C++深入学习之STL:2、适配器、迭代器与算法部分
适配器概述
C++标准模板库(STL)中提供了几种适配器,这些适配器主要用于修改或扩展容器类的功能。STL中的适配器主要包括以下几种:
1、迭代器适配器:迭代器适配器提供了一种机制,可以将非迭代器对象转换为迭代器对象。比如back_insert_iterator和front_insert_iterator,这两个迭代器适配器分别提供了在容器的末尾和开头插入元素的功能。
2、函数对象适配器:函数对象适配器是一种通用机制,它为任何满足函数对象需求的对象提供了一个接口。这包括函数调用适配器如binder1st和binder2nd,这些适配器可以将二元操作符转换为单目操作符;以及函数对象适配器如unary_function和binary_function,这些适配器为函数对象提供了统一的接口。
3、流适配器:流适配器允许你将流包装在其他流中,从而改变或扩展其行为。例如,stringstream可以用于将字符串作为输入或输出流。
4、容器适配器:容器适配器提供了一种机制,可以修改或扩展容器的行为。例如,stack和queue就是容器适配器,它们分别提供了栈和队列的数据结构。
这些适配器为C++程序员提供了强大的工具,使他们能够以灵活的方式使用STL容器和算法。
容器适配器
C++标准模板库(STL)中的容器适配器是一种特殊类型的容器,它们为特定的STL容器提供了一种包装器,允许以不同的方式使用这些容器。容器适配器提供了一种机制,可以修改或扩展容器的行为,以满足特定的需求。
容器适配器主要有以下几种:
1、栈(stack)适配器:栈是一种后进先出(LIFO)的数据结构,只能在一端(称为栈顶)进行插入和删除操作。STL中的stack适配器提供了一个基于栈的容器,它提供了在栈顶插入和删除元素的操作。stack适配器提供了一个push方法用于在栈顶插入元素,一个pop方法用于删除栈顶元素,以及一个top方法用于获取栈顶元素。
2、队列(queue)适配器:队列是一种先进先出(FIFO)的数据结构,只能在一端插入元素,在另一端删除元素。STL中的queue适配器提供了一个基于队列的容器,它提供了在队列尾部插入元素和从队列头部删除元素的操作。queue适配器提供了两个方法:push用于在队列尾部插入元素,pop用于删除队列头部元素。
3、优先队列(priority_queue)适配器:优先队列是一种数据结构,其中元素具有优先级,优先级最高的元素总是位于队列的顶部。STL中的priority_queue适配器提供了一个基于优先队列的容器,它允许你指定一个比较函数或函数对象,用于确定元素的优先级。priority_queue适配器提供了两个方法:push用于向队列中插入元素,pop用于删除优先级最高的元素。
这些容器适配器为C++程序员提供了一种方便的方式来使用STL容器,而无需编写大量的代码来手动实现这些数据结构的行为。通过使用容器适配器,我们可以更轻松地处理特定类型的数据,并利用STL提供的强大功能来处理这些数据。
栈(stack)适配器
C++标准模板库(STL)中的栈容器适配器是一个封装了底层容器行为,使其符合栈数据结构操作的特殊容器。栈是一种后进先出(LIFO)的数据结构,只能在一端(称为栈顶)进行插入和删除操作。
栈容器适配器提供了一种方便的方式来使用STL中的容器,同时保持栈的特性。它提供了一组与栈操作相对应的方法,用于在栈顶插入和删除元素。下面是关于C++ STL中栈容器适配器的详细介绍:
基本操作:
push:在栈顶插入一个元素。
pop:删除栈顶元素。
top:获取栈顶元素,但不删除。
empty:检查栈是否为空。
使用方式:
#include <stack>
#include <iostream> int main() { std::stack<int> myStack; // 向栈中压入元素 myStack.push(10); myStack.push(20); myStack.push(30); // 输出栈顶元素 std::cout << "栈顶元素: " << myStack.top() << std::endl; // 弹出栈顶元素并输出 while (!myStack.empty()) { std::cout << "弹出的元素: " << myStack.top() << std::endl; myStack.pop(); } return 0;
}
底层容器:栈容器适配器底层可以使用任何STL容器作为其存储机制,如vector、deque等。默认情况下,std::stack使用std::vector作为底层容器。你可以通过构造函数或成员函数来指定底层容器的类型。例如,std::stack<int, std::deque> myStack;使用deque作为底层容器。
异常处理:在进行插入和删除操作时,如果底层容器无法满足需求(例如,空间不足),栈容器适配器会抛出相应的异常。你可以通过捕获异常来处理这些错误情况。
自定义比较函数:在某些情况下,你可能希望根据自定义的比较函数来确定元素的优先级。你可以通过向std::priority_queue提供自定义的比较函数或函数对象来实现这一点。同样,栈容器适配器也可以使用类似的机制来控制元素的排序行为。
关联容器:除了基础的栈操作,STL还提供了关联容器如std::map和std::set,它们本质上也是基于栈的适配器,但提供了更复杂的操作和语义。这些关联容器允许你根据键值对进行插入、删除和查找操作,同时保持元素的顺序。
总的来说,C++ STL中的栈容器适配器提供了一种高效的方式来使用STL容器来模拟栈数据结构的行为。通过使用这些适配器,我们可以更方便地处理特定类型的数据,并利用STL提供的强大功能来处理这些数据。
队列(queue)适配器
C++标准模板库(STL)中的队列容器适配器是一个封装了底层容器行为,使其符合队列数据结构操作的特殊容器。队列是一种先进先出(FIFO)的数据结构,只能在一端插入元素,在另一端删除元素。
队列容器适配器提供了一种方便的方式来使用STL中的容器,同时保持队列的特性。它提供了一组与队列操作相对应的方法,用于在队列尾部插入元素和从队列头部删除元素。下面是关于C++ STL中队列容器适配器的详细介绍:
基本操作:
push:在队列尾部插入一个元素。
pop:删除队列头部元素。
front:获取队列头部元素,但不删除。
back:获取队列尾部元素,但不删除。
empty:检查队列是否为空。
使用方式:
#include <queue>
#include <iostream> int main() { std::queue<int> myQueue; // 向队列中插入元素 myQueue.push(10); myQueue.push(20); myQueue.push(30); // 输出队列头部元素 std::cout << "队列头部元素: " << myQueue.front() << std::endl; // 弹出队列头部元素并输出 while (!myQueue.empty()) { std::cout << "弹出的元素: " << myQueue.front() << std::endl; myQueue.pop(); } return 0;
}
底层容器:队列容器适配器底层可以使用任何STL容器作为其存储机制,如vector、deque等。默认情况下,std::queue使用std::deque作为底层容器。我们可以通过构造函数或成员函数来指定底层容器的类型。例如,std::queue<int, std::vector> myQueue;使用vector作为底层容器。
异常处理:在进行插入和删除操作时,如果底层容器无法满足需求(例如,空间不足),队列容器适配器会抛出相应的异常。我们可以通过捕获异常来处理这些错误情况。
自定义比较函数:类似于栈容器适配器,我们也可以通过提供自定义的比较函数或函数对象来控制队列中元素的排序行为。这对于实现优先队列等高级数据结构非常有用。
关联容器:除了基础的队列操作,STL还提供了关联容器如std::map和std::set,它们本质上也是基于队列的适配器,但提供了更复杂的操作和语义。这些关联容器允许你根据键值对进行插入、删除和查找操作,同时保持元素的顺序。
总的来说,C++ STL中的队列容器适配器提供了一种高效的方式来使用STL容器来模拟队列数据结构的行为。通过使用这些适配器,我们可以更方便地处理特定类型的数据,并利用STL提供的强大功能来处理这些数据。
优先队列(priority_queue)适配器
#include <functional>
#include <iostream>
#include <queue>
#include <vector>using namespace std;void test(){//原理:优先级队列底层使用的是大根堆(大顶堆)。//当将元素存到优先级队列后,会按照std::less的标准进行排序,当//只有一个元素的时候,优先级最高的就是该元素,该元素会放在堆顶//当有新的元素插入进来之后,此时会与堆顶进行比较,如果堆顶小于//插入进来的元素,此时就满足std::less,就会将新的元素与堆顶进行//置换,新的元素成为新的堆顶,如果新插入的元素与堆顶进行比较,//发现堆顶大于等于新插入的元素,此时不满足std::less,那么老的堆顶//依旧是新的堆顶,不会发生置换//创建优先级对象//对于优先级对象来说其无法使用大括号形式进行初始化//可以使用迭代器范围的方式进行初始化vector<int> vec = {1,5,6,7,3};//priority_queue<int> number(vec.begin(),vec.end());//使用追加方式进行初始化//priority_queue<int> pque; 默认是升序,即值大的优先级最高priority_queue<int,vector<int>,greater<int>> pque;//改变默认方式,使其按降序排优先级//与之前学习容器的内容一样,若是自定义类型,那么就需要手动实现一下其优先的规则//实现一个compare类或者函数即可for(size_t idx=0; idx != vec.size();++idx){pque.push(vec[idx]);cout << "优先级最高的元素" << pque.top() << endl;}//优先级队列的遍历while(!pque.empty()){cout << pque.top() << " ";pque.top();}
}int main(){test();return 0;
}函数对象适配器
这一部分主要讲bind_first 和 bind_second。
bind_first 和 bind_second 是 C++ Standard Template Library (STL) 中的两个函数对象适配器,它们用于将二元函数对象绑定到特定的第一个和第二个参数。这两个函数对象在 STL 的 头文件中定义。
bind_first
bind_first 用于绑定二元函数对象的第一个参数。它的作用是将二元函数对象的第一个参数绑定到一个特定的值,然后返回一个新的一元函数对象,该对象在调用时将使用绑定的值作为其参数。
函数原型如下:
template <class BinaryFunction, class T> BinaryFunction bind_first(const BinaryFunction& f, const T& x);参数说明:
f:要绑定的二元函数对象。
x:要绑定为二元函数对象第一个参数的值。
返回值:返回一个新的一元函数对象,该对象在调用时将使用绑定的值作为其参数。
bind_second
bind_second 用于绑定二元函数对象的第二个参数。它的作用是将二元函数对象的第二个参数绑定到一个特定的值,然后返回一个新的一元函数对象,该对象在调用时将使用绑定的值作为其参数。
函数原型如下:
template <class BinaryFunction, class T> BinaryFunction bind_second(const BinaryFunction& f, const T& x);
参数说明:
f:要绑定的二元函数对象。
x:要绑定为二元函数对象第二个参数的值。
返回值:返回一个新的一元函数对象,该对象在调用时将使用绑定的值作为其参数。
bind_first与bind_second示例
假设我们有一个二元函数对象 Add,它用于将两个数相加。我们可以使用 bind_first 和 bind_second 来创建一个新的一元函数对象,该对象将一个特定的数作为参数,并返回两个固定数之和。
#include <iostream>
#include <functional> // for bind_first and bind_second // 定义一个二元函数对象,用于将两个数相加
struct Add { int operator()(int a, int b) const { return a + b; }
}; int main() { Add add; // 二元函数对象用于相加 // 使用 bind_first 绑定第一个参数为 5,创建一个新的一元函数对象 std::function<int(int)> add5 = std::bind_first(add, 5); std::cout << add5(3) << std::endl; // 输出:8,因为 5 + 3 = 8 // 使用 bind_second 绑定第二个参数为 10,创建一个新的一元函数对象 std::function<int(int)> add10 = std::bind_second(add, 10); std::cout << add10(2) << std::endl; // 输出:12,因为 2 + 10 = 12 return 0;
}
在这个例子中,我们使用 bind_first 将第一个参数绑定为 5,然后创建了一个新的一元函数对象 add5。这个新函数对象接受一个参数并返回 5 与该参数的和。类似地,我们使用 bind_second 将第二个参数绑定为 10,创建了另一个新的一元函数对象 add10。这个新函数对象接受一个参数并返回该参数与 10 的和。
bind
前面说的bind_first与bind_second都太死板了,bind是更为灵活的一个函数的对象适配器。
std::bind 是 C++ Standard Template Library (STL) 中的一个非常有用的函数,它用于绑定一个函数或可调用对象到一个或多个参数上,从而创建一个新的可调用对象。
函数原型如下:
template <class F, class... BoundArgs> constexpr auto bind(F&& f, BoundArgs&&... args) -> typename std::bind_helper<typename std::is_bind_expression<F>::type, F&&, BoundArgs&&...>::type;
参数说明:
f:要绑定的函数或可调用对象。
args:要绑定到函数或可调用对象的参数。
返回值:返回一个新的一元函数对象,该对象在调用时将使用绑定的参数作为其参数。
bind示例
假设我们有一个函数 gcd,用于计算两个数的最大公约数。我们想创建一个新的函数,该函数接受一个参数并返回两个固定数(例如42和56)的最大公约数。
#include <iostream>
#include <functional> // for std::bind // 定义一个函数,用于计算两个数的最大公约数
int gcd(int a, int b) { return b == 0 ? a : gcd(b, a % b);
} int main() { // 使用 std::bind 创建一个新函数,该函数接受一个参数并返回 42 和 56 的最大公约数 std::function<int(int)> gcdFixed = std::bind(gcd, 42, 56); std::cout << gcdFixed(14) << std::endl; // 输出:2,因为 42 和 56 的最大公约数是 2,并且 14 可以被 2 整除 return 0;
}
在这个例子中,我们使用 std::bind 将 gcd 函数绑定到两个固定的参数 42 和 56,然后创建了一个新的函数对象 gcdFixed。这个新函数对象接受一个参数并返回 42 和 56 的最大公约数。通过这种方式,我们可以轻松地创建一个新的函数对象,该对象执行特定的操作并返回固定的结果。
成员函数适配器(成员函数绑定器):mem_fn
std::mem_fn 是 C++ Standard Template Library (STL) 中的成员函数绑定器,它提供了一种便捷的方式来绑定成员函数到一个特定的对象实例,并创建一个新的可调用对象。std::mem_fn 主要用于绑定非静态成员函数。
std::mem_fn 的原型如下:
template <class T>
class mem_fn;
使用 std::mem_fn 的方式是通过 std::mem_fn(object, member_function) 来创建新的可调用对象,其中 object 是包含成员函数的类的实例,而 member_function 是要绑定的成员函数名。
以下是一个使用 std::mem_fn 的示例:
#include <iostream>
#include <functional> // for std::mem_fn
#include <vector> class MyClass {
public: int myMemberFunction(int value) { return value * 2; }
}; int main() { MyClass obj; std::vector<std::function<int()>> callbacks; // 使用 std::mem_fn 绑定成员函数和对象实例 //在C语言中,函数名字是函数的入口地址,C语言是不支持函数重载的//而在C++中因为存在函数重载,要找到函数,可以使用函数进行取地址&add;C++是兼容C语言,所以普通//函数的函数名就是函数的入口地址,但是C++中成员函数的函数名字就不是函数的入口地址,所以需要像下面这样写。auto callback = std::mem_fn(&MyClass::myMemberFunction, &obj); // 将回调添加到向量中 callbacks.push_back(callback); // 调用回调函数并获取结果 for (const auto& func : callbacks) { int result = func(); // 输出:84,因为 42 * 2 = 84 std::cout << "Result: " << result << std::endl; } return 0;
}在这个示例中,我们创建了一个 MyClass 的对象 obj,并使用 std::mem_fn 将其成员函数 myMemberFunction 绑定到该对象实例上。通过这种方式,我们创建了一个新的可调用对象 callback,它可以在稍后被调用。我们将这个回调添加到一个向量中,并在循环中调用它,从而演示了 std::mem_fn 的用法。需要注意的是,使用 std::mem_fn 时需要包含类的对象来调用绑定的成员函数。
函数包装器function
std::function 是 C++ Standard Template Library (STL) 中的一个通用、多态的函数包装器。它是一个类型安全的解决方案,用于存储、复制和调用任何 Callable 目标:函数、lambda 表达式、bind 表达式或任何其他可调用对象。
std::function 的主要用途包括:
回调和事件处理:在许多情况下,我们可能需要将一个函数或可调用对象作为参数传递给其他函数或存储为某个对象的状态。使用 std::function 可以简化这个过程,使其更加类型安全。
组合和链式调用:通过将函数或可调用对象存储在 std::function 对象中,我们可以轻松地与其他函数或方法组合使用,实现链式调用。
实现回调和观察者模式:在回调机制和观察者模式中,经常需要将函数或可调用对象作为参数传递给其他对象或组件。std::function 可以简化这个过程。
std::function 的声明语法如下:
std::function<返回类型(参数列表)>
其中,返回类型和参数列表指定了 std::function 所持有的 Callable 目标的签名。
下面是一个简单的 std::function 使用示例:
#include <iostream>
#include <functional> // for std::function
#include <vector> // 声明一个 std::function 对象,用于存储可调用对象
std::function<int(int)> f; // 定义一个可调用对象(函数或 lambda 表达式)
int add(int a, int b) { return a + b;
} int main() { // 将函数赋值给 std::function 对象 f = add; // 调用 std::function 对象并获取结果 int result = f(42, 56); // 输出:98,因为 42 + 56 = 98 std::cout << "Result: " << result << std::endl; // 使用 lambda 表达式赋值给 std::function 对象 f = [](int a, int b) { return a * b; }; result = f(42, 56); // 输出:2352,因为 42 * 56 = 2352 std::cout << "Result: " << result << std::endl; return 0;
}
在这个示例中,我们声明了一个 std::function 对象 f,并使用函数 add 和 lambda 表达式来赋值给它。然后我们可以通过 f 来调用这些可调用对象,并获取返回的结果。注意,std::function 可以持有任何可调用对象,包括函数、lambda 表达式、bind 表达式或其他任何可调用对象。
迭代器概述
迭代器是一种设计模式,用于遍历容器中的元素而不需要知道容器的底层表示方式。
C++标准模板库(STL)中的迭代器允许程序员通过迭代器来访问和操作容器中的元素,而不是直接使用指针。
迭代器具有以下特性:
1、双向访问:迭代器允许你通过++和–运算符向前或向后遍历容器中的元素。
2、随机访问:某些迭代器(如std::vector::iterator)还允许你通过索引操作符([])直接访问特定位置的元素。
3、关联容器:关联容器(如std::map和std::set)的迭代器通常也支持基于键的访问。
4、多态迭代器:多态迭代器可以指向不同类型的容器,只要它们都满足一定的接口要求。
迭代器的主要用途包括:
1、遍历容器:使用迭代器可以方便地遍历容器中的所有元素。例如,for循环结合迭代器可以用来遍历一个容器。
2、算法通用化:通过接受迭代器作为参数,STL算法可以在不同的容器上使用,从而提供更大的灵活性。
3、算法复用:由于算法只需要知道迭代器的接口,而不需要关心底层容器的实现细节,这有助于代码复用和减少重复的代码。
4、泛型编程:迭代器提供了一种通用的方式来处理不同类型的容器,使得算法可以在不同的数据结构上工作,从而实现更高级别的抽象和复用。
C++ STL提供了多种类型的迭代器,包括输入迭代器、前向迭代器、双向迭代器和随机访问迭代器。
1、输入迭代器:这是最简单的迭代器类型,它只支持前向遍历,且只能读取元素,不能修改元素。这种迭代器常用于需要读取元素但不需要修改元素的操作。
2、前向迭代器:与输入迭代器类似,前向迭代器也只支持前向遍历,但它可以修改元素。这意味着前向迭代器可以用于读取和修改元素的操作。
3、双向迭代器:双向迭代器既可以向前也可以向后遍历元素。这种迭代器通常用于需要在两个方向上遍历元素的操作。
4、随机访问迭代器:随机访问迭代器支持快速随机访问容器中的任意元素,无论是向前还是向后。这种迭代器通常用于需要高效访问和修改元素的操作,如排序、查找等。
这些不同类型的迭代器提供了不同程度的访问和遍历能力,以满足不同的需求。
例如,std::vector::iterator是一个随机访问迭代器,它允许你以任意顺序访问容器中的元素。而std::list::iterator则是一个双向迭代器,只能顺序遍历元素,不支持随机访问。
总之,C++ STL中的迭代器提供了一种强大而灵活的工具,用于遍历和操作容器中的元素。通过使用迭代器,程序员可以编写更加通用和可复用的代码,以适应不同的数据结构和算法需求。
流迭代器
C++标准模板库(STL)中的流迭代器是一种特殊的迭代器,用于处理输入流和输出流的数据。流迭代器允许程序员使用迭代器的方式来处理输入流或输出流中的数据,类似于处理容器中的数据。
流迭代器的主要用途是将数据从输入流中读取到容器中,或将数据从容器中写入到输出流中。通过使用流迭代器,程序员可以以一致的方式处理输入和输出流,并利用STL提供的算法和容器进行操作。
流迭代器的工作原理:
流迭代器通过包装输入流或输出流的指针来工作。它提供了一组类似于迭代器的操作,如++、–、*等,以便程序员可以像处理容器中的元素一样处理流中的数据。
流迭代器的种类:
istream_iterator:用于从输入流中读取数据的迭代器。它通常与输入流(如std::cin)一起使用,以从标准输入中读取数据。
ostream_iterator:用于向输出流中写入数据的迭代器。它通常与输出流(如std::cout)一起使用,以将数据写入标准输出。
如何使用流迭代器:
使用流迭代器通常涉及以下步骤:
创建一个流迭代器对象,并传递要使用的输入流或输出流的指针。
使用迭代器来读取或写入数据。例如,可以使用++操作符来逐个读取输入流中的元素,或使用*操作符来向输出流中写入元素。
在完成操作后,记得关闭流迭代器或相应的输入/输出流。
下面是一个使用istream_iterator和ostream_iterator从标准输入读取数据和从标准输出输出数据的示例:
void test()
{vector<int> numbers{1, 2, 3, 4, 5};ostream_iterator<int> osi(cout, "\n");copy(numbers.begin(), numbers.end(), osi);//copy是算法库algorithm中的一个函数
}void test()
{vector<int> numbers;cout << "111" << endl;istream_iterator<int> isi(cin);cout << "222" << endl;/* copy(isi, istream_iterator<int>(), numbers.begin());//对于vector插入元素应该调用push_back */copy(isi, istream_iterator<int>(), std::back_inserter(numbers));//插入迭代器cout << "333" << endl;copy(numbers.begin(), numbers.end(), ostream_iterator<int>(cout ,"\n"));
}
算法概述
算法中包含很多对容器进行处理的算法,使用迭代器来标识要处理的数据或数据段、以及结果的存放位
置,有的函数还作为对象参数传递给另一个函数,实现数据的处理。
这些算法可以操作在多种容器类型上,所以称为“泛型”,泛型算法不是针对容器编写,而只是单独依赖迭
代器和迭代器操作实现。
这些算法都位于下面的头文件中:
#include <algorithm> //泛型算法
#include <numeric> //泛化的算术算法
算法类型
1、非修改式的算法 count、find、find_xxx、for_each
2、修改式的算法 copy、remove、remove_if、unique、fill
3、排序算法 sort以及sort相关、lower_bound、upper_bound、binary_search
4、集合操作 set_intersection
5、heap的操作 make_heap、push_heap、pop_heap
6、最大值与最小值 min、max
7、比较函数 equal
8、当空间的申请与对象的构建分开的时候,可以uninitialized_copy未初始化拷贝操作,uninitialized_xxx
因为这些不用肯定就会忘的,所以只挑几个比较具有代表性的学习一下,其它的后面随用随查就是了。
函数类型
一元函数(UnaryFunction):函数的参数只有一个。
一元断言/一元谓词(UnaryPredicate):函数的参数只有一个,并且函数的返回类型是bool。
二元函数:函数的参数有两个。
n元函数:函数的参数有n个。
for_each、count 以及 find
重点提一下for_each的算法原型如下:
template <class _InputIter, class _Function>
_Function for_each(_InputIter __first, _InputIter __last, _Function __f)
{for ( ; __first != __last; ++__first)__f(*__first);//print(*__first)return __f;
}
对着测试代码很容易看出来其代码原型的逻辑,测试代码如下:
#include <iostream>
#include <algorithm>
#include <vector>
#include <iterator>using namespace std;//for_each的一元打印函数
void print(int value){cout << value << " ";
}void test(){//想去将vector进行遍历vector<int> number = {1,6,8,4,2,7,9};copy(number.begin(),number.end(),ostream_iterator<int>(cout," "));cout << endl;//使用for_each进行遍历的时候,第三个参数需要我们自己手动实现一个一元函数//然后for_each会根据这个函数来进行打印for_each(number.begin(),number.end(),print);cout << endl;//传函数时也可以使用匿名函数,匿名函数也就是lambda表达式//前面加个[]是语法要求,没有为什么,然后(int& value)是参数列表//最后跟大括号写上函数体,->后面跟函数的返回值类型for_each(number.begin(),number.end(),[](int& value)->void{++value;cout << value << " ";});cout << endl;
}void test2(){//count的使用vector<int> number = {1,2,5,5,2,3,6};size_t cnt = count(number.begin(),number.end(),3);cout << "cnt = " << cnt << endl;//find的使用auto it = find(number.begin(),number.end(),5);if(it == number.end()){cout << "该元素不存在" << endl;}else{cout << "该元素存在" << endl;}
}int main(){test();return 0;
}copy
STL中的copy函数是一个通用算法,用于将一个序列(源范围)中的元素复制到另一个序列(目标范围)中。这个函数在 头文件中定义。
函数原型如下:
template <class InputIterator, class OutputIterator> OutputIterator copy (InputIterator first, InputIterator last, OutputIterator result);
参数说明:
first 和 last:这两个参数定义了源范围的开始和结束,通常是一个迭代器对。
result:这个参数定义了目标范围的开始位置,即元素应该复制到的位置。
返回值:返回目标范围的末尾的下一个位置的迭代器。
使用示例:
#include <iostream>
#include <vector>
#include <algorithm> int main() { std::vector<int> src = {1, 2, 3, 4, 5}; std::vector<int> dst(src.size()); std::copy(src.begin(), src.end(), dst.begin()); for (int i : dst) { std::cout << i << " "; } std::cout << std::endl; return 0;
}输出:1 2 3 4 5
注意:copy函数不会检查目标范围是否足够大以容纳源序列的所有元素。因此,在使用此函数时,必须确保目标范围有足够的空间来容纳源序列的所有元素,以防止缓冲区溢出。如果需要将元素复制到已分配的空间之外,可以使用std::copy_n函数。
remove_if
remove_if 是 C++ Standard Template Library (STL) 中的一个非常有用的算法,用于从容器中删除满足特定条件的元素。这个函数返回一个迭代器,指向第一个被删除元素之后的位置。
函数原型如下:
template <class BidirIt, class UnaryPredicate>
BidirIt remove_if (BidirIt first, BidirIt last, UnaryPredicate p);
参数说明:
first 和 last:这两个参数定义了要处理的序列的开始和结束。
p:这是一个一元谓词,它接受一个元素并返回一个布尔值,如果元素满足条件(即返回 true),则该元素被删除,否则保留。
返回值:返回指向第一个被删除元素之后的位置的迭代器。
使用示例:
#include <iostream>
#include <vector>
#include <algorithm>
#include <functional> // for std::not_equal_to int main() { std::vector<int> v = {1, 2, 3, 4, 5, 6}; auto it = std::remove_if(v.begin(), v.end(), [](int i){ return i % 2 == 0; }); // 删除所有偶数 v.erase(it, v.end()); // 删除所有满足条件的元素 for (int i : v) { std::cout << i << " "; } std::cout << std::endl; return 0;
}
输出:1 3 5
在这个例子中,我们使用了 lambda 函数 [](int i){ return i % 2 == 0;} 来检查一个数字是否是偶数。remove_if 将所有偶数移动到容器的前面,并返回一个指向第一个被删除元素之后的位置的迭代器。然后,我们使用 erase 方法删除这些元素。结果是容器中只剩下奇数。
使用remove_if的时候需要注意,remove_if不会将满足条件的数据删除,但是会返回待删除元素的首地址(或者说首迭代器),然后再配合erase函数使用即可。
相关文章:

C++深入学习之STL:2、适配器、迭代器与算法部分
适配器概述 C标准模板库(STL)中提供了几种适配器,这些适配器主要用于修改或扩展容器类的功能。STL中的适配器主要包括以下几种: 1、迭代器适配器:迭代器适配器提供了一种机制,可以将非迭代器对象转换为迭代器对象。比如back_ins…...
Tiktok/抖音旋转验证码识别
一、引言 在数字世界的飞速发展中,安全防护成为了一个不容忽视的课题。Tiktok/抖音,作为全球最大的短视频平台之一,每天都有数以亿计的用户活跃在其平台上。为了保护用户的账号安全,Tiktok/抖音引入了一种名为“旋转验证码”的安…...

【Java 设计模式】设计原则
文章目录 ✨单一职责原则(SRP)✨开放/封闭原则(OCP)✨里氏替换原则(LSP)✨依赖倒置原则(DIP)✨接口隔离原则(ISP)✨合成/聚合复用原则(CARP&#…...

Druid连接池工具公式化SQL附踩坑记录
1. 需求 使用Druid连接池工具格式化sql用于回显时候美观展示 2. 代码示例 2.1 依赖 <dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.6</version> </dependency> 2.2 ParseUtils…...
UDP数据包发送)
Linux内核--网络协议栈(二)UDP数据包发送
目录 一、引言 二、数据包发送 ------>2.1、数据发送流程 三、协议层注册 ------>3.1、socket系统调用 ------>3.2、socket创建 ------>3.3、协议族初始化 ------>3.4、对应协议的socket创建 ------>3.5、协议注册 四、通过套接字发送网络数据 --…...
基于深度学习的时间序列算法总结
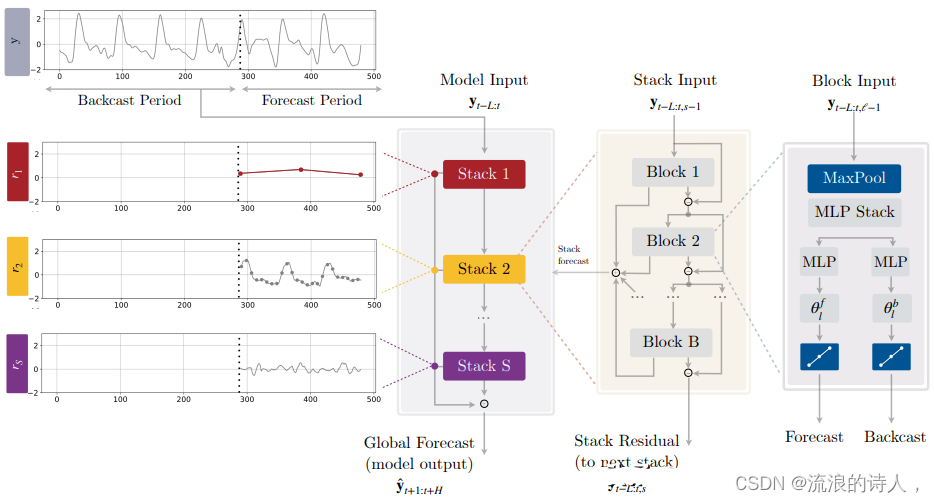
1.概述 深度学习方法是一种利用神经网络模型进行高级模式识别和自动特征提取的机器学习方法,近年来在时序预测领域取得了很好的成果。常用的深度学习模型包括循环神经网络(RNN)、长短时记忆网络(LSTM)、门控循环单元&a…...

nginx中多个server块共用upstream会相互影响吗
背景 nginx中经常有这样的场景,多个server块共用一个域名。 如:upstream有2个以上的域名,nginx配置两个server块,共用一个upstream配置。 那么,如果其中一个域名发生"no live upstreams while connecting to ups…...

基于信号完整性的一些PCB设计建议
最小化单根信号线质量的一些PCB设计建议 1. 使用受控阻抗线; 2. 理想情况下,所有信号都应该使用完整的电源或地平面作为其返回路径,关键信号则使用地平面作为返回路径; 3. 信号的返回参考面发生变化时,在尽可能接近…...
《BackTrader量化交易图解》第8章:plot 绘制金融图
文章目录 8. plot 绘制金融图8.1 金融分析曲线8.2 多曲线金融指标8.3 Observers 观测子模块8.4 plot 绘图函数的常用参数8.5 买卖点符号和色彩风格8.6 vol 成交参数8.7 多图拼接模式8.8 绘制 HA 平均 K 线图 8. plot 绘制金融图 8.1 金融分析曲线 BackTrader内置的plot绘图函…...

什么是欧拉筛??
欧拉筛(Eulers Sieve),又称线性筛法或欧拉线性筛,是一种高效筛选素数的方法。它的核心思想是从小到大遍历每个数,同时标记其倍数为合数,但每个合数只被其最小的质因数标记一次,从而避免了重复标…...
2023年全国职业院校技能大赛软件测试赛题—单元测试卷⑩
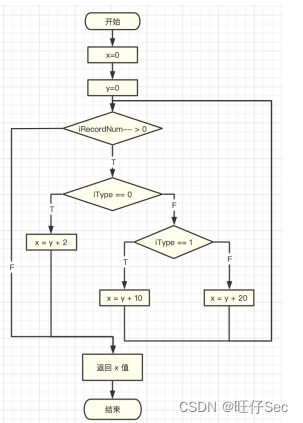
单元测试 一、任务要求 题目1:根据下列流程图编写程序实现相应处理,程序根据两个输入参数iRecordNum和IType计算x的值并返回。编写程序代码,使用JUnit框架编写测试类对编写的程序代码进行测试,测试类中设计最少的测试数据满足基路…...

使用WAF防御网络上的隐蔽威胁之SSRF攻击
服务器端请求伪造(SSRF)攻击是一种常见的网络安全威胁,它允许攻击者诱使服务器执行恶意请求。与跨站请求伪造(CSRF)相比,SSRF攻击针对的是服务器而不是用户。了解SSRF攻击的工作原理、如何防御它࿰…...
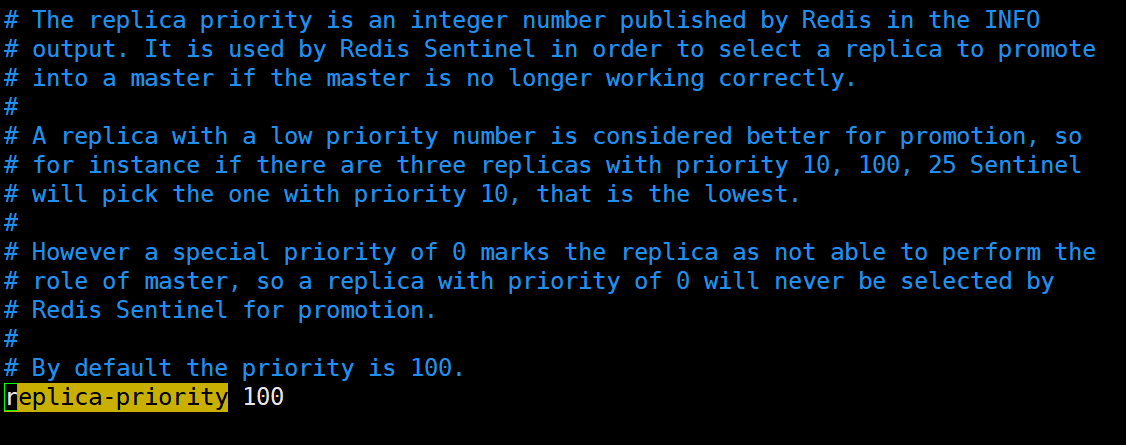
Redis基础系列-哨兵模式
Redis基础系列-哨兵模式 文章目录 Redis基础系列-哨兵模式1. 引言2. 什么是哨兵模式?3. 哨兵模式的配置4. 哨兵模式的启动和验证4.1 主master宕机,看会出现什么问题4.2 重启6379主机 5. 哨兵模式的工作原理和选举原理5.1. SDown主观下线(Subj…...
 Angular中的数据请求 与 路由)
【angular教程240112】09(完) Angular中的数据请求 与 路由
【angular教程240112】09(完) Angular中的数据请求 与 路由 目录标题 一、 Angular 请求数据简介0 使用Angular内置模块HttpClientModule和HttpClientJsonpModule:1 Angular中的GET请求:2 Angular中的POST请求:3 Angular中的JSONP请求:4使用Axios进行数据请求: 二、 详解 Angul…...

go中拷贝文件操作
一. 拷贝文件内容到另一个文件位置 // 拷贝文件内容到另一个文件里面 func copyContent() {filepath1 : "d:/abc.txt"filepath2 : "e:/eee.txt"// 读取内容data, err : os.ReadFile(filepath1) // 使用os.ReadFile函数读取指定路径的文件内容if err ! nil…...

未来气膜体育馆的发展趋势是什么?
未来气膜体育馆的发展趋势是多方面的,以下是其中几个方面的趋势。 起初,随着人们对体育运动的需求不断增加,气膜体育馆的建设和使用将成为一种趋势。气膜体育馆具有灵活性和可移动性的特点,可以快速搭建和拆除,能够适…...
)
通信扫盲(五)
系列文章目录 1 通信扫盲(一): 通信的本质、通信发展史-各代移动通信的多祉技术、5G、6G应用场景/愿景、LTE是什么?3GPP是什么? 链接:通信扫盲(一) 2 通信扫盲(二&…...

nbcio-boot项目的文件上传与回显处理方法
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 更多nbcio-boot功能请看演示系统 gitee源代码地址 后端代码: https://gitee.com/nbacheng/n…...

《动手学深度学习》学习笔记 第9章 现代循环神经网络
本系列为《动手学深度学习》学习笔记 书籍链接:动手学深度学习 笔记是从第四章开始,前面三章为基础知识,有需要的可以自己去看看 关于本系列笔记: 书里为了让读者更好的理解,有大篇幅的描述性的文字,内容很…...

「HDLBits题解」Vector100r
本专栏的目的是分享可以通过HDLBits仿真的Verilog代码 以提供参考 各位可同时参考我的代码和官方题解代码 或许会有所收益 题目链接:Vector100r - HDLBits module top_module( input [99:0] in,output [99:0] out );integer i ; always (*) beginfor (i 0 ; i <…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...