基于Pytorch实现的声纹识别系统
前言
本项目使用了EcapaTdnn、ResNetSE、ERes2Net、CAM++等多种先进的声纹识别模型,不排除以后会支持更多模型,同时本项目也支持了MelSpectrogram、Spectrogram、MFCC、Fbank等多种数据预处理方法,使用了ArcFace Loss,ArcFace loss:Additive Angular Margin Loss(加性角度间隔损失函数),对应项目中的AAMLoss,对特征向量和权重归一化,对θ加上角度间隔m,角度间隔比余弦间隔在对角度的影响更加直接,除此之外,还支持AMLoss、ARMLoss、CELoss等多种损失函数。
源码地址:VoiceprintRecognition-Pytorch
使用环境:
- Anaconda 3
- Python 3.8
- Pytorch 1.13.1
- Windows 10 or Ubuntu 18.04
项目特性
- 支持模型:EcapaTdnn、TDNN、Res2Net、ResNetSE、ERes2Net、CAM++
- 支持池化层:AttentiveStatsPool(ASP)、SelfAttentivePooling(SAP)、TemporalStatisticsPooling(TSP)、TemporalAveragePooling(TAP)、TemporalStatsPool(TSTP)
- 支持损失函数:AAMLoss、AMLoss、ARMLoss、CELoss
- 支持预处理方法:MelSpectrogram、Spectrogram、MFCC、Fbank
模型论文:
- EcapaTdnn:ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification
- PANNS:PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition
- TDNN:Prediction of speech intelligibility with DNN-based performance measures
- Res2Net:Res2Net: A New Multi-scale Backbone Architecture
- ResNetSE:Squeeze-and-Excitation Networks
- CAMPPlus:CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking
- ERes2Net:An Enhanced Res2Net with Local and Global Feature Fusion for Speaker Verification
模型下载
| 模型 | Params(M) | 预处理方法 | 数据集 | train speakers | threshold | EER | MinDCF |
|---|---|---|---|---|---|---|---|
| CAM++ | 7.5 | Fbank | CN-Celeb | 2796 | 0.26 | 0.09557 | 0.53516 |
| ERes2Net | 8.2 | Fbank | CN-Celeb | 2796 | |||
| ResNetSE | 9.4 | Fbank | CN-Celeb | 2796 | 0.20 | 0.10149 | 0.55185 |
| EcapaTdnn | 6.7 | Fbank | CN-Celeb | 2796 | 0.24 | 0.10163 | 0.56543 |
| TDNN | 3.2 | Fbank | CN-Celeb | 2796 | 0.23 | 0.12182 | 0.62141 |
| Res2Net | 6.6 | Fbank | CN-Celeb | 2796 | 0.22 | 0.14390 | 0.67961 |
| ERes2Net | 8.2 | Fbank | 其他数据集 | 20W | 0.36 | 0.02936 | 0.18355 |
| CAM++ | 7.5 | Fbank | 其他数据集 | 20W | 0.29 | 0.04765 | 0.31436 |
说明:
- 评估的测试集为CN-Celeb的测试集,包含196个说话人。
安装环境
- 首先安装的是Pytorch的GPU版本,如果已经安装过了,请跳过。
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia
- 安装ppvector库。
使用pip安装,命令如下:
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simple
建议源码安装,源码安装能保证使用最新代码。
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
python setup.py install
创建数据
本教程笔者使用的是CN-Celeb,这个数据集一共有约3000个人的语音数据,有65W+条语音数据,下载之后要解压数据集到dataset目录,另外如果要评估,还需要下载CN-Celeb的测试集。如果读者有其他更好的数据集,可以混合在一起使用,但最好是要用python的工具模块aukit处理音频,降噪和去除静音。
首先是创建一个数据列表,数据列表的格式为<语音文件路径\t语音分类标签>,创建这个列表主要是方便之后的读取,也是方便读取使用其他的语音数据集,语音分类标签是指说话人的唯一ID,不同的语音数据集,可以通过编写对应的生成数据列表的函数,把这些数据集都写在同一个数据列表中。
执行create_data.py程序完成数据准备。
python create_data.py
执行上面的程序之后,会生成以下的数据格式,如果要自定义数据,参考如下数据列表,前面是音频的相对路径,后面的是该音频对应的说话人的标签,就跟分类一样。自定义数据集的注意,测试数据列表的ID可以不用跟训练的ID一样,也就是说测试的数据的说话人可以不用出现在训练集,只要保证测试数据列表中同一个人相同的ID即可。
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795
修改预处理方法
配置文件中默认使用的是Fbank预处理方法,如果要使用其他预处理方法,可以修改配置文件中的安装下面方式修改,具体的值可以根据自己情况修改。如果不清楚如何设置参数,可以直接删除该部分,直接使用默认值。
# 数据预处理参数
preprocess_conf:# 音频预处理方法,支持:MelSpectrogram、Spectrogram、MFCC、Fbankfeature_method: 'Fbank'# 设置API参数,更参数查看对应API,不清楚的可以直接删除该部分,直接使用默认值method_args:sample_frequency: 16000num_mel_bins: 80
训练模型
使用train.py训练模型,本项目支持多个音频预处理方式,通过configs/ecapa_tdnn.yml配置文件的参数preprocess_conf.feature_method可以指定,MelSpectrogram为梅尔频谱,Spectrogram为语谱图,MFCC梅尔频谱倒谱系数等等。通过参数augment_conf_path可以指定数据增强方式。训练过程中,会使用VisualDL保存训练日志,通过启动VisualDL可以随时查看训练结果,启动命令visualdl --logdir=log --host 0.0.0.0
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.py
训练输出日志:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件参数 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Non-trainable params: 0
Total mult-adds (M): 468.81
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 10.36
Params size (MB): 32.05
Estimated Total Size (MB): 42.44
===============================================================================================
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 训练数据:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
VisualDL页面:
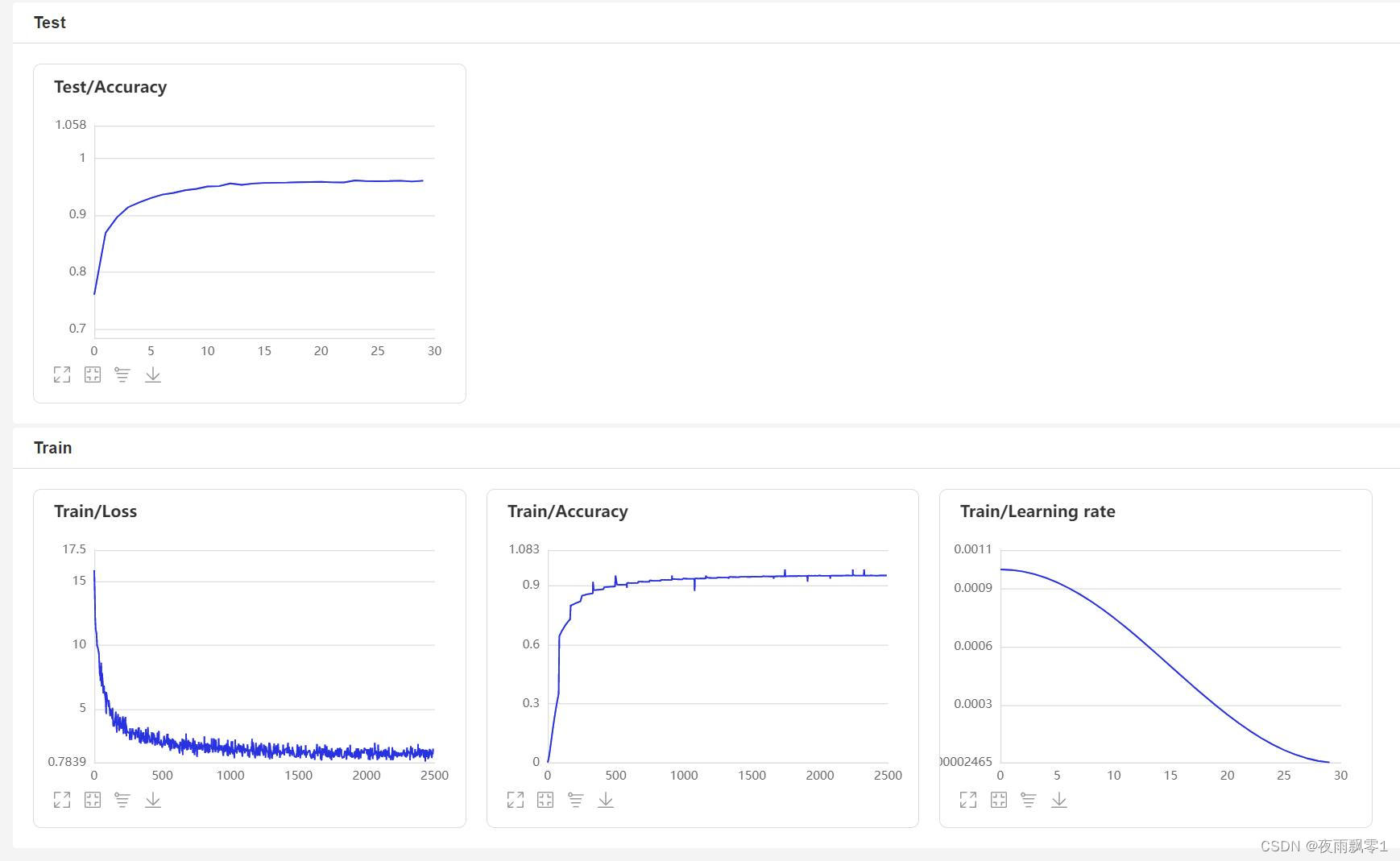
评估模型
训练结束之后会保存预测模型,我们用预测模型来预测测试集中的音频特征,然后使用音频特征进行两两对比,计算EER和MinDCF。
python eval.py
输出类似如下:
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加载模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
开始两两对比音频特征...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
评估消耗时间:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
声纹对比
下面开始实现声纹对比,创建infer_contrast.py程序,编写infer()函数,在编写模型的时候,模型是有两个输出的,第一个是模型的分类输出,第二个是音频特征输出。所以在这里要输出的是音频的特征值,有了音频的特征值就可以做声纹识别了。我们输入两个语音,通过预测函数获取他们的特征数据,使用这个特征数据可以求他们的对角余弦值,得到的结果可以作为他们相识度。对于这个相识度的阈值threshold,读者可以根据自己项目的准确度要求进行修改。
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wav
输出类似如下:
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav 和 audio/b_2.wav 不是同一个人,相似度为:-0.09565544128417969
声纹识别
在上面的声纹对比的基础上,我们创建infer_recognition.py实现声纹识别。同样是使用上面声纹对比的infer()预测函数,通过这两个同样获取语音的特征数据。 不同的是笔者增加了load_audio_db()和register(),以及recognition(),第一个函数是加载声纹库中的语音数据,这些音频就是相当于已经注册的用户,他们注册的语音数据会存放在这里,如果有用户需要通过声纹登录,就需要拿到用户的语音和语音库中的语音进行声纹对比,如果对比成功,那就相当于登录成功并且获取用户注册时的信息数据。第二个函数register()其实就是把录音保存在声纹库中,同时获取该音频的特征添加到待对比的数据特征中。最后recognition()函数中,这个函数就是将输入的语音和语音库中的语音一一对比。
有了上面的声纹识别的函数,读者可以根据自己项目的需求完成声纹识别的方式,例如笔者下面提供的是通过录音来完成声纹识别。首先必须要加载语音库中的语音,语音库文件夹为audio_db,然后用户回车后录音3秒钟,然后程序会自动录音,并使用录音到的音频进行声纹识别,去匹配语音库中的语音,获取用户的信息。通过这样方式,读者也可以修改成通过服务请求的方式完成声纹识别,例如提供一个API供APP调用,用户在APP上通过声纹登录时,把录音到的语音发送到后端完成声纹识别,再把结果返回给APP,前提是用户已经使用语音注册,并成功把语音数据存放在audio_db文件夹中。
python infer_recognition.py
输出类似如下:
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/ecapa_tdnn/model.pth
Loaded 沙瑞金 audio.
Loaded 李达康 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434
其他版本
- Tensorflow:VoiceprintRecognition-Tensorflow
- PaddlePaddle:VoiceprintRecognition-PaddlePaddle
- Keras:VoiceprintRecognition-Keras
参考资料
- https://github.com/PaddlePaddle/PaddleSpeech
- https://github.com/yeyupiaoling/PaddlePaddle-MobileFaceNets
- https://github.com/yeyupiaoling/PPASR
- https://github.com/alibaba-damo-academy/3D-Speaker
相关文章:
基于Pytorch实现的声纹识别系统
前言 本项目使用了EcapaTdnn、ResNetSE、ERes2Net、CAM等多种先进的声纹识别模型,不排除以后会支持更多模型,同时本项目也支持了MelSpectrogram、Spectrogram、MFCC、Fbank等多种数据预处理方法,使用了ArcFace Loss,ArcFace loss…...
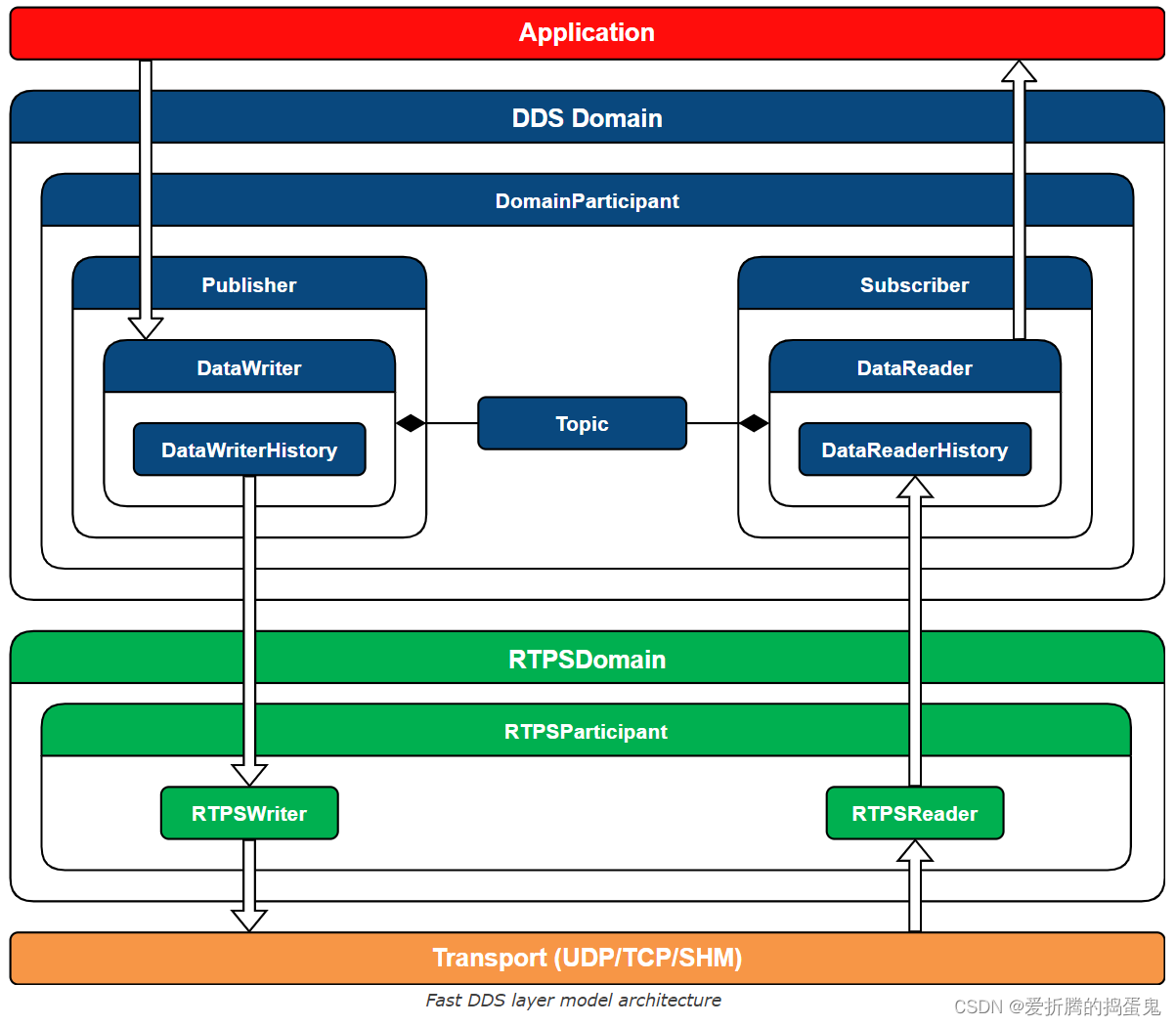
Fast DDS (2)
1、结构: Fast DDS的架构如下图所示,可以看到以下不同环境的层模型: 应用层:利用Fast DDS API 在分布式系统中实现通信的用户应用程序。Fast DDS层:DDS 通信中间件的稳健实现。它允许部署一个或多个 DDS 域ÿ…...

HarmonyOS/OpenHarmony应用开发-ArkTS语言渲染控制if/else条件渲染
ArkTS提供了渲染控制的能力。条件渲染可根据应用的不同状态,使用if、else和else if渲染对应状态下的UI内容。说明:从API version 9开始,该接口支持在ArkTS卡片中使用。一、使用规则 支持if、else和else if语句。 if、else if后跟随的条件语句…...
飞天使-k8s基础组件分析-pod
文章目录 pod介绍pod 生命周期init 容器容器handlerpod中容器共享进程空间sidecar 容器共享 参考链接 pod介绍 最小的容器单元 为啥需要pod? 答: 多个进程丢一个容器里,会因为容器里个别进程出问题而出现蝴蝶效应,pod 是更高级的处理方式pod 如何共享相…...

css题库
什么是css? CSS 是“Cascading Style Sheet”的缩写,中文意思为“层叠样式表”,它是一种标准的样式表语言,用于描述网页的表现形式(例如网页元素的位置、大小、颜色等)。 为什么最好把 CSS 的 link 标签放在…...

中文医疗大模型汇总
【写在前面】随着大语言模型的发展,越来越多的垂直领域的LLM发不出来,针对医学这一垂直领域的LLM进行整理,放在这里,希望对大家有一定的帮助吧。还会继续更新,大家有兴趣的话可以持续关注。 更多关于中文医疗自然语言处…...

smiley-http-proxy-servlet 实现springboot 接口反向代理,站点代理,项目鉴权,安全的引入第三方项目服务
背景: 项目初期 和硬件集成,实现了些功能服务,由于是局域网环境,安全问题当时都可以最小化无视。随着对接的服务越来越多,部分功能上云,此时就需要有一种手段可以控制到其他项目/接口的访问权限。 无疑 反向…...
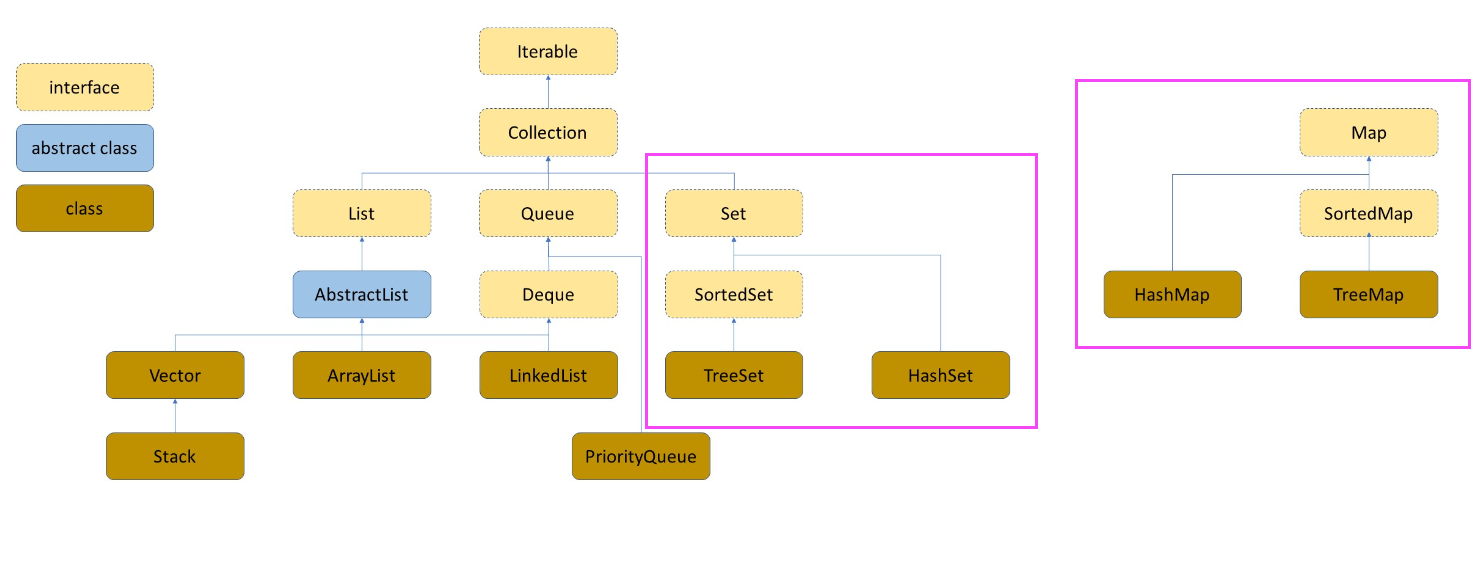
Java集合利器 Map Set
Map & Set 一、概念二、Map三、Set下期预告 一、概念 Map和Set是一种专门用来进行搜索的数据结构,其搜索的效率与其具体的实例化子类有关。它们分别定义了两种不同的数据结构和特点: Map(映射) :Map是一种键值对&…...

HJ106 字符逆序
描述 将一个字符串str的内容颠倒过来,并输出。 数据范围:1≤len(str)≤10000 1≤len(str)≤10000 输入描述: 输入一个字符串,可以有空格 输出描述: 输出逆序的字符串 示例1 输入: I am a student 输…...
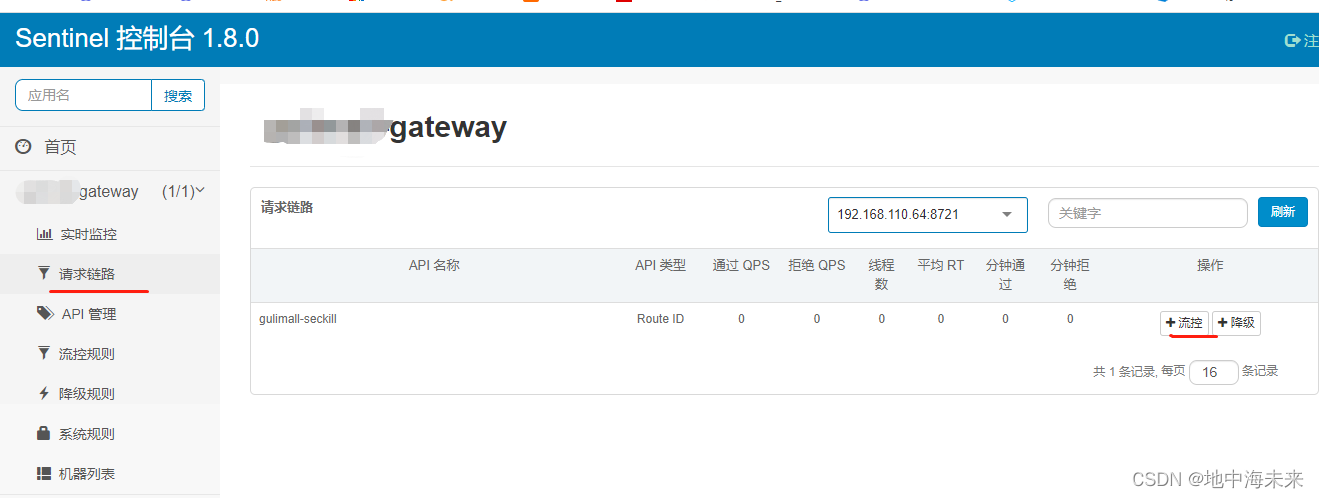
sentinel的基本使用
在一些互联网项目中高并发的场景很多,瞬间流量很大,会导致我们服务不可用。 sentinel则可以保证我们服务的正常运行,提供限流、熔断、降级等方法来实现 一.限流: 1.导入坐标 <dependency><groupId>com.alibaba.c…...

【STM32】串口通信乱码(认识系统时钟来源)
使用 stm32f407 与电脑主机进行串口通信时,串口助手打印乱码,主要从以下方面进行排查: 检查传输协议设置是否一致(波特率、数据位、停止位、校验位)检查MCU外部晶振频率是否和库函数设置的一致 最终发现是外部晶振频…...
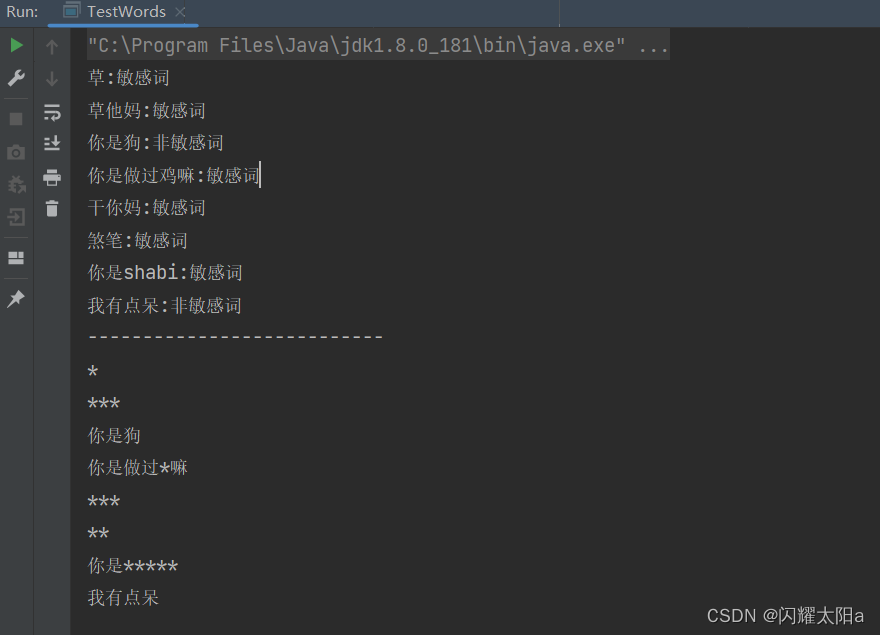
Java实现敏感词过滤功能
敏感词过滤功能实现 1.GitHub上下载敏感词文件 2.将敏感词文件放在resources目录下 在业务中可以将文本中的敏感词写入数据库便于管理。 3.提供实现类demo 代码编写思路如下:1.将敏感词加载到list中,2.添加到StringSearch中,3.校验&#x…...

大数据向量检索的细节问题
背景:现有亿级别数据(条数),其文本大小约为150G,label为字符串,content为文本。用于向量检索,采用上次的试验进行,但有如下问题需要面对: 1、向量维度及所需空间 向量维度一版采用768的bert系列的模型推理得到,openai也有类似的功能,不过是2倍的维度(即1536),至…...
如何让智能搜索引擎更灵活、更高效?
随着互联网的发展和普及,搜索引擎已经成为人们获取信息、解决问题的主要工具之一。 然而,传统的搜索引擎在面对大数据时,往往存在着搜索效率低下、搜索结果精准度不够等问题。 为了解决这些问题,越来越多的企业开始采用智能搜索技…...

C++set集合与并查集map映射,哈希表应用实例B3632 集合运算 1P1918 保龄球
集合的性质 无序性互异性确定性 B3632 集合运算 1 题面 题目背景 集合是数学中的一个概念,用通俗的话来讲就是:一大堆数在一起就构成了集合。 集合有如下的特性: 无序性:任一个集合中,每个元素的地位都是相同的&…...
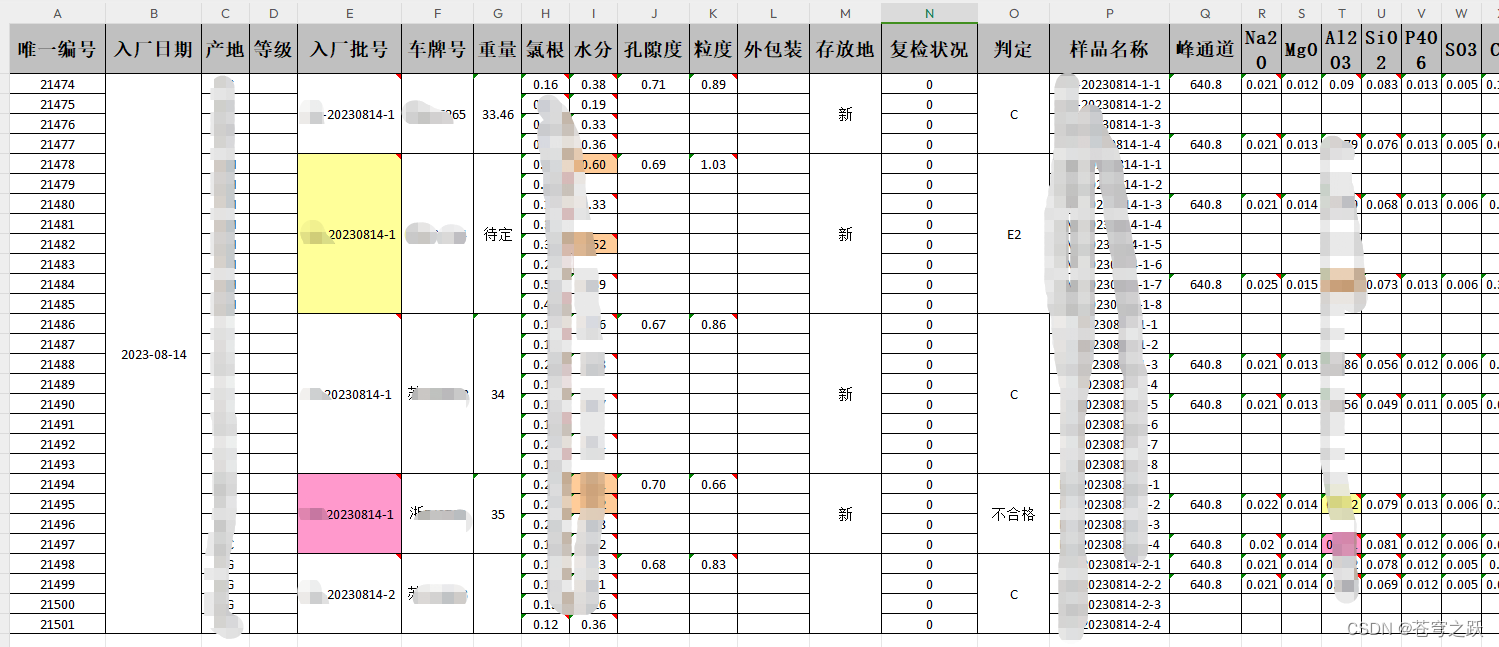
easyexcel合并单元格底色
一、效果图 二、导出接口代码 PostMapping("selectAllMagicExport")public void selectAllMagicExport(HttpServletRequest request, HttpServletResponse response) throws IOException {ServiceResult<SearchResult<TestMetLineFe2o3Export>> result …...

OpenCV图片校正
OpenCV图片校正 背景几种校正方法1.傅里叶变换 霍夫变换 直线 角度 旋转3.四点透视 角度 旋转4.检测矩形轮廓 角度 旋转参考 背景 遇到偏的图片想要校正成水平或者垂直的。 几种校正方法 对于倾斜的图片通过矫正可以得到水平的图片。一般有如下几种基于opencv的组合方…...
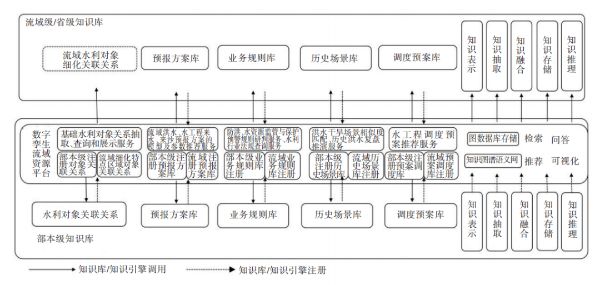
数字孪生流域共建共享相关政策解读
当前数字孪生技术在水利方面的应用刚起步,2021年水利部首次提出“数字孪生流域”概念,即以物理流域为单元、时空数据为底座、数学模型为核心、水利知识为驱动,对物理流域全要素和水利治理管理活动全过程的数字映射、智能模拟、前瞻预演&#…...
FSC147数据集格式解析
一. 引言 在研究很多深度学习框架的时候,往往需要使用到FSC147格式数据集,若要是想在自己的数据集上验证深度学习框架,就需要自己制作数据集以及相关标签,在论文Learning To Count Everything中,该数据集首次被提出。 …...

el-element中el-tabs案例的使用
el-element中el-tabs的使用 代码呈现 <template><div class"enterprise-audit"><div class"card"><div class"cardTitle"><p>交易查询</p></div><el-tabs v-model"activeName" tab-cl…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...
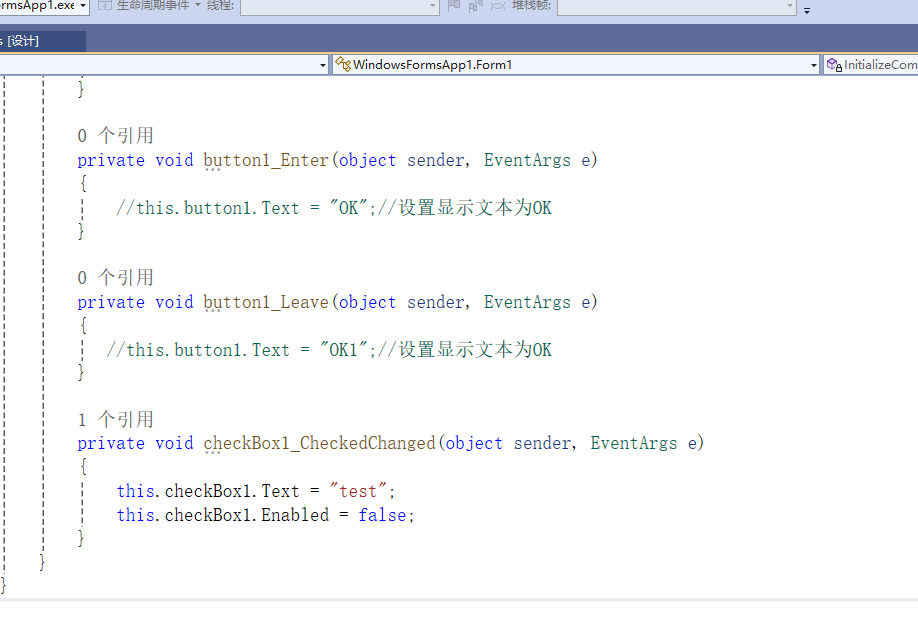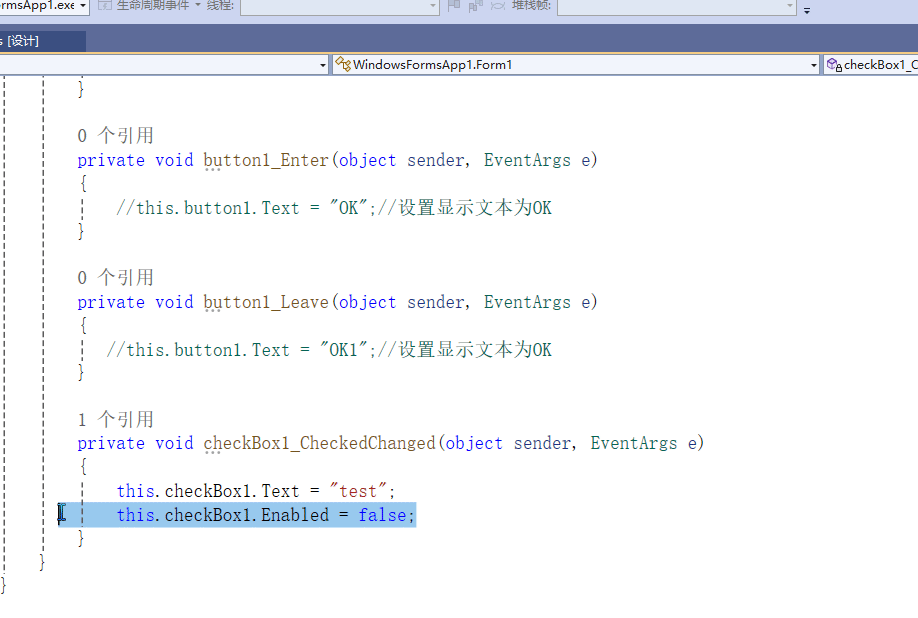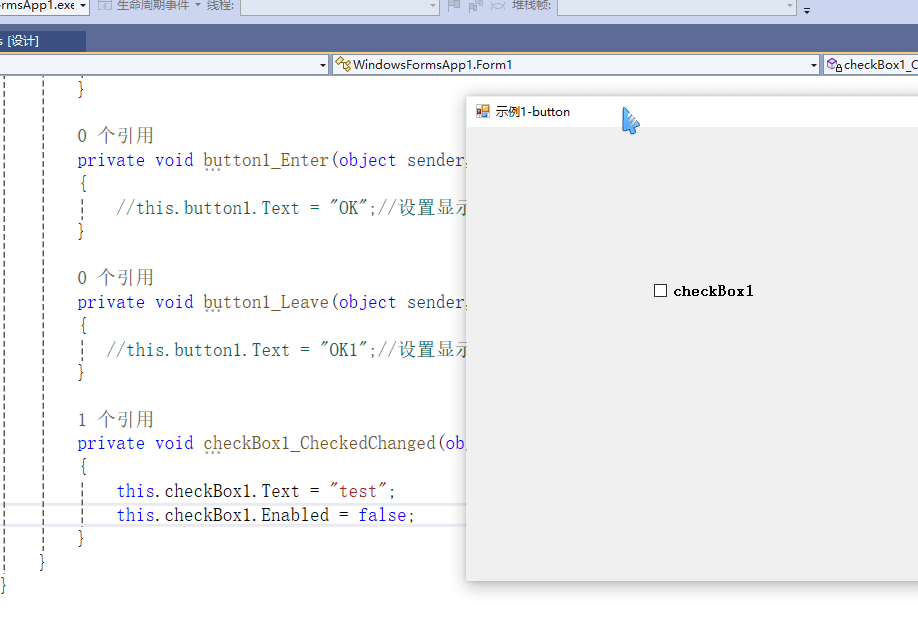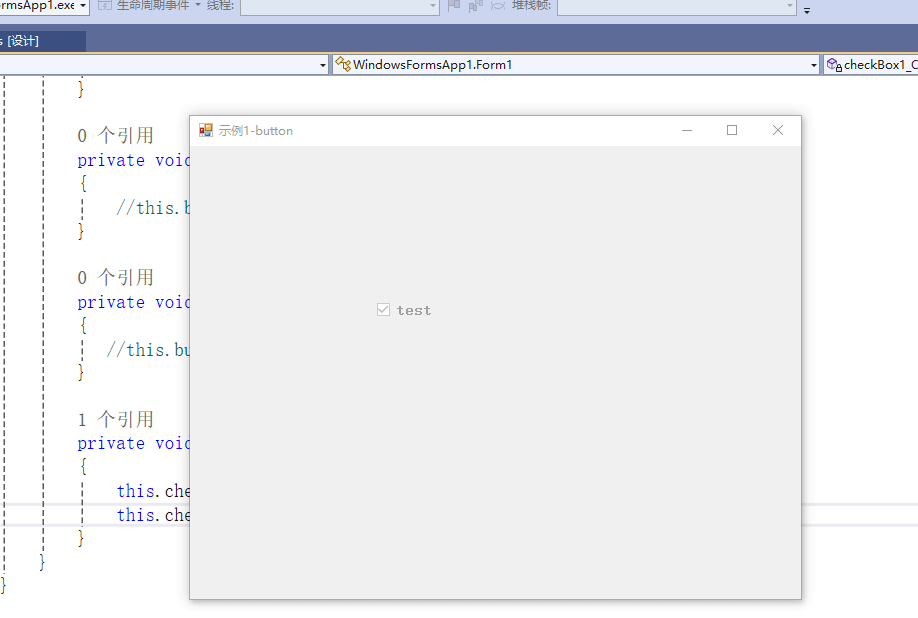
C# winform教程(二)----checkbox
一、作用 提供一个用户选择或者不选的状态,这是一个可以多选的控件。 二、属性 其实功能大差不差,除了特殊的几个外,与button基本相同,所有说几个独有的 checkbox属性 名称内容含义appearance控件外观可以变成按钮形状checkali…...

6.9本日总结
一、英语 复习默写list11list18,订正07年第3篇阅读 二、数学 学习线代第一讲,写15讲课后题 三、408 学习计组第二章,写计组习题 四、总结 明天结束线代第一章和计组第二章 五、明日计划 英语:复习l默写sit12list17&#…...
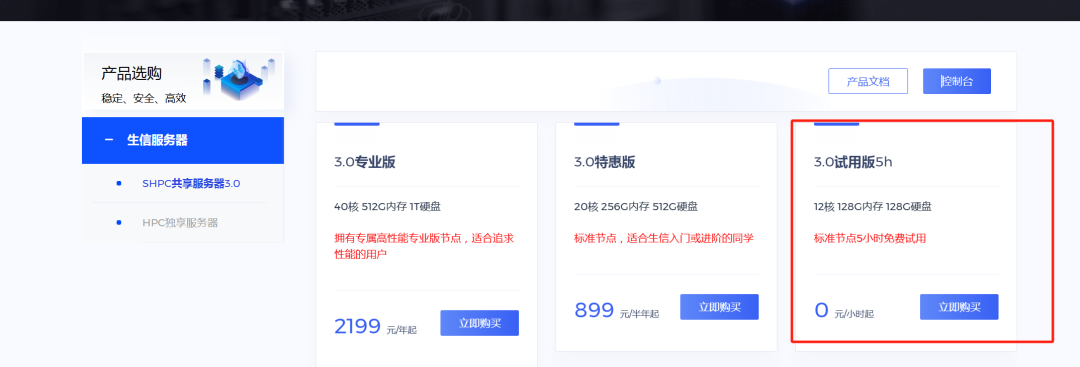
生信服务器 | 做生信为什么推荐使用Linux服务器?
原文链接:生信服务器 | 做生信为什么推荐使用Linux服务器? 一、 做生信为什么推荐使用服务器? 大家好,我是小杜。在做生信分析的同学,或是将接触学习生信分析的同学,<font style"color:rgb(53, 1…...