else '','year': info.xpath('div[@class="bd"]/p/text()')[-1].strip().replace('(', '').replace(')', '') if len(info.xpath('div[@class="bd"]/p')) == 2 else info.xpath('div[@class="bd"]/p/text()')[-1].strip()}next_page = response.xpath('//span[@class="next"]/a/@href')if next_page:yield scrapy.Request(url=response.urljoin(next_page.extract_first()), callback=self.parse)
代码演示了如何使用Scrapy爬取豆瓣电影TOP250的数据。
首先,我们定义了一个名为DoubanMovieSpider的爬虫类,并设置了访问URL。在parse()函数中,我们首先使用XPath选择器来解析电影数据,然后通过yield关键字返回一个Python字典,字典的键是电影标题、评分、导演和年份。接着,我们使用XPath选择器获取下一页的链接,并使用yield关键字发送一个HTTP请求,进入下一页继续执行parse()函数。
- 使用middlewares设置User-Agent
import random
from scrapy.downloadermiddlewares.useragent import UserAgentMiddlewareclass RandomUserAgentMiddleware(UserAgentMiddleware):user_agents = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36','Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36','Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36','Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; AS; rv:11.0) like Gecko','Mozilla/5.0 (Windows NT 6.3; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299']def process_request(self, request, spider):user_agent = random.choice(self.user_agents)request.headers.setdefault('User-Agent', user_agent)
代码演示了如何使用middlewares设置User-Agent。我们首先创建RandomUserAgentMiddleware类,并继承自Scrapy提供的UserAgentMiddleware类,然后定义user_agents列表,保存多种User-Agent。接着,我们重载process_request()函数,并随机选择一个User-Agent,将其添加到HTTP请求头中。
- 将数据写入MySQL数据库
import pymysql
from scrapy.exceptions import DropItemclass MysqlPipeline(object):def __init__(self, mysql_host, mysql_db, mysql_user, mysql_pwd, mysql_table):self.mysql_host = mysql_hostself.mysql_db = mysql_dbself.mysql_user = mysql_userself.mysql_pwd = mysql_pwdself.mysql_table = mysql_tabledef process_item(self, item, spider):if item['title'] and item['score']:db = pymysql.connect(host=self.mysql_host, user=self.mysql_user, password=self.mysql_pwd, db=self.mysql_db)cursor = db.cursor()sql = "INSERT INTO %s (title, score, director, year) VALUES ('%s', '%s', '%s', '%s')" % (self.mysql_table, item['title'], item['score'], item['director'], item['year'])try:cursor.execute(sql)db.commit()except Exception as e:db.rollback()raise DropItem("Failed to insert item: {}".format(e))finally:db.close()return item
代码演示了如何将数据写入MySQL数据库。我们首先定义了一个名为MysqlPipeline的类,并继承自一个Scrapy提供的基本管道类。在__init__()函数中,我们从配置文件或命令行参数中获取MySQL的连接参数,包括主机、数据库名、用户名、密码以及数据表名。在process_item()函数中,我们判断需要保存的数据是否为空,并使用pymysql库连接数据库。然后,我们执行SQL插入语句,并在发生错误时进行回滚操作。最后,在finally中关闭数据库连接。
完结

相关文章:
Python网络爬虫基础进阶到实战教程
文章目录 认识网络爬虫HTML页面组成Requests模块get请求与实战效果图代码解析 Post请求与实战代码解析 发送JSON格式的POST请求使用代理服务器发送POST请求发送带文件的POST请求 Xpath解析XPath语法的规则集:XPath解析的代码案例及其详细讲解:使用XPath解…...
树莓派使用VNC、SSH、Xrdp等方式进行远程控制的方法和注意事项
下面来总结一下远程操控树莓派用到的三种方式及其注意事项,其实这三种方式对于所有的Linux系统来说都是适用的。 目录 一、ssh控制树莓派 1.开启 ssh服务方法一 2.开启 ssh服务方法二 二、VNC远程连接 三、xrdp远程连接 四、其他注意事项 一、ssh控制树莓派 S…...

C++ 第二弹封装-类和对象
目录 1.类的引入 2.类的定义方式 3.访问权限 4.封装 5.类也是作用域 6.类的实例化 7.如何求一个类的大小 8.this指针 9.默认成员函数 10.构造函数 11.析构函数 12.拷贝构造函数 13.赋值运算符重载 14.const的类成员 15初始化列表 16.static的类成员 17.友元 …...
浅析 GeoServer CVE-2023-25157 SQL注入
原创稿件征集 邮箱:eduantvsion.com QQ:3200599554 黑客与极客相关,互联网安全领域里 的热点话题 漏洞、技术相关的调查或分析 稿件通过并发布还能收获 200-800元不等的稿酬 更多详情,点我查看! 简介 GeoServer是一个开…...

1001router6-react
文章目录 1 一级路由2 Navigate3 NavLink 自定义高亮样式4 useRoutes()5 嵌套路由6 路由传参6.1 传递params参数6.2 传递search参数6.3 传递state参数 7 编程式导航7.1 路由跳转7.2 前进、后退 8 钩子函数8.1 useInRouterContext()8.2 useNavigationType()8.3 useOutlet()8.4 u…...
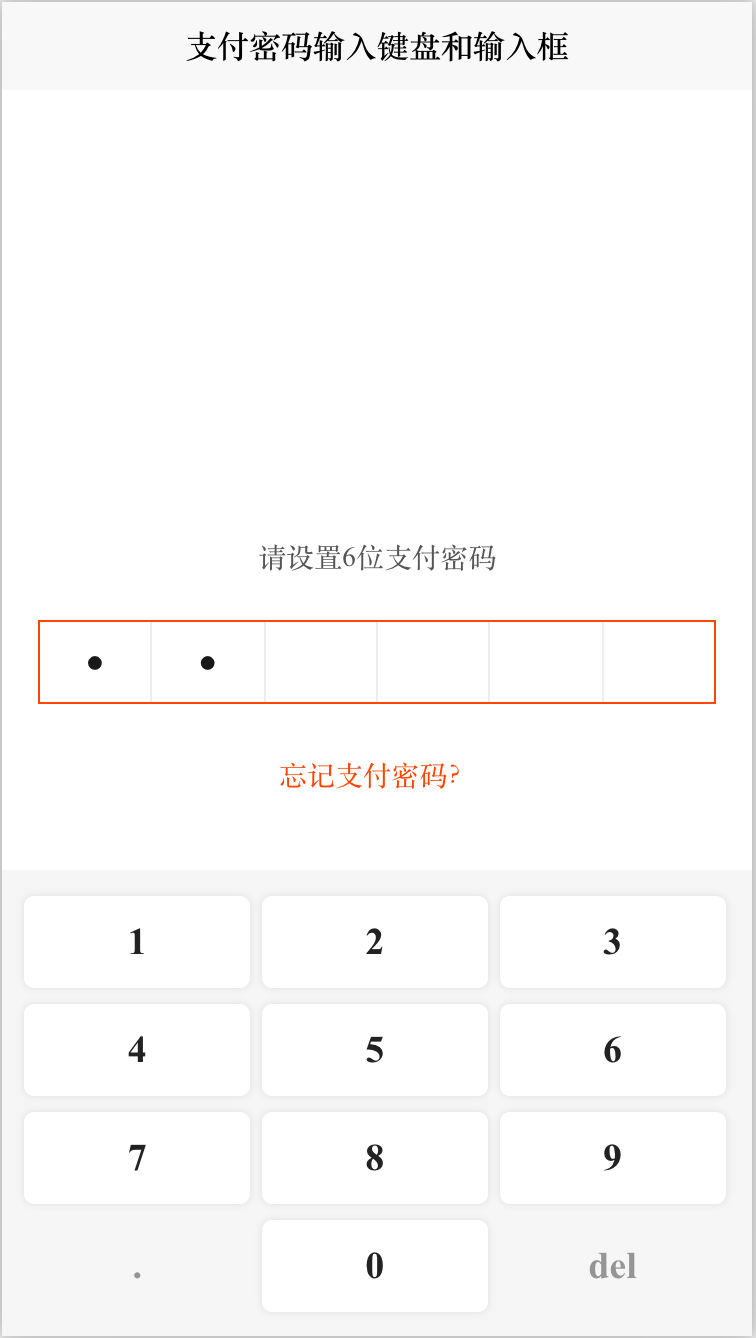
前端Vue自定义支付密码输入键盘Keyboard和支付设置输入框Input
前端Vue自定义支付密码输入键盘Keyboard和支付设置输入框Input, 下载完整代码请访问uni-app插件市场地址:https://ext.dcloud.net.cn/plugin?id13166 效果图如下: # cc-defineKeyboard #### 使用方法 使用方法 <!-- ref:唯一ref pas…...
)
VB+ACCESS超市管理系统设计(源代码+系统)
超市管理系统是典型的信息管理系统(MIS),其开发主要包括后台数据库的建立和维护以及前端应用程序的开发两个方面。对于前者要求建立起数据一致性和完整性强、数据安全性好的库。而对于后者则要求应用程序功能完备,易使用等特点。经过分析,我们使用 MICROSOFT公司的 VISUAL BASI…...

【机器学习】十大算法之一 “神经网络”
作者主页:爱笑的男孩。的博客_CSDN博客-深度学习,活动,python领域博主爱笑的男孩。擅长深度学习,活动,python,等方面的知识,爱笑的男孩。关注算法,python,计算机视觉,图像处理,深度学习,pytorch,神经网络,opencv领域.https://blog.csdn.net/Code_and516?typeblog个…...

【MarkDown】CSDN Markdown之流程图graphflowchart详解
基本语法 flowchart/graph 流程图(Flowcharts/Graphs)是由节点 (几何形状) 和连接线 (箭头或线条)组成的. Mermaid代码定义了节点和连线的编码方式,并支持不同的箭头类型、多向箭头以及子图之间的任意链接。 警告 如果在流程图的节点使用e…...
Git下:Git命令使用-详细解读
目录 一、Git 安装 二、Git 配置 三、Git 工作流程 四、Git 工作区、暂存区和版本库 五、常用 Git 命令清单 1. 创建仓库 2. 增加/删除文件 3. 代码提交 4. 分支管理 5. 标签 6. 查看历史提交 7. 远程仓库同步 8. 撤销操作 六、Git 常用命令速查表 七、Git 电子…...

一条SQL语句的前世今生
文章目录 MySQL 基础架构分析语句分析查询语句更新语句 总结 本篇文章会分析下一个 SQL 语句在 MySQL 中的执行流程,包括 SQL 的查询在 MySQL 内部会怎么流转,SQL 语句的更新是怎么完成的。 MySQL 基础架构分析 下图是 MySQL 的一个简要架构图ÿ…...

各种架构比较
架构特点适用领域x86- 市场份额大,广泛支持和应用<br>- 成熟稳定,软件生态丰富<br>- 相对较低的功耗<br>- 适用于桌面、服务器和嵌入式系统等桌面应用、服务器、嵌入式系统x86-64- 支持 64 位操作系统和应用程序<br>- 更大的内存…...

scapy定制数据包探测主机
kali 输入scapy 进入界面 scapy定制ARP协议 输入ARP().display()显示ARP包的详细信息 输入sr1(ARP(pdst"192.168.133.2")),向网关发送arp请求数据包 scapy定制PING包 输入IP().display()显示IP包的详细信息 输入ICMP().display()显示ICMP包的详细信息…...

【Java】Java核心要点总结70
文章目录 1. volatile 如何保证变量的可⻅性?2. volatile 可以保证原⼦性么?3. synchronized 关键字4. synchronized 和 volatile 的区别5. synchronized 和 ReentrantLock 的区别 1. volatile 如何保证变量的可⻅性? 在Java中,使…...

如何把一个 Git 仓库的分支加入另一个无关的 Git 仓库
文章目录 笔者需要将两个无关的 Git 仓库合并,也就是把一个 Git 仓库的分支加入另一个无关的 Git 仓库。笔者琢磨了一下之后就实现了。方法如下。 笔者的运行环境: git version 2.37.0.windows.1 TortoiseGit 2.11.0.0 IntelliJ IDEA 2023.1.1 (Ultima…...

深蓝学院C++基础与深度解析笔记 第 4 章 表达式
第 4 章 表达式 一、表达式基础 A、表达式: 由一到多个操作数组成,可以求值并 ( 通常会 ) 返回求值结果: #include <iostream> int main(){int x;x 3; }最基本的表达式:变量、字面值通常来说,表达式会包含操作符(运算符…...
)
CLION开发STM32之W5500系列(一)
开篇说明 本系列适用于需要使单片机通过网口进行通信的开发。针对的是刚入门的同学们,也是个人的经验分享。本次使用到的芯片为stm32f103vet6(其他的也可以)本次使用的网口模块为W5500,其网关有示例程序均可以参考.本次使用Clion+OpenOCD+ARM-GCC 进行开发、烧录、编译.建议熟…...
Web3通过ganache运行起一个本地虚拟区块链
通过文章 Web3开发准备工作 手把手带你创建自己的 MetaMask 账号大家简单的对网络 有了个比较模糊的概念 不同的网络连接这不同的区块链 那么 我们就要搞清楚 我们切换不同的网络 我们的数字资产是不一样的 在这里 我们需要先安装一个插件工具 ganache 我们先在本地创建一个文…...

01 背包问题解析与代码 python 实现
01 背包问题解析与代码 问题定义 给定一堆具有不同重量 { w 1 , w 2 , ⋯ , w n } \{ w_1,w_2, \cdots,w_n \} {w1,w2,⋯,wn}与价值 { v 1 , v 2 , ⋯ , v n } \{ v_1,v_2, \cdots,v_n \} {v1,v2,⋯,vn}的背包(knapsack),在总重…...

Vue实现前端视频展示列表及特征提取、笔记、删除、文件夹组织功能
Vue实现前端视频展示列表及特征提取、笔记、删除、文件夹组织功能 在前端展示上传的视频列表时,我们可以使用Element-UI中的Card组件来实现。同时,我们还可以添加一些功能,如缓存播放的视频、选择视频文本特征提取处理、写笔记、删除视频、组…...

Gorilla APIZoo详解:1600+精选API的社区驱动管理平台
Gorilla APIZoo详解:1600精选API的社区驱动管理平台 【免费下载链接】gorilla Gorilla: An API store for LLMs 项目地址: https://gitcode.com/gh_mirrors/go/gorilla Gorilla APIZoo是一个由社区驱动的API管理平台,汇集了1600精选API࿰…...

Express-Admin自定义开发:静态文件与视图扩展完全指南
Express-Admin自定义开发:静态文件与视图扩展完全指南 【免费下载链接】express-admin simov/express-admin: 是一个基于 Express.js 和 AdminLTE 框架的 Node.js MySQL 数据库管理面板,它提供了易于使用的 Web 界面用于管理 MySQL 数据库。适合用于管理…...

ESP32-C61 AT命令全解析:系统配置、Flash/NVS管理与Wi-Fi 6控制
ESP32-C61 AT 命令深度解析:系统级配置、存储管理与 Wi-Fi 控制全指南 在嵌入式物联网设备开发中,AT 命令作为轻量级、标准化的串行通信接口,承担着连接控制、状态查询、固件维护与底层硬件配置等关键职责。ESP32-C61 作为乐鑫新一代支持 Wi-Fi 6 和 Bluetooth LE 5.3 的 S…...

2024前端字体优化指南:从阿里巴巴普惠体到可变字体实战
2024前端字体优化实战:从品牌定制到性能极致的全链路方案 去年我们团队接手了一个面向全球市场的金融科技产品重构,设计稿里指定了一款精致的品牌字体。上线后,市场团队却收到了大量来自Windows用户的反馈,抱怨界面文字“发虚”、…...
)
告别“封号”与“宕机”:2026企业级Python分布式爬虫架构实战(微服务+K8s全链路解析)
前言 在2026年的今天,数据采集早已不是写个requests循环就能搞定的小事。 面对反爬机制的智能化(指纹识别、行为分析、AI验证码)、目标网站的高并发压力以及企业内部对数据时效性、合规性的严苛要求,传统的单体爬虫架构显得捉襟见…...

06|AI 参与开发的安全底线:别把密钥和隐私喂进去
本篇目标:这是“卷 0”的最后一篇。在正式开始写代码前,我们必须立下“生死状”。遵守这些规则,能让你免于牢狱之灾或破产风险。一、血淋淋的教训 在你觉得“我只是个小透明,黑客不会搞我”之前,先看两个真实案例&…...

carsim simulink仿真,纯电动汽车Acc 自适应巡航 上层控制器 包括 mpc跟车...
carsim simulink仿真,纯电动汽车Acc 自适应巡航 上层控制器 包括 mpc跟车加速度计算 巡航pid 。 安全距离计算,跟车巡航切换策略等 下层控制器 纯电动车模型搭建, 包含制动驱动扭矩计算,制动驱动切换,制动能量回收&…...

在 PHP 中写真正的异步代码 TrueAsync 0.6.0 已支持数据库链接池
在 PHP 中写真正的异步代码 TrueAsync 0.6.0 已支持数据库链接池 现代软件的构建最终仍然要回到实践。再复杂的产品,也必须经过真实用户的检验。只有最终用户,才能真正区分哪些设计是有效的、哪些方向值得继续推进。再优雅的架构,如果没有落…...

零基础入门Overleaf-Workshop:从安装到编译的简单步骤
零基础入门Overleaf-Workshop:从安装到编译的简单步骤 【免费下载链接】Overleaf-Workshop Open Overleaf/ShareLaTex projects in vscode, with full collaboration support. 项目地址: https://gitcode.com/gh_mirrors/ov/Overleaf-Workshop Overleaf-Work…...

Cosmos-Reason1-7B惊艳输出:多约束条件下最优解存在性逻辑论证
Cosmos-Reason1-7B惊艳输出:多约束条件下最优解存在性逻辑论证 1. 引言:当AI开始“讲道理” 想象一下,你正在为一个复杂的项目做规划,手头有十几个限制条件:预算不能超、时间要最短、资源要最省、效果还要最好。你挠…...