向量数据库——AI时代的基座
向量数据库——AI时代的基座
1.前言
向量数据库在构建基于大语言模型的行业智能应用中扮演着重要角色。大模型虽然能回答一般性问题,但在垂直领域服务中,其知识深度、准确度和时效性有限。为了解决这一问题,企业可以利用向量数据库结合大模型和自有知识资产,构建垂直领域的智能服务。向量数据库存储和处理向量数据,提供高效的相似度搜索和检索功能。通过向量嵌入,将企业知识库文档和数据转化为向量表示,并与大模型进行交互,实现专有、私域的垂直的行业智能化应用。
2.亚马逊向量数据库:探索新时代的数据存储
概述
亚马逊向量数据库是一种专门为处理大规模、复杂的数据集而设计的数据库系统。这类数据库特别擅长处理所谓的“向量数据”,即那些可以在多维空间中表示的数据。这对于执行机器学习、深度学习和其他高级数据分析任务特别有用。
- 向量数据的处理: 亚马逊向量数据库可以高效地处理和存储向量数据。在传统数据库中,这类数据的处理往往非常耗时和困难。
- 应用场景: 这种数据库在图像识别、自然语言处理、推荐系统等领域表现出色。例如,在电子商务中,可以通过向量数据库来改进产品推荐算法。
- 与亚马逊云服务的结合: 亚马逊的向量数据库与其云计算服务紧密结合,为用户提供了强大的扩展性和灵活性。
借助 Amazon OpenSearch Service,您可以轻松执行交互式日志分析、实时应用程序监控、网站搜索等。OpenSearch 是源自 Elasticsearch 的开源、分布式搜索和分析套件。Amazon OpenSearch Service 提供最新版本的 OpenSearch,支持 19 个版本的 Elasticsearch(1.5 至 7.10 版),以及由 OpenSearch 控制面板和 Kibana(1.5 至 7.10 版)提供支持的可视化功能。

优点

- 与社群驱动的开源软件的主要贡献者一起运营 OpenSearch。
- 快速搜索和分析非结构化和半结构化数据,轻松找到所需的内容。
- 通过自动调配、软件安装、修补、存储分层等功能,削减运营开销并降低成本。
- 快速查询与匹配大规模和多维度的向量数据。
亚马逊云科技预测,随着技术的进步和市场的需求,将词汇搜索方法与先进的机器学习、生成式AI功能结合的混合搜索将会日益流行。这种混合搜索模式将融合了传统搜索的准确性和AI的智能性,为企业和用户带来更加智能、高效的搜索体验。
亚马逊云科技不仅仅满足于提供高性能的向量数据库服务,更持续不断地进行优化和改进,确保客户获得最前沿的技术体验。在向量图方面,团队一直在努力优化其性能和内存使用。亚马逊云科技进行了一系列的升级和改进,目标是进一步提高向量图的效率。其中,缓存改进是其中的一项重要策略。通过优化缓存机制,向量图能够更快速地访问常用数据,大大减少了访问延迟,提高了整体性能。
除了缓存优化,亚马逊云科技还进行了合并功能的改进。在某些场景中,向量图需要合并多个小的数据结构为一个大的数据结构。通过优化合并算法,现在的合并过程更为高效,不仅减少了内存占用,还加速了合并操作的速度。
3.亚马逊云科技的服务支持
优势



总结
AWS 提供多种多样的服务,可以满足各种企业需求。底层强大的设计支撑又可以满足上层多样灵活的配置。由于非常灵活也可能会让刚刚上手 AWS 的人面对面对众多服务不知如何下手。所以,如果企业选择上云,还是需要有经验的架构做很多基础配置上的支撑,小步快走式逐步将各个应用迁移到云平台上
AWS 提供了非常完善的文档说明,日常遇到的一些问题都可以通过查阅文档的方式来解决,如果需要更好的理解 AWS 的相关服务与术语,建议阅读英文文档,可能对于某些程序员来说是一种挑战
AWS 虽然提供了完整的服务,但是有些服务的调试功能还不够完善,只能借助 CloudWatch 等log 日志排查问题。好在 AWS 也非常注重用户的使用体验,也在不断更新和完善产品内容
AWS 提供的服务功能丰富,这也可能导致一些功能实现变得复杂,AWS 在迭代自己产品的同时, 周边的支撑服务也在快速发展,比如 Serverless Framework 等,在逐步降低上手门槛,完善整个生态圈
整体来说,周边的好多公司都在用云,或在上云的路上,Amazon AWS 还是他们首要考虑的云服务
4.向量数据库概述
4.1 什么是向量
向量数据库中的向量指的是用于表示数据特征的数学概念。在计算机科学和数据处理领域,向量通常是指由一组有序的数值构成的数据结构。这些数值可以代表各种不同的特征,比如图像的像素值、文本的词频、音频的频谱等。
向量数据库通过存储和管理大量的向量数据,可以支持各种数据挖掘、相似性搜索、聚类分析等任务。在实际应用中,向量数据库可以用于人脸识别、图像搜索、推荐系统、自然语言处理等领域,通过对向量之间的相似度进行计算和比较,来实现各种有用的功能和应用。
为了高效地支持向量存储和检索,向量数据库通常会使用各种索引结构和算法,比如KD树、LSH(局部敏感哈希)、近似最近邻算法(ANN)等。这些技术可以帮助加速向量的查询和匹配过程,从而提高数据库的性能和效率。
4.2 什么是向量数据库

向量数据库(Vector Database),也叫矢量数据库,主要用来存储和处理向量数据。
在数学中,向量是有大小和方向的量,可以使用带箭头的线段表示,箭头指向即为向量的方向,线段的长度表示向量的大小。两个向量的距离或者相似性可以通过汉明距离、欧式距离或者余弦距离得到。
图像、文本和音视频这种非结构化数据都可以通过某种变换或者嵌入学习转化为向量数据存储到向量数据库中,从而实现对图像、文本和音视频的相似性搜索和检索。这意味着您可以使用向量数据库根据语义或上下文含义查找最相似或相关的数据,而不是使用基于精确匹配或预定义标准查询数据库的传统方法。

向量数据库的主要特点是高效存储与检索。利用索引技术和向量检索算法能实现高维大数据下的快速响应。向量数据库也是一种数据库,除了要管理向量数据外,还是支持对传统结构化数据的管理。实际使用时,有很多场景会同时对向量字段和结构化字段进行过滤检索,这对向量数据库来说也是一种挑战。
5.其他向量数据库对比
5.1 总体情况
根据VectorDBBench.com数据,2023年7月的国产向量数据库排行榜中,排名前十的向量数据库分别是Milvus、Milvus Cloud、Tencent Cloud VectorDB、Zilliz Cloud、TensorDB、cVector、Om-iBASE、Vearch、Transwarp Hippo和Proxima。这些数据库分别来自不同的公司和技术团队,涵盖了文档、图形、空间数据等多种类型的数据。

5.2 各数据库情况
Milvus

Milvus是排名第一的向量数据库,VectorDBBench得分为22.70。它是国内首个支持海量向量数据存储和查询的开源向量数据库,具有高性能、高扩展性和易用性强的特点。Milvus还提供了一系列高级功能,如向量搜索、相似度计算、聚类等,可以满足不同领域的需求。
Milvus Cloud

Milvus Cloud是Milvus的云服务版本,排名第二,VectorDBBench得分为16.30。它提供了云端向量数据库服务,可以快速搭建云端向量数据库平台,支持多种数据源接入和多种查询语言,同时还提供了可视化界面和API接口,方便用户进行数据管理和查询。
Tencent Cloud VectorDB

Tencent Cloud VectorDB是腾讯云推出的向量数据库产品,排名第三,VectorDBBench得分为13.40。它具有高性能、高扩展性和高安全性的特点,支持多种数据类型和多种查询语言,同时还提供了丰富的的高级功能,如相似度计算、搜索等。
Zilliz Cloud

Zilliz Cloud是一个向量数据库云平台,排名第四,VectorDBBench得分为13.20。它支持多种数据类型和多种查询语言,具有高性能、高扩展性和高安全性的特点。同时,它还提供了一系列高级功能,如相似度计算、搜索等,方便用户进行数据管理和分析。
TensorDB
TensorDB是一个分布式向量数据库系统,排名第五,VectorDBBench得分为5.75。它具有高性能、高扩展性和易用性强的特点,支持多种数据类型和多种查询语言,同时还提供了丰富的高级功能,如相似度计算、搜索等。
其他数据库
除了前五名之外,还有其他一些数据库也在排行榜中占据了一席之地。其中,cVector是一个支持大规模向量数据存储和查询的分布式数据库,VectorDBBench得分为3.96;Om-iBASE是一个支持多维数组存储和查询的分布式数据库,VectorDBBench得分为2.33;Vearch是一个支持文本和向量数据存储和查询的分布式搜索引擎,VectorDBBench得分为1.92;Transwarp Hippo是一个支持多维数组和文本数据存储和查询的分布式数据库,VectorDBBench得分为1.42;Proxima是一个支持大规模文本数据存储和查询的分布式搜索引擎,VectorDBBench得分为1.42。
三、结论

随着技术的不断进步和市场的不断需求,我们可以预见,未来将会有更多创新的产品和服务出现,为我们带来更多更好的数据处理和分析体验。同时,也将有更多的企业和机构开始采用这些数据库来提升自己的数据处理和分析能力,为未来的发展打下坚实的基础。
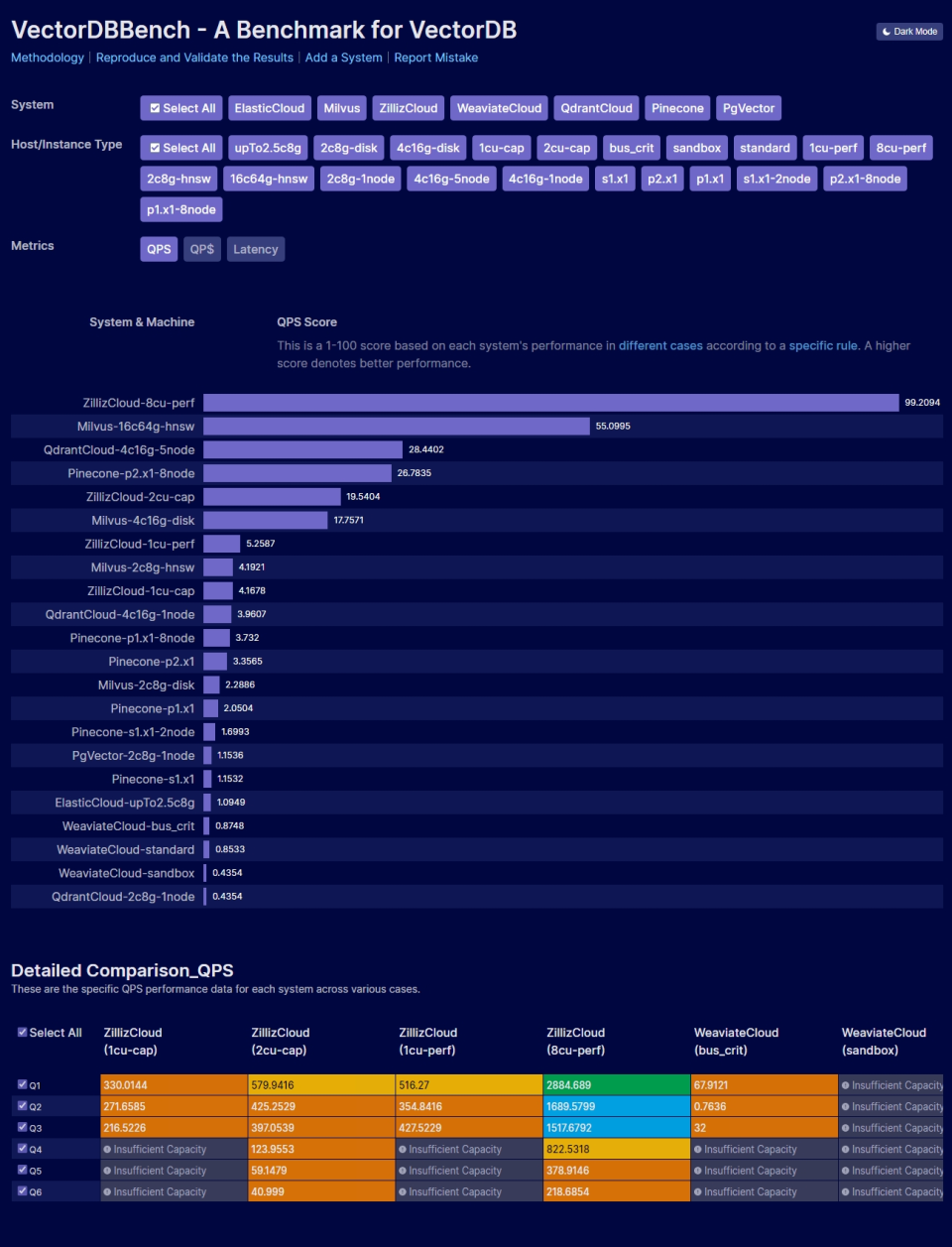
在具体排名方面,Milvus和Milvus Cloud分别位列第一和第二名,表现出色。Tencent Cloud VectorDB、Zilliz Cloud和TensorDB等数据库也在排行榜中占据了一席之地。这些数据库都具有高性能、高扩展性和易用性强的特点,同时提供了丰富的高级功能,可以满足不同领域的需求。
总的来说,国产向量数据库排行榜的变化反映了中国数据库领域的快速发展和变革。随着技术的不断进步和市场的不断需求,我们可以预见,未来将会有更多创新的产品和服务出现,为我们带来更多更好的数据处理和分析体验。同时,也将有更多的企业和机构开始采用这些数据库来提升自己的数据处理和分析能力,为未来的发展打下坚实的基础。
6.向量数据库的原理
6.1 概述
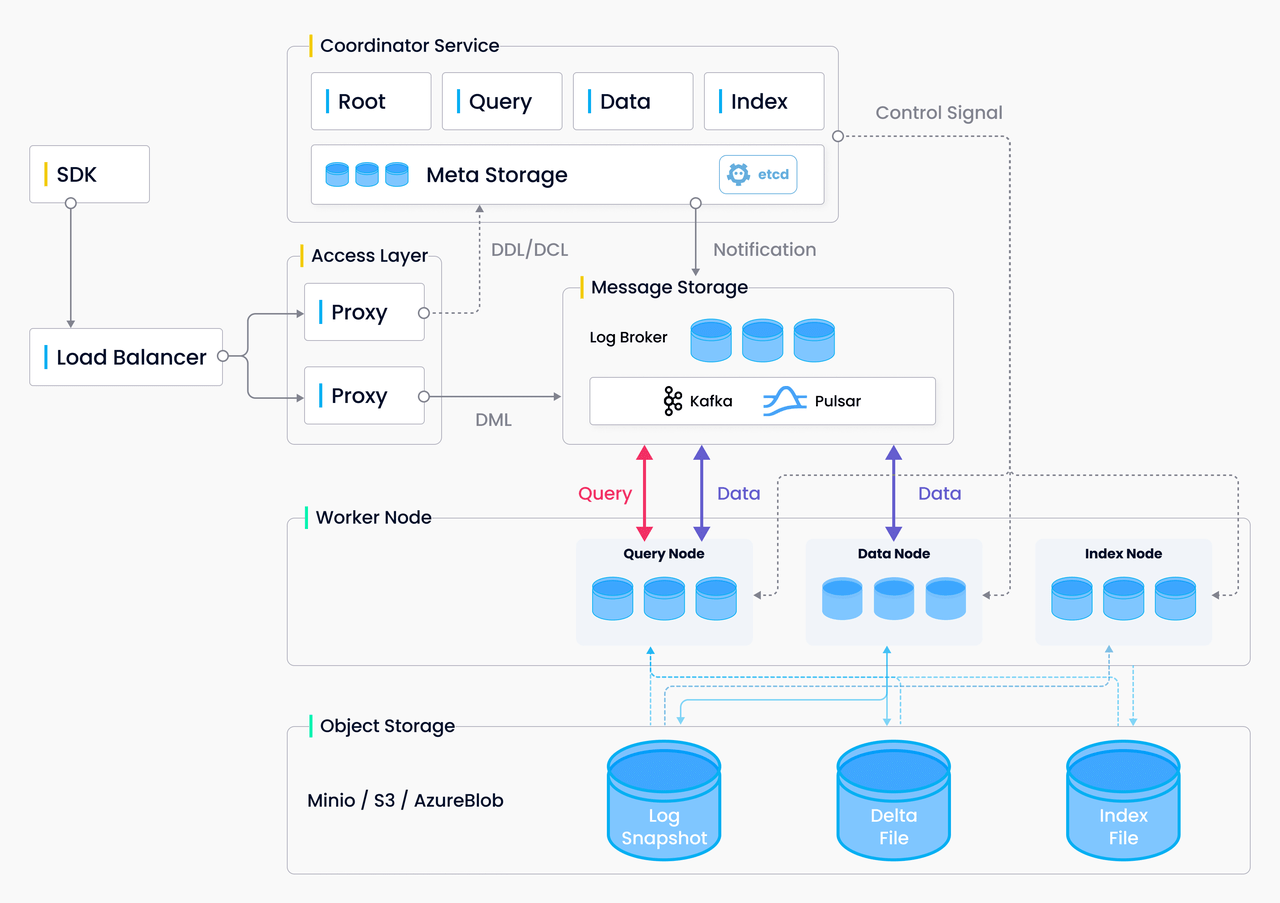
一个简单的向量数据库是如何执行的呢,我们下面看一个简单的流程图。

在向量数据库中,数据以向量的形式进行存储和处理,因此需要将原始的非向量型数据转化为向量表示。数据向量化是指将非向量型的数据转换为向量形式的过程。通过数据向量化,实现了在向量数据库中进行高效的相似性计算和查询。此外,向量数据库使用不同的检索算法来加速向量相似性搜索,如 KD-Tree、VP-Tree、LSH 以及倒排索引等。在实际应用中,需要根据具体场景进行算法的选择和参数的调优,具体选择哪种算法取决于数据集的特征、数据量和查询需求,以及对搜索准确性和效率的要求。
6.2 向量数据库的优点
7.Amazon向量数据库的AI应用
7.1 AmazonAurora数据库概述
Amazon Aurora 是专为云构建的一种兼容 MySQL 和 PostgreSQL 的关系**数据库**,它既具有传统企业数据库的性能和可用性,又具有开源数据库的精简性和成本效益。
Amazon Aurora 的速度可达标准 MySQL 数据库的五倍、标准 PostgreSQL 数据库的三倍。Amazon Aurora 由 Amazon Relational Database Service (RDS) 完全托管,Amazon RDS 可以自动执行各种耗时的管理任务,例如硬件调配、数据库的设置、修补和备份。
Amazon Aurora 采用分布式、有容错能力并且可以自我修复的存储系统,这一系统可以使每个数据库实例最高扩展到 128TB。它可实现高性能和高可用性,支持多达 15 个低延迟读取副本、时间点恢复、持续备份到 Amazon S3,以及跨三个可用区 (AZ) 复制。
7.2 AmazonAurora数据库的优势
- 高性能和可扩展性: 获得 5 倍于标准 MySQL 的吞吐量,以及 3 倍于标准 PostgreSQL 的吞吐量。您可以根据需求变化轻松扩展和缩小数据库部署,包括从较小的实例类型到较大的实例类型,或者可以让 Aurora 无服务器自动为您处理扩展。要扩展读取容量和性能,您可以在三个可用区中添加多达 15 个低延迟只读副本。Amazon Aurora 会根据需要自动增加存储空间,每个数据库实例最多可达 128 TB。
- 高可用性和耐用性: Amazon Aurora 旨在提供超过 99.99% 的可用性,跨 3 个可用区复制 6 个数据副本,并将数据持续备份到 Amazon S3。它可以透明地从物理存储故障中恢复;实例故障转移通常需要不到 30 秒的时间。
- MySQL 和 PostgreSQL 兼容: Amazon Aurora 数据库引擎与现有的 MySQL 和 PostgreSQL 开源数据库完全兼容,并会定期增加新版本的兼容性。这意味着您可以使用标准的 MySQL 或 PostgreSQL 导入/导出工具或快照轻松地将 MySQL 或 PostgreSQL 数据库迁移到 Aurora。这还表示您已经在现有数据库中使用的代码、应用程序、驱动程序和工具可以与 Amazon Aurora 一起使用,只需进行少量更改或根本无需更改。
- 完全托管式: Amazon Aurora 完全由 Amazon Relational Database Service (RDS) 管理。有了它,您无需担心硬件调配、软件修补、设置、配置或备份等数据库管理任务。Aurora 会自动持续地监控您的数据库并将其备份到 Amazon S3,因此可实现精细的时间点恢复。您可以使用 Amazon CloudWatch、增强监控或性能详情来监控数据库性能,这是一种易于使用的工具,可帮助您快速检测性能问题。
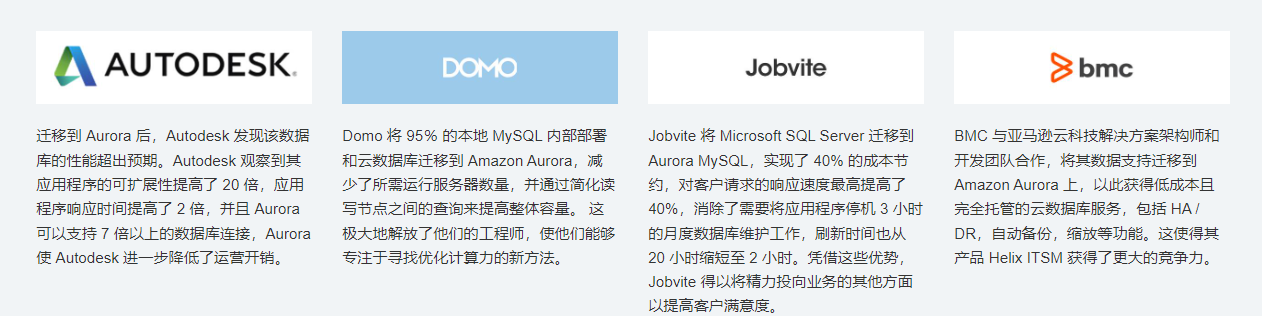
7.3 Aurora 数据库相关案例
8.向量数据库的应用领域
向量数据库是一种专门用于存储和查询向量数据的数据库系统。它在以下领域有广泛应用:
- 相似性搜索:向量数据库可以高效地执行相似性搜索,例如图像检索、音频检索和视频检索等。通过将向量表示存储在数据库中,可以快速找到与查询向量最相似的数据。
- 推荐系统:向量数据库可以用于构建个性化推荐系统。通过将用户和物品表示为向量,可以根据它们之间的相似度来进行推荐。
- 自然语言处理:向量数据库可以用于存储和查询文本向量,例如词向量、句向量和段落向量。这对于一些需要大规模文本数据处理的任务非常有用。
8.1 向量数据库可以处理大规模数据,而 ANN 算法库只能处理小型的数据集
从本质上,向量数据库是一套完整的非结构化数据解决方案。正如前文所言,向量数据库具备诸多功能——云原生、多租户、可扩展性等。但诸如 FAISS 等都是轻量级 ANN 算法库,而不是全托管的解决方案。这些算法库的主要用于构建向量索引(一种数据结构),从而加速多维向量的最近邻检索。这些算法库可以轻松应对小型数据集。但是,随着数据集和用户数量不断增长,这些算法库无法处理大规模数据。
8.2 向量数据库一套完整的解决方案,而 ANN 算法库只是其中一部分
向量数据库与 ANN 算法库另一大不同之处在于:向量数据库是一套完整的服务,而算法库是需要被集成到应用中去的。因此,从某种意义上而言,算法库是向量数据库的组件之一。这有点类似于 Elasticsearch 是一套基于 Apache Lucene 的搜索引擎解决方案。
为了具体说明这种区别, 我们来举一个例子。 在 Milvus 向量数据库中插入非结构化数据只需要三行代码即可。
from pymilvus import Collection
collection = Collection('book')
mr = collection.insert(data)
但对于 FAISS 或 ScaNN 这样的算法库,没有这样可以简单插入数据的方法。即使自己通过代码实现插入数据,ANN 算法库仍然缺乏可扩展性和多租户等特性。
向量数据库与传统数据库向量检索插件的区别 越来越多的传统关系型数据库和检索系统(如 Clickhouse、Elasticsearch等)开始提供内置的向量检索插件。例如,Elasticsearch 8.0 支持通过 Restful API 来插入向量和开展 ANN 检索。但是,向量检索插件的问题显而易见——无法提供 embedding 向量管理和检索的全栈方法。这些插件仅可在现有的架构基础上用作优化方案,使用场景十分有限。在传统数据库基础上开发非结构化数据应用就如同在汽油车中安装锂电池和电动机一样不合常理。向量检索插件不支持灵活调参,也不提供易用的 API 或 SDK。但这两点是向量数据库的基本特性。为了展示向量数据库与向量检索插件的区别,文本将以 Elasticsearch ANN 搜索引擎为例。其他向量检索插件运行方式类似,因此不进一步展开。
Elasticsearch 的 dense_vector 字段支持向量数据类型,且可以通过 knnsearch endpoint 进行向量查询。
PUT index
{"mappings": {"properties": {"image-vector": {"type": "dense_vector","dims": 128,"index": true,"similarity": "l2_norm"}}}}PUT index/_doc
{"image-vector": [0.12, 1.34, ...]}
GET index/_knn_search
{"knn": {"field": "image-vector","query_vector": [-0.5, 9.4, ...],"k": 10,"num_candidates": 100}}
Elasticsearch 的 ANN 插件仅支持 HNSW 一种索引和 L2(欧式距离)一种距离计算方法。但下面,让我们来使用向量数据库 Milvus(以 pymilvus 为例)。
>>> field1 = FieldSchema(name='id', dtype=DataType.INT64, description='int64', is_primary=True)
>>> field2 = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, description='embedding', dim=128, is_primary=False)
>>> schema = CollectionSchema(fields=[field1, field2], description='hello world collection')
>>> collection = Collection(name='my_collection', data=None, schema=schema)
>>> index_params = {'index_type': 'IVF_FLAT','params': {'nlist': 1024},"metric_type": 'L2'}
>>> collection.create_index('embedding', index_params)
>>> search_param = {'data': vector,'anns_field': 'embedding','param': {'metric_type': 'L2', 'params': {'nprobe': 16}},'limit': 10,'expr': 'id_field > 0'}
>>> results = collection.search(**search_param)
虽然 Elasticsearch 和 Milvus 都支持创建索引、插入 embedding 向量、执行 ANN 向量检索,但从以上示例中可以明显看出,Milvus 具备更直观的向量检索 API(可更好服务用户),支持更多样的向量索引类型和距离计算公式(方便用户灵活调参)。Milvus 还计划在未来支持更多的索引类型,并允许用户通过类似 SQL 语句进行查询,从而进一步提升向量数据库的可用性。
简而言之,诸如 Milvus 的向量数据库比向量检索插件更好用。因为 Milvus 是从零开始构建的向量数据库,相较而言,具备更丰富的功能和更适合非结构化数据的系统架构。
8.3 向量数据库的优势
向量数据库的主要应用领域为相似性检索、机器学习、人工智能等。与传统数据库比较,向量数据库具备以下几点优势:
- 高维向量检索:向量数据库可以高效进行高维向量相似性检索,非常适用于机器学习和人工智能应用中,如:图片识别、自然语言处理、推荐系统等。
- 可扩展性:向量数据库支持水平扩展,因此可以存储和处理海量向量数据。在实时检索和召回海量数据的应用场景中,向量数据库的可扩展性显得至关重要。
- 灵活性:向量数据库可以处理多样的向量数据类型,包括稀疏向量和稠密向量。此外,向量数据库还可以处理其他的数据类型,包括:数字、文本、二进制数据(Binary)。
- 性能:相较于传统数据,使用向量数据库进行相似性检索更高效。
- 支持选择不同索引结构:向量数据库支持用户根据不同的应用场景和数据类型构建不同的索引结构。
总结一下,向量数据库在相似性检索和机器学习场景中具有显著优势,能够快速、高效检索和召回高维向量数据。
8.4 向量数据库有哪些应用场景?
向量数据库在许多领域都有广泛的应用场景。以下是一些常见的向量数据库应用场景:
- 相似度搜索: 向量数据库可以用于相似度搜索,例如图像搜索、音频搜索和视频搜索。通过将图像、音频或视频转换为向量表示,可以使用向量数据库来快速检索相似的图像、音频片段或视频片段。
- 推荐系统: 向量数据库可以用于构建个性化推荐系统,根据用户的历史行为和兴趣,将用户和物品表示为向量,并使用向量相似度搜索来获取最相关的推荐物品。
- 自然语言处理: 向量数据库可以用于文本相似度匹配和语义搜索。通过将文本转换为向量表示,可以使用向量数据库来搜索与查询文本相似的文档、句子或短语。
- 人脸识别: 向量数据库可以用于人脸识别和人脸搜索。通过将人脸图像转换为向量表示,可以使用向量数据库来搜索与查询人脸相似的图像或人脸。
- 基因组学: 向量数据库可以用于基因组学研究和基因序列比对。通过将基因序列转换为向量表示,可以使用向量数据库来搜索与查询相似的基因序列
- 网络安全: 向量数据库可以用于网络入侵检测和恶意软件分析。通过将网络流量、日志和恶意软件样本转换为向量表示,可以使用向量数据库来搜索与已知恶意行为相似的网络流量或恶意软件。
- 物体识别:向量数据库可以用于物体识别和物体搜索。通过将物体的特征向量存储在向量数据库中,可以使用向量相似度搜索来识别和搜索相似的物体。
这些只是向量数据库的一些常见应用场景,实际上,向量数据库可以在许多其他领域中发挥作用,以处理和分析大规模的向量数据。
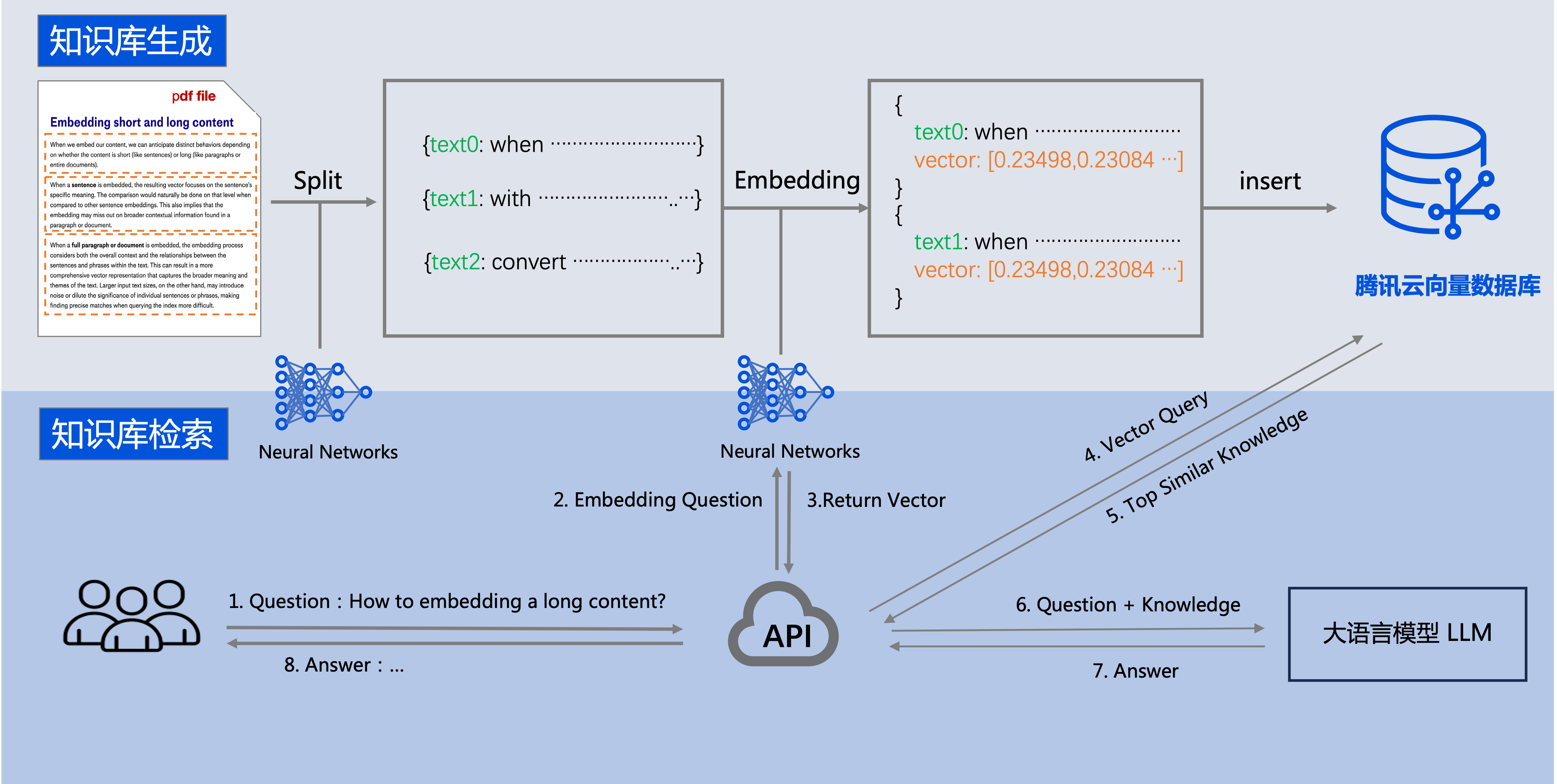
大模型知识库
腾讯云向量数据库可以和大语言模型 LLM 配合使用。企业的私域数据在经过文本分割、向量化后,可以存储在腾讯云向量数据库中,构建起企业专属的外部知识库,从而在后续的检索任务中,为大模型提供提示信息,辅助大模型生成更加准确的答案。
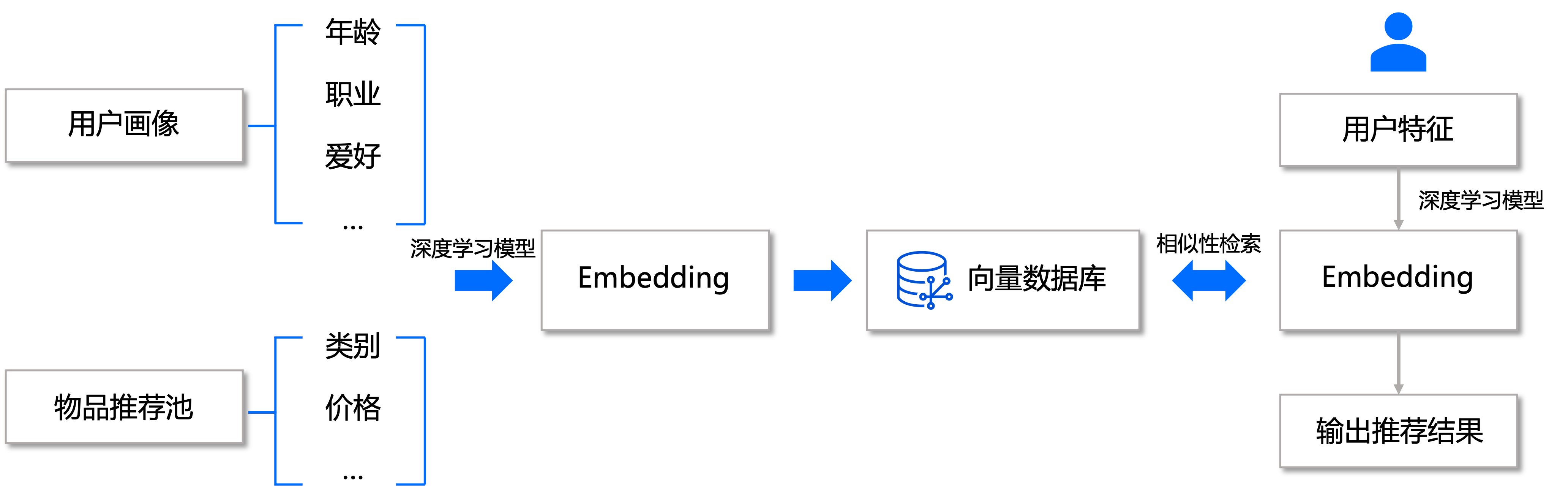
推荐系统
推荐系统的目标是根据用户的历史行为和偏好,向用户推荐可能感兴趣的物品。在这种场景下,将用户行为特征向量化存储在向量数据库。当发起推荐请求时,系统会基于用户特征进行相似度计算,然后返回与用户可能感兴趣的物品作为推荐结果。
问答系统
智能问答系统是一种能够回答用户提出问题的智能应用,通常使用 NLP 服务和深度学习等技术实现。在问答系统中,问题和答案通常被转换为向量表示,并存储在向量数据库中。当用户提出问题时,问答系统可以通过计算向量之间的相似度,检索最相关的问题信息并返回对应的答案信息。因此,使用向量数据库来存储和检索相关的向量数据,可以提高问答系统的检索效率和准确性。
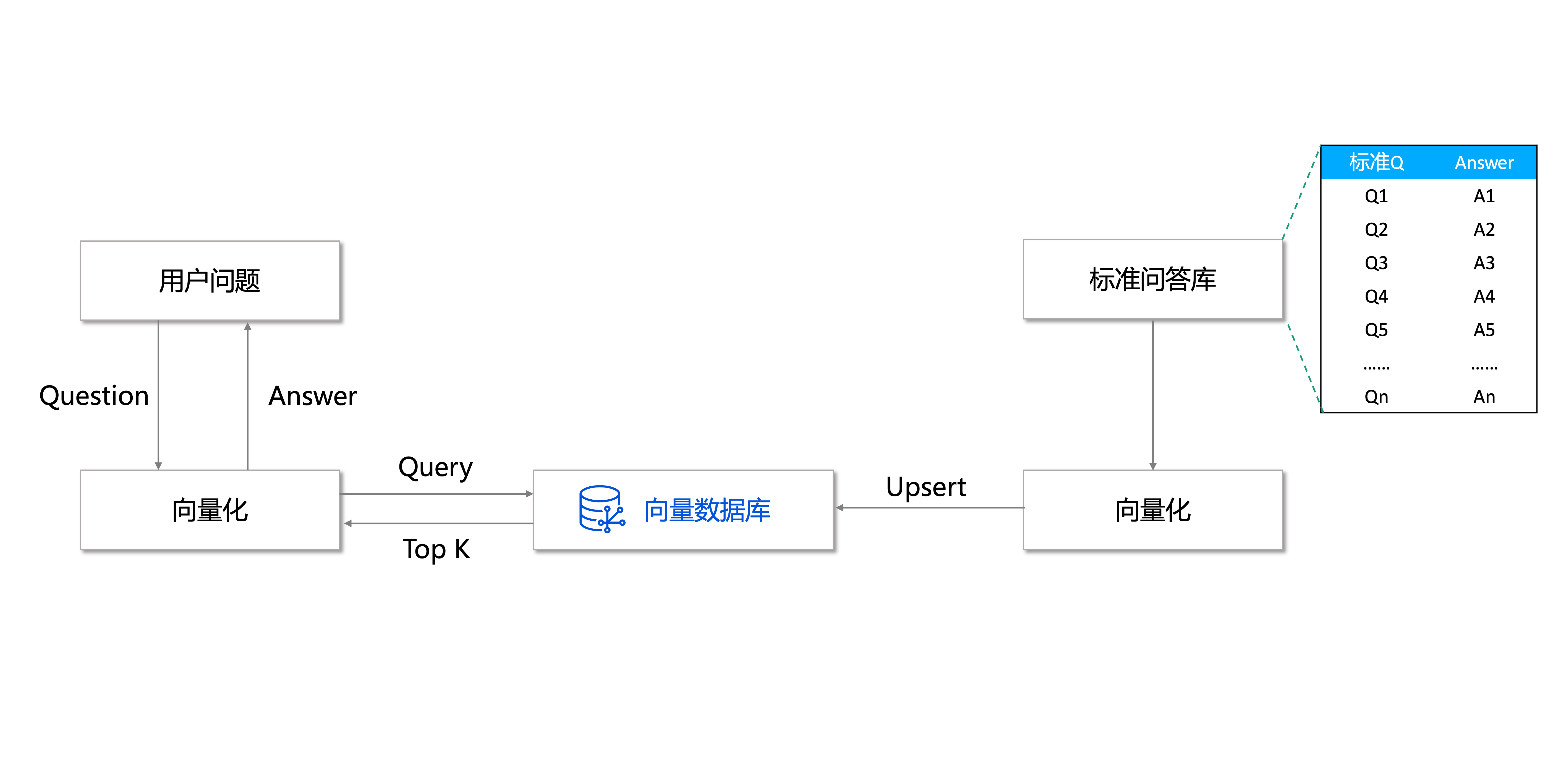
问答系统的应用场景非常广泛,例如智能客服、智能助手、智能家居等。在这些场景中,用户可以通过自然语言提问获取相关信息,例如查询产品信息、控制家居设备等。通过使用向量数据库来存储和检索相关的向量数据,问答系统可以更快速、准确地响应用户的请求,提高用户体验。
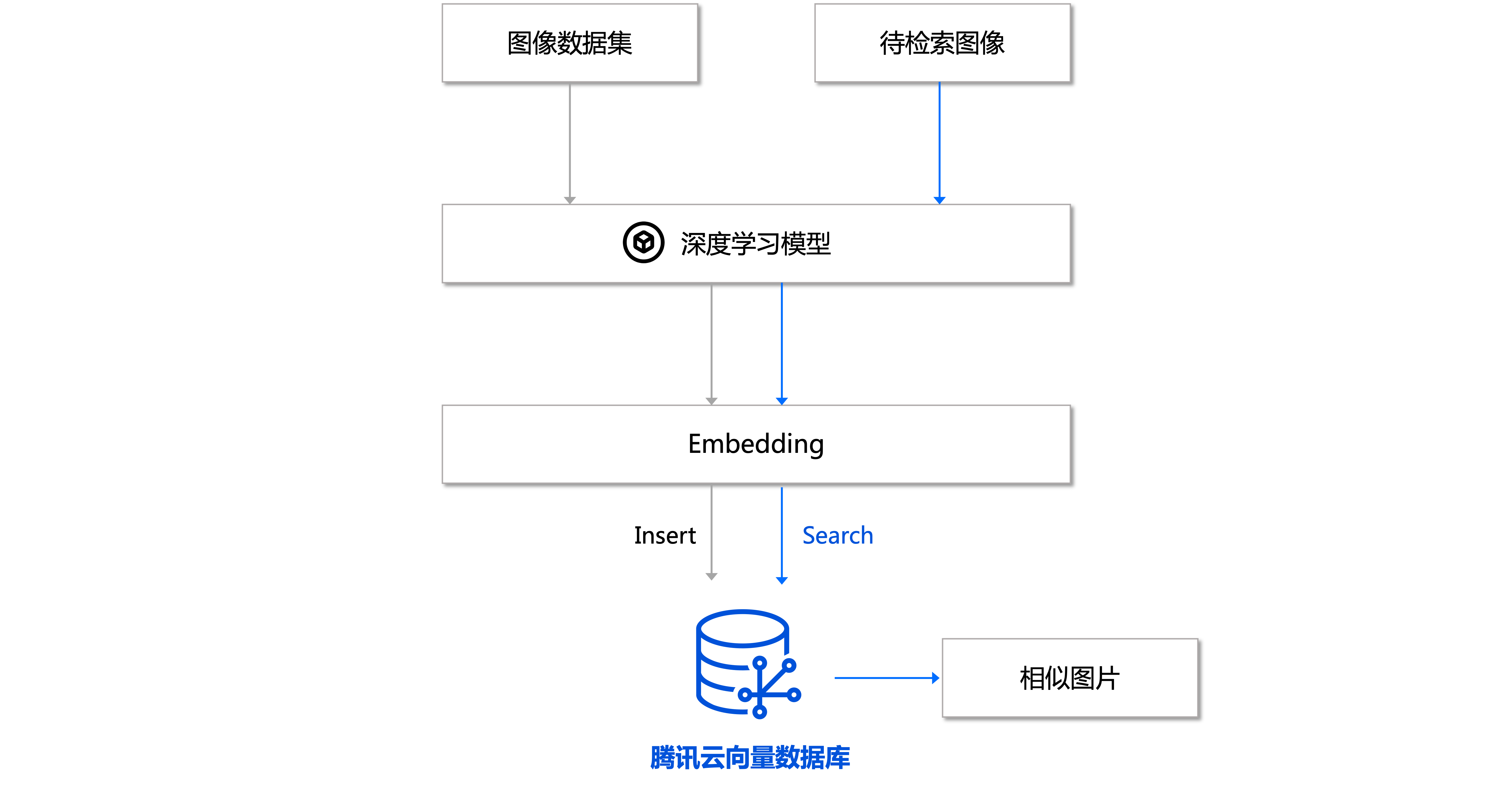
文本/图像检索
文本/图像检索任务是指在大规模文本/图像数据库中搜索出与指定图像最相似的结果,在检索时使用到的文本/图像特征可以存储在向量数据库中,通过高性能的索引存储实现高效的相似度计算,进而返回和检索内容相匹配的文本/图像结果。下图以图像检索为例介绍任务流程。
图库类网站多模态搜索场景
当前大型的图片素材网站和分享社交应用等,通常都有几亿甚至上百亿的图片量,只能提供简单的文字搜索或者单一的图片搜索方式,用户无法快速地找到所需的图片。而使用DashVector向量检索服务,将图片内容和文本描述以向量形式表示,并将其存储到向量数据库中。当用户搜索时,支持以文搜图,图搜图以及文字+图片组合搜索精确过滤等多种模态的搜索模式,将搜索需求也通过向量表示,在向量数据库中进行相似搜索,帮助用户迅速找到想要的图片,从而提升用户体验。
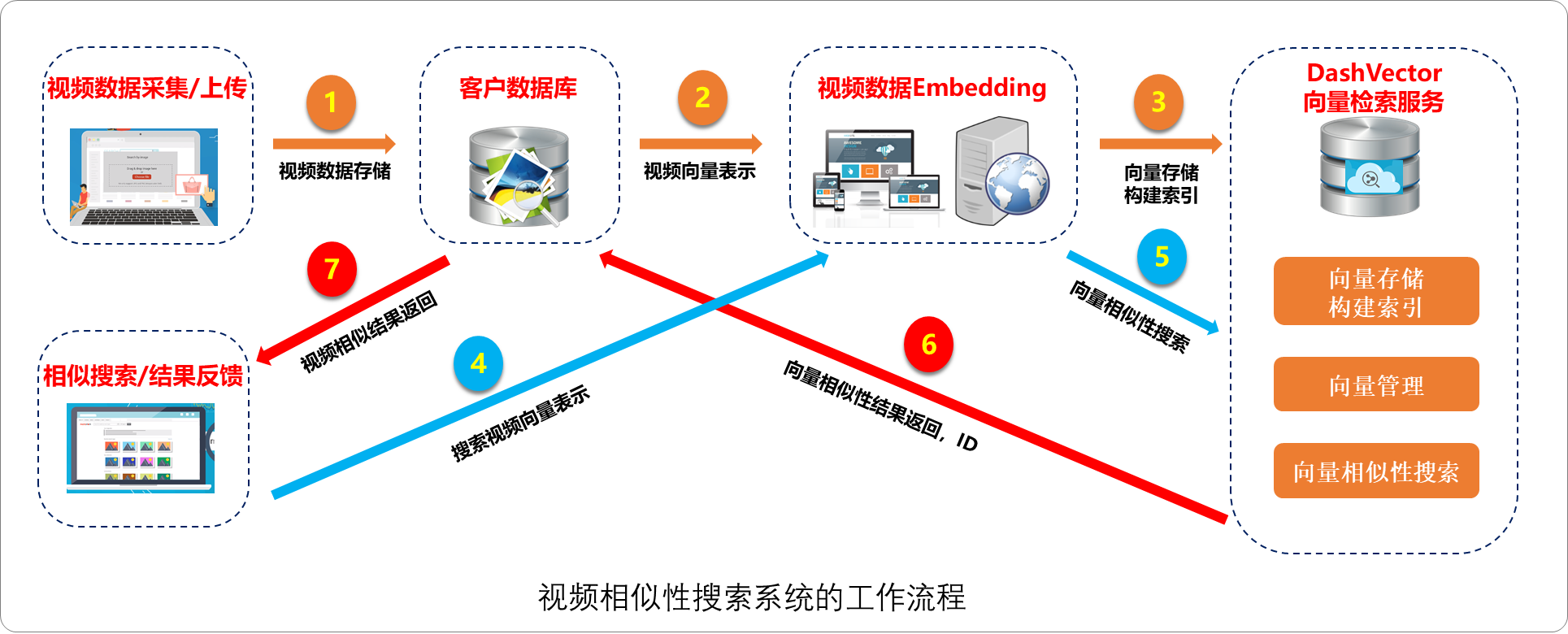
视频检索场景
在视频检索场景中,例如视频监控系统、影视资源网站、短视频应用等平台,其中包含了各种视频数据。使用向量检索服务通过将视频数据转换为向量表示,并将其存储到向量数据库中。当用户看到一个电影片段或频频截图时,使用视频相似性搜索系统进行基于内容向量的视频检索,从而快速检索出与查询视频最相似的视频,并返回给用户作为搜索结果。同时还可以在向量数据库中使用基于聚类的视频检索方法,对视频进行聚类,并在聚类之间进行快速检索,提高检索效率和准确度。
9.总结
亚马逊云科技大语言模型和向量数据库都在其各自领域带来了创新和广泛应用。在实际应用中,我们应根据需求和优势进行选择,并充分评估其性能、功能支持、扩展性以及社区支持和文档资料等因素。随着技术的不断进步和发展,这些技术将为我们带来更多创新和应用的可能性。
AWS向量数据库拥有出色的相似度查询能力。借助先进的算法和索引,它能快速在百万向量中定位最相似向量。这对需要进行相似度匹配或搜索的应用十分实用。AWS向量数据库支持丰富的数据模型。它能存储多种类型的向量数据,如图像、文字、音频等等。这让用户能根据自身需求自由选择合适的数据类型和模型,并灵活进行数据存储和查询。总结来看,AWS向量数据库是一款可靠性高、效率佳、灵活性强且安全的数据库服务。其全球化支持、可扩展性、强大的相似度查询功能、灵活的数据模型以及多重安全保护都是其显著优势。这使其成为处理大规模向量数据的完美选择。
相关文章:
向量数据库——AI时代的基座
向量数据库——AI时代的基座 1.前言 向量数据库在构建基于大语言模型的行业智能应用中扮演着重要角色。大模型虽然能回答一般性问题,但在垂直领域服务中,其知识深度、准确度和时效性有限。为了解决这一问题,企业可以利用向量数据库结合大模…...

【️什么是分布式系统的一致性 ?】
😊引言 🎖️本篇博文约8000字,阅读大约30分钟,亲爱的读者,如果本博文对您有帮助,欢迎点赞关注!😊😊😊 🖥️什么是分布式系统的一致性 ?…...

鸿蒙ArkTS Web组件加载空白的问题原因及解决方案
问题症状 初学鸿蒙开发,按照官方文档Web组件文档《使用Web组件加载页面》示例中的代码照抄运行后显示空白,纠结之余多方搜索后扔无解决方法。 运行代码 import web_webview from ohos.web.webviewEntry Component struct Index {controller: web_webv…...
【Java】网络编程-UDP回响服务器客户端简单代码编写
这一篇文章我们将讲述网络编程中UDP服务器客户端的编程代码 1、前置知识 UDP协议全称是用户数据报协议,在网络中它与TCP协议一样用于处理数据包,是一种无连接的协议。 UDP的特点有:无连接、尽最大努力交付、面向报文、没有拥塞控制 本文讲…...

【设计模式】之工厂模式
工厂模式 1.介绍 工厂模式(创建型模式),是我们最常用的实例化对象模式,是用工厂方法代替new操作的一种模式;在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的…...

70.爬楼梯
题目描述 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 注意: 给定 n 是一个正整数。 示例 1: 输入: 2 输出: 2 解释: 有两种方法可以爬到楼顶…...

【论文解读】ICLR 2024高分作:ViT需要寄存器
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://arxiv.org/abs/2309.16588 摘要: Transformer最近已成为学习视觉表示的强大工具。在本文中,我们识别并表征监督和自监督 ViT 网络的特征图中的伪影。这些…...
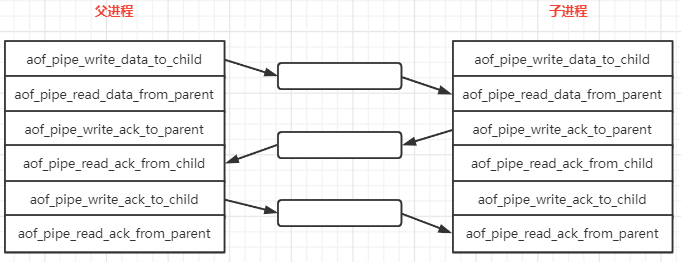
【Redis】AOF 基础
因为 Redis AOF 的实现有些绕, 就分成 2 篇进行分析, 本篇主要是介绍一下 AOF 的一些特性和依赖的其他函数的逻辑,为下一篇 (Redis AOF 源码) 源码分析做一些铺垫。 AOF 全称: Append Only File, 是 Redis 提供了一种数据保存模式, Redis 默认不开启。 AOF 采用日志的形式来记…...
C语言—每日选择题—Day50
一天一天的更新,也是达到50天了,精选的题有250道,博主累计做了不下500道选择题,最喜欢的题型就是指针和数组之间的计算呀,不知道关注我的小伙伴是不是一直在坚持呢?文末有投票,大家可以投票让博…...
[C/C++]——内存管理
学习C/C的内存管理 前言:一、C/C的内存分布二、C语言中动态内存管理方式三、C中动态内存管理方式3.1、new/delete操作符3.1.2、new/delete操作内置类型3.1.3、new/delete操作自定义类型 3.2、认识operator new和operator delete函数3.3、了解new和delete的实现原理3…...
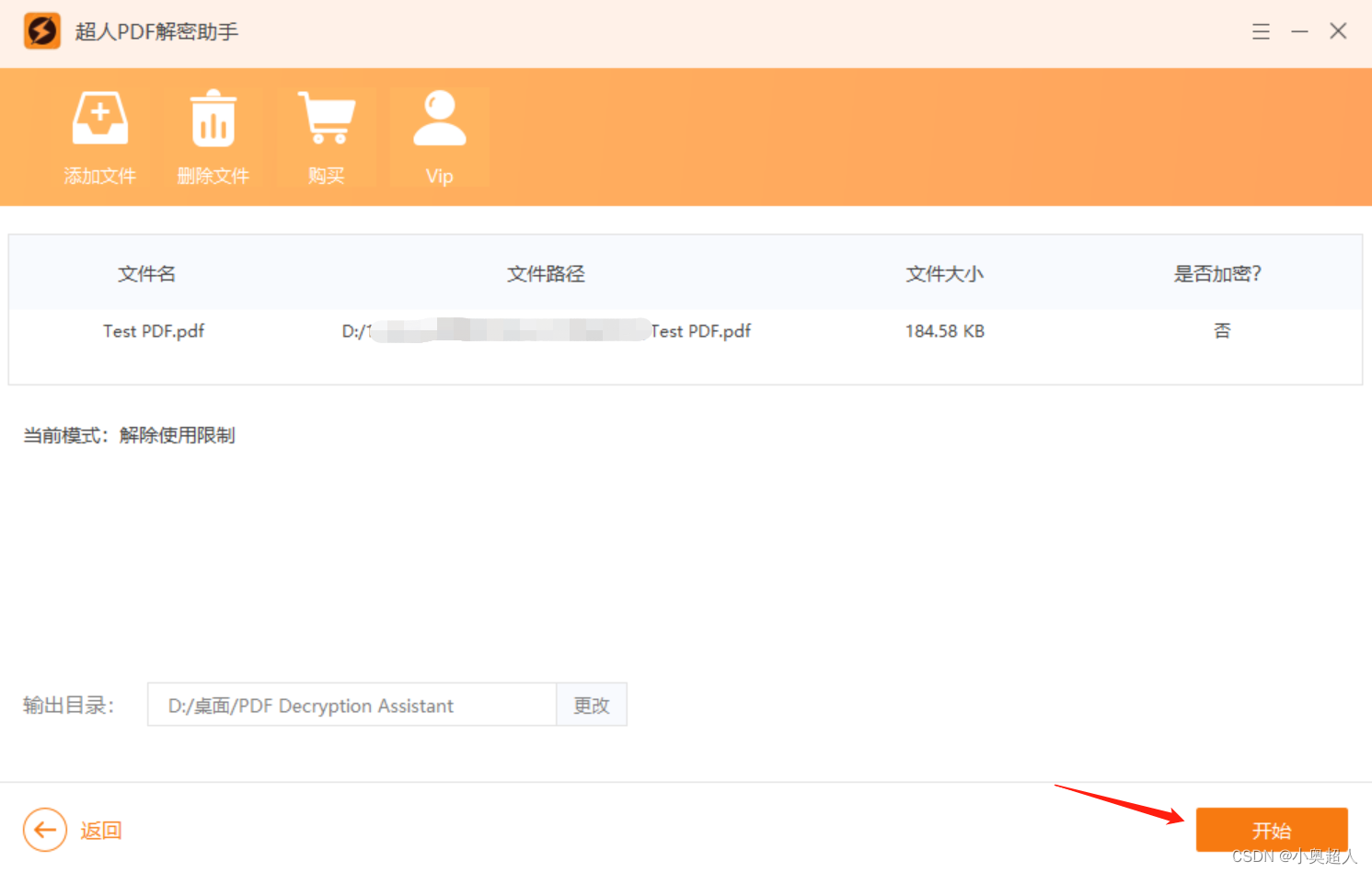
PDF文件的限制编辑,如何设置?
想要给PDF文件设置一个密码防止他人对文件进行编辑,那么我们可以对PDF文件设置限制编辑,设置方法很简单,我们在PDF编辑器中点击文件 – 属性 – 安全,在权限下拉框中选中【密码保护】 然后在密码保护界面中,我们勾选【…...
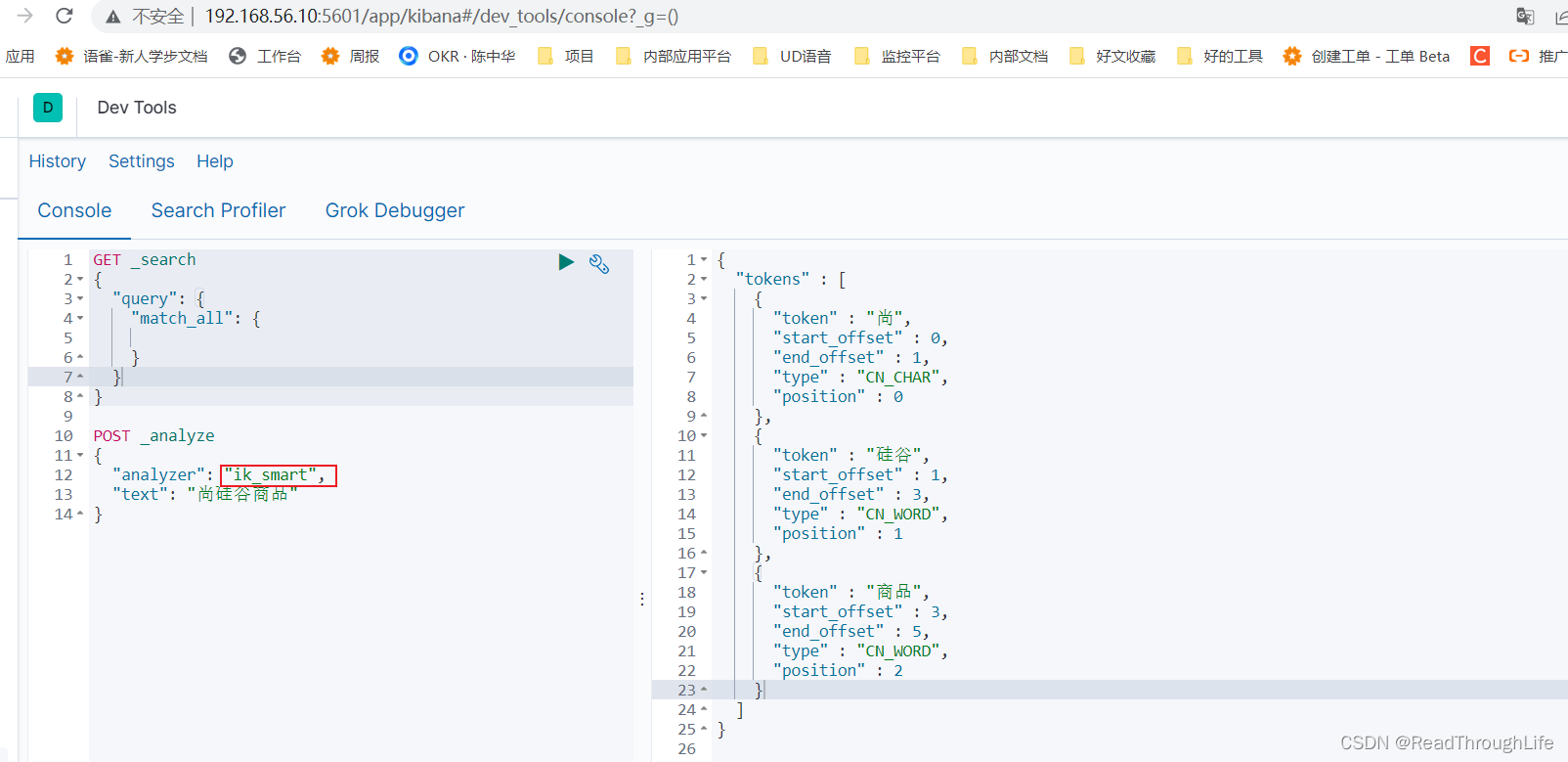
Linux 中使用 docker 安装 Elasticsearch 及 Kibana
Linux 中使用 docker 安装 Elasticsearch 及 Kibana 安装 Elasticsearch 和 Kibana安装分词插件 ik_smart 安装 Elasticsearch 和 Kibana 查看当前运行的镜像及本地已经下载的镜像,确认之前没有安装过 ES 和 Kibana 镜像 docker ps docker images从远程镜像仓库拉…...

在Flutter中使用PhotoViewGallery指南
介绍 Flutter中的PhotoViewGallery是一个功能强大的插件,用于在应用中展示可缩放的图片。无论是构建图像浏览器、相册应用,还是需要在应用中查看大图的场景,PhotoViewGallery都是一个不错的选择。 添加依赖 首先,需要在pubspec…...

c语言中的static静态(1)static修饰局部变量
#include<stdio.h> void test() {static int i 1;i;printf("%d ", i); } int main() {int j 0;while (j < 5){test();j j 1;}return 0; } 在上面的代码中,static修饰局部变量。 当用static定义一个局部变量后,这时局部变量就是…...

生信算法4 - 获取overlap序列索引和序列的算法
生信序列基本操作算法 建议在Jupyter实践,python版本3.9 1. 获取overlap序列索引和序列的算法实现 # min_length 最小overlap碱基数量3个 def getOverlapIndexAndSequence(a, b, min_length3):""" Return length of longest suffix of a matching…...

springboot 学习网站
Spring Boot 系列教程https://www.docs4dev.com/ Spring Boot 教程汇总 http://www.springboot.wiki/ Spring Cloud 微服务教程 http://www.springboot.wiki/ 1、自定义banner https://www.cnblogs.com/cc11001100/p/7456145.html 2、事件和监听器 https://blog.csd…...
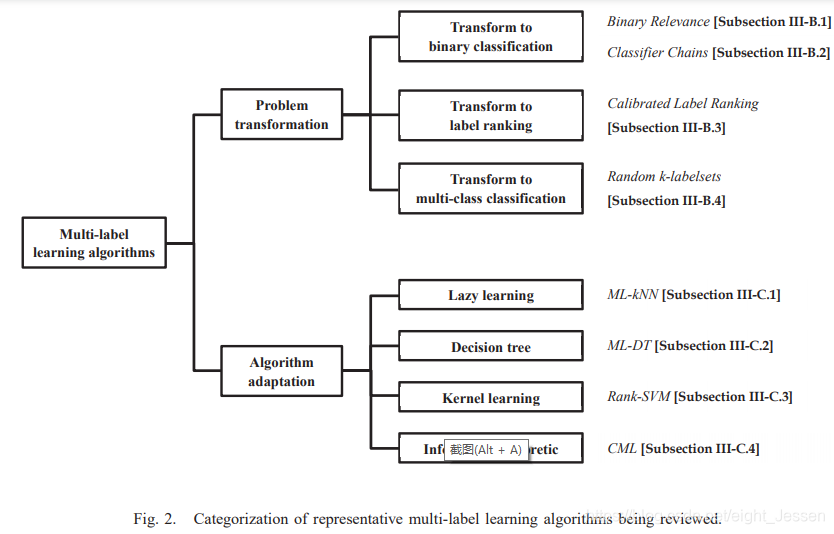
论文笔记:A review on multi-label learning
一、介绍 传统的监督学习是单标签学习,但是现实中一个实例可能对应多个标签。这篇文章介绍了多标签分类的定义和评价指标、多标签学习的算法还有其他相关的任务。 二、问题相关定义 2.1 多标签学习任务 假设 X R d X R^d XRd,表示d维的输入空间&am…...
接口文档 YAPI介绍
YAPI介绍 YAPI使用流程...

LeetCode 300最长递增子序列 674最长连续递增序列 718最长重复子数组 | 代码随想录25期训练营day52
动态规划算法10 LeetCode 300 最长递增子序列 2023.12.15 题目链接代码随想录讲解[链接] int lengthOfLIS(vector<int>& nums) {//创建变量result存储最终答案,设默认值为1int result 1;//1确定dp数组,dp[i]表示以nums[i]为结尾的子数组的最长长度ve…...

Improving IP Geolocation with Target-Centric IP Graph (Student Abstract)
ABSTRACT 准确的IP地理定位对于位置感知的应用程序是必不可少的。虽然基于以路由器为中心(router-centric )的IP图的最新进展被认为是前沿的,但一个挑战仍然存在:稀疏IP图的流行(14.24%,少于10个节点,9.73%孤立)限制了图的学习。为了缓解这个问题,我们将目标主机(ta…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...
Element-Plus:popconfirm与tooltip一起使用不生效?
你们好,我是金金金。 场景 我正在使用Element-plus组件库当中的el-popconfirm和el-tooltip,产品要求是两个需要结合一起使用,也就是鼠标悬浮上去有提示文字,并且点击之后需要出现气泡确认框 代码 <el-popconfirm title"是…...
Web APIS Day01
1.声明变量const优先 那为什么一开始前面就不能用const呢,接下来看几个例子: 下面这张为什么可以用const呢?因为复杂数据的引用地址没变,数组还是数组,只是添加了个元素,本质没变,所以可以用con…...

统计按位或能得到最大值的子集数目
我们先来看题目描述: 给你一个整数数组 nums ,请你找出 nums 子集 按位或 可能得到的 最大值 ,并返回按位或能得到最大值的 不同非空子集的数目 。 如果数组 a 可以由数组 b 删除一些元素(或不删除)得到,…...

Spring Boot 中实现 HTTPS 加密通信及常见问题排查指南
Spring Boot 中实现 HTTPS 加密通信及常见问题排查指南 在金融行业安全审计中,未启用HTTPS的Web应用被列为高危漏洞。通过正确配置HTTPS,可将中间人攻击风险降低98%——本文将全面解析Spring Boot中HTTPS的实现方案与实战避坑指南。 一、HTTPS 核心原理与…...

【Flask】:轻量级Python Web框架详解
什么是Flask? Flask是一个用Python编写的轻量级Web应用框架。它被称为"微框架"(microframework),因为它核心简单但可扩展性强,不强制使用特定的项目结构或库。Flask由Armin Ronacher开发,基于Werkzeug WSGI工具包和Jin…...