xgboost学习-原理
文章目录
- 一、xgboost库与XGB的sklearn API
- XGBoost的三大板块
- 二、梯度提升树
- 提升集成算法:重要参数n_estimators
- 三、有放回随机抽样:重要参数subsample
- 四、迭代决策树:重要参数eta
- 总结
一、xgboost库与XGB的sklearn API
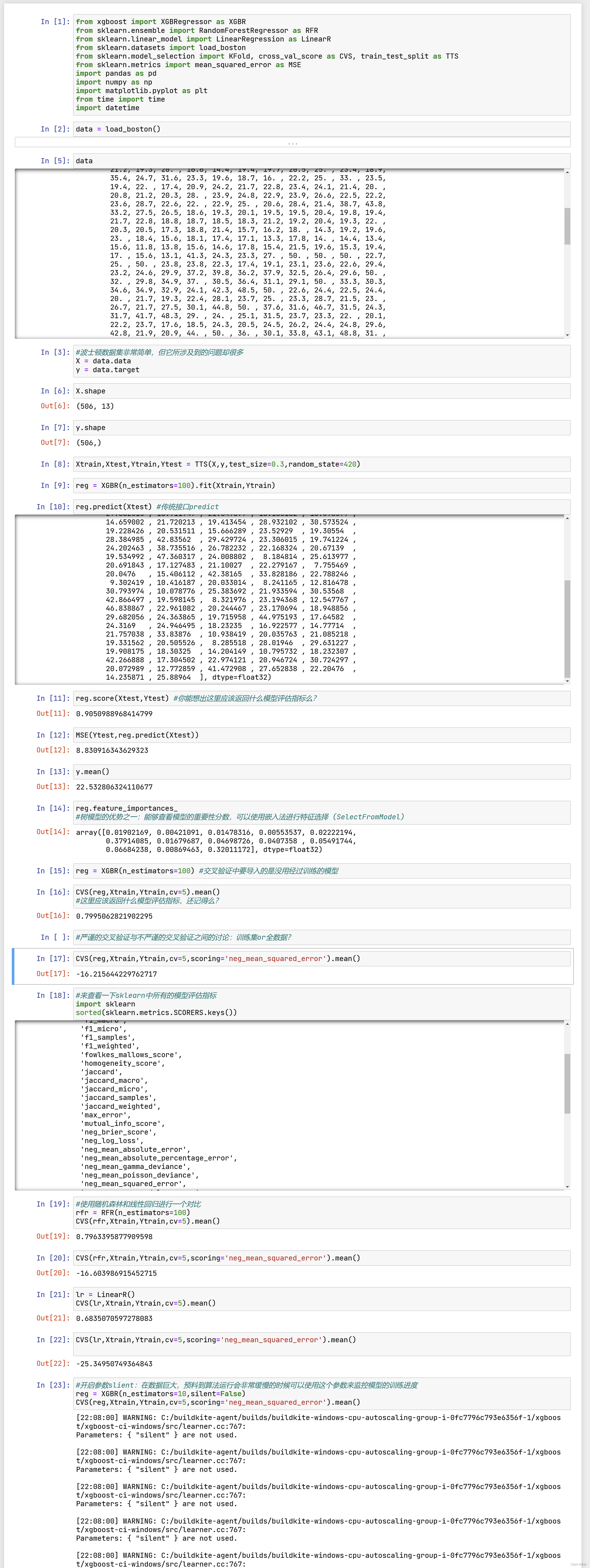
现在,我们有两种方式可以来使用我们的xgboost库。第一种方式,是直接使用xgboost库自己的建模流程。
params {eta, gamma, max_depth, min_child_weight, max_delta_step, subsample, colsample_bytree,
colsample_bylevel, colsample_bynode, lambda, alpha, tree_method string, sketch_eps, scale_pos_weight, updater,
refresh_leaf, process_type, grow_policy, max_leaves, max_bin, predictor, num_parallel_tree}
xgboost.train (params, dtrain, num_boost_round=10, evals=(), obj=None, feval=None, maximize=False,
early_stopping_rounds=None, evals_result=None, verbose_eval=True, xgb_model=None, callbacks=None,
learning_rates=None)
或者,我们也可以选择第二种方法,使用xgboost库中的sklearn的API。这是说,我们可以调用如下的类,并用我们
sklearn当中惯例的实例化,fit和predict的流程来运行XGB,并且也可以调用属性比如coef_等等。当然,这是我们回
归的类,我们也有用于分类,用于排序的类。他们与回归的类非常相似,因此了解一个类即可。
class xgboost.XGBRegressor (max_depth=3, learning_rate=0.1, n_estimators=100, silent=True,
objective=‘reg:linear’, booster=‘gbtree’, n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0,
subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1,
base_score=0.5, random_state=0, seed=None, missing=None, importance_type=‘gain’, **kwargs)
看到这长长的参数条目,可能大家会感到头晕眼花——没错XGB就是这门复杂。但是眼尖的小伙伴可能已经发现了,
调用xgboost.train和调用sklearnAPI中的类XGBRegressor,需要输入的参数是不同的,而且看起来相当的不同。但
其实,这些参数只是写法不同,功能是相同的。比如说,我们的params字典中的第一个参数eta,其实就是我们
XGBRegressor里面的参数learning_rate,他们的含义和实现的功能是一模一样的。只不过在sklearnAPI中,开发团
队友好地帮助我们将参数的名称调节成了与sklearn中其他的算法类更相似的样子。
所以对我们来说,使用xgboost中设定的建模流程来建模,和使用sklearnAPI中的类来建模,模型效果是比较相似
的,但是xgboost库本身的运算速度(尤其是交叉验证)以及调参手段比sklearn要简单。我们的课是sklearn课堂,
因此在今天的课中,我会先使用sklearnAPI来为大家讲解核心参数,包括不同的参数在xgboost的调用流程和sklearn
的API中如何对应,然后我会在应用和案例之中使用xgboost库来为大家展现一个快捷的调参过程。如果大家希望探
索一下这两者是否有差异,那必须具体到大家本身的数据集上去观察。
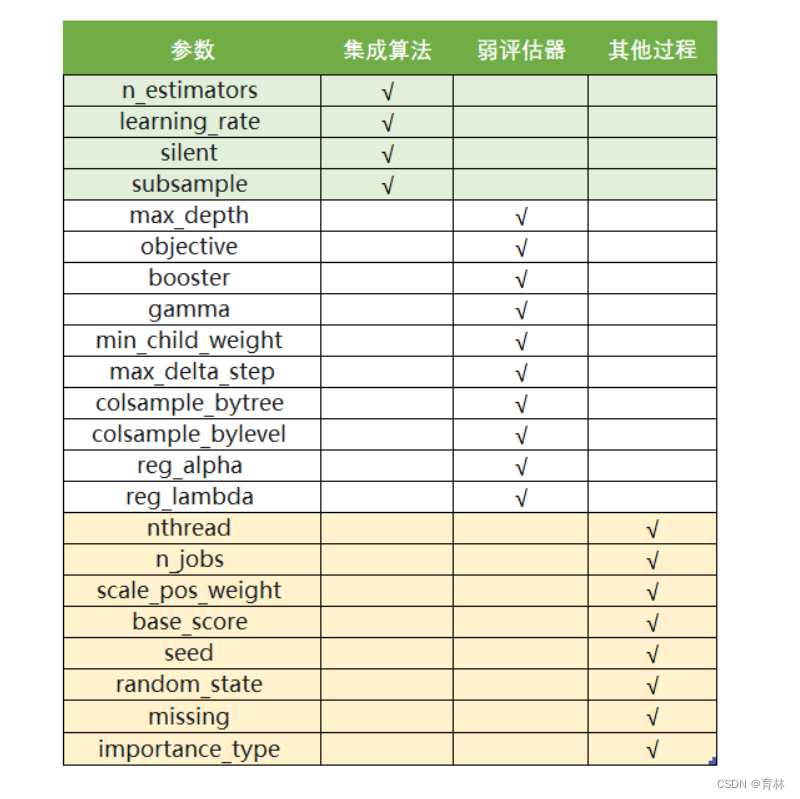
XGBoost的三大板块
二、梯度提升树
class xgboost.XGBRegressor (max_depth=3, learning_rate=0.1, n_estimators=100, silent=True,
objective=‘reg:linear’, booster=‘gbtree’, n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0,
subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1,
base_score=0.5, random_state=0, seed=None, missing=None, importance_type=‘gain’, **kwargs)
提升集成算法:重要参数n_estimators
XGBoost的基础是梯度提升算法,因此我们必须先从了解梯度提升算法开始。梯度提升(Gradient boosting)是构
建预测模型的最强大技术之一,它是集成算法中提升法(Boosting)的代表算法。集成算法通过在数据上构建多个弱
评估器,汇总所有弱评估器的建模结果,以获取比单个模型更好的回归或分类表现。弱评估器被定义为是表现至少比
随机猜测更好的模型,即预测准确率不低于50%的任意模型。
集成不同弱评估器的方法有很多种。有像我们曾经在随机森林的课中介绍的,一次性建立多个平行独立的弱评估器的
装袋法。也有像我们今天要介绍的提升法这样,逐一构建弱评估器,经过多次迭代逐渐累积多个弱评估器的方法。提
升法的中最著名的算法包括Adaboost和梯度提升树,XGBoost就是由梯度提升树发展而来的。梯度提升树中可以有
回归树也可以有分类树,两者都以CART树算法作为主流,XGBoost背后也是CART树,这意味着XGBoost中所有的树
都是二叉的。接下来,我们就以梯度提升回归树为例子,来了解一下Boosting算法是怎样工作的。
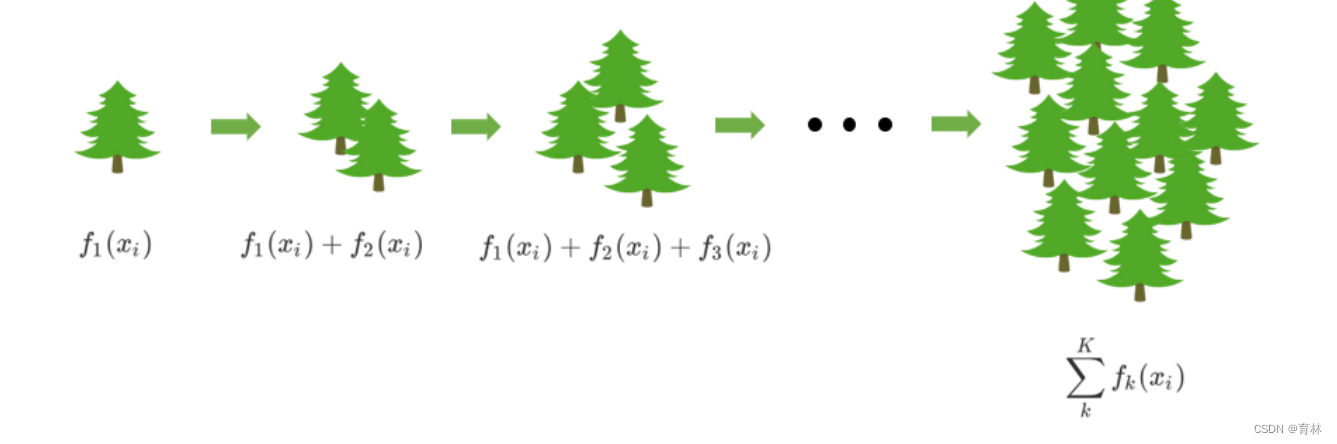
梯度提升回归树是专注于回归的树模型的提升集成模型,其建模过程大致如下:最开始先建立一棵树,然后逐
渐迭代,每次迭代过程中都增加一棵树,逐渐形成众多树模型集成的强评估器。
对于梯度提升回归树来说,每个样本的预测结果可以表示为所有树上的结果的加权求和:
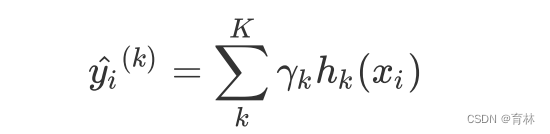
其中, 是树的总数量, 代表第 棵树, 是这棵树的权重, 表示这棵树上的预测结果。
值得注意的是,XGB作为GBDT的改进,在 上却有所不同。对于XGB来说,每个叶子节点上会有一个预测分数
(prediction score),也被称为叶子权重。这个叶子权重就是所有在这个叶子节点上的样本在这一棵树上的回归取
值,用 或者 来表示,其中 表示第 棵决策树, 表示样本 对应的特征向量。当只有一棵树的时候,
就是提升集成算法返回的结果,但这个结果往往非常糟糕。当有多棵树的时候,集成模型的回归结果就是所有树的预
测分数之和,假设这个集成模型中总共有 棵决策树,则整个模型在这个样本 上给出的预测结果为:
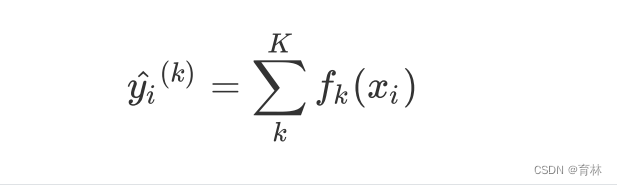
回忆一下我们曾经在随机森林中讲解过的方差-偏差困境。在机器学习中,我们用来衡量模型在未知数据上的准确率
的指标,叫做泛化误差(Genelization error)。一个集成模型(f)在未知数据集(D)上的泛化误差 ,由方差
(var),偏差(bais)和噪声(ε)共同决定。其中偏差就是训练集上的拟合程度决定,方差是模型的稳定性决定,噪音是不
可控的。而泛化误差越小,模型就越理想。
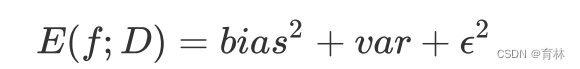
三、有放回随机抽样:重要参数subsample
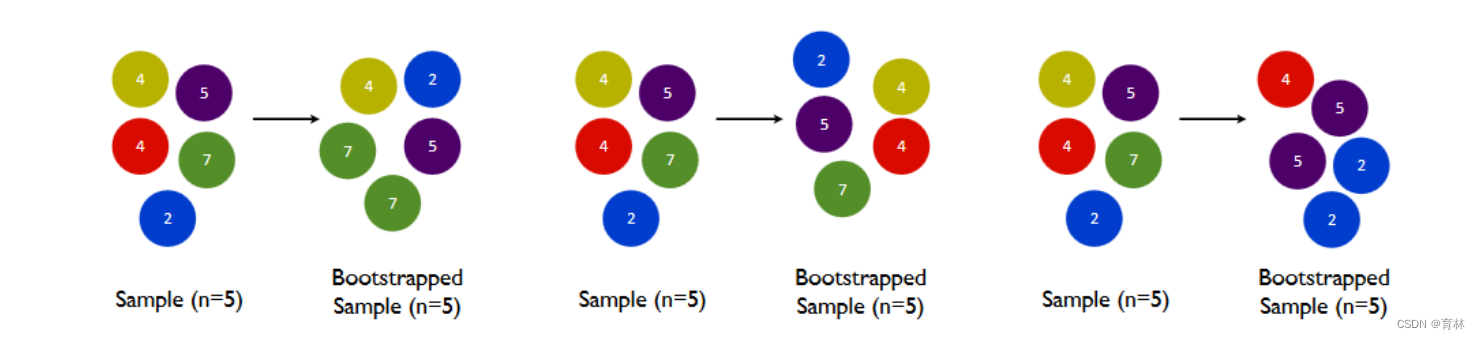
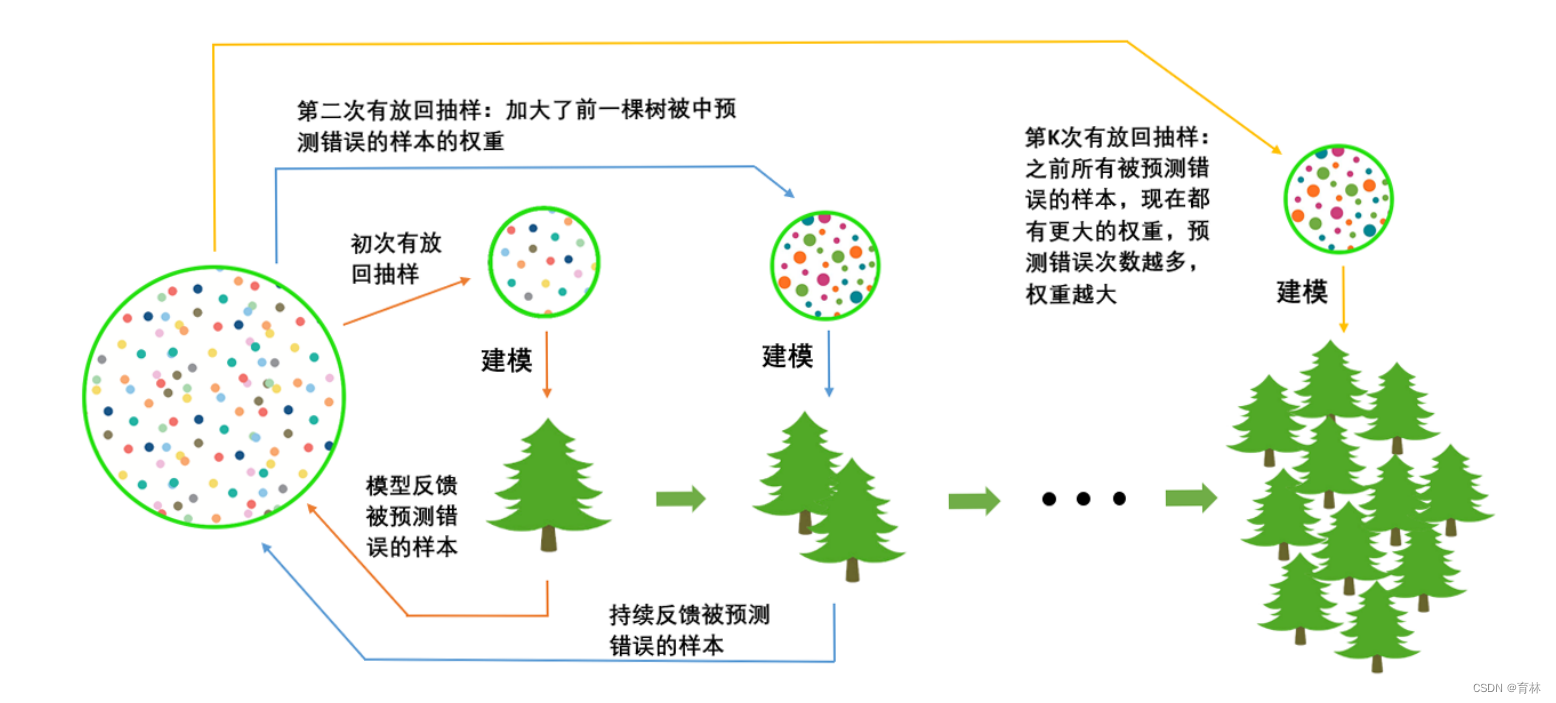
首先我们有一个巨大的数据集,在建第一棵树时,我们对数据进行初次又放回抽样,然后建模。建模完毕后,我们对
模型进行一个评估,然后将模型预测错误的样本反馈给我们的数据集,一次迭代就算完成。紧接着,我们要建立第二
棵决策树,于是开始进行第二次又放回抽样。但这次有放回抽样,和初次的随机有放回抽样就不同了,在这次的抽样
中,我们加大了被第一棵树判断错误的样本的权重。也就是说,被第一棵树判断错误的样本,更有可能被我们抽中。
基于这个有权重的训练集来建模,我们新建的决策树就会更加倾向于这些权重更大的,很容易被判错的样本。建模完
毕之后,我们又将判错的样本反馈给原始数据集。下一次迭代的时候,被判错的样本的权重会更大,新的模型会更加
倾向于很难被判断的这些样本。如此反复迭代,越后面建的树,越是之前的树们判错样本上的专家,越专注于攻克那
些之前的树们不擅长的数据。对于一个样本而言,它被预测错误的次数越多,被加大权重的次数也就越多。我们相
信,只要弱分类器足够强大,随着模型整体不断在被判错的样本上发力,这些样本会渐渐被判断正确。如此就一定程
度上实现了我们每新建一棵树模型的效果都会提升的目标。
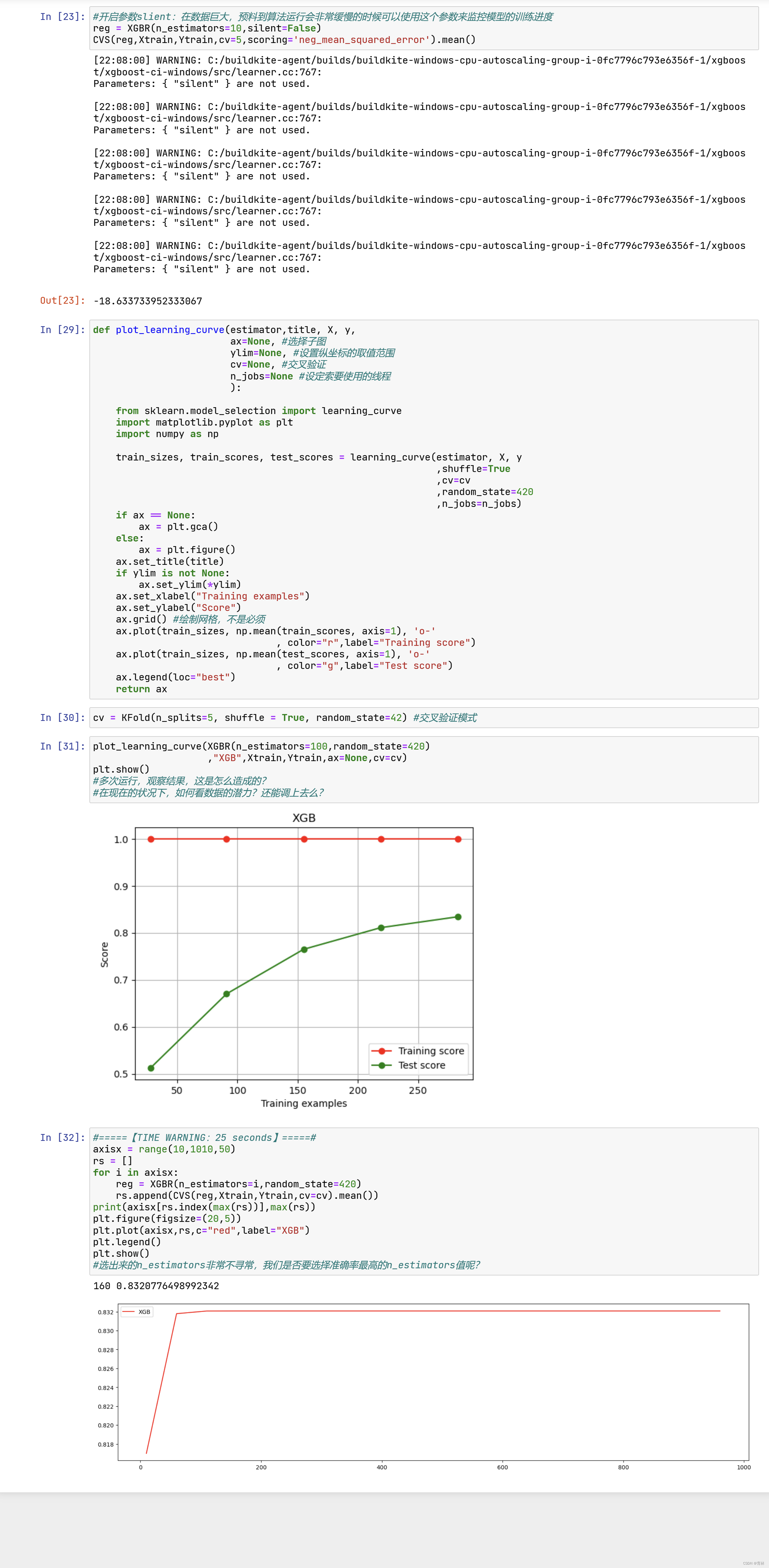
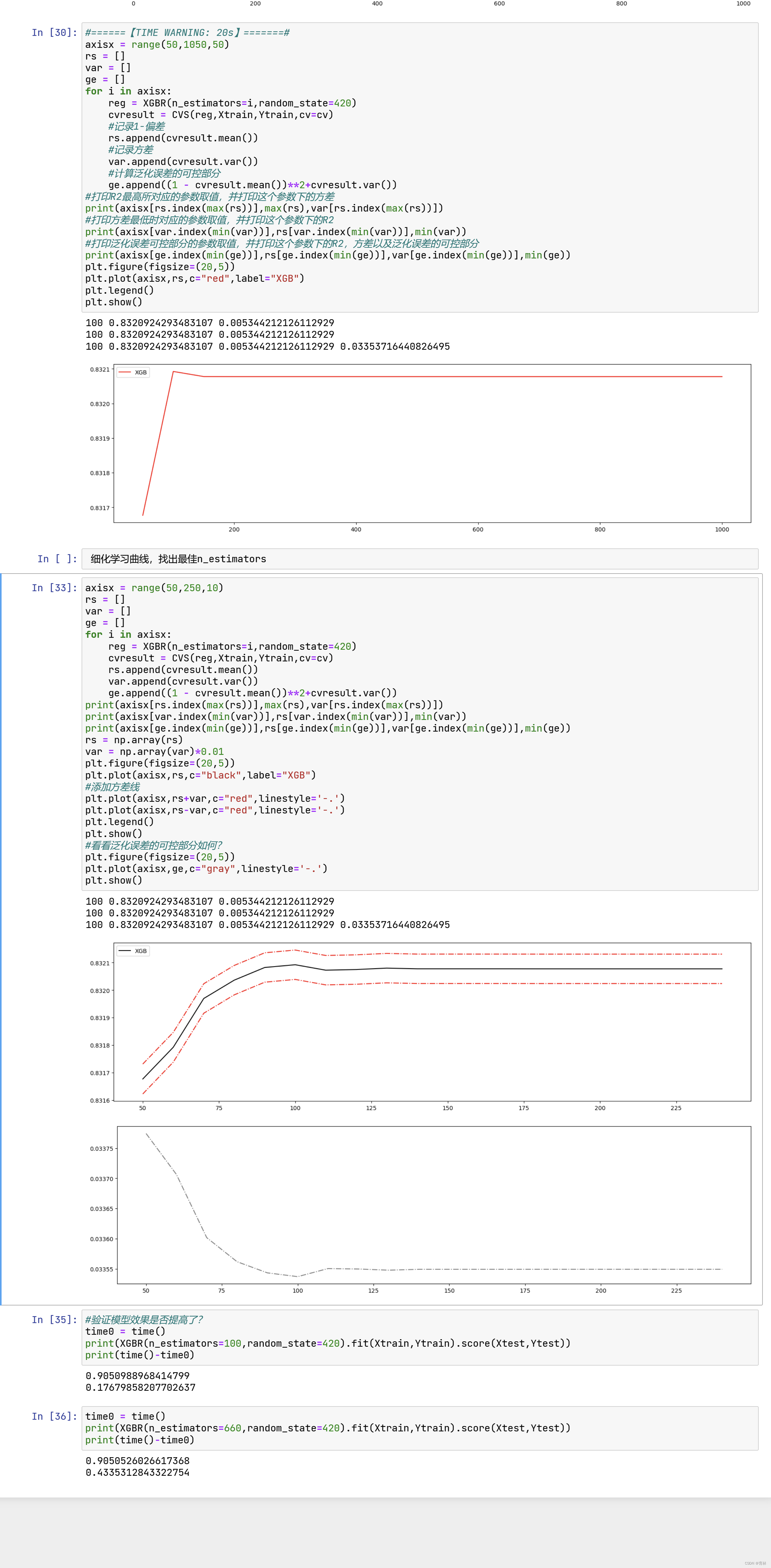
四、迭代决策树:重要参数eta
虽然从图上来说,默认的0.1看起来是一个比较理想的情况,并且看起来更小的步长更利于现在的数据,但我们也无
法确定对于其他数据会有怎么样的效果。所以通常,我们不调整 ,即便调整,一般它也会在[0.01,0.2]之间变动。如
果我们希望模型的效果更好,更多的可能是从树本身的角度来说,对树进行剪枝,而不会寄希望于调整 。
梯度提升树是XGB的基础,本节中已经介绍了XGB中与梯度提升树的过程相关的四个参数:n_estimators,
learning_rate ,silent,subsample。这四个参数的主要目的,其实并不是提升模型表现,更多是了解梯度提升树的
原理。现在来看,我们的梯度提升树可是说是由三个重要的部分组成:
- 一个能够衡量集成算法效果的,能够被最优化的损失函数Obj
- 一个能够实现预测的弱评估器fk(x)
- 一种能够让弱评估器集成的手段,包括我们讲解的迭代方法,抽样手段,样本加权等等过程
XGBoost是在梯度提升树的这三个核心要素上运行,它重新定义了损失函数和弱评估器,并且对提升算法的集成手段
进行了改进,实现了运算速度和模型效果的高度平衡。并且,XGBoost将原本的梯度提升树拓展开来,让XGBoost不
再是单纯的树的集成模型,也不只是单单的回归模型。只要我们调节参数,我们可以选择任何我们希望集成的算法,
以及任何我们希望实现的功能。
总结
相关文章:
xgboost学习-原理
文章目录一、xgboost库与XGB的sklearn APIXGBoost的三大板块二、梯度提升树提升集成算法:重要参数n_estimators三、有放回随机抽样:重要参数subsample四、迭代决策树:重要参数eta总结一、xgboost库与XGB的sklearn API 现在,我们有…...

如何查看CUDA版本
Linux 查看CUDA版本: nvcc --version或 nvcc --VWindows 查看CUDA版本: nvcc --version或进入 CUDA 的安装目录查看: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA使用PyTorch 查看 CUDA 版本 import torch print(torch.__ver…...

三、iperf3代码主要架构分析之main函数主要流程
iperf3是一个非常强大的工具,它是用C语言编写的。同时iperf3也是用C语言实现面向对象编程的典范,他以数据结构函数指针为基础,非常好的用C语言实现面向对象的编程的三大特征:封装,继承,多态。相信通过阅读i…...
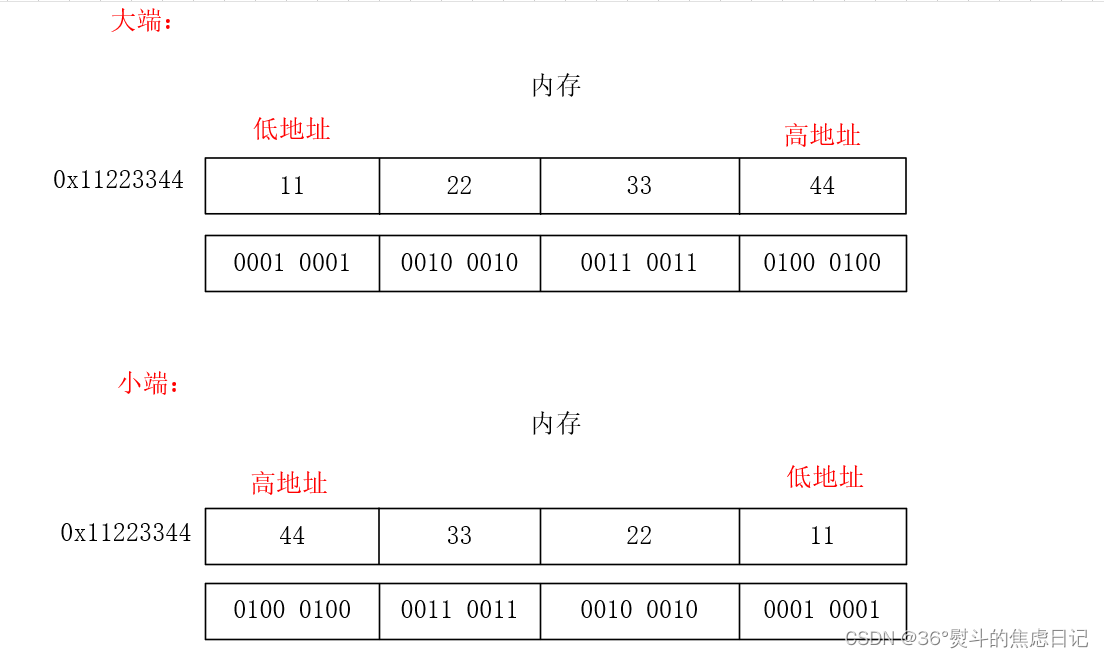
【概念辨析】大小端存储
一、情境 在进行内存调试窗口的查看时,是不是会有一种错觉,就是它存的数据与我们预期的都是颠倒的,比如: 这里的a就和我们预期的不是很相同。 二、大小端 大小端是计算机厂家根据自己的习惯制定的关于数据字节序的规则。 1.大端…...

并发编程-学习总结(下)
目录 1、Future 1.1、Callable和Runnable的不同 1.2、Future的主要功能 1.3、常用方法 1.4、Future使用注意事项 1.5、CompletableFuture(旅游平台问题) 1.5.1、需求 1.5.2、解决方案1:串行 1.5.3、解决方案2:线程池 1.5.4、解决方案3…...

arm汇编指令详细整理及实例详解
目录一、简介二、ARM 汇编指令说明2.1 32位数据操作指令2.2 32位存储器数据传送指令2.3 32位转移指令2.4 其它32位指令三、实例讲解3.1 MRS3.2 MSR3.3 PRIMASK3.4 FAULTMASK3.5 BX指令3.6 零寄存器 wzr、xzr3.7 立即寻址指令3.8 寄存器间接寻址指令3.9 寄存器移位寻址指令3.10 …...
)
高等数学笔记(下下)
无穷级数 定义 一般的,如果给定一个数列u1,u2,u3,...un,...,u_1, u_2, u_3, ... u_n, ... ,u1,u2,u3,...un,...,,那么由这个梳理构成的表达式u1u2u3...un...u_1u_2u_3...u_n...u1u2u3...un...叫做(常数项)无穷级数,简称(常…...
零基础如何入门网络安全(黑客)
我经常会看到这一类的问题: 学习XXX知识没效果;学习XXX技能没方向;学习XXX没办法入门; 给大家一个忠告,如果你完全没有基础的话,前期最好不要盲目去找资料学习,因为大部分人把资料收集好之后&a…...

【C++】map和set用法详解
文章目录1.关联式容器2.键值对3.树形结构的关联式容器3.1 set3.1.1 set的介绍3.1.2 set的模板参数列表3.1.3 set的使用3.2 mapmap的介绍map的模板参数列表map的使用关于map的元素访问总结3.3multimap1.关联式容器 我们接触过STL中的部分容器,比如:vecto…...

BLIP2-图像文本预训练
文章目录摘要解决问题算法模型结构通过frozen图像编码器学习视觉语言表征图像文本对比学习(ITC)基于图像文本生成(ITG)图文匹配(ITM)从大规模语言模型学习视觉到语言生成模型预训练预训练数据预训练图像编码…...
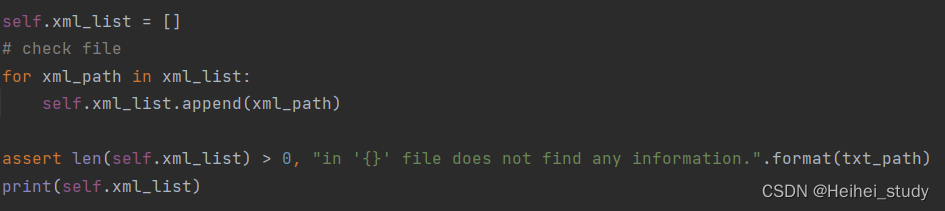
Faster-Rcnn修改转数据集文件
目录 学习python的一些基础知识 argparser assert关键字 让你秒懂Python 类特殊方法__getitem__ lxml.etree.fromstring的使用 统计一下json文件内的种类 正脸红外光 正脸-混合红外光 正脸-交叉偏振光 正脸-平行偏振光 正脸-紫外光 正脸-棕色光 调用mydataset可视化…...
带你沉浸式体验删库跑路
前言:学习的过程比较枯燥,后面会记录一些比较有意思的东西,比如程序员之间流传的删库跑路的梗,当然本次测试是在虚拟机上进行的并进行了快照保护,所以其实没太大问题。首先得要有一个虚拟机要有一个linux iso文件装在虚拟机上以上两点不是本文重点,如果有需要可以私…...
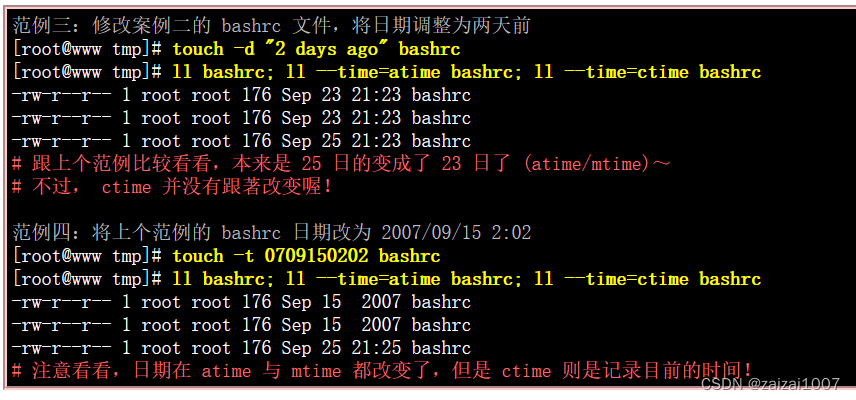
Linux学习(8.5)文件内容查阅
目录 文件内容查阅: 直接检视文件内容 cat (concatenate) tac (反向列示) nl (添加行号列印) 可翻页检视 more (一页一页翻动) less (一页一页翻动) 数据撷取 tail (取出后面几行) 非纯文字档: od 修改文件时间或建置新档: touc…...
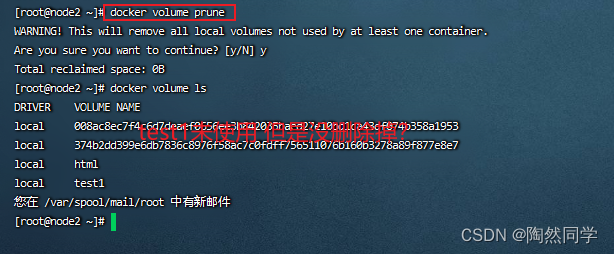
【Docker】命令总结
目录 1.镜像命令 1.1拉取镜像 1.2查看镜像 1.3保存镜像 1.4导入镜像 2.容器命令 2.1创建并运行容器 2.2删除容器 2.3进入容器 2.4查看容器状态 2.5暂停容器 2.6恢复容器 2.7停止容器 2.8启动容器 2.8查看容器日志 3.数据卷命令 3.1创建数据卷 3.2查看所有数据…...
并发编程-学习总结(上)
目录 1、线程基础 1.1、线程实现方法 1.2、如何正确停止线程 1.3、Java线程的六种状态 1.4、wait/notify/notifyAll注意事项 1.4.1、为什么 wait 、notify、notifyAll必须在 synchronized 保护的同步代码中使用? 1.4.2、为什么 wait/notify/notifyAll 被定义…...
QT之OpenGL混合
QT之OpenGL混合1. 概述2. 实现2.1 丢弃片段2.1.1 Demo2.2 混合2.2.1 相关函数2.2.2 排序问题2.2.3 Demo1. 概述 OpenGL中,混合(Blending)通常是实现物体透明度(Transparency)的一种技术。 2. 实现 2.1 丢弃片段 在某些情况下,有些片段是只需要设置显…...

【1255. 得分最高的单词集合】
来源:力扣(LeetCode) 描述: 你将会得到一份单词表 words,一个字母表 letters (可能会有重复字母),以及每个字母对应的得分情况表 score。 请你帮忙计算玩家在单词拼写游戏中所能获…...

nginx模块介绍
新编译前,在对应的nginx原编译文件夹 如:nginx-1.23.0 下,要 make clean 清空以前编译的objs文件夹,实际上就是执行了rm objs文件夹。 很多要用到git,先yum install git -y echo-nginx-module 让nginx直接使用echo的…...
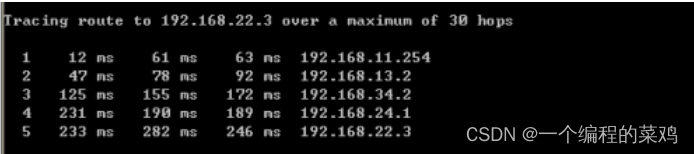
排错工具ping和trace(电子科技大学TCP/IP实验四)
一.实验目的 1、了解网络连通性测试的方法和工作原理 2、了解网络路径跟踪的方法和工作原理 3、掌握 MTU 的概念和 IP 分片操作 4、掌握 IP 分组生存时间(TTL)的含义和作用 5、掌握路由表的作用和路由查找算法 二.预备知识 …...

node.js中ws模块创建服务端和客户端
一、WebSocket出现的原因 1、Http协议发布REST API 的不足: 每次请求响应完成之后,服务器与客户端之间的连接就断开了,如果客户端想要继续获取服务器的消息,必须再次向服务器发起请 求。这显然无法适应对实时通信有高要求的场景…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...