postgresql_conf中常用配置项
在 PostgreSQL 的 postgresql.conf 配置文件中,有许多常用的配置项,这些配置项可以根据特定需求和性能优化进行调整。以下是一些常用的配置项及其作用:
1. shared_buffers
用于设置 PostgreSQL 实例使用的共享内存缓冲区大小。增加此值可以提高对常用数据的访问速度,但设置过高可能影响其他系统资源。
shared_buffers 是 PostgreSQL 中一个重要的配置参数,它用于指定分配给 PostgreSQL 实例使用的共享内存缓冲区大小。这些缓冲区被用来存储从磁盘读取的数据页的副本,以便在需要时能够更快地访问数据,从而提高数据库的性能。
这个参数的设置对于 PostgreSQL 数据库系统的性能和效率至关重要。增大 shared_buffers 可以提高对数据的访问速度,因为更多的数据可以在内存中找到,而不必频繁地从磁盘中读取。然而,设置过大可能会导致系统内存竞争和其他资源问题。
一些关键点关于 shared_buffers 的设置和工作原理:
-
设置大小: 通常建议将
shared_buffers设置为系统可用内存的一部分,但并不是将可用内存的大部分都分配给这个参数。通常建议将其设置为总内存的 25% - 40%。 -
影响性能: 增加
shared_buffers的值可以提高对常用数据的访问速度,尤其是针对频繁访问的数据。这可以减少从磁盘读取数据的需求,从而提高查询性能。 -
内存竞争: 设置过大的
shared_buffers值可能会导致内存竞争和数据库性能问题。这是因为 PostgreSQL 实例不是唯一使用系统内存的进程,其他系统进程和应用程序也需要内存。 -
动态修改: 通常需要重启 PostgreSQL 实例才能应用对
shared_buffers的更改。动态修改shared_buffers的方式会因为重新分配内存而导致性能波动,因此建议在维护窗口或者低负载时进行。 -
性能监控: 监控数据库性能指标可以帮助判断是否需要调整
shared_buffers的大小。监视磁盘 I/O、缓存命中率、查询响应时间等指标,以确定是否需要优化内存配置。 -
其他缓存层:
shared_buffers只是 PostgreSQL 数据库的一部分缓存。操作系统和文件系统也会使用缓存来存储数据。effective_cache_size参数可以帮助 PostgreSQL 了解操作系统级别的缓存大小。
综上所述,shared_buffers 是 PostgreSQL 中一个关键的性能调优参数,适当设置可以提高数据库的性能。但是,需要根据实际情况进行测试和监控,以确保最佳的配置值。
2. work_mem
控制每个排序操作或哈希表操作可使用的内存量。增加此值可提高排序和哈希操作的性能,但每个连接的内存使用量也会增加。
work_mem 是 PostgreSQL 中一个用于控制每个数据库会话可用于内部排序操作和哈希表操作的内存量的配置参数。这个参数决定了在执行诸如排序、哈希连接、聚合等需要临时存储空间的操作时,每个数据库连接可以使用的最大内存量。
以下是关于 work_mem 参数的详细描述和一些重要信息:
-
作用:
work_mem决定了每个数据库会话(每个连接)用于内部排序和哈希表操作的内存量。较大的值可以提高排序和哈希操作的性能,因为更多的数据可以在内存中处理而不必写入磁盘临时文件。但是,过大的值可能会占用过多的内存资源,导致系统内存压力增大。 -
单位: 默认单位是 KB(千字节),但可以使用其他单位(MB、GB)进行设置。例如,
work_mem = 4MB表示每个数据库连接可使用的内存量为 4MB。 -
内存分配: 每个数据库连接都会独立分配其设置的
work_mem内存量。这意味着,当有多个并发的查询操作时,每个查询都可以使用work_mem设置的内存。 -
排序和哈希操作:
work_mem适用于排序操作(例如 ORDER BY 或 DISTINCT)以及哈希表操作(例如哈希连接或聚合操作)。较大的work_mem值可以改善排序和哈希操作的性能,尤其是在处理大量数据时。 -
动态修改:
work_mem的修改可以在运行时生效,无需重新启动 PostgreSQL 实例。但是,修改的过程中可能会有内存重新分配的开销,可能会导致瞬时的性能波动。 -
资源消耗和建议值: 合理设置
work_mem取决于系统的可用内存和数据库工作负载。建议根据实际情况和负载进行调整。通常,较大的系统可用内存可以支持较大的work_mem设置。 -
监控和性能调优: 监控内存使用情况和查询性能,特别是与排序和哈希操作相关的查询,以确定最佳的
work_mem设置。在查询执行计划中也可以查看是否使用了内存排序或哈希表来优化查询。
综上所述,work_mem 是用于控制每个数据库连接可用于内部排序和哈希操作的内存量的重要参数。合理设置这个参数可以改善排序和哈希操作的性能,但需要根据实际情况进行测试和监控。
3. maintenance_work_mem
用于设置维护任务(如索引重建、VACUUM等)所需的最大内存量。增加此值可以加快这些维护任务的执行速度。
maintenance_work_mem 是 PostgreSQL 中一个重要的配置参数,用于控制数据库维护任务(如索引重建、VACUUM 等)所需的最大内存量。这个参数指定了在执行数据库维护任务时,每个并行运行的工作进程(或者每个 VACUUM 进程)可以使用的最大内存量。
以下是关于 maintenance_work_mem 参数的详细描述和一些重要信息:
-
作用:
maintenance_work_mem用于控制诸如 VACUUM、索引重建、CLUSTER 等维护操作所需的内存量。这些维护操作通常需要对数据库进行重组或者清理,maintenance_work_mem决定了在执行这些操作时所使用的最大内存量。 -
单位: 默认单位是 KB(千字节),但可以使用其他单位(MB、GB)进行设置。例如,
maintenance_work_mem = 256MB表示每个并行运行的维护操作可使用的最大内存量为 256MB。 -
维护操作: 维护操作(例如 VACUUM、REINDEX、CLUSTER 等)通常需要执行大量的磁盘和内存操作来重组或清理数据。较大的
maintenance_work_mem值可以加快这些操作的执行速度,尤其是在处理大型表时。 -
动态修改: 与
work_mem相似,maintenance_work_mem的修改也可以在运行时生效,无需重新启动 PostgreSQL 实例。但增大此值可能导致系统内存竞争和其他资源问题。 -
建议值: 合理设置
maintenance_work_mem取决于系统的可用内存和数据库工作负载。一般来说,对于较大的数据库或者需要频繁进行维护操作的环境,增加maintenance_work_mem可以提高维护操作的执行速度。 -
监控和性能调优: 监控维护操作的执行时间以及内存使用情况,根据需要调整
maintenance_work_mem的设置。同时,也需要注意监控系统的其他资源使用情况,避免因为增大maintenance_work_mem而影响其他系统进程和应用程序的正常运行。
maintenance_work_mem 参数在执行数据库维护任务时发挥着重要作用,可以加快这些操作的执行速度。但是,与其他配置参数一样,需要根据实际情况进行测试和监控,以确定最佳的设置值。
4. effective_cache_size
effective_cache_size 是 PostgreSQL 中的一个重要配置参数,它用于向查询优化器提供关于系统中可用缓存的估计信息。该参数不代表实际内存量,而是用于告知 PostgreSQL 查询规划器系统中可用的磁盘缓存和操作系统级别的文件系统缓存的大小。
以下是关于 effective_cache_size 参数的详细描述和其作用:
-
作用:
effective_cache_size参数用于向 PostgreSQL 查询规划器提供有关系统中可用缓存的估计信息。这个参数指导优化器估算特定查询所需的成本,并选择最佳的查询执行计划。 -
单位和设置值: 默认单位为页(通常是 8KB)。你可以设置
effective_cache_size参数为一个适当的大小的值,例如:effective_cache_size = 4GB,表示系统中大约有 4GB 的缓存可用于数据块的读取。 -
影响查询优化器的决策: 优化器使用
effective_cache_size参数来估计磁盘 I/O 操作的成本。如果该值设置得较大,优化器可能会认为系统有更多的数据在缓存中,从而可能更倾向于选择全表扫描而不是索引扫描,因为全表扫描可能更快。相反,设置过小可能会导致优化器更倾向于选择索引扫描。 -
动态修改: 可以动态修改
effective_cache_size参数而不需要重新启动 PostgreSQL 实例,但这仍需要重新加载配置文件才能生效。 -
性能监控和调优: 调整
effective_cache_size参数可能影响查询优化器对索引扫描、排序、连接等操作的成本估算,因此需要仔细监控系统性能变化。监控查询执行计划和性能指标,以确保调整后的参数能够提升系统的整体性能。 -
适当的设置: 合理设置
effective_cache_size取决于实际的硬件资源、负载情况以及数据库工作负载等因素。通常需要进行实际测试和性能监控来确定最佳的配置值。
综上所述,effective_cache_size 参数在 PostgreSQL 中对于优化器的查询执行计划选择非常重要。合理设置这个参数可以帮助优化器更准确地估算查询成本,选择更有效的执行计划,提高查询性能。然而,调整这个参数时最好在测试环境中进行,并需要仔细监控系统性能的变化,以确定最佳的配置值。
5. checkpoint_completion_target
控制检查点完成时写入的目标量(以检查点期间完成的工作的百分比)。较低的值可以减少检查点期间的 I/O 负载,但可能会增加检查点持续时间。
checkpoint_completion_target 是 PostgreSQL 中一个用于控制检查点完成时写入的目标量的配置参数。该参数控制了检查点进程在完成检查点时写入的量,通常以检查点期间完成的工作的百分比来表示。
以下是关于 checkpoint_completion_target 参数的详细描述和其作用:
-
作用:
checkpoint_completion_target用于控制检查点进程在完成检查点时写入的目标量。它表示检查点期间完成的工作的百分比量。较低的值意味着检查点进程在完成检查点时会写入较少的数据,而较高的值会导致更多的数据写入。 -
设置范围:
checkpoint_completion_target的值介于 0 和 1 之间。0 表示检查点时不写入任何数据,1 表示检查点完成时写入所有工作量。 -
对数据库性能的影响: 较低的
checkpoint_completion_target值可以减少检查点期间的磁盘 I/O 压力,因为它减少了在完成检查点时写入磁盘的数据量。但是较低的值可能会导致更频繁的检查点,从而增加了检查点的数量和对系统性能的影响。较高的值可以减少检查点的频率,但会增加每次检查点的写入量。 -
动态修改: 可以在运行时动态修改
checkpoint_completion_target参数,而不需要重新启动 PostgreSQL 实例。修改此参数会影响后续检查点的行为。 -
适当的设置: 合理设置
checkpoint_completion_target取决于系统的硬件配置、磁盘 I/O 性能、数据库工作负载等因素。通常需要进行实际测试和性能监控来确定最佳的配置值。 -
性能监控和调优: 监控系统的磁盘 I/O、检查点频率以及查询执行时间等指标,以确定最佳的
checkpoint_completion_target设置。此参数的调整可能需要根据数据库工作负载和系统性能进行优化。
综上所述,checkpoint_completion_target 参数在 PostgreSQL 中用于控制检查点进程完成时写入的目标量,从而影响了检查点的频率和对系统的影响。合理设置这个参数可以在磁盘 I/O 和系统性能之间寻找一个平衡点,以提高数据库的性能和稳定性。
6. max_connections
设置允许的最大客户端连接数量。需要注意的是,每个连接都会占用一定的系统资源,因此需要权衡资源和连接数。
7. autovacuum
自动执行 VACUUM 和 ANALYZE 操作来管理表和索引的空间,保持性能的参数设置。
autovacuum 是 PostgreSQL 中的一个功能,用于自动执行 VACUUM 和 ANALYZE 操作来管理数据库表和索引的空间以及维护统计信息。
以下是关于 autovacuum 的详细描述和其作用:
-
作用: PostgreSQL 中的
autovacuum功能用于自动执行 VACUUM 和 ANALYZE 操作。VACUUM 用于回收已删除行所占用的空间并防止数据的物理膨胀,而 ANALYZE 用于更新数据库表和索引的统计信息,帮助查询优化器生成更好的执行计划。 -
空间回收和性能: 定期执行 VACUUM 操作可以回收表中被删除行所占用的空间,避免表的物理膨胀。这有助于保持数据库性能,防止长时间运行后出现性能下降的情况。
-
统计信息更新: ANALYZE 操作更新表和索引的统计信息,这些统计信息对于查询优化器决定最佳查询执行计划至关重要。通过保持这些统计信息的最新,数据库可以更有效地执行查询。
-
自动触发:
autovacuum是自动触发的,它会监视数据库中的表,并根据需要执行 VACUUM 和 ANALYZE 操作。它会根据数据库中数据的变化情况和统计信息的更新情况来决定执行操作的时机。 -
参数配置: PostgreSQL 提供了一些参数来调整
autovacuum的行为,例如:autovacuum_vacuum_threshold、autovacuum_analyze_threshold等,可以设置触发 VACUUM 和 ANALYZE 操作的阈值。 -
系统资源和性能影响:
autovacuum可能会占用系统资源,特别是在大型数据库中,频繁执行 VACUUM 和 ANALYZE 可能会影响数据库性能。因此,需要合理配置参数以平衡维护和性能。 -
监控和调优: 监控数据库的空间使用情况、统计信息的更新情况以及
autovacuum进程的活动,根据实际情况调整相关参数以及执行计划。
综上所述,autovacuum 是 PostgreSQL 中一个重要的自动化维护功能,它通过自动执行 VACUUM 和 ANALYZE 操作来管理数据库表和索引的空间以及保持统计信息的最新,从而维护数据库的性能和稳定性。合理配置和监控 autovacuum 是维护大型数据库健康运行的重要步骤。
8. log_min_duration_statement
控制记录在日志中的最小查询执行时间。这对于诊断和性能优化很有用。
log_min_duration_statement 是 PostgreSQL 中用于配置日志记录的参数之一,它指定了记录到日志的查询的最小执行时间阈值。这个参数用于控制是否将执行时间超过指定阈值的 SQL 查询记录到 PostgreSQL 的日志文件中。
以下是关于 log_min_duration_statement 参数的详细描述和其作用:
-
作用:
log_min_duration_statement用于控制在日志中记录哪些执行时间超过特定阈值的 SQL 查询。只有执行时间超过指定阈值的查询语句才会被记录到日志中。 -
单位和设置值: 默认单位是毫秒(ms),可以设置一个时间阈值,例如:
log_min_duration_statement = 500,表示超过 500 毫秒(0.5 秒)执行的 SQL 查询语句将被记录到日志中。 -
日志记录级别: 参数有不同的设置选项:
log_min_duration_statement = -1(默认值):不记录任何查询语句到日志中。log_min_duration_statement = 0:记录所有查询语句到日志中。log_min_duration_statement = N(N为毫秒数):记录执行时间超过 N 毫秒的查询语句到日志中。
-
性能影响: 较低的阈值会导致更多的查询被记录到日志中,可能会增加日志文件大小,因此需要注意磁盘空间的使用。同时,开启日志记录可能会轻微影响查询性能。
-
监控和诊断: 通过设置合适的阈值,可以监控和诊断执行时间较长的查询。这有助于识别潜在的性能瓶颈和优化数据库查询。
-
生产环境中的使用: 在生产环境中,通常会根据需要设置一个合适的
log_min_duration_statement阈值,以便在需要时记录执行时间较长的查询,并避免不必要的日志记录。 -
注意事项: 日志记录所有查询可能会泄露敏感信息,因此在生产环境中要慎重考虑设置为记录所有查询。
综上所述,log_min_duration_statement 参数是用于控制是否将执行时间超过指定阈值的 SQL 查询记录到 PostgreSQL 日志中的重要配置项。适当设置这个参数可以帮助监控和诊断数据库中执行时间较长的查询,并有助于优化数据库性能。
9. listen_addresses 和 port
控制 PostgreSQL 服务器监听的 IP 地址和端口号。
listen_addresses 和 port 是 PostgreSQL 数据库配置中用于控制服务器监听地址和端口的参数。
-
listen_addresses:
listen_addresses用于指定 PostgreSQL 数据库服务器监听的地址。它决定了哪些网络接口和 IP 地址可以连接到 PostgreSQL 服务器。- 默认情况下,
listen_addresses被设置为localhost,表示只有本地连接才被接受。如果需要允许来自其他主机的连接,则可以设置为合适的 IP 地址或者'*'(表示接受来自所有网络接口的连接)。 - 示例:
listen_addresses = '*',表示接受来自所有网络接口的连接。
-
port:
port参数用于指定 PostgreSQL 服务器监听的端口号。默认端口号为 5432。- 如果在同一台主机上运行多个 PostgreSQL 实例,可以为每个实例指定不同的端口号以避免冲突。
- 示例:
port = 5432,表示 PostgreSQL 服务器监听在默认的 5432 端口上。
这两个参数一起控制了 PostgreSQL 服务器接受连接的方式和端口号。合理配置 listen_addresses 和 port 参数是确保 PostgreSQL 服务器能够正常接受远程连接并以安全方式运行的重要步骤。
需要注意的是,在允许远程连接时,必须确保网络连接是安全的,并采取适当的措施来防止未经授权的访问。例如,可以使用防火墙、访问控制列表(ACL)或者其他安全措施来限制远程访问 PostgreSQL 数据库。
10. logging_collector
控制日志收集器的启用与禁用。当启用时,它负责收集日志消息并将其写入日志文件中。
logging_collector 是 PostgreSQL 中用于控制日志收集方式的配置参数。它决定了是否启用 PostgreSQL 的日志收集器进程,以及日志消息是写入到文件还是通过其他方式处理。
以下是关于 logging_collector 参数的详细描述和其作用:
-
作用:
logging_collector控制是否启用 PostgreSQL 的日志收集器进程。当启用时,该进程负责收集数据库服务器产生的日志消息,并将其写入到日志文件中。 -
默认设置: 默认情况下,
logging_collector参数被设置为关闭状态(通常为off)。这意味着 PostgreSQL 将不会使用日志收集器进程来管理日志消息。 -
日志文件: 当
logging_collector设置为启用时(通常为on),PostgreSQL 会将日志消息写入到指定的日志文件中。可以使用log_directory参数指定日志文件的保存路径。 -
日志级别: 日志收集器会记录各种级别的消息,包括错误、警告、信息和调试消息。你可以使用
log_min_messages参数来设置日志记录的消息级别。 -
日志格式和设置: 可以通过
log_line_prefix参数来配置日志条目的格式,包括时间戳、进程ID、用户名等信息。此外,还可以使用其他参数来控制日志的滚动、保留时间等设置。 -
性能影响: 启用日志收集器可能会轻微增加数据库服务器的负载,因为它需要处理和写入日志消息到磁盘。这种额外的开销取决于日志的频率和消息数量。
-
用途和监控: 启用日志收集器对于监控数据库活动、故障排除以及了解系统运行状况非常有用。它可以记录重要的事件、查询执行情况等信息,帮助管理员跟踪和解决问题。
-
安全性注意事项: 需要小心处理日志信息,因为可能包含敏感信息。确保对日志文件设置适当的权限,以防止未授权的访问。
综上所述,logging_collector 参数控制了 PostgreSQL 是否启用日志收集器进程来管理和记录数据库服务器的日志消息。合理配置日志收集方式并确保适当处理日志信息对于监控和维护 PostgreSQL 数据库非常重要。
11. log_destination
确定日志消息输出的目的地,可以是文件、syslog、stderr 等。
log_destination 是 PostgreSQL 中用于配置日志输出目的地的参数。它决定了数据库日志信息的输出位置和方式。
以下是关于 log_destination 参数的详细描述和其作用:
-
作用:
log_destination用于指定 PostgreSQL 日志信息的输出目的地。这个参数决定了日志消息将被发送到何处以及以何种格式输出。 -
输出目的地选项:
log_destination支持多种日志输出目的地,常用的选项包括:stderr:日志消息被发送到服务器进程的标准错误输出(通常是控制台)。csvlog:将日志消息以 CSV 格式写入到日志文件中。syslog:将日志消息发送到系统日志(适用于支持 syslog 协议的系统)。eventlog:仅适用于 Windows 平台,将日志消息写入到 Windows 事件日志。stdout:类似于stderr,但将日志消息发送到标准输出。
-
默认设置: 默认情况下,
log_destination被设置为stderr,这意味着日志消息将输出到服务器进程的标准错误输出。 -
日志格式和设置: 不同的输出目的地可以有不同的日志格式和设置,例如,可以使用
log_line_prefix来定义日志条目的格式,包括时间戳、用户名、数据库名称等信息。 -
日志级别和过滤: 可以使用
log_min_messages参数设置日志消息的最小级别,以过滤记录到日志中的消息类型。 -
安全性注意事项: 对于输出到文件的日志目的地,需要小心处理日志文件,确保适当的文件权限设置以防止未授权的访问。
-
灵活性: 可以同时指定多个输出目的地,以便将日志消息同时发送到多个地方。例如,可以将日志同时输出到文件和 syslog。
-
性能影响: 输出到文件或者其他远程目的地(如 syslog)可能会对性能产生一定影响,具体取决于日志的频率和消息数量。
log_destination 参数允许管理员根据需要将 PostgreSQL 产生的日志信息输出到不同的目的地,这对于监控、故障排除和安全审计非常有用。合理配置日志目的地和格式,确保数据库运行状况的可观察性和安全性。
12. log_line_prefix
定义日志行的前缀,可以包括时间戳、用户名、数据库名等信息。
log_line_prefix 是 PostgreSQL 中用于配置日志条目格式的参数。它决定了每条日志消息的前缀内容和格式,包括时间戳、进程 ID、用户信息等。
以下是关于 log_line_prefix 参数的详细描述和其作用:
-
作用:
log_line_prefix用于配置每条日志消息的前缀格式。这个参数允许你定义日志条目中包含的元数据信息,例如时间戳、进程 ID、用户信息等。 -
常用的转义符号:
log_line_prefix支持一系列转义符号,这些符号在实际记录日志时会被替换为相应的信息,例如:%t:当前时间戳(timestamp)。%p:进程 ID。%u:当前用户名。%d:数据库名。%h:主机名。%m:日志消息级别(例如 ERROR、WARNING)。%c:会话 ID。%s:会话的统计信息。%i:SQL 命令标识符(如果设置了)。
-
示例设置: 例如,设置
log_line_prefix = '%t [%p]: [%l-1] user=%u,db=%d '将在每条日志消息前加上时间戳、进程 ID,并显示用户和数据库信息。 -
定制化日志格式: 使用
log_line_prefix可以根据特定需求定制化日志格式,使日志信息更易于阅读和分析。 -
性能影响: 设置复杂的格式可能会轻微影响性能,特别是在高频率记录大量日志的情况下。
-
安全性注意事项: 小心处理可能包含敏感信息的日志,确保不会泄露敏感数据。
log_line_prefix 参数允许管理员根据需要自定义日志条目的格式,使得日志消息更易于阅读和分析。合理配置这个参数可以为监控、故障排除和安全审计提供更详细和有用的信息。
13. log_statement
控制是否记录所有 SQL 语句到日志中。可选的值包括 none(不记录)、ddl(只记录数据定义语言)、mod(记录数据修改语言)等。
log_statement 是 PostgreSQL 中用于控制是否记录执行的 SQL 语句到日志的参数。它决定了是否将用户会话执行的 SQL 语句记录到 PostgreSQL 的日志文件中。
以下是关于 log_statement 参数的详细描述和作用:
-
作用:
log_statement用于控制是否将用户会话执行的 SQL 语句记录到日志中。这个参数可以帮助管理员监控数据库中实际执行的 SQL 操作。 -
设置选项:
log_statement允许有不同的设置选项来控制记录的级别:none(默认值):不记录任何 SQL 语句到日志中。ddl:只记录数据定义语言(DDL)语句,比如 CREATE、ALTER、DROP 等。mod:记录所有修改表数据的语句,例如 INSERT、UPDATE、DELETE 等。all:记录所有 SQL 语句,包括查询语句 SELECT、DDL、以及修改数据的语句。
-
性能影响: 启用
log_statement并记录所有 SQL 语句会增加日志文件的大小,并轻微影响数据库性能,特别是在高负载环境下。 -
安全性注意事项: 启用记录所有 SQL 语句可能会泄露敏感信息(如密码或敏感数据),因此在生产环境中需要慎重考虑。
-
用途: 通过设置合适的
log_statement参数,可以监控数据库中发生的各种类型的 SQL 操作,有助于故障排除、性能优化和安全审计。 -
定期轮换和保护日志文件: 当启用日志记录时,需要确保定期轮换日志文件、设置合适的权限以及对日志文件进行保护,以防止未经授权的访问。
总的来说,log_statement 参数允许管理员控制记录到日志中的 SQL 语句类型。合理设置这个参数可以帮助监控数据库的活动和行为,但需要在安全性和性能之间做出权衡,特别是在生产环境中。
14. wal_level
控制 WAL(Write-Ahead Logging)的记录级别。可以设置为 minimal、replica、或 logical,决定了可用的 WAL 信息量。
wal_level 是 PostgreSQL 中控制 WAL(Write-Ahead Logging)的详细程度的配置参数。WAL 是一种持久化数据变更的机制,用于保证数据库在发生故障时的一致性和可恢复性。
以下是关于 wal_level 参数的详细描述和其作用:
-
作用:
wal_level用于定义 WAL 日志的记录程度和详细程度。WAL 是 PostgreSQL 用于实现持久性和数据恢复的关键机制。 -
设置选项:
wal_level允许有不同的设置选项来控制 WAL 日志记录的详细程度:minimal:记录必要的信息来支持崩溃恢复,是最少的记录级别。replica:除了支持崩溃恢复外,还包括用于流复制的信息。这个级别允许 PostgreSQL 实例充当流复制的源。logical:除了replica级别的信息外,还包括用于逻辑复制的信息。这个级别允许基于逻辑复制来构建复杂的数据流。
-
功能和应用:
minimal级别提供最小的 WAL 日志记录,适用于不需要流复制或逻辑复制的单一数据库实例。replica级别适用于需要使用流复制的场景,允许一个 PostgreSQL 实例作为另一个实例的备份或复制源。logical级别用于支持更复杂的数据复制需求,例如实现自定义数据流或者跨版本复制。
-
性能影响: 更高级别的 WAL 日志记录会产生更多的日志信息,可能会增加磁盘 I/O 以及对系统性能的影响,特别是在高负载的情况下。
-
使用场景和建议: 选择合适的
wal_level应基于应用程序需求,例如是否需要流复制或逻辑复制等。对于简单的单个数据库实例,通常使用minimal就足够了;而对于需要流复制或逻辑复制的分布式架构,则需要使用replica或logical。 -
动态修改: 可以在运行时动态修改
wal_level参数,但需要重新启动 PostgreSQL 实例才能使修改生效。
综上所述,wal_level 参数是用于控制 PostgreSQL 中 WAL 日志记录的详细程度。合理设置这个参数可以满足数据库的持久性和可恢复性需求,但需要根据实际应用场景和系统负载进行权衡和调整。
15. max_wal_size 和 min_wal_size
控制 WAL 文件的大小,max_wal_size 设置 WAL 文件的最大大小,min_wal_size 则是设置 WAL 文件的最小大小。
max_wal_size 和 min_wal_size 是 PostgreSQL 中用于控制 WAL(Write-Ahead Logging)日志文件大小的参数。
-
max_wal_size:
max_wal_size参数定义了 WAL 日志文件的最大大小。一旦 WAL 达到这个大小,PostgreSQL 将触发检查点并将活跃的 WAL 文件归档或复制,以释放空间供新的 WAL 日志写入。- 这个参数的设置对于控制 WAL 文件的大小以及限制 WAL 文件持续增长至关重要。默认情况下,
max_wal_size设置为 1GB(1GB = 1,073,741,824 字节)。
-
min_wal_size:
min_wal_size参数定义了 WAL 日志文件的最小大小。它表示 PostgreSQL 在执行检查点时确保 WAL 文件的最小保留量。- 当 WAL 文件的大小低于
min_wal_size设置时,PostgreSQL 将尝试在不触发检查点的情况下维持 WAL 文件的大小。 - 默认情况下,
min_wal_size设置为 80MB。
-
作用:
- 合理设置这两个参数可以控制 WAL 日志文件的增长速度和持续保留的最小量,有助于数据库性能和恢复能力的平衡。
max_wal_size和min_wal_size可以确保 WAL 日志文件不会无限制地增长,并允许数据库在故障恢复时使用适当数量的 WAL 日志信息。
-
性能和空间影响:
- 较大的
max_wal_size可能会增加 WAL 文件的大小,导致更长的恢复时间和更多的磁盘空间占用。 - 较小的
max_wal_size可能会导致更频繁的检查点和 WAL 文件归档,但会减少恢复时需要的 WAL 日志量。
- 较大的
-
动态修改:
max_wal_size和min_wal_size可以在运行时动态修改,但在修改后可能需要重新启动 PostgreSQL 实例才能生效。
综上所述,max_wal_size 和 min_wal_size 参数在 PostgreSQL 中用于控制 WAL 日志文件的大小和持续保留量。合理设置这些参数可以平衡数据库性能和存储空间的需求,并确保在发生故障时能够提供必要的 WAL 日志信息来恢复数据库。
16. max_parallel_workers
用于设置并行查询和并行化操作的工作进程数量上限。
在 PostgreSQL 中,max_parallel_workers 参数用于控制查询执行过程中允许的最大并行工作者(worker)数量。这个参数影响着查询执行计划中可以并行执行的操作数量。
以下是关于 max_parallel_workers 参数的详细描述和作用:
-
作用:
max_parallel_workers用于限制并行查询执行中允许的最大工作者数量。并行查询允许单个查询操作在多个 CPU 核心上并行执行,提高查询性能。 -
设置选项:
max_parallel_workers是一个整数参数,表示在一个查询中允许并行执行的最大工作者数量。- 在 PostgreSQL 9.6 版本之前,这个参数没有区分具体类型的并行工作者,而在 9.6 版本之后,引入了不同类型的并行工作者:
max_parallel_workers_per_gather用于并行表扫描和聚合操作,max_parallel_workers用于其他操作,如并行索引扫描等。
-
默认设置: 默认情况下,
max_parallel_workers的值通常设置为 8 或者与系统 CPU 核心数量相关的值。这个值可以通过修改postgresql.conf中的参数来调整。 -
性能影响: 增加并行工作者数量可以加速查询执行,特别是对于需要大量 CPU 计算的查询,但过多的并行操作可能会增加系统负载,占用额外的资源并影响其他查询的性能。
-
限制和注意事项:
- 需要注意的是,并不是所有类型的查询操作都能够有效地并行执行,某些操作可能并不适合进行并行处理。
- 并行查询需要额外的资源和开销,包括 CPU 和内存资源。因此,需要根据系统配置和负载情况来调整此参数的值。
-
动态修改和生效: 可以在运行时动态地修改
max_parallel_workers参数,但是为了使修改生效,通常需要重新加载 PostgreSQL 配置或者重启 PostgreSQL 实例。
综上所述,max_parallel_workers 参数用于控制并行查询执行中允许的最大工作者数量。合理调整这个参数可以优化查询执行性能,但需要考虑系统资源、查询类型和负载情况,避免过度消耗资源导致性能下降。
17. temp_buffers
用于设置每个数据库会话的临时缓冲区的大小,用于临时表和排序操作。
temp_buffers 是 PostgreSQL 中用于配置临时内存缓冲区的参数。这些缓冲区用于存储临时表的数据以及一些执行中的临时操作结果。
以下是关于 temp_buffers 参数的详细描述和作用:
-
作用:
temp_buffers用于定义在执行查询过程中,用于存储临时表数据和临时操作结果的内存缓冲区的大小。 -
默认设置: 默认情况下,
temp_buffers的值通常设置为 8MB。这个值可以通过修改postgresql.conf中的参数来进行调整。 -
内存缓冲区: 当 PostgreSQL 执行查询操作时,可能会需要临时存储一些数据,比如排序、临时表、hash 连接等操作需要的内存空间。这些操作需要使用
temp_buffers中配置的内存空间来存储中间结果。 -
性能影响: 增加
temp_buffers可以提高某些类型的查询性能,特别是对于大型临时表的查询。这会减少将数据写入磁盘的次数,提高查询执行速度。但是,如果设置过高可能会占用过多的内存,影响其他查询的性能。 -
注意事项:
temp_buffers参数设置过高可能会影响并发查询的性能,因为它会占用更多的共享内存。- 需要根据实际负载情况和系统可用内存来调整
temp_buffers的值,避免因过度分配内存而影响整个系统性能。
-
动态修改和生效: 可以在运行时动态地修改
temp_buffers参数的值,但是为了使修改生效,通常需要重新加载 PostgreSQL 配置或者重启 PostgreSQL 实例。
综上所述,temp_buffers 参数用于配置 PostgreSQL 中用于存储临时数据和中间操作结果的内存缓冲区大小。合理调整这个参数可以提高某些查询的性能,但需要注意内存资源的使用,避免影响其他查询和整个系统的稳定性。
18. checkpoint_timeout
设置自动执行检查点的间隔时间,以确保数据持久化到磁盘。
checkpoint_timeout 是 PostgreSQL 中用于配置自动执行检查点(checkpoint)操作的时间间隔的参数。
以下是关于 checkpoint_timeout 参数的详细描述和作用:
-
作用:
checkpoint_timeout用于指定自动执行检查点的时间间隔。检查点是将内存中的被修改的数据写入到持久化存储(通常是磁盘)的过程,以确保数据库的一致性和持久性。 -
默认设置: 默认情况下,
checkpoint_timeout参数未被明确设置,因此它的默认值是 5 分钟(5min)。 -
时间单位: 时间间隔以秒为单位指定。例如,
checkpoint_timeout = 300表示每 300 秒(即 5 分钟)执行一次检查点操作。 -
作用机制: 当设置了
checkpoint_timeout后,PostgreSQL 将定期触发检查点操作,将内存中被修改的数据写入磁盘。这有助于减少崩溃恢复时需要重做的日志量,提高数据库的恢复性能。 -
性能影响: 设置较短的检查点时间间隔可能会增加系统的 I/O 负载,因为更频繁地执行检查点会导致更多的数据写入到磁盘中。
-
动态修改和生效:
checkpoint_timeout可以在运行时动态地修改。修改参数后,新的设置将在下一个检查点触发时生效。 -
其他检查点相关参数: 除了
checkpoint_timeout,PostgreSQL 还有其他与检查点相关的参数,如checkpoint_completion_target(检查点完成目标)和checkpoint_segments(最小 WAL 文件数量触发检查点),它们可以进一步调整检查点的行为和性能。 -
优化和调整: 调整
checkpoint_timeout可能需要根据实际的负载和系统性能进行优化,避免过于频繁或不足的检查点操作。
综上所述,checkpoint_timeout 参数用于控制 PostgreSQL 数据库执行自动检查点操作的时间间隔。合理配置这个参数可以平衡数据持久性和性能,并确保数据库系统在崩溃时能够快速恢复。
19. max_locks_per_transaction 和 max_pred_locks_per_transaction
分别控制每个事务中可以获得的最大锁的数量,用于控制并发操作。
max_locks_per_transaction 和 max_pred_locks_per_transaction 是 PostgreSQL 中用于控制事务内锁的数量限制的参数。
-
max_locks_per_transaction:
max_locks_per_transaction参数用于限制单个事务能够获取的所有类型锁的总数量。- 默认情况下,
max_locks_per_transaction参数设置为 64。这个值决定了一个事务能够同时持有的锁的数量上限。
-
max_pred_locks_per_transaction:
max_pred_locks_per_transaction参数用于限制单个事务能够获取的 Predicate Locks(谓词锁)的数量。- 默认情况下,
max_pred_locks_per_transaction参数设置为 64。这个值决定了一个事务能够同时持有的谓词锁的数量上限。
-
锁类型:
- PostgreSQL 中有多种类型的锁,包括行级锁、页级锁、表级锁等,它们用于确保事务之间的数据一致性和并发性。
- 谓词锁(Predicate Locks)是一种特殊类型的锁,它用于支持并发事务间的数据一致性保证。
-
作用:
- 这两个参数限制了一个事务能够同时获取的锁的总数量,防止某个事务持有过多的锁,从而导致其他事务阻塞或者系统资源不足。
- 合理配置这两个参数可以平衡数据库的并发性能和系统资源的利用率,避免因锁竞争而导致的性能问题。
-
性能影响:
- 若设置过低,可能导致并发事务之间因锁等待而出现阻塞。
- 若设置过高,可能会占用过多的系统资源,导致系统性能下降。
-
动态修改和生效:
max_locks_per_transaction和max_pred_locks_per_transaction可以在运行时动态修改,但为了使修改生效,可能需要重新加载 PostgreSQL 配置或者重启 PostgreSQL 实例。
-
优化和调整:
- 调整这两个参数可能需要根据实际的负载和并发情况进行优化,避免过度占用系统资源或者导致阻塞。
综上所述,max_locks_per_transaction 和 max_pred_locks_per_transaction 用于限制单个事务内可以获取的锁的数量。合理配置这两个参数可以确保系统的并发性能,并防止锁竞争导致的问题。
相关文章:

postgresql_conf中常用配置项
在 PostgreSQL 的 postgresql.conf 配置文件中,有许多常用的配置项,这些配置项可以根据特定需求和性能优化进行调整。以下是一些常用的配置项及其作用: 1. shared_buffers 用于设置 PostgreSQL 实例使用的共享内存缓冲区大小。增加此值可以…...
使用MfgTool烧写前需准备的文件
一. 简介 本文我们就来学习,如何将我们编译的 uboot,zImage(内核镜像),xxx.dtb设备树文件,还有制作的根文件系统,这四个文件烧写到开发板中,最后 开发板能正常启动。 本文这里使用…...

SAP UI5 walkthrough step4 XML Views
SAPUI5 指出多种VIEW类型,包括XML,HTML,JavaScript 推荐使用XML,因为可读性更高 我们提前介绍一下MVC架构。 MVC是一种软件架构模式,它包括三个主要组件:模型(Model)、视图(View)…...

Java 1对1
文章目录 前言 客户端 服务器端 输出线程端 End 前言 TCP(Transmission Control Protocol)是一种面向连接的、可靠的网络传输协议,它提供了端到端的数据传输和可靠性保证。 本程序就是基于tcp协议编写而成的。 利用 TCP 协议进行通信的…...

云服务器Centos中安装Docker
云服务器Centos中安装Docker 1 简介DockerCentosCentos和Ubuntu区别 2 安装3 测试hello-world的镜像测试 1 简介 Docker Docker是一个开源的应用容器引擎,利用操作系统本身已有的机制和特性,可以实现远超传统虚拟机的轻量级虚拟化。它支持将软件编译成…...
人工智能教程(三):更多有用的 Python 库
目录 前言 推荐 JupyterLab 入门 复杂的矩阵运算 其它人工智能和机器学习的 Python 库 前言 在本系列的上一篇人工智能教程(二):人工智能的历史以及再探矩阵中,我们回顾了人工智能的历史,然后详细地讨论了矩阵。在…...

【带头学C++】----- 九、类和对象 ---- 9.10 C++设计模式之单例模式设计
❤️❤️❤️❤️❤️❤️❤️❤️❤️❤️❤️麻烦您点个关注,不迷路❤️❤️❤️❤️❤️❤️❤️❤️❤️❤️❤️❤️ 目 录 9.10 C设计模式之单例模式设计 举例说明: 9.10 C设计模式之单例模式设计 看过我之前的文章的,简单讲解过C/Q…...

Qt之QCache和QContiguousCache
一.QCache QCache在构造的时候指定了缓存中允许的最大成本,也就是如下构造函数中的参数maxCost。默认情况下,QCaches maxCost() 是100。 QCache(int maxCost = 100) ~QCache() void clear() bool contains(const Key &key) const int count() const bool insert(const …...
Django讲课笔记01:初探Django框架
文章目录 一、学习目标二、课程导入(一)课程简介(二)课程目标(三)适用人群(四)教学方式(五)评估方式(六)参考教材 三、新课讲授&#…...

JS中的闭包
闭包 闭包的概念其实很简单,就是函数A内部有一个函数B,函数B可以访问函数A的变量。也就是说闭包是指有权访问另一个函数作用域中变量的函数,利用闭包可以突破作用域链。 闭包的特性: 1、函数内再嵌套函数 2、内部函数可以引用外层的参数和变…...
深度学习在计算机视觉中的应用
深度学习在计算机视觉中的应用 摘要:本文介绍了深度学习在计算机视觉领域的应用,包括目标检测、图像分类、人脸识别等。通过分析深度学习在计算机视觉中的实际应用案例,阐述了深度学习在计算机视觉中的优势和未来发展趋势。 一、引言 计算…...

模板与泛型编程
函数模板 显示实例化 区别定义与声明 T是模板形参 int是模板实参 inpunt是函数形参 3是函数实参 显示实例化 模板必须实例化可见 翻译单元一处定义原则 与内联函数异同 引入原因:函数模板是为了编译器两个阶段的处理 内联函数是为了能在编译期展开 模板实参的类…...
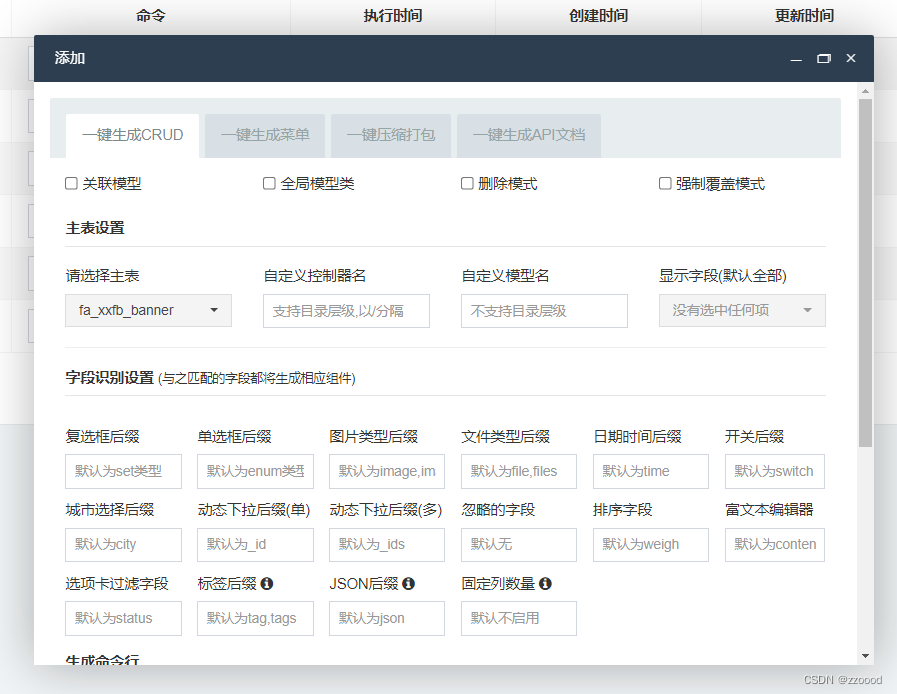
【Fastadmin】一个完整的轮播图功能示例
目录 1.效果展示: 列表 添加及编辑页面同 2.建表: 3.使用crud一键生成并创建控制器 4.html页面 add.html edit.html index.php 5.js页面 6.小知识点 1.效果展示: 列表 添加及编辑页面同 2.建表: 表名:fa_x…...

Ribbon 饥饿加载
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载: 一、懒加载 Ribbon 默认为懒加载即在首次启动Application…...
【AIGC】大语言模型的采样策略--temperature、top-k、top-p等
总结如下: 图片链接 参考 LLM解码-采样策略串讲 LLM大模型解码生成方式总结 LLM探索:GPT类模型的几个常用参数 Top-k, Top-p, Temperature...

pip的基本命令和使用
Pip的基本命令和使用 介绍 Pip是Python的包管理工具,它能够帮助我们安装、升级和卸载Python模块。它是Python标准库的一部分,因此在大多数Python发行版中都已经预装了Pip。本文将介绍Pip的基本命令和使用方法,帮助读者更好地使用Pip管理Pyt…...
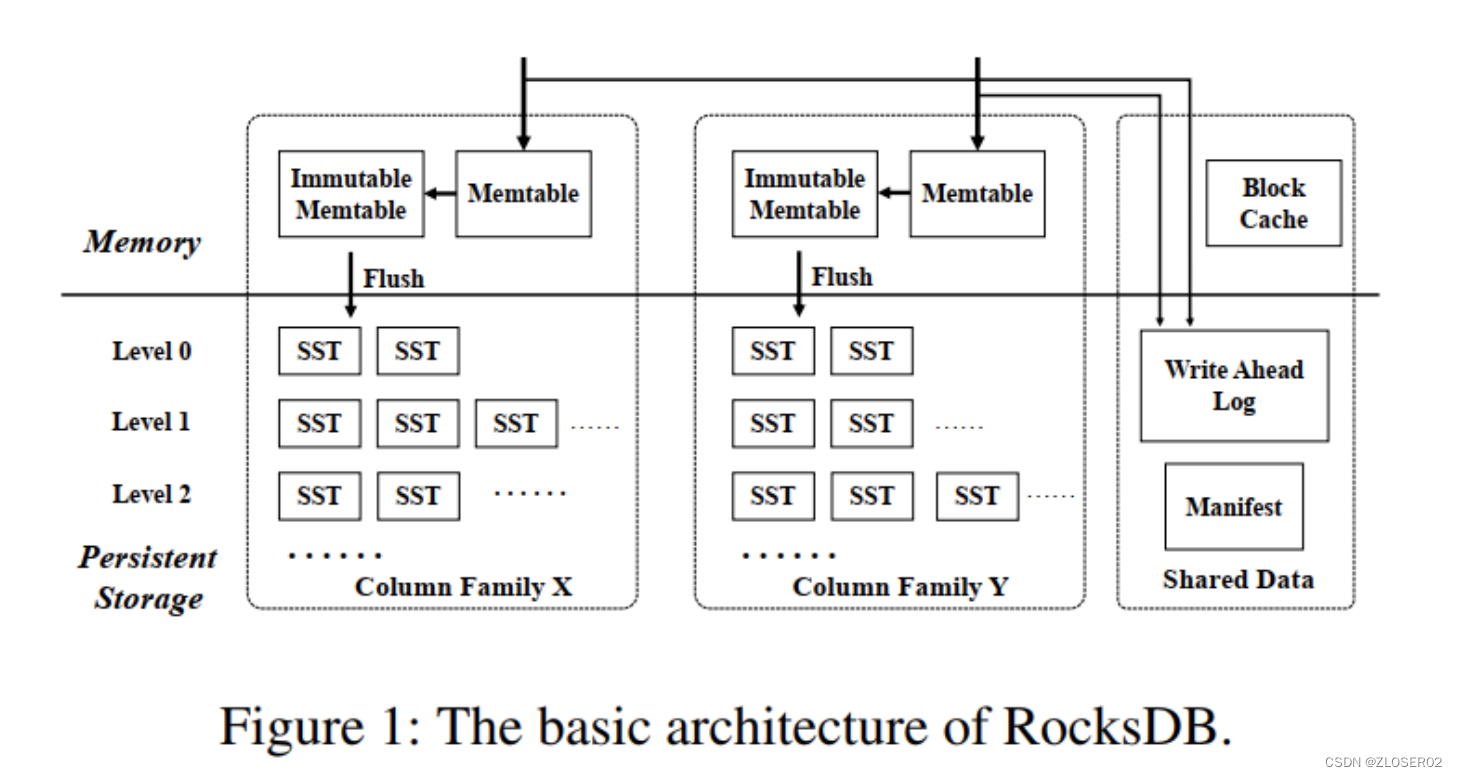
RocksDB实现原理
文章目录 简介编译安装RocksDB压缩库UbuntuCentos 基本接口高度分层架构LSM-Tree关于访问速度 MemTable落盘策略 WALRocksDB 中的每个更新操作都会写到两个地方:WAL 创建时机:重要参数 Immutable MemTableSSTBlockCacheLRU 缓存Clock缓存 写入流程读取流…...

mysql 链接超时的几个参数详解
mysql5.7版本中,先查看超时设置参数,我们这里只关注需要的超时参数,并不是全都讲解 show variables like %timeout%; connect_timeout 指的是连接过程中握手的超时时间,在5.0.52以后默认为10秒,之前版本默认是5秒,主…...
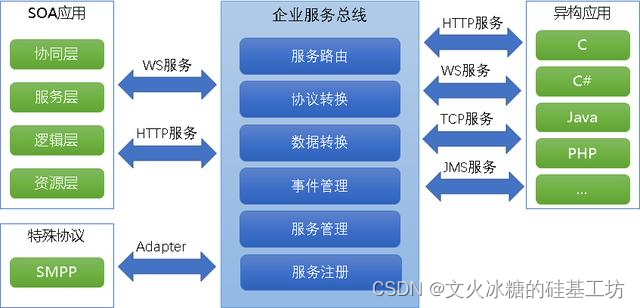
[架构之路-259]:目标系统 - 设计方法 - 软件工程 - 软件设计 - 架构设计 - 面向服务的架构SOA与微服务架构(以服务为最小的构建单位)
目录 前言: 二、软件架构层面的复用 三、什么是面向服务的架构SOA 3.1 什么是面向服务的架构 3.2 面向服务架构的案例 3.3 云服务:everything is service一切皆服务 四、什么是微服务架构 4.1 什么是微服务架构 4.2 微服务架构的案例 五、企业…...
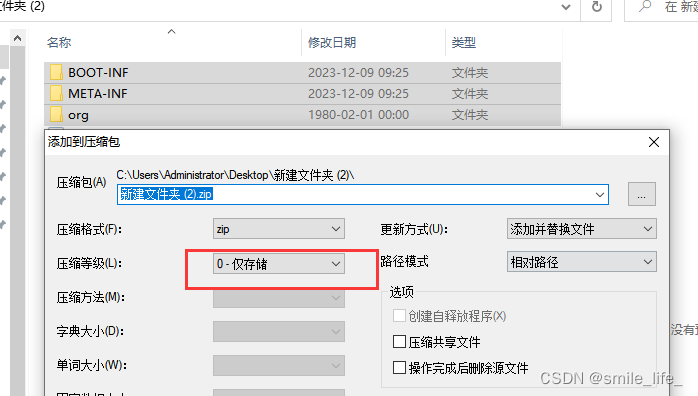
7z压缩成jar包
比如我们要改下jar包中的某个文件,或者更换一下,那么就要先解压。解压后是这样的 弄好后,使用7z进行压缩,7z默认是标准压缩,会把BOOT-INF\lib 目录下的jar包也进行一次压缩,这会导致java -jar 会报 jar包相…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...