数仓建设(一)
想了想,我们的数仓的建设是基于大数据平台进行的,中间也经历了比较曲折的过程。
每个行业都有自身的业务区别,不过很多还是比较相通的。
本文将全面讲解数仓建设规范,从数据模型规范,到数仓公共规范,数仓各层规范,最后到数仓命名规范,包括表命名,指标字段命名规范等!
目录:
一、数据模型架构原则
- 数仓分层原则
- 主题域划分原则
- 数据模型设计原则
二、数仓公共开发规范
- 层次调用规范
- 数据类型规范
- 数据冗余规范
- NULL字段处理规范
- 指标口径规范
- 数据表处理规范
- 表的生命周期管理
三、数仓各层开发规范
- ODS层设计规范
- 公共维度层设计规范
- DWD明细层设计规范
- DWS公共汇总层设计规范
四、数仓命名规范
- 词根设计规范
- 表命名规范
- 指标命名规范
一、数据模型架构原则
1. 数仓分层原则
优秀可靠的数仓体系,往往需要清晰的数据分层结构,即要保证数据层的稳定又要屏蔽对下游的影响,并且要避免链路过长。那么问题来了,一直在讲数仓要分层,那数仓分几层最好?
目前市场上主流的分层方式眼花缭乱,不过看事情不能只看表面,还要看到内在的规律,不能为了分层而分层,没有最好的,只有适合的。
分层是以解决当前业务快速的数据支撑为目的,为未来抽象出共性的框架并能够赋能给其他业务线,同时为业务发展提供稳定、准确的数据支撑,并能够按照已有的模型为新业务发展提供方向,也就是数据驱动和赋能。
一个好的分层架构,要有以下好处:
- 清晰数据结构;
- 数据血缘追踪;
- 减少重复开发;
- 数据关系条理化;
- 屏蔽原始数据的影响。
数仓分层要结合公司业务进行,并且需要清晰明确各层职责,一般采用如下分层结构:
数据分层架构
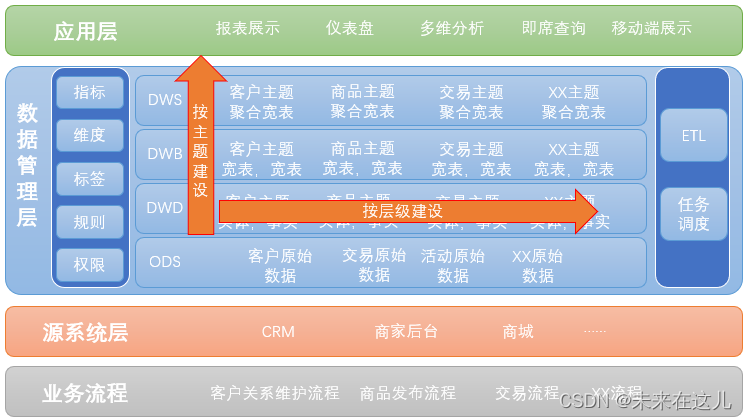
数仓建模在哪层建设呢?我们以维度建模为例,建模是在数据源层的下一层进行建设,在上图中,就是在DW层进行数仓建模,所以DW层是数仓建设的核心层。
下面详细阐述下每层建设规范,和上图的分层稍微有些区别:
1. 数据源层:ODS(Operational Data Store)
ODS 层,是最接近数据源中数据的一层,为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可,至于数据的去噪、去重、异常值处理等过程可以放在后面的 DWD 层来做。
2. 数据仓库层:DW(Data Warehouse)
数据仓库层是我们在做数据仓库时要核心设计的一层,在这里,从 ODS 层中获得的数据按照主题建立各种数据模型。
DW 层又细分为 DWD(Data Warehouse Detail)层、DWM(Data WareHouse Middle)层和 DWS(Data WareHouse Servce) 层。
1) 数据明细层:DWD(Data Warehouse Detail)
该层一般保持和 ODS 层一样的数据粒度,并且提供一定的数据质量保证。DWD 层要做的就是将数据清理、整合、规范化、脏数据、垃圾数据、规范不一致的、状态定义不一致的、命名不规范的数据都会被处理。
同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。
另外,在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性 。
2) 数据中间层:DWM(Data WareHouse Middle)
该层会在 DWD 层的数据基础上,数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。
直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。
在实际计算中,如果直接从 DWD 或者 ODS 计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在 DWM 层先计算出多个小的中间表,然后再拼接成一张 DWS 的宽表。由于宽和窄的界限不易界定,也可以去掉 DWM 这一层,只留 DWS 层,将所有的数据再放在 DWS 亦可。
3) 数据服务层:DWS(Data WareHouse Servce)
DWS 层为公共汇总层,会进行轻度汇总,粒度比明细数据稍粗,基于 DWD 层上的基础数据,整合汇总成分析某一个主题域的服务数据,一般是宽表。DWS 层应覆盖 80% 的应用场景。又称数据集市或宽表。
按照业务划分,如主题域流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP 分析,数据分发等。
一般来讲,该层的数据表会相对比较少,一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
3. 数据应用层:APP(Application)
在这里,主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、 PostgreSql、Redis 等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。比如我们经常说的报表数据,一般就放在这里。
4. 维表层(Dimension)
如果维表过多,也可针对维表设计单独一层,维表层主要包含两部分数据:
高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。 数据量可能是个位数或者几千几万。
2. 主题域划分原则
1) 按照业务或业务过程划分
业务容易理解,就是指的功能模块/业务线。
业务过程:指企业的业务活动事件,如下单、支付、退款都是业务过程。不过需要注意的是,一个业务过程是一个不可拆分的行为事件,通俗的讲,业务过程就是企业活动中的事件。

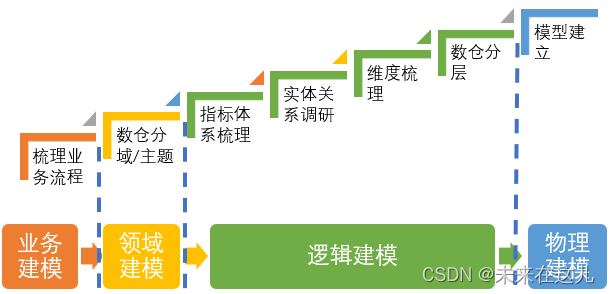
2) 按照数据域划分
数据域是指面向业务分析,将业务过程或者维度进行抽象的集合。其中,业务过程可以概括为一个个不可拆分的行为事件,在业务过程下,可以定义指标,维度是指度量的环境,如买家下单事件,买家是维度。为保障整个体系的生命力,数据域是需要抽象提炼,并且长期维护和更新的,但不轻易变动。在划分数据域时,既能涵盖当前所有的业务需求,又能在新业务进入时无影响地被包含进已有的数据域中和扩展新的数据域。
3. 数据模型设计原则
1) 高内聚、低耦合
即主题内部高内聚、 不同主题间低耦合。明细层按照业务过程划分主题,汇总层按照“实体+ 活动”划分不同分析主题,应用层根据应用需求划分不同应用主题。
2) 核心模型和扩展模型要分离
建立核心模型与扩展模型体系,核心模型包括的字段支持常用的核心业务,扩展模型包括的字段支持个性化或少量应用的需要,不能让扩展模型的字段过度侵入核心模型,以免破坏核心模型的架构简洁性与可维护性。
3) 公共处理逻辑下沉及单一
越是底层公用的处理逻辑越应该在数据调度依赖的底层进行封装与实现,不要让公用的处理逻辑暴露给应用实现,不要让公共逻辑多处同时存在。
4) 成本与性能平衡
适当的数据冗余可换取查询和刷新性能,不宜过度冗余与数据复制。
5) 数据可回滚
处理逻辑不变,在不同时间多次运行数据结果确定不变。
二、数仓公共开发规范
1. 层次调用规范
稳定业务按照标准的数据流向进行开发,即 ODS –> DWD –> DWS –> APP。非稳定业务或探索性需求,可以遵循 ODS -> DWD -> APP 或者 ODS -> DWD -> DWM ->APP 两个模型数据流。
在保障了数据链路的合理性之后,也必须保证模型分层引用原则:
- 正常流向:ODS -> DWD -> DWM -> DWS -> APP,当出现 ODS -> DWD -> DWS -> APP 这种关系时,说明主题域未覆盖全。应将 DWD 数据落到 DWM 中,对于使用频度非常低的表允许 DWD -> DWS。
- 尽量避免出现 DWS 宽表中使用 DWD 又使用(该 DWD 所归属主题域)DWM 的表。
- 同一主题域内对于 DWM 生成 DWM 的表,原则上要尽量避免,否则会影响 ETL 的效率。
- DWM、DWS 和 APP 中禁止直接使用 ODS 的表, ODS 的表只能被 DWD 引用。
- 禁止出现反向依赖,例如 DWM 的表依赖 DWS 的表。
举例:
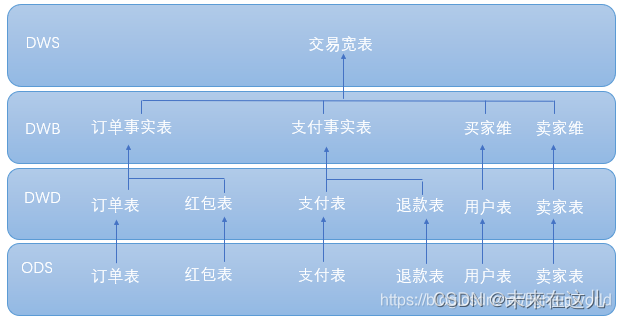
2. 数据类型规范
需统一规定不同的数据的数据类型,严格按照规定的数据类型执行:
- 金额:double 或使用 decimal(31,4) 控制精度等,明确单位是分还是元。
- 字符串:string。
- id类:bigint。
- 时间:string。
- 状态:string
3. 数据冗余规范
宽表的冗余字段要确保:
- 冗余字段要使用高频,下游3个或以上使用。
- 冗余字段引入不应造成本身数据产生过多的延后。
- 冗余字段和已有字段的重复率不应过大,原则上不应超过60%,如需要可以选择join或原表拓展。
4. NULL字段处理规范
- 对于维度字段,需设置为-1
- 对于指标字段,需设置为 0
5. 指标口径规范
保证主题域内,指标口径一致,无歧义。
通过数据分层,提供统一的数据出口,统一对外输出的数据口径,避免同一指标不同口径的情况发生。
相关文章:
数仓建设(一)
想了想,我们的数仓的建设是基于大数据平台进行的,中间也经历了比较曲折的过程。 每个行业都有自身的业务区别,不过很多还是比较相通的。 本文将全面讲解数仓建设规范,从数据模型规范,到数仓公共规范,数仓各…...

Springboot整合taos时序数据库TDengine
1.首先安装TDengine服务端在linux上 TDengine多种安装包的安装和卸载 - TDengine | 涛思数据安装过程直接去官网看,非常详细简单 2.出现的问题 windows连接 invalid app version 版本不对应 版本不对应的问题,需要在linux上安装的版本和windows client版本一致,不然w…...
Epoch、批量大小、迭代次数
梯度下降 它是 机器学习中使用的迭代 优化算法,用于找到最佳结果(曲线的最小值)。 坡度 是指 斜坡的倾斜度或倾斜度 梯度下降有一个称为 学习率的参数。 正如您在上图(左)中看到的,最初步长较大&#…...

qt-C++笔记之清空QVBoxLayout中的QCheckBox
qt-C笔记之清空QVBoxLayout中的QCheckBox QVBoxLayout 和 QCheckBox 是两个类,都是 PyQt/PySide 中用于创建图形用户界面 (GUI) 的工具。它们通常与 Qt 库一起使用,Qt 是一个流行的跨平台 GUI 库,可以用于创建桌面应用程序。 QVBoxLayout: Q…...

pc微信39223部分算法call偏移
WechatWin.dll 基址:78FD0000 MD5_Init_call 7AF48C80 | 56 | push esi | 7AF48C81 | 8B7424 08 | mov esi,dword ptr ss:[esp0x8] | 7AF48C85 | 6A 4C | push 0x4C …...
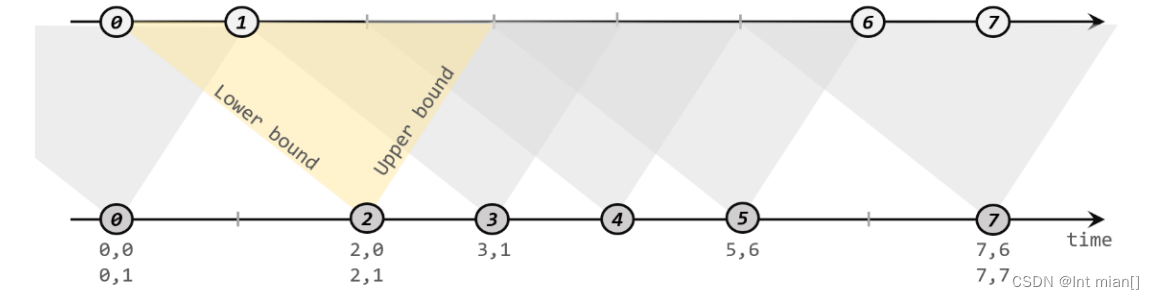
尚硅谷Flink(三)时间、窗口
1 🎰🎲🕹️ 🎰时间、窗口 🎲窗口 🕹️是啥 Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就…...

MPLS基础
1. MPLS原理与配置 MPLS基础 (1)MPLS概念 MPLS位于TCP/IP协议栈中的数据链路层和网络层之间,可以向所有网络层提供服务。 通过在数据链路层和网络层之间增加额外的MPLS头部,基于MPLS头部实现数据快速转发。 本课程仅介绍MPLS在…...

react+antd+Table实现表格初始化勾选某条数据,分页切换保留上一页勾选的数据
加上rowKey这个属性 <Table rowKey{record > record.id} // 加上rowKey这个属性rowSelection{rowSelection}columns{columns}dataSource{tableList}pagination{paginationProps} />...

Linux shell编程学习笔记13:文件测试运算
Linux Shell 脚本编程和其他编程语言一样,支持算数、关系、布尔、逻辑、字符串、文件测试等多种运算。前面几节我们依次研究了 Linux shell编程 中的 字符串运算、算术运算、关系运算、布尔运算 和 逻辑运算,今天我们来研究 Linux shell编程中的文件测…...

element ui this.$msgbox 自定义组件
this.$msgbox({title: "选择", message: (<com1figs{this.figs} on-selected{this.new_selected}></com1>),showCancelButton: false,showConfirmButton: false,}); 运行报错 Syntax Error: Unexpected token (89:20) 参考: https://gith…...
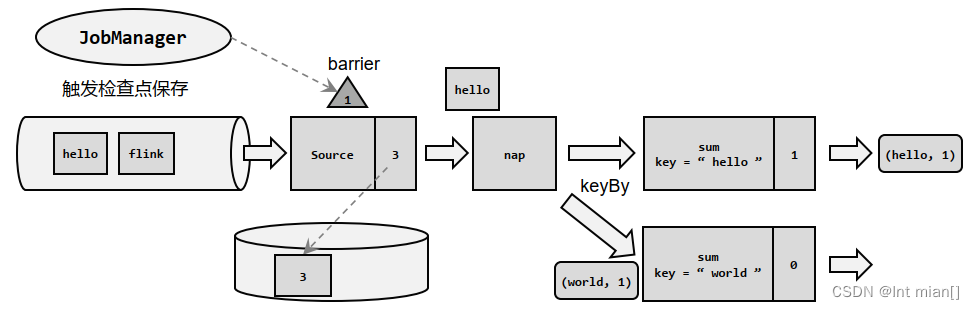
尚硅谷Flink(四)处理函数
目录 🦍处理函数 🐒基本处理函数 🐒按键分区处理函数(KeyedProcessFunction) 🐵定时器(Timer)和定时服务(TimerService) // 1、事件时间的案例 // 2、处理…...
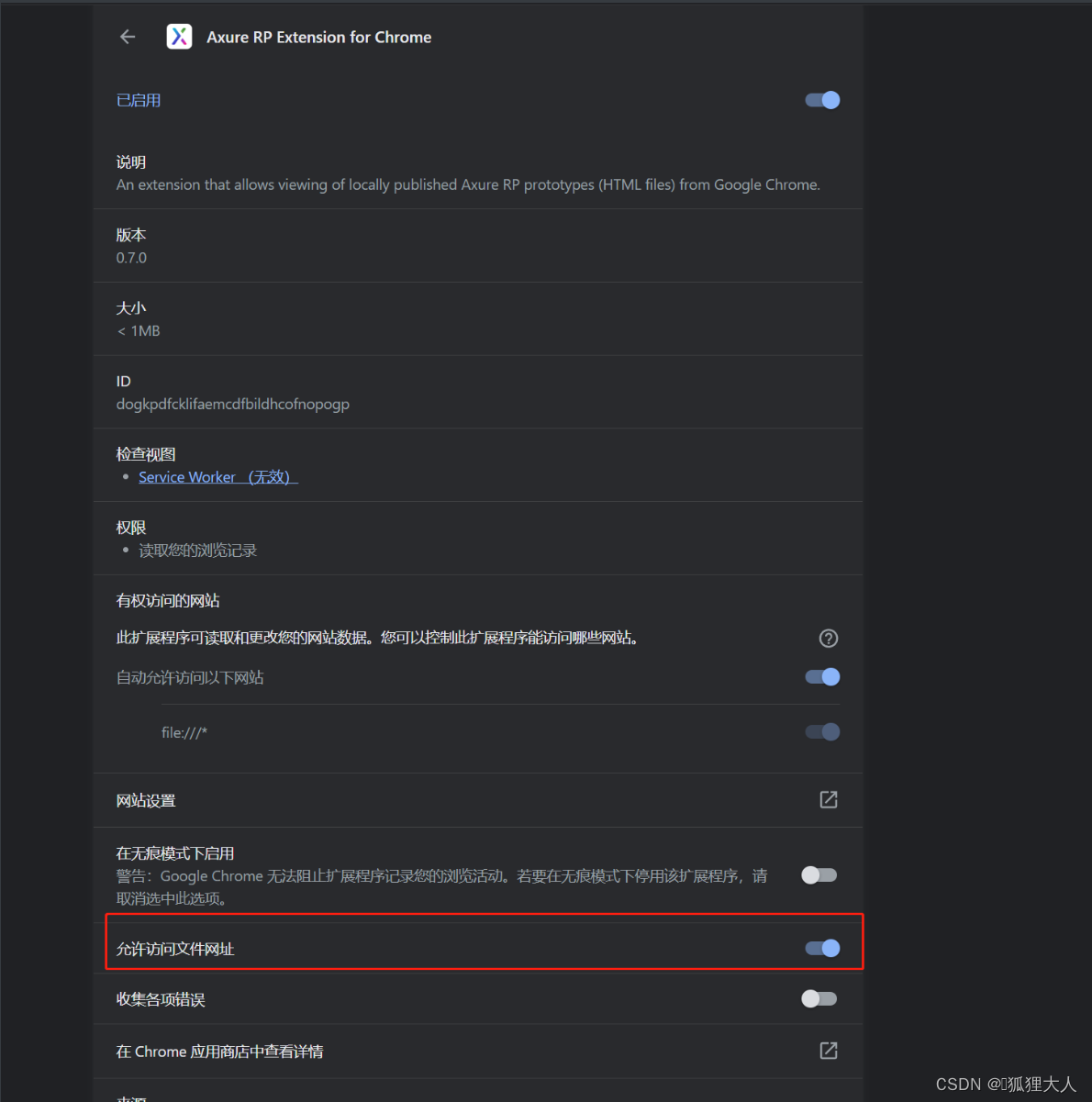
AXURE RP EXTENSION For Chrome 安装
在浏览器上输入地址:chrome://extensions/ 打开图片中这个选项,至此你就能通过index.html访问...
-3)
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...
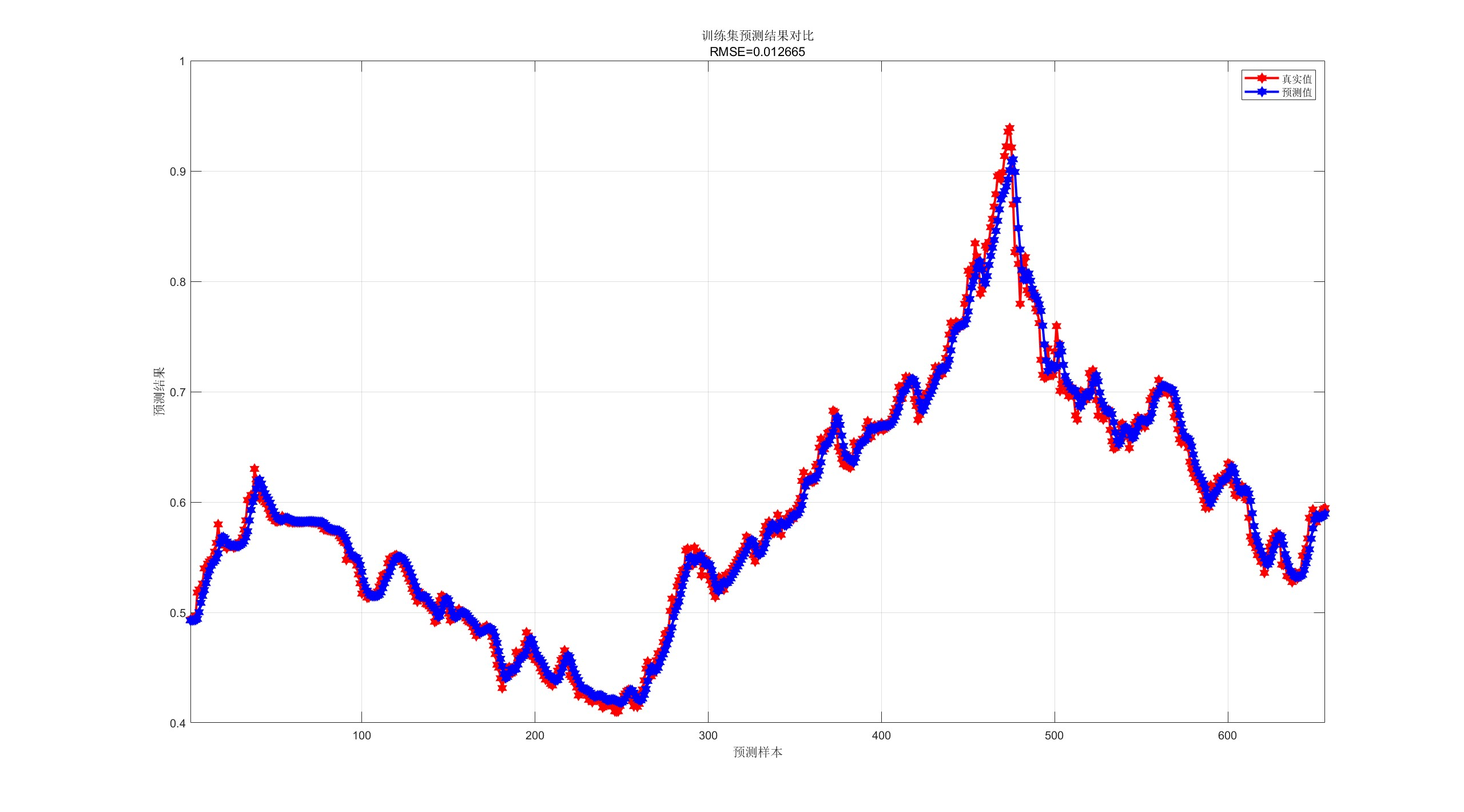
【CNN-GRU预测】基于卷积神经网络-门控循环单元的单维时间序列预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
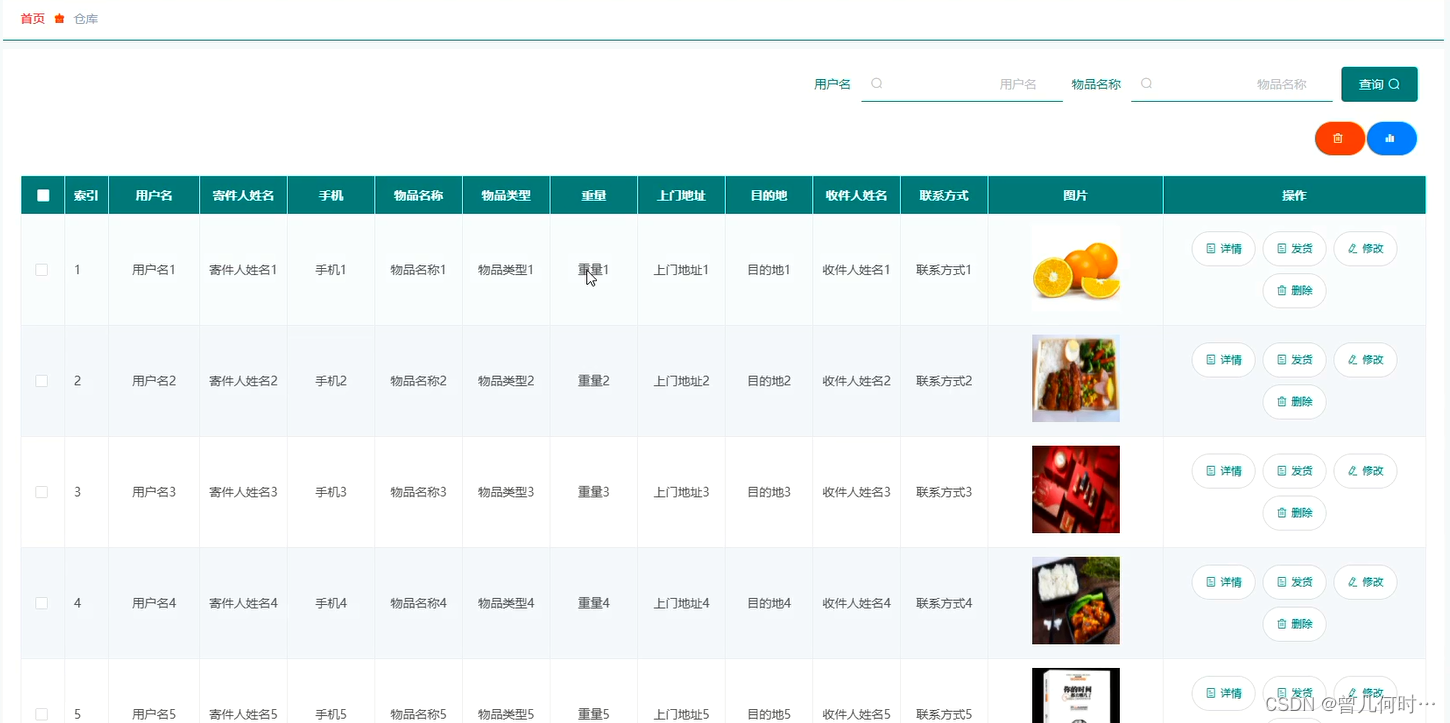
计算机毕业设计--基于SSM+Vue的物流管理系统的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

GPT4 Plugins 插件 WebPilot 生成抖音文案
1. 生成抖音文案 1.1. 准备1篇优秀的抖音文案范例 1.2. Promept公式 你是一个有1000万粉丝的抖音主播, 请模仿下面的抖音脚本文案,重新改与一篇文章改写成2分钟的抖音视频脚本, 要求前一部分是十分有争议性的内容,并且能够引发…...
通过核密度分析工具建模,基于arcgis js api 4.27 加载gp服务
一、通过arcmap10.2建模,其中包含三个参数 注意input属性,选择数据类型为要素类: 二、建模之后,加载数据,执行模型,无错误的话,找到执行结果,进行发布gp服务 注意,发布g…...
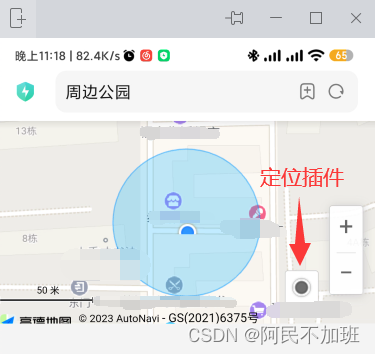
【vue2高德地图api】02-npm引入插件,在页面中展示效果
系列文章目录 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、安装高德地图二、在main.js中配置需要配置2个key值以及1个密钥 三、在页面中使用3.1 新建路由3.2新建vue页面3.2-1 index.vue3.2…...

ai智能语音电销机器人怎么选?
智能语音电销机器人哪家好?如何选择一款智能语音电销机器人?这几年生活中人工智能的普及越来越广泛,就如智能语音机器人在生活当中的应用还是比较方便的,有许多行业都会选择这类的智能语音系统来把工作效率提高上去,随…...

NumPy基础及取值操作
目录 第1关:ndarray对象 相关知识 怎样安装NumPy 什么是ndarray对象 如何实例化ndarray对象 使用array函数实例化ndarray对象 使用zeros,ones,empty函数实例化ndarray对象 代码文件 第2关:形状操作 相关知识 怎样改变n…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...
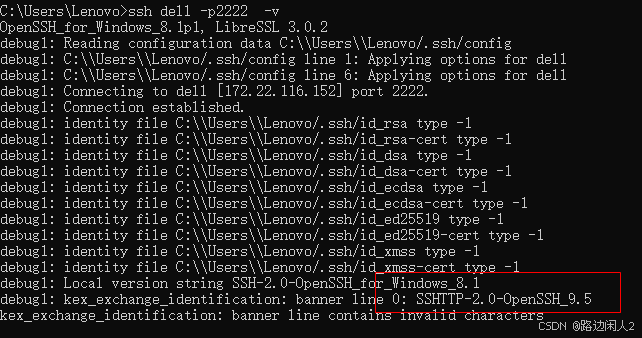
sshd代码修改banner
sshd服务连接之后会收到字符串: SSH-2.0-OpenSSH_9.5 容易被hacker识别此服务为sshd服务。 是否可以通过修改此banner达到让人无法识别此服务的目的呢? 不能。因为这是写的SSH的协议中的。 也就是协议规定了banner必须这么写。 SSH- 开头,…...
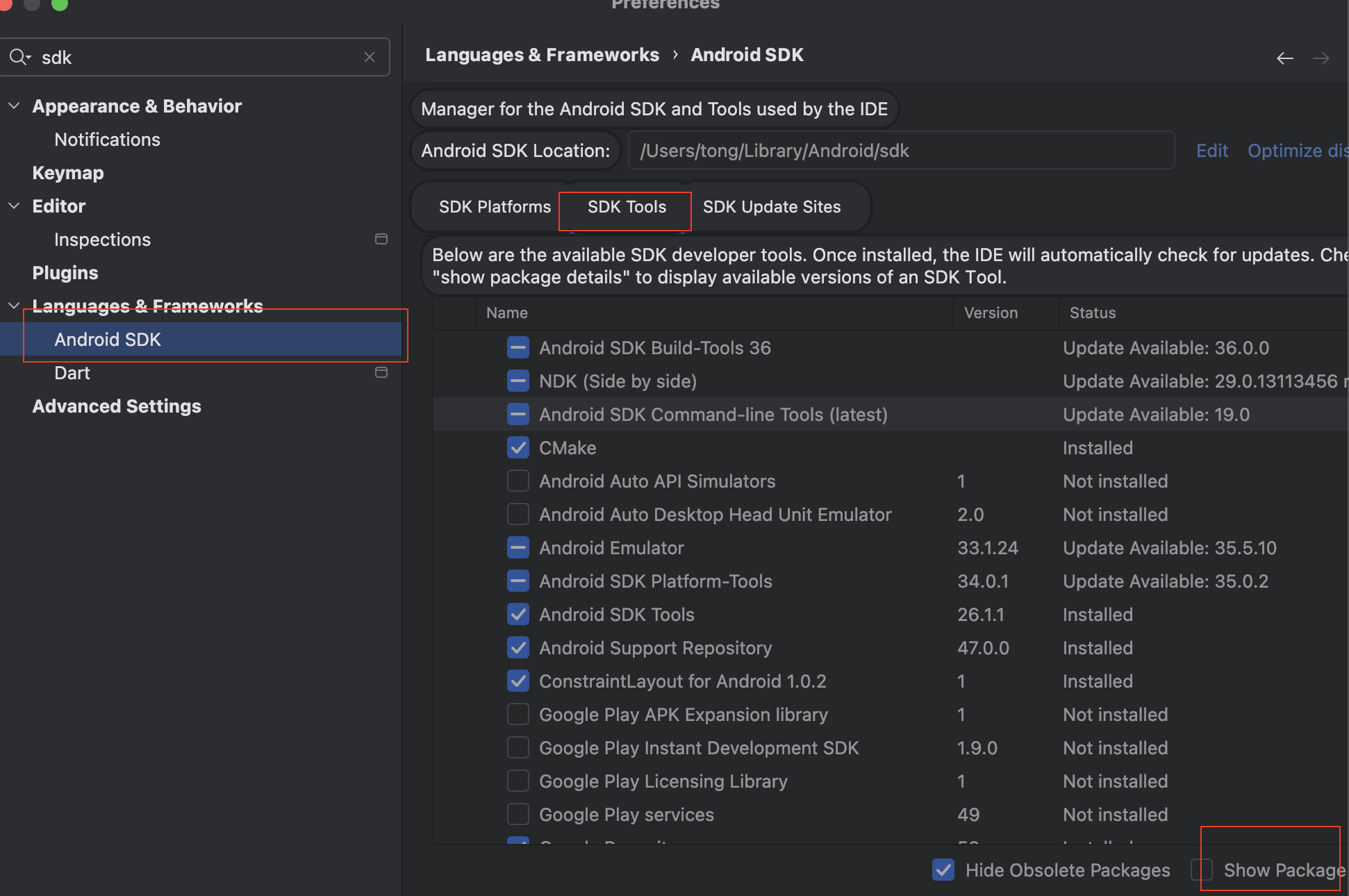
Mac flutter环境搭建
一、下载flutter sdk 制作 Android 应用 | Flutter 中文文档 - Flutter 中文开发者网站 - Flutter 1、查看mac电脑处理器选择sdk 2、解压 unzip ~/Downloads/flutter_macos_arm64_3.32.2-stable.zip \ -d ~/development/ 3、添加环境变量 命令行打开配置环境变量文件 ope…...