Python3数据科学包系列(一):数据分析实战

Python3中类的高级语法及实战
Python3(基础|高级)语法实战(|多线程|多进程|线程池|进程池技术)|多线程安全问题解决方案
Python3数据科学包系列(一):数据分析实战
Python3数据科学包系列(二):数据分析实战
认识下数据科学中数据处理基础包:
(1)NumPy
俗话说: 要学会跑需先学会走
(1)数据分析基础认知:NumPy是,Numerical Python的简称,它是目前Python数值计算中最为重要的基础包,大多数计算包提供了基于NumPy的科学函数功能;将NumPy的数值对象作为数据交换的通用语
NumPy通常用于处理如下场景数据的处理:ndarray,是一种高效多维数组,提供了基于数组的便捷算术操作以及灵活的广播功能;对所有数据进行快速的计算,而无需编写循环程序对硬盘数据进行读写的工具,并对内存映射文件进行操作线性代数,随机数生成以及傅里叶变换功能用于连接NumPy到C,C++代码库封装,并为这些代码提供动态,易用的接口
在大数据领域,通常更关注的内容如下 :在数据处理,数据清洗,构造子集,过滤,变换以及其他计算中进行快速的向量化计算常见的数组算法,比如sort,unique以及set操作高效的描述性统计和聚合,概述数据数据排序和相关数据操作,例如对异构数据进行merge和join使用数组表达式来表明条件逻辑,代替if-elif-else条件分支的循环分组数据的操作(聚合,变换,函数式操作)
(2)NumPy两大亮点NumPy在内部将数据存储在连续的内存地址上,这与其他的Python内建数据结构时不同的。NumPy的算法库时C语言编写的,所以在操作数据内存时,不需要任何类型检查或者其他管理操作。NumPy数据使用的内存量也小于其他Python内建序列。NumPy可以针对全量数值进行复杂计算而不需要编写Python循环
一: 数据分析高级语法:序列(Series)
# -*- coding:utf-8 -*- from pandas import Series import pandas as pdprint('-------------------------------------序列Series定义与取值-------------------------------------------') print("""Series序列可以省略,此时索引号默认从0开始;索引可以使指定的字母,或者字符串Series序列也可以任务是一维列表""") X = pd.Series(["a", 2, "螃蟹"], index=[1, 2, 3]) print("Series数据类型: ", type(X)) print() print(X) print() A = pd.Series([1, 2, 3, 22, 140, 23, 123, 2132131, 232222222222]) print(A) print() print("序列A的第二个值: ", A[1]) print() B = pd.Series([11, 23, 33, 44, 55, 56], index=['A', 'B', 'C', 'D', 'E', 'F']) print() print("序列B: ") print(B) print() print(B.__dict__.keys())print('访问序列的A的值:', B['A']) print('访问序列的B的值:', B['B'])print('-------------------------------------------------------------------------------------------------')print()AA = pd.Series([14, 24, 53, 33], index=['First', 'Second', 'Three', 'Four']) print("序列AA") print(AA) print() print("序列AA['Second']的取值: ", AA['Second']) print("序列AA[1]的取值: ", AA[1]) print() try:print(AA[5]) except IndexError as err:print("序列AA索引越界异常: ", err)N = pd.Series([2], index=['Hello']) # 给序列追加单个元素,会报错;但可用追加序列 # AA.append(N) try:pd.concat(N) except TypeError as err:print("序列AA追加单个元素异常: ", err)x = ['上海', '北京', '深圳', '广州', '重庆'] y = ['上海', '北京', '深圳', '广州', '天津'] z = ['天津', '苏州', '成都', '武汉', '杭州'] gdp1 = pd.Series([32679, 30320, 24691, 23000, 20363], index=x) gdp2 = pd.Series([30133, 28000, 22286, 21500, 18595], index=y) gdp3 = pd.Series([18809, 18597, 15342, 14847, 13500], index=z) result = [gdp1, gdp3] gdp4 = pd.concat(result) print(gdp4)
运行效果:
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\dataanalysis\DataAnalysisExecutorSerias.py
俗话说: 要学会跑需先学会走
(1)数据分析基础认知:
NumPy是,Numerical Python的简称,它是目前Python数值计算中最为重要的基础包,大多数计算包提供了基于NumPy的科学函数功能;
将NumPy的数值对象作为数据交换的通用语
NumPy通常用于处理如下场景数据的处理:
ndarray,是一种高效多维数组,提供了基于数组的便捷算术操作以及灵活的广播功能;
对所有数据进行快速的计算,而无需编写循环程序
对硬盘数据进行读写的工具,并对内存映射文件进行操作
线性代数,随机数生成以及傅里叶变换功能
用于连接NumPy到C,C++代码库封装,并为这些代码提供动态,易用的接口
在大数据领域,通常更关注的内容如下 :
在数据处理,数据清洗,构造子集,过滤,变换以及其他计算中进行快速的向量化计算
常见的数组算法,比如sort,unique以及set操作
高效的描述性统计和聚合,概述数据
数据排序和相关数据操作,例如对异构数据进行merge和join
使用数组表达式来表明条件逻辑,代替if-elif-else条件分支的循环
分组数据的操作(聚合,变换,函数式操作)
(2)NumPy两大亮点
NumPy在内部将数据存储在连续的内存地址上,这与其他的Python内建数据结构时不同的。
NumPy的算法库时C语言编写的,所以在操作数据内存时,不需要任何类型检查或者其他管理操作。
NumPy数据使用的内存量也小于其他Python内建序列。
NumPy可以针对全量数值进行复杂计算而不需要编写Python循环
-------------------------------------序列Series定义与取值-------------------------------------------
Series序列可以省略,此时索引号默认从0开始;
索引可以使指定的字母,或者字符串
Series序列也可以任务是一维列表
Series数据类型: <class 'pandas.core.series.Series'>1 a
2 2
3 螃蟹
dtype: object0 1
1 2
2 3
3 22
4 140
5 23
6 123
7 2132131
8 232222222222
dtype: int64序列A的第二个值: 2
序列B:
A 11
B 23
C 33
D 44
E 55
F 56
dtype: int64dict_keys(['_is_copy', '_mgr', '_item_cache', '_attrs', '_flags', '_name'])
访问序列的A的值: 11
访问序列的B的值: 23
-------------------------------------------------------------------------------------------------序列AA
First 14
Second 24
Three 53
Four 33
dtype: int64序列AA['Second']的取值: 24
序列AA[1]的取值: 24序列AA索引越界异常: index 5 is out of bounds for axis 0 with size 4
序列AA追加单个元素异常: first argument must be an iterable of pandas objects, you passed an object of type "Series"
上海 32679
北京 30320
深圳 24691
广州 23000
重庆 20363
天津 18809
苏州 18597
成都 15342
武汉 14847
杭州 13500
dtype: int64Process finished with exit code 0
二:NumPy包的多维数组对象
首先来看看使用NumPy生成一千万个数据与list列表生成同样多数据耗时情况
# -*- coding:utf-8 -*-import numpy as np import time import datetime# 获取当前时间 current_time = datetime.datetime.now() # 格式化输出带有毫秒的当前时间字符串 start_current_time_str = current_time.strftime("%Y-%m-%d %H:%M:%S.%f")[:-3] print(start_current_time_str) my_arr = np.arange(10000000) print("NumPy生成一千万数据: ", my_arr) # 获取当前时间 current_time = datetime.datetime.now() # 格式化输出带有毫秒的当前时间字符串 end_current_time_str = current_time.strftime("%Y-%m-%d %H:%M:%S.%f")[:-3] print(end_current_time_str)start_time = time.time() my_list = list(range(10000000)) # print("生成一千万个数据: ", my_list) end_time = time.time() print("列表生成1千万个数据耗时: %d 秒" % (end_time - start_time)) print() print("""NumPy核心特质之一就是N-维数值对象---ndarray;ndarray是Python中一个快速灵活的大型数据集容器。数值允许你使用类似于标量的操作语法在整块数据上进行数学计算 """)data = np.random.randn(2, 3) print("data二维数组: ", data)dataArray = data * 2 print("dataArray计算结果: ", dataArray)andData = data + data print("两个二维data数组相加: ", andData)print("""一个ndarray时一个通用的多维同步数据容器,也就是说,它包含的每一个元素均为相同的数据类型。每一个数组都有一个shape属性,用来表征数组每一维度的数量,每一个数组都有一个dtype属性,用来描述数组的数据类型 """) print() print(data.shape)print(data.dtype)print("生成ndarray对象: 通常使用array函数,函数接收任意的序列型对象,当然也包括其他数组;生成一个新的包含传递数据的NumPy数组")data1 = [7, 2.5, 4, 44, 5, 0.1, 3354] arrayData = np.array(data1) print("arrayData: ", type(arrayData)) print(arrayData.dtype)data2 = [[1, 2, 3, 4, 5], [7, 8, 9, 10, 11]] array2 = np.array(data2) print(array2) print(array2.ndim) print(array2.shape) print(array2.dtype)print("""给定长度和形状后,zeros函数会生成全部包含0的数组 """) zeroArray = np.zeros(10) print() print(zeroArray)zeroArray1 = np.zeros((3, 6)) print(zeroArray1) print('--------------------------------------------') zeroArray2 = np.empty((2, 3, 2)) print(zeroArray2)rangeArray = np.arange(15) print(rangeArray) print(type(rangeArray))print("""ndarray的数据类型 """) array001 = np.array([1, 2, 3], dtype=np.float64) array002 = np.array([1, 2, 3], dtype=np.int32)print(array001.dtype) print(array002.dtype)print("""NumPy数组算术运算 """) arr = np.array([[1., 2., 3.], [4., 5., 6.]]) print(arr) print() arr1 = arr * arr print(arr1) print() arr2 = arr - arr print(arr2) print() arr3 = arr + arr print(arr3)arr4 = 1 / arr print() print(arr4) print() arr5 = arr ** 0.5print(arr5)print()arr22 = np.array([[0., 4., 1.], [7., 2., 12.]]) print(arr22)arr33 = arr22 > arr print() print(arr33)
运行效果: NumPy比list列表块近1000倍
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\dataanalysis\DataAnalysisExecutorNumPy.py
2023-10-01 13:18:17.923
NumPy生成一千万数据: [ 0 1 2 ... 9999997 9999998 9999999]
2023-10-01 13:18:17.939
.(939-923)=16 毫秒.
.
.
列表生成1千万个数据耗时: 3 秒
NumPy核心特质之一就是N-维数值对象---ndarray;
ndarray是Python中一个快速灵活的大型数据集容器。数值允许你使用类似于标量的操作语法在整块数据上进行数学计算data二维数组: [[ 0.60773878 -0.67998347 -1.13246668]
[-0.50485897 -1.38068128 -0.09343696]]
dataArray计算结果: [[ 1.21547755 -1.35996695 -2.26493337]
[-1.00971795 -2.76136255 -0.18687392]]
两个二维data数组相加: [[ 1.21547755 -1.35996695 -2.26493337]
[-1.00971795 -2.76136255 -0.18687392]]一个ndarray时一个通用的多维同步数据容器,也就是说,它包含的每一个元素均为
相同的数据类型。每一个数组都有一个shape属性,用来表征数组每一维度的数量,每一个数组都有一个
dtype属性,用来描述数组的数据类型
(2, 3)
float64
生成ndarray对象: 通常使用array函数,函数接收任意的序列型对象,当然也包括其他数组;生成一个新的包含传递数据的NumPy数组
arrayData: <class 'numpy.ndarray'>
float64
[[ 1 2 3 4 5]
[ 7 8 9 10 11]]
2
(2, 5)
int32给定长度和形状后,zeros函数会生成全部包含0的数组
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]]
--------------------------------------------
[[[6.23042070e-307 1.42417221e-306]
[1.60219306e-306 9.79097008e-307]
[6.89807188e-307 1.20161730e-306]][[7.56587585e-307 1.37961302e-306]
[6.23053614e-307 6.23053954e-307]
[1.37961302e-306 1.42410974e-306]]]
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
<class 'numpy.ndarray'>ndarray的数据类型
float64
int32NumPy数组算术运算
[[1. 2. 3.]
[4. 5. 6.]][[ 1. 4. 9.]
[16. 25. 36.]][[0. 0. 0.]
[0. 0. 0.]][[ 2. 4. 6.]
[ 8. 10. 12.]][[1. 0.5 0.33333333]
[0.25 0.2 0.16666667]][[1. 1.41421356 1.73205081]
[2. 2.23606798 2.44948974]][[ 0. 4. 1.]
[ 7. 2. 12.]][[False True False]
[ True False True]]Process finished with exit code 0
三: 数据分析高级语法: 数据框(DataFrame)
DataFrame表示的是矩阵数据表,它包含已经排序的集合;每一列可以是不同的值类型(数值,字符串,布尔值等)DataFrame既有行索引和列索引,它被视为一个共享相同索引的Series的字典,可以看作是序列Series的容器;在DataFrame中,数据被存储为一个以上的二维块,而不是列表,字典或者其他一维数值的集合;
可以使用分层索引在DataFrame中展示更高维度的数据
# -*- coding:utf-8 -*-import pandas as pdprint("""DataFrame表示的是矩阵数据表,它包含已经排序的集合;每一列可以是不同的值类型(数值,字符串,布尔值等)DataFrame既有行索引和列索引,它被视为一个共享相同索引的Series的字典,可以看作是序列Series的容器;在DataFrame中,数据被存储为一个以上的二维块,而不是列表,字典或者其他一维数值的集合;可以使用分层索引在DataFrame中展示更高维度的数据 """) data = {'state': ['python', 'java', 'C', 'C++', 'C#', 'go'],'year': [2000, 2001, 2003, 2004, 2005, 2006],'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}frame = pd.DataFrame(data) print("frame: ", frame)print("默认展示前5行: ", frame.head()) print("当然可以指定展示几行: ", frame.head(2))print("指定排序顺序,DataFrame的列将会按照指定的顺序排序:") sortFrame = pd.DataFrame(data, columns=['year', 'state', 'pop']) print("sortFrame: ", sortFrame) print("如果指定排序的类不存在,此时的数据结构如下: ")sortNotNullFrame = pd.DataFrame(data, columns=['year', 'state', 'popt'])print() print("指定排序顺序的二维数据结构: ", sortNotNullFrame)print("""DataFrame中的一列,可以按照字典标记或属性那样检索为Series序列 """)frameData = pd.DataFrame(data, columns=['year', 'state', 'pop']) frameSeries = frameData['state'] print("frameSeries: ", frameSeries) frameSeries = frameData['year'] print("frameSeries: ", frameSeries)data = pd.DataFrame(np.random.randn(1000, 4)) print("data: ", data.describe())print("""DataFrame数据框是用于存储多行多列的数据集合,是Series;类似于Excel二维表格,对应DataFrame的操作无外乎"增,删,改,查" """) dataFrameSeries = pd.DataFrame({'age': Series([26, 29, 24]), 'name': Series(['Ken', 'Jerry', 'Ben'])}) print("dataFrameSeries: ", dataFrameSeries) print() A = dataFrameSeries['age'] print(A) print() print("""获取索引号是第一行的值(其实是第二行,从0开始) """) B = dataFrameSeries[1:2] print(B) print("-------------------------------------------------------") print("""获取第0行到第二行(不包括)与第0列到第2列(不包括2行)的数据块 """) C = dataFrameSeries.iloc[0:2, 0:2] print(C) print() D = dataFrameSeries.at[0, 'name'] # 获取第0行与name列的交叉值 print(D) print() print("""访问某一行的时候,不能仅用行的index来访问,如要访问dataFrameSeries的index = 1的行,不能写成dataFrameSeries[1],而要写成dataFrameSeries[1:2] ; DataFrame的index可以使任意的,不会像Series那样报错,但会显示"Empty DataFrame",并列出Columns:[列名],执行下面的代码看看结果 """) dataFrameDo = pd.DataFrame(data={'age': [26, 29, 24], 'name': ['KEN', 'John', 'JIMI']},index=['first', 'second', 'third'])# 访问行 0-99行 varData = dataFrameDo[1:100] print(varData)print() print(varData[2:2]) # 显示空 print() print(varData[2:1]) # 显示空print('----------------------------------------------------------------') print() print("访问列") print(varData['age']) # 按照列名访问 print() print(varData[varData.columns[0:1]]) # 按索引号访问 print() print("访问数据块") print(varData.iloc[0:1, 0:1]) # 按行列索引访问print('---------------------------------------------------------------') # 访问位置 print(dataFrameSeries.at[1, 'name']) # 这里的1是索引 print(varData.at['second', 'name']) try:print(varData.at[1, 'name']) except KeyError as err:print("如果这里用索引号就会报错,当有索引名时,不能用索引号,异常信息: ", err)print() print("修改列名") dataFrameSeries.columns = ['name1', 'name2'] print(dataFrameSeries[0:1]) print("修改行的索引") dataFrameSeries.index = range(1, 4) print(dataFrameSeries)print("根据行索引删除") dataFrameSeries.drop(1, axis=0) # axis =0 是表示行轴,也可以省略 print("根据列名进行删除") dataFrameSeries.drop('name1', axis=1) # axis =1 是表示列轴,不可以省略 print(dataFrameSeries)
运行效果:
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\dataanalysis\DataAnalysisExecutorPandas.py
DataFrame表示的是矩阵数据表,它包含已经排序的集合;
每一列可以是不同的值类型(数值,字符串,布尔值等)
DataFrame既有行索引和列索引,它被视为一个共享相同索引的Series的字典,可以看作是序列Series的容器;
在DataFrame中,数据被存储为一个以上的二维块,而不是列表,字典或者其他一维数值的集合;
可以使用分层索引在DataFrame中展示更高维度的数据frame: state year pop
0 python 2000 1.5
1 java 2001 1.7
2 C 2003 3.6
3 C++ 2004 2.4
4 C# 2005 2.9
5 go 2006 3.2
默认展示前5行: state year pop
0 python 2000 1.5
1 java 2001 1.7
2 C 2003 3.6
3 C++ 2004 2.4
4 C# 2005 2.9
当然可以指定展示几行: state year pop
0 python 2000 1.5
1 java 2001 1.7
指定排序顺序,DataFrame的列将会按照指定的顺序排序:
sortFrame: year state pop
0 2000 python 1.5
1 2001 java 1.7
2 2003 C 3.6
3 2004 C++ 2.4
4 2005 C# 2.9
5 2006 go 3.2
如果指定排序的类不存在,此时的数据结构如下:指定排序顺序的二维数据结构: year state popt
0 2000 python NaN
1 2001 java NaN
2 2003 C NaN
3 2004 C++ NaN
4 2005 C# NaN
5 2006 go NaNDataFrame中的一列,可以按照字典标记或属性那样检索为Series序列
frameSeries: 0 python
1 java
2 C
3 C++
4 C#
5 go
Name: state, dtype: object
frameSeries: 0 2000
1 2001
2 2003
3 2004
4 2005
5 2006
Name: year, dtype: int64
data: 0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean -0.078736 0.017925 -0.012978 0.000483
std 1.029096 0.976971 0.979431 0.980950
min -3.586244 -2.816405 -3.242575 -2.875089
25% -0.756937 -0.680205 -0.661406 -0.720338
50% -0.060153 0.056706 0.005630 0.014671
75% 0.583656 0.716136 0.618660 0.650299
max 2.954882 2.742432 3.512564 2.935388
DataFrame数据框是用于存储多行多列的数据集合,是Series;
类似于Excel二维表格,对应DataFrame的操作无外乎"增,删,改,查"dataFrameSeries: age name
0 26 Ken
1 29 Jerry
2 24 Ben0 26
1 29
2 24
Name: age, dtype: int64
获取索引号是第一行的值(其实是第二行,从0开始)age name
1 29 Jerry
-------------------------------------------------------获取第0行到第二行(不包括)与第0列到第2列(不包括2行)的数据块
age name
0 26 Ken
1 29 JerryKen
访问某一行的时候,不能仅用行的index来访问,如要访问dataFrameSeries的index = 1的行,
不能写成dataFrameSeries[1],而要写成dataFrameSeries[1:2] ; DataFrame的index可以使任意的,
不会像Series那样报错,但会显示"Empty DataFrame",并列出Columns:[列名],执行下面的代码看看结果age name
second 29 John
third 24 JIMIEmpty DataFrame
Columns: [age, name]
Index: []Empty DataFrame
Columns: [age, name]
Index: []
----------------------------------------------------------------访问列
second 29
third 24
Name: age, dtype: int64age
second 29
third 24访问数据块
age
second 29
---------------------------------------------------------------
Jerry
John
如果这里用索引号就会报错,当有索引名时,不能用索引号,异常信息: 1修改列名
name1 name2
0 26 Ken
修改行的索引
name1 name2
1 26 Ken
2 29 Jerry
3 24 Ben
根据行索引删除
根据列名进行删除
name1 name2
1 26 Ken
2 29 Jerry
3 24 BenProcess finished with exit code 0
相关文章:
Python3数据科学包系列(一):数据分析实战
Python3中类的高级语法及实战 Python3(基础|高级)语法实战(|多线程|多进程|线程池|进程池技术)|多线程安全问题解决方案 Python3数据科学包系列(一):数据分析实战 Python3数据科学包系列(二):数据分析实战 认识下数据科学中数据处理基础包: (1)NumPy 俗话说: 要学会跑需先…...

【LittleXi】【MIT6.S081-2020Fall】Lab: locks
【MIT6.S081-2020Fall】Lab: locks 【MIT6.S081-2020Fall】Lab: locks内存分配实验内存分配实验准备实验目的1. 举一个例子说明修改前的**kernel/kalloc.c**中如果没有锁会导致哪些进程间竞争(races)问题2. 说明修改前的kernel/kalloc.c中锁竞争contention问题及其后果3. 解释a…...
图像压缩:Transformer-based Image Compression with Variable Image Quality Objectives
论文作者:Chia-Hao Kao,Yi-Hsin Chen,Cheng Chien,Wei-Chen Chiu,Wen-Hsiao Peng 作者单位:National Yang Ming Chiao Tung University 论文链接:http://arxiv.org/abs/2309.12717v1 内容简介: 1)方向:…...

C++ 类和对象篇(四) 构造函数
目录 一、概念 1. 构造函数是什么? 2. 为什么C要引入构造函数? 3. 怎么用构造函数? 3.1 创建构造函数 3.2 调用构造函数 二、构造函数的特性 三、构造函数对成员变量初始化 0. 对构造函数和成员变量分类 1. 带参构造函数对成员变量初始化 2. …...

Swing程序设计(5)绝对布局,流布局
文章目录 前言一、布局管理器二、介绍 1.绝对布局2.流布局总结 前言 Swing窗体中,每一个组件都有大小和具体的位置。而在容器中摆放各种组件时,很难判断其组件的具体位置和大小。即一个完整的界面中,往往有多个组件,那么如何将这…...

linux基础知识之文件系统 df/du/fsck/dump2fs
du du [选项][目录或者文件名] -a 显示每个子文件等磁盘占用量,默认只统计子目录的磁盘占用量 -h 使用习惯单位显示磁盘占用量,如KB,MB或者GB -s 统计总占用量,不列出子目录和文件占用量 面向文件 du -a 16 ./.DS_Store 8 ./requi…...
华为云云耀云服务器L实例评测|Elasticsearch的Docker版本的安装和参数设置 端口开放和浏览器访问
前言 最近华为云云耀云服务器L实例上新,也搞了一台来玩,期间遇到各种问题,在解决问题的过程中学到不少和运维相关的知识。 本篇博客介绍Elasticsearch的Docker版本的安装和参数设置,端口开放和浏览器访问。 其他相关的华为云云…...
8章:scrapy框架
文章目录 scrapy框架如何学习框架?什么是scarpy?scrapy的使用步骤1.先转到想创建工程的目录下:cd ...2.创建一个工程3.创建之后要转到工程目录下4.在spiders子目录中创建一个爬虫文件5.执行工程setting文件中的参数 scrapy数据解析scrapy持久…...
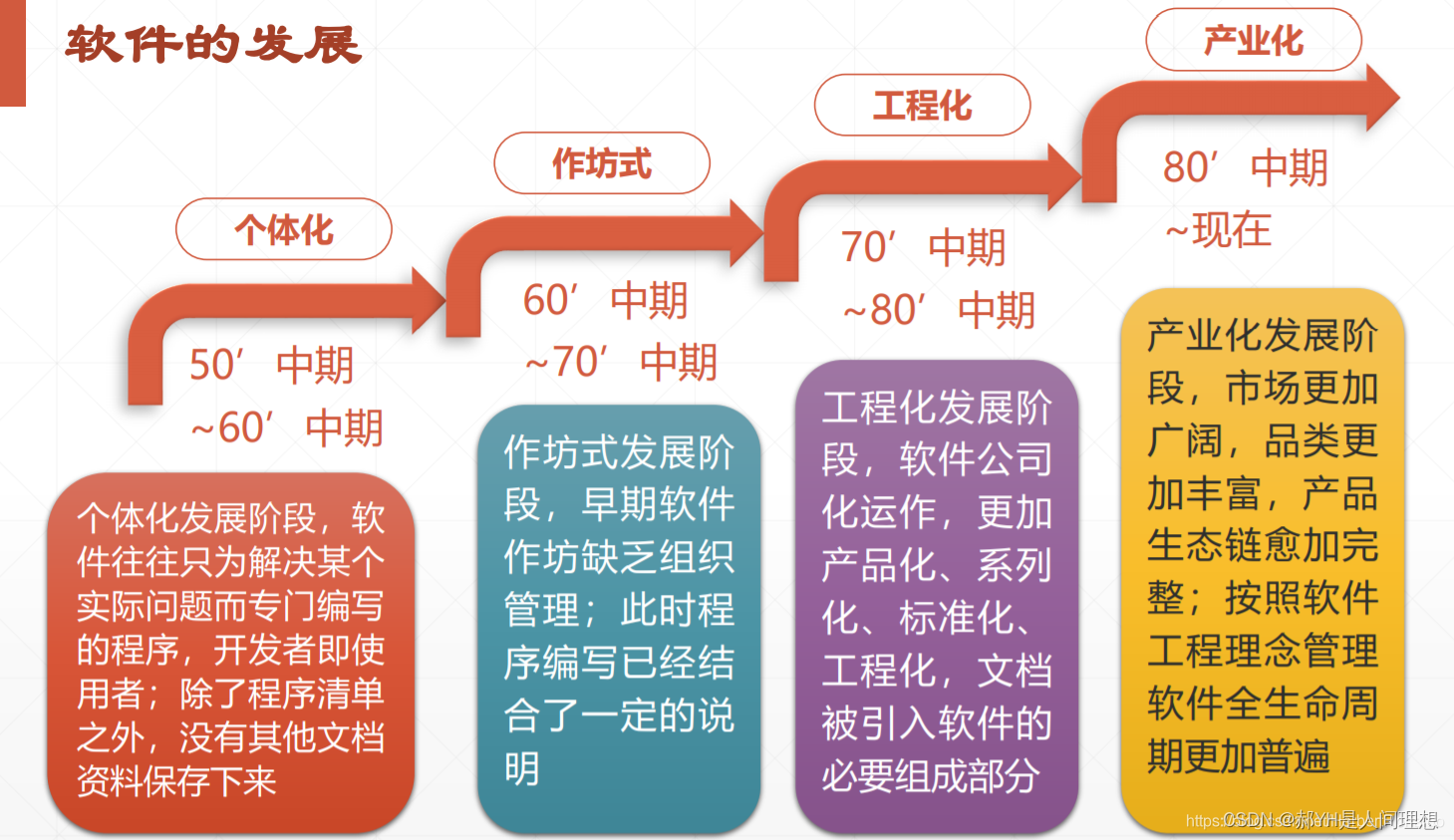
软件工程与计算总结(二)软件工程的发展
本章开始介绍第二节内容,主要是一些历史性的东西~ 一.软件工程的发展脉络 1.基础环境因素的变化及其对软件工程的推动 抽象软件实体和虚拟计算机都是软件工程的基础环境因素,它们能从根本上影响软件工程的生产能力,而且是软件工程无法反向…...
Appium开发
特点 开源免费支持多个平台 IOS(苹果)、安卓App的自动化都支持 支持多种类型的自动化 支持苹果、安卓应用原生界面的自动化支持应用内嵌网络视图的自动化支持手机浏览器(Chrome)中的web网站自动化支持flutter应用的自动化 支持多种编程语言 像selenium一样,可以用多…...

EGL函数翻译--eglInitialize
EGL函数翻译–eglInitialize 函数名 EGLBoolean eglInitialize(EGLDisplay display,EGLInt* major,EGLInit* minor); 参数描述 参数display: EGL要初始化的显示连接。 参数major: 输出EGL的主版本号;参数可为空。 参数minor: 输出EGL的次版本号;参数可…...
二项分布以及实现
文章目录 前言所谓二项分布就是只会产生两种结果的概率 1.概念 前言 所谓二项分布就是只会产生两种结果的概率 1.概念 下面是一个二项分布的的theano实现 import numpy as np import theano import theano.tensor as T from theano.tensor.nnet import conv from theano.ten…...

css自学框架之幻灯片展示效果
这一节,我自学了焦点图效果(自动播放,圆点控制),首先看一下效果: 下面我们还是老思路,css展示学习三个主要步骤:一是CSS代码,二是Javascript代码,三是Html代码。 一、css代码主要如…...

坦克世界WOT知识图谱三部曲之爬虫篇
文章目录 关于坦克世界1. 爬虫任务2. 获取坦克列表3. 获取坦克具体信息结束语 关于坦克世界 《坦克世界》(World of Tanks, WOT)是我在本科期间玩过的一款战争网游,由Wargaming公司研发。2010年10月30日在俄罗斯首发,2011年4月12日在北美和欧洲推出&…...
Idea上传项目到gitlab并创建使用分支
Idea上传项目到gitlab并创建使用分支 1 配置git 在idea的setting中,找到git,配置好git的位置,点击Test按钮显示出git版本号,则说明配置成功。 2 项目中引入git Idea通过VCS,选择Create Git Repository 在弹出的对话框…...
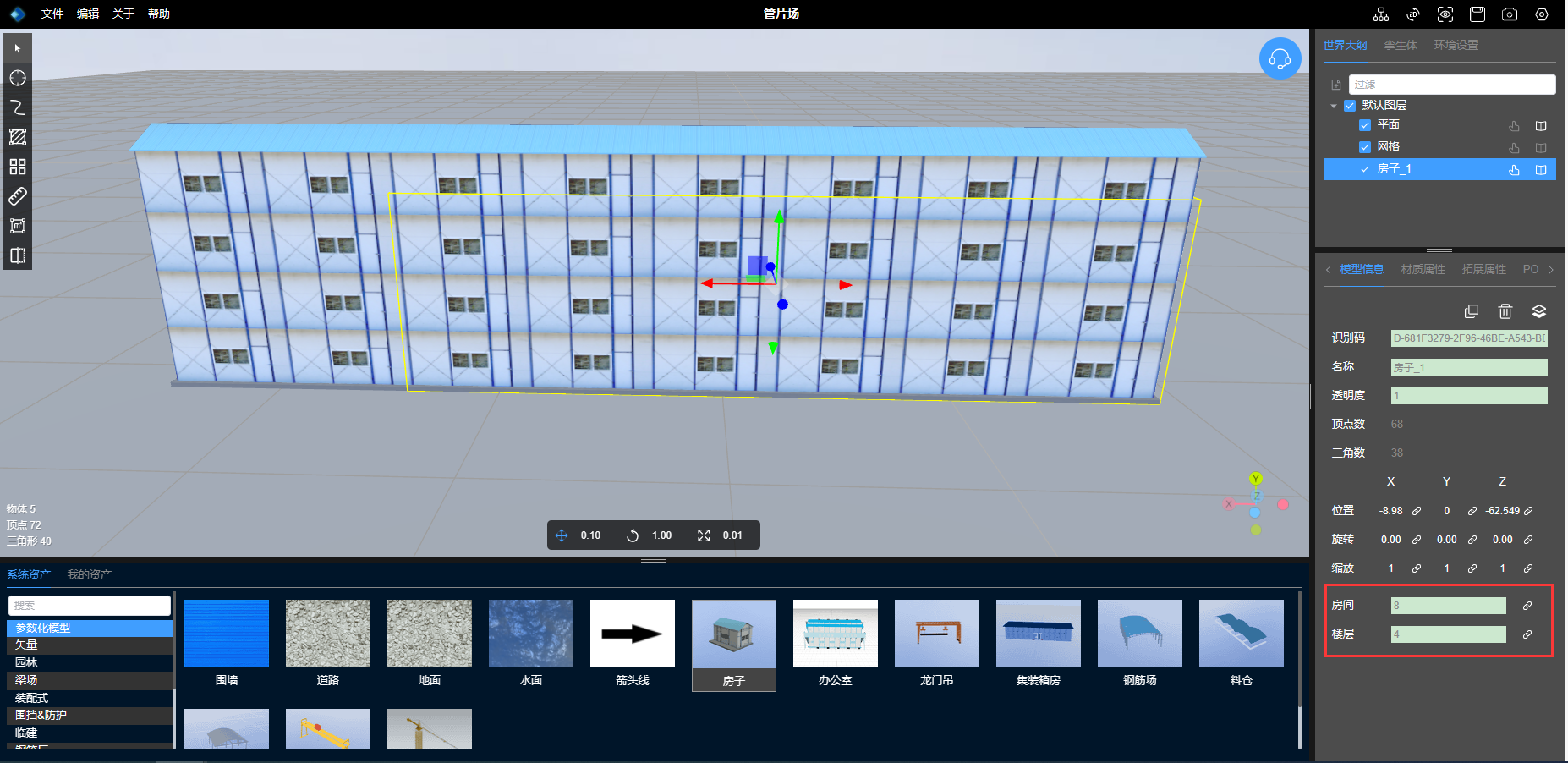
3D孪生场景搭建:参数化模型
1、什么是参数化模型 参数化模型是指通过一组参数来定义其形状和特征的数学模型或几何模型。这些参数可以用于控制模型的大小、形状、比例、位置、旋转、曲率等属性,从而实现对模型进行灵活的调整和变形。 在计算机图形学和三维建模领域,常见的参数化模…...

最短路径专题6 最短路径-多路径
题目: 样例: 输入 4 5 0 2 0 1 2 0 2 5 0 3 1 1 2 1 3 2 2 输出 2 0->1->2 0->3->2 思路: 根据题意,最短路模板还是少不了的, 我们要添加的是, 记录各个结点有多少个上一个结点走动得来的…...

【Linux】Linux常用命令—文件管理(上)
创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 🔥c系列专栏:C/C零基础到精通 🔥 给大…...

【Python】基于OpenCV人脸追踪、手势识别控制的求生之路FPS游戏操作
【Python】基于OpenCV人脸追踪、手势识别控制的求生之路FPS游戏操作 文章目录 手势识别人脸追踪键盘控制整体代码附录:列表的赋值类型和py打包列表赋值BUG复现代码改进优化总结 py打包 视频: 基于OpenCV人脸追踪、手势识别控制的求实之路FPS游戏操作 手…...
约束优化算法(optimtool.constrain)
import optimtool as oo from optimtool.base import np, sp, pltpip install optimtool>2.4.2约束优化算法(optimtool.constrain) import optimtool.constrain as oc oc.[方法名].[函数名]([目标函数], [参数表], [等式约束表], [不等式约数表], [初…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...