Lostash同步Mysql数据到ElasticSearch(二)logstash脚本配置和常见坑点
1. logstash脚本编写(采用单文件对应单表实例)
新建脚本文件夹
| cd /usr/local/logstash mkdir sql & cd sql vim 表名称.conf #如: znyw_data_gkb_logstash.conf |
建立文件夹,保存资源文件更新Id
| mkdir -p /data/logstash/data/last_run_metadata |
脚本JDBC插件参数说明:

增加新脚本步骤:修改statement 查询执行SQL脚本(对应数据库表)可以通过代码工具生成。地址: 增量同步字段,建议使用更新时间字段tracking_column => "updateDate" tracking_column_type => timestamp(类型成对出现) 修改数据存储文件路径,红色为索引名称,每个脚本对应一个。last_run_metadata_path => "xxx_last_update_time.txt" 同步频率(可以通过在线表达式进行生成)在线Cron表达式生成器
第一步要做的事情,配置logstasht同步脚本文件,内容如下:
input {jdbc {type => "jdbc"# 数据库连接地址jdbc_connection_string => "jdbc:mysql://172.168.9.131:3306/gffp_om?characterEncoding=UTF-8&autoReconnect=true&serverTimezone=CTT"# 数据库连接账号密码jdbc_user => "znyg"jdbc_password => "hTORRp86!7"# MySQL依赖包路径jdbc_driver_library => "/usr/local/logstash/mysql-connector-java-8.0.22.jar"# the name of the driver class for mysqljdbc_driver_class => "com.mysql.cj.jdbc.Driver"# 数据库重连尝试次数connection_retry_attempts => "5"# 判断数据库连接是否可用,默认false不开启jdbc_validate_connection => "true"# 数据库连接可用校验超时时间,默认3600Sjdbc_validation_timeout => "3600"# 开启分页查询(默认false不开启);jdbc_paging_enabled => "true"# 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值);jdbc_page_size => "500"# statement为查询数据sql,如果sql较复杂,建议配通过statement_filepath配置sql文件的存放路径;# sql_last_value为内置的变量,存放上次查询结果中最后一条数据tracking_column的值,此处即为ModifyTime;# statement_filepath => "mysql/jdbc.sql"statement => "select * from xxx WHERE id>= :sql_last_value"# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);lowercase_column_names => false# Value can be any of: fatal,error,warn,info,debug,默认info;sql_log_level => warn## 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;record_last_run => true# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值;use_column_value => true# 需要记录的字段,用于增量同步,需是数据库字段tracking_column => "id"# Value can be any of: numeric,timestamp,Default value is "numeric"tracking_column_type => numeric# record_last_run上次数据存放位置;last_run_metadata_path => "/data/logstash/data/last_run_metadata/_last_id.txt"# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;clean_run => false## 同步频率(分 时 天 月 年),默认每分钟同步一次;schedule => "* * * * *"}
}filter {}
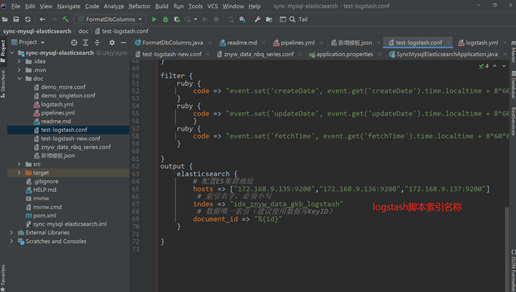
output {elasticsearch {# 配置ES集群地址hosts => ["172.168.9.135:9200","172.168.9.136:9200","172.168.9.137:9200"]# 索引名字,必须小写index => ""A# 数据唯一索引(建议使用数据库KeyID)document_id => "%{id}"}
}
第二部要做的事情,根据_mapping.json初始化模版在kibana中执行
PUT /_template/索引名称 (与模板名称保持一致。)
模板内容如下:
PUT /_template/A_temp A
{A "template": "A_temp.json" ,"order": 1,
# 索引配置设置,这里需要注意 分片数,在索引创建的时候使用,这个索引一旦创建了后就不能再修改,想改只能删索引重建了,副本数可以热更新,其他参数可以关闭索引更新内容。"settings": {"number_of_shards": 5,"number_of_replicas": 1,"max_result_window": 65536,"max_inner_result_window": 10000,"translog.durability": "request","translog.sync_interval": "3s","auto_expand_replicas": false,"analysis.analyzer.default.type": "ik_max_word","analysis.search_analyzer.default.type": "ik_smart","shard.check_on_startup": false,"codec": "default","store.type": "niofs"},"mappings": {#这个需要注意一下,主要是做模板验证用的,详细参考ES template模板相关内容。"dynamic": "true","dynamic_date_formats": ["yyyy-MM-dd'T'HH:mm:ss.SSS'Z'","yyyy-MM-dd'T'HH:mm:ss.SSS+0800","yyyy-MM-dd'T'HH:mm:ss'Z'","yyyy-MM-dd'T'HH:mm:ss+0800","yyyy-MM-dd'T'HH:mm:ss","yyyy-MM-dd HH:mm:ss","yyyy-MM-dd"],"properties": {"@timestamp": {"type": "date"},"@version": {"type": "integer"},"_class": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},#这里的是对应数据库字段,一一对于,格式可以指定,特殊的一些使用,我提供了一个工具,大家在文章中找一下。"id": {"type": "long"}}}
}这里想重点说几个需要注意的地方:
1.logstash同步脚本中index名称与索引名称、模板名称保持一致 看蓝色的A,三个在上面的模板文件和脚本文件中,注意这三个A是给大家标记用的,文件中不需要。
2.看索引模板的代码中,红色代码块,是需要注意的地方,我在文件中写了注释,注意这是json参数,使用时把注释删掉。
2.数据同步
2.1单表同步
| #编写一个单表实例测试,如下启动日志会实时打印,便于调试错误 bin/logstash -f test-new.conf & |
注意: ES模板名称与logstash脚本index名称保存一致
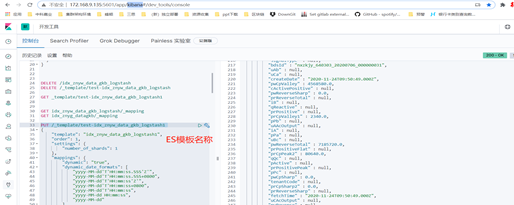
检查_mapping是否与template模板一致,字段类型,长度是否与模板一致(同步完成后在kibana中执行)
如:GET idx_znyw_data_gkb_logstash/_mapping
此时会多出几个模板中没有定义,select查询不包含的字段:
有坑的地方重点标准一下
@timestamp,@version, _class, type(这里有个大坑,type属于logstash,mysql实体不能存在此字段,官方也没有解决方案)
检查数据
检查时间类型等是否与mysql中数据同步一致
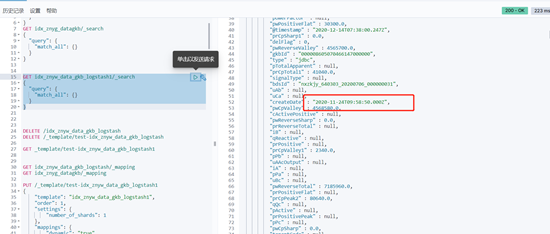
脚本同步时配置的时间字段包含具体时间信息的以UTC时间,
与数据库保持一致,一种操作是同步时+8处理,一种是不处理,因为ES这块是UTC时间,ES提供的JAVA版本API也是UTC处理,这块时间会进行转换。
那么需要注意的地方是什么:
+8操作后,所有界面上显示的时间均为转换后时区时间,具体减价看服务所在的时区,界面上显示的时间指的是Kibana或者ES HEAD查询出的时间,那么需要注意的是什么呢,在java中查询时你需要注意这个+8操作。主要是查询参数,但是得到的结果你会发现,还是不准确。
我推荐的操作是怎么操作呢,我建议不要在数据同步时做什么特殊处理,这块特别绕,一会+8,一会不+8,那么怎么操作呢,我建议在VO对象中做格式转换使用注解进行view层的数据转换,给用户显示正确的时间,查询时别用vo对象做反射哦,否则参数也会根据注解进行修改,查询参数就不对了。
2.2多文件配置
修改配置文件,这里还可以修改path.config: “/map/es/soft/logstash-7.6.2/config/myconfig/*.conf” 不推荐这种方式,但是👀注意一下,这是一个大坑,与机制有关,我没有扒代码,只是把自己的推断写下来,logstash 本次任务未执行完成,有异常,会保存当前任务执行状态,包括配置文件内容,类似存储同步ID序列,也就是说,如果批量执行过程中,有任务未完成,此时logstash会把包括配置文件的状态一起保存。此时,想修改批处理为单个执行,修改配置文件后不起作用,即便指定单个文件运行,也会把所有的一起执行,只能把同步脚本做迁移,保留一个来运行,或者删除其他脚本,保留一个,当记录的任务执行成功后,此时会释放,重新加载配置文件,在生成环境中遇到了,修改配置文件不起作用,任务重新执行完,logstash才重新加载配置文件
| vim /usr/local/logstash/config/pipelines.yml 追加配置所有脚本文件 – pipeline.id: znyw_data_gkb_logstash path.config: “/usr/local/logstash/sql/znyw_data_gkb_logstash.conf” – pipeline.id: znyw_data_gkb_logstash1 path.config: “/usr/local/logstash/sql/znyw_data_gkb_logstash1.conf” |
启动检查数据同步:
nohup ./bin/logstash &
tail -f /usr/local/logstash/nohup.out ps#查看执行实时情况(更详细排错)
tail -f /data/logstash/logs/logstash-plain.log #查看任务执行情况(查看执行结果)
3. 问题及解决方案
3.1″path.data” setting.
异常问题:
Logstash could not be started because there is already another instance using the configured data directory. If you wish to run multiple instances, you must change the “path.data” setting.
- 查看是否存在正在运行的进程
ps aux|grep logstash
kill -9 73803
3.2、数据同步后,ES没有数据
output.elasticsearch模块的index必须是全小写;
3.3、增量同步后last_run_metadata_path文件内容不改变
如果lowercase_column_names配置的不是false,那么tracking_column字段配置的必须是全小写。
3.4、提示找不到jdbc_driver_library
2032 com.mysql.jdbc.Driver not loaded.
Are you sure you've included the correct jdbc driver in :jdbc_driver_library?
检测配置的地址是否正确,如果是linux环境,注意路径分隔符是“/”,而不是“\”。
3.5、数据丢失
statement配置的sql中,如果比较字段使用的是大于“>”,可能存在数据丢失。
假设当同步完成后last_run_metadata_path存放的时间为2019-01-30 20:45:30,而这时候新入库一条数据的更新时间也为2019-01-30 20:45:30,那么这条数据将无法同步。
解决方案:将比较字段使用 大于等于“>=”。
3.6、数据重复更新
上一个问题“数据丢失”提供的解决方案是比较字段使用“大于等于”,但这时又会产生新的问题。
假设当同步完成后last_run_metadata_path存放的时间为2019-01-30 20:45:30,而数据库中更新时间最大值也为2019-01-30 20:45:30,那么这些数据将重复更新,直到有更新时间更大的数据出现。
当上述特殊数据很多,且长期没有新的数据更新时,会导致大量的数据重复同步到ES。
何时会出现以上情况呢:①比较字段非“自增”;②比较字段是程序生成插入。
解决方案:
①比较字段自增保证不重复或重复概率极小(比如使用自增ID或者数据库的timestamp),这样就能避免大部分异常情况了;
②如果确实存在大量程序插入的数据,其更新时间相同,且可能长期无数据更新,可考虑定期更新数据库中的一条测试数据,避免最大值有大量数据。
3.7 logstash突然报Unable to connect to database. Tried 1 times
检查一下上服务部署的机器用命令:
>telnet 172.168.9.131 3306
若报错显示:MySql Host is blocked because of many connection errors; unblock with ‘mysqladmin flush-hosts’
2、使用mysqladmin flush-hosts 命令清理一下hosts文件(不知道mysqladmin在哪个目录下可以使用命令查找:whereis mysqladmin);
① 在查找到的目录下使用命令修改:/usr/local/bin/mysqladmin flush-hosts -uroot -p
备注:
其中端口号,用户名,密码都可以根据需要来添加和修改;
配置有master/slave主从数据库的要把主库和从库都修改一遍的(我就吃了这个亏明明很容易的几条命令结果折腾了大半天);
第二步也可以在数据库中进行,命令如下:flush hosts;
4. 最后一定要做的事情
4.1 索引副本数配置
因环境节点数量不同,所以特殊索引副本数量需要设置,如下索引进行动态修改
| idx_znyg_devicemodel idx_znyg_devicetype idx_znyg_sysdevtype idx_znyg_sysinfo |
在kibana中执行如下代码修改副本数量,参数为副本数量为节点数-1,如下操作还可以修改索引settings相关属性,除了分片数量不能动态修改外,只有副本数量可以热更新,其他属性需要关闭索引后,进行修改。
| PUT /idx_znyg_sysinfo/_settings { “index”:{ “number_of_replicas”: 2 } } |
4.2服务健康状态检查任务配置
| crontab -e 0 * * * /bin/sh /opt/logstash/logstash-7.1.1/logstash_health.sh |
提供一个索引配置工具,自己写的,包括生产SQL语句,显示表数据量,生成ruby关于时间字段的脚步,批量创建更新ES模板,但是模板需要事先写好。
相关文章:
Lostash同步Mysql数据到ElasticSearch(二)logstash脚本配置和常见坑点
1. logstash脚本编写(采用单文件对应单表实例) 新建脚本文件夹 cd /usr/local/logstash mkdir sql & cd sql vim 表名称.conf #如: znyw_data_gkb_logstash.conf 建立文件夹,保存资源文件更新Id mkdir -p /data/logstash/data/last_r…...

兔兔答题企业版1.0.0版本全网发布,同时开源前端页面到unicloud插件市场
项目说明 兔兔答题是用户端基于uniapp开发支持多端适配,管理端端采用TypeScriptVue3.jselement-plus,后端采用THinkPHP6PHP8Golang开发的一款在线答题应用程序。 问题反馈 线上预览地址 相关问题可以通过下方的二维码,联系到我。了解更多 …...
76、SpringBoot 整合 MyBatis------使用 sqlSession 作为 Dao 组件(就是ssm那一套,在 xml 写sql)
就是 ssm 那套,在xml 上面写sql ★ 基于SqlSession来实现DAO组件的方式 - MyBatis提供的Starter会自动在Spring容器中配置SqlSession(其实SqlSessionTemplate实现类)、并将它注入其他组件(如DAO组件)- DAO组件可直接…...

【ROS】RViz、Gazebo和Navigation的关系
1、RViz RViz(Robot Visualization,机器人可视化)是一个用于可视化机器人系统的开源工具,用于显示和调试机器人的传感器数据、状态信息和运动规划等。它是ROS(Robot Operating System)的一部分,是ROS中最常用的可视化工具之一。 RViz:“我们不生产数据只做数据的搬运…...
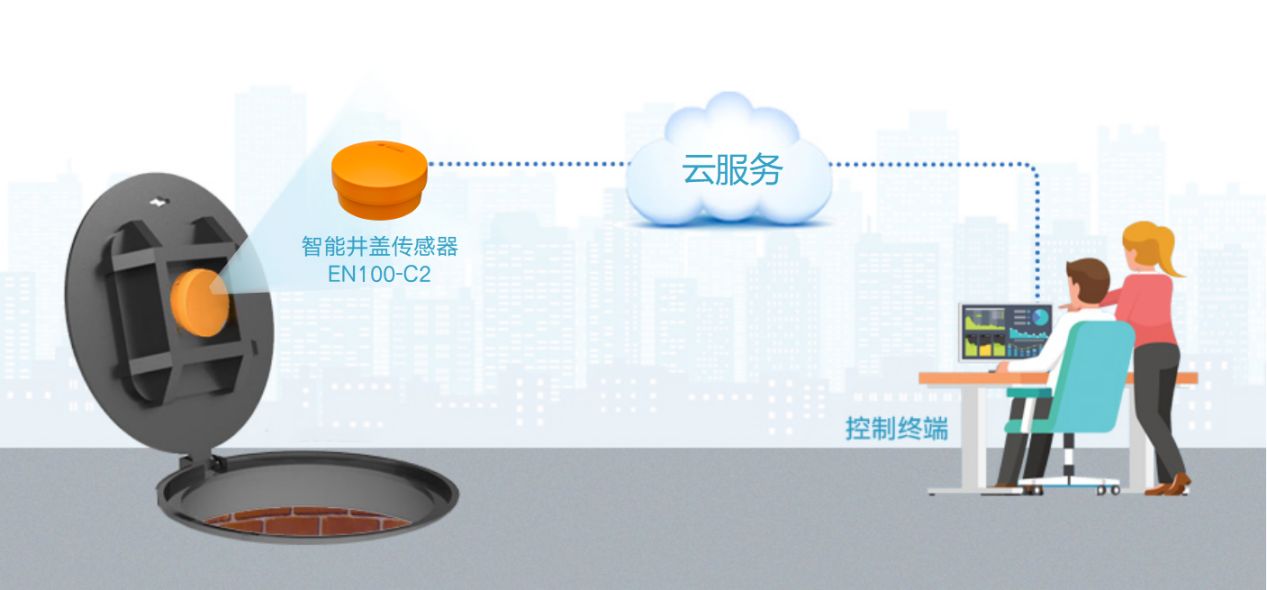
智能井盖:提升城市井盖安全管理效率
窨井盖作为城市基础设施的重要组成部分,其安全管理与城市的有序运行和群众的生产生活安全息息相关,体现城市管理和社会治理水平。当前,一些城市已经将智能化的窨井盖升级改造作为新城建的重要内容,推动窨井盖等“城市部件”配套建…...

JavaWeb开发-06-SpringBootWeb-MySQL
一.MySQL概述 1.安装、配置 官网下载地址:https://dev.mysql.com/downloads/mysql/ 2.数据模型 3.SQL简介 二.数据库设计-DDL 1.数据库 官网:http:// https://www.jetbrains.com/zh-cn/datagrip/ 2.表(创建、查询、修改、删除) #…...

十六、垃圾回收相关概念
目录 一、System.gc()的理解二、内存溢出和内存泄漏2、内存泄漏 三、Stop the World1、什么是 stop the word ? 四、垃圾回收的并行和并发1、并发和并发2、垃圾回收的并行和并发 五、安全点与安全区域1、什么是安全点?2、安全区域 六、强引用(不可回收&…...
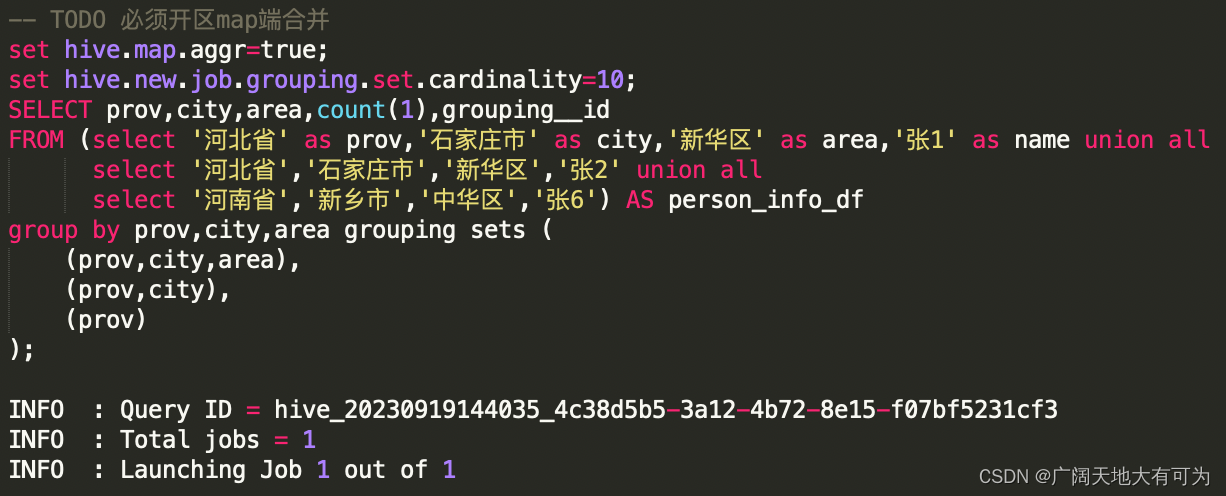
hive、spark、presto 中的增强聚合-grouping sets、rollup、cube
目录 1、什么是增强聚合和多维分析函数? 2、grouping sets - 指定维度组合 3、with rollup - 上卷维度组合 4、with cube - 全维度组合 5、Grouping__ID、grouping() 的使用场景 6、使用 增强聚合 会不会对查询性能有提升呢? 7、对grouping sets、…...
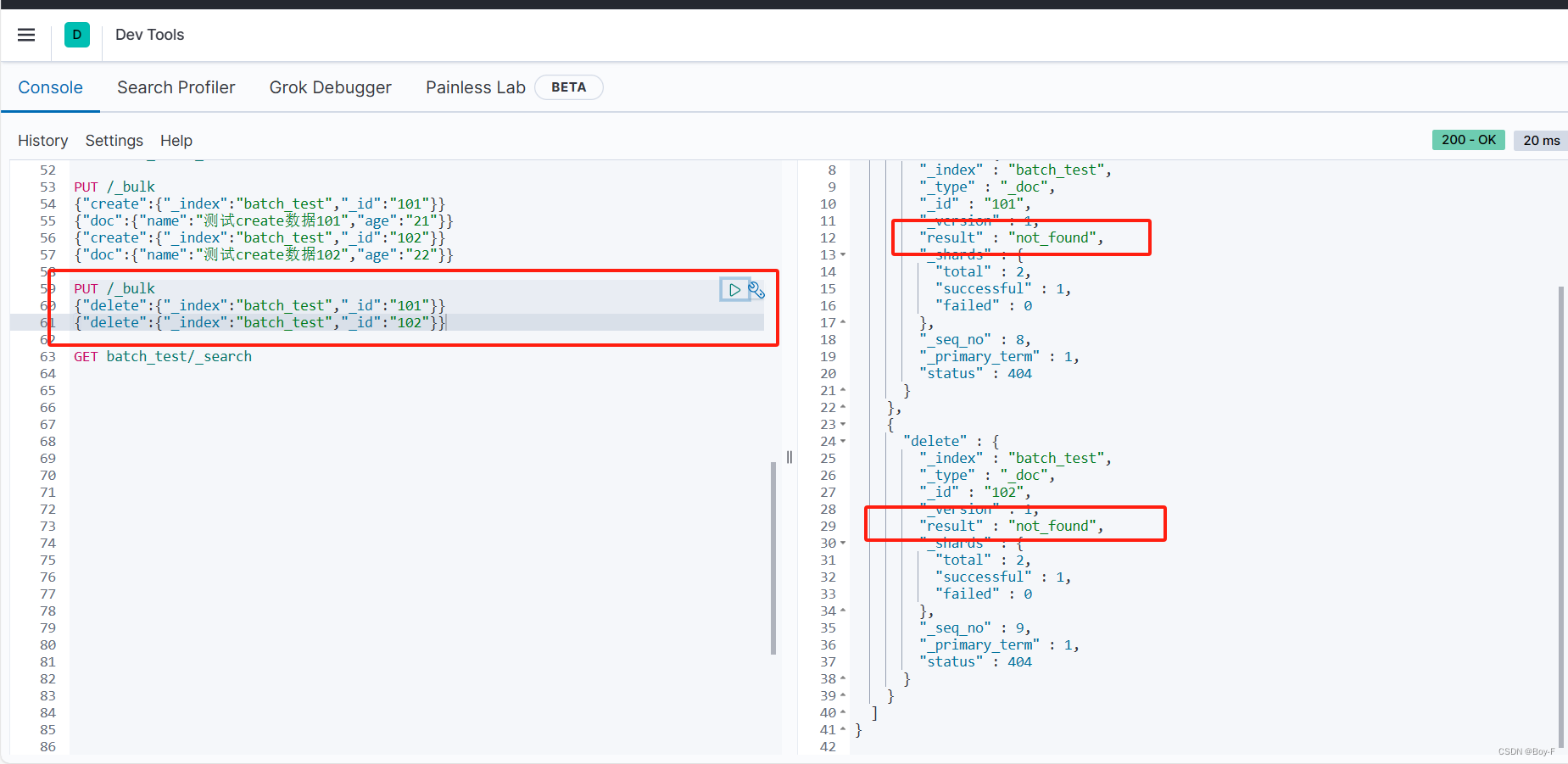
elasticsearch bulk 批量操作
1:bulk 是 elasticsearch 提供的一种批量增删改的操作API bulk 对 JSON串 有着严格的要求。每个JSON串 不能换行 ,只能放在同一行,同时, 相邻的JSON串之间必须要有换行 (Linux下是\n;Window下是\r\n&#…...

力扣11、 盛最多水的容器
方法一:双指针 考察: 贪心、数组、双指针 说明 本题是一道经典的面试题,最优的做法是使用「双指针」。如果读者第一次看到这题,不一定能想出双指针的做法。 复杂度分析 时间复杂度:O(N),双指针总计最多…...
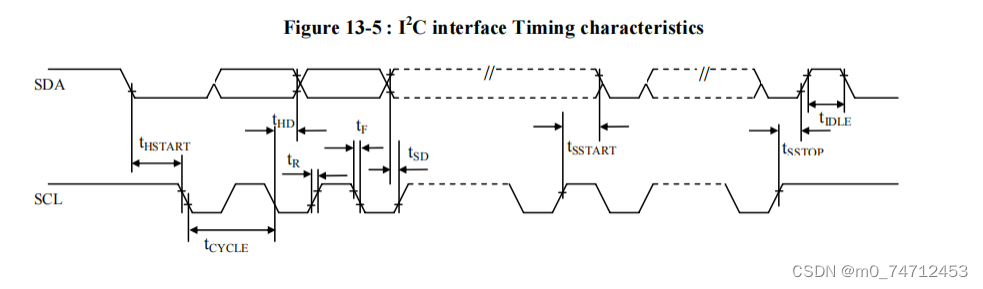
IIC协议详解
目录 1.IIC协议概述 2.IIC总线传输 3.IIC-51单片机应用 1.起始信号 2.终止信号 3.应答信号 4.数据发送 4.IIC-32单片机应用 用到的库函数: 1.IIC协议概述 IIC全称Inter-Integrated Circuit (集成电路总线)是由PHILIPS公司在80年代开发的两线式串行总线&…...

element ui-表头自定义提示框
版本 “element-ui”: “^2.15.5”,需求:鼠标悬浮到该列表头,显示提示框代码 <el-table:data"xxxx"><el-table-column label"序号" width"40" type"index" /><el-table-columnv-for"(ite…...

Python 图形化界面基础篇:创建顶部菜单
Python 图形化界面基础篇:创建顶部菜单 引言 Tkinter 库简介步骤1:导入 Tkinter 模块步骤2:创建 Tkinter 窗口步骤3:创建顶部菜单栏步骤4:处理菜单项的点击事件步骤5:启动 Tkinter 主事件循环 完整示例代码…...
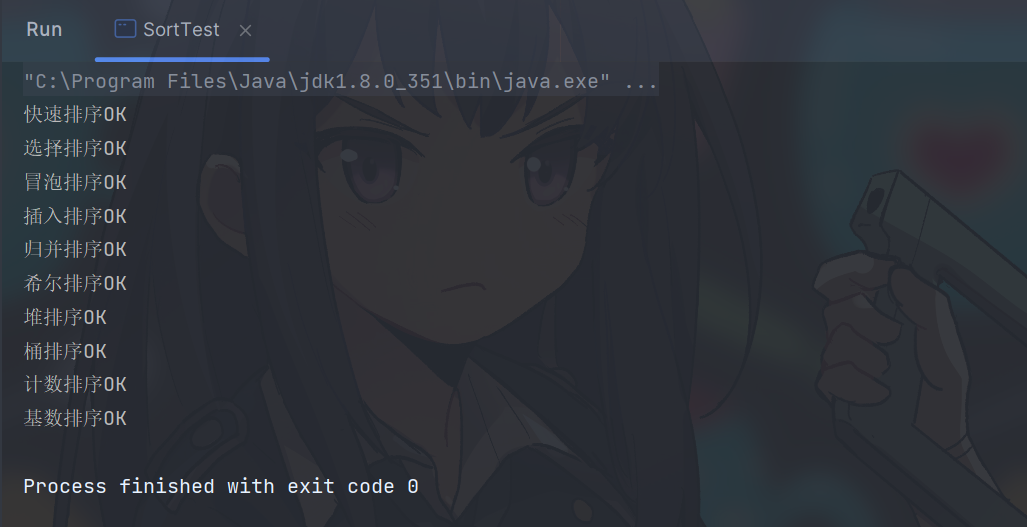
java实现十大排序算法
文章目录 冒泡排序选择排序插入排序希尔排序归并排序快速排序堆排序桶排序基数排序计数排序验证各个排序的时间复杂度和空间复杂度 冒泡排序 冒泡排序(Bubble Sort)是一种简单的比较排序算法,它的基本思想是重复地交换相邻的两个元素&#x…...
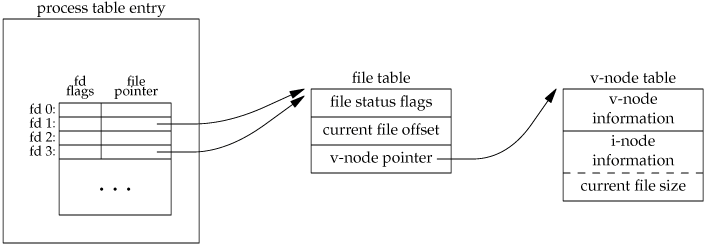
Linux日志管理-logrotate(crontab定时任务、Ceph日志转储)
文章目录 一、logrotate概述二、logrotate基本用法三、logrotate运行机制logrotate参数 四、logrotate是怎么做到滚动日志时不影响程序正常的日志输出呢?Linux文件操作机制方案一方案二 五、logrotate实战--Ceph日志转储参考 一、logrotate概述 logrotate是一个用于…...
用PHP异步协程控制python爬虫脚本,实现多协程分布式爬取
背景 公司需要爬取指定网站的产品数据。但是个人对python的多进程和协程不是特别熟悉。所以,想通过php异步协程,发起爬取url请求控制python爬虫脚本,达到分布式爬取的效果。 准备 1.准备一个mongodb数据库用于存放爬取数据2.引入flask包&a…...
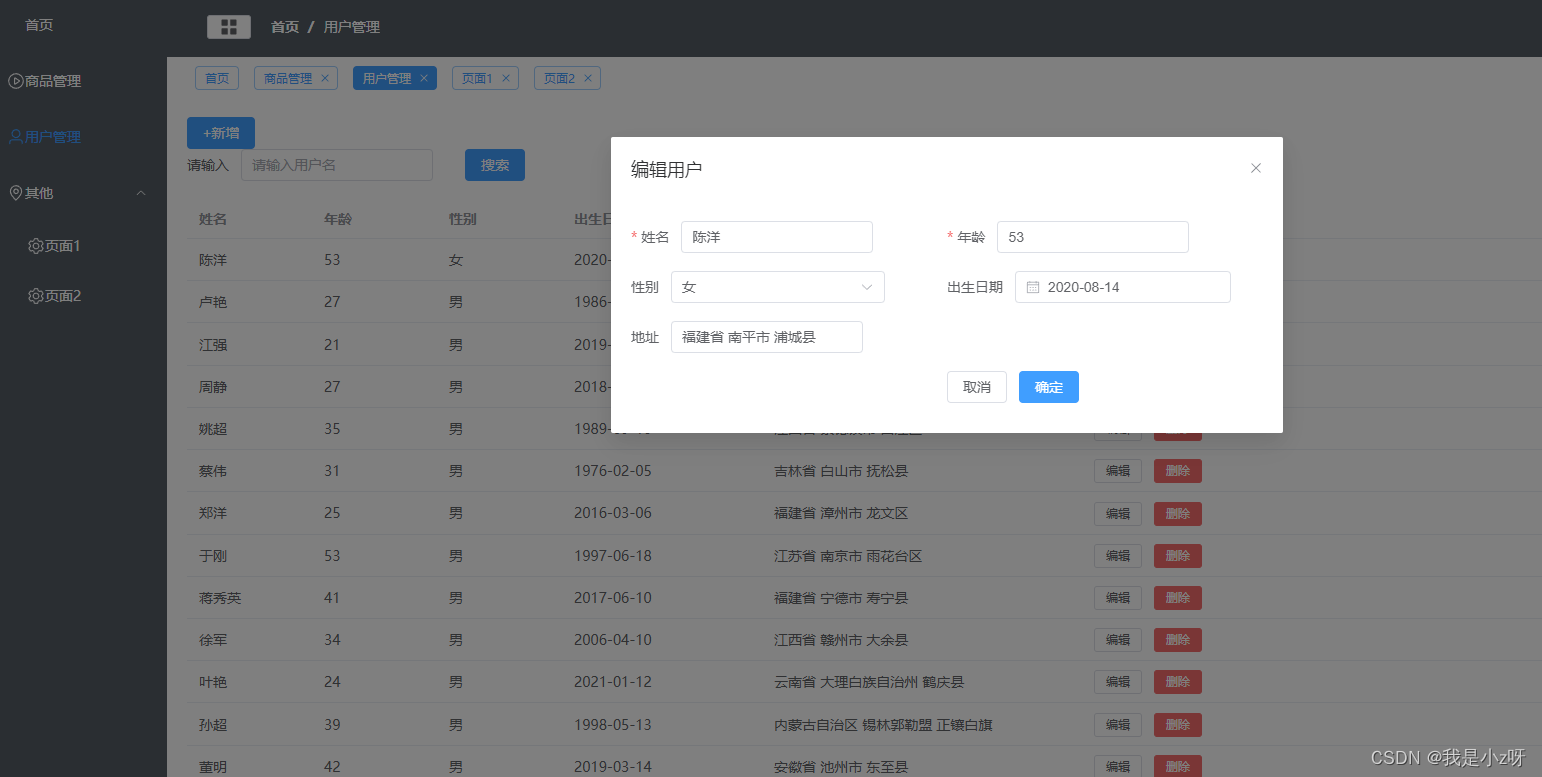
VUE3写后台管理(3)
VUE3写后台管理(3) 1.环境1.node2.vite3.Element-plus4.vue-router5.element icon6.less7.vuex8.vue-demi9.mockjs10.axios11.echarts 2.首页1.布局Main2.头部导航栏CommonHeader3.左侧菜单栏CommonLeft4.首页Home1.从后端获取数据显示到前端table的三种…...
无约束优化问题——共轭梯度法)
机器学习笔记之最优化理论与算法(十二)无约束优化问题——共轭梯度法
机器学习笔记之最优化理论与方法——共轭梯度法 引言回顾:共轭方向法的重要特征线性共轭梯度法共轭方向公式的证明过程 关于线搜索公式中参数的化简关于线搜索公式中步长部分的化简关于线搜索公式中共轭方向系数的化简参数化简的目的 非线性共轭梯度法(FR,PRP方法)关…...

JVM中的java同步互斥工具应用演示及设计分析
1.火车站售票系统仿真 某火车站目前正在出售火车票,共有50张票,而它有3个售票窗口同时售票,下面设计了一个程序模拟该火车站售票,通过实现Runnable接口实现(模拟网络延迟)。 伪代码: Ticket类…...

数据治理-数据质量
实现数据质量的前提就是数据本身是可靠和可信的。 导致数据质量低下的因素 组织缺乏对低质量数据影响的理解,缺乏规划、孤岛式系统设计、不一致的开发过程、不完整的文档、缺乏标准或缺乏治理等。 所有组织都会遇到与数据质量有关的问题。数据质量需要跨职能的承诺…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...