MYSQL06高级_为什么使用索引、优缺点、索引的设计、方案、聚簇索引、联合索引、注意事项
文章目录
- ①. 为什么使用索引
- ②. 索引及其优缺点
- ③. InnoDb - 索引的设计
- ④. InnoDb中的索引方案
- ⑤. 索引 - 聚簇索引
- ⑥. 索引 - 二级索引
- ⑦. B+树索引的注意事项
- ⑧. MyISAM中索引方案
①. 为什么使用索引
-
①. 索引是存储引擎用于快速找到数据记录的一种数据结构,就好比去图书馆找书,或者新华字典里找字,相当于一个目录,可以帮助我们快速的查找到数据所在的位置
-
②. 在MySQL中也是同样的道理,进行数据查找时,首先看查询条件是否命中索引,符合则通过索引查找相关数据,如果不符合则需要全表扫描,即一条一条的查找记录,直到找到与条件符合的记录
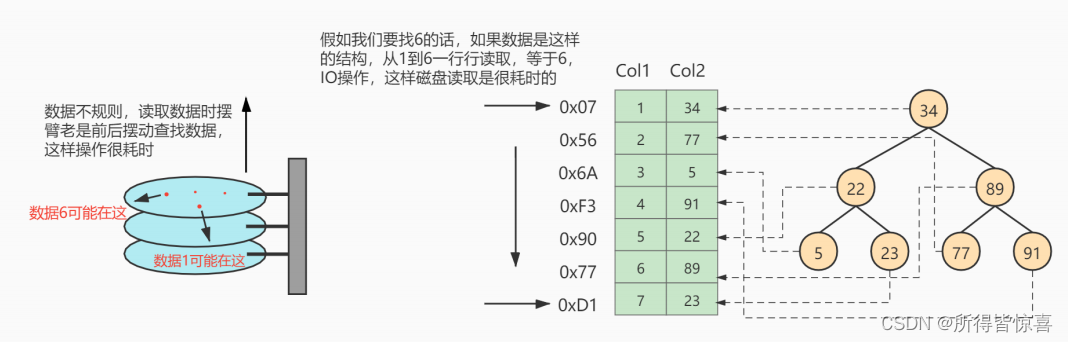
-
③. 假如给数据使用二叉树这样的数据结构进行存储,如下图所示
建立索引目的是为了减少磁盘I/O次数,加快查询效率
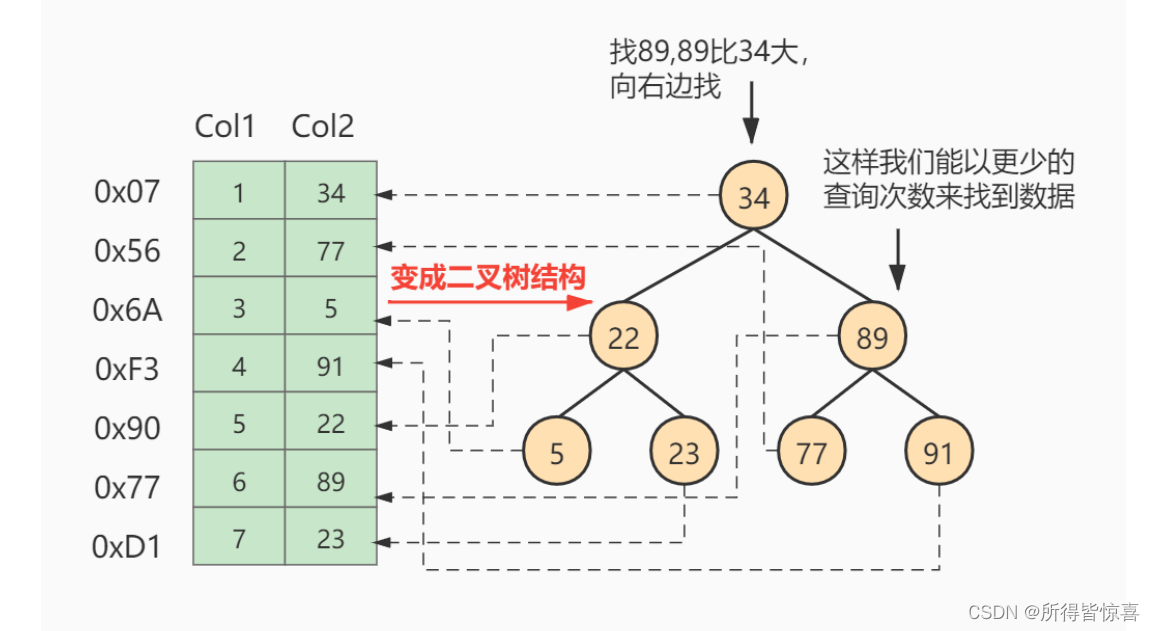
②. 索引及其优缺点
-
①. MySQL官方对索引的定义为:索引是帮助MySQL高效获取数据的数据结构
-
②. 本质:索引是数据结构,可以理解为“排好序的快速查找数据结构
-
③. 索引是在存储引擎中实现的,因此每种存储引擎的索引不一定完全相同,并且每种存储引擎不一定支持所有索引类型
-
④. 优点
- 提高数据检索效率,降低数据库的IO成本
- 通过创建唯一索引,可以保证数据库表中每一行数据的唯一性
- 在实现数据的参考完整性方面,可加速表和表之间的连接。换句话说,对于有依赖关系的子表和父表联合查询时,可以提高查询效率
- 在使用分组和排序子句进行数据查询时,可以显著减少查询中分组和排序的时间,降低了CPU的消耗
- ⑤. 缺点
- 创建索引和维护索引要消耗时间,并且随着数据量的增加,所耗费的时间也会增加
- 索引需要占用磁盘空间,除了数据表占数据空间外,每一个索引还要占一定的物理空间,存储在磁盘上,如果有大量的索引,索引文件就可能比数据文件更快达到最大文件尺寸
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度。当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度
③. InnoDb - 索引的设计
- ①. 首先,建一个表:
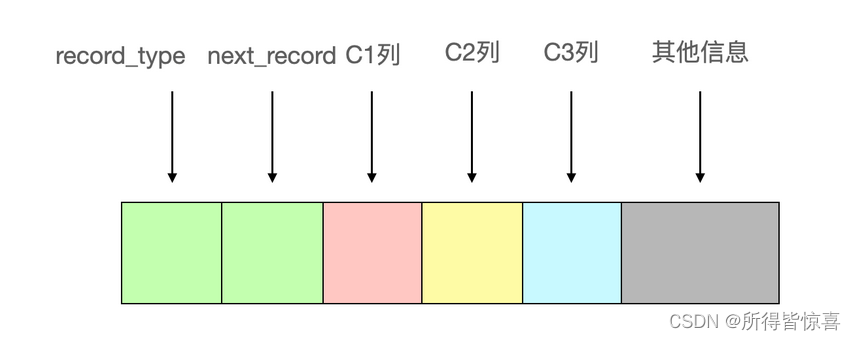
这个新建的index_demo表有2个INT类型的列,1个CHAR类型的列,而且规定了c1位逐渐,这个表使用Compact行格式来实际存储记录,行格式之后会学习到。以下是简化了行格式的示意图:
CREATE TABLE index_demo(c1 INT,c2 INT,c3 CHAR(1),PRIMARY KEY (c1)
) ROW_FORMAT = Compact;
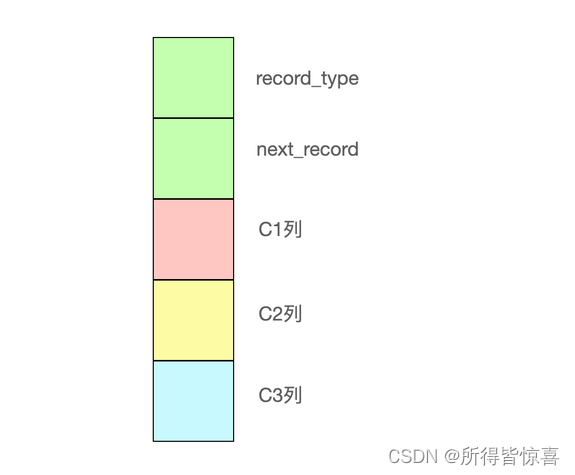
- ②. 我们只在示意图中展示记录这几个部分
- record_type:记录头信息的一项属性,表示记录的类型,0表示普通记录、2表示最小记录、3表示最大记录、1是目录项
- next_record:记录头信息的一项属性,表示下一条地址相对于本条记录的地址偏移量,我们用箭头来表明下一条记录是谁。可以理解为链表
- 各个列的值:这里只记录在index_demo表中的三个列,分别是c1,c2,c3
- 其他信息:除了上述3种信息以外的所有信息,包括其他隐藏列的值以及记录的额外信息
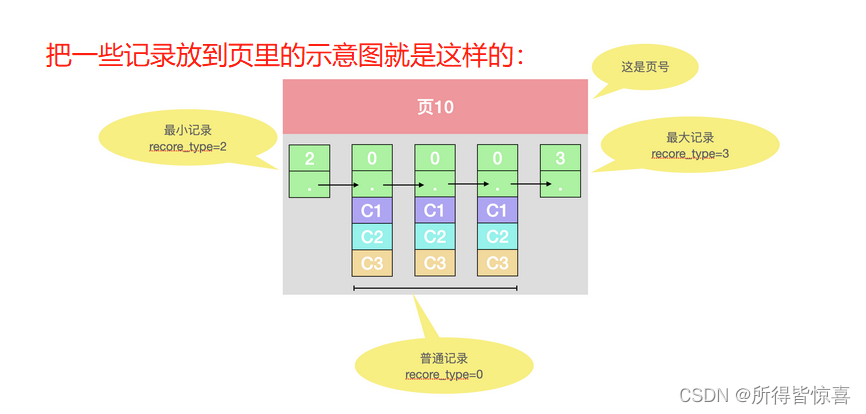
- ③. 下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值
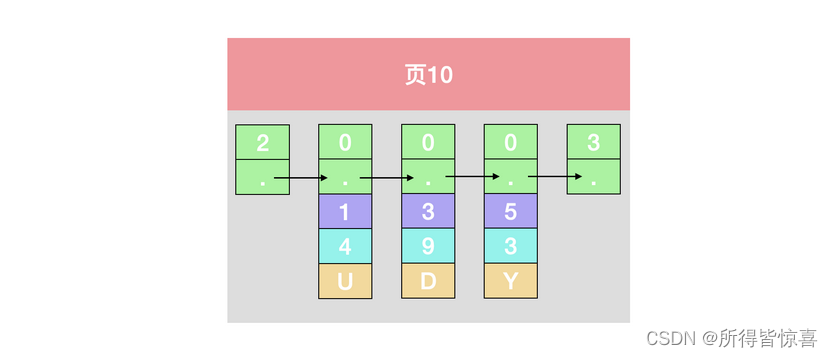
- 假设:每一个数据页最多能存放三条记录,实际上一个数据页非常大,可以存放好多记录。向表中插入3条记录,填充数据页
INSERT INTO index_demo VALUES(1,4,'u'),(3,9,'d'),(5,3,'y');
- 那么这些记录已经按照主键值的大小串联成一个单向链表了
 3. 那这时候我们插入一条主键为4的记录,这个数据页已经显示不下了,只能新建一个数据页,而且因为4 < 5,所以这条记录应该保存在页10中,把主键为5的记录移动到下一个页中,这个过程叫页分裂
3. 那这时候我们插入一条主键为4的记录,这个数据页已经显示不下了,只能新建一个数据页,而且因为4 < 5,所以这条记录应该保存在页10中,把主键为5的记录移动到下一个页中,这个过程叫页分裂
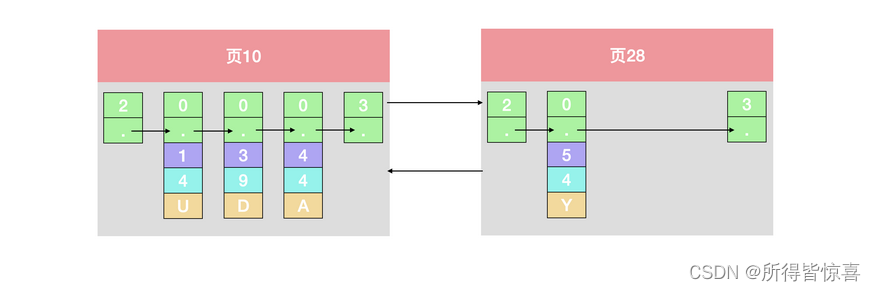
- ④. 给所有的页建立一个目录项 - 由于数据页的编号可能是不连续的,所以插入了多条记录后,可能会出现以下的情况

- ⑤. 因为这些数据页在物理存储上是不连续的,所以如果想从这么多页中根据主键值快速定位某些记录所在的位置,我们需要给他们做一个目录,每一个页对应一个目录项,每个目录项包括下边两个部分:
- 比如:查找主键值为20的记录,具体查找过程分两步:
- 先从目录项中根据二分法快速确定出主键值为20的记录在目录项3中因为12 < 20 <209),它对应的页 - 是页9
- 再根据前边说的在页中查找记录的方式去页9中定位具体的记录
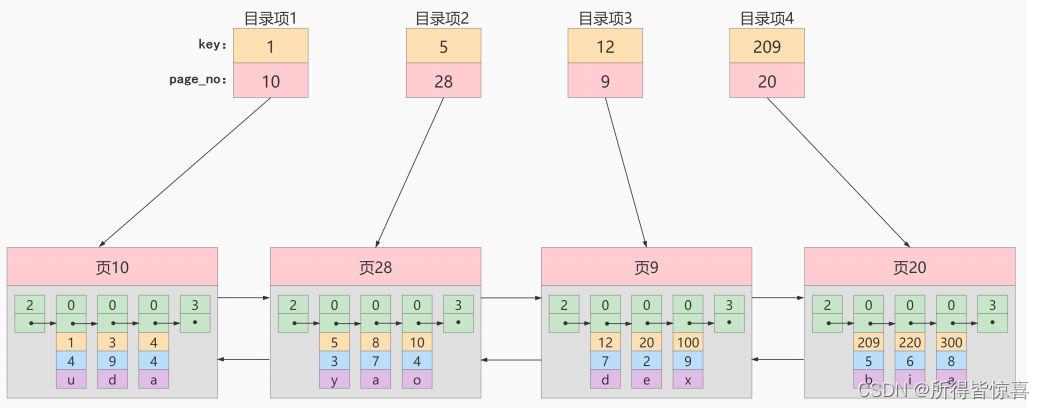
- ⑥. 针对数据页做的简易目录就搞定了。这个目录有一个别名,称为索引
④. InnoDb中的索引方案
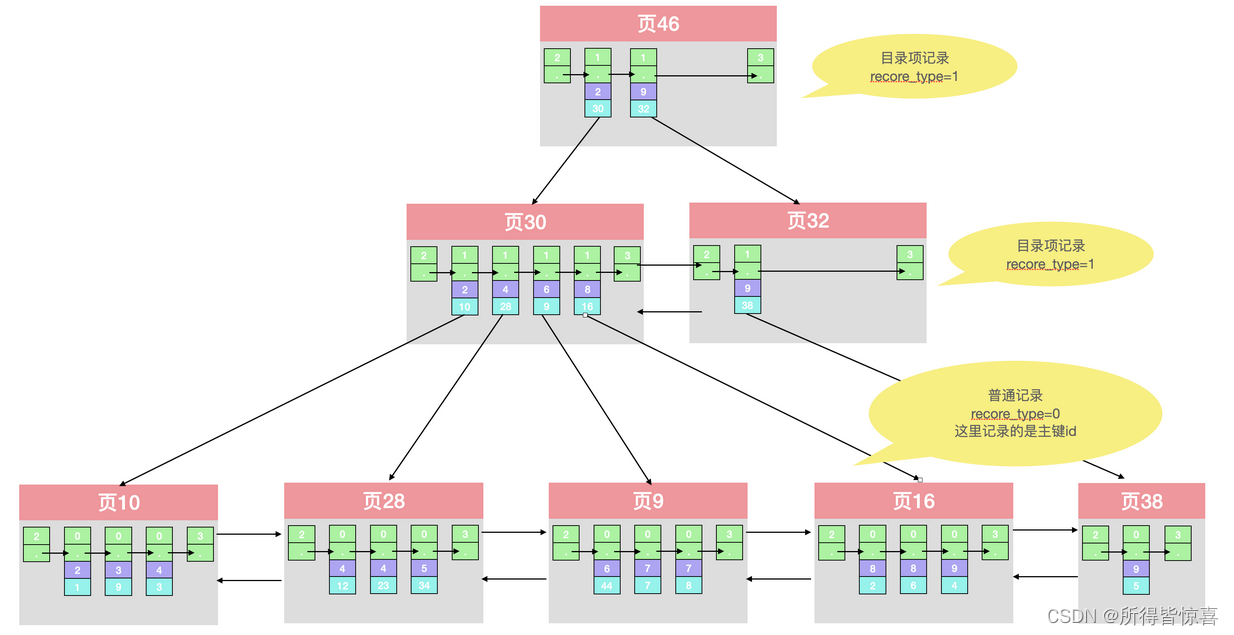
- ①. 迭代1次:目录项纪录的页 - 我们把前边使用到的目录项放到数据页中的样子就是这样
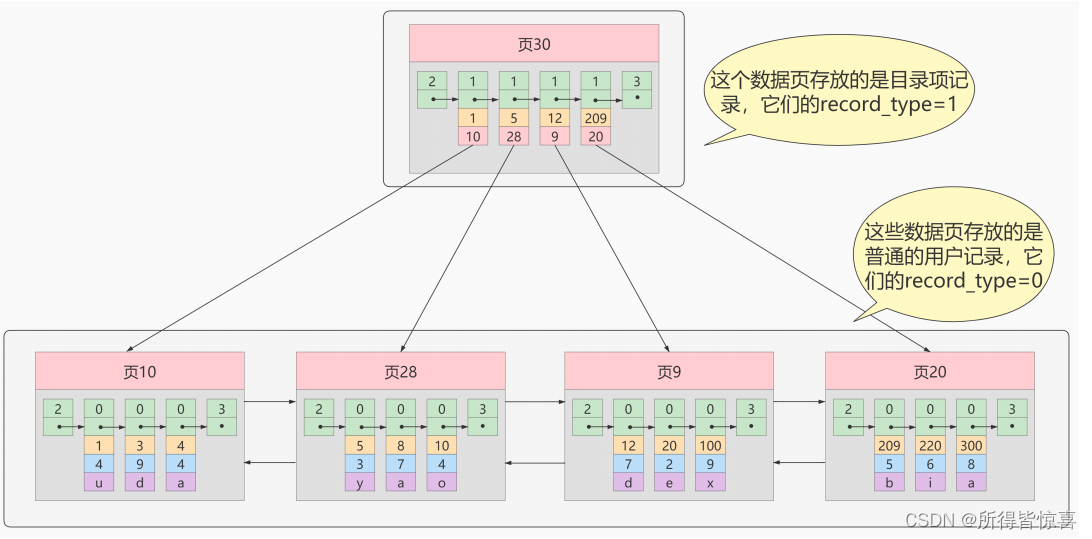
- ②. 从图中可以看出来,我们新分配了一个编号为30的页来专门存储目录项记录。这里再次强调目录项记录和普通的用户记录的不同点:
- 目录项记录的record_type值是1,而普通用户记录的record_type值是0
- 目录项记录只有主键值和页的编号两个列,而普通的用户记录的列是用户自己定义的,可能包含很多列 ,另外还有InnoDB自己添加的隐藏列
- 了解:记录头信息里还有一个叫min_rec_mask的属性,只有在存储目录项记录的页中的主键值最小的目录项记录的min_rec_mask值为1 ,其他别的记录的min_rec_mask值都是0
- ③. 相同点:两者用的是一样的数据页,都会为主键值生成 Page Directory 页目录,从而在按照主键值进行查找时可以使用二分法来加快查询速度
- 现在以查找主键为 20 的记录为例,根据某个主键值去查找记录的步骤就可以大致拆分成下边两步:
- 先到存储目录项记录 的页,也就是页30中通过 二分法 快速定位到对应目录项,因为12 < 20 <209 ,所以定位到对应的记录所在的页就是页9
- 再到存储用户记录的页9中根据二分法 快速定位到主键值为20的用户记录
- ④. 迭代2次:多个目录项纪录的页
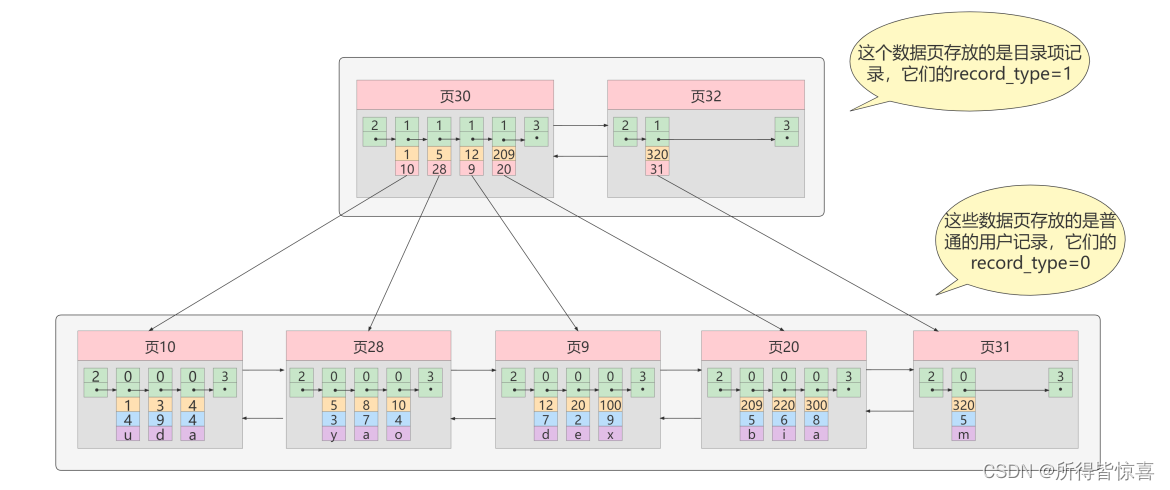

- ⑤. 迭代3次:目录项记录页的目录页
如图,我们生成了一个存储更高级目录项的页33 ,这个页中的两条记录分别代表页30和页32,如果用户记录的主键值在 [1, 320) 之间,则到页30中查找更详细的目录项记录,如果主键值不小于320的话,就到页32中查找更详细的目录项记录
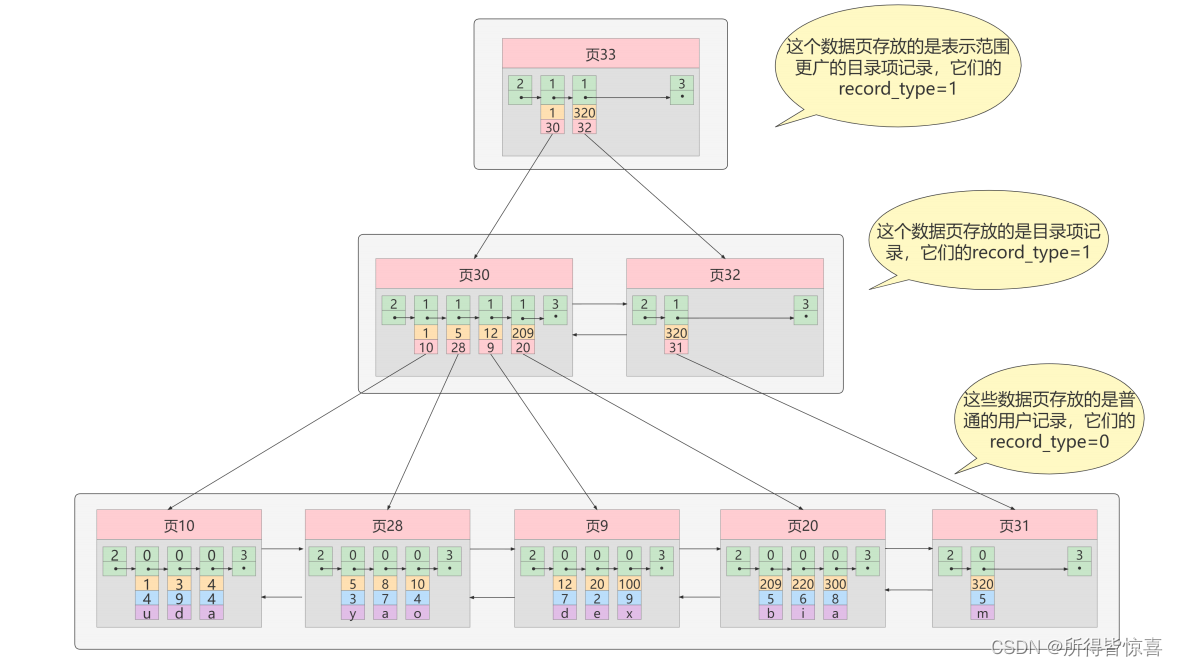
- ⑥. 我们可以用下边这个图来描述它 - 这个数据结构,它的名称是B+树
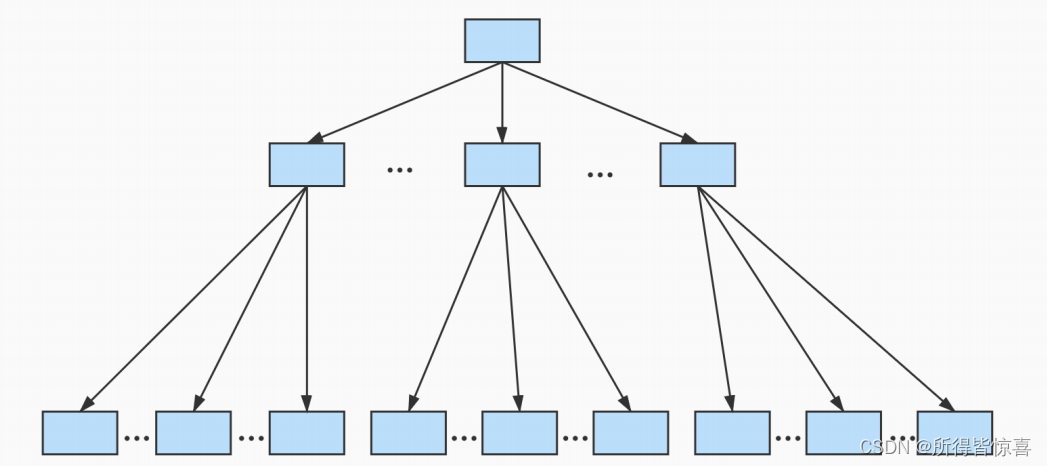
- ⑦. 一个B+树的节点其实可以分成好多层,规定最下边的那层,也就是存放我们用户记录的那层为第0层,之后依次往上加。之前我们做了一个非常极端的假设:存放用户记录的页 最多存放3条记录 ,存放目录项记录的页最多存放4条记录 。其实真实环境中一个页存放的记录数量是非常大的,假设所有存放用户记录的叶子节点代表的数据页可以存放100条用户记录 ,所有存放目录项记录的内节点代表的数据页可以存放1000条目录项记录 ,那么
- 如果B+树只有1层,也就是只有1个用于存放用户记录的节点,最多能存放100条记录
- 如果B+树有2层,最多能存放1000×100=10,0000条记录
- 如果B+树有3层,最多能存放1000×1000×100=1,0000,0000条记录
- 如果B+树有4层,最多能存放 1000×1000×1000×100=1000,0000,0000条记录。相当多的记录
- 你的表里能存放100000000000条记录吗?所以一般情况下,我们用到的B+树都不会超过4层 ,那我们通过主键值去查找某条记录最多只需要做4个页面内的查找查找3个目录项页和一个用户记录页,又因为在每个页面内有所谓的Page Directory页目录,所以在页面内也可以通过二分法实现快速定位记录
⑤. 索引 - 聚簇索引
- ①. 使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
- 页内的记录是按照主键的大小顺序排成一个单向链表
- 各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表
- 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表
-
②. B+树的叶子节点存储的是完整的用户记录
完整的用户记录,就是指这个记录中存储了所有列的值包括隐藏列 -
③. 们把具有这两种特性的B+树称为聚簇索引,所有完整的用户记录都存放在这个聚簇索引的叶子节点处。这种聚簇索引并不需要我们在MySQL语句中显式的使用INDEX语句去创建,InnoDB存储引擎会自动的为我们创建聚簇索引
-
④. 聚簇索引优点
- 数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
- 聚簇索引对于主键的排序查找和范围查找速度非常快
- 按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不用从多个数据块中提取数据,所以节省了大量的io操作
- ⑤. 聚簇索引缺点
- 插入速度严重依赖插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能,因此对于InnoDB表,我们一般都会定义一个自增的ID列为主键
- 更新主键的代价很高,因为将会导致被更新的行移动。因此对于InnoDB表,我们一般定义主键为不可更新
- ⑥. 限制
- 对于MySQL数据库,目前只有InnoDB数据引擎支持聚簇索引,而MyISAM并不支持聚簇索引
- 由于数据物理存储排序方式只能由有一种,所以每个MySQL的表只能有一个聚簇索引。一般情况下就是该表的主键
- 如果没有定义主键,InnoDB会选择非空的唯一索引代替。如果没有这样的索引,InnoDB会隐式的定义一个主键来作为聚簇索引
- 为了充分利用聚簇索引的聚簇的特性,索引InnoDB表的主键列尽量选择有序的顺序id,而不建议用无序的id,比如UUID、MD5、HASH、字符串列作为主键无法保证数据的顺序增长
- ⑦. 聚簇索引并不是一种单独的索引类型,而是一种数据存储方式(所有的记录都存储在了叶子节点),也就是所谓的索引即数据,数据即索引
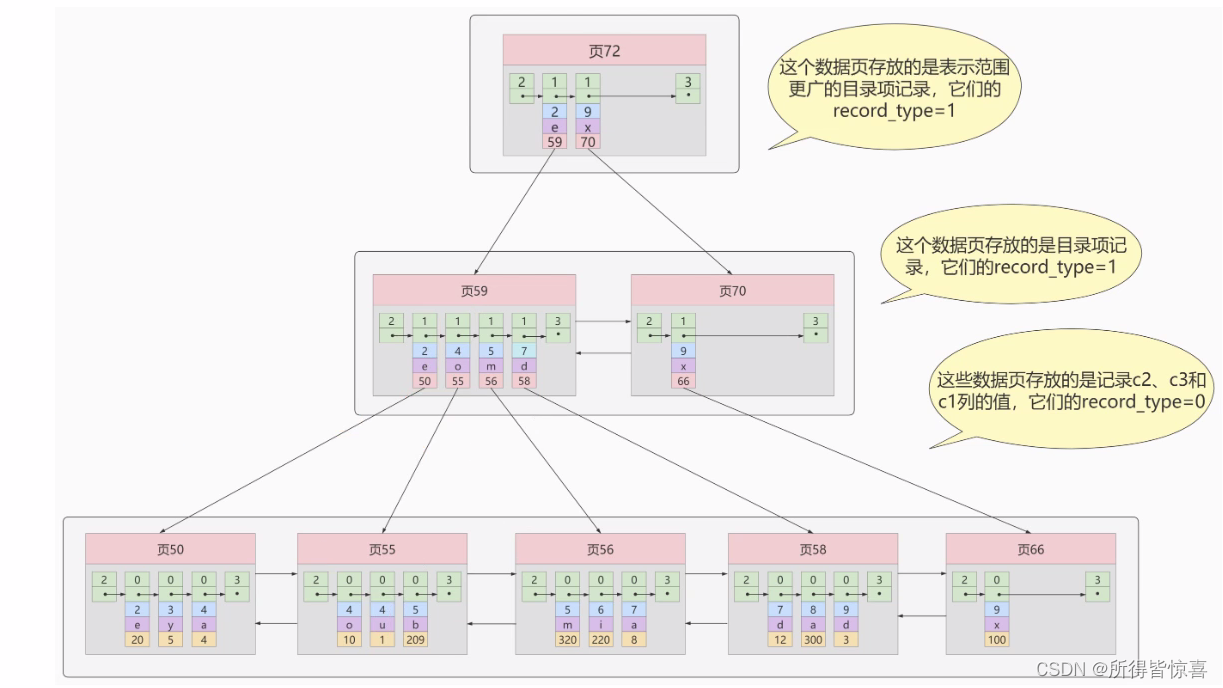
⑥. 索引 - 二级索引
- ①. 二级索引也被称为辅助索引、非聚簇索引,上面介绍的聚簇索引只能在搜索条件是主键时才能发挥作用,因为B+树的数据都是按照主键进行排序的
在实际开发过程中,我们经常使用别的列作为搜索条件,如果使用该列为搜索条件的频率非常高时,我们就可以考虑使用此列创建一个二级索引,依次来提升搜索的速度
- ②. 使用记录c2列的大小进行记录和页的排序,这包括三个方面的含义
- 页内的记录是按照c2列的大小顺序排成一个单向链表
- 各个存放用户记录的页也是根据页中用户记录的c2列的大小顺序排成一个双向链表
- 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的c2列的大小顺序排成一个双向链表
-
③. B+树的叶子节点存储的并不是完整的用户记录,而只是c2列+主键这两个列的值
-
④. 目录项记录中不再是主键+页号的搭配,而是c2列+页号的
-
⑤. 通过二级索引搜索,需要先从二级索引的B+树找到符合条件的主键id,然后再去聚簇索引的B+树进行搜索。这里就会有同学想问了,为什么不在二级索引的B+树中存储完整的用户记录呢?
如果把完整的用户记录放到叶子节点是可以不用回表,但是太占用地方了,相当于每创建一个索引,就将用户记录都拷贝一份,非常浪费存储空间 -
⑥. 聚簇索引与非聚簇索引的原理不同,在使用上也有一些区别
- 聚簇索引的叶子节点存储的就是我们的数据记录,非聚簇索引的叶子节点存储的是数据位置。非聚簇索引不会影响表的物理存储数据
- 一个表只能由一个聚簇索引,因为只能有一种排序存储方式,但可以有多个非聚簇索引
- 使用聚簇索引的时候,数据的查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚簇索引低。这是因为修改非聚簇索引,只需要操作当前的B+树,而如果修改聚簇索引,不仅要操作当前B+树,所有非聚簇索引的叶子节点的id都需要修改
- ⑦. 联合索引也是二级索引的一种,如果我们使用了多个列创建索引,例如先按照c2排序,c2相同按照c3排序,那么这就是一个联合索引。
联合索引相较于二级索引,在每一个节点上存储的数据更多了,这里就画一个草图,不再赘述了
⑦. B+树索引的注意事项
InnoDB的B+树索引的注意事项
- ①. 根界面位置万年不动
前边介绍B+树索引的时候,为了大家理解上的方便,先把存储用户记录的叶子节点都画出来,然后接着画存储目录项记录的内节点,实际上B+树的行程过程是这样的:
- 每当为某个表创建一个B+树索引聚簇索引不是认为创建的,默认就有的时候,都会为这个索引
创建一个根节点页面,最开始表中没有数据的时候,每个B+树索引对应的根节点中既没有用户记录,也没有目录项记录 - 随后向表中插入用户记录时,先把用户记录存储到这个
根节点中 - 当根节点中的可用空间用完时继续插入记录,此时会将根节点中的所有记录复制到一个新分配的也,比如页a中,然后对这个新页进行页分裂的操作,得到另一个新页,比如
页b。这是新插入的记录根据简直也就是聚簇索引中的主键值,二级索引中对应的索引列的值的大小就会被分配到页a或者页b中,跟根节点便升级为存储目录项记录的页
这个过程特别注意的是:一个B+树索引的根节点自诞生之日起,便不会再移动,这样只要我们对某个表建立一个索引,那么它的根节点的页号便会被记录到某个地方,然后凡是InnoDB存储引擎需要用到这个索引的时候,都会从那个固定的地方取出根节点的页号,从而来访问这个索引。
- ②. 内节点中目录项记录的唯一性
我们知道B+树索引的内节点中目录项记录的内容是索引列+页号的搭配,但是这个搭配对于二级索引来说有点不严谨。还拿index_demo表为例,假设这个表中的数据是这样的:
c1 c2 c3
1 1 ‘u’
3 1 ‘d’
5 1 ‘y’
7 1 ‘a’
如果二级索引中目录项记录的内容只是索引列 +页号的搭配的话,那么为c2建议索引后的B+树应该长这样:
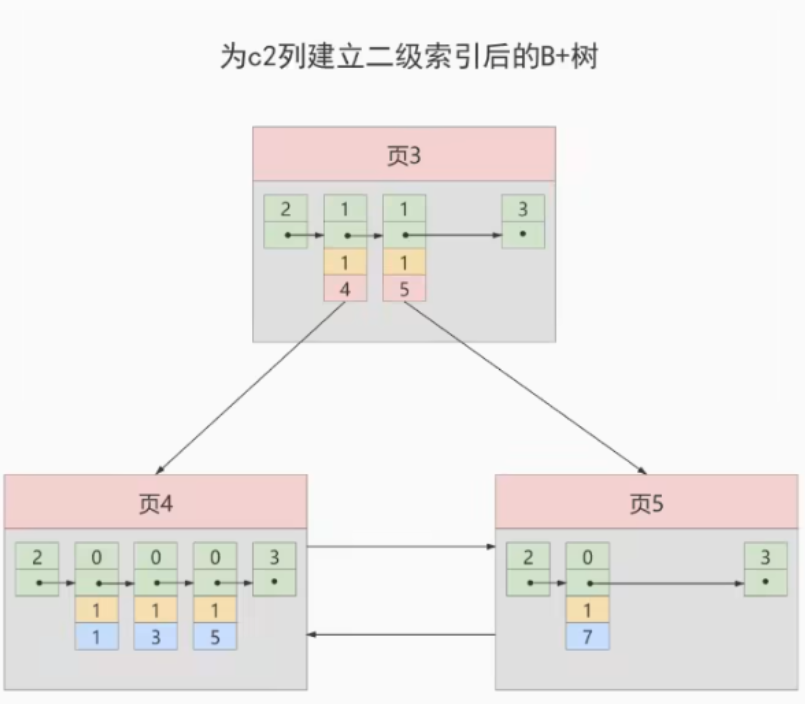 如果我们想新插入一行记录,其中
如果我们想新插入一行记录,其中c1、c2、c3的值分别是:9、1、c,那么在修改这个为c2列建立二级索引对应B+树时便碰到了个大问题:由于页3中存储的目录项记录是由c2列 + 页号的值构成的,页3中的两条目录项记录对应的c2列的值都是1,而我们新插入的这条记录的c2列的值也是1,那我们这条新插入的记录到底应该放到页4中,还是应该放到页5中啊?答案是:对不起,懵了
为了让新插入记录能找到自己在哪个页中,我们需要保证在B+树的同一层内节点的目录项记录除页号这个字段以外是唯一的。所以对二级索引的内节点的目录项记录的记录的内容实际上是有三个部分构成的:
- 索引列的值
- 主键值
- 页号
也就是我们把主键值也添加到二级索引内节点中的目录项记录了,这样就能保证B+树每一层节点中各条目录项记录除页号这个字段外是唯一的,所以我们为c2列建议二级索引后的示意图实际上应该是这样子的:
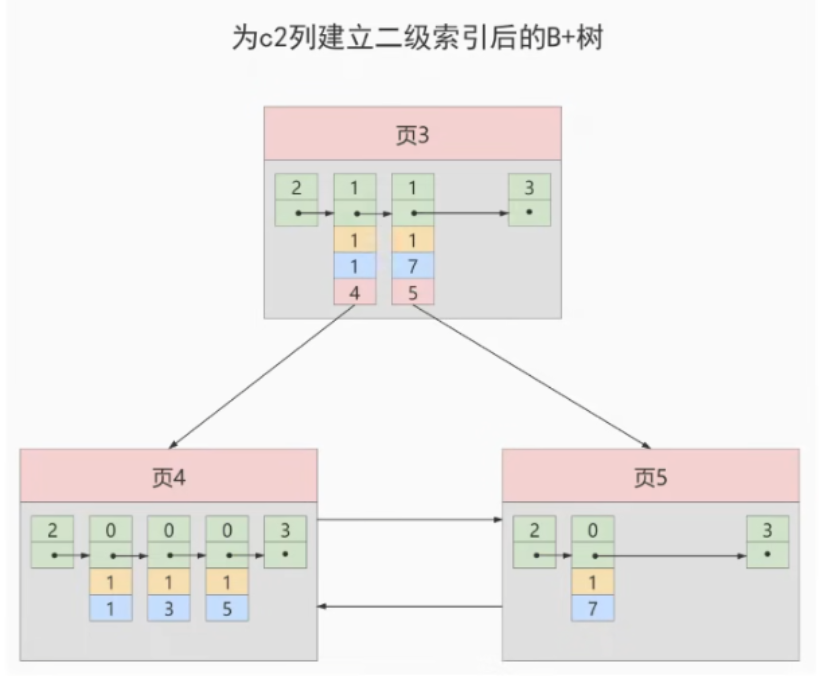 这样我们再插入记录
这样我们再插入记录(9,1,'c')时,由于页3中存储的目录项记录是由c2列 + 主键 + 页号的值构成的,可以先把新记录的c2类的值和页3中各目录项记录的c2l列的值作比较,如果c2列的值相同的话,可以接着比较主键值,因为B+树同一层中不同目录项记录的c2列 + 主键的值肯定是不一样的,所以最后肯定能定位唯一的一条目录项记录,在本例中最后确定新记录应该被插入页5中
- ③. 一个页面最少存储2条记录
一个B+树只需要很少的层级就可以轻松存储数亿条记录,查询速度相当不错!这是因为B+树本质上就是一个大的多层级目录,每经过一个目录时都会过滤调许多无效的子目录,直到最后访问到存储真实数据的目录。那如果一个大的目录中只存放一个子目录是个啥效果呢?那就是目录层级非常非常多,而且最后的那个存放真实数据的目录中,只能存放一条记录。费半天劲只能存放一条真实的用户记录?所以InnoDB的一个数据页至少可以存放两条记录
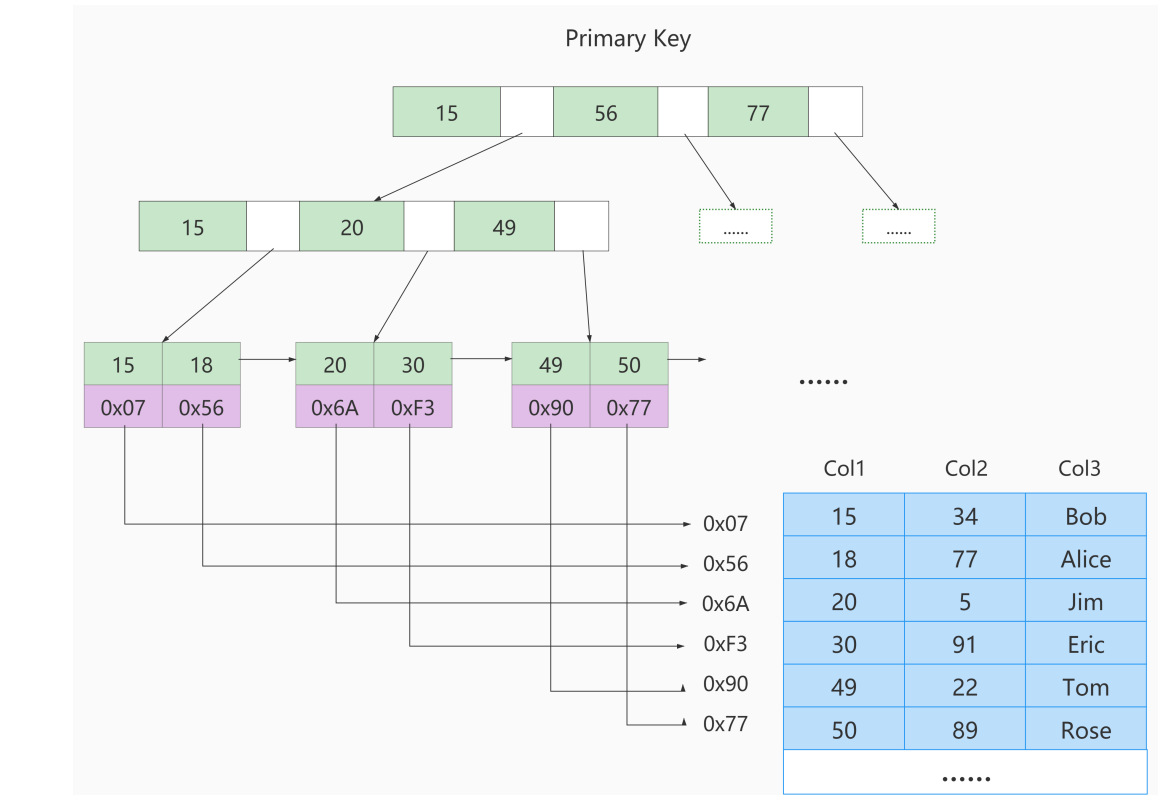
⑧. MyISAM中索引方案
- ①. B树索引适用存储引擎如表所示:
- Innodb和MyISAM默认的索引是Btree索引;而Memory默认的索引是Hash索引
- MyISAM引擎使用B+Tree作为索引结构,叶子节点的data域存放的是
数据记录的地址

- ②. 下图是MyISAM索引的原理图
- ③. 如果我们在Col2上建立一个二级索引,则此索引的结构如下图所示:
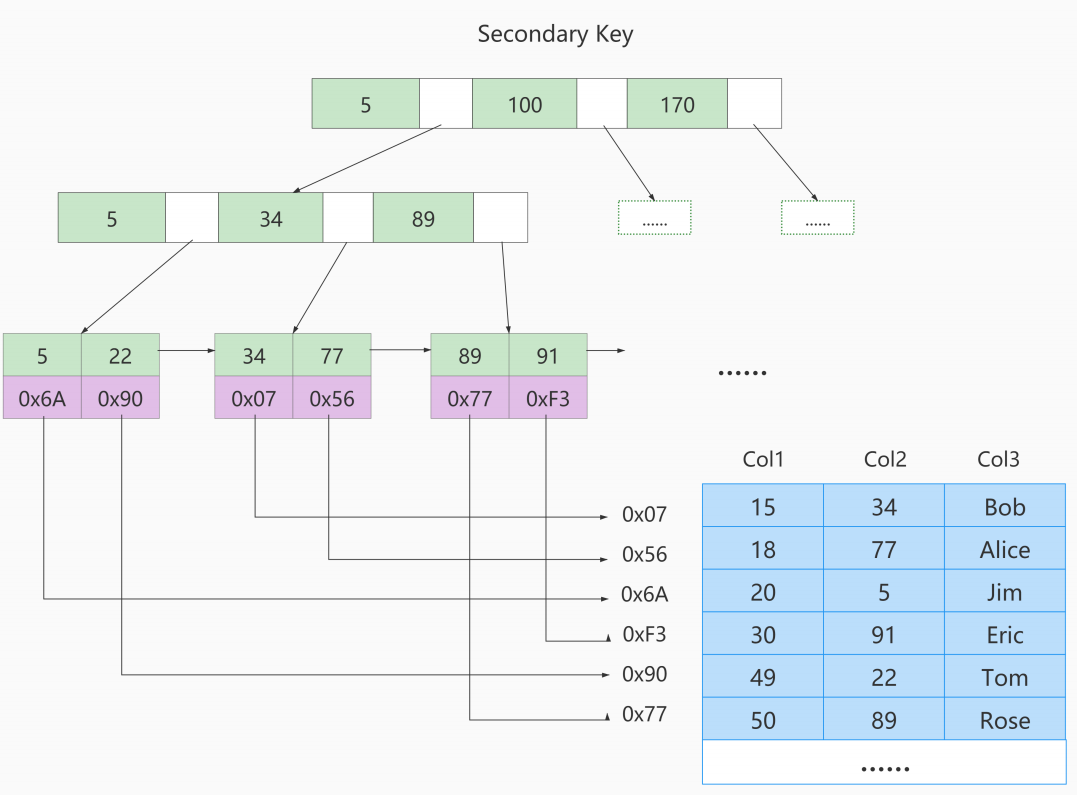
- ④. MyISAM与InnoDB对比
- 在InnoDB存储引擎中,我们只需要根据主键值对
聚簇索引进行一次查找就能找到对应的记录,而在MyISAM中却需要进行一次回表操作,意味着MyISAM中建立的索引相当于全部都是二级索引 - InnoDB的数据文件本身就是索引文件,而MyISAM索引文件和数据文件是
分离的,索引文件仅保存数据记录的地址 - InnoDB的非聚簇索引data域存储相应记录
主键的值,而MyISAM索引记录的是地址。换句话说,InnoDB的所有非聚簇索引都引用主键作为data域 - MyISAM的回表操作是十分
快速的,因为是拿着地址偏移量直接到文件中取数据的,反观InnoDB是通过获取主键之后再去聚簇索引里找记录,虽然说也不慢,但还是比不上直接用地址去访问 - InnoDB要求表
必须有主键(MyISAM可以没有)如果没有显式指定,则MySQL系统会自动选择一个可以非空且唯一标识数据记录的列作为主键。如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型
相关文章:
MYSQL06高级_为什么使用索引、优缺点、索引的设计、方案、聚簇索引、联合索引、注意事项
文章目录 ①. 为什么使用索引②. 索引及其优缺点③. InnoDb - 索引的设计④. InnoDb中的索引方案⑤. 索引 - 聚簇索引⑥. 索引 - 二级索引⑦. B树索引的注意事项⑧. MyISAM中索引方案 ①. 为什么使用索引 ①. 索引是存储引擎用于快速找到数据记录的一种数据结构,就好比去图书馆…...

LeetCode 130. 被围绕的区域
题目链接:130. 被围绕的区域 题目描述 给你一个 m x n 的矩阵 board ,由若干字符 ‘X’ 和 ‘O’ ,找到所有被 ‘X’ 围绕的区域,并将这些区域里所有的 ‘O’ 用 ‘X’ 填充。 示例1: 输入:board [[“…...
python中2等于2.0吗,python中【1:2】
本篇文章给大家谈谈python中2等于2.0吗,以及python中【1:2】,希望对各位有所帮助,不要忘了收藏本站喔。 变量和赋值 Python中的变量不需要声明, 直接定义即可. 会在初始化的时候决定变量的 “类型” 使用 来进行初始化和赋值操作 定义变量时…...
》)
【2023年11月第四版教材】《第2章-信息技术发展(第一部分)》
《第2章-信息技术发展(第一部分)》 章节说明1 计算机软硬件2 计算机网络2.1 网络的作用范围2.2 OSI模型2.3 广域网协议2.4 网络协议2.5 TCP/IP2.6 软件定义网络(SDN)2.7 第五代移动通信技术 章节说明 大部分为新增内容࿰…...

【CSS】说说对BFC的理解
目录 一、概念 二、BFC的布局规则 三、设置BFC的常用方式 四、BFC的应用场景 1、解决浮动元素令父元素高度坍塌的问题 2、解决非浮动元素被浮动元素覆盖问题 3、解决外边距垂直方向重合的问题 五、总结 一、概念 我们在页面布局的时候,经常出现以下情况&am…...

ES6学习-Class类
class constructor 构造方法 this 代表实例对象 方法之间不需要逗号分隔,加了会报错。 typeof Point // "function" Point Point.prototype.constructor // true类的数据类型就是函数,类本身就指向构造函数。 类的所有方法都定义在类的pr…...

C语言经典小游戏之扫雷(超详解释+源码)
“少年气,是历尽千帆举重若轻的沉淀,也是乐观淡然笑对生活的豁达!” 今天我们学习一下扫雷游戏怎么用C语言来实现! 扫雷小游戏 1.游戏介绍2.游戏准备3.游戏实现3.1生成菜单3.2游戏的具体实现3.2.1初始化棋盘3.2打印棋盘3.3布置雷…...
)
算法leetcode|67. 二进制求和(rust重拳出击)
文章目录 67. 二进制求和:样例 1:样例 2:提示: 分析:题解:rust:go:c:python:java: 67. 二进制求和: 给你两个二进制字符串 a 和 b &a…...
【ASP.NET MVC】第一个登录页面(8)
一、准备工作 先从网上(站长之家、模板之家,甚至TB)下载一个HTML模板,要求一整套的CSS和必要的JS,比如下图: 登录页面的效果是: 首页: 利用这些模板可以减少前台网页的设计——拿来…...

使用Openoffice或LibreOffice实现World、Excel、PPTX在线预览
使用Openoffice或LibreOffice实现World、Excel、PPTX在线预览 预览方案使用第三方服务使用前端库转换格式 jodconverterjodconverter概述主要特性OpenOfficeLibreOffice jodconverter的基本使用添加依赖配置创建DocumentConverter实例上传与转换预览启动上传与预览World 与Spri…...
没有object的rust怎么面向对象?)
20天学会rust(三)没有object的rust怎么面向对象?
面向对象我们都很熟悉,可以说它是一种软件开发最重要的编程范式之一,它将程序中的数据和操作数据的方法组织成对象。面向对象有几个重要特性: 封装、继承和多态,基于这些特性带来了在可重用性、可维护性、扩展性、可靠性的优点。 …...
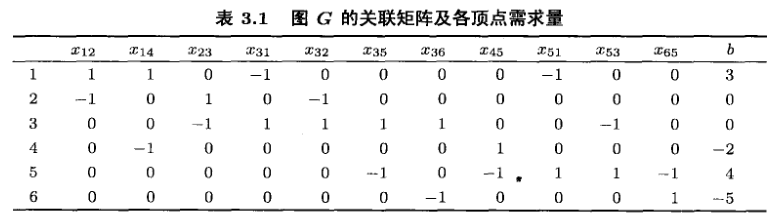
整数规划——第三章 全单模矩阵
整数规划——第三章 全单模矩阵 若线性规划问题的约束矩阵为全单模矩阵,则该问题可行域的顶点都是整数点,从而线性规划与整数规划的最优解相同。 3.1 全单模性与最优性 考虑线性整数规划问题: (IP) min c T x , s . t . A x ≤ b , x …...

数据结构和算法
数据结构和算法目录表 CCJava线性结构 1. 数组、单链表和双链表 2. Linux内核中双向链表的经典实现 数组、单链表和双链表 数组、单链表和双链表 栈 栈 栈 队列 队列 队列树形结构 二叉查找树 二叉查找树 二叉查找树 AVL树 AVL树 AVL树 伸展树 伸展树 伸展树 1. 红黑树(一)之…...
[Vulnhub] matrix-breakout-2-morpheus
目录 <1> 信息收集 <2> getshell <3> Privilege Escalation(提权) <1> 信息收集 nmap -sP 192.168.236.0/24 扫描一下靶机ip 靶机ip: 192.168.236.154 nmap -A -p 1-65535 192.168.236.154 扫描一下靶机开放哪些服务 开放…...
JDK, JRE和JVM之间的区别和联系
JDK, JRE和JVM是与Java编程语言相关的三个重要的概念,它们分别代表Java Development Kit(Java开发工具包)、Java Runtime Environment(Java运行时环境)和Java虚拟机(Java Virtual Machine)。它们…...
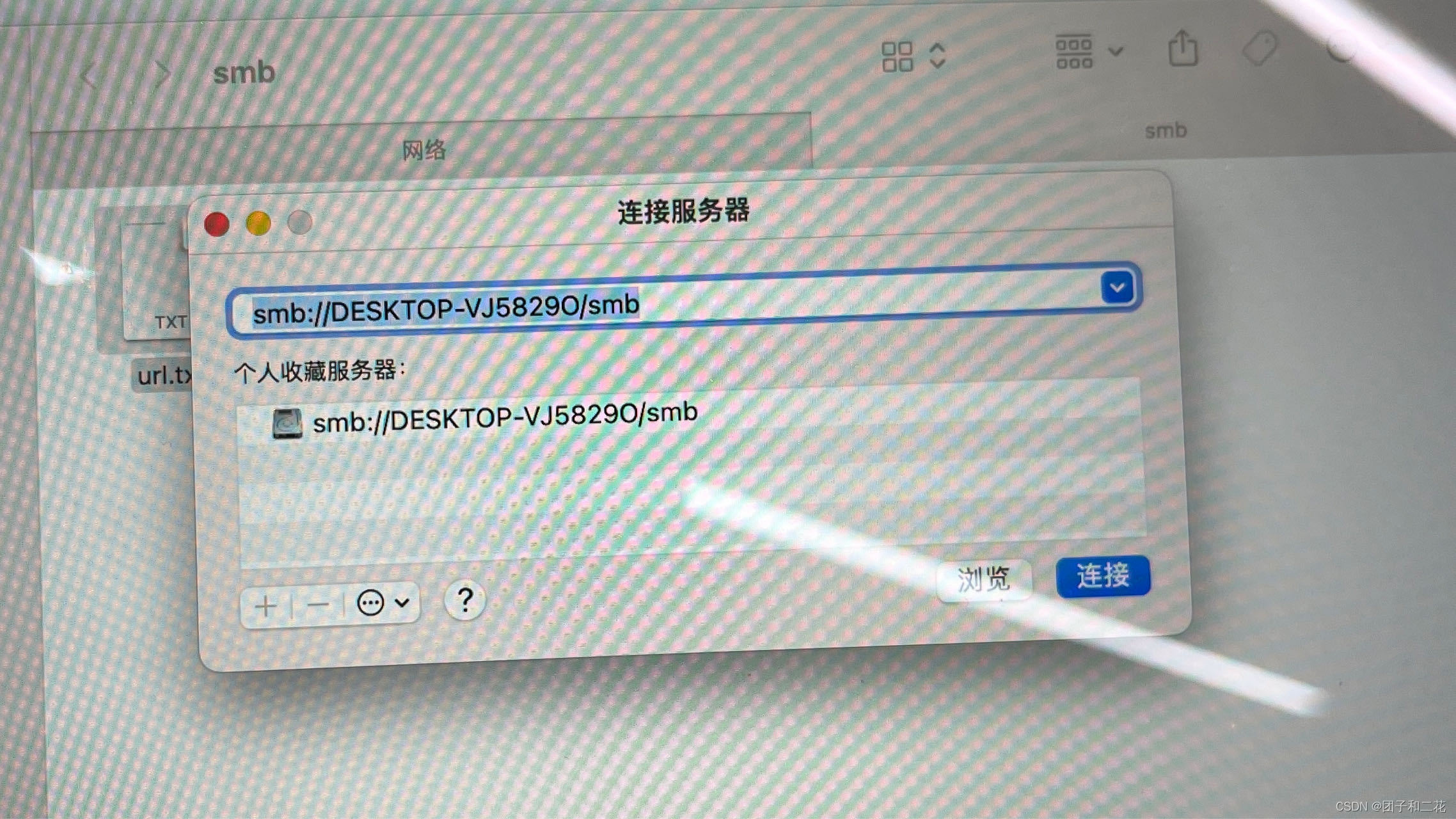
mac电脑访问windows共享文件夹连接不上(设置445端口)
前提:首先需要保证mac和windows都在同一局域网内,如果不在肯定是连不上的,就不用往下看了。 事情是这样的,公司入职发了mac电脑,但是我是window重度用户,在折腾mac的过程中,有许多文件需要从wi…...

metersphere性能压测执行过程
(1) 首先在controller层,通过RunTestPlanRequest接收请求参数 PostMapping("/run")public String run(RequestBody RunTestPlanRequest request) (2) 在PerformanceTestService中的run中进行具体的逻辑处理, 首先根据请求中ID来获取库中存储…...

揭秘Word高级技巧:事半功倍的文字处理策略
Microsoft Word是一款广泛使用的文字处理软件,几乎每个人都有使用过它的经历。但是,你是否知道Word中隐藏着许多高级技巧和功能,可以帮助你事半功倍地处理文字?在本文中,我们将揭秘一些Word的高级技巧,让你…...
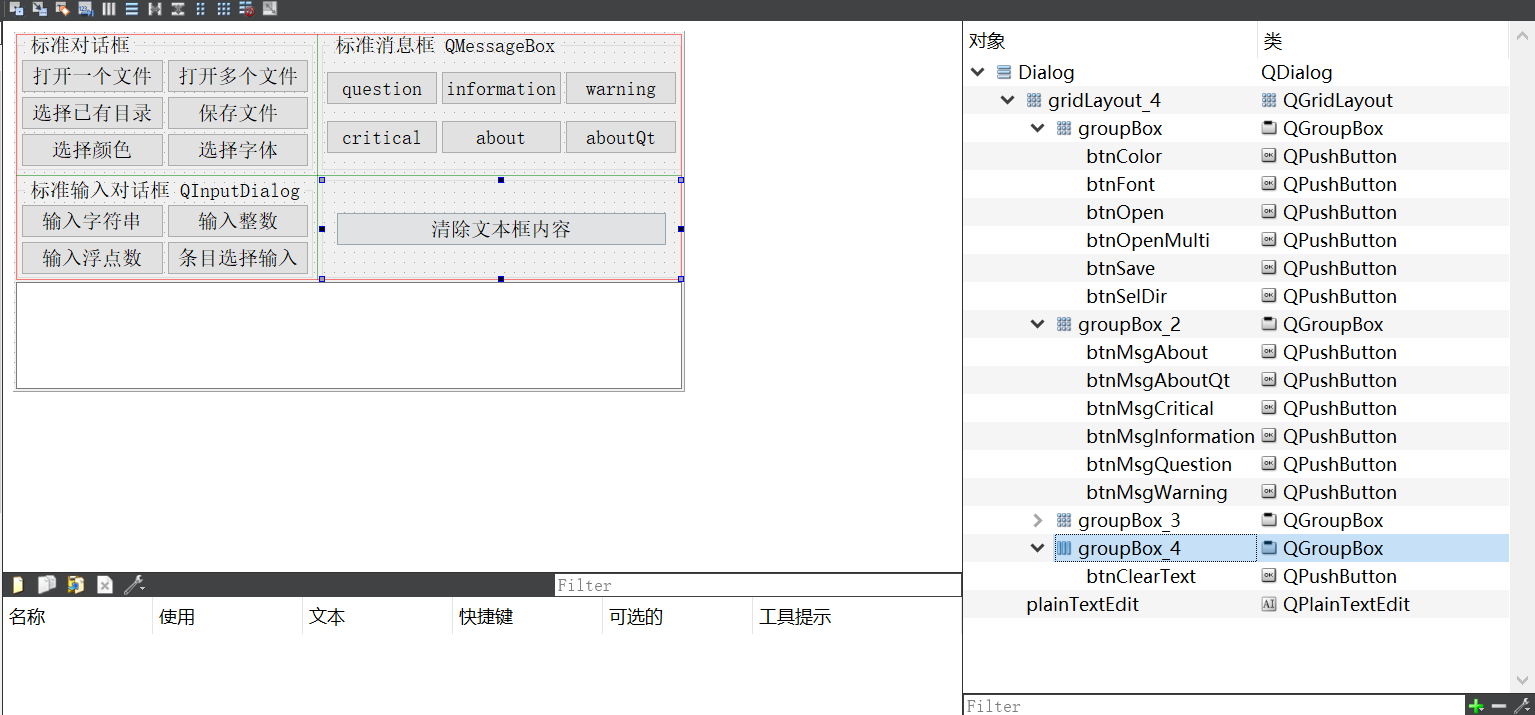
06-1_Qt 5.9 C++开发指南_对话框与多窗体设计_标准对话框
在一个完整的应用程序设计中,不可避免地会涉及多个窗体、对话框的设计和调用,如何设计和调用这些对话框和窗体是搞清楚一个庞大的应用程序设计的基础。本章将介绍对话框和多窗体设计、调用方式、数据传递等问题,主要包括以下几点。 Qt 提供的…...

模拟实现消息队列项目(系列7) -- 实现BrokerServer
目录 前言 1. 创建BrokerServer类 1.1 启动服务器 1.2 停止服务器 1.3 处理一个客户端的连接 1.3.1 解析请求得到Request对象 1.3.2 根据请求计算响应 1.3.3 将响应写回给客户端 1.3.4 遍历Session的哈希表,把断开的Socket对象的键值对进行删除 2. 处理订阅消息请求详解(补充) …...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...
恶补电源:1.电桥
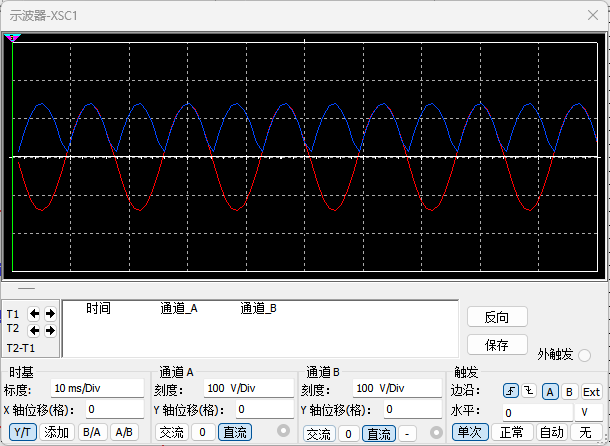
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...
论文阅读:Matting by Generation
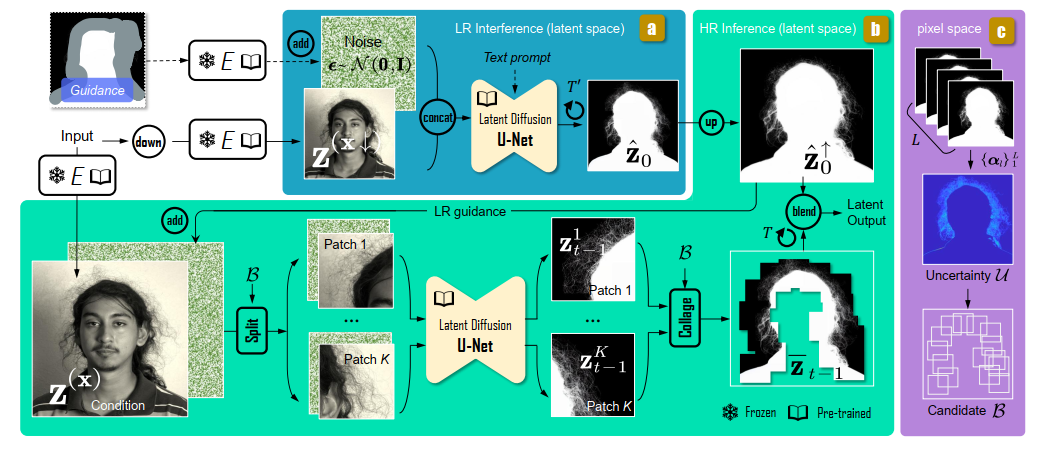
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...