数据统计:词频统计、词表生成、排序及计数、词云图生成
文章目录
- 📚输入及输出
- 📚代码实现
📚输入及输出
-
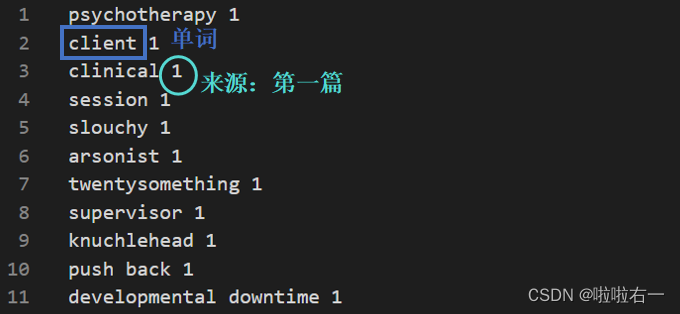
输入:读取一个
input.txt,其中包含单词及其对应的TED打卡号。
-
输出
-
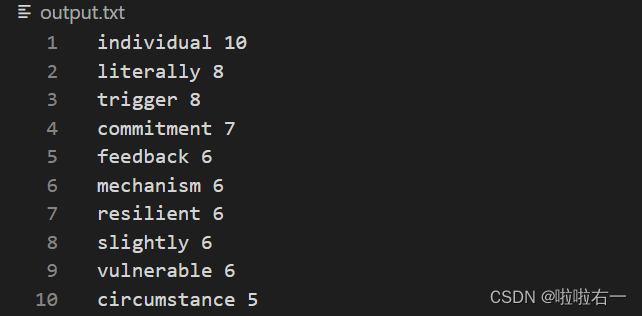
output.txt:包含按频率降序排列的每个单词及其计数(这里直接用于后续的词云图生成)。
-
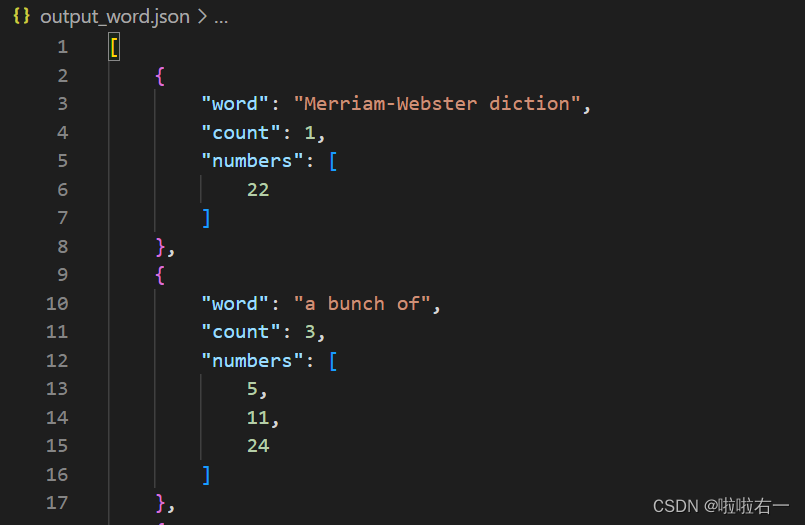
output_word.json:包含每个单词及其计数,以及与之关联的TED打卡号列表,生成一个json文件(按字母序排列,用于后续网页数据导入)。
-
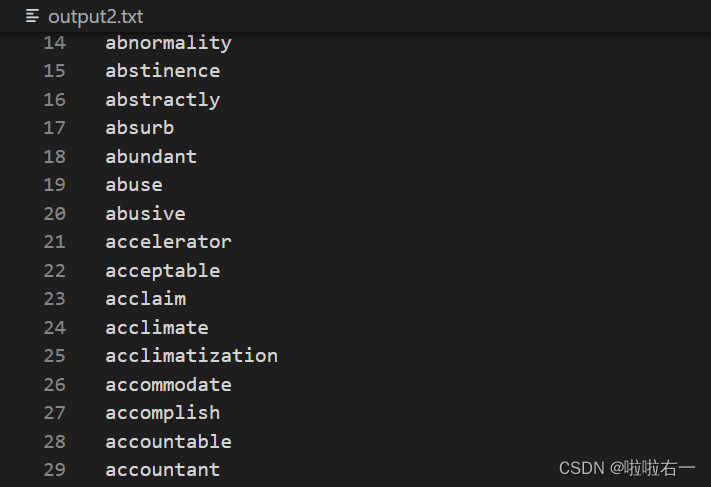
output2.txt:按字母顺序排序的所有单词,即导出一个单词词表(可以导入到不背单词里生成自定义词表)。
-
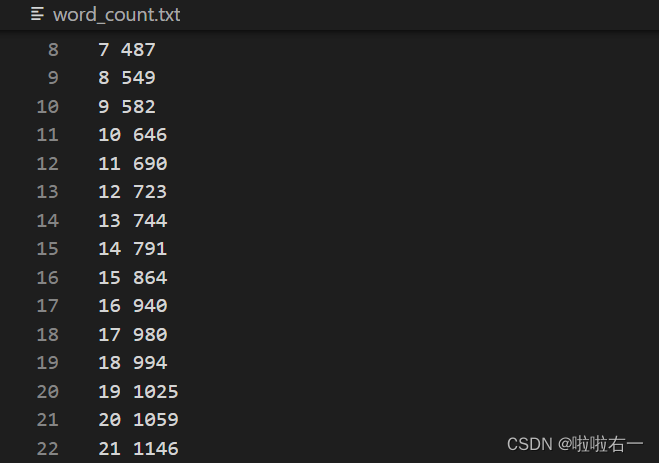
word_count.txt:记录截至每篇TED打卡号时涉及到的单词总数(该数据用于绘制后续的折线图)。
-
-
生成词云:在处理数据后,脚本读取
output.txt并生成基于单词频率的词云,并将词云保存至指定目录。
📚代码实现
-
逻辑梳理
- 在函数中使用了两个defaultdict,一个用于统计单词出现的频率,另一个用于记录单词对应的打卡号集合。
- 打开输入文件,并逐行读取单词及其对应的打卡号,对于每个单词,统计其出现的频率,并将打卡号添加到对应的集合中。同时,对每篇TED的打卡号进行统计,记录每篇 TED 结束时涉及到的当前单词总数量,写入
output_word_count_txt,对应word_count.txt。 - 统计完所有单词后,对单词频率进行排序,并将排序后的结果写入
output_txt_file,对应input.txt。 - 将单词、频率和相应的(排序过后的)打卡号列表存储为 JSON 文件,对应
output_word.json。 - 将所有单词按字母顺序写入
output_txt_file_sorted中,对应output2.txt。
-
具体详见注释↓
import json from collections import defaultdict from wordcloud import WordCloud import matplotlib.pyplot as plt import redef count_word_frequency(input_file, output_txt_file, output_word_json_file, output_txt_file_sorted, output_word_count_txt):# 使用defaultdict初始化两个字典,用于统计单词出现频率、单词对应打卡号集合word_count = defaultdict(int)# 设置为set集合自动去重,单词对应的打卡号集合word_numbers = defaultdict(set) current_number = 0 # 当前打卡号初始化为0# 创建一个空的单词计数分析文本文件open(output_word_count_txt, 'w').close()# 打开输入文件并逐行读取单词及其对应的数字with open(input_file, 'r') as file:for line in file:line_parts = line.strip().split()word = " ".join(line_parts[:-1]) # 提取单词number = int(line_parts[-1]) # 提取打卡号# 如果当前打卡号与前一个不同(即已经开始下一篇了),记录前一个打卡号(即刚刚完成的那一篇)对应的(截至该篇的)单词总数到output_word_count_txt中if number != current_number:current_number = number# 用sum函数来统计word_numbers中非空集合的数量,即当前TED打卡号下已经出现过的单词数current_unique_count = sum(1 for word_set in word_numbers.values() if len(word_set) > 0)with open(output_word_count_txt, 'a') as count_file:count_file.write(f"{current_number-1} {current_unique_count}\n")# 统计单词的频率及相应的打卡号(这里排除了同一个单词在一片篇TED里多次记录的重复计数情况)if number not in word_numbers[word]: word_count[word] += 1word_numbers[word].add(number) # 对每个单词的打卡号进行排序,使得最后TED打卡号列表按序显示for word in word_numbers:word_numbers[word] = sorted(word_numbers[word])# 补充记录最后一个打卡号对应的(截至该篇的)单词总数到output_word_count_txt中current_unique_count = sum(1 for word_set in word_numbers.values() if len(word_set) > 0)with open(output_word_count_txt, 'a') as count_file:count_file.write(f"{current_number} {current_unique_count}\n")# 对单词频率进行排序,并将排序后的结果写入输出文本文件中sorted_words = sorted(word_count.items(), key=lambda x: (-x[1], x[0]))with open(output_txt_file, 'w') as file_txt:for word, count in sorted_words:file_txt.write(word + " " + str(count) + "\n")# 将单词、频率和相应的打卡号列表存储为JSON文件word_data = []for word, count in word_count.items():word_entry = {"word": word,"count": count,"numbers": list(word_numbers[word]) }word_data.append(word_entry)word_data_sorted = sorted(word_data, key=lambda x: x["word"])with open(output_word_json_file, 'w') as file_word_json:json.dump(word_data_sorted, file_word_json, indent=4)# 将所有单词按字母顺序写入输出文本文件中all_words = list(word_count.keys())all_words.sort()with open(output_txt_file_sorted, 'w') as file_txt_sorted:file_txt_sorted.write('\n'.join(all_words) + '\n')# 定义输入文件和输出文件的名称 input_file = "input.txt" output_txt_file = "output.txt" output_word_json_file = "output_word.json" output_txt_file_sorted = "output2.txt" output_word_count_txt = "word_count.txt"# 调用函数统计单词频率并生成相关输出 count_word_frequency(input_file, output_txt_file, output_word_json_file, output_txt_file_sorted, output_word_count_txt)# 读取输出文本文件的单词频率数据 words = [] with open('output.txt', 'r', encoding='utf-8') as file:for line in file:# 使用正则表达式匹配每行的单词和对应的频率match = re.match(r'(.+?)\s+(\d+)', line)if match: # 如果匹配成功word = match.group(1) # 提取匹配到的单词部分freq = int(match.group(2)) # 提取匹配到的数字部分作为频率words.append((word, freq)) # 将单词和对应的频率以元组的形式添加到列表中# 生成词云图像并保存为文件 wordcloud = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(dict(words)) plt.figure(figsize=(10, 6)) plt.imshow(wordcloud, interpolation='bilinear') plt.axis('off') wordcloud.to_file('./images/wordcloud.png') plt.show()
相关文章:
数据统计:词频统计、词表生成、排序及计数、词云图生成
文章目录 📚输入及输出📚代码实现 📚输入及输出 输入:读取一个input.txt,其中包含单词及其对应的TED打卡号。 输出 output.txt:包含按频率降序排列的每个单词及其计数(这里直接用于后续的词云…...
W801学习笔记二十四:NES模拟器游戏
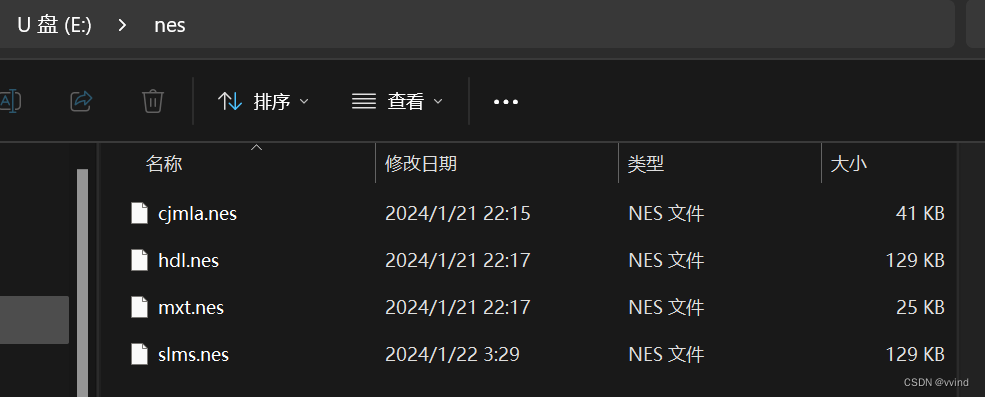
之前已经实现了NES模拟器玩游戏。W801学习笔记九:HLK-W801制作学习机/NES游戏机(模拟器) 现在要在新版本掌机中移植过来。 1、把NES文件都拷贝到SD卡中。 这回不会受内存大小限制了。我这里拷贝了4个,还可以拷贝更多。 2、应用初始化中,加载…...

ECMAScript 6简介
ECMAScript 6简介 发布日期目标ECMAScript 和 JavaScript 的关系ES6 与 ECMAScript 2015 的关系 ESx标准 命名规则 ECMAScript 的历史 1. ECMAScript 6简介 1.1. 发布日期 ECMAScript 6.0(以下简称 ES6)是 JavaScript 语言的下一代标准,已…...

第1个数据库:编号,文本,时间,
写一个数据库 编号 文本 时间1 第一个文本 有100万条数据 -- 创建一个名为texts的表格来存储数据 CREATE TABLE texts ( id INTEGER PRIMARY KEY, text TEXT, time TIMESTAMP DEFAULT CURRENT_TIMESTAMP);-- 插入数据INSERT INTO texts (text) VALUES (第一个文…...

线性数据结构-手写链表-LinkList
为什么需要手写实现数据结构? 其实技术的本身就是基础的积累和搭建的过程,基础扎实 地基平稳 万丈高楼才会久战不衰,做技术能一通百,百通千就不怕有再难得技术了。 一:链表的分类 主要有单向,双向和循环链表…...

快手客户端一二面+美团前端一面+腾讯企业微信开发客户端一面
快手一面结志 1、自我介绍 2、对称加密非对称加密 3、TCP/UDP 4、在学校有什么课程是强项,说了过去几次面试中面到的C的语言基础知识 5、问C、Java中兴趣在哪里 6、问到项目,自己做的还是跟着学校老师做的,同样问到兴趣在哪里 7、LRU …...
探索数据结构
什么是数据结构 数据结构是由:“数据”与“结构”两部分组成 数据与结构 数据:如我们所看见的广告、图片、视频等,常见的数值,教务系统里的(姓名、性别、学号、学历等等); 结构:当…...

VMware虚拟机中ubuntu使用记录(6)—— 如何标定单目相机的内参(张正友标定法)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、张正友相机标定法1. 工具的准备2. 标定的步骤(1) 启动相机(2) 启动标定程序(3) 标定过程的操作(5)可能的报错 3. 标定文件内容解析 前言 张正友相机标定法…...
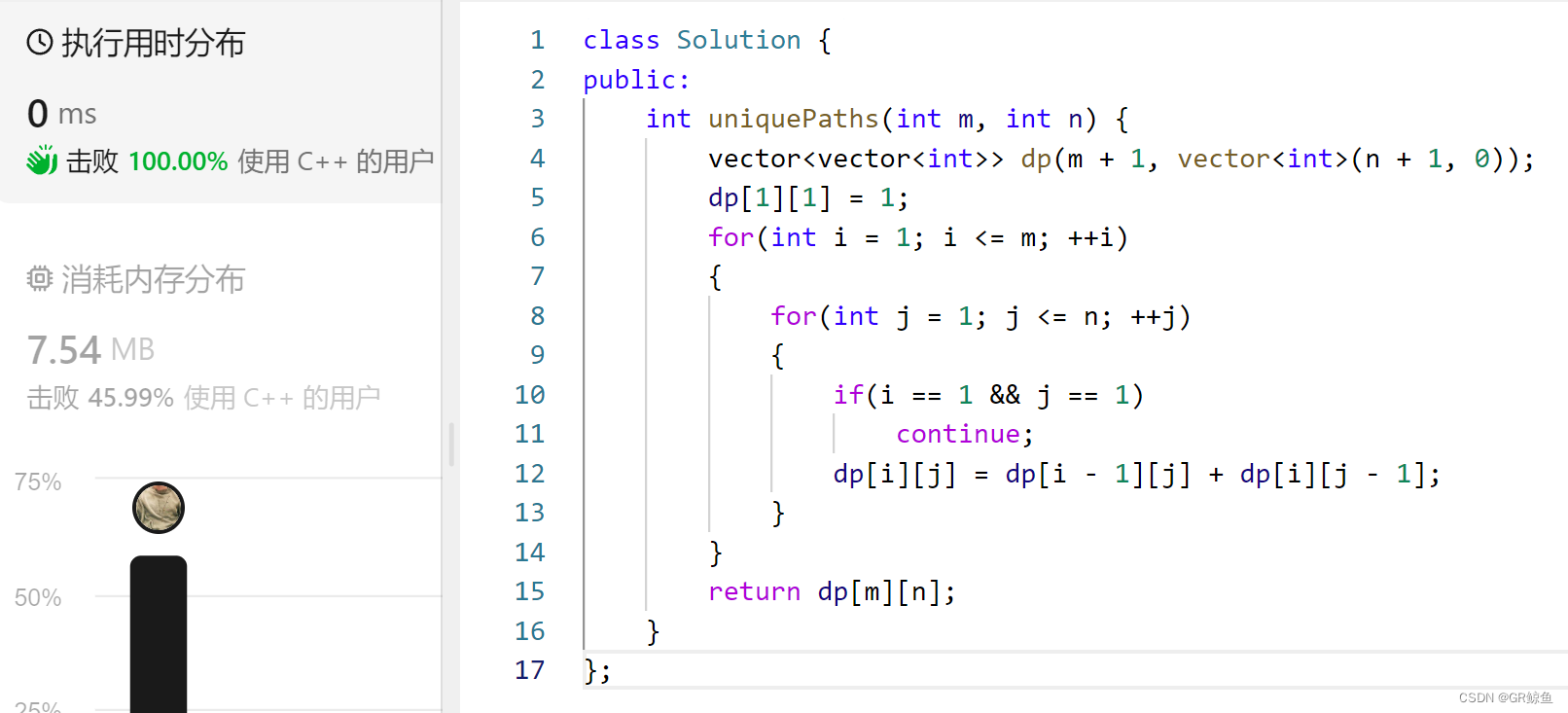
每日OJ题_记忆化搜索②_力扣62. 不同路径(三种解法)
目录 力扣62. 不同路径 解析代码1_暴搜递归(超时) 解析代码2_记忆化搜索 解析代码3_动态规划 力扣62. 不同路径 62. 不同路径 难度 中等 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 机器…...
【微信小程序开发】微信小程序、大前端之flex布局方式详细解析
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...
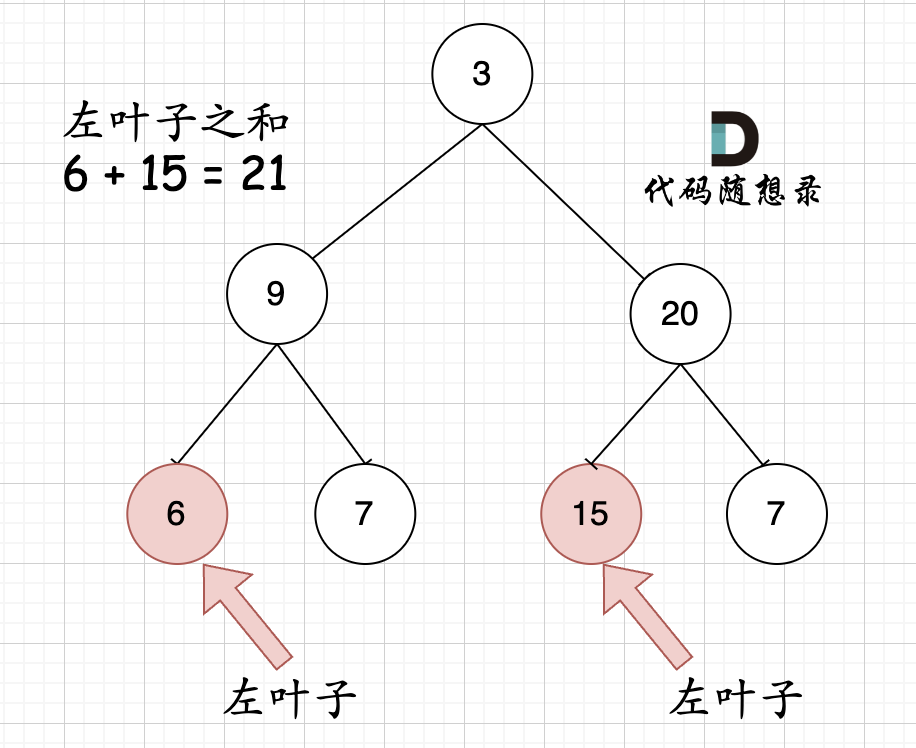
代码随想录算法训练营第二十天:二叉树成长
代码随想录算法训练营第二十天:二叉树成长 110.平衡二叉树 力扣题目链接(opens new window) 给定一个二叉树,判断它是否是高度平衡的二叉树。 本题中,一棵高度平衡二叉树定义为:一个二叉树每个节点 的左右两个子树的高度差的绝…...

Opensbi初始化分析:设备初始化-warmboot
Opensbi初始化分析:设备初始化-warmboot 设备初始化sbi_init函数init_warmboot函数coolboot & warmbootwait_for_coldboot函数domain && scratch(coldboot所特有)console初始化及print相关工作(coldboot所特有)系统调用的相关初始化(coldboot所特有)综上设备…...
)
软考 系统架构设计师系列知识点之软件可靠性基础知识(13)
接前一篇文章:软考 系统架构设计师系列知识点之软件可靠性基础知识(12) 所属章节: 第9章. 软件可靠性基础知识 第3节 软件可靠性管理 为了进一步提高软件可靠性,人们又提出了软件可靠性管理的概念,把软件可…...
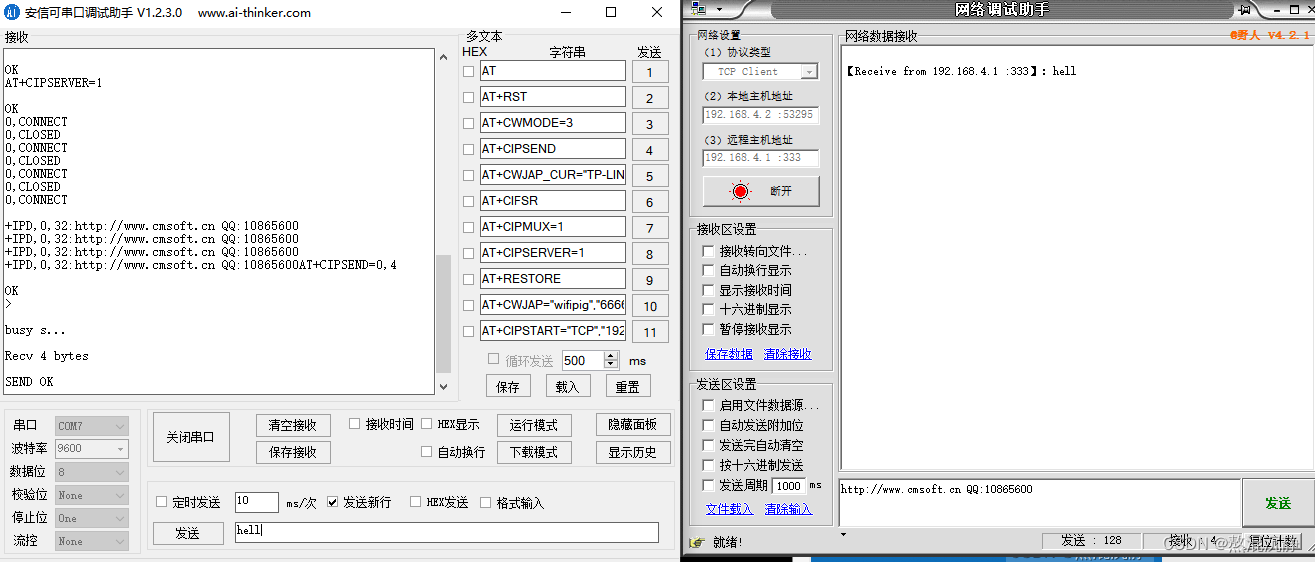
将ESP工作为AP路由模式并当成服务器
将ESP8266模块通过usb转串口接入电脑 ATCWMODE3 //1.配置成双模ATCIPMUX1 //2.使能多链接ATCIPSERVER1 //3.建立TCPServerATCIPSEND0,4 //4.发送4个字节在链接0通道上 >ATCIPCLOSE0 //5.断开连接通过wifi找到安信可的wifi信号并连接 连接后查看自己的ip地址变为192.168.4.…...
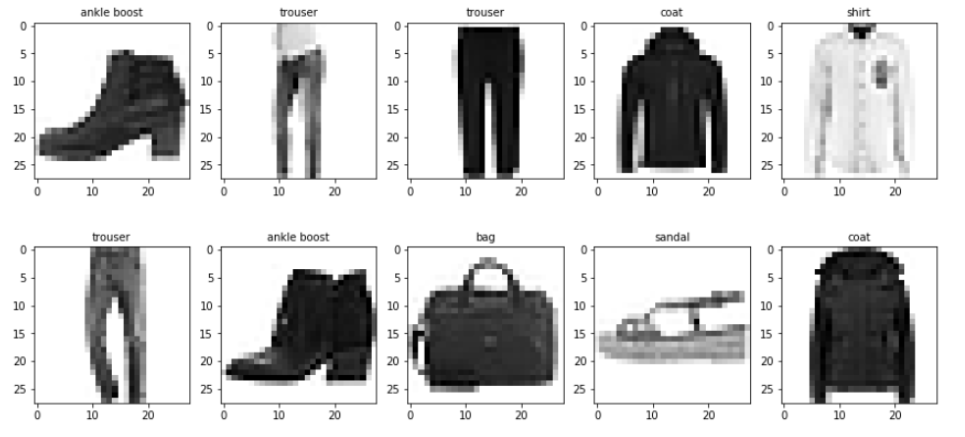
Python深度学习基于Tensorflow(6)神经网络基础
文章目录 使用Tensorflow解决XOR问题激活函数正向传播和反向传播解决过拟合权重正则化Dropout正则化批量正则化 BatchNormal权重初始化残差连接 选择优化算法传统梯度更新算法动量算法NAG算法AdaGrad算法RMSProp算法Adam算法如何选择优化算法 使用tf.keras构建神经网络使用Sequ…...

力扣HOT100 - 35. 搜索插入位置
解题思路: 二分法模板 class Solution {public int searchInsert(int[] nums, int target) {int left 0;int right nums.length - 1;while (left < right) {int mid left ((right - left) >> 1);if (nums[mid] target)return mid;else if (nums[mid…...
MinimogWP WordPress 主题下载——优雅至上,功能无限
无论你是个人博客写手、创意工作者还是企业站点的管理员,MinimogWP 都将成为你在 WordPress 平台上的理想之选。以其优雅、灵活和功能丰富而闻名,MinimogWP 不仅提供了令人惊叹的外观,还为你的网站带来了无限的创作和定制可能性。 无与伦比的…...
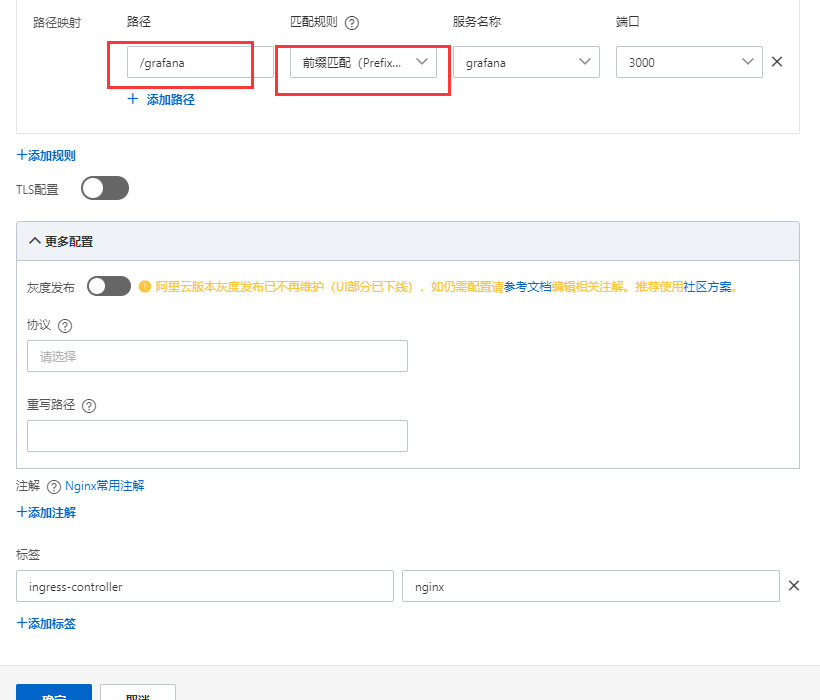
kube-prometheus部署到 k8s 集群
文章目录 **修改镜像地址****访问配置****修改 Prometheus 的 service****修改 Grafana 的 service****修改 Alertmanager 的 service****安装****Prometheus验证****Alertmanager验证****Grafana验证****卸载****Grafana显示时间问题** 或者配置ingress添加ingress访问grafana…...

从0开始学习python(六)
目录 前言 1、循环结构 1.1 遍历循环结构for 1.2 无限循环结构while 总结 前言 上一篇文章我们讲到了python的顺序结构和分支结构。这一章继续往下讲。 1、循环结构 在python中,循环结构分为两类,一类是遍历循环结构for,一类是无限循环结…...
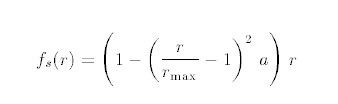
OpenGL 入门(三)—— OpenGL 与 OpenCV 共同打造大眼滤镜
从本篇开始,会在上一篇搭建的滤镜框架的基础上,介绍具体的滤镜效果该如何制作。本篇会先介绍大眼滤镜,先来看一下效果,原图如下: 使用手机后置摄像头对眼部放大后的效果: 制作大眼滤镜所需的主要知识点&…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...