Server端的Actor,分工非常的明确,但是只将Actor作为一部手机来用,真的合适吗?
这是一篇介绍PowerJob,Server端Actor的文章,如果感兴趣可以请点个关注,大家互相交流一下吧。

server端一共有两个Actor,一个是处理worker传过来的信息,一个是server之间的信息传递。
处理Worker的Actor叫做WorkerRequestAkkaHandler,处理Server之间的叫做FriendRequestHandler。从名字来看也是非常的有意思,server之间彼此是朋友,worker之间没有什么朋友,有的只是上下级,说跑偏了。
WorkerRequestAkkaHandler
主要接收五种类型的是消息
-
来自worker的心跳信息(确保worker是活着的)
-
任务实例的状态信息(查看worker的工作进展)
-
worker的日志信息(监视worker是工作每一步是否有错误)
-
worker部署容器的信息(worker额外做了哪些工作)
-
查询执行器集群的信息(来新员工要第一时间知道)
心跳信息的发送与接收
timingPool.scheduleAtFixedRate(new WorkerHealthReporter(workerRuntime), 0, 15, TimeUnit.SECONDS);
心跳的发送,是由worker端的WorkerHealthReporter的run方法发送的,该类实现了Runnable接口,在worker启动的时候,被设置成了每隔15秒执行一次,是worker的后台执行的程序。
心跳的接收,是由server端的WorkerRequestAkkaHandler,接收之后将信息存入到内存中,顺便记录日志,可以自行接入到ELK系统中去(如果连接到ELK)。
这一步操作的作用就是确认worker都活着,当有任务来临的时候,将任务发送到所有活着的,或者发送到状态更好的worker去执行。
任务实例的状态信息
发送方主要是TaskTracker,因为TaskTracker是一个抽象类,所以有两个实现类,一个是FrequentTaskTracker,主要负责是秒级任务,一个是CommonTaskTracker,主要负责管理JobInstance的运行,负责任务派发,这三个类均会发送任务实例的状态信息,抽象类TaskTracker主要是在创建任务的时候,如果发生异常,就会向server发送发生异常的任务实例的状态信息,源代码如下:
public static TaskTracker create(ServerScheduleJobReq req, WorkerRuntime workerRuntime) {try {... ...} catch (Exception e) {// 直接发送失败请求TaskTrackerReportInstanceStatusReq response = new TaskTrackerReportInstanceStatusReq();//这就是一堆set信息,没什么好看的...String serverPath = AkkaUtils.getServerActorPath(workerRuntime.getServerDiscoveryService().getCurrentServerAddress());ActorSelection serverActor = workerRuntime.getActorSystem().actorSelection(serverPath);serverActor.tell(response, null);}return null;
}FrequentTaskTracker主要是在Check内部类里面的的reportStatus方法执行,是一个定时执行的方法。
CommonTaskTracker也是在一个内部类StatusCheckRunnable里面的innerRun方法执行,主要是检查当前任务的执行状态,每隔13秒回执行一次,这个时间可以在启动java的时候设置。
接收端是server的WorkerRequestAkkaHandler类,接收到信息之后更新任务状态,主要代码是InstanceManager的updateStatus方法。源代码如下:为了篇幅不太长,有些日志输出给省略了,大部分都是源代码的注释说明,感觉说的挺详细,还不乏幽默感,所以就保留了。
public void updateStatus(TaskTrackerReportInstanceStatusReq req) throws ExecutionException {Long instanceId = req.getInstanceId();// 获取相关数据JobInfoDO jobInfo = instanceMetadataService.fetchJobInfoByInstanceId(req.getInstanceId());InstanceInfoDO instanceInfo = instanceInfoRepository.findByInstanceId(instanceId);if (instanceInfo == null) {return;}// 丢弃过期的上报数据if (req.getReportTime() <= instanceInfo.getLastReportTime()) {return;}// 丢弃非目标 TaskTracker 的上报数据(脑裂情况)if (!req.getSourceAddress().equals(instanceInfo.getTaskTrackerAddress())) {return;}InstanceStatus receivedInstanceStatus = InstanceStatus.of(req.getInstanceStatus());Integer timeExpressionType = jobInfo.getTimeExpressionType();// 更新 最后上报时间 和 修改时间instanceInfo.setLastReportTime(req.getReportTime());instanceInfo.setGmtModified(new Date());// 下面这个IF主要是处理FrequentTaskTracker发来的消息// FREQUENT 任务没有失败重试机制,TaskTracker一直运行即可,只需要将存活信息同步到DB即可// FREQUENT 任务的 newStatus 只有2中情况,一种是 RUNNING,一种是 FAILED(表示该机器 overload,需要重新选一台机器执行)// 综上,直接把 status 和 runningNum 同步到DB即可if (TimeExpressionType.FREQUENT_TYPES.contains(timeExpressionType)) {// 如果实例处于失败状态,则说明该 worker 失联了一段时间,被 server 判定为宕机,而此时该秒级任务有可能已经重新派发了,故需要 Kill 掉该实例if (instanceInfo.getStatus() == InstanceStatus.FAILED.getV()) {stopInstance(instanceId, instanceInfo);return;}LifeCycle lifeCycle = LifeCycle.parse(jobInfo.getLifecycle());// 检查生命周期是否已结束if (lifeCycle.getEnd() != null && lifeCycle.getEnd() <= System.currentTimeMillis()) {stopInstance(instanceId, instanceInfo);instanceInfo.setStatus(InstanceStatus.SUCCEED.getV());} else {instanceInfo.setStatus(receivedInstanceStatus.getV());}instanceInfo.setResult(req.getResult());instanceInfo.setRunningTimes(req.getTotalTaskNum());instanceInfoRepository.saveAndFlush(instanceInfo);// 任务需要告警if (req.isNeedAlert()) {alert(instanceId, req.getAlertContent());}return;}// 更新运行次数if (instanceInfo.getStatus() == InstanceStatus.WAITING_WORKER_RECEIVE.getV()) {// 这里不会存在并发问题instanceInfo.setRunningTimes(instanceInfo.getRunningTimes() + 1);}// QAQ ,不能提前变更 status,否则会导致更新运行次数的逻辑不生效继而导致普通任务 无限重试instanceInfo.setStatus(receivedInstanceStatus.getV());boolean finished = false;if (receivedInstanceStatus == InstanceStatus.SUCCEED) {instanceInfo.setResult(req.getResult());instanceInfo.setFinishedTime(System.currentTimeMillis());finished = true;} else if (receivedInstanceStatus == InstanceStatus.FAILED) {// 当前重试次数 <= 最大重试次数,进行重试 (第一次运行,runningTimes为1,重试一次,instanceRetryNum也为1,故需要 =)if (instanceInfo.getRunningTimes() <= jobInfo.getInstanceRetryNum()) {// 延迟10S重试(由于重试不改变 instanceId,如果派发到同一台机器,上一个 TaskTracker 还处于资源释放阶段,无法创建新的TaskTracker,任务失败)instanceInfo.setExpectedTriggerTime(System.currentTimeMillis() + 10000);// 修改状态为 等待派发,正式开始重试// 问题:会丢失以往的调度记录(actualTriggerTime什么的都会被覆盖)instanceInfo.setStatus(InstanceStatus.WAITING_DISPATCH.getV());} else {instanceInfo.setResult(req.getResult());instanceInfo.setFinishedTime(System.currentTimeMillis());finished = true;}}// 同步状态变更信息到数据库instanceInfoRepository.saveAndFlush(instanceInfo);if (finished) {// 这里的 InstanceStatus 只有 成功/失败 两种,手动停止不会由 TaskTracker 上报processFinishedInstance(instanceId, req.getWfInstanceId(), receivedInstanceStatus, req.getResult());}}所谓脑裂问题,就是同一个集群中的不同节点,对于集群的状态有了不一样的理解
worker的日志信息

timingPool.scheduleWithFixedDelay(omsLogHandler.logSubmitter, 0, 5, TimeUnit.SECONDS);
发送方式Worker中的OmsLogHandler类里的LogSubmitter内部类的run方法,也是另起线程进行处理的,将产生的日记内容进行上传,这里面使用了一个锁,保证只有一个线程上传日志。
接收端是server的WorkerRequestAkkaHandler类,接收之后保存到数据库中。
worker部署容器的信息
发送端是Worker的OmsContainerFactory类中的fetchContainer方法,该方法是由WorkActor触发的,当server要部署容器的时候,会向WorkerActor接收,然后调用方法onReceiveServerDeployContainerRequest,方法中判断该容器是否已经保存在本地,如果没有再通过fetchContainer向server的WorkerRequestAkkaHandler发送请求获取容器信息,然后部署。
接收端是server的WorkerRequestAkkaHandler类,接收到信息之后,server会将容器id,name,version和下载的url发回给worker,让worker通过url下载容器进行部署。
查询执行器集群的信息
发送端是worker的TaskTracker类的内部类WorkerDetector的run方法,如果是秒级任务,在任务初始化的时候会设置成每一分钟执行一次,在FrequentTaskTracker的initTaskTracker方法内
scheduledPool.scheduleAtFixedRate(new WorkerDetector(), 1, 1, TimeUnit.MINUTES);
如果是正常的任务,任务类型是Map或者MapReduce,会执行该方法:
if (executeType == ExecuteType.MAP || executeType == ExecuteType.MAP_REDUCE) { scheduledPool.scheduleAtFixedRate(new WorkerDetector(), 1, 1, TimeUnit.MINUTES); }
接收端是server的WorkerRequestAkkaHandler类,接收之后,将所有可以使用的worker的信息返回。
FriendRequestHandler
主要接收两种类型的信息:
-
Ping 检测目标机器是否存活(还有和我一个级别的活人吗)
-
RemoteProcessReq 远程执行命令(告诉你的直接下属干活,我不想得罪人)
检测目标机器是否存活
发送方式server的ServerElectionService类的activeAddress方法,该方法是worker启动的时候连接server时调用acquire服务的时候,会调用该方法,该方法会向worker发送的server地址询问目前存活的所有server地址信息。
触发的起点是在Worker的PowerJobWorker的init()中
serverDiscoveryService.start(timingPool);
=》ServerDiscoveryService的start方法的this.currentServerAddress = discovery();
=》ServerDiscoveryService的discovery方法的result = acquire(这个地址不重要,重要的是调用了这个方法);
=》ServerDiscoveryService的acquire方法的result = CommonUtils.executeWithRetry0(() -> HttpUtils.get(url));
然后转到了Server的ServerController类的acquireServer方法中
return ResultDTO.success(serverElectionService.elect(appId, protocol, currentServer));
=》ServerElectionService的elect方法的return getServer0(appId, protocol);
=》ServerElectionService的getServer0方法的String activeAddress = activeAddress(originServer, downServerCache, protocol);
=》ServerElectionService的activeAddress方法的CompletionStage<Object> askCS = Patterns.ask(serverActor, ping, Duration.ofMillis(PING_TIMEOUT_MS));
以上就是调用前的全部步骤了。
接收方是server的FriendRequestHandler,返回给询问方目前所有存活的server地址。
远程执行命令
发送方式server中JobServer上的注解DesignateServer的切面方法,在server执行某个任务时,会对当前worker的直属server进行判断,如果worker的直属server是当前调度任务的server,则直接执行,如果不是,则会将该方法发送给直属server进行执行。
比如说立即执行任务的命令,会在JobService的runJob中执行,但是该方法上有一个注解@DesignateServer,这也就会在方法执行之前,调用DesignateServerAspect的execute方法,如果将目标server地址与本地地址进行对比不一样,则会执行该远程方法。
接收方是server的FriendRequestHandler,接到执行方法的类名,方法名,入参和返回值等信息,执行方法。执行方法是在RemoteRequestProcessor类中。
总结

server的这两个Actor职责划分还是很清晰的,不过感觉将Actor仅仅只是用在通信上,有点大材小用的感觉,Actor这个单词本身就是将其比作一个演员,应该是扮演某个角色,当然了,让其仅仅扮演一个手机,可能也是个不错的想法。Akka-remote的底层是Netty,如果直接使用Netty估计也可以,只不过Akka将其进行了封装,使用起来能够更方便一些,不过就是给人一种用大炮打蚊子的感觉。
相关文章:
Server端的Actor,分工非常的明确,但是只将Actor作为一部手机来用,真的合适吗?
这是一篇介绍PowerJob,Server端Actor的文章,如果感兴趣可以请点个关注,大家互相交流一下吧。 server端一共有两个Actor,一个是处理worker传过来的信息,一个是server之间的信息传递。 处理Worker的Actor叫做WorkerRequ…...
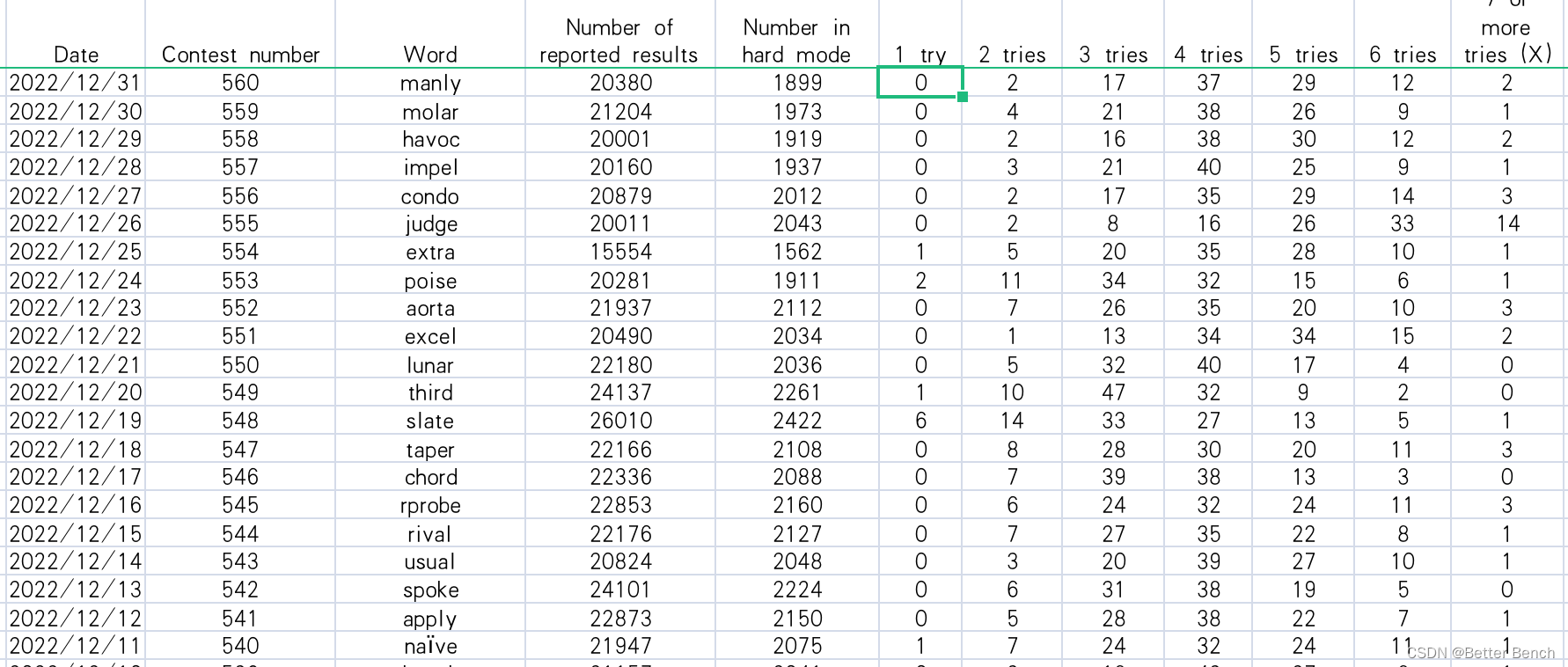
2023年美赛C题 预测Wordle结果Predicting Wordle Results这题太简单了吧
2023年美赛C题 预测Wordle结果Predicting Wordle Results 更新时间:2023-2-17 11:30 1 题目 2023年MCM 问题C:预测Wordle结果 Wordle是纽约时报目前每天提…...
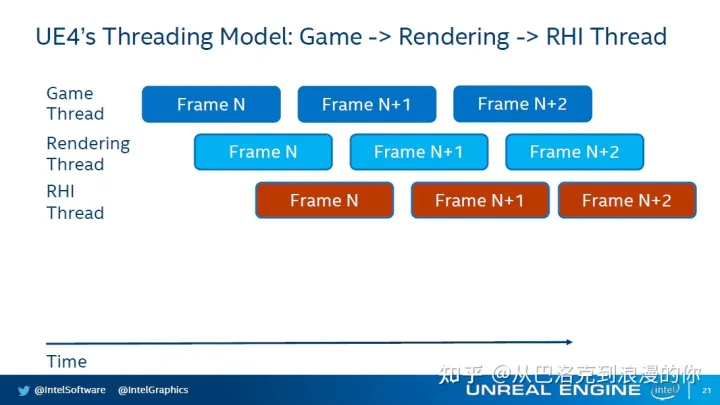
UE4 渲染学习笔记(未完)
原文链接:虚幻4渲染管线入门 - 知乎 从原文摘抄一下: 渲染框架 1,一套是传统的以RHICmdList为核心构建RenderPass,从RHICmdList.BeginRenderPass(...)开始,以RHICmdList.EndRenderPass()结束的框架。 2.一套是以新的Gr…...

Ajax?阿贾克斯?
一、Ajax简介 AJAX Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。 AJAX 不是新的编程语言,而是一种使用现有标准的创新方法。 AJAX 最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网…...

项目质量要怎么保持? 如何借助系统软件进行管理
对于任何项目型的企业总是很关心项目成本的话题,但不知从什么时候开始,高质量等于高成本成了各个企业的一种潜意识。 如果交付的项目产品不符合质量标准,即使企业使用最好的项目管理工具或者每个里程碑都达到并在预算范围内完成项目…...
没有接口文档的怎样进行接口测试
前言: 在进行接口测试之前,一般开发会提供接口文档,给出一些接口参数和必要熟悉,便于我们编写接口脚本。但如果没有提供接口开发文档的请求下,我们该如何编写接口测试脚本呢?在编写测试脚本前要做哪些必要…...
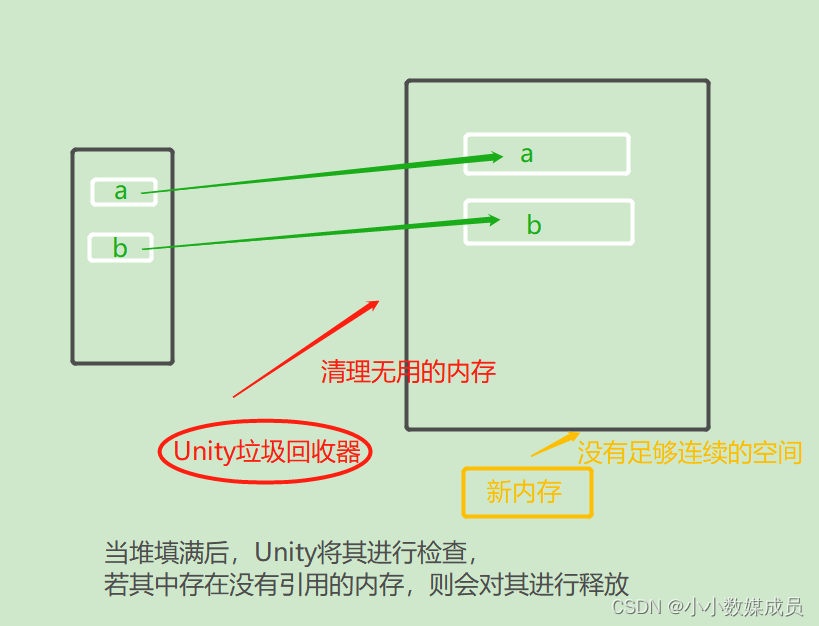
Unity—游戏设计模式+GC
每日一句:"少年一贯快马扬帆 道阻且长不转弯 要盛大要绚烂要哗然 要用理想的泰坦尼克去撞现实的冰川 要当烧赤壁的风而非借箭的草船 要为一片海就肯翻万山。" 目录 状态模式: 外观模式 组合模式, 单例模式 命令模式 观察者模…...
【刷题笔记】--二分查找binarysearch
当给一个有序的数组,在其中查找某个数,可以考虑用二分查找。 题目1: 二分查找的思路: 设置left和right指针分别指向要查找的区间。mid指针指向这个区间的中间。比较mid指针所指的数与target。 如果mid所指的数小于target&…...

Python版本的常见模板(二) 数论(一)
文章目录前言质数相关质数判断求约数求取区间质数埃氏筛法线性筛法分解质因数欧拉欧拉函数求取单个数线性筛法求取欧拉定理求逆元快速幂/幂取模欧几里得算法求最小公约数拓展欧几里得算法求解同余方程前言 本文主要是提供Python版本的常见的一些与数论相关的模板,例…...
)
SQL快速上手(知识点总结+训练资料)
文章目录一 SQL训练资料二 SQL知识点总结1.SQL语句的执行顺序2.窗口函数3.字符串处理函数模糊查询三 SQL题目的总结一 SQL训练资料 牛客SQL题目 猴子数据分析题目 关注的公众号 猴子数据分析 二 SQL知识点总结 1.SQL语句的执行顺序 每一个子句产生的中间结果供接下来的子句…...

无需经验的steam搬砖,每天操作1小时,轻松创业赚钱!
我作为一个95后社畜,就喜欢倒腾各种赚钱的事情,8年老韭菜告诉你,副业创收一点都不难,难就难在是否找对项目,俗话说方向不对,努力白费! 什么做苦力、技能、直播卖货,电商等等对比我这…...
如何创建你的公司的FAQ页面?
很多企业考虑为公司搭建一个“常见问题”页面,作为帮助客户回答关于产品和服务的常见问题的一种方式。 FAQ页面和登录/销售页面不同,没有展现出直接的投资回报,但是为团队节省了其他成本,据了解,高达67%的客户相比于跟…...
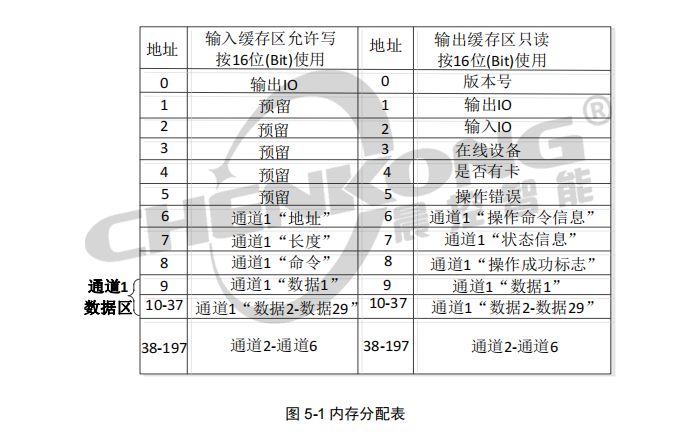
CK-GW06-E03与欧姆龙PLC配置指南
CK-GW06-E03与欧姆龙PLC配置指南CK-GW06-E03是一款支持标准工业EtherCAT协议的网关控制器,方便用户集成到PLC等控制系统中。本控制器提供了网络 POE 供电和直流电源供电两种方式,确保用户在使用无POE供电功能的交换机时可采用外接电源供电;系统还集成了六…...
使用docker-compose部署RocketMQ5.0
简介:使用docker-compose部署rocketmq5.0。文中会介绍docker-compose版本以及需要注意的项第一步:进入hub.docker.com搜索rocketmq我们选择第一个,因为第一个是7个月前更新的,(我看有很多博客使用的依旧是最下面的那种…...

嵌入式ARM设计编程(四) ARM启动过程控制
文章和代码已归档至【Github仓库:hardware-tutorial】,需要的朋友们自取。或者公众号【AIShareLab】回复 嵌入式 也可获取。 一、实验目的 (1) 掌握建立基本完整的ARM 工程,包含启动代码,C语言程序等&…...

企业维基都说好,今天我们来看看 wiki 软件的缺点有哪些?
企业维基企业wiki和内部知识库可能看起来是一回事——但它们实际上是非常不同的软件类型。也许您可能不知道你在寻找的是知识基础软件,还是wiki软件。 无论哪种方式,缺乏知识都是生产力的巨大瓶颈。事实上,未能分享知识是财富500强企业每年亏…...
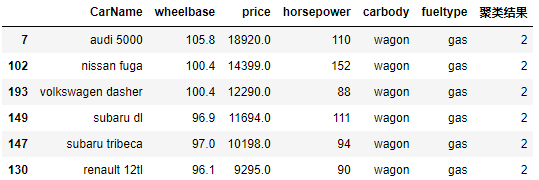
08- 汽车产品聚类分析综合项目 (机器学习聚类算法) (项目八)
找出性价比较高的车 LabelEncoder: python:sklearn标签编码(LabelEncoder) sklearn.preprocessing.LabelEncoder的使用:在训练模型之前,通常都要对数据进行一定得处理。将类别编号是一种常用的处理方法,比如把类别“电脑”,“手机…...

揭开苹果供应链,如何将其命运与中国深度捆绑
前 言 诺基亚在2007年时拥有9亿用户,在手机市场上占据主导地位,福布斯在当时以“谁能赶上手机之王?”为标题刊登了一篇关于该公司的报道,与此同时,苹果公司推出了iPhone系列产品。16年后,苹果公司以充足的…...
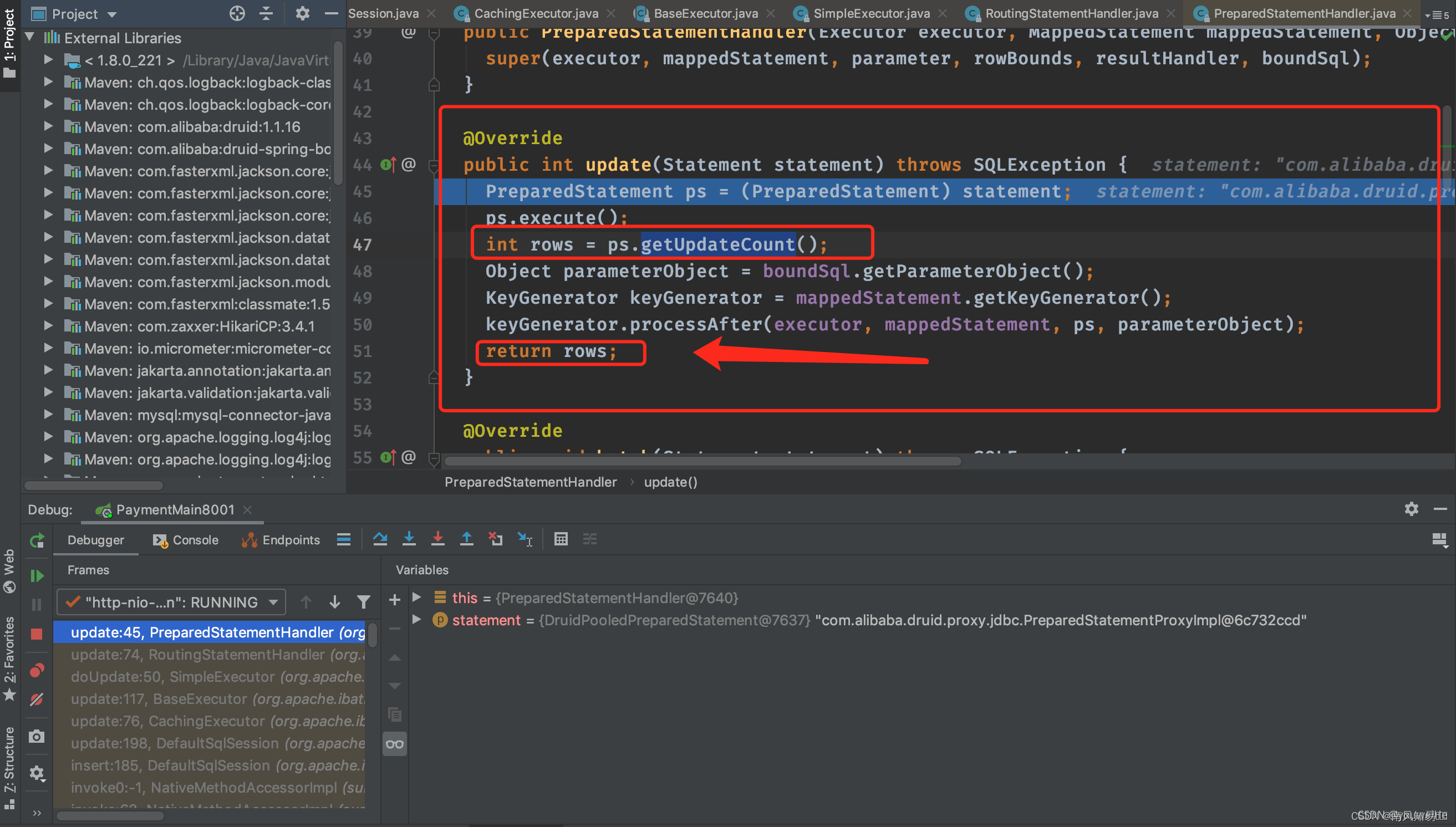
Mybatis 之useGeneratedKeys注意点
一.例子 Order.javapublic class Order {private Long id;private String serial; }orderMapper.xml<?xml version"1.0" encoding"UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org/DTD Mapper 3.0" "http://mybatis.org/dtd…...
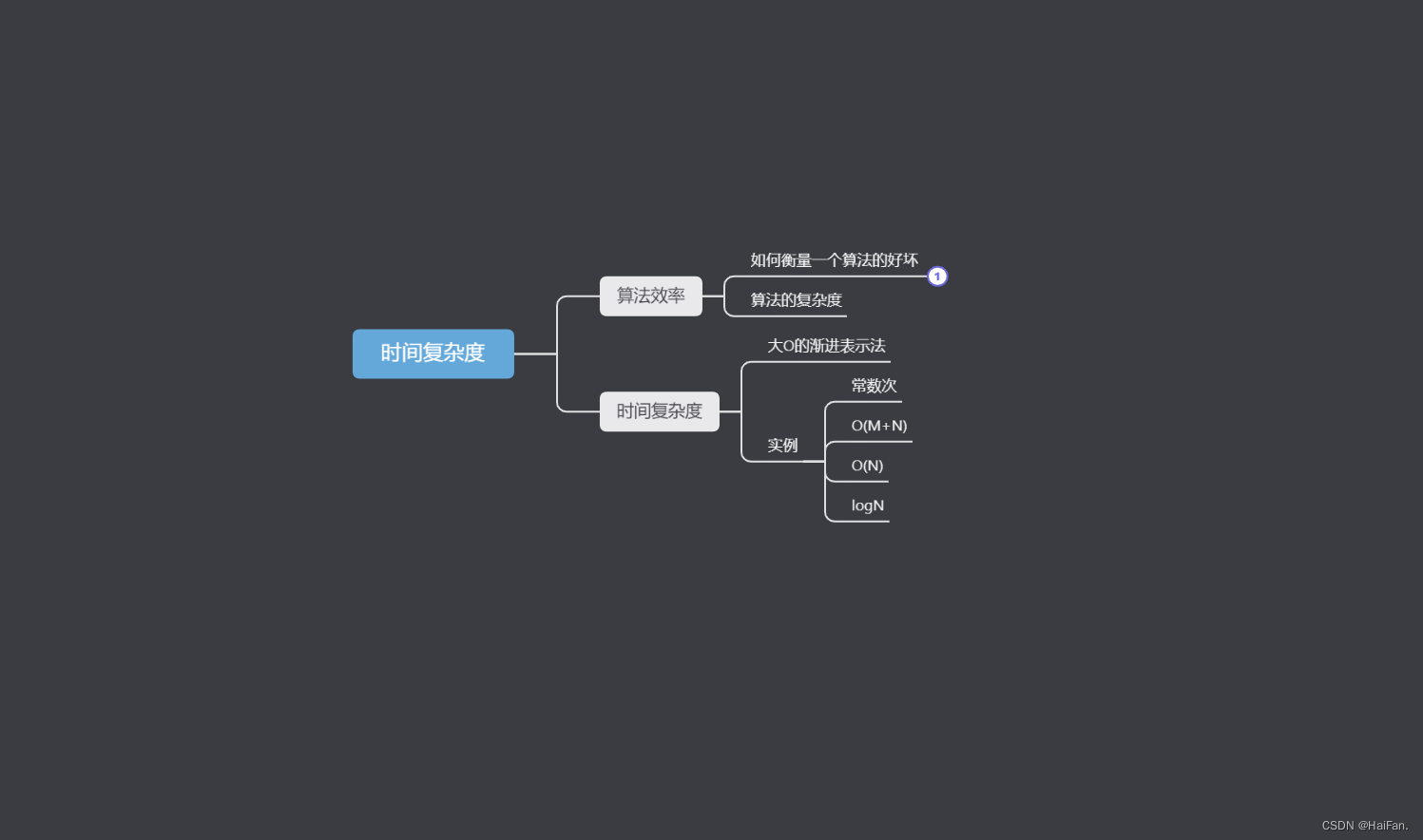
数据结构---时间复杂度
专栏:数据结构 个人主页:HaiFan. 专栏简介:开学数据结构,接下来会慢慢坑新数据结构的内容!!!! 时间复杂度前言1.算法效率1.1如何衡量一个算法的好坏1.2算法的复杂度2.时间复杂度2.1大…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...