坦克世界WOT知识图谱三部曲之爬虫篇
文章目录
- 关于坦克世界
- 1. 爬虫任务
- 2. 获取坦克列表
- 3. 获取坦克具体信息
- 结束语
关于坦克世界
《坦克世界》(World of Tanks, WOT)是我在本科期间玩过的一款战争网游,由Wargaming公司研发。2010年10月30日在俄罗斯首发,2011年4月12日在北美和欧洲推出,2011年3月15日在中国由空中网代理推出(2020年,国服由360代理)。游戏背景设定在二战时期,玩家会扮演1930到1960年代的战车进行对战,要求战略和合作性,游戏中的战车根据历史高度还原。
坦克世界官网:https://wotgame.cn/
坦克世界坦克百科:https://wotgame.cn/zh-cn/tankopedia/#wot&w_m=tanks

1. 爬虫任务

当前的WOT有五种坦克类型,11个系别。我们要构建一个关于坦克百科的知识图谱,接下来就要通过爬虫来获取所有坦克的详细信息,比如坦克的等级、火力、机动性、防护能力、侦察能力等等。以当前的八级霸主中国重型坦克BZ-176为例,坦克的详细信息如下:


2. 获取坦克列表

常规操作,F12+F5查看一下页面信息,定位到坦克列表的具体请求:

是一个POST请求,返回的是一个JSON格式的数据,包含了该类型坦克的一些基本信息:

POST请求参数如下:

特别说明一下:构建该请求
header时,Content-Length参数是必须的。
代码实现:
# -*- coding: utf-8 -*-
# Author : xiayouran
# Email : youran.xia@foxmail.com
# Datetime: 2023/9/29 22:43
# Filename: spider_wot.py
import os
import time
import json
import requestsclass WOTSpider:def __init__(self):self.base_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/117.0.0.0 Safari/537.36','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9',}self.post_headers = {'Accept': 'application/json, text/javascript, */*; q=0.01','Content-Length': '135','Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'}self.from_data = {'filter[nation]': '','filter[type]': 'lightTank','filter[role]': '','filter[tier]': '','filter[language]': 'zh-cn','filter[premium]': '0,1'}self.tank_list_url = 'https://wotgame.cn/wotpbe/tankopedia/api/vehicles/by_filters/'self.tank_label = ['lightTank', 'mediumTank', 'heavyTank', 'AT-SPG', 'SPG']self.tanks = {}def parser_tanklist_html(self, html_text):json_data = json.loads(html_text)for data in json_data['data']['data']:self.tanks[data[0] + '_' + data[4]] = {'tank_nation': data[0],'tank_type': data[1],'tank_rank': data[3],'tank_name': data[4],'tank_name_s': data[5],'tank_url': data[6],'tank_id': data[7]}def run(self):for label in self.tank_label:self.from_data['filter[type]'] = labelhtml_text = self.get_html(self.tank_list_url, method='POST', from_data=self.from_data)if not html_text:print('[{}] error'.format(label))continueself.parser_tanklist_html(html_text)time.sleep(3)self.save_json(os.path.join(self.data_path, 'tank_list.json'), self.tanks)if __name__ == '__main__':tank_spider = WOTSpider()tank_spider.run()
上述代码只实现了一些重要的函数及变量声明,完整的代码可以从github上拉取:WOT
3. 获取坦克具体信息
坦克具体信息的页面就是一个纯HTML页面了,一个GET请求就可以获得。当然啦,具体怎么分析的就不细说了,对爬虫技术感兴趣的同学们可以找找资料,这里就只说一下抓取流程。
先分析GET请求:https://wotgame.cn/zh-cn/tankopedia/60209-Ch47_BZ_176/,可以分成三部分:
Part 1:基本的url请求:https://wotgame.cn/zh-cn/tankopedia;
Part 2:坦克的id:BZ-176坦克的id为60209,每个坦克都是唯一的,这个参数通过上一个步骤的POST请求可以获取到;
Part 3:坦克的名称:Ch47_BZ_176,这个参数也可以通过上一个步骤的POST请求可以获取到。
这样就可以为每个坦克构造一个对应的url了,只需解析该url对应的界面即可。解析的时候我分成了两部分,先对坦克的基本信息进行解析,比如坦克系别、等级及价格等等,由BeautifulSoup库实现,坦克的具体信息,比如火力、机动、防护及侦察能力,这些信息是由JavaScript代码动态请求得到的,这里为了简便没有分析具体的js代码,而是先使用selenium库进行网页渲染,然后再使用BeautifulSoup库进行解析。这里不再细说,下面给出页面解析的代码:
# -*- coding: utf-8 -*-
# Author : xiayouran
# Email : youran.xia@foxmail.com
# Datetime: 2023/9/29 22:43
# Filename: spider_wot.py
import requests
from tqdm import tqdm
from bs4 import BeautifulSoup, Tag
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWaitclass WOTSpider:def __init__(self):passdef is_span_with_value(self, driver):try:element = driver.find_element(By.XPATH, "//span[@data-bind=\"text: ttc().getFormattedBestParam('maxHealth', 'gt')\"]")data = element.text.strip()if data:return Trueexcept:return Falsedef get_html_driver(self, url):self.driver.get(url)self.wait.until(self.is_span_with_value)page_source = self.driver.page_sourcereturn page_sourcedef parser_tankinfo_html(self, html_text):tank_info = copy.deepcopy(self.tank_info)soup = BeautifulSoup(html_text, 'lxml')# tank_name = soup.find(name='h1', attrs={'class': 'garage_title garage_title__inline js-tank-title'}).strip()tank_statistic = soup.find_all(name='div', attrs={'class': 'tank-statistic_item'})for ts in tank_statistic:ts_text = [t for t in ts.get_text().split('\n') if t]if len(ts_text) == 5:tank_info['价格'] = {'银币': ts_text[-3],'经验': ts_text[-1]}else:tank_info[ts_text[0]] = ts_text[-1]tank_property1 = soup.find(name='p', attrs='garage_objection')tank_property2 = soup.find(name='p', attrs='garage_objection garage_objection__collector')if tank_property1:tank_info['性质'] = tank_property1.textelif tank_property2:tank_info['性质'] = tank_property2.textelse:tank_info['性质'] = '银币坦克'tank_desc_tag = soup.find(name='p', attrs='tank-description_notification')if tank_desc_tag:tank_info['历史背景'] = tank_desc_tag.texttank_parameter = soup.find_all(name='div', attrs={'class': 'specification_block'})for tp_tag in tank_parameter:param_text = tp_tag.find_next(name='h2', attrs={'class': 'specification_title specification_title__sub'}).get_text()# spec_param = tp_tag.find_all_next(name='div', attrs={'class': 'specification_item'})spec_param = [tag for tag in tp_tag.contents if isinstance(tag, Tag) and tag.attrs['class'] == ['specification_item']]spec_info = {}for tp in spec_param:tp_text = [t for t in tp.get_text().replace(' ', '').split('\n') if t]if not tp_text or not tp_text[0][0].isdigit():continuespec_info[tp_text[-1]] = ' '.join(tp_text[:-1])tank_info[param_text] = spec_inforeturn tank_infodef run(self):file_list = [os.path.basename(file)[:-5] for file in glob.glob(os.path.join(self.data_path, '*.json'))]for k, item in tqdm(self.tanks.items(), desc='Crawling'):file_name = k.replace('"', '').replace('“', '').replace('”', '').replace('/', '-').replace('\\', '').replace('*', '+')if file_name in file_list:continuetank_url = self.tank_url + str(item['tank_id']) + '-' + item['tank_url']html_text = self.get_html_driver(tank_url)# html_text = self.get_html(tank_url, method='GET')tank_info = self.parser_tankinfo_html(html_text)self.tanks[k].update(tank_info)self.save_json(os.path.join(self.data_path, '{}.json'.format(file_name)), self.tanks[k])time.sleep(1.5)self.save_json(os.path.join(self.data_path, 'tank_list_detail.json'), self.tanks)if __name__ == '__main__':tank_spider = WOTSpider()tank_spider.run()
大约半个小时即可获取全部的坦克信息,如下:

Selenium库依赖chromedriver,需要根据自己的Chrome浏览器版本下载合适的版本,chromedriver的官方下载地址为:https://chromedriver.chromium.org/downloads/version-selection
结束语
本篇的完整代码及爬取的结果已经同步到仓库中,感兴趣的话可以拉取一下,下一篇文章就基于当前获取到的坦克信息来构造一个关于坦克百科的知识图谱。
开源代码仓库
如果喜欢的话记得给我的GitHub仓库WOT点个Star哦!ヾ(≧∇≦*)ヾ
公众号已开通:
夏小悠,关注以获取更多关于Python文章、AI领域最新技术、LLM大模型相关论文及内部PPT等资料^_^
相关文章:
坦克世界WOT知识图谱三部曲之爬虫篇
文章目录 关于坦克世界1. 爬虫任务2. 获取坦克列表3. 获取坦克具体信息结束语 关于坦克世界 《坦克世界》(World of Tanks, WOT)是我在本科期间玩过的一款战争网游,由Wargaming公司研发。2010年10月30日在俄罗斯首发,2011年4月12日在北美和欧洲推出&…...
Idea上传项目到gitlab并创建使用分支
Idea上传项目到gitlab并创建使用分支 1 配置git 在idea的setting中,找到git,配置好git的位置,点击Test按钮显示出git版本号,则说明配置成功。 2 项目中引入git Idea通过VCS,选择Create Git Repository 在弹出的对话框…...
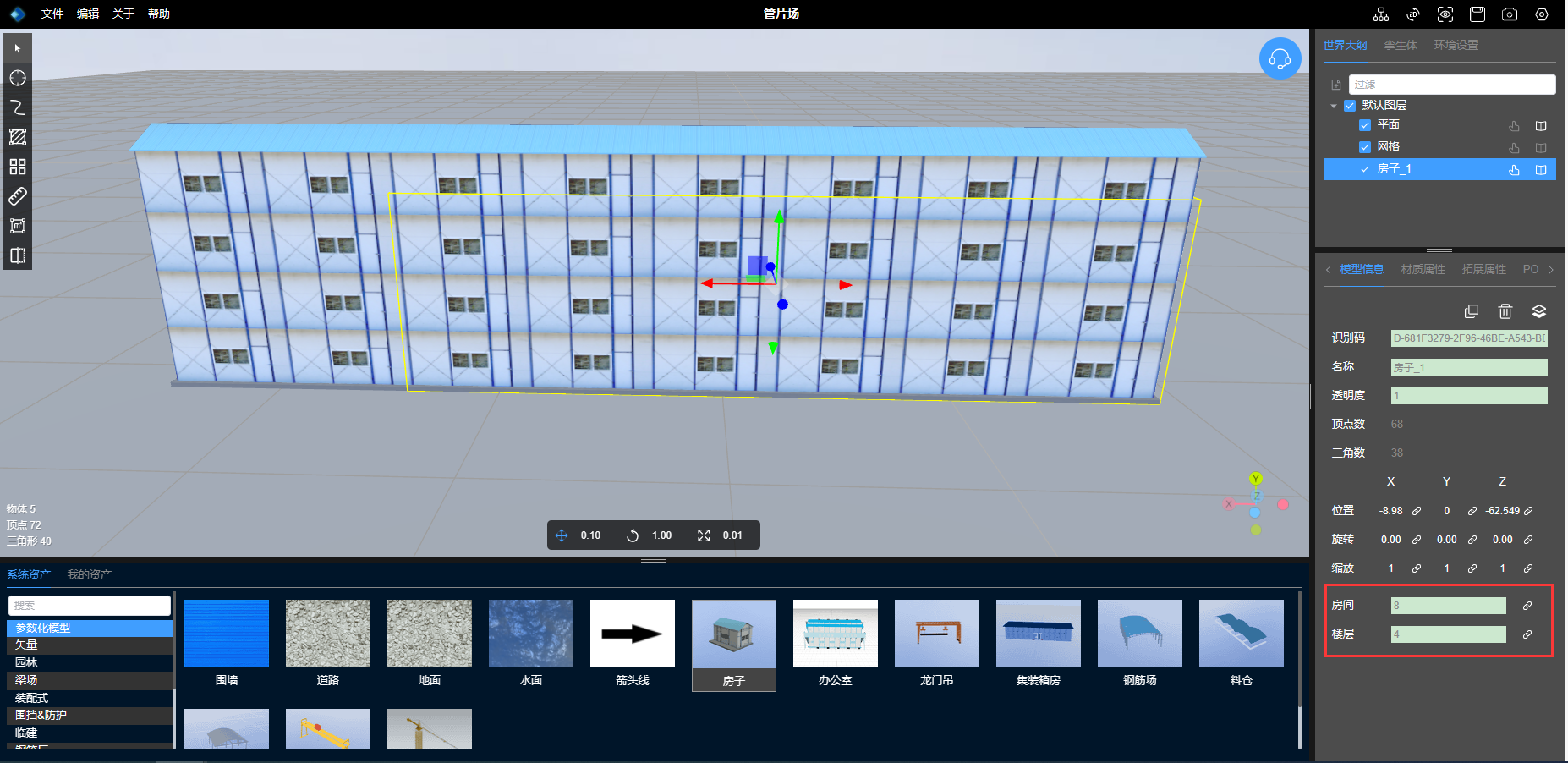
3D孪生场景搭建:参数化模型
1、什么是参数化模型 参数化模型是指通过一组参数来定义其形状和特征的数学模型或几何模型。这些参数可以用于控制模型的大小、形状、比例、位置、旋转、曲率等属性,从而实现对模型进行灵活的调整和变形。 在计算机图形学和三维建模领域,常见的参数化模…...

最短路径专题6 最短路径-多路径
题目: 样例: 输入 4 5 0 2 0 1 2 0 2 5 0 3 1 1 2 1 3 2 2 输出 2 0->1->2 0->3->2 思路: 根据题意,最短路模板还是少不了的, 我们要添加的是, 记录各个结点有多少个上一个结点走动得来的…...

【Linux】Linux常用命令—文件管理(上)
创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 🔥c系列专栏:C/C零基础到精通 🔥 给大…...

【Python】基于OpenCV人脸追踪、手势识别控制的求生之路FPS游戏操作
【Python】基于OpenCV人脸追踪、手势识别控制的求生之路FPS游戏操作 文章目录 手势识别人脸追踪键盘控制整体代码附录:列表的赋值类型和py打包列表赋值BUG复现代码改进优化总结 py打包 视频: 基于OpenCV人脸追踪、手势识别控制的求实之路FPS游戏操作 手…...
约束优化算法(optimtool.constrain)
import optimtool as oo from optimtool.base import np, sp, pltpip install optimtool>2.4.2约束优化算法(optimtool.constrain) import optimtool.constrain as oc oc.[方法名].[函数名]([目标函数], [参数表], [等式约束表], [不等式约数表], [初…...
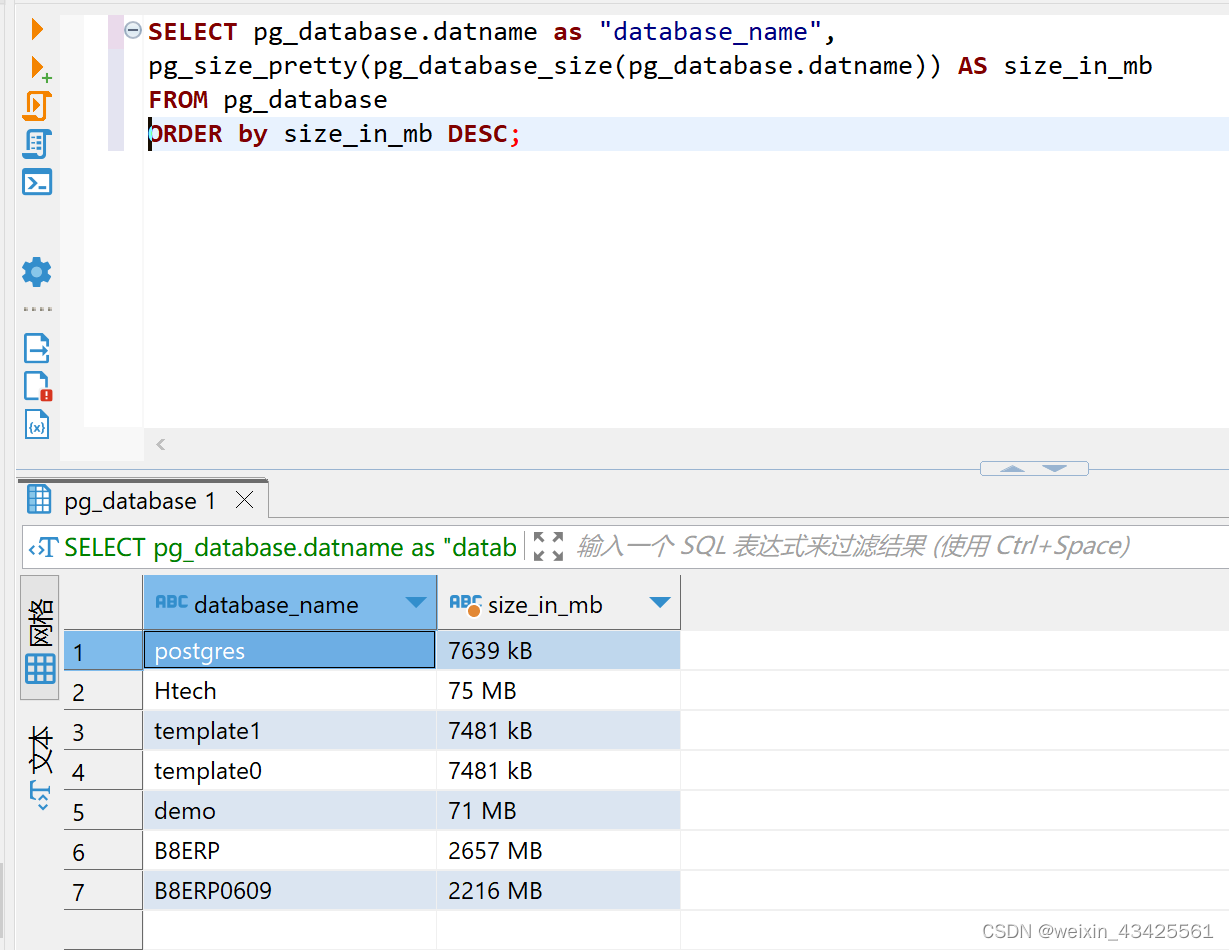
如何查看postgresql中的数据库大小?
你可以使用以下命令来查看PostgreSQL数据库的大小: SELECT pg_database.datname as "database_name", pg_size_pretty(pg_database_size(pg_database.datname)) AS size_in_mb FROM pg_database ORDER by size_in_mb DESC;这将返回一个表格࿰…...

使用python-opencv检测图片中的人像
最简单的方法进行图片中的人像检测 使用python-opencv配合yolov3模型进行图片中的人像检测 1、安装python-opencv、numpy pip install opencv-python pip install numpy 2、下载yolo模型文件和配置文件: 下载地址: https://download.csdn.net/down…...

项目进展(三)-电机驱动起来了,发现了很多关键点,也遇到了一些低级错误,
一、前言 昨天电机没有驱动起来,头发掉一堆,不过今天,终于终于终于把电机驱动起来了!!!!,特别开心,哈哈哈哈,后续继续努力完善!!&…...
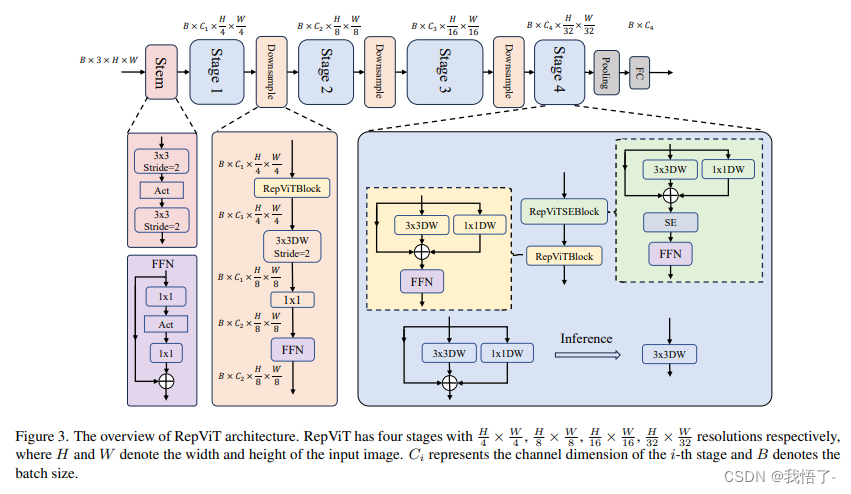
目标检测算法改进系列之Backbone替换为RepViT
RepViT简介 轻量级模型研究一直是计算机视觉任务中的一个焦点,其目标是在降低计算成本的同时达到优秀的性能。轻量级模型与资源受限的移动设备尤其相关,使得视觉模型的边缘部署成为可能。在过去十年中,研究人员主要关注轻量级卷积神经网络&a…...

学习 Kubernetes的难点和安排
Kubernetes 技术栈的特点可以用四个字来概括,那就是“新、广、杂、深”: 1.“新”是指 Kubernetes 用到的基本上都是比较前沿、陌生的技术,而且版本升级很快,经常变来变去。 2.“广”是指 Kubernetes 涉及的应用领域很多、覆盖面非…...

【MATLAB源码-第42期】基于matlab的人民币面额识别系统(GUI)。
操作环境: MATLAB 2022a 1、算法描述 基于 MATLAB 的人民币面额识别系统设计可以分为以下步骤: 1. 数据收集与预处理 数据收集: 收集不同面额的人民币照片,如 1 元、5 元、10 元、20 元、50 元和 100 元。确保在不同环境、不…...
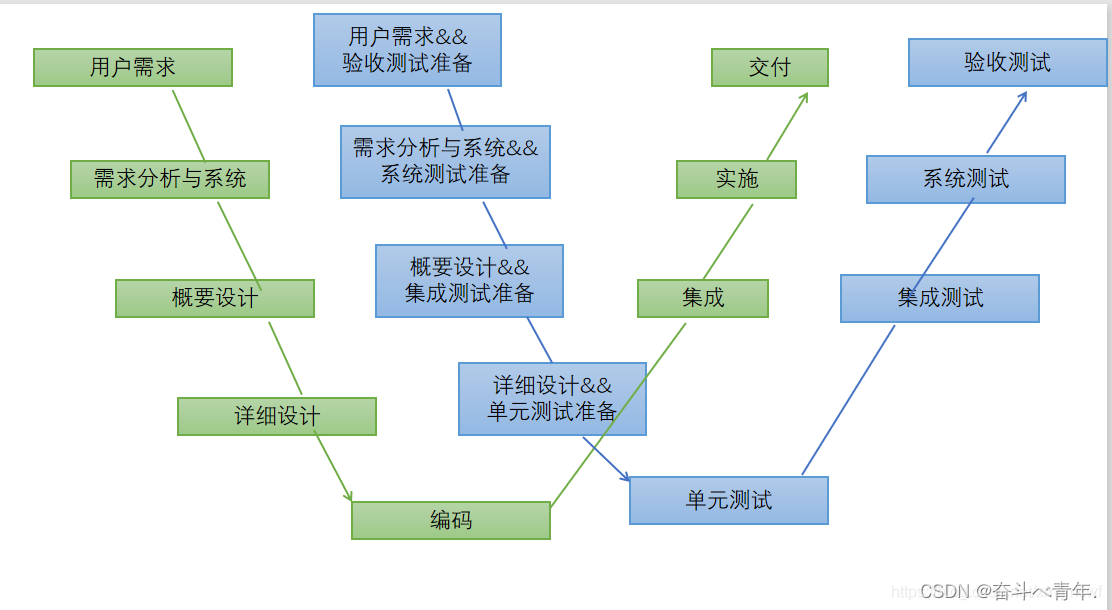
【软件测试】软件测试的基础概念
一、一个优秀的测试人员需要具备的素质 技能方面: 优秀的测试用例设计能力:测试用例设计能力是指,无论对于什么类型的测试,都能够设计出高效的发现缺陷,保证产品质量的优秀测试用例。这就需要我们掌握设计测试用例的方…...
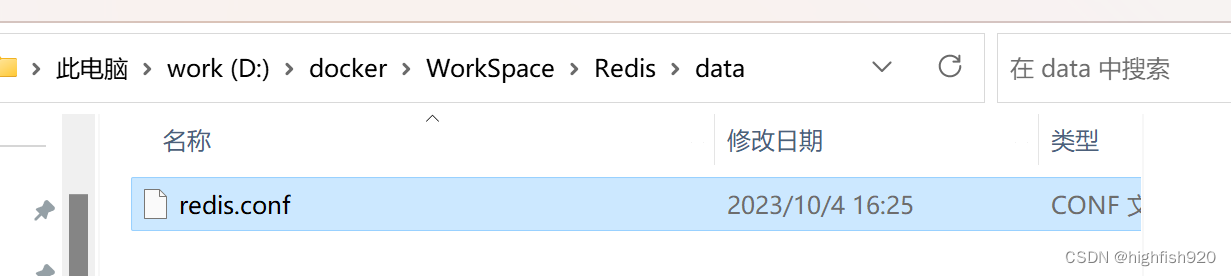
Docker-mysql,redis安装
安装MySQL 下载MySQL镜像 终端运行命令 docker pull mysql:8.0.29镜像下载完成后,需要配置持久化数据到本地 这是mysql的配置文件和存储数据用的目录 切换到终端,输入命令,第一次启动MySQL容器 docker run --restartalways --name mysq…...

五种I/O模型
目录 1、阻塞IO模型2、非阻塞IO模型3、IO多路复用模型4、信号驱动IO模型5、异步IO模型总结 blockingIO - 阻塞IOnonblockingIO - 非阻塞IOIOmultiplexing - IO多路复用signaldrivenIO - 信号驱动IOasynchronousIO - 异步IO 5种模型的前4种模型为同步IO,只有异步IO模…...

用nativescript开发ios程序常用命令?
NativeScript是一个用于跨平台移动应用程序开发的开源框架,允许您使用JavaScript或TypeScript构建原生iOS和Android应用程序。以下是一些常用的NativeScript命令,用于开发iOS应用程序: 1、创建新NativeScript项目: tns create m…...
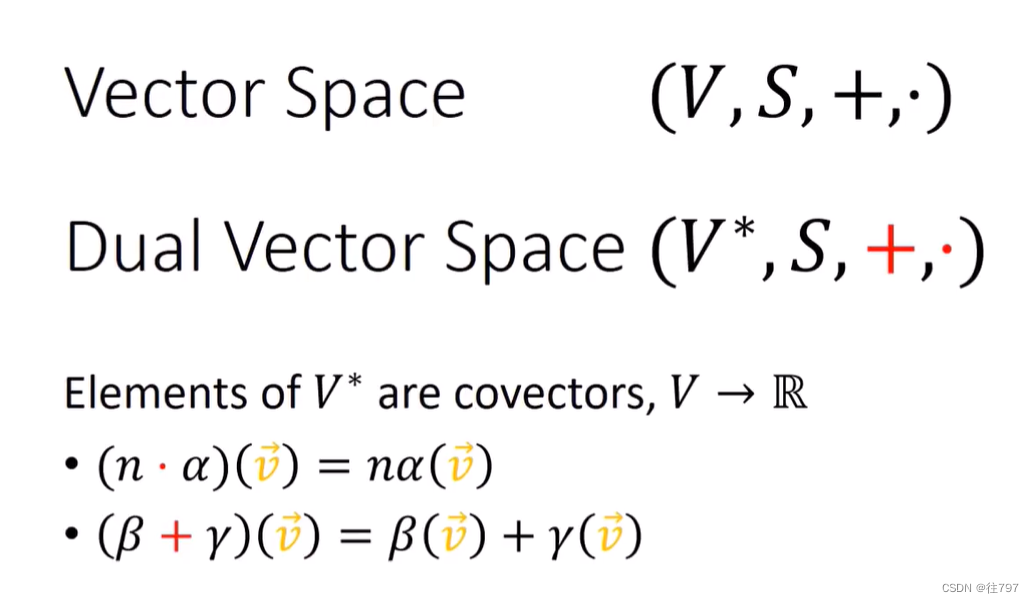
6.Tensors For Beginners-What are Convector
Covectors (协向量) What‘s a covector Covectors are “basically” Row Vectors 在一定程度上,可认为 协向量 基本上就像 行向量。 但不能简单地认为 这就是列向量进行转置! 行向量 和 列向量 是根本不同类型的对象。 …...
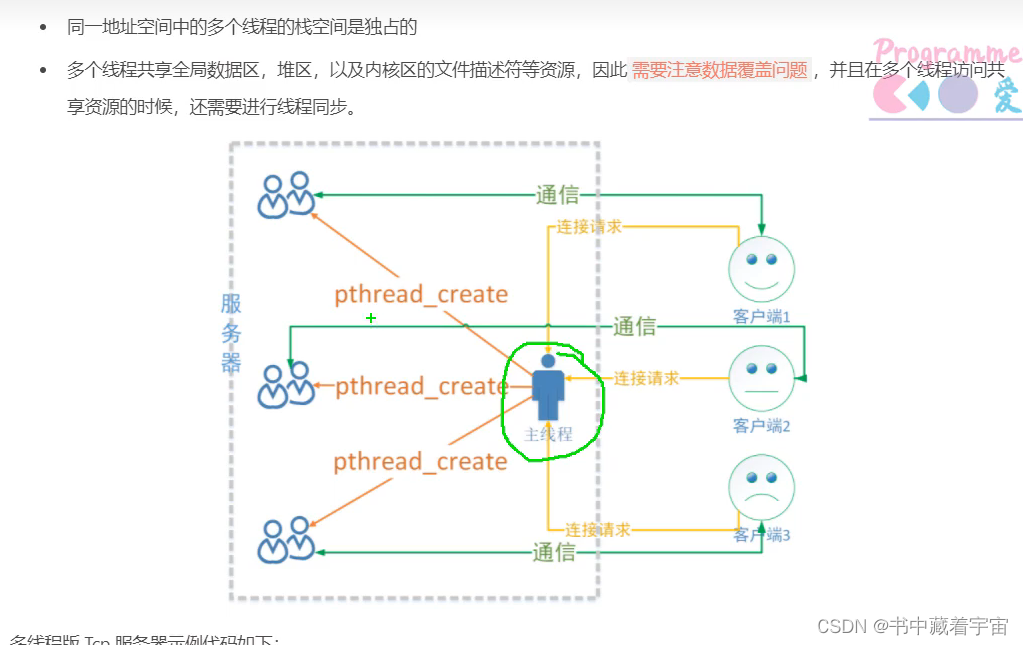
Linux多线程网络通信
思路:主线程(只有一个)建立连接,就创建子线程。子线程开始通信。 共享资源:全局数据区,堆区,内核区描述符。 线程同步不同步需要取决于线程对共享资源区的数据的操作,如果是只读就不…...

矩阵的c++实现(2)
上一次我们了解了矩阵的运算和如何使用矩阵解决斐波那契数列,这一次我们多看看例题,了解什么情况下用矩阵比较合适。 先看例题 1.洛谷P1939 【模板】矩阵加速(数列) 模板题应该很简单。 补:1<n<10^9 10^9肯定…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...
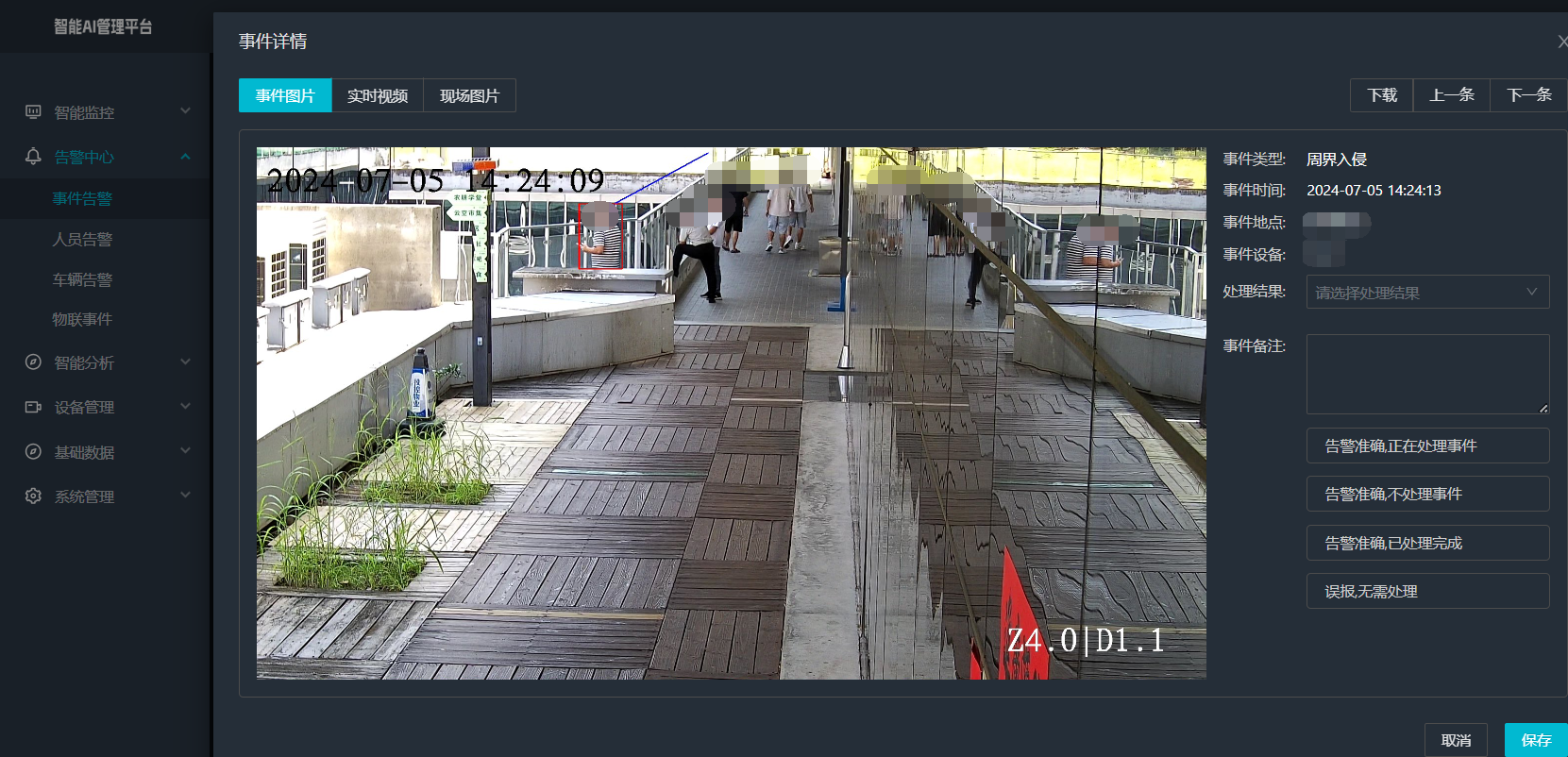
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...