Java kafka
JAVA面试题--Kafka(最新最全)
- 目录
- 概述
- 需求:
- 设计思路
- 实现思路分析
- 1.URL管理
- 2.网页下载器
- 3.爬虫调度器
- 4.网页解析器
- 5.数据处理器
- 拓展实现
- 性能参数测试:
- 参考资料和推荐阅读
)
Survive by day and develop by night.
talk for import biz , show your perfect code,full busy,skip hardness,make a better result,wait for change,challenge Survive.
happy for hardess to solve denpendies.
目录

概述
Java 消费者
需求:
设计思路
1.为什么要使用 kafka?为什么要使用消息队列?
1.为什么要使用 kafka?为什么要使用消息队列?
2.Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么?
3.kafka中的broker 是干什么的?
4.kafka中的 zookeeper 起到什么作用?可以不用zookeeper么?
5.kafka follower如何与leader同步数据?
6.什么情况下一个 broker 会从 ISR 中被踢出去?
7.kafka 为什么那么快?
8.kafka producer如何优化打入速度?
9.kafka producer 打数据,ack 为 0, 1, -1 的时候代表啥, 设置 -1 的时候,什么情况下,leader 会认为一条消息 commit 了
10.kafka unclean 配置代表啥?会对 spark streaming 消费有什么影响?
11.如果leader crash时,ISR为空怎么办?
12.kafka的message格式是什么样的?
13.kafka中consumer group 是什么概念?
14.Kafka中的消息是否会丢失和重复消费?
15.为什么Kafka不支持读写分离?
16.Kafka中是怎么体现消息顺序性的?
17.kafka如何实现延迟队列?
18.什么是消费者组?
19.解释下 Kafka 中位移(offset)的作用。
20.阐述下 Kafka 中的领导者副本(Leader Replica)和追随者副本 (Follower Replica)的区别。
21.如何设置 Kafka 能接收的最大消息的大小?
22.监控 Kafka 的框架都有哪些?
23.Broker 的 Heap Size 如何设置?
24.如何估算 Kafka 集群的机器数量?
25.Leader 总是 -1,怎么破?
26.LEO、LSO、AR、ISR、HW 都表示什么含义?
27.Kafka 能手动删除消息吗?
28.consumer_offsets 是做什么用的?
29.分区 Leader 选举策略有几种?
30.Kafka 的哪些场景中使用了零拷贝(Zero Copy)?
31.如何调优 Kafka?
32.Controller 发生网络分区(Network Partitioning)时,Kafka 会怎么样?
33.Java Consumer 为什么采用单线程来获取消息?
34.简述 Follower 副本消息同步的完整流程。
缓冲和削峰:上游数据时有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,下游服务就可以按照自己的节奏进行慢慢处理。
解耦和扩展性:项目开始的时候,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流2.Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么?
程。只需要遵守约定,针对数据编程即可获取扩展能力。
冗余:可以采用一对多的方式,一个生产者发布消息,可以被多个订阅topic的服务消费到,供多个毫无关联的业务使用。
健壮性:消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
2.Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么?
AR:Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟(包括延迟时间replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度, 当前最新的版本0.10.x中只支持replica.lag.time.max.ms这个维度),任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
3.kafka中的broker 是干什么的?
broker 是消息的代理,Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉取指定Topic的消息,然后进行业务处理,broker在中间起到一个代理保存消息的中转站。
4.kafka中的 zookeeper 起到什么作用?可以不用zookeeper么?
zookeeper 是一个分布式的协调组件,早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及 offset的值。考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖,但是broker依然依赖于ZK,zookeeper 在kafka中还用来选举controller 和 检测broker是否存活等等。
5.kafka follower如何与leader同步数据?
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。完全同步复制要求All Alive Follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,Follower异步的从Leader复制数据,数据只要被Leader写入log就被认为已经commit,这种情况下,如果leader挂掉,会丢失数据,kafka使用ISR的方式很好的均衡了确保数据不丢失以及吞吐率。Follower可以批量的从Leader复制数据,而且Leader充分利用磁盘顺序读以及send file(zero copy)机制,这样极大的提高复制性能,内部批量写磁盘,大幅减少了Follower与Leader的消息量差。
6.什么情况下一个 broker 会从 ISR 中被踢出去?
leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),每个Partition都会有一个ISR,而且是由leader动态维护 ,如果一个follower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除 。
7.kafka 为什么那么快?
Cache Filesystem Cache PageCache缓存
Cache Filesystem Cache PageCache缓存
顺序。 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快。
Zero-copy。零拷技术减少拷贝次数
Batching of Messages 批量量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限。
Pull 拉模式。使用拉模式进行消息的获取消费,与消费端处理能力相符。
8.kafka producer如何优化打入速度?
增加线程
提高 batch.size
增加更多 producer 实例
增加 partition 数
设置 acks=-1 时,如果延迟增大:可以增大 num.replica.fetchers(follower 同步数据的线程数)来调解;
跨数据中心的传输:增加 socket 缓冲区设置以及 OS tcp 缓冲区设置。
9.kafka producer 打数据,ack 为 0, 1, -1 的时候代表啥, 设置 -1 的时候,什么情况下,leader 会认为一条消息 commit 了
1(默认):数据发送到Kafka后,经过leader成功接收消息的的确认,就算是发送成功了。在这种情况下,如果leader宕机了,则会丢失数据。
0:生产者将数据发送出去就不管了,不去等待任何返回。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
-1:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。当ISR中所有Replica都向Leader发送ACK时,leader才commit,这时候producer才能认为一个请求中的消息都commit了。
10.kafka unclean 配置代表啥?会对 spark streaming 消费有什么影响?
unclean.leader.election.enable 为true的话,意味着非ISR集合的broker 也可以参与选举,这样有可能就会丢数据,spark streaming在消费过程中拿到的 end offset 会突然变小,导致 spark streaming job挂掉。如果unclean.leader.election.enable参数设置为true,就有可能发生数据丢失和数据不一致的情况,Kafka的可靠性就会降低;而如果unclean.leader.election.enable参数设置为false,Kafka的可用性就会降低。
11.如果leader crash时,ISR为空怎么办?
kafka在Broker端提供了一个配置参数:unclean.leader.election,这个参数有两个值:
true(默认):允许不同步副本成为leader,由于不同步副本的消息较为滞后,此时成为leader,可能会出现消息不一致的情况。
false:不允许不同步副本成为leader,此时如果发生ISR列表为空,会一直等待旧leader恢复,降低了可用性。
一个Kafka的Message由一个固定长度的header和一个变长的消息体body组成。
header部分由一个字节的magic(文件格式)和四个字节的CRC32(用于判断body消息体是否正常)构成。
当magic的值为1的时候,会在magic和crc32之间多一个字节的数据:attributes(保存一些相关属性,比如是否压缩、压缩格式等等);如果magic的值为0,那么不存在attributes属性。
body是由N个字节构成的一个消息体,包含了具体的key/value消息。
13.kafka中consumer group 是什么概念?
同样是逻辑上的概念,是Kafka实现单播和广播两种消息模型的手段。同一个topic的数据,会广播给不同的group;同一个group中的worker,只有一个worker能拿到这个数据。换句话说,对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个worker消费。group内的worker可以使用多线程或多进程来实现,也可以将进程分散在多台机器上,worker的数量通常不超过partition的数量,且二者最好保持整数倍关系,因为Kafka在设计时假定了一个partition只能被一个worker消费(同一group内)。
14.Kafka中的消息是否会丢失和重复消费?
要确定Kafka的消息是否丢失或重复,从两个方面分析入手:消息发送和消息消费。
1)消息发送
Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过producer.type属性进行配置。Kafka通过配置request.required.acks属性来确认消息的生产:
Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过producer.type属性进行配置。Kafka通过配置request.required.acks属性来确认消息的生产:
0—表示不进行消息接收是否成功的确认;
1—表示当Leader接收成功时确认;
-1—表示Leader和Follower都接收成功时确认;
综上所述,有6种消息生产的情况,下面分情况来分析消息丢失的场景:
(1)acks=0,不和Kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
(2)acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
2)消息消费
Kafka消息消费有两个consumer接口,Low-level API和High-level API:
实现思路分析
1.URL管理
这里我们可以使用规则的数据结构来存储和转发。
2.网页下载器
下载器我们可以使用建立HTTP请求把界面的URL元素下载下来。实质就是
下载器。
3.爬虫调度器
爬虫调度器就是可以利用多线程机制,进行调度似的更快的进行网页爬取。
4.网页解析器
这个也比较简单,就是对网页元素进行解析,通常利用JSONP,xpath等技术进行网页分析。
5.数据处理器
在这个过程一般在数据存储和,存储到mysql中,或者进行其他逻辑判断等。
拓展实现
这里参考:github:简单实现上述流程:
入门级实现:
: 部分源码实现.
: 源码实现
性能参数测试:
每秒大概18-20个请求,主要用于网络IO操作耗费了不少时间。
参考资料和推荐阅读
- 爬虫框架的设计与实现之JAVA篇.
- 主流爬虫框架的基本介绍.
- 高拓展性的Java多线程爬虫框架reptile.
欢迎阅读,各位老铁,如果对你有帮助,点个赞加个关注呗!~
相关文章:
Java kafka
JAVA面试题--Kafka(最新最全) 目录概述需求:设计思路实现思路分析1.URL管理2.网页下载器3.爬虫调度器4.网页解析器5.数据处理器拓展实现性能参数测试:参考资料和推荐阅读)Survive by day and develop by night. talk for import b…...

DBA之路---Stream数据共享同步机制与配置方法
oracle的Stream解析–数据共享 在g版本常用,如果是c版本项目一般都会选择goldengate,比stream靠谱多了 Oracle中的stream是消息队列一种应用形式,原理如下: 收集oracle中的事件,将事件保存在队列里,然后将…...

CF1790E Vlad and a Pair of Numbers 题解
CF1790E Vlad and a Pair of Numbers 题解题目链接字面描述题面翻译题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1思路代码实现题目 链接 https://www.luogu.com.cn/problem/CF1790E 字面描述 题面翻译 共有 ttt 组数据。 每组数据你会得到一个正整数 xxx&…...

漏洞预警|Apache Kafka Connect JNDI注入漏洞
棱镜七彩安全预警 近日网上有关于开源项目Apache Kafka Connect JNDI注入漏洞,棱镜七彩威胁情报团队第一时间探测到,经分析研判,向全社会发起开源漏洞预警公告,提醒相关安全团队及时响应。 项目介绍 Karaf是Apache旗下的一个开…...

企业小程序开发步骤【教你创建小程序】
随着移动互联网的兴起,微信已经成为了很多企业和商家必备的平台,而其中,微信小程序是一个非常重要的工具。本文将为大家介绍小程序开发步骤,教你创建小程序。 步骤一、注册小程序账号 先准备一个小程序账号,在微信公…...

刚性电路板的特点及与柔性电路板的区别
打开市场上的任何一个电子产品,会发现里面都有一块或多块电路板。电路板是电子产品运行的核心,之前沐渥小编已经给大家介绍了柔性电路板,下面给大家介绍刚性电路板的基础知识。 刚性电路板俗称硬板,是由不容易变形的刚性基材制成的…...

扫码过磅+车牌识别,内蒙古蒙维过磅实现信息化管理
扫码过磅、车牌识别、对接SAP ERP系统设计思路: 无人值守系统升级改造包括车牌自动识别系统、信息化(扫码等方式)管理系统、智能自动控制系统等实现信息无纸化传递。远程监管地点设于公司东磅房,可以实现远程监测监控画面、称重过…...
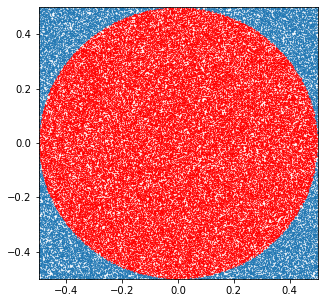
蒙特卡洛计算圆周率
使用MC计算圆周率的小例子,使用python的numpy,matplotlib库import numpy as npimport matplotlib.pyplot as pltdef mc_calculate_pi(t):np.random.seed(t)rand_num np.random.rand(t)rand_num2 np.random.rand(t)l1 rand_num-0.5l2 rand_num2-0.5l0…...
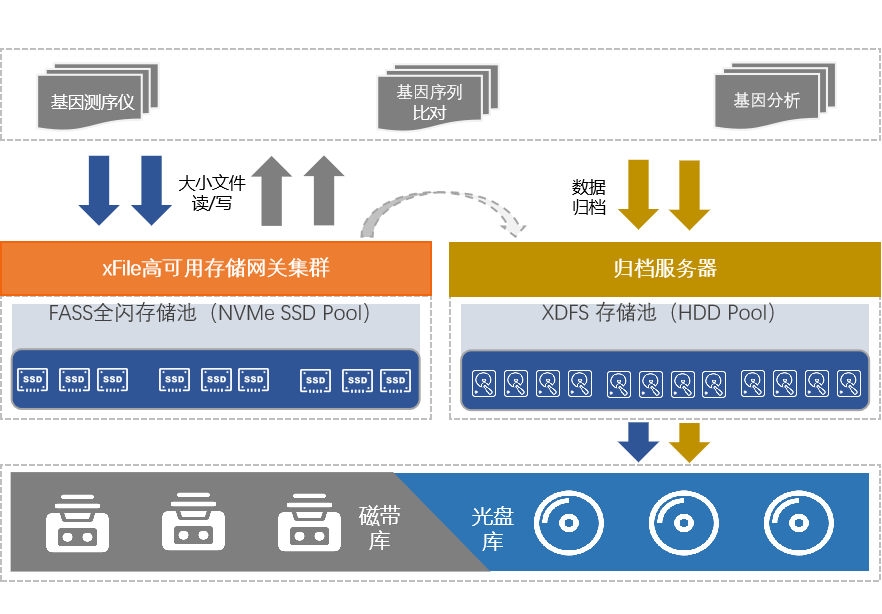
生物信息场景下的用户需求
背景分析概念定义基因测序是一种新型基因检测技术,是基因检测的方法之一,其又叫基因谱测序,是国际上公认的一种基因检测标准。基因测序技术能锁定病变基因,提前预防和治疗。过长的测序周期以及上万美元的仪器成本,成了…...
和sudo(superuser do)的区别?(sudo su与su的区别))
linux su(switch user)和sudo(superuser do)的区别?(sudo su与su的区别)
文章目录linux su(switch user)和sudo(superuser do)的区别?sudo su与su的区别linux su(switch user)和sudo(superuser do)的区别? 在Unix或Linux操作系统中…...
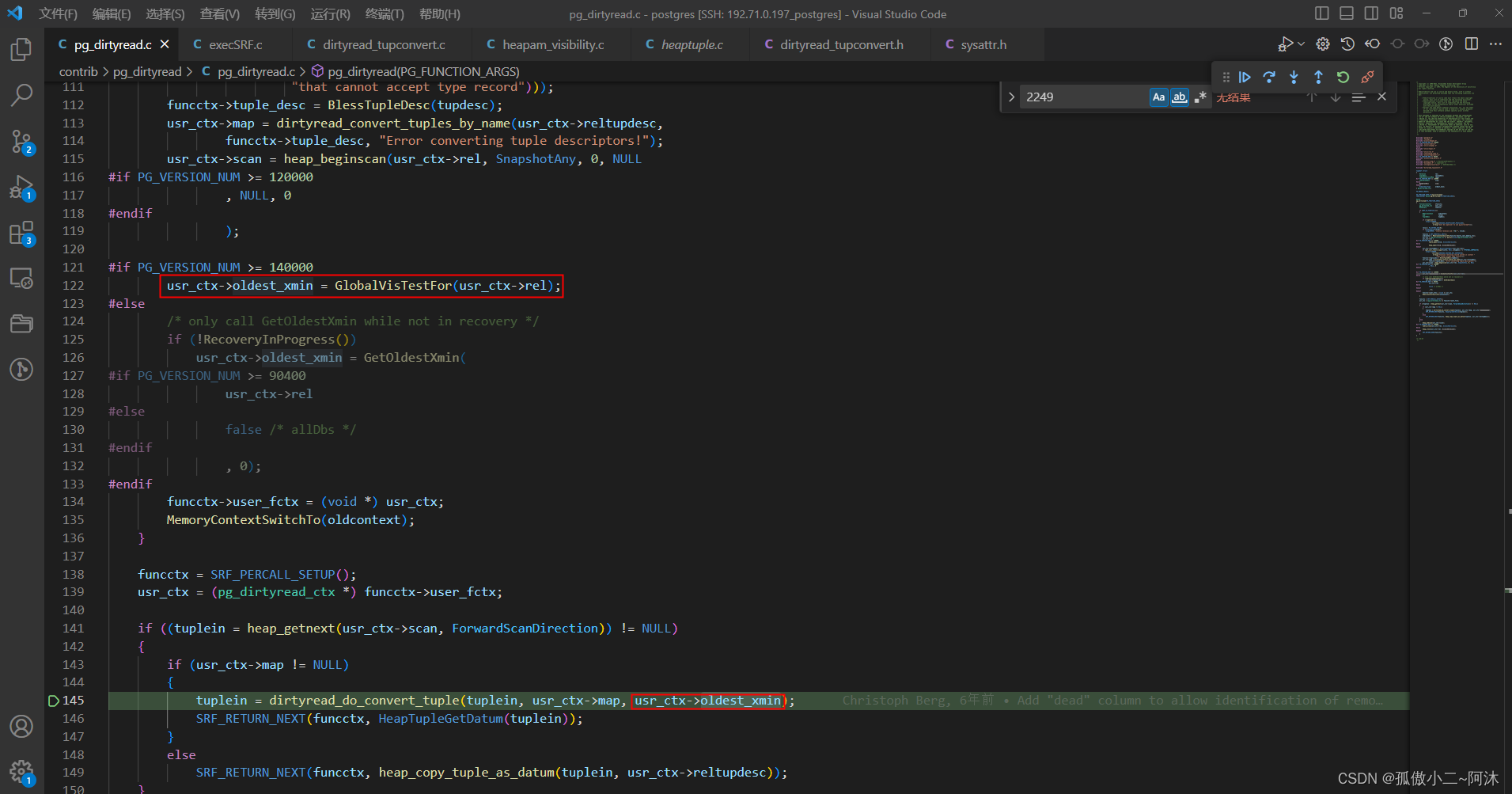
PostgreSQL的学习心得和知识总结(一百二十三)|深入理解PostgreSQL数据库开源扩展pg_dirtyread的使用场景和实现原理
目录结构 注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下: 1、参考书籍:《PostgreSQL数据库内核分析》 2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》 3、PostgreSQL数据库仓库…...
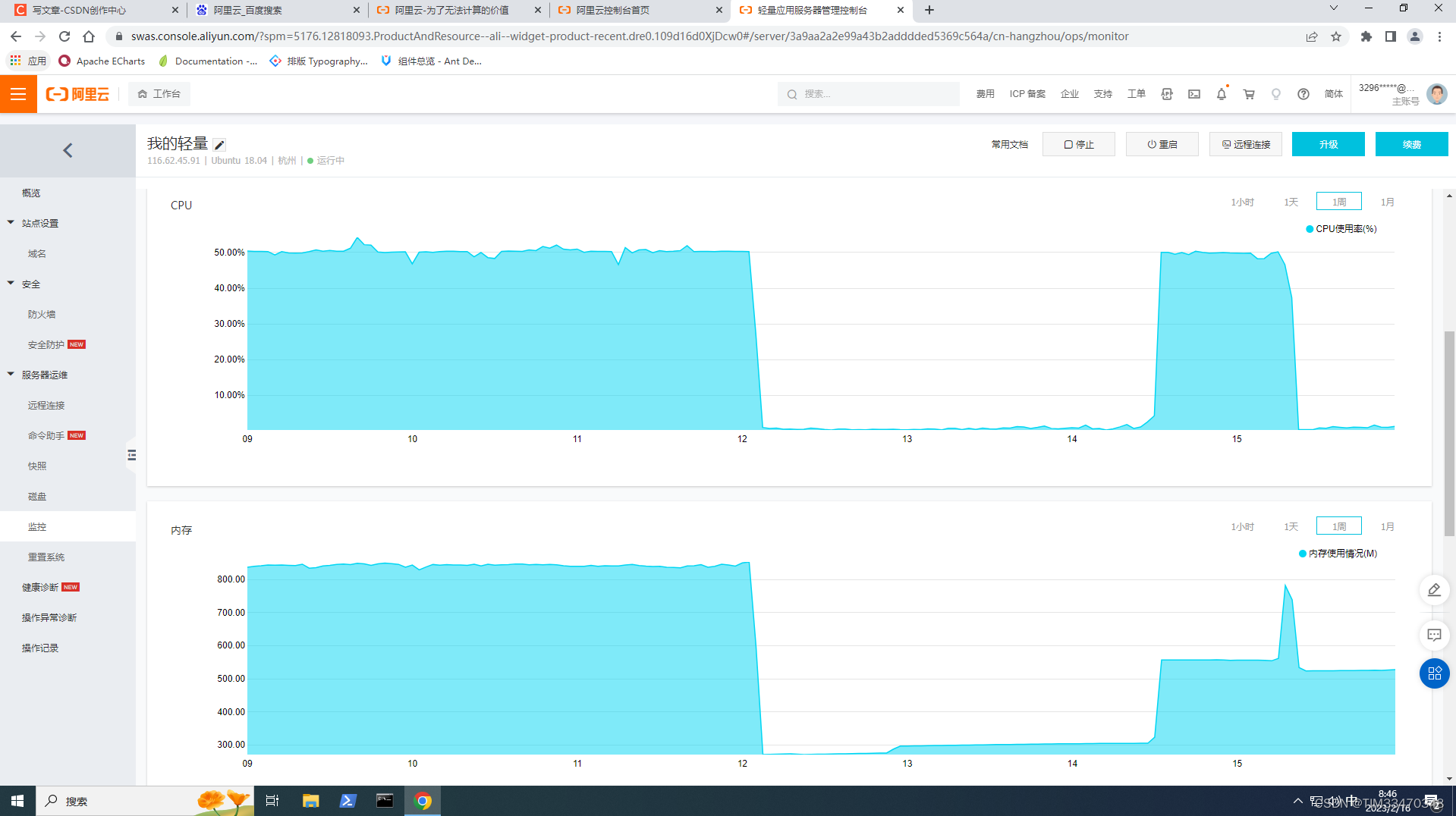
ubuntu清理挖矿病毒
0 序言 我之前搭建的hadoop用于测试,直接使用了8088和9870端口,没有放入docker,从而没有端口映射。于是,就被不法之徒盯上了,hadoop被提交了很多job,使得系统被感染了挖矿病毒,在前几天阿里云站…...

【代码随想录训练营】【Day16】第六章|二叉树|104.二叉树的最大深度|559.n叉树的最大深度|111.二叉树的最小深度|222.完全二叉树的节点个数
二叉树的最大深度 题目详细:LeetCode.104 递归法很容易理解: 定义一个全局变量max, 记录二叉树的最大深度在递归函数中增加一个深度参数,表示当前的节点的深度然后对二叉树进行深度优先遍历当遍历到叶子节点时,比较…...
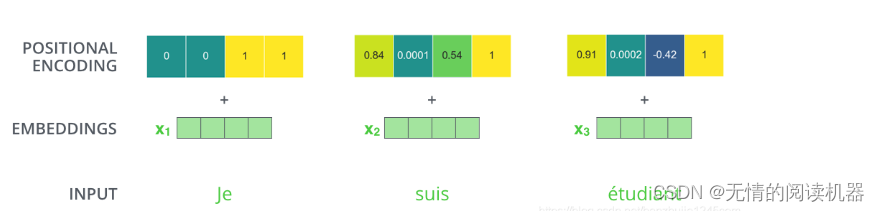
transformer总结
1.注意力机制 意义:人类的注意力机制极大提高了信息处理的效率和准确性。 公式: 1)自注意力机制 b都是在考虑了所有a的情况下生成的。 以产生b1向量为例: 1.在a这个序列中,找到与a1相关的其他向量 2.每个向量与a1关联的程度&a…...

dart flutter入门教程,开发手册 分享
我最近在学校dart flutter.这是我收集的一些手册和教程. 不需要关注公众号,不需要加好友. 我发现flutter(dart)的中文资料比较奇缺.入门的教程非常多.但是api手册几乎没有(全是英文的). 收集原则 1.中文(我英文不好) 2.不要pdf的,网上有一些pdf的 从入门到进阶的,但是太长…...

教育舆情监测关键词有哪些,TOOM教育舆情监测系统流程?
教育舆情监测是指对教育领域的舆情进行收集、分析和处理的过程。舆情是指公众在各种渠道上对教育政策、教育机构、教育事件等方面的言论、态度和情绪。通过对教育舆情的监测和分析,可以了解公众对教育行业的看法和反应,提高对教育行业的管控能力…...
MySQL高级(一)
MySQL-day01 1 MySQL简介 1.1 MySQL简介 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB(创始人Michael Widenius)公司开发,2008被Sun收购(10亿美金),2009年Sun被Oracle收购。MariaDBMaria…...
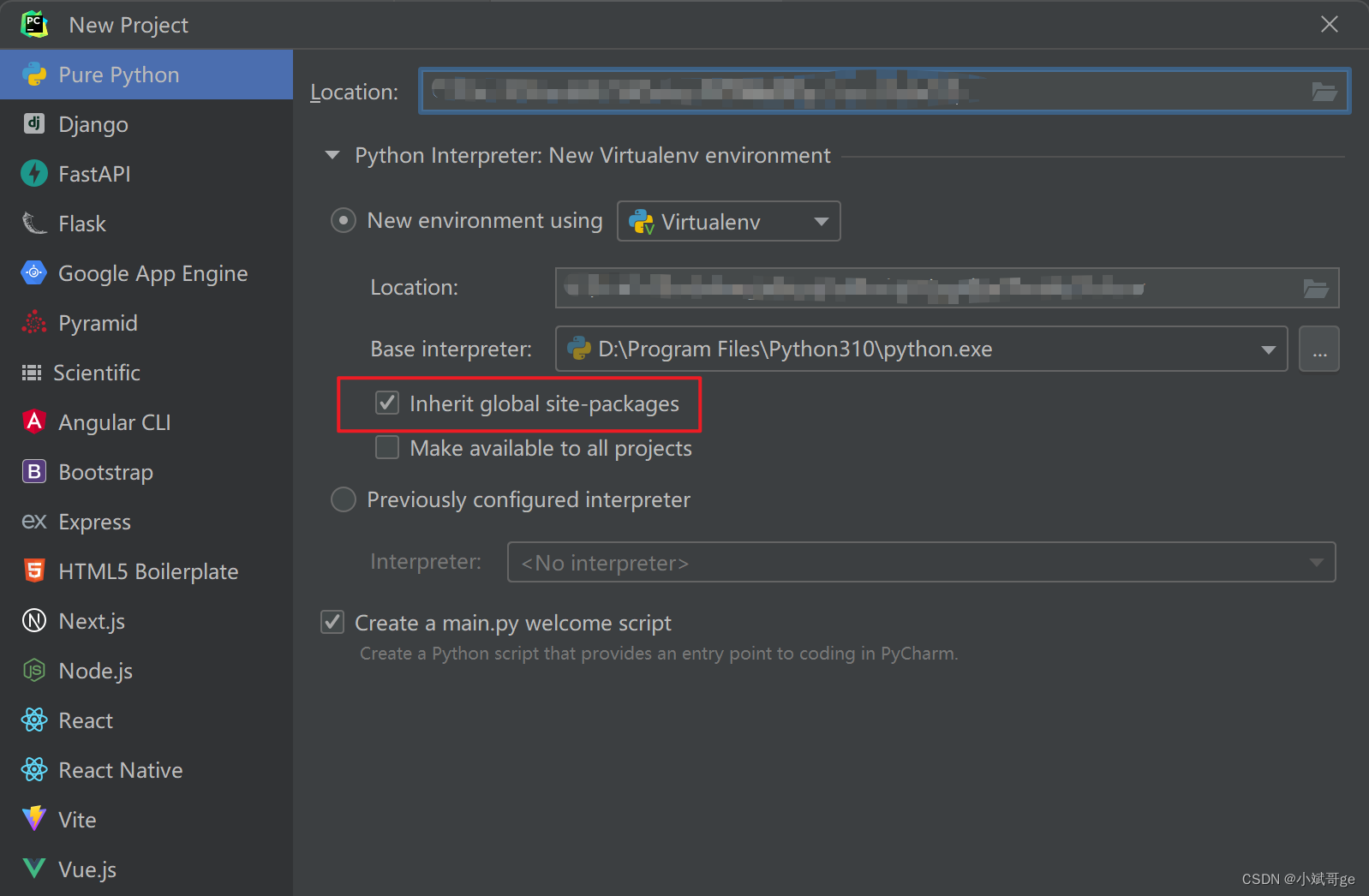
如何将Python项目部署到新电脑上运行?
如何将Python项目部署到新电脑上运行? 在工作中,可能需要在新服务器上部署项目代码,例如新增服务器、把测试环境的代码部署到生产环境等。 在生活中,也会遇到换新电脑,需要将自己在旧电脑上写的(项目&…...
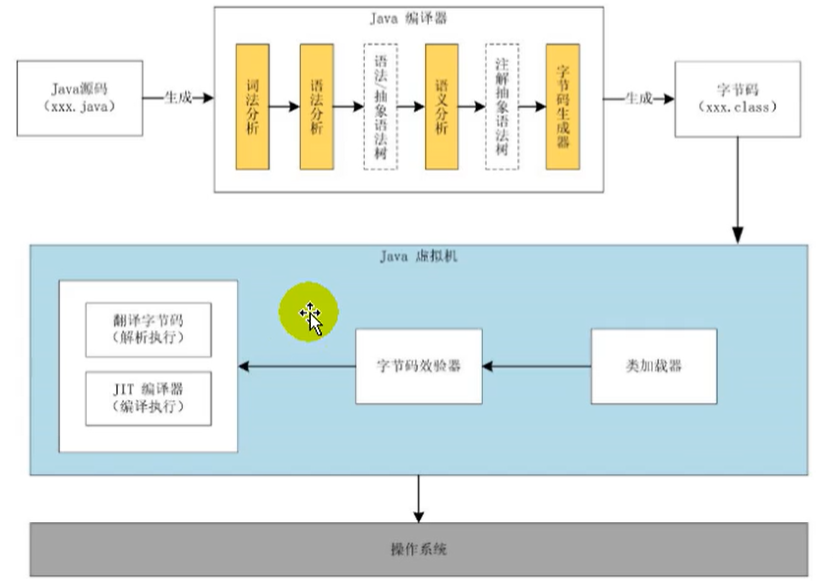
JVM和JAVA体系结构
1、为什么要学习JVM作为Java工程师的你曾被伤害过吗?你是否也遇到过这些问题?运行着的线上系统突然卡死,系统无法访问,甚至直接OOM想解决线上JVM GC问题,但却无从下手新项目上线,对各种JVM参数设置一脸茫然…...
(十)、通过云对象修改阅读量+点赞功能的实现【uniapp+uinicloud多用户社区博客实战项目(完整开发文档-从零到完整项目)】
1,通过云对象importObj修改阅读量 1.1 新建云对象 1.2 云对象中写自增自减方法 封装云对象utilsObj中的自增自减方法,方法名取为operation,传递4个参数。 // 云对象教程: https://uniapp.dcloud.net.cn/uniCloud/cloud-obj // jsdoc语法提…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...