一文读懂PaddleSpeech中英混合语音识别技术

语音识别技术能够让计算机理解人类的语音,从而支持多种语音交互的场景,如手机应用、人车协同、机器人对话、语音转写等。然而,在这些场景中,语音识别的输入并不总是单一的语言,有时会出现多语言混合的情况。例如,在中文场景中,我们经常会使用一些英文专业术语来表达意思,如“GPS信号弱”、“Java工程师”等,这就给语音识别技术带来了新的挑战。
本次PaddleSpeech发布的中英文语音识别预训练模型Conformer_talcs可以通过PaddleSpeech封装的命令行工具CLI或者Python接口快速使用,开发者们可以基于此搭建自己的智能语音应用,也可以参考示例训练自己的中英文语音识别模型。
示例链接
https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/tal_cs/asr1
快速体验
示例音频
https://paddlespeech.bj.bcebos.com/PaddleAudio/ch_zh_mix.wav
使用命令行工具CLI 快速体验语音识别效果,命令如下:
bashpaddlespeech asr --model conformer_talcs --lang zh_en --codeswitch True --input ./ch_zh_mix.wav -v# 终端输出:今天是monday 明天是tuesdayPython 接口快速体验,代码实现如下:
python
>>> import paddle
>>> from paddlespeech.cli.asr import ASRExecutor
>>> asr_executor = ASRExecutor()
>>> text = asr_executor(model='conformer_talcs',lang='zh_en',sample_rate=16000,config=None, ckpt_path=None,audio_file='./ch_zh_mix.wav',codeswitch=True,force_yes=False,device=paddle.get_device())
>>> print('ASR Result: \n{}'.format(text))
ASR Result:
今天是 monday 明天是tuesday
中英文语音识别技术

中英文语音识别难点
中英文语音识别相较于单语言的语音识别而言,主要难点如下:
数据量少
中英混合数据相较于单语言的数据更少。目前开源的中文语音识别数据集如WenetSpeech(10000小时有监督,2500小时弱监督,10000小时无监督)、英文语音识别数据集Giga Speech(10000小时有监督,33000小时无监督)都达到了万小时级别,但是混合的开源中英文语音识别数据只有SEAME(120小时)和TAL_CSASR(587小时)两个开源数据,混合数据集比单语言数据集会更少。
中英相似发音易混淆
中英文语音识别需要一个单一的模型来学习多种语音,相似但具有不同含义的发音通常会导致模型的复杂度和计算量增加,同时由于它需要区分处理不同语言的类似发音,因此在模型建模时就需要按照不同语言区分不同的建模单元。

PaddleSpeech 中英文语音识别方案
模型选择与介绍
本方案使用了一种端到端语音识别模型Conformer U2模型,其采用了Joint CTC/Attention with Transformer or Conformer的结构。训练时使用CTC 和 Attention Loss 联合优化,并且通过dynamic chunk的训练技巧,使Shared Encoder能够处理任意大小的chunk(即任意长度的语音片段)。其还使用CTC-Prefix Beam Search和Attention Decoder的方式进行解码,得到最终结果,同时实现了流式和非流式的语音识别,支持控制推理延迟。
本次PaddleSpeech开源的预训练模型,是非流式的端到端识别Conformer U2模型,chunk中包含全部上下文信息,需要整句输入进行识别。如果你想训练流式中英文语音识别模型,也可以参考PaddleSpeech的Conformer U2/U2++模型流式语音识别的示例训练自己的流式中英文语音识别模型。
示例链接
https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/wenetspeech/asr1
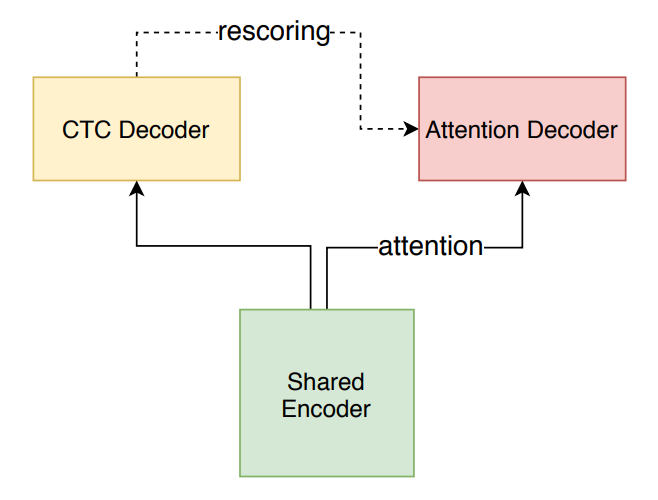
Conformer U2 结构示意图[1]
数据集介绍
本次使用了TAL_CSASR中英混合语音数据集。语音场景为语音授课音频,包括中英混合讲课的情况,总计587小时语音。
数据集下载地址
https://ai.100tal.com/dataset
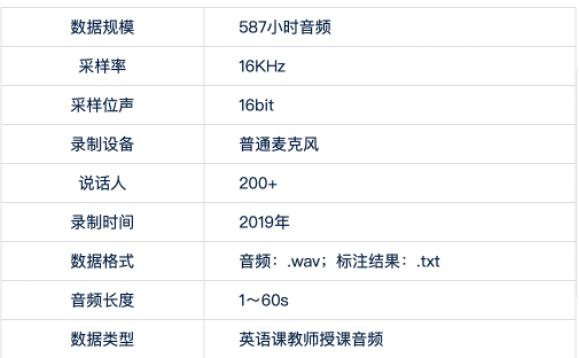
数据集介绍[2]
中英混合语音识别建模单元
在中文语音识别系统中,常采用音素、汉字、词等作为声学模型的建模单元,在英文语音识别系统中则常采用英文音素、国际音标、子词等作为声学模型的建模单元。
本次PaddleSpeech开源的预训练中英文语音识别模型是采用端到端语音识别模型Conformer U2,未接入语言模型,使用了中文字/词加英文子词的建模方法,将中英文分开建模,通过模型推理,直接得到识别后的结果。

试验结果对比
由于本项目使用的是中英文混合数据集,所以我们选择混合错误率(MER,Mix Error Rate)作为评价指标,中文部分计算字错误率(CER,Character Error Rate),英文部分计算词错误率(Word Error Rate)。测试数据集选择TAL_CSASR中已经划分好的测试集。由于不同的解码方式识别的效果不同,这里我们使用 Attention、CTC Greedy Search、CTC Prefix Beam Search、Attention Rescoring 四种解码方式进行试验,解码效果最佳为Attention Rescoring,混合错误率MER为0.084,折算为我们常说的语音识别正确率91.6%。
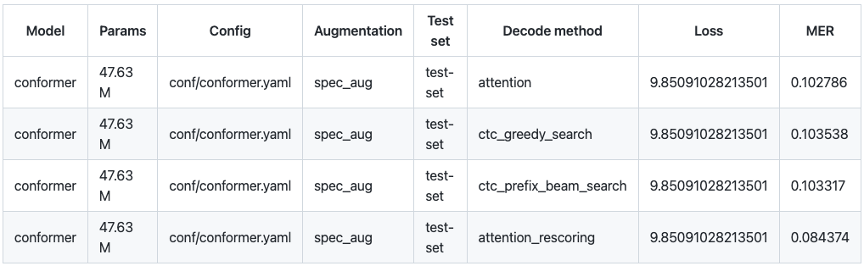
进一步优化与效果提升
当前中英文语音识别方案的效果还有进一步提升的空间,比如在Conformer U2 模型后面加入Language Model,通过语言模型学习中英文语言信息,PaddleSpeech中提供了基于N-Gram的语言模型训练方案。此外,可以在训练过程中加入Language ID,使用token级别或者帧级别的语言ID标注信息,可以进一步提高中英文语音识别的效果。如果你有更大的中英文混合数据集或者是场景相关的数据集,可以通过微调或者进一步训练,提高在业务场景中的识别效果。

PaddleSpeech 语音识别技术介绍
除了中英文混合的Conformer U2模型以外,飞桨语音模型库PaddleSpeech中包含了多种语音识别模型,能力涵盖了声学模型、语言模型、解码器等多个环节,支持多种语言。目前PaddleSpeech已经支持的语音识别声学模型包括DeepSpeech2、Transfromer、Conformer U2/U2 ++,支持中文和英文的单语言识别以及中英文混合识别;支持CTC前束搜索(CTC Prefix Beam Search)、CTC贪心搜索(CTC Greedy Search)、注意力重打分(Attention Rescoring)等多种解码方式;支持 N-Gram语言模型、有监督多语言大模型Whisper、无监督预训练大模型wav2vec2;同时还支持服务一键部署,可以快速封装流式语音识别和非流式语音识别服务。通过PaddleSpeech提供的命令行工具CLI和Python接口可以快速体验上述功能。
通过PaddleSpeech精品项目合集,可以在线体验PaddleSpeech的优秀项目,上面更有PaddleSpeech核心开发者精心打造的《飞桨PaddleSpeech语音技术课程》,帮助开发者们快速入门。
项目传送门
https://aistudio.baidu.com/aistudio/projectdetail/4692119?contributionType=1

如果您想了解更多有关PaddleSpeech的内容,欢迎前往PaddleSpeech主页学习更多用法,Star 关注,获取PaddleSpeech最新资讯。
PaddleSpeech地址
https://github.com/PaddlePaddle/PaddleSpeech

引用
[1] 模型结构图
https://arxiv.org/pdf/2012.05481.pdf
[2] 数据集介绍
https://ai.100tal.com/dataset
拓展阅读
提速300%,PaddleSpeech 语音识别高性能部署方案重磅来袭
定制音库成本骤降98%,PaddleSpeech小样本语音合成方案重磅来袭

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
相关文章:
一文读懂PaddleSpeech中英混合语音识别技术
语音识别技术能够让计算机理解人类的语音,从而支持多种语音交互的场景,如手机应用、人车协同、机器人对话、语音转写等。然而,在这些场景中,语音识别的输入并不总是单一的语言,有时会出现多语言混合的情况。例如&#…...

问题三十四:傅立叶变换——高通滤波
高通滤波器是一种可以通过去除图像低频信息来增强高频信息的滤波器。在图像处理中,高通滤波器常常用于去除模糊或平滑效果,以及增强边缘或细节。在本篇回答中,我们将使用Python和OpenCV实现高通滤波器。 Step 1:加载图像并进行傅…...
)
flink 键控状态(keyed state)
github开源项目flink-note的笔记。本博客的实现代码都写在项目的flink-state/src/main/java/state/keyed/KeyedStateDemo.java文件中。 项目github地址: github 1. flink键控状态 flink键控状态是作用与flink KeyedStream上的,也就是说需要将DataStream先进行keyby之后才能使…...
【ChatGPT】sqlachmey 多表连表查询语句
感受下科技带来的魅力,这篇文章是通过ChatGPT自动生成的,不得不说技术强大!!! 在SQLAlchemy中进行多表连接查询可以使用join()方法或join()函数,具体用法如下: join()方法 join()方法可以在SQLAlchemy ORM中的查询中使用。假设…...

win11 系统登录问题,PIN 设置问题
我的电脑配置是华为MateBook X Pro 12,i7处理器,16G,1T,win11 系统通过微软账户登录,下午一直登录不进去,网络能连外网,分析应该是连微软服务器不行。连续登录几十次,偶尔可能有一次…...
数据结构六大排序
1.插入排序 思路: 从第一个元素开始认为是有序的,去一个元素tem从有序序列从后往前扫描,如果该元素大于tem,将该元素一刀下一位,循环步骤3知道找到有序序列中小于等于的元素将tem插入到该元素后,如果已排序…...

快速生成QR码的方法:教你变成QR Code Master
目录 简介: 具体实现步骤: 一、可以使用Python中的qrcode和tkinter模块来生成QR码。以下是一个简单的例子,演示如何在Tkinter窗口中获取用户输入并使用qrcode生成QR码。 1)首先需要安装qrcode模块,可以使用以下命令在终端或命令…...

tensorflow1.14.0安装教程--保姆级
//方法不止一种,下面仅展示一种。 注:本人电脑为win11,anaconda的python版本为3.9,但tensorflow需要python版本为3.7,所以下面主要阐述将python版本改为3.7后的安装过程以及常遇到的问题。 1.首先电脑安装好anaconda…...

AcWing算法提高课-3.1.3香甜的黄油
宣传一下算法提高课整理 <— CSDN个人主页:更好的阅读体验 <— 题目传送门点这里 题目描述 农夫John发现了做出全威斯康辛州最甜的黄油的方法:糖。 把糖放在一片牧场上,他知道 N 只奶牛会过来舔它,这样就能做出能卖好价…...

私库搭建1:Nexus 安装 Docker 版
本文内容以语雀为准 文档 https://hub.docker.com/r/sonatype/nexus3Docker 安装:https://www.yuque.com/xuxiaowei-com-cn/gitlab-k8s/docker-install 安装 创建文件夹 由于 Nexus 的数据可能会很大,比如:作为 Docker、Maven 私库时&…...

LeetCode-面试题 05.02. 二进制数转字符串【数学,字符串,位运算】
LeetCode-面试题 05.02. 二进制数转字符串【数学,字符串,位运算】题目描述:解题思路一:简单暴力。小数点后面的二进制,now首先从0.5开始之和每次除以2。然后依次判断当前数是否大于now,是则答案加1。若等于…...
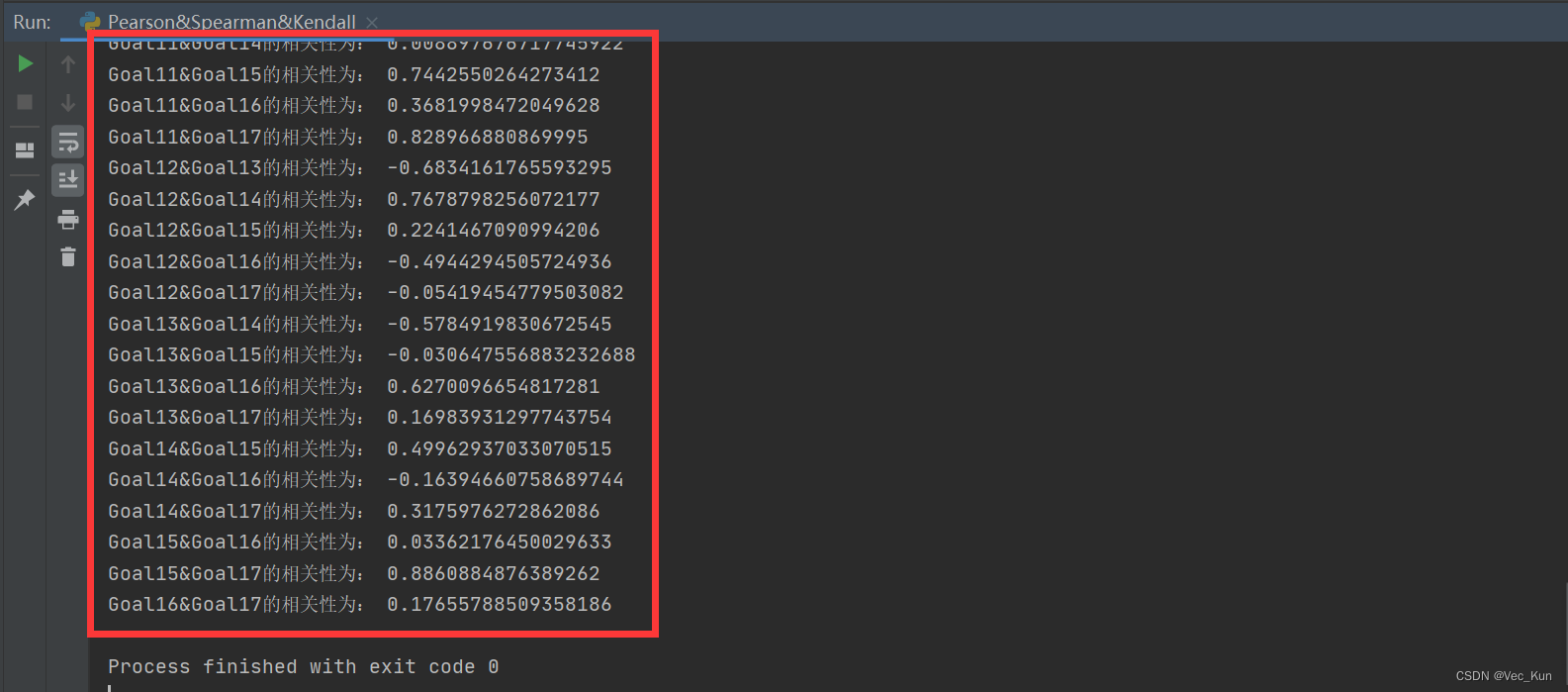
pandas: 三种算法实现递归分析Excel中各列相关性
目录 前言 目的 思路 代码实现 1. 循环遍历整个SDGs列,两两拿到数据 2. 调用pandas库函数直接进行分析 完整源码 运行效果 总结 前言 博主之前刚刚被学弟邀请参与了2023美赛,这也是第一次正式接触数学建模竞赛,现在已经提交等待结果…...

【Python百日进阶-Web开发-Vue3】Day543 - Vue3 商城后台 03:登录页面初建
文章目录 一、创建登录页面 login.vue二、登录页面响应式处理,以适应不同大小的屏幕2.1 element-plus 的layout布局中关于响应式的说明2.2 修改login.vue文件2.2.1 :lg=16 大于1200px 横排 2:12.2.2 :md=12 大于992小于1200px 横排 1:12.2.3 小于992 竖排三、引入Element-plus…...
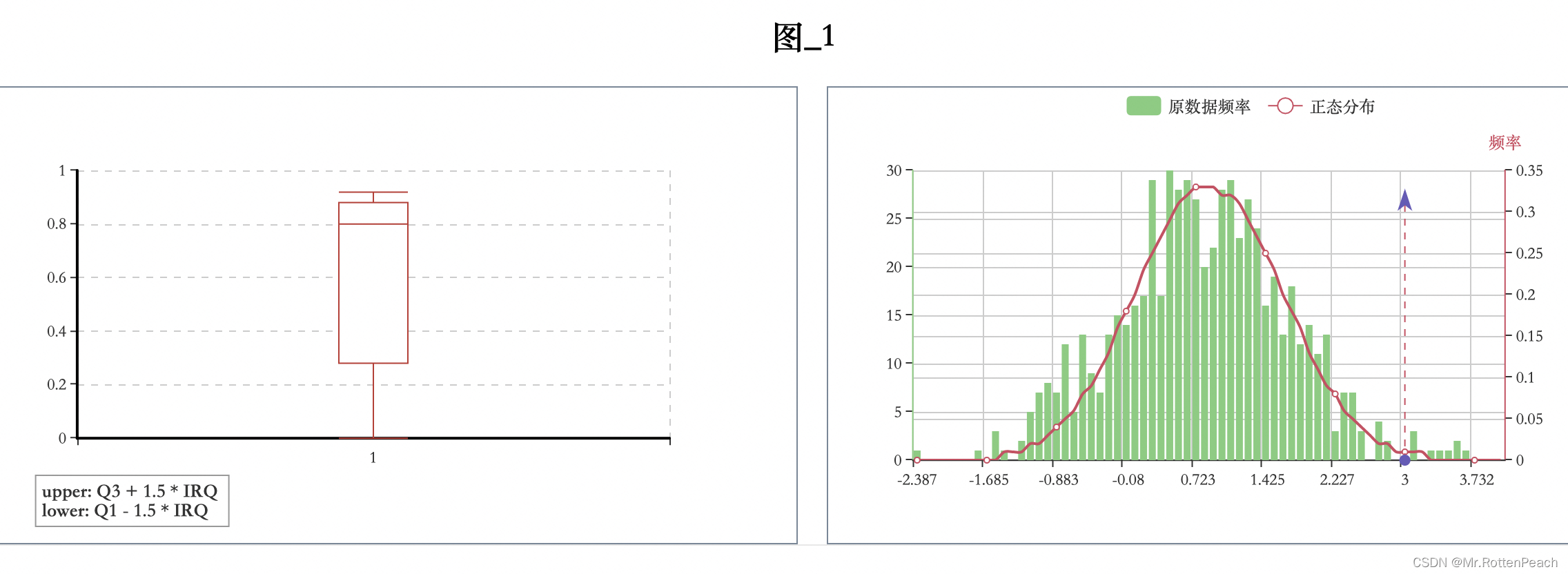
python画直方图,刻画数据分布
先展示效果 准备一维数据 n 个数据元素计算最大值,最小值、均值、标准差、以及直方图分组 import numpy as np data list() for i in range(640):data.append(np.random.normal(1)) print(data)z np.histogram(data, bins64) print(list(z[0])) ### 对应 x 轴数据…...
【学数学关键是要学会在什么情况下,知道使用什么工具。】)
几何学小课堂:非欧几何(广义相对论采用黎曼几何作为数学工具)【学数学关键是要学会在什么情况下,知道使用什么工具。】
文章目录 引言I 非欧几何1.1 黎曼几何1.2 共形几何1.3 罗氏几何II 黎曼几何的应用2.1 广义相对论2.2 超弦III 理解不同的几何体系的共存3.1 更扎实的欧氏几何3.2 殊途同归引言 公理有错会得到两种情况: 如果某一条自己设定的新公理和现有的公理相矛盾,那么相应的知识体系就建…...

Ubuntu配置静态IP的方法
Ubuntu配置静态IP的方法前言一、查看虚机分配的网卡IP二、查看网卡的网关IP三、配置静态IP1.配置IPv4地址2.执行netplan apply使改动生效3.配置的网卡未生效,修改50-cloud-init.yaml文件解决4.测试vlan网络通信总结前言 Ubuntu18.04 欧拉环境 vlan网络支持ipv6场景…...

90%的人都不算会爬虫,这才是真正的技术,从0到高手的进阶
很多人以为学会了urlib模块和xpath等几个解析库,学了Selenium就会算精通爬虫了,但到外面想靠爬虫技术接点私活,才发现寸步难行。 龙叔我做了近20年的程序员,今天就告诉你,真正的爬虫高手应该学哪些东西,就…...

排序之损失函数List-wise loss(系列3)
排序系列篇: 排序之指标集锦(系列1)原创 排序之损失函数pair-wise loss(系列2)排序之损失函数List-wise loss(系列3) 最早的关于list-wise的文章发表在Learning to Rank: From Pairwise Approach to Listwise Approach中,后面陆陆续续出了各种变形&#…...

js对象和原型、原型链的关系
JS的原型、原型链一直是比较难理解的内容,不少初学者甚至有一定经验的老鸟都不一定能完全说清楚,更多的"很可能"是一知半解,而这部分内容又是JS的核心内容,想要技术进阶的话肯定不能对这个概念一知半解,碰到…...
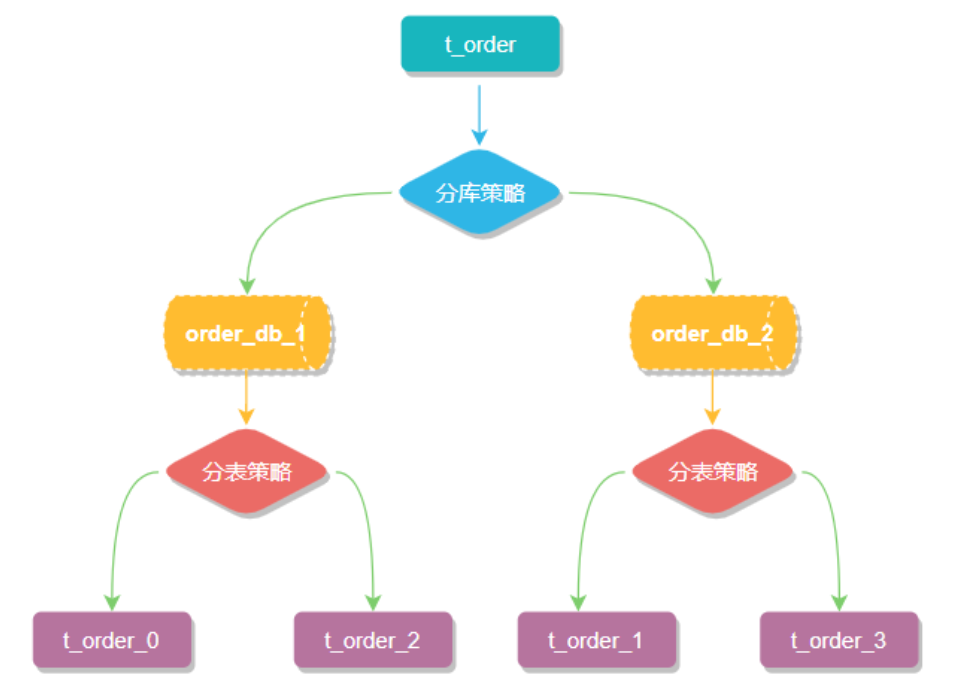
【SpringBoot高级篇】SpringBoot集成Sharding-JDBC分库分表
【SpringBoot高级篇】SpringBoot集成Sharding-JDBC分库分表Apache ShardingSphere分库分表分库分表的方式垂直切分垂直分表垂直分库水平切分水平分库水平分表分库分表带来的问题分库分表中间件Sharding-JDBCsharding-jdbc实现水平分表sharding-jdbc实现水平分库sharding-jdbc实…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...