【大数据Hive】hive 表设计常用优化策略
目录
一、前言
二、hive 普通表查询原理
2.1 操作演示说明
2.1.1 创建一张表,并加载数据
2.1.2 统计3月24号的登录人数
2.1.3 查询原理过程总结
2.2 普通表结构带来的问题
三、hive分区表设计
3.1 区表结构 - 分区设计思想
3.2 操作演示
3.2.1 创建分区表 按照登录日期分区
3.2.2 开启动态分区
按登录日期分区
基于分区表查询数据
查询先检索元数据
查询执行计划
四、hive分桶表设计
4.1 Hive中Join的问题
4.2 分桶表设计思想
4.3 创建分桶表操作
创建第一张普通表
构建分桶emp表
创建第二张普通表dept并加载数据
构建分桶dept表并加载数据
4.4 普通表与分桶表join执行分析
普通表的join执行计划分析
分桶的Join执行计划分析
五、hive索引设计
5.1 hive索引说明
5.2 Hive中索引基本原理
5.2.1 Hive索引目的
5.3 索引的使用
5.4 Hive索引的问题
六、写在文末
一、前言
不管是关系性数据库,比如像mysql,还是类关系型数据库,像mongodb,为了确保在建表开始使用之后,能够充分发挥数据表的高性能查询,需要在表的设计阶段,从表的设计,索引的设计,分区的设计等等一系列因素综合去平衡和考虑,以免为上线后的优化工作带来麻烦。本篇将介绍hive关于表设计常用的一些优化策略。
二、hive 普通表查询原理
通过之前的学习,想必大家对hive的查询原理不再陌生,下图是hive查询的原理图;

为什么要说查询原理呢,理解一个软件的设计有必要对其原理做一定的了解,就像之前学习mysql一样,只有了解了innodb引擎的工作原理,才能更好的指导我们sql的做性能优化,关于hive的查询原理,再做如下补充:
- Hive的设计思想是通过元数据解析描述将HDFS上的文件映射成表;
- 基本的查询原理是当用户通过HQL语句对Hive中的表进行复杂数据处理和计算时,默认将其转换为分布式计算MapReduce程序对HDFS中的数据进行读取处理的过程;
hive自身不存储数据,其数据依赖的载体为hdfs,比如当我们创建一个数据库,一张表之后,在hdfs文件目录上就出现了一个目录;

在表下面加载数据之后,表的文件目录下,可以继续看到一个数据文件;

2.1 操作演示说明
2.1.1 创建一张表,并加载数据
create table tb_login(userid string,logindate string
) row format delimited fields terminated by '\t';load data local inpath '/usr/local/soft/hivedata/login.log' into table tb_login;select * from tb_login;检查数据是否加载成功

检查hdfs数据目录,可以看到表数据已经加载到目录下

2.1.2 统计3月24号的登录人数
selectlogindate,count(*) as cnt
from tb_login
where logindate = '2021-03-24'
group by logindate;通过sql的执行过程,可以看到底层是走了MR的过程;

如果使用explain来分析一下执行的过程
explain extended
selectlogindate,count(*) as cnt
from tb_login
where logindate = '2021-03-24'
group by logindate;重点关注下面的那一段关于数据扫描的信息,这段信息要表达的意思是,执行上面的sql时,需要对表的数据目录下的文件数据进行全表扫描,当目录下的数据量非常大的时候,全表扫描将是非常耗时和耗费性能的;

2.1.3 查询原理过程总结
通过上面的过程分析,关于hive普通表的查询过程原理做简单的小结
1)当执行查询计划时,Hive会使用表的最后一级目录作为底层处理数据的输入
Step1:先根据表名在元数据中进行查询表对应的HDFS目录

Step2: 然后在hive的数据库下找到下面这张表,定位到表的数据目录在hdfs上面的具体路径;

2) 然后将整个HDFS中表的目录作为底层查询的输入,可以通过explain命令查看执行计划依赖的数据

2.2 普通表结构带来的问题
通过上面的操作演示,有心的小伙伴们可能发现了一些问题,更进一步,我们来看下面的这个场景:
1、假设每天有1G的数据增量,一年就是365GB的数据,按照业务需求,每次只需要对其中一天的数据进行处理,也就是处理1GB的数据;
2、程序会先加载365GB的数据,然后将364GB的数据过滤掉,只保留一天的数据再进行计算,导致了大量的磁盘和网络的IO的损耗;

三、hive分区表设计
在之前的讲解中,我们使用过hive的分区表,接下来再从原理层面再次聊聊hive分区表的设计与思想。
3.1 区表结构 - 分区设计思想
Hive提供了一种特殊的表结构来解决——分区表结构,分区表结构的设计思想是:
- 据查询的需求,将数据按照查询的条件【一般以时间】进行划分分区存储;
- 将不同分区的数据单独使用一个HDFS目录来进行存储;
- 当底层实现计算时,根据查询的条件,只读取对应分区的数据作为输入,减少不必要的数据加载,提高程序的性能;

3.2 操作演示
在上面的案例中,按照登陆日期进行分区存储到Hive表中,每一天一个分区,在HDFS的底层就可以自动实现将每天的数据存储在不同的目录中;
接下来看具体的操作过程
3.2.1 创建分区表 按照登录日期分区
create table tb_login_part(userid string
)partitioned by (logindate string)row format delimited fields terminated by '\t';执行过程
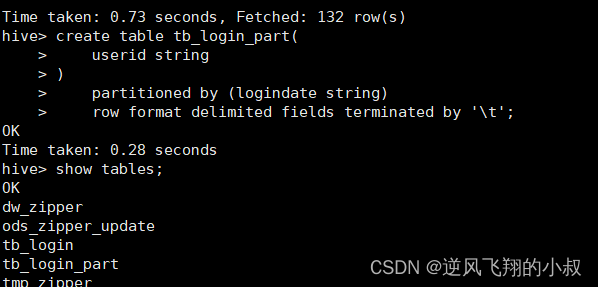
3.2.2 开启动态分区
set hive.exec.dynamic.partition.mode=nonstrict;
按登录日期分区
insert into table tb_login_part partition(logindate)
select * from tb_login;执行过程

执行完成后再次检查hdfs表的数据目录,可以看到就按照日期创建了3个分区目录;

基于分区表查询数据
selectlogindate,count(*) as cnt
from tb_login_part
where logindate = '2021-03-23' or logindate = '2021-03-24'
group by logindate;可以发现在分区表的情况下查询速度明显提升了;

从之前对hive分区表的学习我们也了解到,使用分区表的目的就是为了减少数据文件的扫描,从而达到提升查询性能的目的,下面来看看具体的原理,
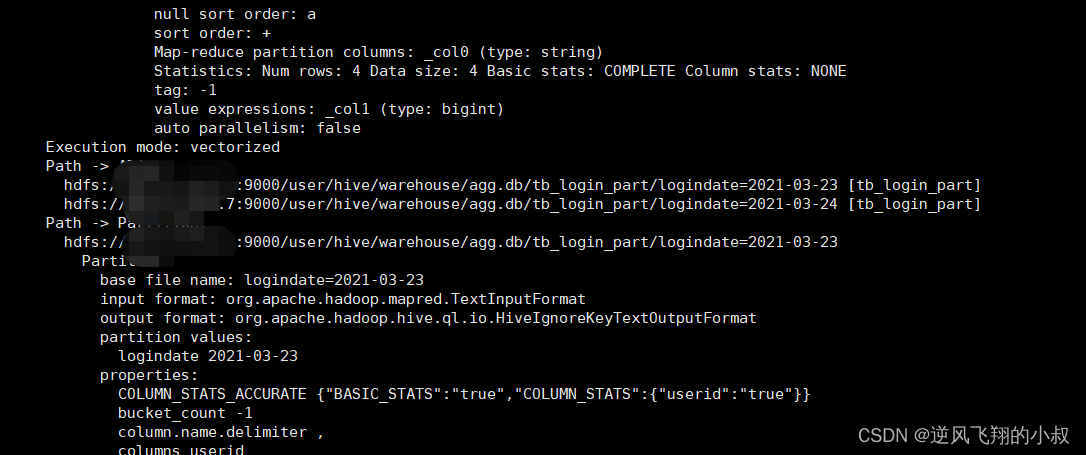
查询先检索元数据
元数据中记录该表为分区表,即PARTITIONS这张表中,并且查询过滤条件为分区字段,所以找到该分区对应的HDFS目录;

然后再去SDS表中可以看到分区表在hdfs存储的具体目录地址;

查询执行计划
如果此时再看执行计划,会有什么结果呢?
explain extended
selectlogindate,count(*) as cnt
from tb_login_part
where logindate = '2021-03-23' or logindate = '2021-03-24'
group by logindate;此时不难看出,基于分区表的情况下,不再是做全表扫描了,而是针对各自的分区做数据的扫描;
四、hive分桶表设计
4.1 Hive中Join的问题
默认情况下,Hive底层是通过MapReduce来实现的,MapReduce在处理数据之间join的时候有两种方式:MapJoin、ReduceJoin,其中MapJoin效率较高,如果有两张非常大的表要进行Join,底层无法使用MapJoin提高Join的性能,只能走默认的ReduceJoin,而ReduceJoin必须经过Shuffle过程,相对性能比较差,而且容易产生数据倾斜;

基于上面的问题,可以考虑使用hive的分桶表来设计和优化;
4.2 分桶表设计思想
分区表是将数据划分不同的目录进行存储,而分桶表是将数据划分不同的文件进行存储
分桶表的设计是按照一定的规则【底层通过MapReduce中的多个Reduce来实现】将数据划分到不同的文件中进行存储,构建分桶表。

有了分桶表之后,如果再次对两张比较大的数据表进行join的时候,由于两张表按照相同的划分规则【比如按照Join的关联字段】将各自的数据进行划分(即基于分桶表的设计规则之下),在Join时,就可以实现Bucket与Bucket的Join,避免不必要的比较,减少笛卡尔积数量;

4.3 创建分桶表操作
创建第一张普通表
--创建普通表
create table tb_emp01(empno string,ename string,job string,managerid string,hiredate string,salary double,jiangjin double,deptno string
) row format delimited fields terminated by '\t';--加载数据
load data local inpath '/usr/local/soft/data/emp01.txt' into table tb_emp01;select * from tb_emp01;执行完成后检查数据是否加载成功;

构建分桶emp表
create table tb_emp02(empno string,ename string,job string,managerid string,hiredate string,salary double,jiangjin double,deptno string
)clustered by(deptno) sorted by (deptno asc) into 3 bucketsrow format delimited fields terminated by '\t';执行建表sql

将数据写入分桶表
insert overwrite table tb_emp02
select * from tb_emp01;由于表的数据量较大,执行耗时较长,执行完成后,可以检查数据是否加载成功

从hdfs文件目录上也可以看出来,数据被分散存储到各个虚拟的“桶”中;
创建第二张普通表dept并加载数据
-- 构建普通dept表
create table tb_dept01(deptno string,dname string,loc string
)row format delimited fields terminated by ',';-- 加载数据
load data local inpath '/usr/local/soft/data/dept01.txt' into table tb_dept01;select * from tb_dept01;执行过程

构建分桶dept表并加载数据
-- 构建分桶dept表
create table tb_dept02(deptno string,dname string,loc string
)clustered by(deptno) sorted by (deptno asc) into 3 bucketsrow format delimited fields terminated by ',';-- 数据写入分桶表
insert overwrite table tb_dept02
select * from tb_dept01;执行过程

从hdfs目录上面可以看到tb_emp02表的数据已经分好了桶;

4.4 普通表与分桶表join执行分析
上面创建了2张普通表以及两张分桶表,基于以上的数据,我们使用explain分别执行一下看看执行计划如何;
普通表的join执行计划分析
explain
selecta.empno,a.ename,a.salary,b.deptno,b.dname
from tb_emp01 a join tb_dept01 b on a.deptno = b.deptno;执行上面的explain计划分析,从显示结果来看,就是单纯的两张表的inner join操作,也就是两张表进行笛卡尔的乘积;

分桶的Join执行计划分析
--开启分桶SMB(Sort-Merge-Buket) join
set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;--查看执行计划
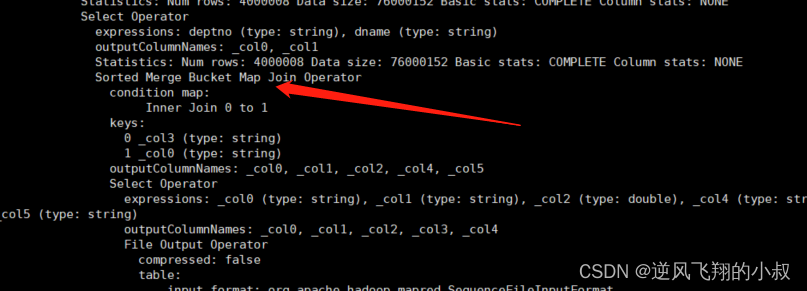
explain
selecta.empno,a.ename,a.salary,b.deptno,b.dname
from tb_emp02 a join tb_dept02 b on a.deptno = b.deptno;执行上面的sql之后,再次来看看分析的结果如下,此时可以看到,这时尽管也存在表的join,却是bucket桶与桶之间的数据的join,由于bucket中的数据量比原始数据要小很多,笛卡尔的乘积结果也会小很多,这样就提升了整体的关联查询的效率;
五、hive索引设计
使用过mysql的同学对索引应该不陌生,索引可以说是用于优化mysql表查询性能的利器,在hive中也提供了索引的功能,用于提升数据查询时的性能。
5.1 hive索引说明
Hive中提供了索引的设计,允许用户为字段构建索引,提高数据的查询效率。但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键索引。
Hive索引可以建立在表中的某些列上,以提升一些操作的效率。
5.2 Hive中索引基本原理
当为某张表的某个字段创建索引时,Hive中会自动创建一张索引表,该表记录了该字段的每个值与数据实际物理位置之间的关系,例如数据所在的HDFS文件地址,以及所在文件中偏移量offset等信息。
5.2.1 Hive索引目的
提高Hive表指定列的查询速度。没有索引时,类似WHERE tab1.col1 = 10的查询,Hive会加载整张表或分区,然后处理所有的行,但是如果在字段col1上面存在索引时,那么只会加载和处理文件的一部分。
5.3 索引的使用
创建索引语句
-- 为表中的userid构建索引
create index idx_user_id_login on table tb_login_part(userid)
-- 索引类型为Compact,Hive支持Compact和Bitmap类型,存储的索引内容不同
as 'COMPACT'
-- 延迟构建索引
with deferred rebuild;
索引创建完成后,还需要运行一个MR任务来构建索引,相当于是为索引在hdfs目录中创建一个数据目录;
alter index idx_user_id_login ON tb_login_part rebuild;
查看索引结构
desc default__tb_login_part_idx_user_id_login__;
查看索引内容
select * from default__tb_login_part_idx_user_id_login__;
删除索引
DROP INDEX idx_user_id_login ON tb_login_part;
5.4 Hive索引的问题
由于hive索引自身的机制在实际使用中并不推荐,在3.0之后的某个版本直接被移除了,其主要问题如下:
- Hive构建索引的过程是通过一个MapReduce程序来实现的;
- 每次Hive中原始数据表的数据发生更新时,索引表不会自动更新;
- 必须手动执行一个Alter index命令来实现通过MapReduce更新索引表,导致整体性能较差,维护相对繁琐;
六、写在文末
在大数据场景下,表的优化是一个永恒的话题,在实际生产过程中,在表的优化思路上通常是通过多种策略组合的方式寻求最优解,前提是需要对常用的优化策略有深入的了解才能合理的使用。
相关文章:
【大数据Hive】hive 表设计常用优化策略
目录 一、前言 二、hive 普通表查询原理 2.1 操作演示说明 2.1.1 创建一张表,并加载数据 2.1.2 统计3月24号的登录人数 2.1.3 查询原理过程总结 2.2 普通表结构带来的问题 三、hive分区表设计 3.1 区表结构 - 分区设计思想 3.2 操作演示 3.2.1 创建分区表…...

jvm垃圾收集器之七种武器
目录 1.回收算法 1.1 标记-清除算法(Mark-Sweep) 1.2 复制算法(Copying) 1.3 标记-整理算法(Mark-Compact) 2.HotSpot虚拟机的垃圾收集器 2.1 新生代的收集器 Serial 收集器(复制算法) ParNew 收集器 (复制算法) Parallel Scavenge 收集器 (复制…...

STM32面试相关问题
STM32面试相关问题: STM32的内核型号,主频,传感器和单片机总线类型,IIC,SPI,RS485UART数据帧项目中一些参数的设置 STM32 系统移植 ARM编译 常用的驱动编写方式 自己写过哪些方面驱动 其实如果问32的问题,…...

风行智能电视N39S、N40 强制刷机升级方法,附刷机升级数据MstarUpgrade.bin
升级步骤: 1、下载刷机数据,如是压缩包,需要先解压,然后将刷机bin格式的文件重命名为MstarUpgrade.bin 2、将此文件放到U盘根目录 (U盘格式FAT32,单分区,建议4G的优盘刷机成功率高)…...

【C语言】简易英语词典
文章目录 一、定义英语单词信息的结构体二、主函数功能逻辑三、查单词函数四、背单词函数五、补充 一、定义英语单词信息的结构体 添加必要的头文件、宏定义和声明,之后定义英语单词信息结构体。 /* 头文件和宏定义 */ #include <stdio.h> #include <std…...

【算法题】104. 二叉树的最大深度
题目 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:3 示例 2: 输入:root [1,nul…...
Docker配置Portainer容器管理界面
目录 一、Portainer 简介 优点: 缺点: 二、环境配置 1. 拉取镜像 2. 创建启动容器 三、操作测试 1. 进入容器 2. 拉取镜像并部署 3. 访问测试 一、Portainer 简介 Portainer 是一个开源的轻量级容器管理界面,用于管理 Docker 容器…...
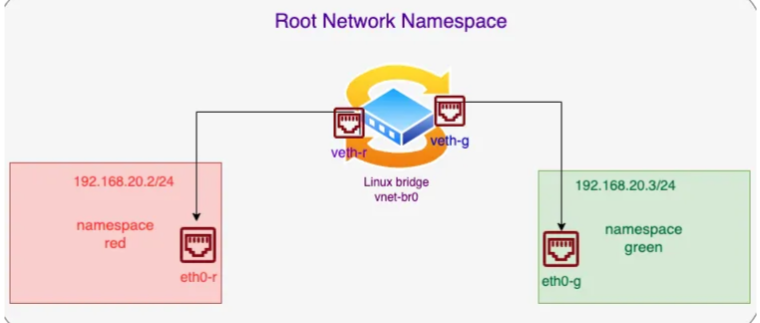
Linux network namespace 访问外网以及多命名空间通信(经典容器组网 veth pair + bridge 模式认知)
写在前面 整理K8s网络相关笔记博文内容涉及 Linux network namespace 访问外网方案 Demo实际上也就是 经典容器组网 veth pair bridge 模式理解不足小伙伴帮忙指正 不必太纠结于当下,也不必太忧虑未来,当你经历过一些事情的时候,眼前的风景已…...

网络渗透测试:Wireshark抓取qq图片
Wireshark Wireshark Downloadhttps://www.wireshark.org/download.html 简介 WireShark是非常流行的网络封包分析工具,可以截取各种网络数据包,并显示数据包详细信息。常用于开发测试过程中各种问题定位。本文主要内容包括: 1、Wireshar…...
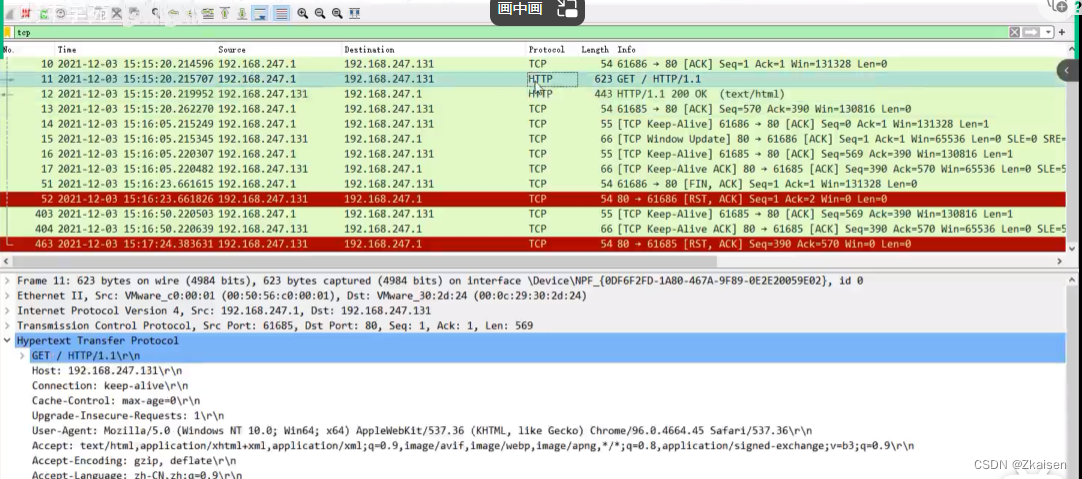
网络协议与攻击模拟_16HTTP协议
1、HTTP协议结构 2、在Windows server去搭建web扫描器 3、分析HTTP协议流量 一、HTTP协议 1、概念 HTTP(超文本传输协议)用于在万维网服务器上传输超文本(HTML)到本地浏览器的传输协议 基于TCP/IP(HTML文件、图片、查询结构等&…...

叙事弧基础
原文:MasterClass. 2020. Learn About Narrative Arcs: Definition, Examples, and How to Create a Narrative Arc in Your Writing - 2021. https://www.masterclass.com/articles/what-are-the-elements-of-a-narrative-arc-and-how-do-you-create-one-in-writin…...
:python的exe程序打包制作)
python从入门到精通(二十):python的exe程序打包制作
python的exe程序打包制作 python打包的概念python打包的模块导入模块安装验证基本语法命令参数文件夹模式单文件模式资源嵌入exe更改图标启动画面(闪屏)禁用异常提示 python打包的概念 将普通的*.py程序文件打包成exe文件。exe文件即可执行文件…...
three.js 细一万倍教程 从入门到精通(一)
目录 一、three.js开发环境搭建 1.1、使用parcel搭建开发环境 1.2、使用three.js渲染第一个场景和物体 1.3、轨道控制器查看物体 二、three.js辅助设置 2.1、添加坐标轴辅助器 2.2、设置物体移动 2.3、物体的缩放与旋转 缩放 旋转 2.4、应用requestAnimationFrame …...
电路设计(16)——纪念馆游客进出自动计数显示器proteus仿真
1.设计要求 设计、制作一个纪念馆游客进出自动计数显示器。 某县,有一个免费参观的“陶渊明故里纪念馆”,游客进出分道而行,如同地铁有确保单向通行的措施。在入口与出口处分别设有红外检测、声响、累加计数器装置,当游人进&#…...
Python数学建模之回归分析
1.基本概念及应用场景 回归分析是一种预测性的建模技术,数学建模中常用回归分析技术寻找存在相关关系的变量间的数学表达式,并进行统计推断。例如,司机的鲁莽驾驶与交通事故的数量之间的关系就可以用回归分析研究。回归分析根据变量的…...
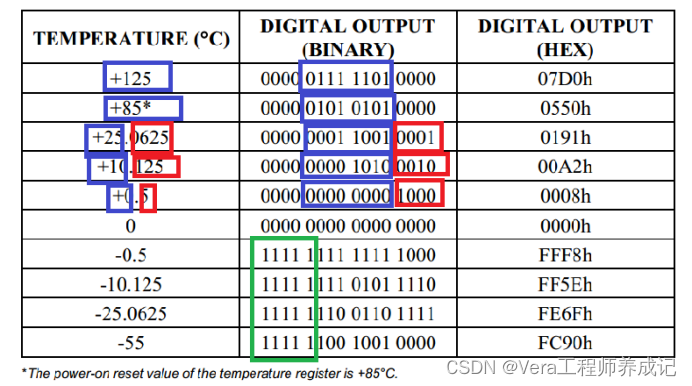
单片机学习笔记---DS18B20温度传感器
目录 DS18B20介绍 模拟温度传感器的基本结构 数字温度传感器的应用 引脚及应用电路 DS18B20的原理图 DS18B20内部结构框图 暂存器内部 单总线介绍 单总线电路规范 单总线时序结构 初始化 发送一位 发送一个字节 接收一位 接收一个字节 DS18B20操作流程 指令介…...
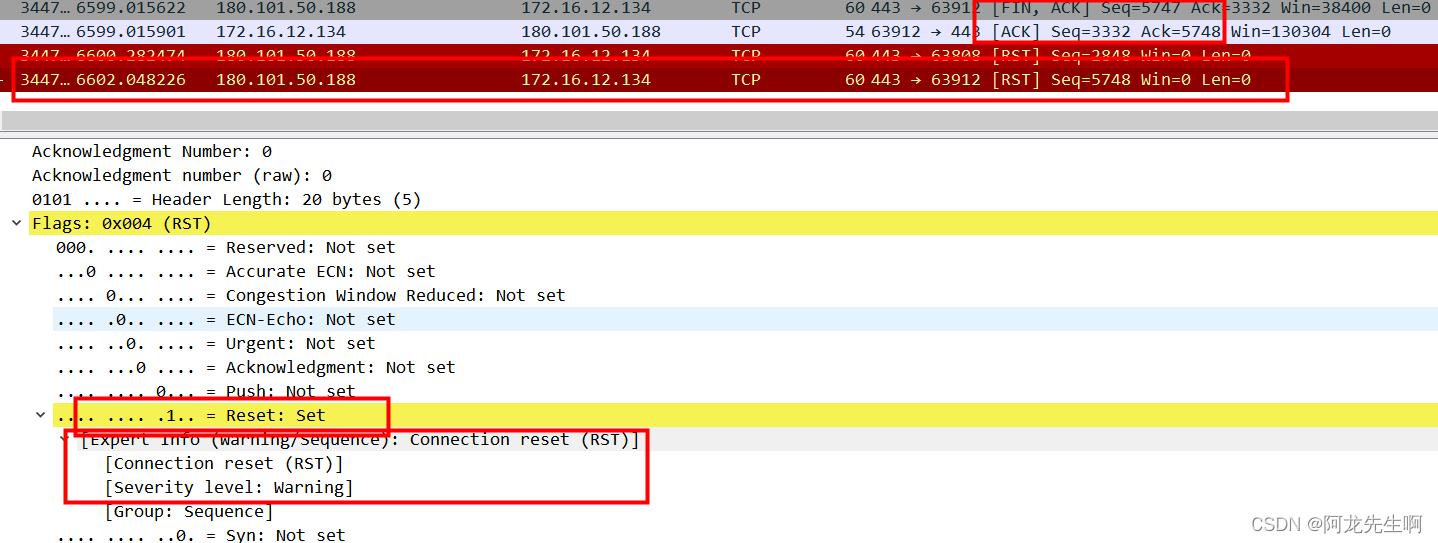
【网络】WireShark过滤 | WireShark实现TCP三次握手和四次挥手
目录 一、开启WireShark的大门 1.1 WireShark简介 1.2 常用的Wireshark过滤方式 二、如何抓包搜索关键字 2.1 协议过滤 2.2 IP过滤 编辑 2.3 过滤端口 2.4 过滤MAC地址 2.5 过滤包长度 2.6 HTTP模式过滤 三、ARP协议分析 四、WireShark之ICMP协议 五、TCP三次握…...
开源免费的Linux服务器管理面板分享
开源免费的Linux服务器管理面板分享 一、1Panel1.1 1Panel 简介1.2 1Panel特点1.3 1Panel面板首页1.4 1Panel使用体验 二、webmin2.1 webmin简介2.2 webmin特点2.3 webmin首页2.4 webmin使用体验 三、Cockpit3.1 Cockpit简介3.2 Cockpit特点3.3 Cockpit首页3.4 Cockpit使用体验…...

leetcode算法-位运算
位运算,直接在二进制上进行的按位操作,位运算的种类如下: 1.按位异或^:异或的含义是操作的两位不同,则结果为1,相同则结果为0,所以两个相同的数异或,结果应该是0,3^3的结果是0,3^4的…...

「MySQL」约束
概述 分类 约束描述关键字非空约束限制该字段的数据不能为 nullNOT NULL唯一约束保证该字段的所有数据都是唯一、不重复的UNIQUE主键约束主键是一行数据的唯一标识,要求非空且唯一PRIMARY KEY默认约束保存数据时,如果未指定该字段的值,则采…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...