大数据面试题之MapReduce(3)
目录
reduce任务什么时候开始?
MapReduce的reduce使用的是什么排序?
MapReduce怎么确定MapTask的数量?
Map数量由什么决定
MapReduce的map进程和reducer进程的ivm垃圾回收器怎么选择可以提高吞吐量?
MapReduce的task数目划分
MapReduce作业执行的过程中,中间的数据会存在什么地方?不会存在内存中么?
Mapper端进行combiner之后,除了速度会提升,那从Mapper端到Reduece端的数据量会怎么变?
map输出的数据如超出它的小文件内存之后,是落地到磁盘还是落地到HDFS中?
Map到Reduce默认的分区机制是什么?
结合wordcount述说MapReduce,具体各个流程,map怎么做,reduce怎么做
MapReduce数据倾斜产生的原因及其解决方案
Map Join为什么能解决数据倾斜
MapReduce运行过程中会发生OOM,OOM发生的位置?
MapReduce用了几次排序,分别是什么?
MapReduce压缩方式
MapReduce中怎么处理一个大文件
reduce任务什么时候开始?
在Hadoop MapReduce中,Reduce任务的开始时间取决于几个关键因素:1、Map任务的完成情况:
Reduce任务不能在所有相关的Map任务完成之前开始处理。但是,Hadoop允许在Map任务完成一定比例后就开始
执行Reduce任务,这一特性称为Reduce的慢启动。
2、配置参数:
Hadoop中有一个配置参数叫做 mapreduce.job.reduce.slowstart.completedmaps(在较旧版本中可能
是 mapred.reduce.slowstart.completed.maps),它控制Reduce任务何时开始执行。这个参数的默认值
通常是0.95,意味着当至少95%的Map任务完成时,Reduce任务就可以开始执行。
3、Shuffle和Sort阶段:
在Reduce任务真正开始处理数据之前,它必须先经历Shuffle和Sort阶段。Shuffle阶段涉及从各个Map任务收
集数据并将其传输到Reduce节点,而Sort阶段则是对这些数据进行排序,以便相同键的值能够被聚合在一起。只
有当Shuffle和Sort完成之后,Reduce任务才会进入Reduce阶段,开始处理数据。
4、Reduce任务槽的可用性:
Reduce任务需要Reduce槽(slot)才能执行,这是Hadoop中的资源管理概念。如果Reduce槽不可用,即使
Map任务完成了,Reduce任务也无法立即开始。因此,Reduce任务开始的时机是当Map任务完成到一定程度,并且Reduce任务所需的资源(如Reduce槽)可用
时,同时,Shuffle和Sort阶段也需完成才能正式进入Reduce阶段。这种设计允许MapReduce作业更早地开始Reduce阶段,从而可能加速整体作业的完成时间,尤其是在大型集群和
大规模数据集的情况下。然而,这也需要权衡,因为如果Reduce任务过早开始,可能会因为等待更多的Map输出
而花费额外的时间。MapReduce的reduce使用的是什么排序?
在MapReduce框架中,Reduce阶段使用的排序主要是基于键(key)的排序。在数据从Map阶段流向Reduce阶段
的过程中,会发生以下排序步骤:1、Map 输出排序:
在Map阶段,每个Map任务在输出键值对前,会对自己的输出进行局部排序。这是通过缓冲区溢写(spill)机制
实现的,当缓冲区满时,会将数据写入磁盘,同时在这个过程中进行一次快速排序。
2、Merge 排序:
每个Map任务可能产生多个溢写文件,这些文件会被合并(merge)成一个或少数几个已排序的文件,这个过程通
常使用归并排序(merge sort)。
3、Shuffle 排序:
在Shuffle阶段,来自不同Map任务的键值对会被重新分配给Reduce任务。MapReduce框架会确保在Shuffle过
程中,相同键的所有值都被发送到同一个Reduce任务,并且按照键的顺序排列。
4、Reduce 输入排序:
当数据到达Reduce任务时,它已经按照键进行了排序。Reduce任务会读取这些已经排序的数据,并且在
Reducer函数中处理每一个键的所有值。因此,Reduce阶段使用的是基于键的排序,确保所有具有相同键的值都聚集在一起,然后被Reducer函数处理。
这是MapReduce模型的关键特性之一,它简化了数据处理流程,使得开发人员只需要关注键值对的处理逻辑,而
不需要关心数据的排序和分发细节。需要注意的是,MapReduce框架提供了默认的排序和分组行为,但是用户也可以自定义排序比较器
(Comparator)和分组策略(GroupingComparator),以满足特定的排序需求。例如,二次排序就是在键的
基础上进一步排序,通常涉及到复合键的使用,其中包含主要排序键和次要排序键。MapReduce怎么确定MapTask的数量?
在Hadoop的MapReduce框架中,MapTask的数量是由输入数据的大小和Hadoop的配置决定的。具体来说,
MapTask的数量通常是基于输入文件的切片(splits)数量来确定的。以下是决定MapTask数量的主要因素和过
程:1、输入切片(Splits):
每个输入切片都会触发一个MapTask。输入切片是根据输入文件的大小和Hadoop配置参数来创建的。
2、HDFS块大小:
默认情况下,输入切片的大小会与HDFS的块大小相匹配,这是因为Hadoop通常试图将MapTask的数据保留在本地
节点上,以减少网络传输。HDFS的块大小默认为64MB或128MB,具体取决于Hadoop版本和集群配置。
3、最小和最大切片大小:
用户可以通过配置参数mapreduce.input.fileinputformat.split.minsize和
mapreduce.input.fileinputformat.split.maxsize来设置最小和最大切片大小,从而间接控制MapTask
的数量。
4、优化参数:
Hadoop提供了一些优化参数,如
mapreduce.input.fileinputformat.split.ignorephysicalsplits,这可以影响切片的生成方式。如
果设置为true,那么切片可能会跨越HDFS块边界,这可能会影响MapTask的数量。
5、自定义InputFormat:
开发者可以自定义InputFormat类来控制如何创建切片。自定义的InputFormat可以基于不同的标准(如记录
数、行数等)来创建切片,从而影响MapTask的数量。
6、文件大小和数量:
如果有多个小文件作为输入,即使它们的总大小小于HDFS块大小,每个文件也可能被视为一个独立的切片,从而
生成更多的MapTask。
7、其他配置:
其他配置参数,如mapreduce.job.reduces,虽然主要用于控制ReduceTask的数量,但在某些情况下也可能
影响MapTask的调度和执行。综上所述,MapTask的数量主要由输入数据的切片数量决定,而切片数量又受到HDFS块大小、自定义切片大小和
InputFormat实现的影响。在实践中,合理调整这些参数可以帮助优化MapReduce作业的性能。例如,增加切片
数量可以提高并行度,但过多的MapTask可能导致资源过度分散和调度延迟。Map数量由什么决定
"Map数量" 通常指的是在分布式系统、数据库或某些特定应用中,如Apache Hadoop中的MapReduce任务、
Elasticsearch的shards、或者是其他键值存储系统中的映射数量。这些Map数量的决定因素可以因系统而异,
但通常包括以下几个方面:1、数据量:
数据量的大小直接影响Map数量的选择。对于大规模数据集,通常需要更多的Map任务或分片来处理数据,以确保
并行性和性能。
2、并行性需求:
如果需要更高的并行处理能力来加速任务,那么可能需要增加Map数量。更多的Map任务可以分布在更多的节点或
线程上执行。
3、资源限制:
可用资源(如CPU、内存、磁盘I/O等)限制了可以并行运行的Map任务的数量。资源不足可能导致任务执行缓慢
或失败。
4、数据划分策略:
数据如何被划分成多个Map任务或分片,也决定了Map的数量。例如,在Hadoop中,数据的划分通常基于输入文件
的大小和配置的分片大小。
5、系统配置:
在某些系统中,Map数量可以由用户配置或通过系统参数自动确定。例如,在Hadoop中,可以通过
mapred.map.tasks属性设置Map任务的数量。
6、负载均衡:
为了确保集群中的节点负载均衡,可能需要动态调整Map数量。如果某些节点负载过高,可能需要将更多数据划分
到其他节点上处理。
7、数据特性和查询需求:
在某些应用中,数据的特性和查询需求也可能影响Map数量的选择。例如,在Elasticsearch中,索引的shards
数量(类似于Map)可能基于数据的大小、更新频率和查询性能需求来设置。
8、容错性:
Map数量的选择也可能考虑到容错性。在分布式系统中,如果某个Map任务或分片失败,系统应该能够重新分配任
务或利用冗余数据来继续处理。总之,"Map数量"的决定因素是多方面的,包括数据量、并行性需求、资源限制、数据划分策略、系统配置、负载
均衡、数据特性和查询需求以及容错性等。在设计和配置分布式系统时,需要综合考虑这些因素来确定合适的Map
数量。MapReduce的map进程和reducer进程的ivm垃圾回收器怎么选择可以提高吞吐量?
MapReduce的map进程和reducer进程的JVM(Java虚拟机)垃圾回收器选择对于提高吞吐量至关重要。在选择
垃圾回收器时,应考虑到MapReduce任务通常涉及大规模数据处理,因此,吞吐量是首要考虑的因素。以下是一
些建议,可以帮助您选择合适的垃圾回收器来提高MapReduce的吞吐量:1、吞吐量优先的垃圾回收器:
选择那些以吞吐量为主要优化目标的垃圾回收器。例如,在Java 8及更高版本中,G1(Garbage-First)垃圾
回收器通常是一个很好的选择,因为它旨在提供可预测的暂停时间和良好的吞吐量。
对于MapReduce任务,可以考虑使用G1垃圾回收器的"Parallel"模式,该模式可以并行执行多个垃圾回收线
程,从而增加吞吐量。
2、调整JVM参数:
根据您的MapReduce任务的具体需求和资源限制,调整JVM的启动参数。例如,增加堆内存大小(-Xmx)和新生
代大小(-Xmn)可以为垃圾回收器提供更多的内存空间来工作,从而提高吞吐量。
同时,也可以调整垃圾回收器的相关参数,如G1垃圾回收器的暂停时间目标(-XX:MaxGCPauseMillis)和堆占
用率阈值(-XX:InitiatingHeapOccupancyPercent),以平衡吞吐量和暂停时间。
3、监控和调整:
使用JMX(Java Management Extensions)或其他监控工具来监控MapReduce任务的JVM性能和垃圾回收活
动。根据监控结果,调整JVM参数和垃圾回收器配置,以找到最佳的吞吐量和暂停时间权衡。
4、注意资源分配:
确保MapReduce任务的JVM进程有足够的CPU和内存资源来执行垃圾回收和其他任务。资源不足可能导致垃圾回收
器无法正常工作,从而降低吞吐量。
5、避免频繁的全局垃圾回收:
在MapReduce任务中,频繁的全局垃圾回收可能会导致性能下降。因此,应尽量避免在Map或Reduce任务中创建
大量短生命周期的对象,以减少垃圾回收的压力。
6、考虑使用其他JVM技术:
除了调整垃圾回收器外,还可以考虑使用其他JVM技术来提高MapReduce的吞吐量。例如,使用Java的并行流
(parallel streams)或CompletableFuture来并行处理数据,或者使用其他高性能的JVM实现(如
GraalVM)来优化代码执行。总之,在选择MapReduce的JVM垃圾回收器时,应优先考虑吞吐量,并根据具体的任务需求和资源限制进行调整和
优化。通过监控和调整JVM参数和垃圾回收器配置,可以找到最佳的吞吐量和暂停时间权衡,从而提高MapReduce
的性能。MapReduce的task数目划分
在MapReduce框架中,任务(task)的数目划分主要分为两部分:Map任务和Reduce任务。这两类任务的数目划
分对于作业的执行效率和资源利用至关重要。下面是关于Map和Reduce任务数目如何确定的一些细节:1、Map任务数目
Map任务的数目主要由输入数据的切片(split)数目决定。Hadoop MapReduce使用InputFormat来决定如何
分割输入数据,以及如何创建Map任务。默认情况下,一个切片对应一个Map任务。切片的大小通常与HDFS的块大
小相关,但也可以通过配置或自定义逻辑来改变。切片大小:默认情况下,切片大小等于HDFS的块大小,这在Hadoop 1.x中通常是64MB,在Hadoop 2.x中是
128MB。但是,可以通过设置mapreduce.input.fileinputformat.split.minsize和
mapreduce.input.fileinputformat.split.maxsize来调整最小和最大切片大小。
自定义InputFormat:开发者可以实现自己的InputFormat类,以更精细地控制切片的创建,包括切片的大小和
位置。2、Reduce任务数目
Reduce任务的数目通常由用户指定,但也可以通过默认值来确定。Reduce任务用于对Map阶段产生的中间结果进
行汇总或进一步处理。用户指定:可以通过设置mapreduce.job.reduces这个配置参数来显式指定Reduce任务的数目。这是最常见的
方式,因为Reduce任务的数目直接影响了输出文件的数目和数据的聚合方式。
默认值:如果未显式设置Reduce任务数目,MapReduce框架通常会使用默认值,这个默认值可能是1或者根据某
种策略计算得出的数值。优化建议
为了优化MapReduce作业的性能,以下是一些关于任务数目划分的考虑:Map任务:增加Map任务的数量可以提高并行性,但如果切片过小,则可能导致大量的任务调度开销和额外的管理
负担。因此,选择合适的切片大小以平衡并行性和效率是很重要的。
Reduce任务:过多的Reduce任务会导致更多的shuffle阶段数据传输和排序开销,而过少的Reduce任务则可能
导致单个Reduce任务处理过多数据,从而成为瓶颈。一种常见的策略是根据集群的节点数和每个节点上可运行的
Reduce任务的最大数目来设定Reduce任务的数目。
合理的任务数目划分可以显著提升MapReduce作业的执行效率和资源利用率,因此在设计MapReduce应用时,应
该仔细考虑这些因素。MapReduce作业执行的过程中,中间的数据会存在什么地方?不会存在内存中么?
在MapReduce作业执行的过程中,中间的数据的存储位置主要取决于MapReduce的实现和配置,以及处理的数据
量大小。以下是关于MapReduce作业中间数据存储的详细说明:1、Map阶段的中间数据存储:
Map阶段的输出,即中间结果,首先会被写入到每个Map任务的本地内存缓冲区中。这个缓冲区的大小通常是可配
置的,但默认大小可能是100M。
当内存缓冲区中的数据量达到某个阈值(当达到80%即80M时)时,数据会被溢写到本地磁盘上。这是为了防止内存溢出并确保数据的持久化存储。
如果一个Map任务输出的数据没有达到缓冲区溢写的阈值,但Map任务已经完成,那么剩余的数据也会被写入磁
盘。
写入磁盘的数据会经过分区(partitioning)和排序(sorting)操作,以确保相同key的数据被写入到同一个文件中,并且这些数据在文件中是按key排序的。
2、Reduce阶段的中间数据获取:
Reduce任务从Map任务获取中间结果时,它会从Master节点获取Map任务输出数据的位置信息,并从本地磁盘中
读取这些数据。
Reduce任务在读取数据后,会根据key对数据进行排序和合并(merge),以便进行归约(reduce)操作。
3、是否全部存储在内存中?
不是。如上所述,MapReduce的中间数据主要存储在本地磁盘上,而不是完全存储在内存中。这是因为处理大规
模数据时,完全依赖内存来存储中间数据是不现实的,容易导致内存溢出。
使用磁盘存储还有一个好处是数据持久化,即使在Map或Reduce任务失败的情况下,数据也不会丢失,可以重新
利用。总结来说,MapReduce作业执行过程中,中间数据主要存储在本地磁盘上,而不是完全存储在内存中。Map阶段的
输出数据首先写入内存缓冲区,当达到阈值时或Map任务完成时,数据会被写入磁盘。Reduce阶段从磁盘中读取
Map任务的输出数据,并进行归约操作。Mapper端进行combiner之后,除了速度会提升,那从Mapper端到Reduece端的数据量会怎么变?
在MapReduce作业中,使用Combiner之后,从Mapper端到Reducer端的数据量通常会减少。Combiner的主要
作用是在Mapper端对输出进行局部聚合,这意味着它会合并那些拥有相同键的键值对,减少重复数据的传输。例如,在典型的WordCount应用中,Mapper会输出每行文本中每个单词的出现次数,格式为(word, 1)这样的
键值对。如果没有Combiner,Mapper的所有输出都会直接传送到Reducer,这可能包括大量重复的(word, 1)
对。然而,使用Combiner后,Mapper端会先对(word, 1)进行聚合,将相同的单词出现次数相加,输出
(word, count),其中count是该单词在Mapper处理的数据块中的出现总次数。因此,Combiner减少了网络传输的数据量,因为现在传输的是聚合后的数据,而不是原始的、未聚合的数据。这
对于提高MapReduce作业的整体性能尤其重要,因为网络I/O往往是整个作业的瓶颈之一。值得注意的是,Combiner的使用不会改变最终的计算结果,因为它只是在Mapper端进行局部聚合。最终的聚合
和计算仍由Reducer完成,但它接收到的数据量更少,这有助于减少Reducer的负载,缩短作业的执行时间。不
过,Combiner的使用也需要谨慎,过度使用可能会导致Mapper端的计算时间增加,从而抵消掉网络传输的节
省。因此,是否使用Combiner以及如何设计Combiner逻辑,需要根据具体的作业需求和数据特性来决定。map输出的数据如超出它的小文件内存之后,是落地到磁盘还是落地到HDFS中?
在MapReduce作业中,当Map阶段输出的数据超出其内存缓冲区的大小时,数据会被写入到本地磁盘中,而不是直
接写入HDFS。以下是详细的过程:1、内存缓冲区:Map阶段的输出数据首先会被写入到一个内存缓冲区中。这个内存缓冲区的大小通常是由
MapReduce配置参数(如mapreduce.task.io.sort.mb)来设定的,默认大小可能因Hadoop版本而异,但通
常是几十到几百兆字节(MB)的级别。
2、数据溢出:当内存缓冲区中的数据量达到一定的阈值(通常是缓冲区大小的某个百分比,如80%)时,就会发
生数据溢出。这是为了防止内存溢出并确保数据的持久化存储。
3、写入本地磁盘:溢出的数据会被写入到Map任务所在的本地文件系统的磁盘上。这些数据会被划分为多个溢写
文件(spill files),每个文件包含一部分中间结果数据。同时,为了后续Reduce阶段能够高效地读取数据,
这些溢写文件还会进行分区(partitioning)和排序(sorting)。
4、合并和排序:Map任务结束后,所有的溢写文件会被合并成一个或多个已排序的输出文件。这个过程称为合并
(merge)和排序(sort)。
5、写入HDFS:虽然Map阶段的输出数据首先被写入到本地磁盘上,但整个MapReduce作业的输出结果(即
Reduce阶段的输出)最终会被写入到HDFS(Hadoop Distributed FileSystem)中。这是MapReduce框架
的一个关键特性,它允许MapReduce作业在分布式文件系统中处理大规模数据集。
6、注意:上述过程主要描述了Map阶段输出数据的处理流程。Reduce阶段会从Map任务的输出中读取数据,并将
处理结果写入到HDFS中作为整个作业的输出。总结来说,当Map阶段输出的数据超出其内存缓冲区的大小时,数据会被写入到本地磁盘上的多个溢写文件中,并
最终在Map任务结束时合并成一个或多个已排序的输出文件。而整个MapReduce作业的输出结果则会被写入到
HDFS中。Map到Reduce默认的分区机制是什么?
在MapReduce中,数据从Map阶段传递到Reduce阶段时,默认的分区机制是基于键(key)的哈希分区(Hash
Partitioning)。这种分区机制的工作原理如下:1、哈希计算:MapReduce框架会对Map阶段产生的每个键值对的键(key)进行哈希运算。
2、取模运算:得到的哈希值随后会被对Reduce任务的总数取模(modulus operation)。这意味着哈希值将被
除以Reduce任务的总数,而余数将决定数据被分配到哪个Reduce任务。
3、分区确定:取模运算的结果决定了键值对将被发送到哪个分区,即哪个Reduce任务。具有相同键的键值对经过
哈希和取模运算后,会指向同一个Reduce任务,确保了相同键的数据会在同一个Reduce任务中被处理。
这种分区机制确保了数据的均匀分布,并且具有相同键的数据会汇聚到同一个Reduce任务中,这对于聚合操作
(如计数、求和等)特别有用,因为所有相关的数据都将集中在一个地方进行处理。例如,如果有一个作业设置了3个Reduce任务,那么任何键的哈希值对3取模的结果将是0、1或2,这将决定数据将被发送到3个Reduce任务中的哪一个。值得注意的是,尽管哈希分区在许多场景下工作得很好,但在某些情况下,比如键分布不均或存在热点键时,可能
会导致数据倾斜(skew),即某些Reduce任务处理的数据远多于其他任务。在这种情况下,可能需要自定义分区
器以更有效地分布数据。结合wordcount述说MapReduce,具体各个流程,map怎么做,reduce怎么做
MapReduce是一种编程模型,用于处理和生成大规模数据集,广泛应用于大数据处理领域。WordCount是一个经
典的MapReduce示例,用于统计文本文件中每个单词出现的频率。下面我们将详细解释MapReduce在WordCount
应用中的具体流程:Map阶段
1、输入切分:Hadoop首先将输入的大型文本文件切分成若干个块,每个块称为一个split,然后每个split被分
配给一个Map任务处理。
2、Mapper处理:每个Map任务读取分配给它的split,将文本行读入内存,然后进行处理。Mapper函数通常会
读取一行数据,使用正则表达式或空格将行分割成单词。Mapper(key, value) -> list of (key, value)其中,key是文件的偏移量或文件名,value是文件的内容。Mapper函数会生成一系列的键值对,键是单词,值通常是数字1,表示该单词出现了1次。 例如,对于输入行“Hello world Hello”,Mapper可能产生:
("Hello", 1)
("world", 1)
("Hello", 1)Shuffle阶段
3、分区:Mapper输出的键值对会被分区,即根据键进行哈希计算,然后对Reduce任务的总数取模,以决定数据
应该发送给哪个Reducer。
4、排序:在分区之后,数据会被排序,使得所有具有相同键的键值对都被分组在一起,便于后续的Reduce处理。
5、组合(Combiner,可选):在数据发送到Reducer之前,可以在Mapper端使用Combiner对具有相同键的键
值对进行初步的聚合,减少网络传输的数据量。Combiner函数类似于Reduce函数,但是它只在Mapper节点上运
行。Reduce阶段
6、Reducer处理:当所有Mapper任务完成后,Reducer开始接收来自不同Mapper的键值对。Reducer函数对
具有相同键的键值对进行处理,通常是对所有值进行求和,以计算出单词的总出现次数。Reducer(key, list of values) -> list of (key, value)例如,Reducer可能接收:
("Hello", [1, 1])
("world", [1])并输出:
("Hello", 2)
("world", 1)7、输出:Reducer最后输出的键值对会被写入到Hadoop Distributed File System (HDFS)中,形成最终
的结果文件。整个MapReduce过程涉及到了数据的并行处理、中间数据的洗牌和排序、以及结果的汇总,这些特性使得
MapReduce非常适合处理大规模数据集。在WordCount的例子中,每个阶段都有明确的功能,使得数据处理既高
效又可扩展。MapReduce数据倾斜产生的原因及其解决方案
MapReduce数据倾斜是指在MapReduce作业中,数据在各个处理节点之间分布不均,导致某些节点处理的数据量
远大于其他节点,进而影响整体的处理性能和作业完成时间。数据倾斜可以由多种因素造成,并且可以通过不同的
策略来缓解或解决。数据倾斜产生的原因:
1、Key分布不均:MapReduce通过键(Key)对数据进行分区,如果某些键的出现频率远高于其他键,则会导致
这些键对应的数据集中在少数几个Reducer上。
2、业务数据特性:某些业务数据本身就具有长尾分布的特点,即少数数据点出现频率非常高,而大多数数据点出
现频率较低。
3、SQL查询或数据处理逻辑:特定的SQL查询或数据处理逻辑可能会导致数据倾斜,例如,JOIN操作如果未正确
处理,可能会导致数据集中到少量的Reducer上。
4、数据过滤:过滤条件可能无意中导致数据倾斜,尤其是当过滤器仅适用于数据集的特定部分时。
5、数据大小不均:部分记录的大小远远大于平均值,这也可能导致数据倾斜。解决方案:
1、抽样和范围分区:在作业开始前,通过对数据进行抽样分析,确定数据分布情况,然后根据抽样结果设定分区
边界,使数据更加均匀地分布在各个Reducer上。
2、自定义分区器:开发自定义的分区算法,根据业务需求和数据特性重新设计分区逻辑,避免数据集中到少数几
个Reducer上。
3、使用Combine函数:在Map阶段使用Combine函数对数据进行局部聚合,减少网络传输的数据量,减轻
Reduce阶段的压力。
4、Map Join:对于小表与大表的JOIN操作,可以使用Map Join替代Reduce Join,将小表广播到所有Map任
务中,从而避免数据倾斜。
5、增加Reducer数量:适当增加Reducer的数量,可以减少每个Reducer需要处理的数据量,但同时也会增加总
的处理开销。
6、数据预处理:在数据进入MapReduce作业前进行预处理,如对数据进行散列或随机化处理,以平衡数据分布。
7、动态调整:在运行时动态调整资源分配,确保资源能够更好地匹配任务需求,尤其是在云环境中可以更灵活地
进行资源调度。
8、优化业务逻辑:审查并优化业务逻辑,避免不必要的数据倾斜,如在进行JOIN操作时考虑使用更合适的键。通过上述方法,可以有效地缓解MapReduce作业中的数据倾斜问题,提高作业的效率和稳定性。在实际应用中,
可能需要结合具体情况采取一种或多种策略来解决问题。Map Join为什么能解决数据倾斜
Map Join能解决数据倾斜的问题,主要基于以下几个关键点:1、原理与过程:
Map Join是一种将小表数据加载到内存中进行连接操作的方法。它利用MapReduce的并行计算能力,将Join操
作从Reduce阶段提前到Map阶段,减少了数据的传输和磁盘IO。
在Map阶段,将小表的数据加载到内存中构建一个哈希表,然后将大表的数据按照Join键进行哈希计算,与内存中
的哈希表进行匹配。如果匹配成功,则直接在Map阶段将两个表的记录进行连接并输出,避免了Reduce阶段的数
据传输和合并。2、解决数据倾斜的方面:
减少数据传输:由于Map Join在Map阶段就完成了大部分连接操作,因此减少了在Shuffle阶段需要传输的数据
量。在数据倾斜的场景中,大量数据传输可能导致网络拥塞和节点负载不均,而Map Join通过减少数据传输来减
轻这些问题。
优化内存使用:通过将小表加载到内存中,Map Join能够更高效地使用内存资源。在数据倾斜的场景中,某个特
定的键可能对应大量数据,导致内存使用不均。而Map Join通过在内存中构建哈希表,将小表的数据分布到各个
Map任务中,从而平衡了内存使用。
提前过滤和连接:在Map阶段就进行连接操作,可以提前过滤掉不需要的数据,减少Reduce阶段的数据处理量。
这有助于避免数据倾斜导致的Reduce任务处理时间过长的问题。
3、适用场景:
Map Join特别适用于大小表连接的场景,即当需要连接的表中,一个表的数据量非常大,而另一个表的数据量相
对较小时。在这种情况下,将小表数据加载到内存中进行连接操作,可以显著提高查询性能。综上所述,Map Join通过减少数据传输、优化内存使用以及提前过滤和连接等操作,有效地解决了数据倾斜的问
题。在大小表连接的场景中,使用Map Join可以显著提高查询性能并降低资源消耗。MapReduce运行过程中会发生OOM,OOM发生的位置?
在MapReduce运行过程中,发生Out Of Memory (OOM) 错误通常是因为JVM(Java虚拟机)的堆内存不足以
存储正在处理的数据和对象。OOM错误可能发生在以下几个主要位置:1、Map阶段:
当Mapper任务处理的输入数据量过大,或者Mapper函数在处理数据时产生了大量的中间键值对,导致内存溢出。
如果Mapper任务中创建了大量临时对象,没有及时释放,也可能导致内存消耗过多。
2、Reduce阶段:
在Shuffle阶段,大量的键值对被加载到内存中进行排序和分组,如果数据量过大,可能超出Reduce任务分配的
内存。
Reduce函数在处理大量数据时,特别是在进行聚合操作时,如果中间结果集很大,也可能导致OOM。
3、Driver或Master节点:
在某些情况下,例如Hive中的MapReduce作业,OOM可能发生在Driver节点提交作业阶段,这是因为序列化和反
序列化MapReduce作业的元数据(如MapredWork)时,内存消耗超过了限制。
如果Driver节点需要在内存中保留大量状态或执行复杂的作业调度逻辑,也可能会遇到OOM问题。
4、网络缓冲区:
在数据传输过程中,如果网络缓冲区设置不当,例如shuffle过程中buffer大小不合理,也可能因数据缓存导致
内存溢出。为了避免OOM问题,可以采取以下一些措施:1) 调整JVM参数,增加分配给Map和Reduce任务的内存。
2) 使用Combiner在Map阶段进行局部聚合,减少网络传输的数据量。
3) 优化代码,减少不必要的对象创建,及时释放不再使用的对象。
4) 设置合理的Shuffle buffer大小和Spill threshold,避免过多数据驻留在内存中。
5) 对数据进行预处理,例如采样、过滤或压缩,以减少处理的数据量。
6) 增加Reduce任务的数量,分散数据负载,但需注意过多的Reduce任务也会增加开销。
7) 使用更有效的数据结构和算法,减少内存占用。在实践中,需要根据具体的MapReduce作业和数据特性来调整和优化这些参数和策略。MapReduce用了几次排序,分别是什么?
MapReduce在执行过程中,通常会发生三次或最多四次排序,具体取决于MapReduce任务的实现和配置。以下是
关于MapReduce中排序的详细解释:1、Map阶段的排序:
环形缓冲区排序:当Map函数产生输出时,数据首先被写入内存的环形缓冲区。当缓冲区的数据达到设定的阈值
后,后台线程会对缓冲区中的数据进行一次快速排序,然后将这些有序数据溢写到磁盘上。
溢写文件合并排序:当Map任务处理完毕后,磁盘上可能存在多个已经分区并排序的溢写文件。这些文件会被合并
成一个已分区且已排序的输出文件。由于溢写文件已经经过排序,所以合并时只需再进行一次排序(通常使用归并
排序)即可使输出文件整体有序。2、Reduce阶段的排序:
数据拷贝与排序:在Reduce阶段,需要将多个Map任务的输出文件拷贝到ReduceTask中。如果文件大小或数量
超过一定阈值,会进行溢写磁盘或内存中的合并操作,并可能伴随排序(归并排序)。
Reduce Task前分组排序:当所有文件拷贝完毕后,Reduce Task会统一对内存和磁盘上的所有数据进行一次归
并排序,以确保数据的正确性和有序性。特殊情况:在某些特定情况下,如自定义排序或优化策略,MapReduce可能会执行额外的排序操作,使得总排序次数达到四
次或更多。总结来说,MapReduce中的排序操作主要发生在Map阶段的环形缓冲区、Map任务完成后的溢写文件合并,以及
Reduce阶段的数据拷贝和Reduce Task前的分组过程中。这些排序操作确保了MapReduce任务输出的数据是有
序的,从而提高了数据处理效率和准确性。MapReduce压缩方式
在MapReduce框架中,数据压缩是一种重要的优化策略,它能显著减少磁盘I/O操作,加快文件传输效率,降低网
络带宽的使用,并节省存储空间。Hadoop支持在不同的阶段进行数据压缩,主要包括:1、Input Compression:
在数据读入Map任务之前进行压缩,这通常不是MapReduce框架直接控制的,而是由Hadoop分布式文件系统
(HDFS)或输入格式来管理。常用的压缩算法有Gzip、Bzip2、Snappy、LZO等。
2、Map Output Compression:
Map任务输出的数据在写入磁盘之前可以进行压缩,然后再在网络上传输到Reduce任务。这一步骤的压缩可以显
著减少Map和Reduce之间的数据传输量。
可以使用的压缩算法包括Snappy、LZO、Bzip2等,其中Snappy因其较快的压缩和解压缩速度常被选用。
3、Reduce Output Compression:
Reduce任务的输出也可以进行压缩,然后再写入HDFS。这有助于节省存储空间和后续的数据传输时间。
常见的压缩算法有Gzip、Bzip2、Snappy、LZO等,选择哪种算法取决于对压缩比和CPU使用率的权衡。
4、In-Memory Compression:
尽管这不是标准的MapReduce压缩策略,但在一些实现中,可以在内存中对数据进行压缩,以减少内存使用,尤
其是在处理大量数据时。选择压缩算法时,需要考虑到压缩和解压缩的CPU成本、压缩比率以及压缩速度等因素。例如,Gzip通常提供较高
的压缩比率,但其压缩和解压缩速度较慢;而Snappy则提供较快的压缩和解压缩速度,但压缩比率相对较低。配置MapReduce压缩通常涉及到设置以下配置参数:mapreduce.map.output.compress: 控制Map输出是否应被压缩。
mapreduce.map.output.compress.codec: 指定Map输出的压缩算法。
mapreduce.output.fileoutputformat.compress: 控制Reduce输出是否应被压缩。
mapreduce.output.fileoutputformat.compress.codec: 指定Reduce输出的压缩算法。
此外,对于特定的压缩算法,可能还需要设置额外的参数来调整压缩级别或其他行为。在选择压缩策略时,应当根
据具体的应用场景和数据特性来进行权衡和优化。MapReduce中怎么处理一个大文件
在MapReduce中处理大文件时,主要依赖于Hadoop的分布式文件系统(HDFS)和MapReduce框架本身的设计来
实现数据的高效处理。以下是处理大文件的一般步骤和策略:1、文件切片:
HDFS将大文件切分为多个块(默认块大小可能是64MB或128MB,取决于Hadoop版本),每个块可以被视为一个独
立的文件片段。
MapReduce框架进一步将这些块划分为InputSplits,每个InputSplit可能对应于一个或多个HDFS块的一部
分。InputSplits的大小可以由用户配置,但通常接近于HDFS的块大小。
2、任务分配:
MapReduce框架根据InputSplits的数量启动相应数量的Map任务。每个Map任务处理一个或多个
InputSplits。
Map任务尽可能在存储相关数据的DataNode上本地运行,以减少网络延迟。
3、数据处理:
Map任务读取分配给它的InputSplit,执行用户定义的Map函数,将输入转换为一系列键值对。
Map任务的输出被分区、排序和写入中间文件。这个过程可能涉及多次溢出到磁盘,以防止内存溢出。
4、Shuffle阶段:
Map任务的输出被复制到Reduce任务所在的节点。在此期间,数据被重新分区,以便具有相同键的数据被发送到
相同的Reduce任务。
在Reduce任务上,数据被排序,具有相同键的键值对被组合在一起。
5、Reduce处理:
Reduce任务执行用户定义的Reduce函数,对每个键的所有值进行聚合操作。
Reduce任务的输出被写入到HDFS中作为最终结果。
6、优化和策略:
使用Combiner函数在Map阶段进行局部聚合,以减少Shuffle阶段的数据传输量。
调整Map和Reduce任务的内存分配,以适应大文件处理的需求。
选择适当的压缩算法来压缩Map输出和Reduce输出,以减少数据传输时间和存储空间。
调整Map和Reduce任务的数量,以达到最佳的并行度和数据处理效率。通过这些步骤和策略,MapReduce能够有效地处理大文件,利用分布式集群的计算能力进行并行处理,从而大幅
缩短处理时间。在处理非常大的文件时,重要的是要合理配置MapReduce参数,以避免内存溢出等问题,并确保
数据处理的效率和可靠性。引用:大数据面试题V3.0,约870篇牛客大数据面经480道面试题_牛客网
通义千问、文心一言
相关文章:
)
大数据面试题之MapReduce(3)
目录 reduce任务什么时候开始? MapReduce的reduce使用的是什么排序? MapReduce怎么确定MapTask的数量? Map数量由什么决定 MapReduce的map进程和reducer进程的ivm垃圾回收器怎么选择可以提高吞吐量? MapReduce的task数目划分 MapReduce作业执行的过程中,中…...

[leetcode]squares-of-a-sorted-array. 有序数组的平方
. - 力扣(LeetCode) class Solution { public:vector<int> sortedSquares(vector<int>& nums) {int n nums.size();vector<int> ans(n);for (int i 0, j n - 1, pos n - 1; i < j;) {if (nums[i] * nums[i] > nums[j] *…...

使用Spring Boot和Spring Data JPA进行数据库操作
使用Spring Boot和Spring Data JPA进行数据库操作 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!在现代的Web应用开发中,数据库操作是不可或缺的一…...
《昇思25天学习打卡营第17天 | 昇思MindSporeCycleGAN图像风格迁移互换》
17天 本节学习了CycleGAN图像风格迁移互换。 CycleGAN即循环对抗生成网络,该模型实现了一种在没有配对示例的情况下学习将图像从源域 X 转换到目标域 Y 的方法。该模型一个重要应用领域是域迁移,可以通俗地理解为图像风格迁移。其实在 CycleGAN 之前&a…...

SecureCRT使用SSH登录服务器报错:Key exchange failed
SecureCRT使用SSH登录Ubuntu服务器报错:Key exchange failed 原因: ssh客户端与服务器的公钥协商失败,SecureCRT客户端所指定的秘钥交换算法(KexAlgorithms ),不在服务端支持范围内。可能是服务端的sshd版…...

Oracle给用户单个表查询权限
Oracle给用户单个表查询权限 1. 创建用户 --创建用户thfj_test,密码为thfj_test create user thfj_test identified by thfj_test;2. 用户授权 --授权连接数据库权限给thfj_test grant create session to thfj_test; --授权查询表USER_INFO 的权限给thfj_test grant sele…...
[Go 微服务] Kratos 验证码业务
文章目录 1.环境准备2.验证码服务2.1 kratos 初始化验证码服务项目2.2 使用 Protobuf 定义验证码生成接口2.3 业务逻辑代码实现 1.环境准备 protoc和protoc-gen-go插件安装和kratos工具安装 protoc下载 下载二进制文件:https://github.com/protocolbuffers/protobu…...

等保2.0安全计算环境解读
等保2.0,即网络安全等级保护2.0制度,是中国为了适应信息技术的快速发展和安全威胁的新变化而推出的网络安全保护标准。相较于等保1.0,等保2.0更加强调主动防御、动态防御和全面审计,旨在实现对各类信息系统的全面保护。 安全计算环…...
)
Qt视频播放器(二)
文章目录 1. 安装FFmpeg库2. 创建Qt项目3. 配置项目文件CMakeLists.txt4. 实现核心FFmpeg功能`videoplayer.h``videoplayer.cpp`5. 实现QML界面`main.qml`6. 主函数`main.cpp`运行项目详细说明结合FFmpeg进行视频播放的核心部分,并使用QML进行界面设计,您可以实现一个功能强大…...
普元EOS学习笔记-创建精简应用
前言 本文依旧基于EOS8.3进行描述。 在上一篇文章《EOS8.3精简版安装》中,我们了解到普元预编译好的EOS的精简版压缩包,安装后,只能进行低开,而无法高开。 EOS精简版的高开方式是使用EOS开发工具提供的IDE,创建一个…...
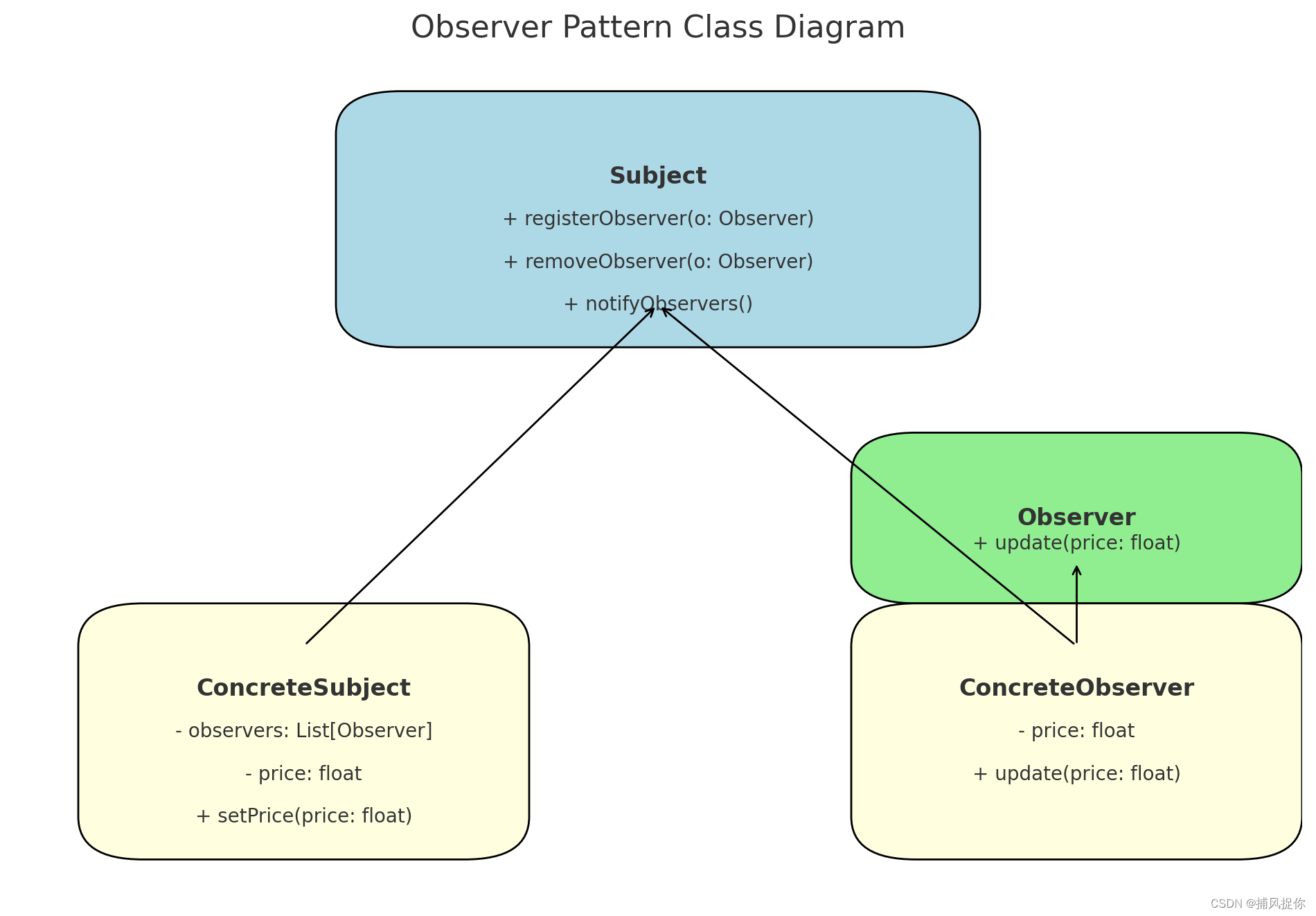
观察者模式在金融业务中的应用及其框架实现
引言 观察者模式(Observer Pattern)是一种行为设计模式,它定义了一种一对多的依赖关系,使得多个观察者对象同时监听某一个主题对象。当这个主题对象发生变化时,会通知所有观察者对象,使它们能够自动更新。…...

最新docker仓库镜像
目前下面的docker仓库镜像源还能使用。 vi /etc/docker/daemon.json添加如下配置{"registry-mirrors": ["https://hub.uuuadc.top", "https://docker.anyhub.us.kg", "https://dockerhub.jobcher.com", "https://dockerhub.icu&…...

springboot 3.x相比之前版本有什么区别
Spring Boot 3.x相比之前的版本(尤其是Spring Boot 2.x),主要存在以下几个显著的区别和新特性: Java版本要求: Spring Boot 3.x要求至少使用Java 17作为最低版本,同时已经通过了Java 19的测试,…...
Python逻辑控制语句 之 判断语句--if语句的基本结构
1.程序执行的三大流程 顺序 分支(判断) 循环 2.if 语句的介绍 单独的 if 语句,就是 “如果 条件成⽴,做什么事” 3.if 语句的语法 if 判断条件: 判断条件成立,执行的代码…...
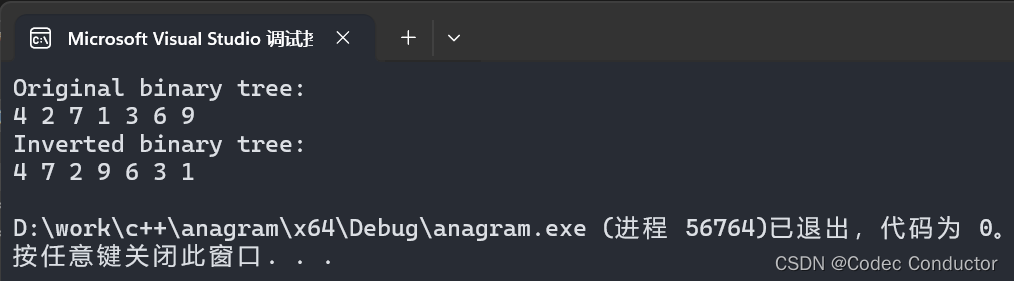
LeetCode 算法:翻转二叉树 c++
原题链接🔗:翻转二叉树 难度:简单⭐️ 题目 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 示例 1: 输入:root [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1] 示例 …...
七天速通javaSE:第五天 数组进阶
文章目录 前言一、二维数组二、Arrays类1.toString打印数组内各元素1.1 示例1.2 自己实现内部逻辑 2. sort升序排列3. fill数组填充(重新赋值)4.equals比较数组元素是否相等 三、冒泡排序 前言 本文将学习二维数组、arrays类以及冒泡排序 一、二维数组 …...

游戏心理学Day28
独立游戏团队架构 独立游戏工作室是一个包括编程美术设计院校项目管理和运营等各种职能的团队找到可以共同奋斗。数月甚至数年的合适人选并不是一件容易的事情。游戏开发过程中要涉及多种常规工作。小团队的每个成员通常都要身兼数职,而且有些角色常由多人担任。 …...

鸿蒙开发设备管理:【@ohos.multimodalInput.inputEventClient (注入按键)】
注入按键 InputEventClient模块提供了注入按键能力。 说明: 本模块首批接口从API version 8开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。本模块接口均为系统接口,三方应用不支持调用。 导入模块 import inputEventCli…...

C++:std::function的libc++实现
std::function是个有点神奇的模板,无论是普通函数、函数对象、lambda表达式还是std::bind的返回值(以上统称为可调用对象(Callable)),无论可调用对象的实际类型是什么,无论是有状态的还是无状态…...
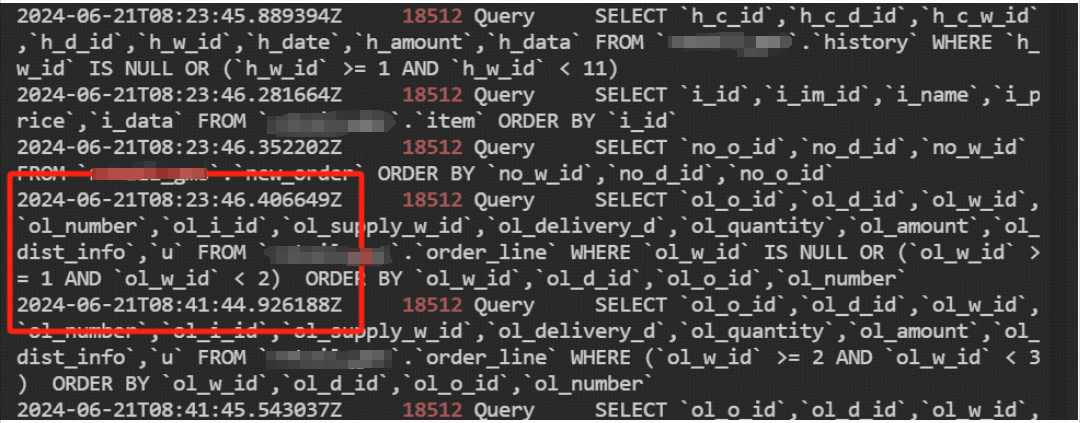
DM 的断点续传测试
作者: 大鱼海棠 原文来源: https://tidb.net/blog/4540ae34 一、概述 DM有all、full、incremental三种数据迁移同步方式(task-mode),在all同步模式下,因一些特殊情况,需要变更上游MySQL的数…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...