2023年美赛C题 预测Wordle结果Predicting Wordle Results这题太简单了吧
2023年美赛C题 预测Wordle结果Predicting Wordle Results
更新时间:2023-2-17 11:30

1 题目
Wordle是纽约时报目前每天提供的一个流行的谜题。玩家尝试在6次或更少的时间内猜出一个5个字母的单词来解决这个谜题,每猜一次都会收到反馈。在这个版本中,每次猜出的单词必须是一个真实的英语单词。没有被比赛认定为单词的猜测是不允许的。Wordle继续流行,现在有60多种语言的版本。
纽约时报网站directions for Wordle指出,在你提交文字后,瓷砖的颜色将发生变化。黄色的瓦片表示字母在那个瓦片里,但它在错误的位置。绿色瓦片表示该瓦片中的字母在单词中,并且在正确的位置。灰色瓦片表示该瓦片中的字母根本不包含在单词中(见附件2)[2]。图1是一个示例解决方案,在三次尝试中找到了正确的结果。

图1:2022年7月21日[3]Wordle谜题的示例解决方案
玩家可以在常规模式或”困难模式”中玩。《Wordle》的困难模式要求玩家在一个单词中找到一个正确的字母(方块是黄色或绿色),这些字母必须用于随后的猜测,从而增加了游戏的难度。图1中的示例是在困难模式下播放的。
许多(但不是全部)用户在推特上报告他们的分数。这个问题,MCM生成的一个文件的日常结果1月7日,从2022年12月31日,2022(见附件1),这个文件包含了日期,比赛号码,词的一天,那天报告分数的人数,在困难模式的玩家数量,和猜测这个词的比例在一个尝试,两次,三次,四个尝试5次,六个尝试,或者无法解决的难题(X)。例如,在图2中7月20日,这个词2022年是”陈腐的”,结果是通过挖掘推特获得的。虽然图2中的百分比总和为100%,但在某些情况下,由于四舍五入的原因,这可能并不正确。

图2:2022年7月20日报告结果向推特[4]的分布
要求
《纽约时报》要求您对这个文件中的结果进行分析,以回答几个问题。
(1)报告结果的数量每天都在变化。开发一个模型来解释这一变化,并使用您的模型为2023年3月1日报告的结果数量创建一个预测区间。单词的任何属性是否会影响困难模式下玩家得分的百分比?如果有,是如何影响的?如果不是,为什么不是?
(2)对于一个给定的未来解决方案Word,在未来的日期,开发一个模型,使您能够预测报告结果的分布。换句话说,预测未来日期(1,2,3,4,5,6,X)的相关百分比。你的模型和预测有哪些不确定性?请给出一个具体的例子,说明你对2023年3月1日“EERIE”一词的预测。你对模型的预测有多大信心?
(3)开发并总结一个模型,根据难度对解决方案单词进行分类。识别与每个分类相关的给定单词的属性。使用你的模型,EERIE这个词有多难?讨论你的分类模型的准确性。
(4)列出并描述这个数据集的其他一些有趣的特征。
(5)最后,给《纽约时报》的字谜编辑写一封一到两页的信,总结你的研究结果。
总页数不超过25页的PDF解决方案应包括:
- 一页汇总表。
- 目录。
- 您的完整解决方案。
- 一封一到两页的求职信。
- 参考名单。
注意:MCM大赛的篇幅限制为25页。您提交的所有内容(汇总表、目录、报告、参考名单和任何附录)都应在25页的限制范围内。你必须引用你的想法、图像和报告中使用的任何其他材料的来源。
附件
1.数据文件。Problem_C_Data_Wordle.xlsx
2 思路方案分析
2.1 分析数据
(1)第一步了解游戏规则
【爱与私语,一款文字游戏为何风靡美国|wordle的玩法和故事】 https://www.bilibili.com/video/BV1iu411U7LJ/?share_source=copy_web&vd_source=d2dd5fcbeeeec396792650b25c110a13
(2)第二步,理解提供的excel内容
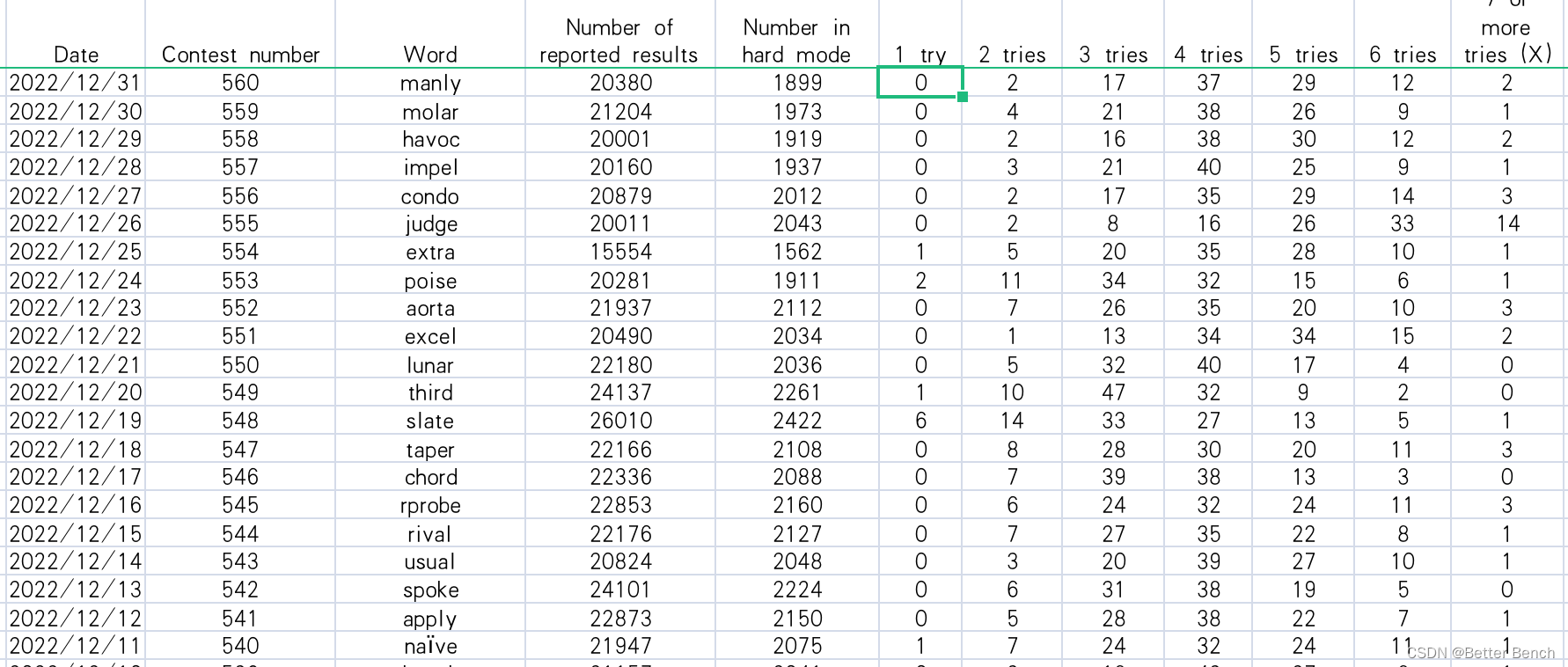
Date:给定Wordle字谜的日期,格式为mm-dd-yyyy(月日-年)。
Contest number:Wordle谜题的索引,从2022年1月7日的202开始。
Word:单词
Number of reported results:当天记录的总分数。
Number in hard mode:当天在hard模式得分。
1try:玩家一次猜中谜题的百分比。
2tries:玩家两次猜中谜题的百分比。
3tries:玩家三次猜中谜题的百分比。
4tries:玩家在四次猜测中解决谜题的百分比。
5tries:玩家在5次猜测中解决谜题的百分比。
6tries:玩家在6次猜测中解决谜题的百分比。
7 on tries more(X):在6次或更少的尝试中无法解决谜题的玩家的百分比。
2.2 思路
(1)问题一: 报告结果的数量每天都在变化。开发一个模型来解释这一变化,并使用您的模型为2023年3月1日 Number of reported results创建一个预测区间。单词的任何属性是否会影响困难模式下玩家得分的百分比?如果有,是如何影响的?如果不是,为什么不是?
分析:第一小问,Number of reported results这一列是一个时间序列,创建一个时间序列预测预测模型,采用线性回归或者非线性回归方法来预测3月1号的数据。有一定的误差,将预测结果结合误差设置一个预测区间。
单词的属性有元音和辅音以及字母。将字母数量、元音、辅音编码后分析与7种百分比的分析相关性,可视化相关性,得出结论。
元音字母有5个:A、E、I、O、U;辅音字母有21个:B、C、D、F、G、H、J、K、L、M、N、P、Q、R、S、T、V、W、X、Z、Y
(2)问题二: 对于一个给定的未来解决方案Word,在未来的日期,开发一个模型,使您能够预测报告结果的分布。换句话说,预测未来日期(1,2,3,4,5,6,X)的相关百分比。你的模型和预测有哪些不确定性?请给出一个具体的例子,说明你对2023年3月1日“EERIE”一词的预测。你对模型的预测有多大信心?
分析:针对1-7种尝试,建立7个回归模型,将单词进行编码,并提取特征,采用机器学习的回归模型,进行预测7种情况的百分比。
回归模型以下几种:
- 线性回归
- 多项式回归
- 逐步回归
- 岭回归
- 套索回归
- 弹性回归
- 分位数回归
- 贝叶斯线性回归
- 偏最小二乘回归
题目问有多大信心,就是对回归模型进行评价,回归模型的评价指标有
- 均方误差(Mean Squared Error,MSE)
观测值与真值偏差的平方和与观测次数的比值:
MSE=1m∑i=1n(yi−yi^2)MSE= \frac{1}{m} \sum_{i=1}^n (y_i-\hat{y_i}^2) MSE=m1i=1∑n(yi−yi^2)
这就是线性回归中最常用的损失函数,线性回归过程中尽量让该损失函数最小。那么模型之间的对比也可以用它来比较。
MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
def rmse(y_test, y_true):return sp.mean((y_test - y_true) ** 2)
- 均方根误差(标准误差)(Root Mean Squard Error,RMSE)
标准差是方差的算术平方根。
标准误差是均方误差的算术平方根。
标准差是用来衡量一组数自身的离散程度,而均方根误差是用来衡量观测值同真值之间的偏差,它们的研究对象和研究目的不同,但是计算过程类似。
RMSE=1m∑i=1n(yi−yi^2)RMSE= \sqrt{\frac{1}{m} \sum_{i=1}^n (y_i-\hat{y_i}^2)} RMSE=m1i=1∑n(yi−yi^2)
它的意义在于开个根号后,误差的结果就与数据是一个级别的,可以更好地来描述数据。标准误差对一组测量中的特大或特小误差反映非常敏感,所以,标准误差能够很好地反映出测量的精密度。这正是标准误差在工程测量中广泛被采用的原因。
python 实现
def rmse(y_test, y_true):return sp.sqrt(sp.mean((y_test - y_true) ** 2))
- 平均绝对误差(Mean Absolute Error,MAE)
平均绝对误差是绝对误差的平均值 :
MAE=1m∑i=1n∣yi−yi^∣MAE= \frac{1}{m} \sum_{i=1}^n |y_i-\hat{y_i}| MAE=m1i=1∑n∣yi−yi^∣
平均绝对误差能更好地反映预测值误差的实际情况.
python 实现如下
def mae(y_test, y_true):return np.sum(np.absolute(y_test - y_true)) / len(y_test)
(3)问题三: 开发并总结一个模型,根据难度对解决方案单词进行分类。识别与每个分类相关的给定单词的属性。使用你的模型,EERIE这个词有多难?讨论你的分类模型的准确性。
分析:对单词进行编码后,采用聚类方法,可以将单词难度分为三类或者更多,如困难、一般、简单。然后对每一类的单词可视化分析,并描述数据得出结论。
聚类算法较多,在论文中可以使用改进的聚类算法
- K-Means(K均值)聚类
Python聚类案例代码
# K-Means(K均值)聚类
import numpy as np
from sklearn.cluster import KMeans
data = np.random.rand(100, 3) #生成一个随机数据,样本大小为100, 特征数为3#假如我要构造一个聚类数为3的聚类器
estimator = KMeans(n_clusters=3)#构造聚类器
estimator.fit(data)#聚类
label_pred = estimator.labels_ #获取聚类标签
centroids = estimator.cluster_centers_ #获取聚类中心
inertia = estimator.inertia_ # 获取聚类准则的总和- 均值漂移聚类
"""聚类 均值漂移算法量化带宽,决定每次调整概率密度函数的步进量
"""
import numpy as np
import sklearn.cluster as sc
import matplotlib.pyplot as mp# 加载数据
x = np.loadtxt("./multiple3.txt", delimiter=",")# 量化带宽 quantile 量化宽度
bw = sc.estimate_bandwidth(x, n_samples=len(x), quantile=0.1)
# 均值漂移算法 模型
model = sc.MeanShift(bandwidth=bw, bin_seeding=True)
model.fit(x)centers = model.cluster_centers_
print(centers)# 分类边界数据
n = 500
l, r = x[:, 0].min() - 1, x[:, 0].max() + 1
b, t = x[:, 1].min() - 1, x[:, 1].max() + 1
grid_x = np.meshgrid(np.linspace(l, r, n),np.linspace(b, t, n))
flat_x = np.column_stack((grid_x[0].ravel(), grid_x[1].ravel()))
flat_y = model.predict(flat_x)
grid_y = flat_y.reshape(grid_x[0].shape)
prd_y = model.predict(x)# 绘制结果
mp.figure('MeanShift Cluster', facecolor='lightgray')
mp.title('MeanShift Cluster', fontsize=20)
mp.xlabel('x', fontsize=14)
mp.ylabel('y', fontsize=14)
mp.tick_params(labelsize=10)
# 分类边界
mp.pcolormesh(grid_x[0], grid_x[1], grid_y, cmap='gray')
# 点数据
mp.scatter(x[:, 0], x[:, 1], c=prd_y, cmap="jet", s=80)
# 分类中心点
mp.scatter(centers[:, 0], centers[:, 1], marker='+', c='gold', s=1000, linewidth=3)
mp.show()- 基于密度的聚类方法(DBSCAN)
# DBSCAN 算法print(__doc__)import numpy as npfrom sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,random_state=0)X = StandardScaler().fit_transform(X)# Compute DBSCAN
db = DBSCAN(eps=0.1, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)print('Estimated number of clusters: %d' % n_clusters_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"% metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f"% metrics.silhouette_score(X, labels))#
import matplotlib.pyplot as plt# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):if k == -1:# Black used for noise.col = [0, 0, 0, 1]class_member_mask = (labels == k)xy = X[class_member_mask & core_samples_mask]plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),markeredgecolor='k', markersize=14)xy = X[class_member_mask & ~core_samples_mask]plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),markeredgecolor='k', markersize=6)plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()- 层级聚类算法
from sklearn.cluster import AgglomerativeClustering #导入sklearn的层次聚类函数
model = AgglomerativeClustering(n_clusters = k, linkage = 'ward')
model.fit(data) #训练模型
#详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import linkage,dendrogram
#这里使用scipy的层次聚类函数
Z = linkage(data, method = 'ward', metric = 'euclidean') #谱系聚类图
P = dendrogram(Z, 0) #画谱系聚类图
plt.show()-
用高斯混合模型(GMM)的最大期望(EM)聚类
-
图团体检测(Graph Community Detection)
(4)问题四: 列出并描述这个数据集的其他一些有趣的特征。
对数据集的Number of reported results:当天记录的总分数、Number in hard mode:当天在hard模式得分、Tries进行可视化分析,以朱庄头、饼状图、散点图等方式进行可视化分析,得出结论。
3 python实现
# 待更新,代码获取,浏览器输入: betterbench.top/#/40/detail
获取方式:betterbench.top/#/40/detail
相关文章:
2023年美赛C题 预测Wordle结果Predicting Wordle Results这题太简单了吧
2023年美赛C题 预测Wordle结果Predicting Wordle Results 更新时间:2023-2-17 11:30 1 题目 2023年MCM 问题C:预测Wordle结果 Wordle是纽约时报目前每天提…...
UE4 渲染学习笔记(未完)
原文链接:虚幻4渲染管线入门 - 知乎 从原文摘抄一下: 渲染框架 1,一套是传统的以RHICmdList为核心构建RenderPass,从RHICmdList.BeginRenderPass(...)开始,以RHICmdList.EndRenderPass()结束的框架。 2.一套是以新的Gr…...

Ajax?阿贾克斯?
一、Ajax简介 AJAX Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。 AJAX 不是新的编程语言,而是一种使用现有标准的创新方法。 AJAX 最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网…...

项目质量要怎么保持? 如何借助系统软件进行管理
对于任何项目型的企业总是很关心项目成本的话题,但不知从什么时候开始,高质量等于高成本成了各个企业的一种潜意识。 如果交付的项目产品不符合质量标准,即使企业使用最好的项目管理工具或者每个里程碑都达到并在预算范围内完成项目…...
没有接口文档的怎样进行接口测试
前言: 在进行接口测试之前,一般开发会提供接口文档,给出一些接口参数和必要熟悉,便于我们编写接口脚本。但如果没有提供接口开发文档的请求下,我们该如何编写接口测试脚本呢?在编写测试脚本前要做哪些必要…...
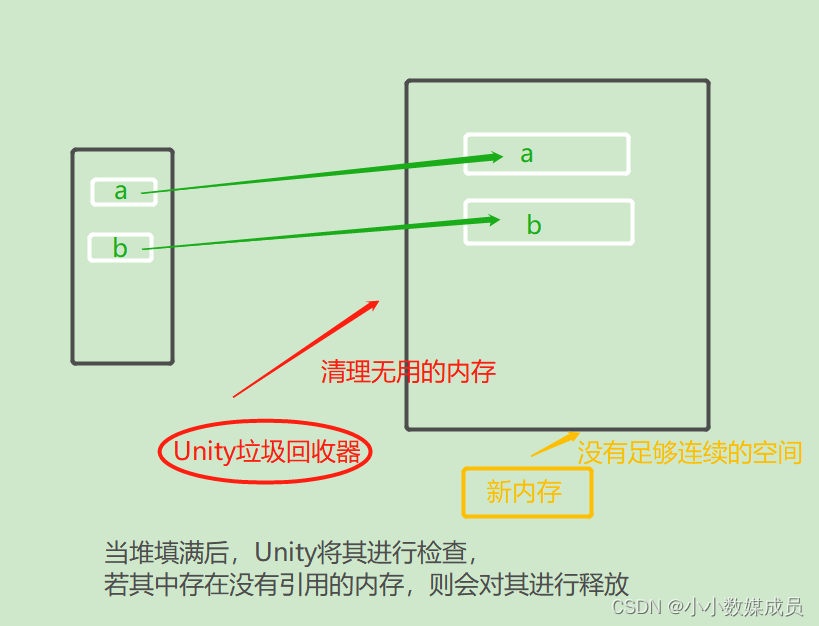
Unity—游戏设计模式+GC
每日一句:"少年一贯快马扬帆 道阻且长不转弯 要盛大要绚烂要哗然 要用理想的泰坦尼克去撞现实的冰川 要当烧赤壁的风而非借箭的草船 要为一片海就肯翻万山。" 目录 状态模式: 外观模式 组合模式, 单例模式 命令模式 观察者模…...
【刷题笔记】--二分查找binarysearch
当给一个有序的数组,在其中查找某个数,可以考虑用二分查找。 题目1: 二分查找的思路: 设置left和right指针分别指向要查找的区间。mid指针指向这个区间的中间。比较mid指针所指的数与target。 如果mid所指的数小于target&…...

Python版本的常见模板(二) 数论(一)
文章目录前言质数相关质数判断求约数求取区间质数埃氏筛法线性筛法分解质因数欧拉欧拉函数求取单个数线性筛法求取欧拉定理求逆元快速幂/幂取模欧几里得算法求最小公约数拓展欧几里得算法求解同余方程前言 本文主要是提供Python版本的常见的一些与数论相关的模板,例…...
)
SQL快速上手(知识点总结+训练资料)
文章目录一 SQL训练资料二 SQL知识点总结1.SQL语句的执行顺序2.窗口函数3.字符串处理函数模糊查询三 SQL题目的总结一 SQL训练资料 牛客SQL题目 猴子数据分析题目 关注的公众号 猴子数据分析 二 SQL知识点总结 1.SQL语句的执行顺序 每一个子句产生的中间结果供接下来的子句…...

无需经验的steam搬砖,每天操作1小时,轻松创业赚钱!
我作为一个95后社畜,就喜欢倒腾各种赚钱的事情,8年老韭菜告诉你,副业创收一点都不难,难就难在是否找对项目,俗话说方向不对,努力白费! 什么做苦力、技能、直播卖货,电商等等对比我这…...
如何创建你的公司的FAQ页面?
很多企业考虑为公司搭建一个“常见问题”页面,作为帮助客户回答关于产品和服务的常见问题的一种方式。 FAQ页面和登录/销售页面不同,没有展现出直接的投资回报,但是为团队节省了其他成本,据了解,高达67%的客户相比于跟…...
CK-GW06-E03与欧姆龙PLC配置指南
CK-GW06-E03与欧姆龙PLC配置指南CK-GW06-E03是一款支持标准工业EtherCAT协议的网关控制器,方便用户集成到PLC等控制系统中。本控制器提供了网络 POE 供电和直流电源供电两种方式,确保用户在使用无POE供电功能的交换机时可采用外接电源供电;系统还集成了六…...
使用docker-compose部署RocketMQ5.0
简介:使用docker-compose部署rocketmq5.0。文中会介绍docker-compose版本以及需要注意的项第一步:进入hub.docker.com搜索rocketmq我们选择第一个,因为第一个是7个月前更新的,(我看有很多博客使用的依旧是最下面的那种…...

嵌入式ARM设计编程(四) ARM启动过程控制
文章和代码已归档至【Github仓库:hardware-tutorial】,需要的朋友们自取。或者公众号【AIShareLab】回复 嵌入式 也可获取。 一、实验目的 (1) 掌握建立基本完整的ARM 工程,包含启动代码,C语言程序等&…...

企业维基都说好,今天我们来看看 wiki 软件的缺点有哪些?
企业维基企业wiki和内部知识库可能看起来是一回事——但它们实际上是非常不同的软件类型。也许您可能不知道你在寻找的是知识基础软件,还是wiki软件。 无论哪种方式,缺乏知识都是生产力的巨大瓶颈。事实上,未能分享知识是财富500强企业每年亏…...
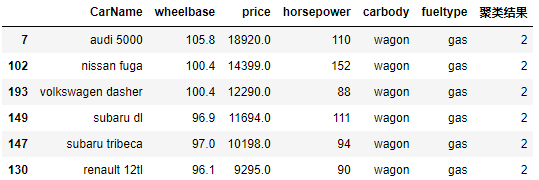
08- 汽车产品聚类分析综合项目 (机器学习聚类算法) (项目八)
找出性价比较高的车 LabelEncoder: python:sklearn标签编码(LabelEncoder) sklearn.preprocessing.LabelEncoder的使用:在训练模型之前,通常都要对数据进行一定得处理。将类别编号是一种常用的处理方法,比如把类别“电脑”,“手机…...

揭开苹果供应链,如何将其命运与中国深度捆绑
前 言 诺基亚在2007年时拥有9亿用户,在手机市场上占据主导地位,福布斯在当时以“谁能赶上手机之王?”为标题刊登了一篇关于该公司的报道,与此同时,苹果公司推出了iPhone系列产品。16年后,苹果公司以充足的…...
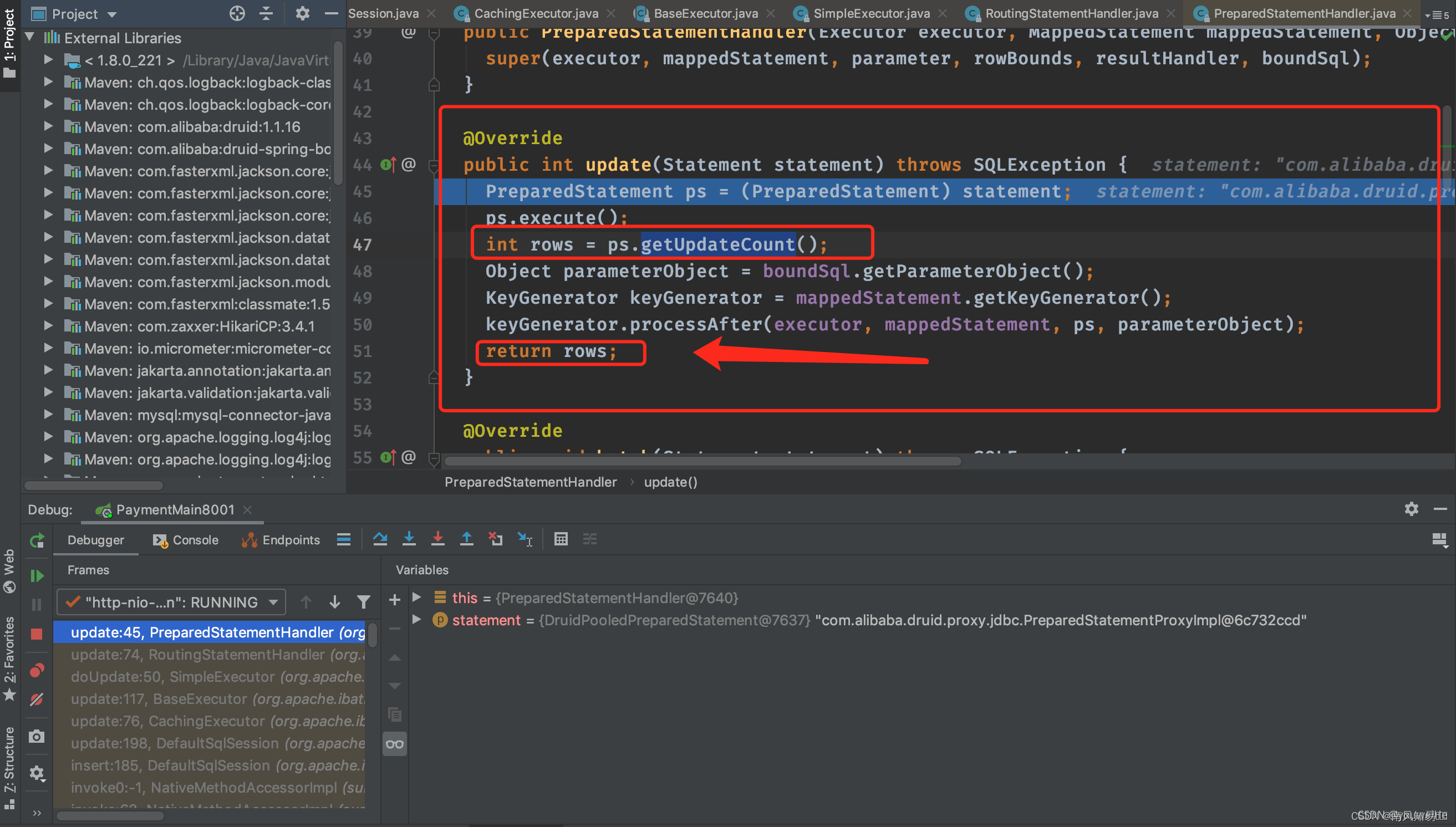
Mybatis 之useGeneratedKeys注意点
一.例子 Order.javapublic class Order {private Long id;private String serial; }orderMapper.xml<?xml version"1.0" encoding"UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org/DTD Mapper 3.0" "http://mybatis.org/dtd…...
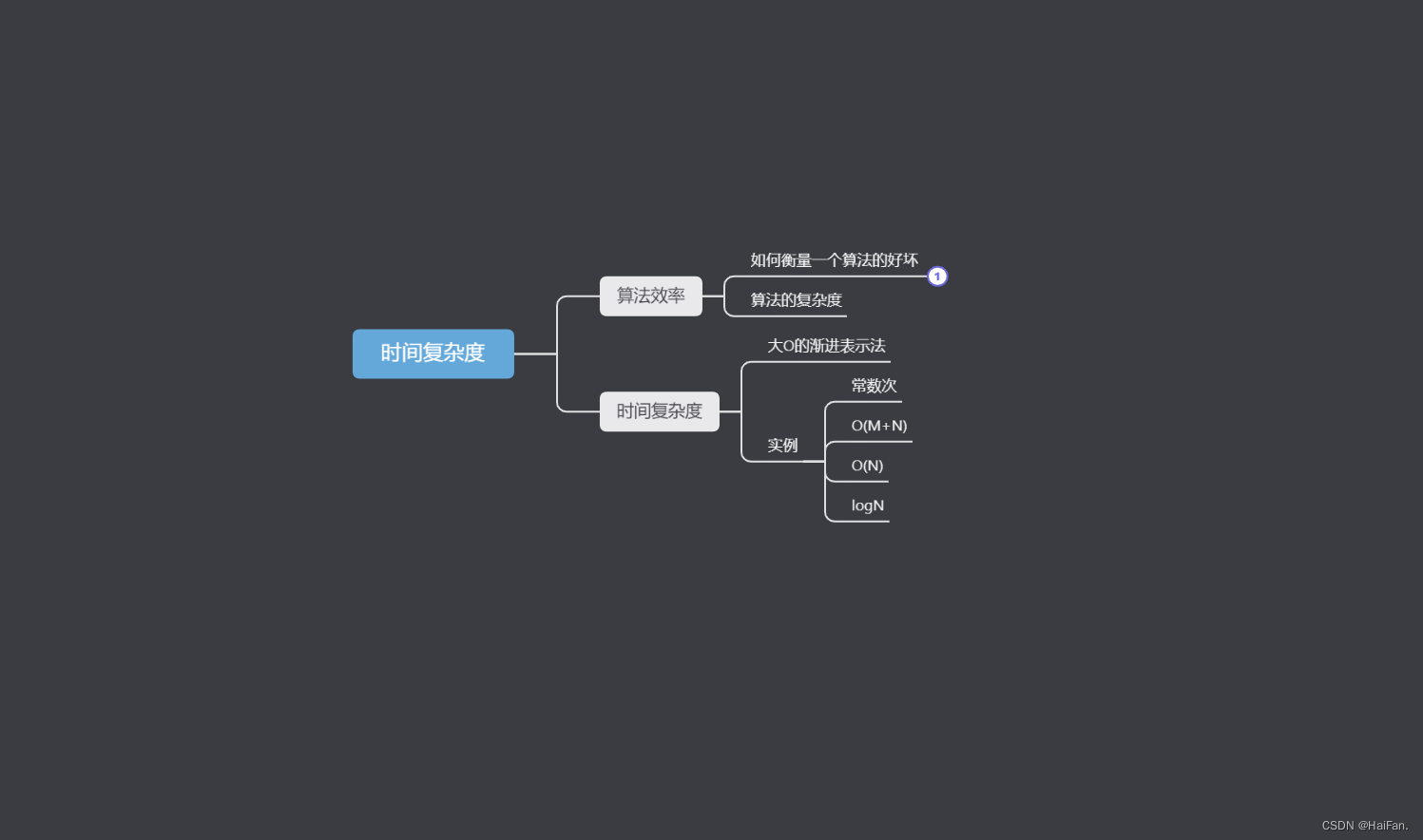
数据结构---时间复杂度
专栏:数据结构 个人主页:HaiFan. 专栏简介:开学数据结构,接下来会慢慢坑新数据结构的内容!!!! 时间复杂度前言1.算法效率1.1如何衡量一个算法的好坏1.2算法的复杂度2.时间复杂度2.1大…...

如何保证集合是线程安全的 ConcurrentHashMap如何实现高效地线程安全?
第10讲 | 如何保证集合是线程安全的? ConcurrentHashMap如何实现高效地线程安全? 我在之前两讲介绍了 Java 集合框架的典型容器类,它们绝大部分都不是线程安全的,仅有的线程安全实现,比如 Vector、Stack,在性能方面也…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...