爬虫工作量由小到大的思维转变---<第十三章 Scrapy之pipelines分离的思考>
前言:
收到留言: "我的爬取的数据处理有点大,scrapy抓网页挺快,处理数据慢了!"
-----针对这位粉丝留言,我只想说:'你那培训班老师可能给你漏了课程! 大概你们上课讲的案例属于demo,他教了你一些基本操作,但他没有对相关业务对你讲透! 你研究一下pipelines,或者看我现在给你讲的.
正文
首先,你要清楚,当在Scrapy框架中,pipelines是顺序执行的,对item的处理通常是同步进行。
这时候,你要分析2件事:
1.我的数据要不要清洗
2.我的数据准备怎么存储
分开讲:
1.我的数据要不要清洗:
如果需要清洗,item的数据里比较多,我建议你转一下pd.dataframe;这样,会比正常运算要快得多;然后,给你3条建议:
- 避免在循环内使用 df.apply():---> apply() 是行或列级别的操作函数,效率相对较低。如果可以,尝试用更高效的Pandas内建函数代替,比如使用逻辑运算与 numpy 的向量化操作。
- 对于字符串处理,如果数据量很大,应当尽量使用向量化方法,例如 .str 方法或其他Pandas字符串操作代替 lambda 函数。
- 当创建新的列时,用条件表达式替代 .apply(lambda) 可以获得更好的性能,条件表达式在Pandas中是向量化的。
如果pandas处理之后,不满足:
分离繁重操作:
如果有些操作很繁重,可以将它们移动到Scrapy的middleware或者扩展来进行,这样可能有助于提高item pipeline的处理速度。这时候,你就可以通过外部自己写一个多线程/多进程来处理你的数据工作!
当然,处理item的数据清理工作,我建议你用:
ItemAdapter
什么是ItemAdapter?
-它是一个包装类,允许我们以一致的方式处理不同种类的数据结构,例如dict、scrapy.Item以及自定义的数据类。无论内部的数据存储格式如何,ItemAdapter都能让我们同等的获取和设置Item中的字段值。
ItemAdapter的使用场景
ItemAdapter特别适用于编写更通用的Pipeline代码。无论传入的Item是Scrapy的Item实例还是普通的dict,甚至是自定义的类实例,你都可以使用相同的方法来处理它们。这样的设计大大提升了代码的复用性和可维护性。
案例:
import scrapy
from itemadapter import ItemAdapter
import pandas as pd
import numpyclass JihaiPipeline:def open_spider(self, spider):# 初始化工作,例如连接数据库passdef close_spider(self, spider):# 清理工作,例如关闭数据库连接passdef process_item(self, item, spider):# 使用ItemAdapter包装itemadapter = ItemAdapter(item)# 进行数据处理...# 例如,假设我们需要给所有Item添加一个新字段adapter['new_field'] = '丢一个新的字段进去'# 处理完后,返回itemreturn item
在上面的代码中,我们没有直接操作原始的item对象,而是将其通过ItemAdapter(item)包装起来。然后就可以像操作字典一样,通过adapter['new_field']来设置新字段。在管道中修改完数据后,可以直接将Item传递到下一个管道。
ItemAdapter中的向量化操作
对于爬虫项目,可能需要对数据进行更复杂的清洗和转换操作。在Pandas的帮助下,我们可以执行向量化的数据处理工作,这是一种高效处理数据的方式。通过Pandas,利用DataFrame进行复杂的数据清洗和分析变得相当简便
案例:
class JihaiPipeline:# ...之前的方法...def process_item(self, item, spider):adapter = ItemAdapter(item)# 假设我们的item有一个成绩的列表需要处理grades = adapter.get('grades', [])# 使用Pandas创建DataFramedf = pd.DataFrame(grades)# 执行一些复杂的计算操作,例如计算平均分adapter['average_grade'] = df['score'].mean()# 返回处理后的itemreturn item
在这个例子中,我们先获取了成绩列表,然后使用这个列表创建了一个Pandas DataFrame。之后我们就可以利用DataFrame提供的方法进行各种操作,比如这里计算了一个平均分成绩,然后将其添加到了item中。
小总结:
ItemAdapter提供了一个透明的方式来处理项,帮助你更简单地编写与项结构无关的代码。与Pandas结合使用,它也使得在Scrapy中进行复杂数据处理成为可能。记住,一致性、可读性和可维护性是编写高质量爬虫代码时的关键点。
2.我的数据准备怎么存储?
如果你的数据比较单一,你直接存(就跟你老师教你的那样!) 如果你的数据已经到达了你的瓶颈,你最好做个分离;然后看我之前的文章,例如:存入sql--->你首先要想到的就是异步!
在Scrapy中,最佳实践通常是将数据处理(清洗、转换等)与数据存储(写入数据库等)分离。这为你的数据处理流水线提供了更好的组织结构和可扩展性。每个Pipeline应该只负责一个操作或一组相关操作。这样做的好处是:
1. 职责分离:这使得每个pipeline的职责更清晰。如果以后需要更改存储逻辑,只需要更改保存到SQL的pipeline,而不需要触及数据处理的pipeline。
2. 模块化:如果在将来需要将数据存储到不同的后端(例如不同的数据库,或者文件系统等),你可以简单地添加一个新的pipeline来处理这种情况,而不是更改现有代码。
3. 可维护性:代码维护更简单,因为数据清洗和存储是分开的,错误更容易追踪,代码更容易调试。
4. 可测试性:独立的pipeline更容易进行单元测试。
既然已经完成了数据处理,并且将结果整理成了待存储的格式,接下来的逻辑步骤是将这些数据保存到SQL数据库。创建一个新的Pipeline类专门用于与SQL数据库的交互,这样,你的 `XXXPipeline` 负责处理数据,并将处理后的数据传递给稍后在settings.py文件中定义优先级更低的SQL存储pipeline。
下面是创建一个专门用于存储数据到SQL数据库的pipeline的简单例子(要异步,往前看我文章有介绍):
# sql_pipeline.pyimport scrapy
from scrapy import Item
from itemadapter import ItemAdapterclass SQLStorePipeline:def open_spider(self, spider):# 这里设置数据库连接self.connection = create_connection_to_database()def close_spider(self, spider):# 关闭数据库连接self.connection.close()def process_item(self, item, spider):# 提取ItemAdapteradapter = ItemAdapter(item)# 保存到数据库的逻辑save_to_database(self.connection, adapter.as_dict())return item # 注意,返回item是为了允许多个pipelinedef create_connection_to_database():# 创建数据库链接逻辑passdef save_to_database(connection, item_data):# 将item数据保存到数据库的逻辑pass
在`settings.py`文件中,您需要确保新的`SQLStorePipeline`在`XXXPipeline`之后执行。这可以通过为它们分配不同的`ITEM_PIPELINES`值来实现:
# settings.pyITEM_PIPELINES = {'myproject.pipelines.XXXPipeline': 300, #处理数据清理的'myproject.pipelines.SQLStorePipeline': 800, #存储的
}
这样,每个item首先通过`JihaiPipeline`进行处理,然后再通过`SQLStorePipeline`进行存储。
通过这种方式,您既保持了pipeline的职责分割,又为后续的维护和可能的扩展性打下了良好的基础。如果有多个数据存储或处理需求,遵循这种模式是非常有好处的。
总结:
你就记住,如果你的item数据量比较大,一定要分离! 分完了,很多都能处理了! 另外,你记得itemAdapter的用法~ 他应该算是一个引子,透过他~你写着写着就会冒出很多怪招出来~ 然后,再不行,你就进行分布式! 反正你的业务已经模块化了,拿一个机器专门清理,拿一个机器专门存储~或者,丢到中间件,甩到外部去做多线程处理!这样,在爬虫过程中,对数据的清理和存储的工作量,就能被划分掉,不就轻了么...
请你看到这文章,给我点个赞!!
(让我知道你来了)
相关文章:

爬虫工作量由小到大的思维转变---<第十三章 Scrapy之pipelines分离的思考>
前言: 收到留言: "我的爬取的数据处理有点大,scrapy抓网页挺快,处理数据慢了!" -----针对这位粉丝留言,我只想说:你那培训班老师可能给你漏了课程! 大概你们上课讲的案例属于demo,他教了你一些基本操作,但他没有对相关业务对你讲透! 你研究一下pipelines,或者看我现…...
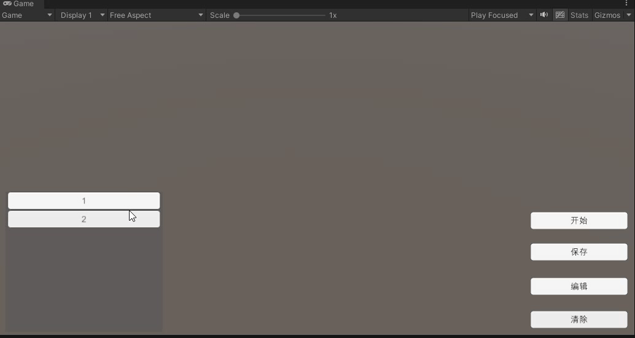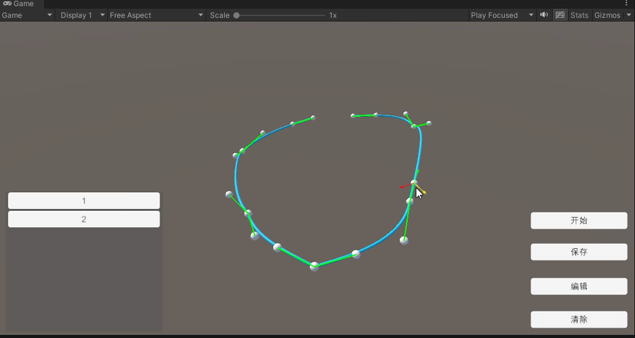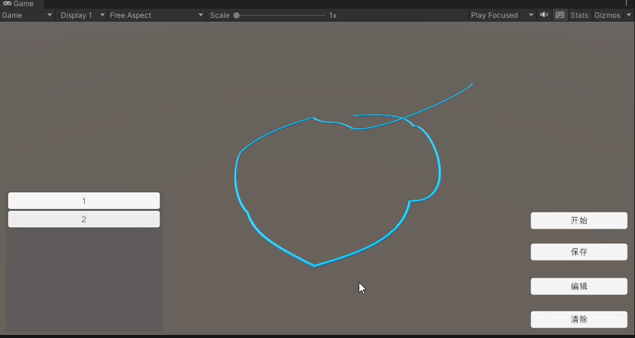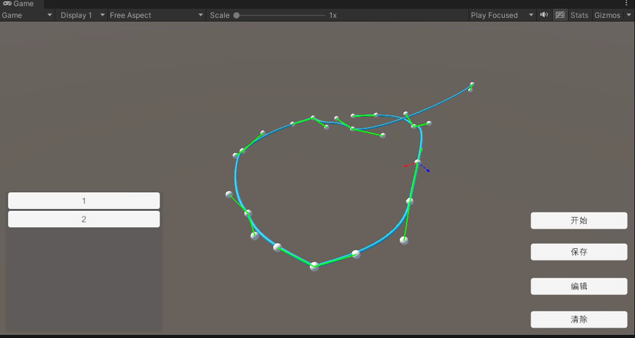
【Unity】运行时创建曲线(贝塞尔的运用)
[Unity]运行时创建线(贝塞尔的运用) 1. 实现的目标 在运行状态下创建一条可以使用贝塞尔方法实时编辑的网格曲线。 2. 原理介绍 2.1 曲线的创建 unity建立网格曲线可以参考Unity程序化网格体的实现方法。主要分为顶点,三角面,…...
基于DSP的IIR数字滤波器(论文+源码)
1.系统设计 在本次基于DSP的IIR数字低通滤波计中,拟以TMS320F28335来作为系统的主控制器,通过ADC0832模数转换芯片来对输入信号进行采集;通过TLC5615来将低通滤波后的信号进行输出;同时结合MATLAB仿真软件,对设计的II…...
Django(一)
1.web框架底层 1.1 网络通信 注意:局域网 个人一般写程序,想要让别人访问:阿里云、腾讯云。 去云平台租服务器(含公网IP)程序放在云服务器 先以局域网为例 我的电脑【服务端】 import socket# 1.监听本机的IP和…...

微信小程序如何利用createIntersectionObserver实现图片懒加载
微信小程序如何利用createIntersectionObserver实现图片懒加载 节点布局相交状态 API 可用于监听两个或多个组件节点在布局位置上的相交状态。这一组API常常可以用于推断某些节点是否可以被用户看见、有多大比例可以被用户看见。 节点布局相交状态 API中有一个 wx.createInter…...
七:爬虫-数据解析之正则表达式
七:正则表达式概述 正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母…...
云原生之深入解析亿级流量架构之服务限流思路与方法
一、限流思路 ① 熔断 系统在设计之初就把熔断措施考虑进去,当系统出现问题时,如果短时间内无法修复,系统要自动做出判断,开启熔断开关,拒绝流量访问,避免大流量对后端的过载请求。系统也应该能够动态监测…...

【Python炫酷系列】祝考研的友友们金榜题名吖(完整代码)
文章目录 环境需求完整代码详细分析系列文章环境需求 python3.11.4及以上版本PyCharm Community Edition 2023.2.5pyinstaller6.2.0(可选,这个库用于打包,使程序没有python环境也可以运行,如果想发给好朋友的话需要这个库哦~)【注】 python环境搭建请见:https://want595.…...

KL散度、CrossEntropy详解
文章目录 0. 概述1. 信息量1.1 定义1.2 性质1.3 例子2. 熵 Entropy2.1 定义2.2 公式2.3 例子3. 交叉熵 Cross Entropy3.1 定义3.2 公式3.3 例子4. KL 散度(相对熵)4.1 公式...

【算法】红黑树
一、红黑树介绍 红黑树是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。 红黑树是在1972年由Rudolf Bayer发明的,当时被称为平衡二叉B树(symmetric binary B-trees)。后来&am…...

2023楚慧杯 WEB方向 部分:(
1、eaaeval 查看源码能看见账号:username169,密码:password196提交这个用户密码可以跳转到页面/dhwiaoubfeuobgeobg.php 通过dirsearch目录爆破可以得到www.zip <?php class Flag{public $a;public $b;public function __construct(){…...

STM32 CAN多节点组网项目实操 挖坑与填坑记录2
系列文章,持续探索CAN多节点通讯, 上一篇文章链接: STM32 CAN多节点组网项目实操 挖坑与填坑记录-CSDN博客文章浏览阅读120次。CAN线性组网项目开发过程中遇到的数据丢包问题,并尝试解决的记录和推测分析。开发了一个多节点线性…...

Flink 数据类型 TypeInformation信息
Flink流应用程序处理的是以数据对象表示的事件流。所以在Flink内部,我么需要能够处理这些对象。它们需要被序列化和反序列化,以便通过网络传送它们;或者从状态后端、检查点和保存点读取它们。为了有效地做到这一点,Flink需要明确知…...

基于python的leetcode算法介绍之递归
文章目录 零 算法介绍一 简单示例 辗转相除法Leetcode例题与思路[509. 斐波那契数](https://leetcode.cn/problems/fibonacci-number/)解题思路:题解: [206. 反转链表](https://leetcode.cn/problems/reverse-linked-list/)解题思路:题解&…...

2023年度佳作:AIGC、AGI、GhatGPT、人工智能大语言模型的崛起与挑战
目录 前言 01 《ChatGPT 驱动软件开发》 内容简介 02 《ChatGPT原理与实战》 内容简介 03 《神经网络与深度学习》 04 《AIGC重塑教育》 内容简介 05 《通用人工智能》 目 录 前言 2023年是人工智能大语言模型大爆发的一年,一些概念和英文缩写也在这一…...
Axure的交互以及情形的介绍
一. 交互 1.1 交互概述 通俗来讲就是,谁用了什么方法做了什么事情,主体"谁"对应的就是axure中的元件,"什么方法"对应的就是交互事件,比如单击事件、双击事件,"什么事情"对应的就是交互…...
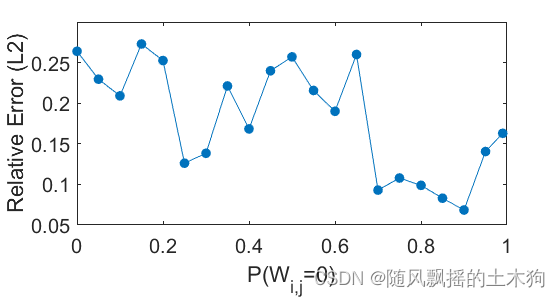
【MATLAB第84期】基于MATLAB的波形叠加极限学习机SW-ELM代理模型的sobol全局敏感性分析法应用
【MATLAB第84期】基于MATLAB的波形叠加极限学习机SW-ELM代理模型的sobol全局敏感性分析法应用 前言 跟往期sobol区别: 1.sobol计算依赖于验证集样本,无需定义变量上下限。 2.SW-ELM自带激活函数,计算具有phi(x)e^x激…...
米游社区表情包整合网站源码
源码介绍 米游社表情包整合网站源码,来自Github大佬的项目,包含米游兔123枚,米游社 玩家12枚,崩坏 星穹铁道112枚,绝区零218枚,NAP32枚,崩坏RPG62枚,崩坏3-1282枚,原神 …...

easyexcel调用公共导出方法导出数据
easyexcel备忘 Slf4j public class ConditionDownloadUtil {//扫描在xboot 包下所有IService 接口的子类, 每次启动服务后, 重新扫描public final static Class[] classesExtendsIService ClassUtil.scanPackageBySuper("cn.exrick.xboot", IService.class).toArra…...
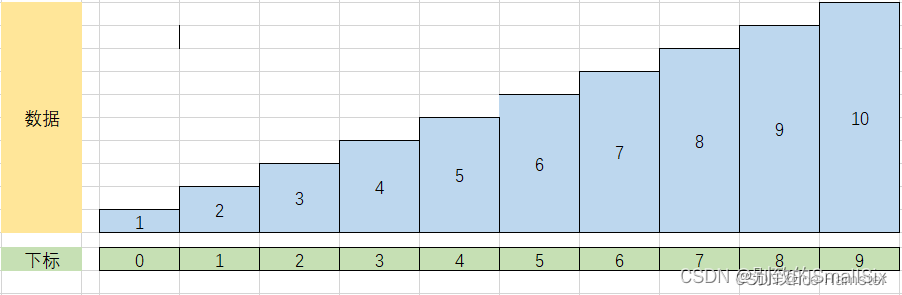
C语言插入排序算法及代码
一、原理 在待排序的数组里,从数组的第二个数字开始,通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。 二、代码部分 #include<stdio.h> #include<stdlib.h> int ma…...

【实践】绝影X20四足机器狗:从多线激光雷达到自主导航的完整链路解析
1. 绝影X20四足机器狗硬件启动与数据采集 第一次接触绝影X20时,我被它流畅的运动姿态惊艳到了。这款由云深处科技研发的四足机器狗,搭载了RoboSense速腾聚创的多线激光雷达,配合高性能IMU,为自主导航提供了扎实的硬件基础。 启动设…...

探索空气流注放电模型:基于Comsol等离子体模块的奇妙之旅
空气流注放电模型,采用等离子体模块,包含多种化学反应 空气流注放电模型,采用等离子体模块,包含多种化学反应 Comsol等离子体模块 空气棒板放电 11种化学反应 放的是求的速率 碰撞界面数据在bolsig里求出来速率 导入模型 然后导入…...
)
Spring Cloud OpenFeign实战:两种方式优雅传递HTTP请求头(附完整代码示例)
Spring Cloud OpenFeign请求头传递深度解析:从原理到实战 微服务架构中,服务间通信的请求头传递是个看似简单却暗藏玄机的问题。想象一下这样的场景:用户登录信息、追踪ID、地域标识等关键数据需要在服务调用链中无损传递,而你的团…...

视频内容结构化提取:自动化PPT提取工具的专业解决方案
视频内容结构化提取:自动化PPT提取工具的专业解决方案 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 当您面对长达数小时的会议录像或在线课程视频,需要从中…...
)
Linux下lspci和setpci工具编译与使用全攻略(附常见问题解决)
Linux下lspci和setpci工具深度解析与实战指南 1. PCI设备管理工具概述 在Linux系统管理中,PCI设备的管理与调试是系统管理员和嵌入式开发者经常需要面对的任务。作为PCI设备信息查询与配置的核心工具,lspci和setpci在设备驱动开发、硬件兼容性测试、系统…...
:关键新材料)
全网唯一 卡脖子全领域破局系列(6):关键新材料
卡脖子全领域破局系列(6):关键新材料——芯片、光刻机、航空、电池都被卡的“底层粮食”,全产业链瓶颈与突围路线 欢迎搬运,让更多技术人看清真相、参与突围,打破技术垄断 0. 开篇明义 前面五章我们讲了&am…...

MCGS与S7-1200以太网通讯实战:从组态变量映射到DB块数据交换的最佳实践
MCGS与S7-1200以太网通讯实战:从组态变量映射到DB块数据交换的最佳实践 在工业自动化项目中,稳定高效的设备通讯是系统可靠运行的基础。MCGS组态软件与西门子S7-1200 PLC的以太网通讯,作为国内自动化领域常见的组合方案,其数据交换…...

手把手教你用GetSet实现Simulink模型与C代码的高效交互
手把手教你用GetSet实现Simulink模型与C代码的高效交互 在嵌入式系统开发中,Simulink模型与外部C代码的高效交互是一个常见需求。无论是硬件在环测试还是嵌入式代码生成,数据如何在模型与已有C代码间双向传递都是开发者必须掌握的技能。本文将深入探讨Ge…...

cv_unet_image-colorization效果对比:自然风景与建筑图像着色作品集
cv_unet_image-colorization效果对比:自然风景与建筑图像着色作品集 黑白照片总带着一种时光的厚重感,但有时候,我们也会好奇,如果它们有了颜色,会是什么样子?是更接近历史的真实,还是能焕发出…...

IMX6Q双通道LVDS屏幕驱动:从设备树配置到双屏同显的实战解析
1. LVDS显示技术基础与IMX6Q硬件特性 LVDS(Low-Voltage Differential Signaling)是嵌入式设备中常见的显示接口技术,我在多个工业控制项目中都深度使用过这种方案。它的核心优势在于通过差分信号传输实现抗干扰能力,实测在电机设备…...