深度学习算法面试常问问题(一)
博主秋招遇到的面试问题以及整理其他面经相关问题,无偿分享~
项目叙述:
- 算法需求及应用场景
- 算法的调研和初步方案的制定
- 数据的准备(包括数据标注和数据增强)
- 算法的介绍(包括输入和输出,loss、backbone、训练细节等)
- 自己对算法增加的模块的介绍(为什么要这样改?消融实验)
- 各种指标的计算
- 算法是否兼顾到参数量和推理速度等
mIOU
一个衡量图像分割精度的重要指标,mIOU可解释为平均交并比,即在每个类别上计算Iou值(真正样本数量 / (真正样本数量+假负样本数量+假正样本数量))

空洞卷积的优缺点
优点:在不做下采样的情况下,加大感受野
缺点:1. 网格效应,如果仅仅多次堆叠多个空洞率为2 的 3*3卷积核,会发现并不是所有输入像素点都会得到计算,也就是卷积核不连续。在逐像素的预测任务中,这是致命的。
- 远距离的信息可能不相关,导致空洞卷积对大物体分割有效果,对小物体分割可能没好处
如何克服网格效应?
- 叠加空洞卷积的膨胀率不能有大于1的公约数。这是为了对抗网格效应。(2,4,6)就不行
- 将膨胀率设计成锯齿状结构,这是为了满足大小物体的需求。[1,2,5,1,2,5]
- 最后一层的空洞卷积的膨胀率最大,且膨胀率小于等于 卷积核大小。主要对抗网格效应。
1x1卷积核作用
- 通过控制卷积核个数来实现升维和降维
- 对不同特征进行归一化操作
- 跨通道信息交互
- 增加网络的非线性
转置卷积:
当填充为0 步幅为1:
- 将输入填充k-1 (k 为卷积核大小)
- 将卷积核上下,左右翻转
- 然后做正常卷积(填充0、步幅为1)

步幅为s:在行列之间插入 s-1行或列


CenterNet的原理,与传统的目标检测有什么不同点?
CenterNet是anchor-free,与yolov3相比,速度相同的情况下,CenterNet精度比yolov3高好几个点,不需要NMS,直接检测目标中心点和大小。
算法流程:
- 1 x 3 x 512 x 512 经过backbone特征提取后 得到32倍下采样特征图 1 x 2048 x 16 x 16
- 然后再经过三层转置卷积模块上采样到 128 x 128,最后送入三个head分支进行预测
- 预测结果分别为物体类别、长宽尺寸和中心点偏置
- 推理的核心是从heatmap中提取需要的bounding box,通过使用3x3的最大池化,检查当前热点值是否比周围的8个临近点值都大,每个类别取100个点,经过box后处理再通过阈值筛选,得到最终的预测框。
CSP结构原理和作用:
CSP是一种思想,与resnet、densenet类似。它将feature map拆分两个部分,一部分进行卷积操作、另一个部分与上一部分卷积操作的结果进行cat。解决了三个问题:
- 增强CNN学习能力,能够在轻量化的同时保持着准确性
- 降低计算成本
- 降低内存开销。CSPNet改进了密集块和过渡块的信息流,优化了梯度反向传播路径,提升网络学习能力,同时在处理速度和内存方面提升不少。
介绍Faster R-CNN 和 Cascade R-CNN
Faster R-CNN是anchor-based和two-stage类型检测器,分为四个部分
- backbone特征提取,然后RPN层通过softmax判断anchors属于positive或者negative,再利用边框回归修正anchors获得精确的候选区域
- RPN生成了大量的候选区域,这些候选区域和feature maps一起送入ROI pooling,得到候选特征区域,最后送入分类和边框回归,得到最终的预测结果
Cascade R-CNN 在Faster R-CNN上改进,通过级联几个检测网络达到不断优化预测结果的目的,与普通级联不同,Cascade R-CNN的几个检测网络是基于不同IOU阈值确定的正负样本上训练得到的。简单的来说cascade R-CNN是由一系列检测模型组成,每个检测模型都基于不同IOU阈值的正负样本训练得到,前一个检测模型的输出作为后一个检测模型的输入,因此是stage by stage的训练方式,而且越往后的检测模型,界定正负样本的IOU阈值是不断上升的。
线性回归为什么要使用mse作为损失函数?
在使用线性回归的时候,基本假设是噪声服从正态分布,当噪声符合正态分布时,因变量则符合正态分布,因此使用mse的时候实际上是假设y服从正态分布。
优化算法:
- 基本梯度下降法,包括SGD等
- 动量优化法,包括momentum,NAG等
- 自适应学习率优化法,包括Adam、AdaGrad、RMSProp等
上采样的原理和常用方式:
在CNN中,由于输入图片通过CNN提取特征后,输出尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进一步计算(图像分割),小分辨率到大分辨率操作为上采样。
- 插值,一般使用双线性插值,效果最好(计算复杂),但与卷积计算比较,计算量不值得一提
- 转置卷积,通过对输入feature map间隔填充0, 再进行标准卷积计算,可以使得输出feature map尺寸比输出更大
- Max unpooling,在对称max pooling位置记录最大值索引值,然后将值填回去,其余位置补0
参数量和FLOPs计算
参数量:

FLOPs:

CNN中add和concat操作:
add和concat分支操作统称为shortcut,add是在ResNet中提出的,增加信息的表达。concat操作是Inception首次使用,被DenseNet发扬光大,保留了一些原始的特征,增加特征的数量,使得有效信息流继续向后传递。
为什么神经网络常用relu作为激活函数
- 计算量小、避免梯度消失
- Relu 可使部分神经元输出为0,造成网络稀疏性,减少前后层参数对当前层参数的影响,提升模型的泛化性能
BN为什么要重构
恢复出原始的某一层所学到的特征,因此引入了λ和β,让我们网络可以学习恢复出原始网络所要学习的特征分布。比如数据分布不平衡。
BN训练和测试时的区别
- 训练阶段:首先计算均值和方差(每次训练给一个批次,计算批次的均值和方差),然后归一化,然后缩放和平移
- 测试阶段:每次只输入一张图片,无法计算批量均值和方差。在训练的时候实现计算好running_mean、running_var,测试的时候直接拿来用就可以,不需要计算均值和方差。
Inception V1 - V4的区别、改进
V1:googlenet某些大卷积核换成小卷积
V2:输入的时候加入BN,训练起来收敛更快,可以减少dropout的使用
V3:GoogleNet里面一些7x7的卷积变成 1x7和7x1两层串联,同理3x3。这样加速了计算,增加网络的非线性、减少过拟合的概率。
V4:原来的inception加上resnet的方法
分类任务中为什么交叉熵损失函数比均方误差损失函数更常用?
交叉熵损失函数关于输入权重的梯度表达式不含激活函数梯度,而均方误差损失函数中存在激活函数的梯度(预测值接近1或0,会导致其梯度接近0),由于常用的sigmoid/tanh存在梯度饱和区,使得MSE对权重的梯度很小。
泛化误差(过拟合)
泛化误差 = 方差 + 偏差 + 噪声
- 噪声是模型训练的上限,也可以说是误差的下限,噪声无法避免
- 方差表示不同样本下模型预测的稳定程度(方差越大其实就是过拟合,预测不稳定)
- 偏差表示模型对训练数据的拟合程度(偏差大就是欠拟合,预测效果不好)
降低方差(过拟合)的方法:
数据:
- 增大数据量、进行数据增强
- 进行数据清洗、进行特征选择降低特征维度
- 类别平衡
网络结构:
-
正则化L1、L2、BN
-
dropout
宏观:
- 选择合适复杂度的模型,或对现有模型进行剪枝
- 标签平滑
- earlystopping
- 增大学习率
- 通过交叉验证
降低偏差(欠拟合)的方法:
网络中间:
- 删除或削弱已有的正则化约束
宏观:
- 增加模型复杂度
- 集成学习
- 增加epoch次数
dropout为什么可以减轻过拟合?
- ensemble效果:训练过程中每次随机关闭不同的神经元,网络结构已经发生改变,整个dropout的训练过程就相等于很多个不同的网络取平均,进而达到ensemble效果
- 减少神经元之间复杂的共适应关系:dropout导致每两个神经元不一定每一次都在网络中出现,减轻了神经元之间的依赖关系。阻止了某些特征仅仅在其他特定特征下才有效果的情况,从而迫使网络无法关注特殊情况,而只能去学习一些更加鲁棒的特征。
KMeans
算法的具体步骤描述:
- 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心
- 遍历所有数据,将每个数据划分到最近的中心点
- 计算每个聚类的平均值,并作为新的中心点
- 重复2-3,直到k个中心点不再变化
优点:
- 原理简单,实现容易,收敛速度快
- 算法的可解释性强
- 主要调参的参数仅仅是k
缺点:
- k的选取不好把握
- 初始化的簇中心敏感,不同选取方式会得到不同的结果
- 如果数据类型不平衡,比如数据量严重失衡或者类别方差不同,则聚类效果不佳
- 采用迭代的方法,只能得到局部最优解
- 对噪音和异常点比较敏感
Focal loss
one-stage算法正负样本严重不均衡,two-stage算法利用RPN网络,将正负样本控制在1:3左右
原理:
- 解决正负样本不均衡问题:添加权重控制,增大少数类样本权重
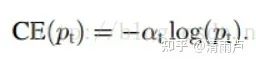
- 解决难易样本问题:Pt越大说明该样本易区分,应当降低容易区分样本的权重。就是说希望增加一个系数,概率越大的样本,权重系数越小。另外,为了提高可控性,引入系数λ
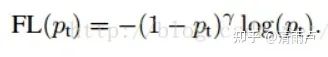
综合:两个参数α和λ协调来控制, 本文作者采用α=0.25,λ=2 效果最好
正则化
原理:在损失函数上加上某些规则(限制),缩小解空间,从而减少求出过拟合解的可能性
常用的正则化手段:
- 数据增强
- 使用L范数约束
- dropout
- early stopping
- 对抗训练
softmax和sigmoid在多分类任务中的优劣
多个sigmoid与一个softmax都可以进行多分类,如果多个类别之间是互斥,就应该使用softmax,即这个东西只可能是几个类别中的一种。如果多个类别之间不是互斥的,使用多个sigmoid。

pooling如何反向传播
max pooling:下一层的梯度会原封不动地传到上一层最大值所在位置的神经元,其他梯度为0
average pooling:下一层的梯度会平均地分配到上一层的对应相连区块的所有神经元
pooling作用:
-
增大感受野 2. 平移不变性 3. 降低优化难度
缺点:造成梯度稀疏,丢失信息
AuC,RoC,mAP,Recall,precision,F1-score
Recall = R=TP/(TP+FN) Precision:P=TP/(TP+FP)
ROC:常用于评价二分类的优劣
AUC:被定义为ROC曲线下的面积,取值范围0.5到1之间 AUC计算公式:https://blog.csdn.net/ustbbsy/article/details/107025087
F1-score:又称调和平均数,precision和recall是相互矛盾的,当recall越大时,框就越多,导致precision就会越小,反之亦然。通常使用F1-score来调和precision和recall,F1 score结果取决于precision和recall。

pytorch多GPU训练机制的原理
pytorch的多GPU处理api:torch.nn.DataParallel(module, device_ids),其中module是要执行的模型,而device_ids则是指定并行GPU id 列表
并行处理机制是,首先将模型加载到主GPU上,然后再将模型复制到各个指定的从GPU中,然后输入数据按照batch维度进行划分,每个GPU分配到的数据为batch/gpu个数。每个GPU将针对各自的输入数据独立进行训练,最后将各个GPU的loss进行求和,再用反向传播更新单个GPU上的模型参数,再将更新后的模型参数复制到剩余指定的GPU中,这样就完成了一次迭代计算。
偏差和方差
模型误差 = 方差+ 偏差+不可避免的误差
偏差:预测值和真实值之间的差距。偏差越大,越偏离真实数据
方差:描述的是预测值的变化范围,离散程度。方差越大,数据分布越分散。
KL散度
KL散度也叫相对熵,用于度量两个概率分布之间的差异程度。

KL散度又叫相对熵, KL散度 = 信息熵 - 交叉熵
不同层次的卷积都提取什么类型的特征?
- 浅层卷积提取 边缘特征
- 中间层卷积提取局部特征
- 深层卷积提取全局特征
BN层面试高频问题
1.BN解决了什么问题?
神经网络在做非线性变换前的激活输入值随着网络深度加深,其分布逐渐发生偏移(內部协变量偏移)。之所以训练收敛慢,一般是整体分布逐渐往非线性函数的区间两端靠近,导致反向传播底层网络训练梯度消失。BN就是通过一定的正则化手段,每层神经网络任意神经元输入值的分布强行拉回到均值为0方差为1的标准正态分布。
2. BN公式

其中γ和β分别是缩放因子和偏移量,因为减去均值除以方差未必是最好的分布。所以要加入两个可学习变量来完善数据分布以达到比较好的效果。
3. BN层训练和测试的不同
训练阶段:BN层对每个batch的训练数据进行标准化,即用每一批数据的均值和方差
测试阶段:只输入单个测试样本,因此这个时候用的均值和方差是整个数据集训练后的均值和方差,可以通过滑动平均法求得。简单来说,均值就是直接计算所有batch 均值的平均值,然后对于标准偏差采用每个batch方差的无偏估计。
4. BN训练时为什么不用整个训练集的均值和方差?
因为用整个数据集的均值和方差容易过拟合,对于BN,其实就是对每一batch数据标准化到一个相同的分布,而不同的batch数据均值和方差会有一定的差异,这个差异能够增加模型的鲁棒性,也会在一定程度上减少过拟合。
6.BN的参数量
γ和β是需要学习的参数,在CNN中,某一层的batch大小为M,那么做BN的参数量为M*2
7. BN的优缺点:
优点:
- 可以选择较大的初始学习率,因为每一层的分布都固定的,不会有底层很难train的现象
- 可以不用dropout,L2正则化:BN的使用使得一个mini-batch中的所有样本都被关联在了一起,因此网络不会某一个训练样本中生成确定的结果
- 可以把数据集彻底打乱
- 模型更加健壮
- 模型训练起来更快,减少了梯度消失
- 降低参数初始化敏感
缺点:
- BN非常依赖Batch的大小,当batch值很小的时候,计算的均值和方差不稳定
- 待更新1!!!
NMS流程
- 先设置两个值:一个score的阈值、一个IOU的阈值
- 过滤掉小于score阈值的候选框,并根据类别分类概率进行排序:A < B < C < D < E < F
- 先标记最⼤概率矩形框F是我们要保留下来的候选
- 接下来分别判断A~E与F的IOU是否大于IOU阈值,假设B、D与F的重叠度超过IOU阈值,那么就去除B、D
- 从剩下的A、C、E中,选择概率最大的E,标记为要保存的候选框,然后判断E与A、C的重叠度,去除重叠度超过设定阈值的框
- 重复3~5,直到没有矩形框剩下。
Soft NMS代码与实现
传统NMS缺点:
- 当前两个目标框接近时,分数更低的框就会因为重叠面积过大而被删掉
- NMS的阈值也不太容易确定,设小了就会漏检,设置过大容易增大误检
Soft NMS算法优点:
- 可以很方便引入object detection中,不需要重新训练原有模型
- soft nms在训练中采用传统nms,可以仅在推断代码中实现soft nms
思路:不要直接删除所有IOU大于阈值的框,而是降低置信度。
(1)线性加权
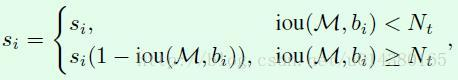
(2)高斯加权
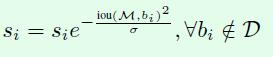
两种改进的思想都是降低框的置信度,从而在第一阶段就被筛选出去。考虑了iou和置信度的关系。
哪些方法可以提升小目标检测效果
- 提高图像分辨率
- 提高模型的输入分辨率
- 平铺图像
- 数据增强
- 自动学习anchor
- 类别优化
为什么加入残差模块会有效果?
假设:如果不使用残差模块,输出为5.1,期望输出为5,如果想要学习输出为5,这个变化率比较低,学习起来是比较困难的。
但是如果设计一个H(X) = F(x)+5=5.1,使得F(x)=0.1,那么学习目标就让0.1变成0,这个是比较简单的,即引入残差模块后的映射对输出变化更加敏感了。
进一步理解:如果F(x) = 5.1,现在继续训练模型,使得映射函数=5。变化率为(5.1-5)/5.1 = 0.02,如果不⽤残差模块的话可能要把学习率从0.01设置为0.0000001。层数少还能对付,⼀旦层数加深的话可能就不太好使了。
ResNet的缺点
resnet真正起作用的层只在中间,深层作用比较小。(在深层网络只有恒等映射在学习,等价于很多小网络在ensemble)
MobileNet系列模型的结构和特点?
-
v1网络结构在VGG基础上使用depthwise 卷积(空间信息)和pointwise 卷积(通道信息)构成,在保证不损失太大精度的同时,大幅降低模型参数量。
-
v2网络结构使用linear bottleneck(线性变换)来代替原本的非线性激活函数,实验证明使用linear bottleneck 可以在小网络中较好地保留有用特征信息。Inverted Residuals 与resnet的通道间操作正好相反。由于v2使用linear bottleneck结构,使其提取的特征维度整体偏低(relu在低维数据下会出现很多0),如果只是使用低维的feature map效果并不好。因此我们需要高维的feature map来进行补充。
-
v3在整体上有两大创新:1.由资源受限的NAS执行模块级搜索;由netadapt执行局部搜索,对各个模块确定之后网络层的微调。2. 网络结构改进:进一步减少网络层数,并引入h-swish激活函数。作者发现swish激活函数能有效提高网络的精度,然而swish计算量太大了。
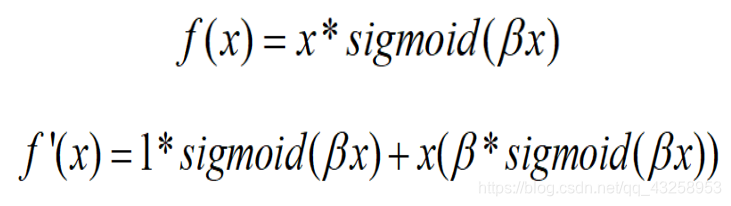
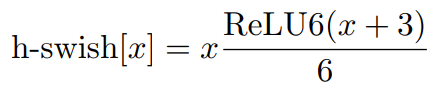
VIT模型的结构和特点?
**特点:**1. VIT直接将标准的transformer结构直接用于图像分类,其模型结构中不含CNN。2.为了满足transformer输入结构要求,将图片打成patch输入到网络中。在最后的输出端,使用了Class Token形式进行分类预测。3. transformer结构vit在大规模数据集上预训练过后,再迁移学习,可以在特定任务上达到SOTA性能。可以具体分成如下几个部分:(1)图像分块嵌入(2)多头注意力结构(3)多层感知机结构(4)使用droppath,class Token, positional encoding
EfficientNet系列的结构和特点?
EfficientNet是通过网络搜索从深度、宽度和输入图片分辨率三个角度共同调节搜索得来得模型,这三个维度并不是相互独立的,对于输入图像分辨率更高的情况,需要有更深的网络来获得更大的感受视野,并且需要有更多的通道来获取更精确的特征。
EfficientNet模型的内部是通过多个MBConv卷积模块实现的,实验证明depthwise 卷积在大模型中依旧非常有效的,因为depthwise 卷积较于标准卷积有更好的特征提取表达能力。使用了DropConnect方法来代替传统dropout来防止过拟合,dropConnect与dropout不同的地方是在训练神经网络模型过程中,它不是对隐层节点的输出进行随机丢弃,而是对隐层节点的输入进行随机丢弃。

数据类别不平衡怎么处理?
- 数据增强
- 对少数类数据做过采样,多数类别数据做欠采样
- 损失函数的权重均衡(focal loss)
- 采集少数类别的数据
- 阈值调整,将原本默认为0.5的阈值调整到:较少类别/(较少类别+ 较多类别)
排序算法

python装饰器
装饰器允许通过将现有函数传递给装饰器,从而向现有函数添加一些额外的功能,该装饰器将执行现有函数的功能和添加的额外功能。
import logging
def use_log(func):def wrapper(*args, **kwargs):logging.warning('%s is running' % func.__name__)return func(*args, **kwargs)return wrapper
@use_log
def bar():print('I am bar')------------结果如下------------
WARNING:root:bar is running
I am bar
python的深拷贝和浅拷贝
在python中,用一个变量给另外一个变量赋值,其实就是给当前内存中的对象增加一个“引用”而已。
- 浅拷贝:创建一个新对象,其内容是原对象中元素的引用(新对象与原对象共享内存中的子对象),例如切片操作、工厂函数、对象的copy方法,copy模块中的copy函数。
- 深拷贝:创建一个新对象,然后递归的拷贝原对象所包含的子对象。深拷贝出来的对象与原对象没有任何关联,copy模块中的deepcopy函数
**注意:**浅拷贝和深拷贝的不同仅仅是对组合对象来说,所谓的组合对象就是包含其他对象的对象,如列表、类实例等。而对于数字、字符串以及其他原子类型,没有拷贝一说,产生的都是原对象的引用。
python是解释语言还是编译语言?
解释语言的优点是可移植性好,缺点是运行需要解释环境,运行起来比编译语言要慢,占用的资源也要多一点,代码效率低
编译语言的优点是运行速度快,代码效率高,编译后程序不可以修改,保密性好。缺点是代码需要经过编译才能运行,可移植性较差,只能在兼容的操作系统上运行。
python的垃圾回收机制
在python中,使用引用计数进行垃圾回收;同时通过标记-清除算法解决容器对象可能产生的循环引用问题,最后通过分代回收算法提高垃圾回收效率
- 引用计数:当有1个变量保存了对象的引用时,此对象的引用计数就会加1。当使用del删除变量指向的对象时,引用计数减1,如果引用计数为0,则将当前对象删除。
- 主要回收垃圾方式:引用计数,每个对象内部都维护了一个值,该值记录对象被引用的次数,如果次数为0,则python垃圾回收机制会自动清除此对象
- 辅助方式:标记-清除算法:被分配对象的计数值与被释放对象的计数值之间差异累计超过某个阈值,则python的收集机制就启动
- 辅助方式:代码中执行gc.collect()命令时,python解释器就会进行垃圾回收。
python中range和xrange的区别
首先,xrange和range函数的用法完全相同,不同的地方是xrange函数生成的不是一个list对象,而是一个生成器。要生成很大的数字序列,使用xrange会比range的性能优很多,因为不需要一上来就开辟很大的内存空间。在python3中,xrange函数被移除了,只保留了range函数,但是range函数的功能结合了xrange和range。之前python2,range中是list类型,python3中是range类型。
相关文章:
深度学习算法面试常问问题(一)
博主秋招遇到的面试问题以及整理其他面经相关问题,无偿分享~ 项目叙述: 算法需求及应用场景算法的调研和初步方案的制定数据的准备(包括数据标注和数据增强)算法的介绍(包括输入和输出,loss、backbone、训…...
Spring 底层原理与解析 - 容器接口
Spring 底层原理与解析 - 容器接口 BeanFactory 能做哪些事 BeanFactory 与 ApplicaiotnContext 到底是谁提前做完了对象的加载 在之前的一篇关于 Spring 的文章Spring IoC 与容器的初始化中提到过,BeanFactory 接口与 ApplicationContext 接口之间的关系 可以看…...
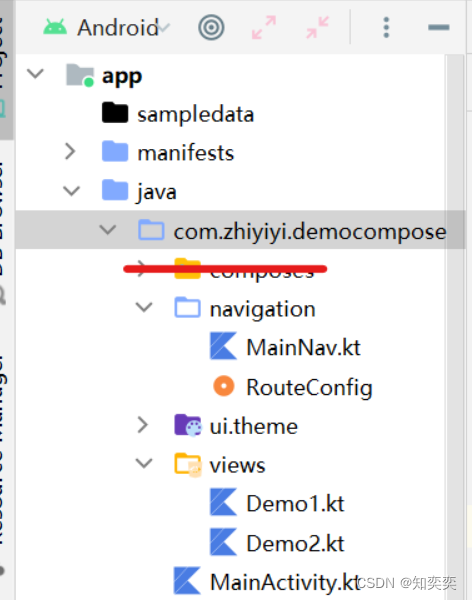
Compose-Navigation简单案例上手
Navigation 快速上手 下面案例简要展示使用 Compose 版本的 Navigation 库来实现两个页面之间的跳转 这是完整的结构(忽略掉红线划过的那个包) 安装适用于 kotlin 的 navigation 依赖 dependencies {implementation("androidx.navigation:navigati…...

855. 考场就座
题目 考场就座 在考场里,一排有 N 个座位,分别编号为 0, 1, 2, …, N-1 。 当学生进入考场后,他必须坐在能够使他与离他最近的人之间的距离达到最大化的座位上。如果有多个这样的座位,他会坐在编号最小的座位上。(另外…...
)
k8s之ingress(二)
文章目录k8s之ingress1.1、Kubernetes 暴露服务的方式:1.2 基本概念1.3为什么需要Ingress资源1.4 Ingress的工作原理1.5ingress 暴露服务的方式总结k8s之ingress 1.1、Kubernetes 暴露服务的方式: Kubernetes暴露服务的方式目前只有三种:LoadBlancer Service、Nod…...
linux下监测串口数据
在编写上下位机通信代码时,需要分阶段测试,确保下位机,线路,上位机都OK. 一.检查设备数据传出 1.确定下位机的串口参数 如果波特率有问题,可能会…...
三分钟深入理解闭包(附详解实例))
【面试之闭包】前端面试那些事(2)三分钟深入理解闭包(附详解实例)
目录1、什么是闭包,什么是作用域1.1 变量作用域1.2 闭包是啥?如何改变变量调用格局1.3 闭包的特性2、怎么用闭包,闭包实例应用2.1 常见闭包实例2.2 闭包异步函数的应用2.3 柯里化的应用3、闭包的优缺点3.1 优点3.2 缺点4、片尾彩蛋【写在前面…...

深入浅出带你学习WebSphere中间件漏洞
前言 上一篇文章给大家介绍了中间件glassfish的一些常见漏洞以及利用方法,今天我给大家带来的是WebSphere中间件的常见漏洞以及这些漏洞的利用方法,下面我们首先介绍一下WebSphere中间件是什么,然后展开来讲关于该中间件的漏洞。 WebSphere…...

如何一眼分辨是C还是C++
C语言的历史C语言是由贝尔实验室的Dennis Ritchie在20世纪70年代初开发的一种通用程序设计语言。在早期的计算机时代,许多计算机使用不同的汇编语言编写程序,这导致了程序的可移植性和代码的可重用性很低。因此,Dennis Ritchie在开发C语言时试…...
CMake系列:正确使用多配置编译系统
目录 常见错误 问题现象 正确做法 if指令应该什么时候使用 活学活用 把IF指令用于多配置编译系统是很多初学者容易犯下的错误。这篇文章启示性的教你如何正确理解、使用CMake的多配置编译系统。 常见错误 以Debug和Release配置有不同的宏定义为例,如下所示&a…...
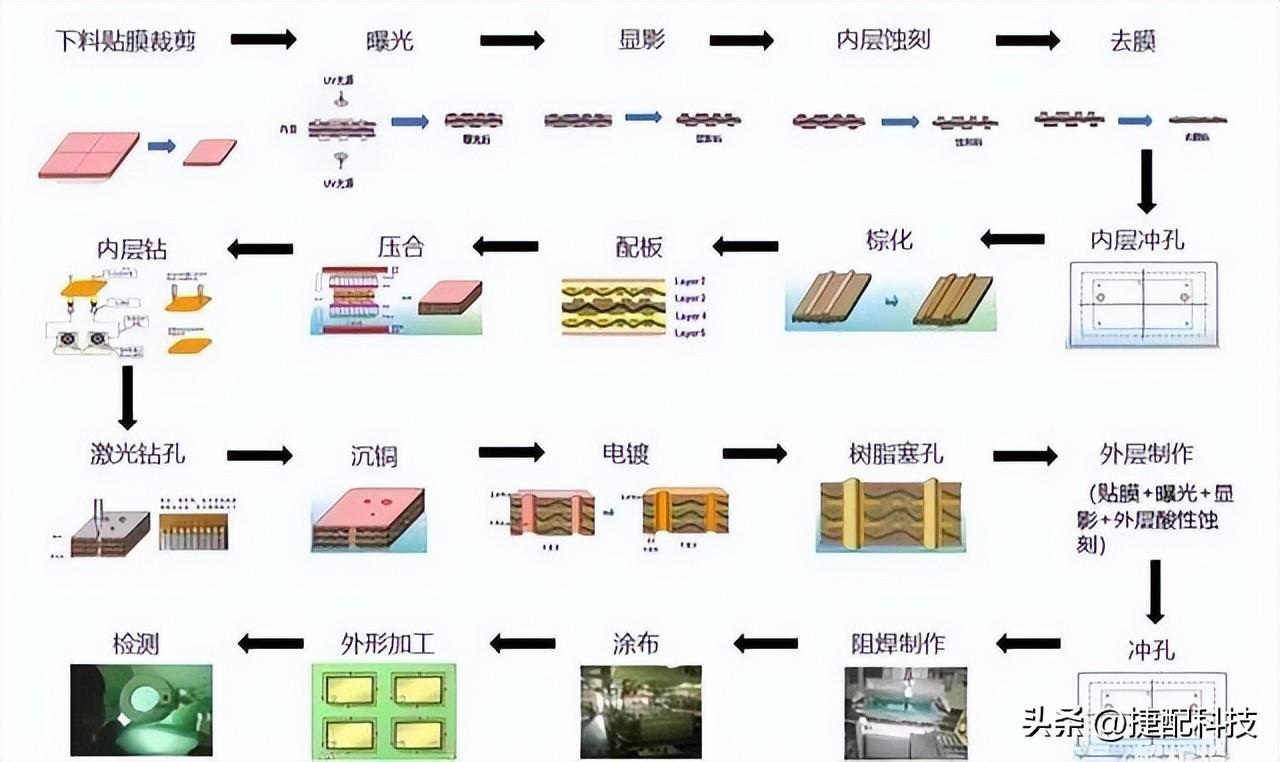
PCB中的HDI板生产中的变化
关键词:HDI概述 HDI发展演变 HDI生产难点如果把一整个电子产业比作浩瀚的宇宙,那些智能电子设备就像宇宙中闪耀的星光,当你以“上帝”的视角手持放大镜去观察时,这些闪烁的星光点点其实都是一个个由精密的“自然规律”所“设计”好…...

程序分析与神经网络后门
原文来自微信公众号“编程语言Lab”:程序分析与神经网络后门 搜索关注“编程语言Lab”公众号(HW-PLLab)获取更多技术内容! 欢迎加入编程语言社区 SIG-程序分析,了解更多程序分析相关的技术内容。 加入方式:…...

redis主从哨兵模式
一.为什么用redis主从模式 1.数据备份:主从复制实现数据的热备份。 2.故障恢复:当主节点出现问题时,由从节点提供服务,实现快速恢复。 3.负载均衡:读写分离,主节点提供写服务,从节点提供读服务。在写少读多时提高Redis的并发。 二.为什么使用哨兵模式 主要用于主节…...
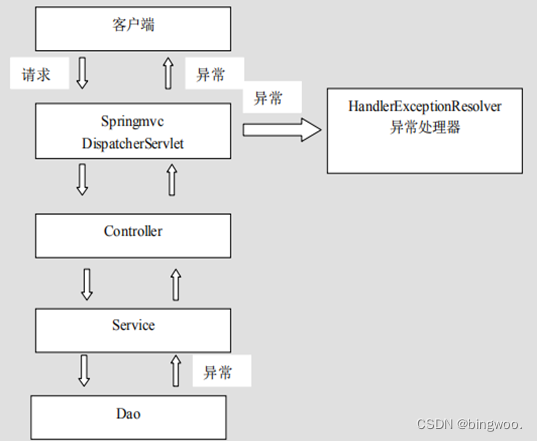
Spring 系列之 MVC
Spring 系列文章目录 文章目录Spring 系列文章目录前言一、介绍二、项目搭建1.创建空项目2.设置maven和lombok3.创建maven web module4. 配置Tomcat启动运行项目(选择local本地)5. 导入jar依赖包6.在web.xml中配置DispatcherServlet7. 加入SpringMVC的配…...
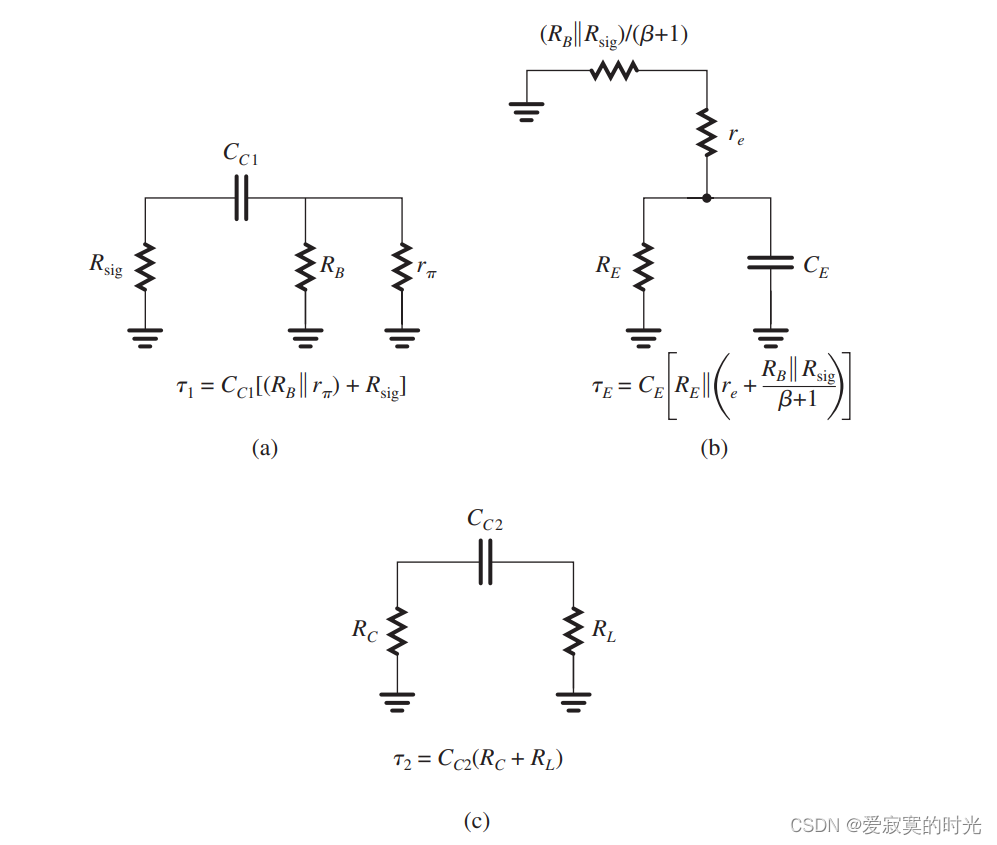
电子技术——分立CS和CE放大器的低频响应
电子技术——分立CS和CE放大器的低频响应 我们之前在学习放大器中从来没有关系过信号频率对放大器的影响,也就是说我们默认放大器具有无限的带宽,这当然不符合现实逻辑。为了说明这一点,我们使用下图: 上图描述了MOS或BJT分立电路…...

代码随想录【Day16】| 104. 二叉树的最大深度、111. 二叉树的最小深度、222. 完全二叉树的节点个数
104. 二叉树的最大深度 题目链接 题目描述: 给定一个二叉树,找出其最大深度。 二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。 说明: 叶子节点是指没有子节点的节点。 示例: 给定二叉树 [3,9,20,null,null,15,7],…...

状态机图、通信图题
1.下列关于通信图与顺序图中的对象的相同点的叙述.正确的是(D)。A.两种图中都可以表示对象的创建和销毁B.对象在两种图中的位置都没有任何限制C.对象在两种图中的表示方式完全一致D.对象名在两种图中的表示完全一致2.下列关于通信图的说法错误的是(C)。A.通信图是对一次交互过程…...

分布式文件存储Minio学习入门
文章目录一、分布式文件系统应用场景1. Minio介绍Minio优点2. MinIO的基础概念、3. 纠删码ES(Erasure Code)4. 存储形式5. 存储方案二、Docker部署单机Minio三、minio纠删码模式部署四、分布式集群部署分布式存储可靠性常用方法冗余校验分布式Minio优势运行分布式minio使用dock…...
handler解析(4)-Message及Message回收机制
Message中可以携带的信息 Message中可以携带的数据比较丰富,下面对一些常用的数据进行了分析。 /*** 用户定义的消息代码,以便当接受到消息是关于什么的。其中每个Hanler都有自己的命名控件,不用担心会冲突*/ public int what; /*** 如果你…...

Linux使用定时任务监控java进程并拉起
需求描述: 设计一个脚本,通过Linux定时任务,每分钟执行一次,监控jar包进程是否存在,存在则不做动作,不存在则重新拉起jar包程序。 定时任务配置: */1 * * * * bash -x /root/myfile/jars/che…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...

【堆垛策略】设计方法
堆垛策略的设计是积木堆叠系统的核心,直接影响堆叠的稳定性、效率和容错能力。以下是分层次的堆垛策略设计方法,涵盖基础规则、优化算法和容错机制: 1. 基础堆垛规则 (1) 物理稳定性优先 重心原则: 大尺寸/重量积木在下…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...

深入理解 React 样式方案
React 的样式方案较多,在应用开发初期,开发者需要根据项目业务具体情况选择对应样式方案。React 样式方案主要有: 1. 内联样式 2. module css 3. css in js 4. tailwind css 这些方案中,均有各自的优势和缺点。 1. 方案优劣势 1. 内联样式: 简单直观,适合动态样式和…...