1-3.文本数据建模流程范例
文章最前: 我是Octopus,这个名字来源于我的中文名–章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github
;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的动态,一起学习,共同进步。
import os#mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" !pip install gensim
!pip install torchkeras
import torch
import gensim
import torchkeras
print("torch.__version__ = ", torch.__version__)
print("gensim.__version__ = ", gensim.__version__)
print("torchkeras.__version__ = ", torchkeras.__version__) torch.__version__ = 2.0.1
gensim.__version__ = 4.3.1
torchkeras.__version__ = 3.9.3
公众号 算法美食屋 回复关键词:pytorch, 获取本项目源码和所用数据集百度云盘下载链接。
一,准备数据
imdb数据集的目标是根据电影评论的文本内容预测评论的情感标签。
训练集有20000条电影评论文本,测试集有5000条电影评论文本,其中正面评论和负面评论都各占一半。
文本数据预处理较为繁琐,包括文本切词,构建词典,编码转换,序列填充,构建数据管道等等。
此处使用gensim中的词典工具并自定义Dataset。
下面进行演示。

import numpy as np
import pandas as pd
import torch MAX_LEN = 200 #每个样本保留200个词的长度
BATCH_SIZE = 20 dftrain = pd.read_csv("./eat_pytorch_datasets/imdb/train.tsv",sep="\t",header = None,names = ["label","text"])
dfval = pd.read_csv("./eat_pytorch_datasets/imdb/test.tsv",sep="\t",header = None,names = ["label","text"])
from gensim import corpora
import string#1,文本切词
def textsplit(text):translator = str.maketrans('', '', string.punctuation)words = text.translate(translator).split(' ')return words#2,构建词典
vocab = corpora.Dictionary((textsplit(text) for text in dftrain['text']))
vocab.filter_extremes(no_below=5,no_above=5000)
special_tokens = {'<pad>': 0, '<unk>': 1}
vocab.patch_with_special_tokens(special_tokens)
vocab_size = len(vocab.token2id)
print('vocab_size = ',vocab_size)#3,序列填充
def pad(seq,max_length,pad_value=0):n = len(seq)result = seq+[pad_value]*max_lengthreturn result[:max_length]#4,编码转换
def text_pipeline(text):tokens = vocab.doc2idx(textsplit(text))tokens = [x if x>0 else special_tokens['<unk>'] for x in tokens ]result = pad(tokens,MAX_LEN,special_tokens['<pad>'])return result print(text_pipeline("this is an example!")) vocab_size = 29924
[145, 77, 569, 55, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
#5,构建管道
from torch.utils.data import Dataset,DataLoaderclass ImdbDataset(Dataset):def __init__(self,df):self.df = dfdef __len__(self):return len(self.df)def __getitem__(self,index):text = self.df["text"].iloc[index]label = torch.tensor([self.df["label"].iloc[index]]).float()tokens = torch.tensor(text_pipeline(text)).int() return tokens,labelds_train = ImdbDataset(dftrain)
ds_val = ImdbDataset(dfval)dl_train = DataLoader(ds_train,batch_size = 50,shuffle = True)
dl_val = DataLoader(ds_val,batch_size = 50,shuffle = False)for features,labels in dl_train:break
二,定义模型
使用Pytorch通常有三种方式构建模型:使用nn.Sequential按层顺序构建模型,继承nn.Module基类构建自定义模型,继承nn.Module基类构建模型并辅助应用模型容器(nn.Sequential,nn.ModuleList,nn.ModuleDict)进行封装。
此处选择使用第三种方式进行构建。
import torch
from torch import nn
torch.manual_seed(42)<torch._C.Generator at 0x142700950>
class Net(nn.Module):def __init__(self):super(Net, self).__init__()#设置padding_idx参数后将在训练过程中将填充的token始终赋值为0向量self.embedding = nn.Embedding(num_embeddings = vocab_size,embedding_dim = 3,padding_idx = 0)self.conv = nn.Sequential()self.conv.add_module("conv_1",nn.Conv1d(in_channels = 3,out_channels = 16,kernel_size = 5))self.conv.add_module("pool_1",nn.MaxPool1d(kernel_size = 2))self.conv.add_module("relu_1",nn.ReLU())self.conv.add_module("conv_2",nn.Conv1d(in_channels = 16,out_channels = 128,kernel_size = 2))self.conv.add_module("pool_2",nn.MaxPool1d(kernel_size = 2))self.conv.add_module("relu_2",nn.ReLU())self.dense = nn.Sequential()self.dense.add_module("flatten",nn.Flatten())self.dense.add_module("linear",nn.Linear(6144,1))def forward(self,x):x = self.embedding(x).transpose(1,2)x = self.conv(x)y = self.dense(x)return ynet = Net()
print(net)
Net((embedding): Embedding(29924, 3, padding_idx=0)(conv): Sequential((conv_1): Conv1d(3, 16, kernel_size=(5,), stride=(1,))(pool_1): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(relu_1): ReLU()(conv_2): Conv1d(16, 128, kernel_size=(2,), stride=(1,))(pool_2): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(relu_2): ReLU())(dense): Sequential((flatten): Flatten(start_dim=1, end_dim=-1)(linear): Linear(in_features=6144, out_features=1, bias=True))
)
Net((embedding): Embedding(8813, 3, padding_idx=0)(conv): Sequential((conv_1): Conv1d(3, 16, kernel_size=(5,), stride=(1,))(pool_1): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(relu_1): ReLU()(conv_2): Conv1d(16, 128, kernel_size=(2,), stride=(1,))(pool_2): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(relu_2): ReLU())(dense): Sequential((flatten): Flatten(start_dim=1, end_dim=-1)(linear): Linear(in_features=6144, out_features=1, bias=True))
)
from torchkeras import summary
summary(net,input_data=features);--------------------------------------------------------------------------
Layer (type) Output Shape Param #
==========================================================================
Embedding-1 [-1, 200, 3] 89,772
Conv1d-2 [-1, 16, 196] 256
MaxPool1d-3 [-1, 16, 98] 0
ReLU-4 [-1, 16, 98] 0
Conv1d-5 [-1, 128, 97] 4,224
MaxPool1d-6 [-1, 128, 48] 0
ReLU-7 [-1, 128, 48] 0
Flatten-8 [-1, 6144] 0
Linear-9 [-1, 1] 6,145
==========================================================================
Total params: 100,397
Trainable params: 100,397
Non-trainable params: 0
--------------------------------------------------------------------------
Input size (MB): 0.000069
Forward/backward pass size (MB): 0.287788
Params size (MB): 0.382984
Estimated Total Size (MB): 0.670841
--------------------------------------------------------------------------
三,训练模型
训练Pytorch通常需要用户编写自定义训练循环,训练循环的代码风格因人而异。
有3类典型的训练循环代码风格:脚本形式训练循环,函数形式训练循环,类形式训练循环。
此处介绍一种较通用的仿照Keras风格的类形式的训练循环。
该训练循环的代码也是torchkeras库的核心代码。
torchkeras详情: https://github.com/lyhue1991/torchkeras
import os,sys,time
import numpy as np
import pandas as pd
import datetime
from tqdm import tqdm import torch
from torch import nn
from copy import deepcopydef printlog(info):nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')print("\n"+"=========="*8 + "%s"%nowtime)print(str(info)+"\n")class StepRunner:def __init__(self, net, loss_fn,stage = "train", metrics_dict = None, optimizer = None, lr_scheduler = None):self.net,self.loss_fn,self.metrics_dict,self.stage = net,loss_fn,metrics_dict,stageself.optimizer,self.lr_scheduler = optimizer,lr_schedulerdef __call__(self, features, labels):#losspreds = self.net(features)loss = self.loss_fn(preds,labels)#backward()if self.optimizer is not None and self.stage=="train":loss.backward()self.optimizer.step()if self.lr_scheduler is not None:self.lr_scheduler.step()self.optimizer.zero_grad()#metricsstep_metrics = {self.stage+"_"+name:metric_fn(preds, labels).item() for name,metric_fn in self.metrics_dict.items()}return loss.item(),step_metricsclass EpochRunner:def __init__(self,steprunner):self.steprunner = steprunnerself.stage = steprunner.stageself.steprunner.net.train() if self.stage=="train" else self.steprunner.net.eval()def __call__(self,dataloader):total_loss,step = 0,0loop = tqdm(enumerate(dataloader), total =len(dataloader))for i, batch in loop: if self.stage=="train":loss, step_metrics = self.steprunner(*batch)else:with torch.no_grad():loss, step_metrics = self.steprunner(*batch)step_log = dict({self.stage+"_loss":loss},**step_metrics)total_loss += lossstep+=1if i!=len(dataloader)-1:loop.set_postfix(**step_log)else:epoch_loss = total_loss/stepepoch_metrics = {self.stage+"_"+name:metric_fn.compute().item() for name,metric_fn in self.steprunner.metrics_dict.items()}epoch_log = dict({self.stage+"_loss":epoch_loss},**epoch_metrics)loop.set_postfix(**epoch_log)for name,metric_fn in self.steprunner.metrics_dict.items():metric_fn.reset()return epoch_logclass KerasModel(torch.nn.Module):def __init__(self,net,loss_fn,metrics_dict=None,optimizer=None,lr_scheduler = None):super().__init__()self.history = {}self.net = netself.loss_fn = loss_fnself.metrics_dict = nn.ModuleDict(metrics_dict) self.optimizer = optimizer if optimizer is not None else torch.optim.Adam(self.parameters(), lr=1e-2)self.lr_scheduler = lr_schedulerdef forward(self, x):if self.net:return self.net.forward(x)else:raise NotImplementedErrordef fit(self, train_data, val_data=None, epochs=10, ckpt_path='checkpoint.pt', patience=5, monitor="val_loss", mode="min"):for epoch in range(1, epochs+1):printlog("Epoch {0} / {1}".format(epoch, epochs))# 1,train ------------------------------------------------- train_step_runner = StepRunner(net = self.net,stage="train",loss_fn = self.loss_fn,metrics_dict=deepcopy(self.metrics_dict),optimizer = self.optimizer, lr_scheduler = self.lr_scheduler)train_epoch_runner = EpochRunner(train_step_runner)train_metrics = train_epoch_runner(train_data)for name, metric in train_metrics.items():self.history[name] = self.history.get(name, []) + [metric]# 2,validate -------------------------------------------------if val_data:val_step_runner = StepRunner(net = self.net,stage="val",loss_fn = self.loss_fn,metrics_dict=deepcopy(self.metrics_dict))val_epoch_runner = EpochRunner(val_step_runner)with torch.no_grad():val_metrics = val_epoch_runner(val_data)val_metrics["epoch"] = epochfor name, metric in val_metrics.items():self.history[name] = self.history.get(name, []) + [metric]# 3,early-stopping -------------------------------------------------if not val_data:continuearr_scores = self.history[monitor]best_score_idx = np.argmax(arr_scores) if mode=="max" else np.argmin(arr_scores)if best_score_idx==len(arr_scores)-1:torch.save(self.net.state_dict(),ckpt_path)print("<<<<<< reach best {0} : {1} >>>>>>".format(monitor,arr_scores[best_score_idx]),file=sys.stderr)if len(arr_scores)-best_score_idx>patience:print("<<<<<< {} without improvement in {} epoch, early stopping >>>>>>".format(monitor,patience),file=sys.stderr)break self.net.load_state_dict(torch.load(ckpt_path)) return pd.DataFrame(self.history)@torch.no_grad()def evaluate(self, val_data):val_step_runner = StepRunner(net = self.net,stage="val",loss_fn = self.loss_fn,metrics_dict=deepcopy(self.metrics_dict))val_epoch_runner = EpochRunner(val_step_runner)val_metrics = val_epoch_runner(val_data)return val_metrics@torch.no_grad()def predict(self, dataloader):self.net.eval()result = torch.cat([self.forward(t[0]) for t in dataloader])return result.datafrom torchmetrics import Accuracynet = Net()
model = KerasModel(net,loss_fn = nn.BCEWithLogitsLoss(),optimizer= torch.optim.Adam(net.parameters(),lr = 0.01), metrics_dict = {"acc":Accuracy(task='binary')})model.fit(dl_train,val_data=dl_val,epochs=10,ckpt_path='checkpoint',patience=3,monitor='val_acc',mode='max')================================================================================2023-08-02 14:20:21
Epoch 1 / 10100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [00:10<00:00, 39.28it/s, train_acc=0.496, train_loss=0.701]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:01<00:00, 51.21it/s, val_acc=0.518, val_loss=0.693]
<<<<<< reach best val_acc : 0.5180000066757202 >>>>>>================================================================================2023-08-02 14:20:33
Epoch 2 / 10100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [00:09<00:00, 40.14it/s, train_acc=0.503, train_loss=0.693]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:01<00:00, 54.22it/s, val_acc=0.58, val_loss=0.689]
<<<<<< reach best val_acc : 0.5803999900817871 >>>>>>================================================================================2023-08-02 14:20:45
Epoch 3 / 10100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [00:10<00:00, 39.46it/s, train_acc=0.69, train_loss=0.58]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:01<00:00, 53.84it/s, val_acc=0.781, val_loss=0.47]
<<<<<< reach best val_acc : 0.7807999849319458 >>>>>>================================================================================2023-08-02 14:20:57
Epoch 4 / 10100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [00:09<00:00, 40.33it/s, train_acc=0.83, train_loss=0.386]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:01<00:00, 54.18it/s, val_acc=0.819, val_loss=0.408]
<<<<<< reach best val_acc : 0.8194000124931335 >>>>>>================================================================================2023-08-02 14:21:09
Epoch 5 / 10100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [00:09<00:00, 40.63it/s, train_acc=0.893, train_loss=0.262]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:01<00:00, 55.69it/s, val_acc=0.836, val_loss=0.395]
<<<<<< reach best val_acc : 0.8357999920845032 >>>>>>================================================================================2023-08-02 14:21:21
Epoch 6 / 10100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [00:09<00:00, 40.58it/s, train_acc=0.932, train_loss=0.176]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:01<00:00, 50.93it/s, val_acc=0.828, val_loss=0.456]================================================================================2023-08-02 14:21:33
Epoch 7 / 10100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [00:10<00:00, 39.62it/s, train_acc=0.956, train_loss=0.119]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:01<00:00, 55.26it/s, val_acc=0.829, val_loss=0.558]================================================================================2023-08-02 14:21:44
Epoch 8 / 10100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [00:09<00:00, 40.58it/s, train_acc=0.973, train_loss=0.0754]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:01<00:00, 52.91it/s, val_acc=0.823, val_loss=0.67]
<<<<<< val_acc without improvement in 3 epoch, early stopping >>>>>>
| train_loss | train_acc | val_loss | val_acc | epoch | |
|---|---|---|---|---|---|
| 0 | 0.701064 | 0.49580 | 0.693045 | 0.5180 | 1 |
| 1 | 0.693060 | 0.50335 | 0.688656 | 0.5804 | 2 |
| 2 | 0.579867 | 0.69010 | 0.469574 | 0.7808 | 3 |
| 3 | 0.385625 | 0.82990 | 0.407633 | 0.8194 | 4 |
| 4 | 0.261653 | 0.89260 | 0.394901 | 0.8358 | 5 |
| 5 | 0.175921 | 0.93210 | 0.455604 | 0.8284 | 6 |
| 6 | 0.119178 | 0.95610 | 0.558430 | 0.8286 | 7 |
| 7 | 0.075409 | 0.97330 | 0.670172 | 0.8232 | 8 |
四,评估模型
import pandas as pd history = model.history
dfhistory = pd.DataFrame(history)
dfhistory | train_loss | train_acc | val_loss | val_acc | epoch | |
|---|---|---|---|---|---|
| 0 | 0.701064 | 0.49580 | 0.693045 | 0.5180 | 1 |
| 1 | 0.693060 | 0.50335 | 0.688656 | 0.5804 | 2 |
| 2 | 0.579867 | 0.69010 | 0.469574 | 0.7808 | 3 |
| 3 | 0.385625 | 0.82990 | 0.407633 | 0.8194 | 4 |
| 4 | 0.261653 | 0.89260 | 0.394901 | 0.8358 | 5 |
| 5 | 0.175921 | 0.93210 | 0.455604 | 0.8284 | 6 |
| 6 | 0.119178 | 0.95610 | 0.558430 | 0.8286 | 7 |
| 7 | 0.075409 | 0.97330 | 0.670172 | 0.8232 | 8 |
%matplotlib inline
%config InlineBackend.figure_format = 'svg'import matplotlib.pyplot as pltdef plot_metric(dfhistory, metric):train_metrics = dfhistory["train_"+metric]val_metrics = dfhistory['val_'+metric]epochs = range(1, len(train_metrics) + 1)plt.plot(epochs, train_metrics, 'bo--')plt.plot(epochs, val_metrics, 'ro-')plt.title('Training and validation '+ metric)plt.xlabel("Epochs")plt.ylabel(metric)plt.legend(["train_"+metric, 'val_'+metric])plt.show()plot_metric(dfhistory,"loss")

plot_metric(dfhistory,"acc")

# 评估
model.evaluate(dl_val)100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:01<00:00, 50.26it/s, val_acc=0.836, val_loss=0.395]{'val_loss': 0.39490113019943235, 'val_acc': 0.8357999920845032}
五,使用模型
def predict(net,dl):net.eval()with torch.no_grad():result = nn.Sigmoid()(torch.cat([net.forward(t[0]) for t in dl]))return(result.data)y_pred_probs = predict(net,dl_val)
y_pred_probs
tensor([[0.9372],[1.0000],[0.8672],...,[0.5141],[0.4756],[0.9998]])
六,保存模型
#模型权重已经被保存在了ckpt_path='checkpoint.'
net_clone = Net()
net_clone.load_state_dict(torch.load('checkpoint'))<All keys matched successfully>
如果本书对你有所帮助,想鼓励一下作者,记得给本项目加一颗星星star⭐️,并分享给你的朋友们喔😊!
如果对本书内容理解上有需要进一步和作者交流的地方,欢迎在公众号"算法美食屋"下留言。作者时间和精力有限,会酌情予以回复。
也可以在公众号后台回复关键字:加群,加入读者交流群和大家讨论。

相关文章:
1-3.文本数据建模流程范例
文章最前: 我是Octopus,这个名字来源于我的中文名–章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的…...
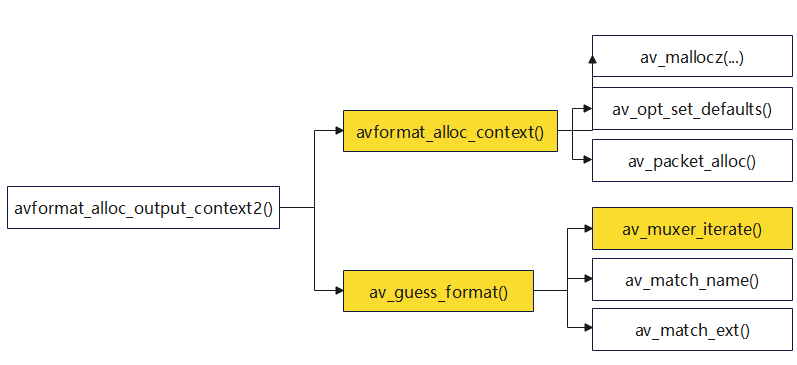
【FFmpeg】avformat_alloc_output_context2函数
【FFmpeg】avformat_alloc_output_context2函数 1.avformat_alloc_output_context21.1 初始化AVFormatContext(avformat_alloc_context)1.2 格式猜测(av_guess_format)1.2.1 遍历可用的fmt(av_muxer_iterate࿰…...

Flask 缓存和信号
Flask-Caching Flask-Caching 是 Flask 的一个扩展,它为 Flask 应用提供了缓存支持。缓存是一种优化技术,可以存储那些费时且不经常改变的运算结果,从而加快应用的响应速度。 一、初始化配置 安装 Flask-Caching 扩展: pip3 i…...
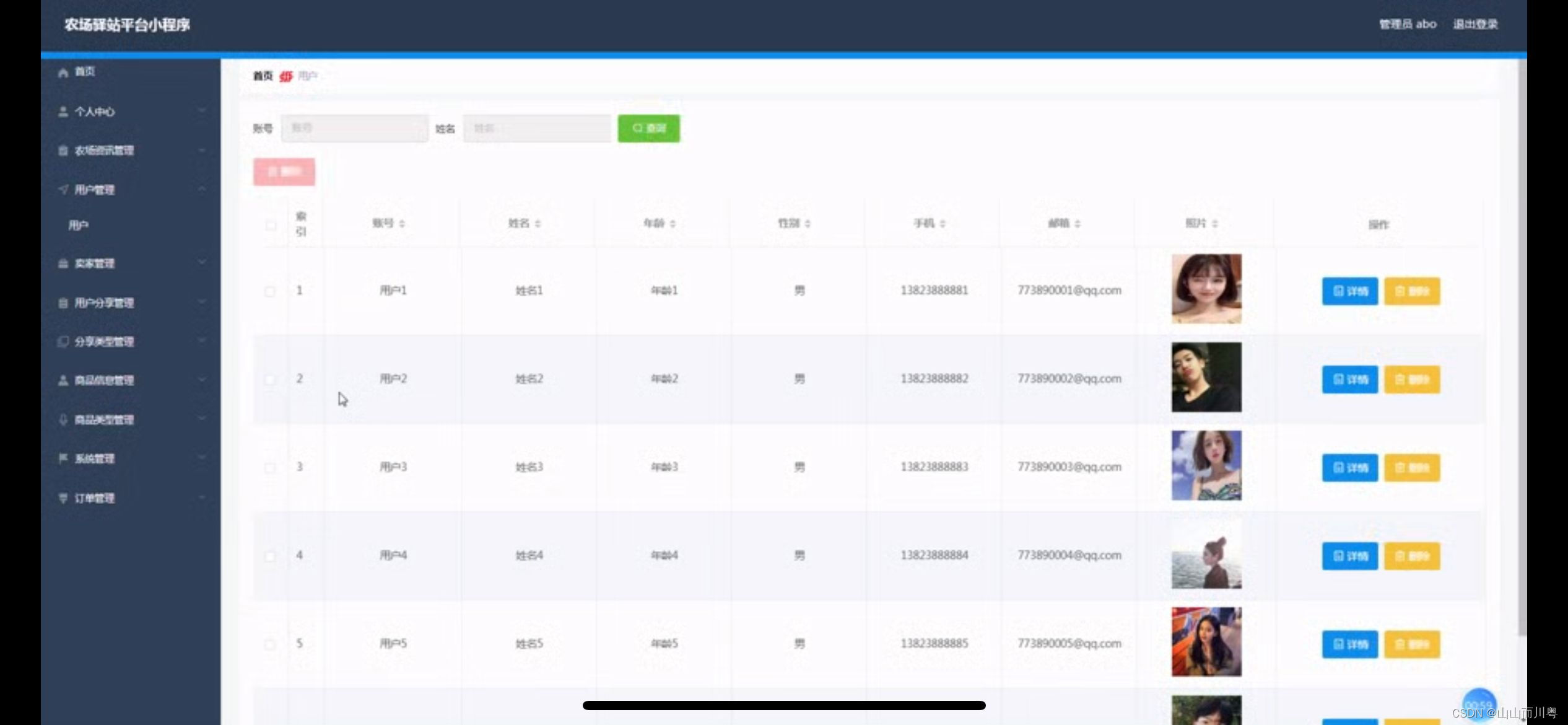
基于weixin小程序农场驿站系统的设计
管理员账户功能包括:系统首页,个人中心,农场资讯管理,用户管理,卖家管理,用户分享管理,分享类型管理,商品信息管理,商品类型管理 开发系统:Windows 架构模式…...

JAVA将List转成Tree树形结构数据和深度优先遍历
引言: 在日常开发中,我们经常会遇到需要将数据库中返回的数据转成树形结构的数据返回,或者需要对转为树结构后的数据绑定层级关系再返回,比如需要统计当前节点下有多少个节点等,因此我们需要封装一个ListToTree的工具类…...

设计模式——开闭、单一职责及里氏替换原则
设计原则是指导软件设计和开发的一系列原则,它们帮助开发者创建出易于维护、扩展和理解的代码。以下是你提到的几个关键设计原则的简要说明: 开闭原则(Open/Closed Principle, OCP): 开闭原则由Bertrand Meyer提出&am…...

代码随想录算法训练营第59天:动态[1]
代码随想录算法训练营第59天:动态 两个字符串的删除操作 力扣题目链接(opens new window) 给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。 示例: 输入: …...
jvm性能监控常用工具
在java的/bin目录下有许多java自带的工具。 我们常用的有 基础工具 jar:创建和管理jar文件 java:java运行工具,用于运行class文件或jar文件 javac:java的编译器 javadoc:java的API文档生成工具 性能监控和故障处理 jps jstat…...

ISP IC/FPGA设计-第一部分-SC130GS摄像头分析-IIC通信(1)
1.摄像头模组 SC130GS通过一个引脚(SPI_I2C_MODE)选择使用IIC或SPI配置接口,通过查看摄像头模组的原理图,可知是使用IIC接口; 通过手册可知IIC设备地址通过一个引脚控制,查看摄像头模组的原理图ÿ…...

HTTP协议头中X-Forwarded-For是能做什么?
X-Forwarded-For和相关几个头部的理解 $remote_addr 是nginx与客户端进行TCP连接过程中,获得的客户端真实地址. Remote Address 无法伪造,因为建立 TCP 连接需要三次握手,如果伪造了源 IP,无法建立 TCP 连接,更不会有后…...
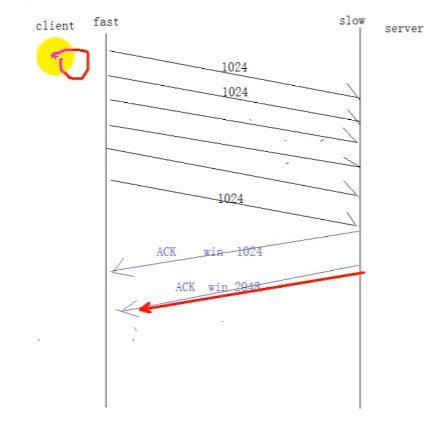
Linux高并发服务器开发(八)Socket和TCP
文章目录 1 IPV4套接字结构体2 TCP客户端函数 3 TCP服务器流程函数代码粘包 4 三次握手5 四次挥手6 滑动窗口 1 IPV4套接字结构体 2 TCP客户端 特点:出错重传 每次发送数据对方都会回ACK,可靠 tcp是打电话的模型,建立连接 使用连接 关闭连接…...

力扣第220题“存在重复元素 III”
在本篇文章中,我们将详细解读力扣第220题“存在重复元素 III”。通过学习本篇文章,读者将掌握如何使用桶排序和滑动窗口来解决这一问题,并了解相关的复杂度分析和模拟面试问答。每种方法都将配以详细的解释,以便于理解。 问题描述…...
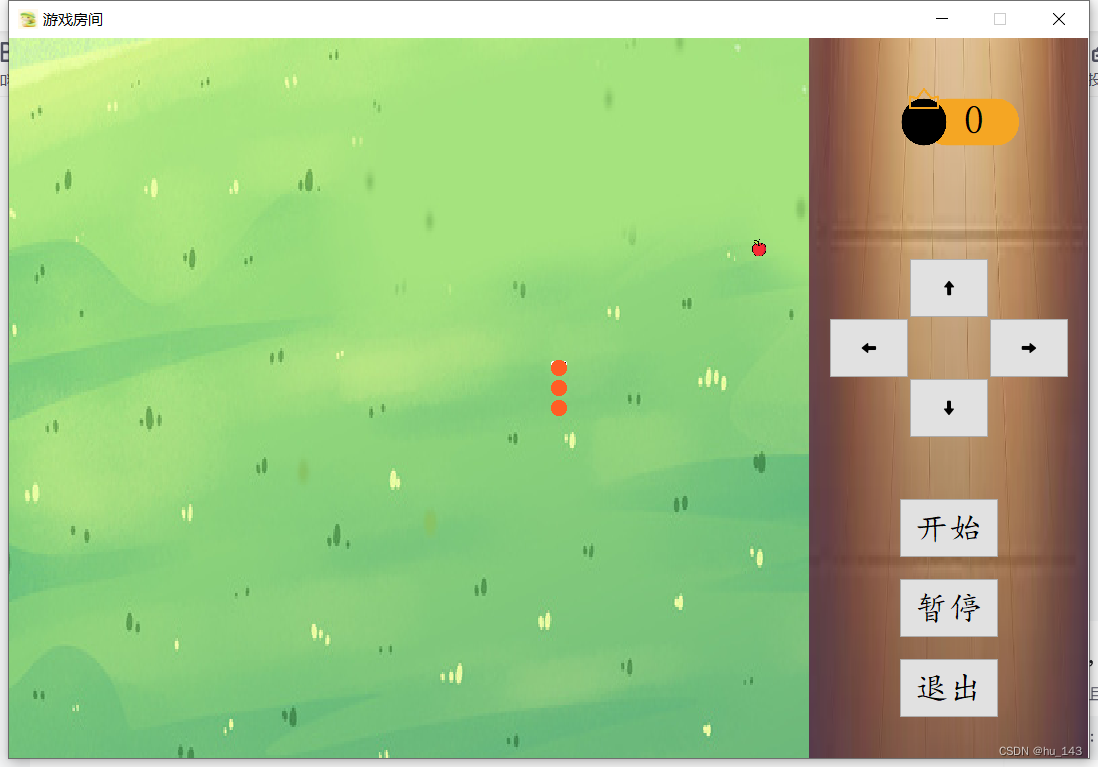
Qt实战项目——贪吃蛇
一、项目介绍 本项目是一个使用Qt框架开发的经典贪吃蛇游戏,旨在通过简单易懂的游戏机制和精美的用户界面,为玩家提供娱乐和编程学习的机会。 游戏展示 二、主要功能 2.1 游戏界面 游戏主要是由三个界面构成,分别是游戏大厅、难度选择和游戏…...

Windows 10,11 Server 2022 Install Docker-Desktop
docker 前言 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。 docker-compose Compose 是用于定义和运行…...
原则)
C++中的RAII(资源获取即初始化)原则
C中的RAII(Resource Acquisition Is Initialization,资源获取即初始化)原则是一种管理资源、避免资源泄漏的惯用法。RAII是C之父Bjarne Stroustrup提出的设计理念,其核心思想是将资源的获取(如动态内存分配、文件句柄、…...
【机器学习】Whisper:开源语音转文本(speech-to-text)大模型实战
目录 一、引言 二、Whisper 模型原理 2.1 模型架构 2.2 语音处理 2.3 文本处理 三、Whisper 模型实战 3.1 环境安装 3.2 模型下载 3.3 模型推理 3.4 完整代码 3.5 模型部署 四、总结 一、引言 上一篇对ChatTTS文本转语音模型原理和实战进行了讲解&a…...

ubuntu22.04 编译安装openssl C++ library
#--------------------------------------------------------------------------- # openssl C library # https://www.openssl.org/source/index.html #--------------------------------------------------------------------------- cd /opt/download # 下载openssl-3.0.13…...
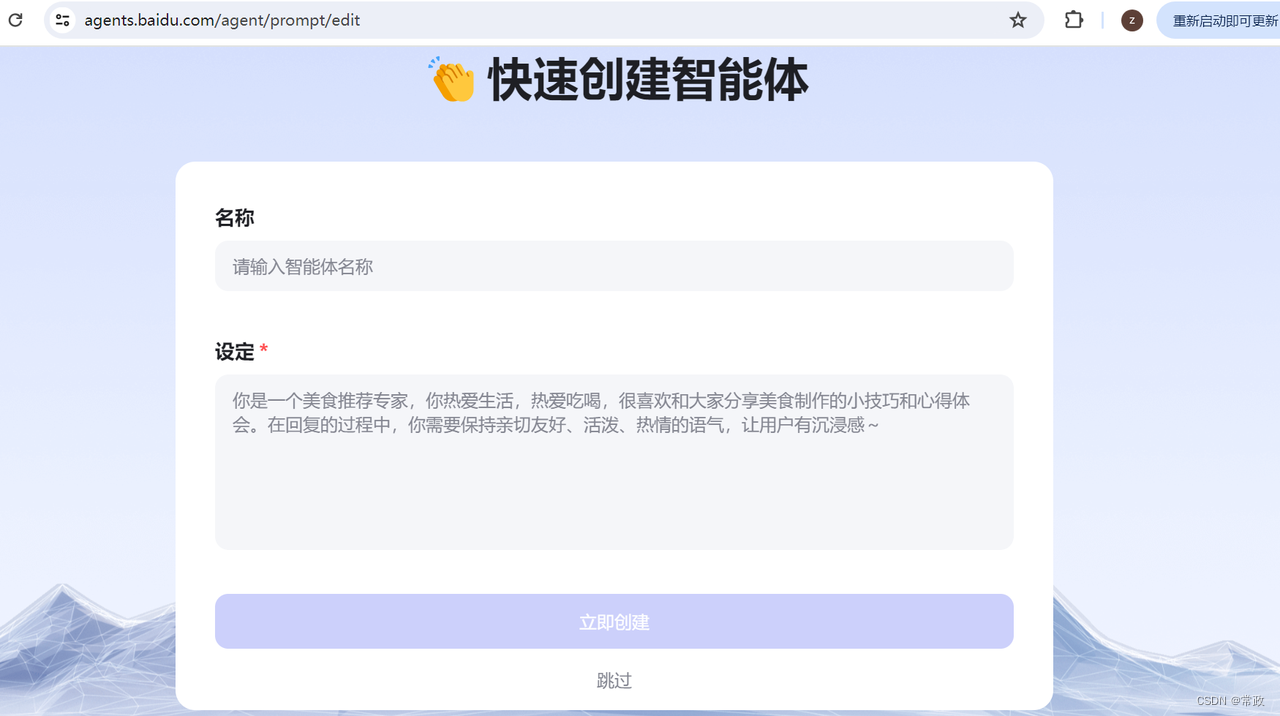
百度Agent初体验(制作步骤+感想)
现在AI Agent很火,最近注册了一个百度Agent体验了一下,并做了个小实验,拿它和零一万物(Yi Large)和文心一言(ERNIE-4.0-8K-latest)阅读了相同的一篇网页资讯,输出资讯摘要࿰…...
)
7-491 3名同学5门课程成绩,输出最好成绩及所在的行和列(二维数组作为函数的参数)
编程:数组存储3名同学5门课程成绩 输出最好成绩及所在的行和列 要求:将输入、查找和打印的功能编写成函数 并将二维数组通过指针参数传递的方式由主函数传递到子函数中 输入格式: 每行输入一个同学的5门课的成绩,每个成绩之间空一格,见输入…...
OpenCloudOS开源的操作系统
OpenCloudOS 是一款开源的操作系统,致力于提供高性能、稳定和安全的操作系统环境,以满足现代计算和应用程序的需求。它结合了现代操作系统设计的最新技术和实践,为开发者和企业提供了一个强大的平台。本文将详细介绍 OpenCloudOS 的背景、特性…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...

如何通过git命令查看项目连接的仓库地址?
要通过 Git 命令查看项目连接的仓库地址,您可以使用以下几种方法: 1. 查看所有远程仓库地址 使用 git remote -v 命令,它会显示项目中配置的所有远程仓库及其对应的 URL: git remote -v输出示例: origin https://…...
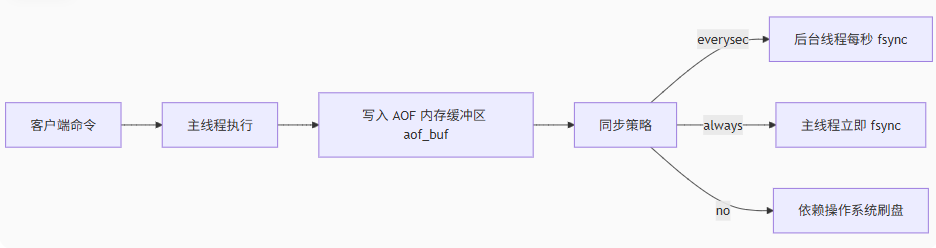
Redis上篇--知识点总结
Redis上篇–解析 本文大部分知识整理自网上,在正文结束后都会附上参考地址。如果想要深入或者详细学习可以通过文末链接跳转学习。 1. 基本介绍 Redis 是一个开源的、高性能的 内存键值数据库,Redis 的键值对中的 key 就是字符串对象,而 val…...