【C++修炼之路】22.哈希
每一个不曾起舞的日子都是对生命的辜负

哈希
- 一.哈希概念及性质
- 1.1 哈希概念
- 1.2 哈希冲突
- 1.3 哈希函数
- 二.哈希冲突解决
- 2.1 闭散列/开放定址法
- 2.2 开散列/哈希桶
- 三.开放定址法代码
- 3.1 插入Insert
- 3.2 查找Find
- 3.3 删除Erase
- 3.4 映射的改良&完整代码
- 四.开散列代码
- 4.1 插入Insert
- 4.2 查找Find
- 4.3 删除Erase
- 4.4 完整代码&统计水果次数
- 五.扩容机制
一.哈希概念及性质
1.1 哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O(log2Nlog_2 Nlog2N),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
-
插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
-
搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小。
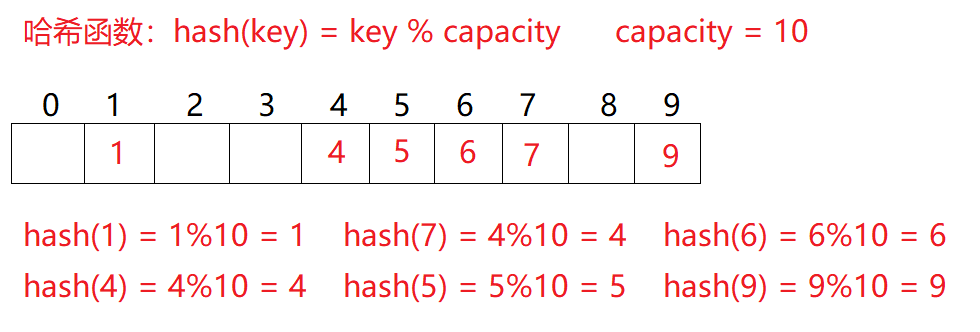
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快
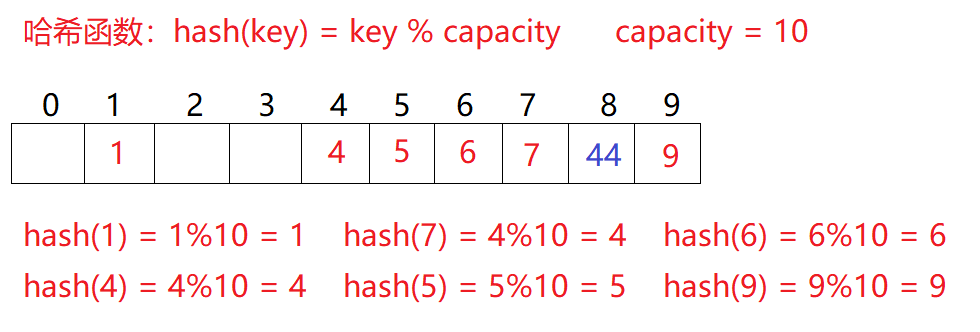
问题:按照上述哈希方式,向集合中插入元素44,会出现什么问题?
1.2 哈希冲突
对于两个数据元素的关键字kik_iki和 kjk_jkj(i != j),有kik_iki != kjk_jkj,但有:Hash(kik_iki) ==
Hash(kjk_jkj),即:不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
发生哈希冲突该如何处理呢?
1.3 哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见哈希函数
1. 直接定址法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况
一旦出现类似于这种数组:[1,2,3,100,10000],此时就会浪费很多比毕业的空间,因此一旦出现这种情况,我们采用下面这种方法:
2. 除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址。
因此,对于上面的数组来说,我们就可以采用%10的方式,将其固定在一定大小的范围之内,从而降低空间上的浪费。但此时,就会发生上面所说的哈希冲突,即对于100,10000,这两个数字%10之后都是0,因此一旦先将100放在了0的位置,那么10000就会发生哈希冲突。
二.哈希冲突解决
解决哈希冲突两种常见的方法是:闭散列和开散列
2.1 闭散列/开放定址法
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
1. 线性探测
比如1.1中的场景,现在需要插入元素44,先通过哈希函数计算哈希地址,hashAddr为4,因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
- 插入
- 通过哈希函数获取待插入元素在哈希表中的位置
- 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素

-
删除
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素。即我们可以采用标记的方式将没有插入过的地方标记为EMPTY,存在数据的地方标记位EXIST。
-
查找
那如果想要具体查找某一个元素,就可以从指定映射的地方直接找,我们知道解决哈希冲突时会往后插入,因此我们会继续往后找,如果找了一圈没有找到,那一定有一个位置代表终止位置,即EMPTY的位置,但是如果将之前的元素删除并标记EMPTY的话,那这个位置之后实际上还有数据可以查找,这样也就不能用这个表示终止位置了,为了能够满足终止位置,我们再设定一个状态,将存在的数据并删除的位置标记位DELETE,这样就可以通过EMPTY来终止查找了。
接下来直接看三.开放定址法代码中的代码实现->
线性探测优点:实现非常简单。
线性探测缺点:**一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。**如何缓解呢?
2.二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为:HiH_iHi = (H0H_0H0 + i2i^2i2 )% m, 或者:HiH_iHi = (H0H_0H0 - i2i^2i2 )% m。其中:i =1,2,3…, H0H_0H0是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。

对于1.1中如果要插入44,产生冲突,使用解决后的情况为:
研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
因此:闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
为了让映射的元素不互相影响,开散列/哈希桶的方式也就与此诞生:
2.2 开散列/哈希桶
1. 开散列概念
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
数组为指针数组:
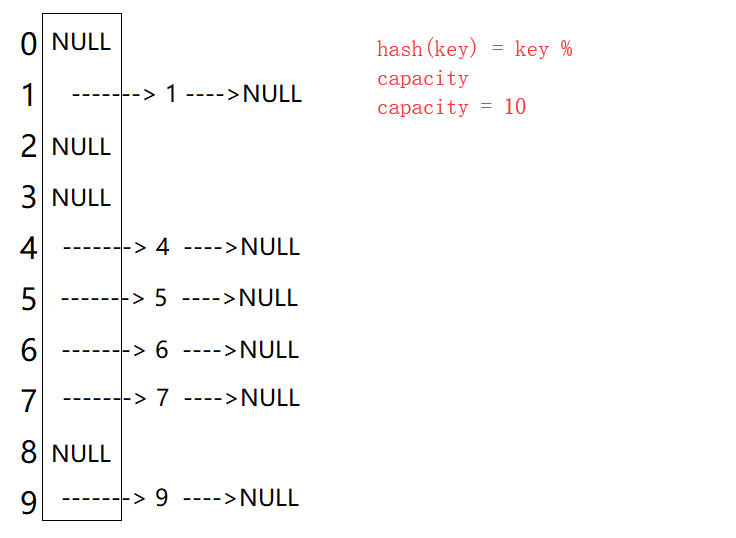
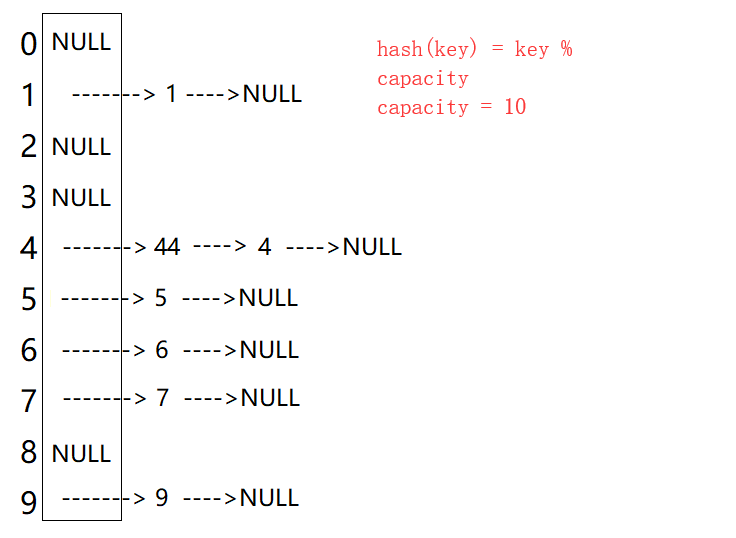
从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。C++库中就是用的这种方式。
指针数组也需要一定的扩容,不然空间为10,而有1000个数据,每个桶就需要挂100个数据,事实上比单链表好不了多少。所以在扩容时同样需要负载因子,不过对于演示来说,负载因子控制在1就好了。相比开放地址法,哈希桶的方式能让负载因子上升到很高的比例。
三.开放定址法代码
将除成员函数之外封装放在这里,这样设计是为了更具观赏性。
HashTable.h
enum State
{EMPTY,EXIST,DELETE,
};template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY;//默认给一个缺省值
};template<class K, class V>
class HaskTable
{typedef HashData<K, V> Data;
public://插入、查找、删除功能
private:vector<Data> _tables;size_t _n;//表中存储的有效数据的个数
};
直接使用vector会更加便捷,这也是一种很好的手段。
3.1 插入Insert
对于插入来说,将采用线性探测法,即如果发生冲突,就往后++遍历找到空的位置,那此时同样会发生一个问题,如果空间不够了,需要扩容,对于哈希来说,并不能等到空间满了才扩容,一旦到达某个程度,就会因哈希冲突的不断发生造成效率的低下,此时为了解决这种问题,就有了负载因子/载荷因子,即 负载因子 = 表中有效数据的个数/表的大小。
- 负载因子越小,冲突概率越小,消耗空间越多。
- 负载因子越大,冲突概率越大,空间的利用率越高。
可以看出,负载因子的出现正是以空间换时间的做法。一般将负载因子控制在0.7左右的样子,超过了这个值就需要扩容了。
对于扩容的过程,实际上随着空间大小的改变,取模%的大小也发生变化,这就造成数据原表的的位置可能与新表的位置寅映射关系的改变而变得不一样,事实上这并非是坏事,或许还会一定程度的减少哈希冲突。
因此一般的写法就是在写出一个 vector<Data> newTable,然后重复下面的逻辑,但是有一个更好的现代写法,重新定义一个类的对象也就是新的哈希表,将旧值通过类的方法重新Insert到新表中,最后这两个表的值进行交换,这样就不用重复写冲突的逻辑了。
注意:是新对象调用的Insert,和递归无关。
当然,一开始会出现除0错误,通过在内部重新写构造函数,直接resize()一个非0的数,就可以避免这个问题了。
那看看类中Insert的代码吧:结点之类的代码没有写,以免代码看起来太多,在代码案例开始已经写过。
template<class K, class V>
class HashTable
{typedef HashData<K, V> Data;
public:HashTable():_n(0){_tables.resize(10);}bool Insert(const pair<K, V>& kv){//大于标定负载因子,就需要扩容if (_n * 10 / _tables.size() > 7)//这样处理了小数为0{旧表数据,重新计算,映射到新表//vector<Data> newTable;//newTable.resize(_tables.size() * 2);//for()//现代写法HashTable<K, V> newHT;newHT._tables.resize(_tables.size() * 2);for (auto& e : _tables){newHT.Insert(e._kv);}_tables.swap(newHT._tables);}//因为需要满足vector的operator[],因此%size而不是capacitysize_t hashi = kv.first % _tables.size();while (_tables[hashi]._state == EXIST){//线性探测++hashi;hashi %= _tables.size();}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;//如果发现插入的值重复就应该返回false,但由于这里还没有讲解find函数,因此直接返回true也没什么问题,后续将会有完整代码return true;}private:vector<Data> _tables;size_t _n = 0;//表中存储的有效数据的个数
};
测试一下:
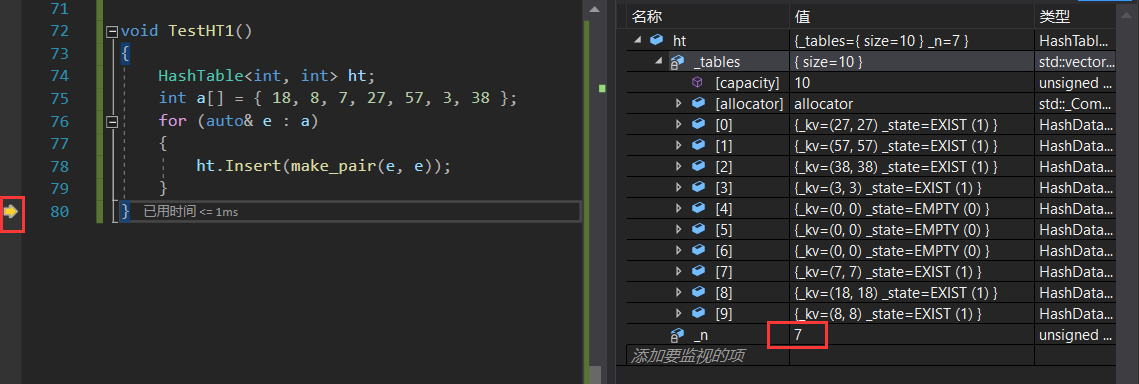
void TestHT1()
{HashTable<int, int> ht;int a[] = { 18, 8, 7, 27, 57, 3, 38 };for (auto& e : a){ht.Insert(make_pair(e, e));}
}

3.2 查找Find
Data* Find(const K& key)
{size_t hashi = key % _tables.size();while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST && _tables[hashi]._kv.first == key){return &_tables[hashi];}++hashi;hashi %= _tables.size();}return nullptr;
}
返回类型为Data*可以更好的删除,下面看看为什么:
3.3 删除Erase
bool Erase(const K& key)
{Data* ret = Find(key);if (ret){ret->_state = DELETE;--_n;return true;}return false;
}
可以发现,通过Find的返回值就可以将删除数据的_state变为DELETE,事实上这是一种伪删除的方式,不过用的恰到好处。
3.4 映射的改良&完整代码
仍然拿出统计水果出现的次数为背景引出问题:
void TestHT2()
{string arr[] = { "苹果", "西瓜", "香蕉", "苹果", "西瓜" , "苹果", "苹果","西瓜","苹果","香蕉", "苹果","香蕉" };HashTable<string, int> countHT;for (auto& e : arr){HashData<string, int>* ret = countHT.Find(e);if (ret){ret->_kv.second++;}else{countHT.Insert(make_pair(e, 1));}}}
对于这段代码来说,看不出有什么问题,那试着编译一下: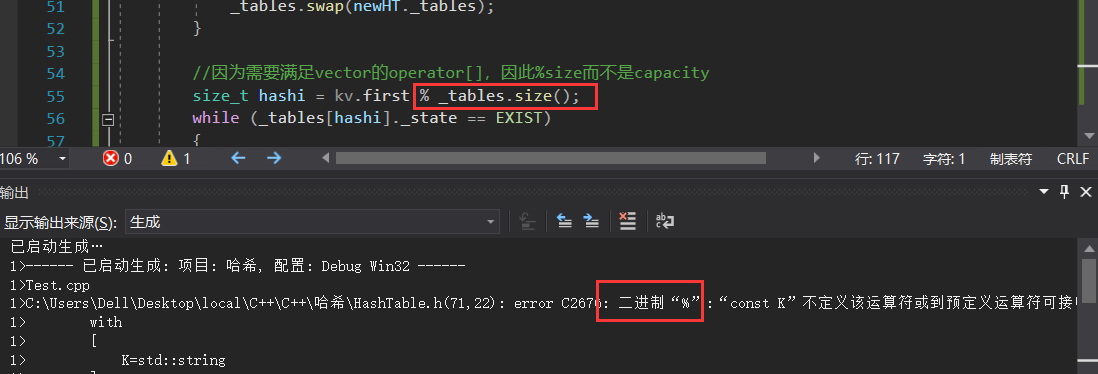
可以发现,我们之前解决哈希冲突的方式为线性探测中的除留余数法,这种方式无法对字符串进行取模,因此出现错误。那字符串转整形怎么转?并且还是汉字,汉字实际上就是由多个字母构成的。
解决方式->仿函数
通过仿函数的方式就可以将类型在映射时将string类型成功转换。在所有取模的地方都加上仿函数对象,就可以通过我们自定义的映射方式解决,即:
enum State
{EMPTY,EXIST,DELETE,
};//仿函数:解决s映射问题,完全没有关联的类型不能随便转,这个不能string转整形,因此还需要写一个
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//这个是针对string类型的仿函数
//特化
template<>
struct HashFunc<string>
{size_t operator()(const string& key){//BKDRsize_t hash = 0;for (auto& ch : key){hash *= 131;hash += ch;}return hash;//这样映射不易产生哈希冲突}
};template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY;//默认给一个缺省值
};template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{typedef HashData<K, V> Data;
public:HashTable():_n(0){_tables.resize(10);}bool Insert(const pair<K, V>& kv){if (Find(kv.first))//已经有了,就不需要插入了{return false;}//大于标定负载因子,就需要扩容if (_n * 10 / _tables.size() > 7)//这样处理了小数为0{旧表数据,重新计算,映射到新表//vector<Data> newTable;//newTable.resize(_tables.size() * 2);//for()//现代写法HashTable<K, V, Hash> newHT;//定义对象多了一个仿函数参数newHT._tables.resize(_tables.size() * 2);for (auto& e : _tables){newHT.Insert(e._kv);}_tables.swap(newHT._tables);}Hash hf;//取模的地方,用定义的仿函数对象封装解决size_t hashi = hf(kv.first) % _tables.size();//因为需要满足vector的operator[],因此%size而不是capacitywhile (_tables[hashi]._state == EXIST){//线性探测++hashi;hashi %= _tables.size();}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}Data* Find(const K& key){Hash hf;//仿函数:把key转化成可以取模的整形size_t hashi = hf(key) % _tables.size();while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST && _tables[hashi]._kv.first == key){return &_tables[hashi];}++hashi;hashi %= _tables.size();}return nullptr;}bool Erase(const K& key){Data* ret = Find(key);if (ret){ret->_state = DELETE;--_n;return true;}return false;}private:vector<Data> _tables;size_t _n = 0;//表中存储的有效数据的个数
};void TestHT2()
{string arr[] = { "苹果", "西瓜", "香蕉", "苹果", "西瓜" , "苹果", "苹果","西瓜","苹果","香蕉", "苹果","香蕉" };HashTable<string, int, HashFunc<string>> countHT;for (auto& e : arr){HashData<string, int>* ret = countHT.Find(e);if (ret){ret->_kv.second++;}else{countHT.Insert(make_pair(e, 1));}}
}

如果映射的是vector<string>甚至是vector<vector<string>>,或者是一个利他的类映射成整形,同样需要配套一个仿函数,这就体现了仿函数的灵活比较。
因此对于unordered_map,通过观察同样发现,其就利用了哈希的仿函数进行映射,在使用unordered_map时,我们一般传入两个参数,第三个有缺省值,对于string类型等还有模板的特化,因此在调用库中的unordered_map也无需自己设计仿函数。
此外:对于map和unordered_map除了底层的区别,还有就是map是比较的方式找值,而unordered_map是通过指定的算法将传入的数据转成整形再映射。

对于我们设计的Hash表,实际上也不需要写默认的六大成员函数,因为vector作为自定义类型会调用自己内置的析构,对于size_t这种内置类型也不用处理。
四.开散列代码
将除成员函数之外封装放在这里,这样设计同样是为了更具观赏性。
template<class K, class V>
struct HashNode
{pair<K, V> _kv;HashNode<K, V>* _next;
};template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{typedef HashNode<K, V> Node;
public://插入、查找、删除private:vector<Node*> _tables;//指针数组size_t _n;
};
4.1 插入Insert
插入时由于是链表,所以头插无疑是最好的方式。此外,对于指针数组来说,如果达到一定的限度,同样需要扩容,负载因子可以根据所需的数量从而控制在一定范围内,在这里负载因子以1为例。
与闭散列不同的是,因为是链表结构,默认生成的析构函数不能将空间全部释放,所以我们需要自己写一个析构函数将链表节点的空间释放。
开散列扩容的问题
对于哈希桶这种结构,扩容意味着重新开辟空间将旧表数据映射到新表,需要注意的是,不能直接一串一串的复制,因为由于新表的空间变大,因此取模时的映射关系也会变话,直接成串复制会导致映射关系发生错误进而在Find时找不到对应位置。所以还是要像正常扩容一样,把旧表的数据都遍历一遍映射拷贝到新表。与闭散列一样的扩容方式:
// 负载因子控制在1,超过就扩容
if (_tables.size() == _n)
{HashTable<K, V, Hash> newHT;newHT._tables.resize(_tables.size() * 2);for (auto cur : _tables){while (cur){newHT.Insert(cur->_kv);cur = cur->_next;}}_tables.swap(newHT._tables);
}
对于这种扩容方式,实际上很浪费空间,因其在插入过程中都是在拷贝节点,在一定程度上浪费了空间,并且在析构时会析构两次,又是一次性能的缺失。本着能优化尽量优化的思想,事实上,我们可以将旧表中的结点头插到新表指定的映射位置,这样就不需要拷贝创建新节点,但这样需要注意的是:要将旧表的每一个元素:_tables[i]清理掉或者都置nullptr,防止同一块空间析构两次造成浅拷贝。因此,改善之后的扩容及插入代码如下:
bool Insert(const pair<K, V>& kv)
{if (Find(kv.first))return false;// 负载因子控制在1,超过就扩容if (_tables.size() == _n){vector<Node*> newTables;newTables.resize(2 * _tables.size(), nullptr);for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = Hash()(cur->_kv.first) % newTables.size();//头插到新表cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}}size_t hashi = Hash()(kv.first) % _tables.size();// 头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;
}
4.2 查找Find
和开放定址法一样:
Node* Find(const K& key)
{size_t hashi = Hash()(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}else{cur = cur->_next;}}return nullptr;
}
4.3 删除Erase
bool Erase(const K& key)
{size_t hashi = Hash()(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}else{prev = cur;cur = cur->_next;}}return false;
}
4.4 完整代码&统计水果次数
//仿函数:解决s映射问题,完全没有关联的类型不能随便转,这个不能string转整形,因此还需要写一个
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//特化
template<>
struct HashFunc<string>
{size_t operator()(const string& key){//BKDR-Hashsize_t hash = 0;for (auto& ch : key){hash *= 131;hash += ch;}return hash;//这样映射不易产生哈希冲突}
};template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{typedef HashNode<K, V> Node;
public:HashTable():_n(0){_tables.resize(10);}~HashTable(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;// 负载因子控制在1,超过就扩容if (_tables.size() == _n){vector<Node*> newTables;newTables.resize(2 * _tables.size(), nullptr);for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = Hash()(cur->_kv.first) % newTables.size();//头插到新表cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}}size_t hashi = Hash()(kv.first) % _tables.size();// 头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}Node* Find(const K& key){size_t hashi = Hash()(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}else{cur = cur->_next;}}return nullptr;}bool Erase(const K& key){size_t hashi = Hash()(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}else{prev = cur;cur = cur->_next;}}return false;}
private:vector<Node*> _tables; //指针数组size_t _n = 0;
};void TestHT2()
{string arr[] = { "苹果", "西瓜", "香蕉", "苹果", "西瓜" , "苹果", "苹果","西瓜","苹果","香蕉", "苹果","香蕉" };//HashTable<string, int, HashFuncString> countHT;HashTable<string, int, HashFunc<string>> countHT;for (auto& e : arr){auto ret = countHT.Find(e);if (ret){ret->_kv.second++;}else{countHT.Insert(make_pair(e, 1));}}
}
五.扩容机制
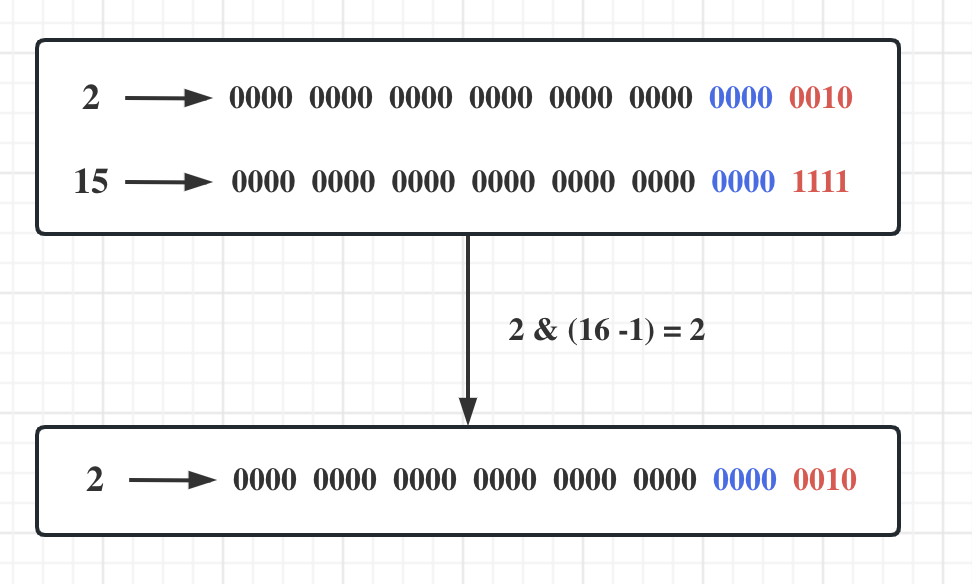
对于哈希来说,源码中采用了哈希容量为奇数,这样或许可以在取模的时候更加的分散,缓解冲突但并不能完全解决,极端场景仍然没有办法。下面改善一下扩容机制,当然这种方式也是可有可无的。
if (_tables.size() == _n)//扩容
{vector<Node*> newTables;//newTables.resize(2 * _tables.size(), nullptr);newTables.resize(__stl_next_prime(_tables.size()), nullptr);for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = Hash()(kot(cur->_data)) % newTables.size();// 头插到新表cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}inline unsigned long __stl_next_prime(unsigned long n)
{static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};for (int i = 0; i < __stl_num_primes; ++i){if (__stl_prime_list[i] > n){return __stl_prime_list[i];}}return __stl_prime_list[__stl_num_primes - 1];
}
当然,一旦数据过于驳杂,哈希桶挂的单链表改成红黑树是一个很好的解决方式。
相关文章:
【C++修炼之路】22.哈希
每一个不曾起舞的日子都是对生命的辜负 哈希一.哈希概念及性质1.1 哈希概念1.2 哈希冲突1.3 哈希函数二.哈希冲突解决2.1 闭散列/开放定址法2.2 开散列/哈希桶三.开放定址法代码3.1 插入Insert3.2 查找Find3.3 删除Erase3.4 映射的改良&完整代码四.开散列代码4.1 插入Inser…...
HashMap原理(一):哈希函数的设计
目录导航哈希函数的作用与本质哈希函数设计哈希表初始容量的校正哈希表容量为2的整数次幂的缺陷及解决办法注:为了简化代码,提高语义,本文将HashMap很多核心代码抽出并根据代码含义为代码片段取名,完全是为了方便读者理解。哈希函…...
06--WXS 脚本
1、简介WXS(WeiXin Script)是小程序的一套脚本语言,结合 WXML ,可以构建出页面的结构。 注意事项WXS 不依赖于运行时的基础库版本,可以在所有版本的小程序中运行。WXS 与 JavaScript 是不同的语言,有自己的…...
【Vue3】vue3 + ts 封装城市选择组件
城市选择-基本功能 能够封装城市选择组件,并且完成基础的显示隐藏的交互功能 (1)封装通用组件src/components/city/index.vue <script lang"ts" setup name"City"></script> <template><div class…...
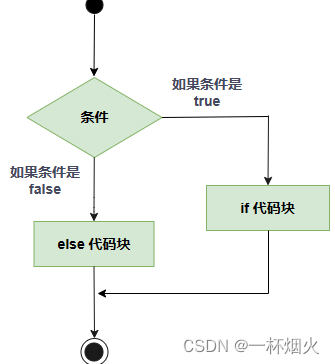
C语言if判断语句的三种用法
C if 语句 一个 if 语句 由一个布尔表达式后跟一个或多个语句组成。 语法 C 语言中 if 语句的语法: if(boolean_expression) {/* 如果布尔表达式为真将执行的语句 */ }如果布尔表达式为 true,则 if 语句内的代码块将被执行。如果布尔表达式为 false&…...

React中echarts的封装
做大屏的时候经常会遇到 echarts 展示 在 React (^18.2.0) 中对 echarts (^5.4.0) 的简单封装 echarts 封装使用 props 说明 参数说明类型可选值默认值opts初始化传入的 opts https://echarts.apache.org/zh/api.html#echarts…...

IV测试系统3A太阳能模拟器在光伏中应用
一、概述IV测试系统3A太阳能模拟器应具备光束准直、光斑均匀、辐照稳定、且与太阳光谱匹配的特点,使用户可足不出户的完成需要太阳光照条件的测试。科迎法电气提供多规格高品质的太阳模拟器,可适用于单晶硅、多晶硅、非晶硅、染料敏化、有机、钙钛矿等各…...
Vue 中过滤器 filter 使用教程
Vue 过滤器 filter 使用教程文章目录Vue 过滤器 filter 使用教程一、过滤器1.1 过滤器使用的背景1.2 格式化时间的不同实现1.3 过滤器的使用1.4 过滤器总结一、过滤器 1.1 过滤器使用的背景 过滤器提供给我们的一种数据处理方式。过滤器功能不是必须要使用的,因为它…...
源码numpy笔记
参考文章 numpy学习 numpy中的浅复制和深复制的详细用法 numpy中的np.where torch.gather() Numpy的核心数据结构,就叫做array就是数组,array对象可以是一维数组,也可以是多维数组 array本身的属性 shape:返回一个元组…...
【VUE】六 路由和传值
目录 一、 路由和传值 二、案例 三、案例存在无法刷新问题 一、 路由和传值 当某个组件可以根据某些参数值的不同,展示不同效果时,需要用到动态路由。 例如:访问网站看到课程列表,点击某个课程,就可以跳转到课程详…...

ChatGPT修炼指南和它的电力畅想
近期,ChatGPT刷屏各大社交平台,无疑成为人工智能界最靓的仔! 身为一款“会说话”的聊天机器人程序,它与前辈产品Siri、小度、微软小冰等有什么不同?先来听听小伙伴们怎么说。 ChatGPT何以修炼得这么强大?…...
基于vscode开发vue项目的详细步骤教程
1、Vue下载安装步骤的详细教程(亲测有效) 1_水w的博客-CSDN博客 2、Vue下载安装步骤的详细教程(亲测有效) 2 安装与创建默认项目_水w的博客-CSDN博客 目录 五、vscode集成npm开发vue项目 1、vscode安装所需要的插件: 2、搭建一个vue小页面(入门vue) 3、大致理解…...
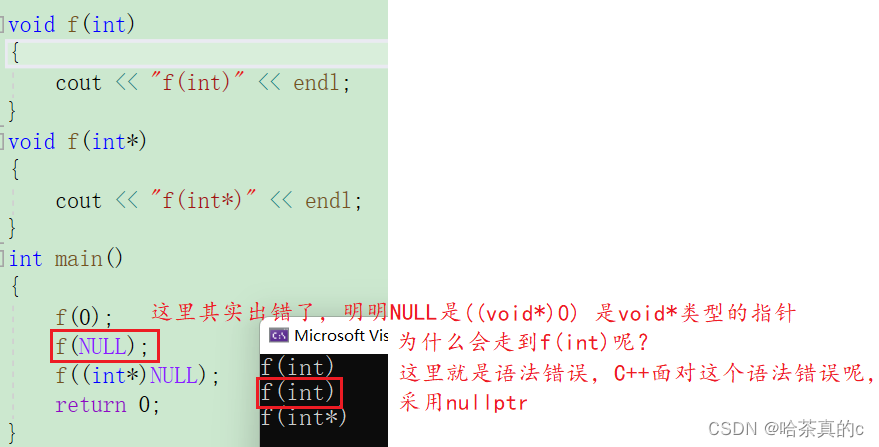
【C++初阶】1. C++入门
1. 前言 1. 什么是C C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的程序,需要高度的抽象和建模时,C语言则不合适。为了解决软件危机, 20世纪80年代, 计算机界提出了OOP(…...
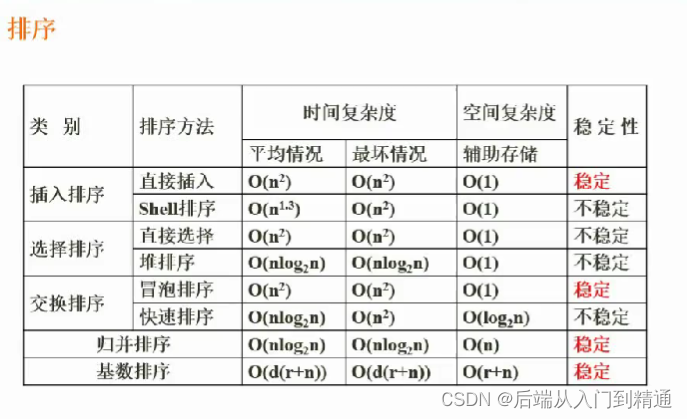
数据结构与算法(二十)快速排序、堆排序(四)
数据结构与算法(三)软件设计(十九)https://blog.csdn.net/ke1ying/article/details/129252205 排序 分为 稳定排序 和 不稳定排序 内排序 和 外排序 内排序指在内存里,外排序指在外部存储空间排序 1、排序的方法分类。 插入排序ÿ…...
)
TensorRT量化工具pytorch_quantization代码解析(二)
有些地方看的不是透彻,后续继续补充! 继续看张量量化函数,代码位于:tools\pytorch-quantization\pytorch_quantization\tensor_quant.py ScaledQuantDescriptor 量化的支持描述符:描述张量应该如何量化。QuantDescriptor和张量…...

buu [BJDCTF2020]easyrsa 1
题目描述 : from Crypto.Util.number import getPrime,bytes_to_long from sympy import Derivative from fractions import Fraction from secret import flagpgetPrime(1024) qgetPrime(1024) e65537 np*q zFraction(1,Derivative(arctan(p),p))-Fraction(1,Deri…...

taobao.user.openuid.getbyorder( 根据订单获取买家openuid )
¥免费不需用户授权 根据订单获取买家openuid,最大查询30个 公共参数 请求地址: HTTP地址 http://gw.api.taobao.com/router/rest 公共请求参数: 请求示例 TaobaoClient client new DefaultTaobaoClient(url, appkey, secret); UserOpenuidGetbyorderR…...
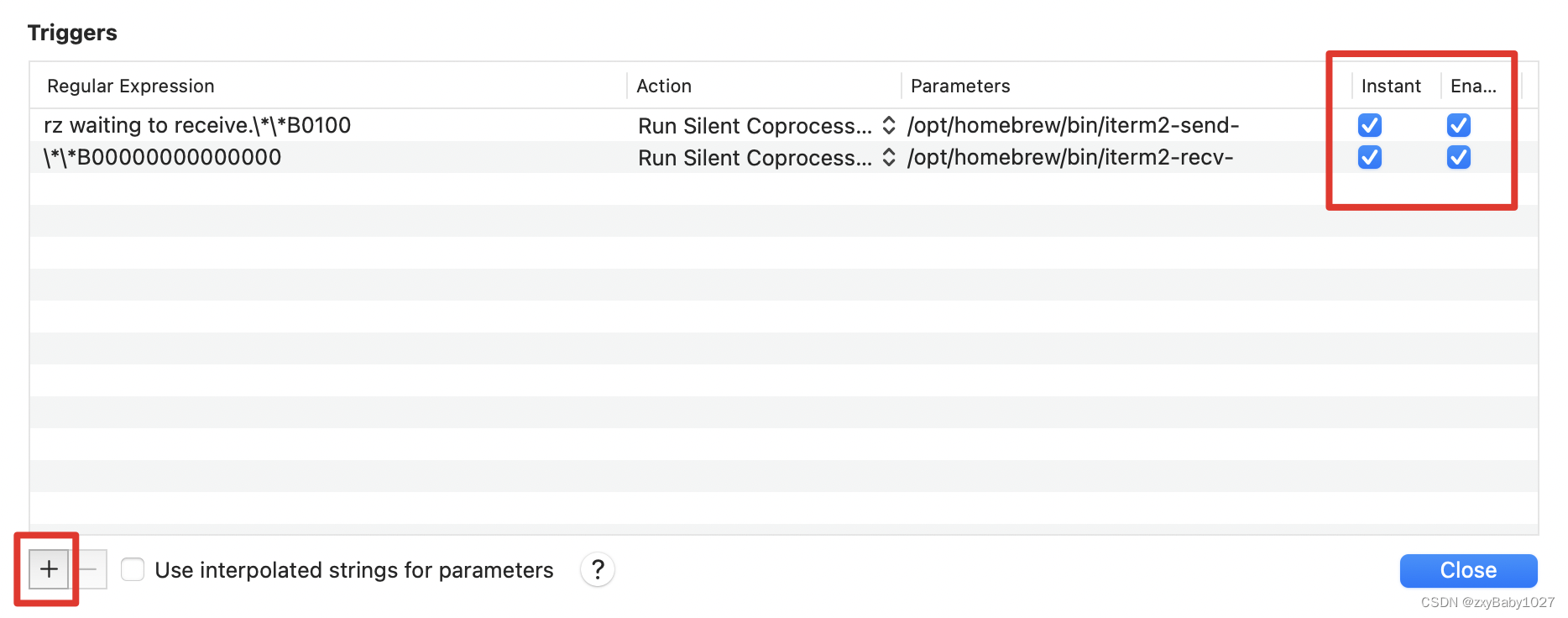
Mac iTerm2 rz sz
1、安装brew(找了很多🔗,就这个博主的好用) Mac如何安装brew?_行走的码农00的博客-CSDN博客_mac brew 2、安装lrzsz brew install lrzsz 检查是否安装成功 brew list 定位lrzsz的安装目录 brew list lrzsz 执…...
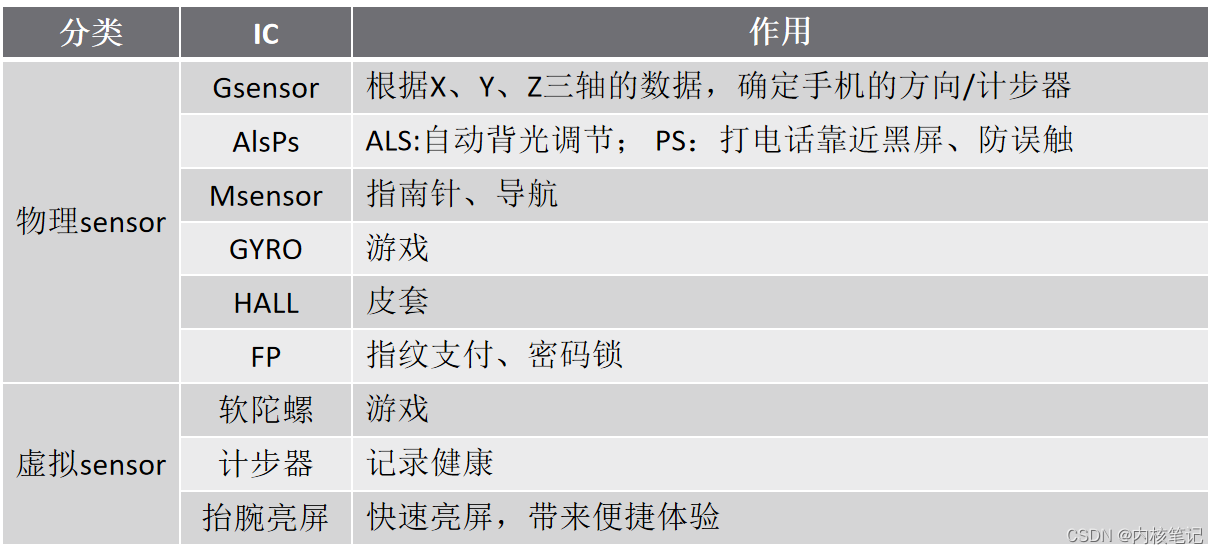
高通平台开发系列讲解(Sensor篇)Gsensor基础知识
文章目录 一、什么是SENSOR?二、Sensor的分类及作用三、Gsensor的工作原理及介绍3.1、常见Gsensor3.2、Gsensor的特性沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇文章将介绍 Sensor 基础 一、什么是SENSOR? 传感器(英文名称:sensor )是一种检测装置,能感…...

图像处理实战--Opencv实现人像迁移
前言: Hello大家好,我是Dream。 今天来学习一下如何使用Opencv实现人像迁移,欢迎大家一起参与探讨交流~ 本文目录:一、实验要求二、实验环境三、实验原理及操作1.照片准备2.图像增强3.实现美颜功能4.背景虚化5.图像二值化处理6.人…...
开发入门:技能创建与任务规划)
Qwen3-14B-Int4-AWQ智能体(Agent)开发入门:技能创建与任务规划
Qwen3-14B-Int4-AWQ智能体开发入门:技能创建与任务规划 1. 智能体开发初探 想象一下,你正在和一个数字助手对话,它不仅能够回答问题,还能主动规划并执行多步骤任务——比如先查询天气,然后根据温度推荐合适的穿搭&am…...

ollama-QwQ-32B模型微调指南:提升OpenClaw任务执行准确率
ollama-QwQ-32B模型微调指南:提升OpenClaw任务执行准确率 1. 为什么需要微调本地模型? 去年冬天,当我第一次用OpenClaw让AI帮我整理桌面文件时,发现它经常把PDF和Word文档混在一起。这让我意识到,通用大模型虽然强大…...

数据结构优化实战:提升MogFace-large后处理NMS算法效率
数据结构优化实战:提升MogFace-large后处理NMS算法效率 不知道你有没有遇到过这种情况:用MogFace-large模型跑人脸检测,模型本身的推理速度挺快,但最后出来的结果总感觉要“卡”那么一下。尤其是在那种人挤人的大合影或者监控视频…...

VCNL4200传感器驱动开发:I²C寄存器控制与中断实战
1. VCNL4200传感器驱动库技术解析与工程实践VCNL4200是Vishay公司推出的集成式环境光(ALS)与近距(Proximity)二合一传感器,采用8引脚QFN封装,内置红外LED发射器、光电二极管接收器、16位ADC、IC接口及可编程…...
Pixel Dimension Fissioner生产环境实践:日均万次调用下的稳定性与GPU优化策略
Pixel Dimension Fissioner生产环境实践:日均万次调用下的稳定性与GPU优化策略 1. 项目背景与挑战 Pixel Dimension Fissioner是一款基于MT5-Zero-Shot-Augment核心引擎构建的高端文本改写工具,其独特的16-bit像素冒险工坊设计风格为用户提供了全新的交…...

OpenClaw 是什么?普通人的 AI 贴身助理
你有没有想过,有一个 24 小时在线、随叫随到、什么都会的私人助理?OpenClaw 正在让这件事变成现实——而且它就运行在你自己的电脑上。先说一个真实的场景 早上 8 点,你还没起床,手机上发了一条消息:“帮我看看今天有没…...
)
WAN2.2文生视频效果展示:‘青花瓷纹样’提示词生成循环动画GIF(含导出设置)
WAN2.2文生视频效果展示:‘青花瓷纹样’提示词生成循环动画GIF(含导出设置) 想不想用一句话,就让静态的“青花瓷”纹样动起来,变成一段优雅的循环动画?今天,我们就来实测一下WAN2.2文生视频模型…...
translategemma-4b-it实战落地:与Notion API联动实现笔记截图自动翻译归档
translategemma-4b-it实战落地:与Notion API联动实现笔记截图自动翻译归档 1. 项目背景与价值 你有没有遇到过这样的情况:阅读英文资料时截取了大量有价值的截图,但时间一长就忘记了内容,或者需要分享给团队时还要手动翻译&…...

Z-Image-Turbo-辉夜巫女保姆级部署教程:Windows系统安装与配置全攻略
Z-Image-Turbo-辉夜巫女保姆级部署教程:Windows系统安装与配置全攻略 你是不是也眼馋那些AI生成的精美图片,但一看到复杂的Linux命令和服务器配置就头疼?别担心,今天咱们就来点不一样的。我手把手带你,在你自己最熟悉…...

http和https的了解
一、HTTP 核心解析 HTTP(HyperText Transfer Protocol,超文本传输协议)是客户端与服务器之间传输数据的应用层协议,是 Web 通信的基础。 1. HTTP 的核心特点特点说明优势 / 问题无状态服务器不记录客户端的请求上下文,…...