【JVM基础篇】垃圾回收
文章目录
- 垃圾回收
- 常见内存管理方式
- 手动回收:C++内存管理
- 自动回收(GC):Java内存管理
- 自动、手动回收优缺点
- 应用场景
- 垃圾回收器需要对哪些部分内存进行回收?
- 不需要垃圾回收器回收
- 需要垃圾回收器回收
- 方法区的回收
- 代码测试
- 手动调用垃圾回收方法`System.gc()`
- 代码运行
- 思考
- 堆回收
- 如何判断堆的对象是否可以回收
- 案例介绍
- 引用计数法(JVM不使用)
- 优缺点
- 验证JVM没有使用引用计数法
- 可达性分析法(JVM使用)
- 四类GC Root对象
- 查看GC Root对象的工具
- 常见的五种引用对象
- 软引用
- 软引用的使用方法
- 软引用对象本身怎么回收呢?
- 工作场景:软引用的缓存案例
- 弱引用(一般不使用)
- 虚引用和终结器引用(常规开发不使用)
- 垃圾回收算法
- 垃圾回收算法的历史和分类
- 垃圾回收算法的评价标准
- 标记清除算法
- 优缺点
- 复制算法
- 优缺点
- 标记整理算法(标记压缩算法)
- 优缺点
- 分代垃圾回收算法(常用)
- JVM参数设置
- 使用Arthas查看内存分区
- 垃圾回收执行流程
- 分代GC算法内存为什么分年轻代、老年代
- 垃圾回收器(垃圾回收算法实现)
- Arthas查看所使用的垃圾回收器
- 年轻代-Serial垃圾回收器
- **回收年代和算法**
- **优点**
- **缺点**
- **适用场景**
- 如何使用
- 老年代-SerialOld垃圾回收器
- **回收年代和算法**
- **优点**
- **缺点**
- **适用场景**
- 如何使用
- 年轻代-ParNew垃圾回收器
- **回收年代和算法:**
- **优点**
- **缺点**
- **适用场景**
- 如何使用
- 老年代-CMS(Concurrent Mark Sweep)垃圾回收器
- **回收年代和算法**
- **优点**
- **缺点**
- **适用场景**
- 使用
- CMS执行步骤
- 年轻代-Parallel Scavenge垃圾回收器
- **回收年代和算法**
- **优点**
- **缺点**
- **适用场景**
- **常用参数**
- 老年代-Parallel Old垃圾回收器
- **回收年代和算法**
- **优点**
- **缺点**
- **适用场景**
- 如何使用
- 测试
- G1(Garbage First)垃圾回收器(极力推荐)
- G1垃圾回收有两种方式
- 年轻代回收(Young GC)
- 混合回收(Mixed GC)
- 如何使用G1垃圾回收器
- **回收年代和算法**
- **优点**
- **缺点**
- 测试
- 垃圾回收器总结
- 几个问题
- 文章说明
垃圾回收

- 字节码文件通过类加载器,将类的信息加载到运行时数据区的方法区中
- 接下来执行引擎的解释器开始解释执行字节码信息的字节码指令,将对象创建出来,放到运行时数据区的堆上
- 在堆上的对象,后面不再使用之后,垃圾回收器会将这些对象进行销毁(自动垃圾回收)
常见内存管理方式
手动回收:C++内存管理
- 在C/C++这类没有自动垃圾回收机制的语言中,一个对象如果不再使用,需要手动释放,否则就会出现内存泄漏。
- 内存泄漏:不再使用的对象在系统中未被回收,内存泄漏的积累可能会导致内存溢出。
【模拟内存溢出】
在这段代码中,通过死循环不停创建Test类的对象,每一轮循环结束之后,这次创建的对象就不再使用了。但是没有手动调用删除对象的方法,此时对象就会出现内存泄漏。

这段代码中,手动调用delete删除对象,就不会出现内存泄漏。

我们称这种释放对象的过程为垃圾回收,而需要程序员编写代码进行回收的方式为手动回收。
自动回收(GC):Java内存管理
Java中为了简化对象的释放,引入了自动的垃圾回收(Garbage Collection简称GC)机制。通过垃圾回收器来对不再使用的对象完成自动的回收,垃圾回收器主要负责对堆上的内存进行回收。其他很多现代语言比如C#、Python、Go都拥有自己的垃圾回收器。
垃圾回收器如果发现某个对象不再使用,就可以回收该对象。

自动、手动回收优缺点
- 自动垃圾回收,自动根据对象是否使用由虚拟机来回收对象
- 优点:降低程序员实现难度、降低对象回收bug的可能性
- 缺点:程序员无法控制内存回收的及时性,对象不用之后,不会及时被清理掉,需要等待垃圾回收器工作,有一定的滞后
- 手动垃圾回收,由程序员编程实现对象的删除
- 优点:回收及时性高,由程序员把控回收的时机
- 缺点:编写不当容易出现悬空指针(对象内存被释放,但是指针没有指向null)、重复释放(delete返回执行)、内存泄漏、程序员粗心忘记释放等问题
应用场景
解决系统僵死的问题:大厂的系统出现的许多系统僵死问题,即程序在运行,但是得不到回应,这个现象与频繁的垃圾回收有关,JVM忙于垃圾回收,把用户请求晾一边性能优化:对垃圾回收器进行合理的设置可以有效地提升程序的执行性能高频面试题:- 常见的垃圾回收器
- 常见的垃圾回收算法
- 四种引用
- 项目中用了哪一种垃圾回收器
垃圾回收器需要对哪些部分内存进行回收?
不需要垃圾回收器回收
- 首先是线程不共享的部分,都是伴随着线程的创建而创建,线程的销毁而销毁(线程不再使用的时候,会将线程的内存释放)。
- Java虚拟机栈、本地方法栈中存储了方法的栈帧,方法的栈帧在执行完方法之后就会自动弹出栈并释放掉对应的内存。

需要垃圾回收器回收

方法区的回收

方法区中能回收的内容主要就是不再使用的类。判定一个类可以被卸载。需要同时满足下面三个条件:
- 此类所有实例对象都已经被回收,在堆中不存在任何该类的实例对象以及子类对象。
这段代码中就将局部变量对堆上实例对象的引用去除了,所以对象就可以被回收。

- 加载该类的类加载器已经被回收。
这段代码让局部变量对类加载器的引用去除,类加载器loader就可以被回收。

- 该类对应的 java.lang.Class 对象没有在任何地方被引用。

代码测试
package chapter04.gc;import java.net.URL;
import java.net.URLClassLoader;
import java.util.ArrayList;/*** 类的卸载*/
public class ClassUnload {public static void main(String[] args) throws InterruptedException {try {ArrayList<Class<?>> classes = new ArrayList<>();ArrayList<URLClassLoader> loaders = new ArrayList<>();ArrayList<Object> objs = new ArrayList<>();while (true) {URLClassLoader loader = new URLClassLoader(new URL[]{new URL("file:D:\\lib\\")});Class<?> clazz = loader.loadClass("com.itheima.my.A");Object o = clazz.newInstance();// objs.add(o);
// classes.add(clazz);
// loaders.add(loader);System.gc();}} catch (Exception e) {e.printStackTrace();}}
}
添加这两个虚拟机参数进行测试:
-XX:+TraceClassLoading -XX:+TraceClassUnloading
-XX:+TraceClassLoading:程序运行过程中,打印出类的加载
-XX:+TraceClassUnloading:类被卸载的时候,会打印出日志

如果注释掉代码中三句add调用,就可以同时满足3个条件。
手动调用垃圾回收方法System.gc()
注意:调用System.gc()方法并不一定会立即回收垃圾,仅仅是向Java虚拟机发送一个垃圾回收的请求,具体是否需要执行垃圾回收Java虚拟机会自行判断。
代码运行
执行之后,日志中就会打印出类卸载的内容:
- Unloading:类被卸载
- 三个条件都存在,加载之后会被回收

【第一个条件不满足】

运行之后,发现没有卸载

【还可以模拟其他条件】

当其他条件没有满足的时候,一样不触发类的卸载
思考
我们所写的类是由应用程序加载器加载的,这个加载器是不会被回收的,所以一直不会满足条件二,那么类卸载主要用在什么场景下呢?
- 开发中此类场景一般很少出现,主要在如 OSGi、JSP 的热部署等应用场景中。
- 每个jsp文件对应一个唯一的类加载器,当一个jsp文件修改了,就直接卸载这个jsp类加载器。重新创建类加载器,重新加载jsp文件。
**注:**方法区的回收我们很难用到,了解一下即可
堆回收
堆是java程序中最大的一部分内存,里面有很多对象
如何判断堆的对象是否可以回收
- 垃圾回收器要回收对象的第一步就是判断哪些对象可以回收。
- Java中的对象是否能被回收,是根据对象是否被引用来决定的。如果对象被引用了,说明该对象还在使用,不允许被回收。
案例介绍
【简单案例】
第一行代码执行之后,堆上创建了Demo类的实例对象,同时栈上保存局部变量引用堆上的对象。

第二行代码执行之后,局部变量对堆上的对象引用去掉,引用关系失效,那么堆上的对象就可以被回收了。

【复杂案例】

这个案例中,如果要让对象a和b回收,必须将局部变量到堆上的引用去除。
- 直接找A的引用需要去除,即a1 = null
- 通过B找A的引用也需要去除,即b1.a = null

如果a1 = null;b1 = null;这样可以回收A和B对象吗?
答:可以,虽然a1.b = b1; 但是a1都为null了,就找不到b1了。A和B互相之间的引用需要去除吗?答案是不需要,因为局部变量都没引用这两个对象了,在代码中已经无法访问这两个对象,即便他们之间互相有引用关系,也不影响对象的回收。

判断对象是否可以回收,主要有两种方式:
- 引用计数法
- 可达性分析法。
引用计数法(JVM不使用)
引用计数法会为每个对象维护一个引用计数器(初始值为0),当对象被引用时加1,取消引用时减1。如下图中,对象A的计数器初始为0,局部变量a1对它引用之后,计数器就变成了1。同样A对B产生了引用,B的计数器也是1。

如果把A对B的引用去除,则变为下图

即如果一个对象的引用计数器是0,说明这个对象没有引用,就可以被垃圾回收了。
优缺点
优点:
- 实现简单,C++中的智能指针就采用了引用计数法
缺点:
- 每次引用和取消引用都需要维护计数器,对系统性能会有一定的影响
- 存在循环引用问题,所谓循环引用就是当A引用B,B同时引用A时会出现对象无法回收的问题,导致内存泄漏。
这张图上,由于A和B之间存在互相引用,所以计数器都为1,两个对象都不能被回收。但是由于没有局部变量对这两个代码产生引用,代码中已经无法访问到这两个对象,理应可以被回收。

验证JVM没有使用引用计数法
可以做一个实验,验证下Java中循环引用不会导致内存泄漏,如果不会泄露,说明JVM没有使用引用计数法。
可以通过垃圾回收日志去看一个对象有没有被回收,如果想查看垃圾回收的信息,可以添加虚拟机参数:-verbose:gc。

【代码】
public static void main(String[] args) throws IOException {while (true){A a1 = new A();B b1 = new B();a1.b = b1;|b1.a = a1;a1 = null;b1 = null;System.gc();}
}
【运行】
加上这个参数之后执行代码,发现对象确实被回收了,因为内存大小始终差不多,一直维持在1000K,说明每轮循环创建的两个对象在垃圾回收之后都被回收了。如果没有回收的话,随着循环的进行,每次new A和new B,占用的内存会越来越大。说明JVM没有使用引用计数法

可达性分析法(JVM使用)
Java使用的是可达性分析算法来判断对象是否可以被回收。可达性分析将对象分为两类:
- 垃圾回收的根对象(GC Root)
- 普通对象
根对象和普通对象之间,会存在引用关系。下图中A到B再到C和D,形成了一个引用链。可达性分析算法指的是如果从某个到GC Root对象是可达的,对象就不可被回收。
- 通过对象A,可以找到对象B。通过对象B,又可以找到对象C、对象D。所以对象A、B、C、D都不可以被回收。
- 如果断掉对象A和对象B的联系,则对象B、C、D都可以回收。

四类GC Root对象
GC Root对象是不可以被回收的,**哪些对象被称之为GC Root对象呢?**满足如下四大类即是GC Root对象,否则是普通对象
第一类:线程Thread对象,它会引用线程栈帧中的方法参数、局部变量等。


第二类:系统类加载器加载的java.lang.Class对象,引用类中的静态变量。(GC Root可以关联到静态变量,所以A的实例也不能被回收)

第三类:监视器对象,用来保存同步锁synchronized关键字持有的对象。(如下图的ReferenceCouting对象不可以被回收)

第四类:本地方法调用时使用的全局对象。(虚拟机控制调用,Java程序员可以不用太关注)
查看GC Root对象的工具
通过Arthas和eclipse Memory Analyzer (MAT) 工具可以查看GC Root,MAT工具是eclipse推出的Java堆内存检测工具。具体操作步骤如下:
步骤一:使用arthas的heapdump命令将堆内存快照保存到本地磁盘中。
步骤二:使用MAT工具打开堆内存快照文件选择GC Roots功能查看所有的GC Root。

【演示步骤详解】
1、代码如下:
package com.itheima.jvm.chapter04;import java.io.IOException;public class ReferenceCounting {public static A a2 = null;public static void main(String[] args) throws IOException {
// while (true){A a1 = new A();B b1 = new B();a1.b = b1;b1.a = a1;a2 = a1;// 程序阻塞System.in.read();
// a1 = null;
// b1 = null;
// }}
}class A {B b;
// byte[] t = new byte[1024 * 1024 * 10];
}class B {A a;
// byte[] t = new byte[1024 * 1024 * 10];
}
2、使用arthas连接到程序,输入如下命令:
heapdump 内存快照文件输出目录/test2.hprof(文件名.hprof)

这样就生成了一个堆内存快照(后面介绍,简单来说就是包含了所有堆中的对象信息)。
3、下载MAT工具。
下载路径:https://download.csdn.net/download/laodanqiu/89495359
如果出现如下错误,请将环境变量中的JDK版本升级到17以上

4、选择菜单中的打开堆内存快照功能,并选择刚才生成的文件。

5、选择内存泄漏检测报告,并确定。


6、通过菜单找到GC Roots。

7、MAT对4类GC Root对象做了分类。


8、找到局部变量。


9、找到静态变量。
System Class下面的类太多了,可以通过复制A的内存地址来找

拿到内存地址之后,通过地址反向寻找关联它的RC Root

查询出来的结果


常见的五种引用对象
- 强引用:可达性算法中描述的对象引用,一般指的是强引用,即是GCRoot对象对普通对象有引用关系,只要这层关系存在,普通对象就不会被回收。除了强引用之外,Java中还设计了几种其他引用方式:
- 软引用
- 弱引用
- 虚引用
- 终结器引用
软引用
- 软引用相对于强引用是一种比较弱的引用关系,如果一个对象只有软引用关联到它,当程序内存不足时,就会将软引用中的数据进行回收(强引用的对象还是会保留)。
- 软引用常用于缓存中(不能用来存储重要数据,不然有被回收的风险)
- 如何实现软引用?在JDK 1.2版之后提供了SoftReference类来实现软引用。
如下图中,对象A被GC Root对象强引用了,同时我们创建了一个软引用SoftReference对象(它本身也是一个对象),软引用对象中引用了对象A。

接下来强引用被去掉之后(例如给静态变量赋值一个null),对象A暂时还是处于不可回收状态,因为有软引用存在并且内存还够用。

如果内存出现不够用的情况,对象A就处于可回收状态,可以被垃圾回收器回收。

这样做有什么好处?如果对象A是一个缓存,平时会保存在内存中,如果想访问数据可以快速访问。但是如果内存不够用了,我们就可以将这部分缓存清理掉释放内存。即便缓存没了,也可以从数据库等地方获取数据,不会影响到业务正常运行,这样可以减少内存溢出产生的可能性。
特别注意:
软引用对象本身,需要被强引用(真实环境中一定存在这个关系),否则软引用对象也会被回收掉。

软引用的使用方法

软引用的执行过程如下:
- 将对象使用软引用包装起来,new SoftReference<对象类型>(对象)。
- 内存不足时,虚拟机尝试进行垃圾回收。
- 如果垃圾回收仍不能解决内存不足的问题,回收软引用中的对象。
- 如果依然内存不足,抛出OutOfMemory异常。
代码:
/*** 软引用案例2 - 基本使用*/
public class SoftReferenceDemo2 {public static void main(String[] args) throws IOException {// 强引用byte[] bytes = new byte[1024 * 1024 * 100];// 建立软引用关系SoftReference<byte[]> softReference = new SoftReference<byte[]>(bytes);// 去除强引用bytes = null;// 打印软引用中的真实数据System.out.println(softReference.get());// 再创建一个100M的数组,内存不够用,软引用的对象要被释放掉byte[] bytes2 = new byte[1024 * 1024 * 100];// 这里打印出来的软引用的数据应该是空System.out.println(softReference.get());
//
// byte[] bytes3 = new byte[1024 * 1024 * 100];
// softReference = null;
// System.gc();
//
// System.in.read();}
}
添加虚拟机参数,限制最大堆内存大小为200m,因为堆内存中还需要放一些其他对象,所以堆内存实际上只有100多M可以使用,理论上是放不下两个100M的数组的:

执行后发现,第二个100m对象创建之后需,软引用中包含的对象已经被回收了。



软引用对象本身怎么回收呢?
如果软引用对象里边包含的数据已经被回收了,那么软引用对象本身其实也可以被回收了。
SoftReference提供了一套队列机制:
1、软引用创建时,通过构造器传入引用队列

2、在软引用中包含的对象被回收时,该软引用对象会被放入引用队列

3、通过代码遍历引用队列,将SoftReference的强引用删除
代码
/*** 软引用案例3 - 引用队列使用*/
public class SoftReferenceDemo3 {public static void main(String[] args) throws IOException {ArrayList<SoftReference> softReferences = new ArrayList<>();// 引用队列ReferenceQueue<byte[]> queues = new ReferenceQueue<byte[]>();for (int i = 0; i < 10; i++) {byte[] bytes = new byte[1024 * 1024 * 100];SoftReference studentRef = new SoftReference<byte[]>(bytes,queues);softReferences.add(studentRef);}SoftReference<byte[]> ref = null;// 被回收的软引用对象数量int count = 0;while ((ref = (SoftReference<byte[]>) queues.poll()) != null) {count++;}System.out.println(count);}
}
最终展示的结果是:

这9个软引用对象中包含的数据已经被回收掉,所以可以手动从ArrayList中去掉,这样就可以释放这9个对象。
工作场景:软引用的缓存案例
使用软引用实现学生信息的缓存,内存不足时,会清理Map里面的值存储的Student对象
注意:value回收了,key也要同步回收

代码:
import lombok.Data;import java.lang.ref.ReferenceQueue;
import java.lang.ref.SoftReference;
import java.util.HashMap;
import java.util.Map;/*** 软引用案例4 - 学生信息的缓存*/
public class StudentCache {private static StudentCache cache = new StudentCache();/*** 测试,限制堆内存,死循环,堆内存也不会溢出,因为会及时回收** @param args*/public static void main(String[] args) {for (int i = 0; ; i++) {StudentCache.getInstance().cacheStudent(new Student(i, String.valueOf(i)));}}/*** 用于Cache内容的存储*/private Map<Integer, StudentRef> StudentRefs;/*** 被回收的Reference的队列*/private ReferenceQueue<Student> q;/*** 继承SoftReference,使得每一个实例都具有可识别的标识。* 并且该标识与其在HashMap内的key相同。*/private class StudentRef extends SoftReference<Student> {/*** 根据软引用获取key,这样才能在map中删除相应的key*/private Integer _key = null;public StudentRef(Student em, ReferenceQueue<Student> q) {super(em, q);_key = em.getId();}}/*** 构建一个缓存器实例*/private StudentCache() {StudentRefs = new HashMap<Integer, StudentRef>();q = new ReferenceQueue<Student>();}/*** 取得缓存器实例** @return*/public static StudentCache getInstance() {return cache;}/*** 以软引用的方式对一个Student对象的实例进行引用并保存该引用** @param em*/private void cacheStudent(Student em) {// 清除垃圾引用,删除map的key和valuecleanCache();StudentRef ref = new StudentRef(em, q);StudentRefs.put(em.getId(), ref);System.out.println(StudentRefs.size());}/*** 依据所指定的ID号,获取相应Student对象的实例** @param id* @return*/public Student getStudent(Integer id) {Student em = null;// 缓存中是否有该Student实例的软引用,如果有,从软引用中取得。if (StudentRefs.containsKey(id)) {StudentRef ref = StudentRefs.get(id);// 获取软引用的数据em = ref.get();}// 如果没有软引用,或者从软引用中得到的实例是null,重新构建一个实例,// 并保存对这个新建实例的软引用if (em == null) {em = new Student(id, String.valueOf(id));System.out.println("Retrieve From StudentInfoCenter. ID=" + id);this.cacheStudent(em);}return em;}/*** 清除那些所软引用的Student对象已经被回收的StudentRef对象*/private void cleanCache() {StudentRef ref = null;// q里面存储的是已经被回收的软引用,不停将软引用弹出来,然后删除相应的keywhile ((ref = (StudentRef) q.poll()) != null) {StudentRefs.remove(ref._key);}}
}@Data
class Student {int id;String name;public Student(int id, String name) {this.id = id;this.name = name;}
}
弱引用(一般不使用)
弱引用的整体机制和软引用基本一致,区别在于弱引用包含的对象在垃圾回收时,不管内存够不够都会直接被回收。在JDK 1.2版之后提供了WeakReference类来实现弱引用,弱引用主要在ThreadLocal中使用。
弱引用对象本身也可以使用引用队列进行回收。
package chapter04.weak;import java.io.IOException;
import java.lang.ref.WeakReference;/*** 弱引用案例 - 基本使用*/
public class WeakReferenceDemo2 {public static void main(String[] args) throws IOException {byte[] bytes = new byte[1024 * 1024 * 100];WeakReference<byte[]> weakReference = new WeakReference<byte[]>(bytes);bytes = null;System.out.println(weakReference.get());System.gc();System.out.println(weakReference.get());}
}
执行之后发现gc执行之后,对象已经被回收了。

虚引用和终结器引用(常规开发不使用)
这两种引用在常规开发中是不会使用的。
- 虚引用也叫幽灵引用/幻影引用,不能通过虚引用对象获取到包含的对象。虚引用唯一的用途是当对象被垃圾回收器回收时可以接收到对应的通知。Java中使用PhantomReference实现了虚引用,直接内存中为了及时知道直接内存对象不再使用,从而回收内存,使用了虚引用来实现。

- 终结器引用指的是在对象需要被回收时,终结器引用会关联对象并放置在Finalizer类中的引用队列中,在稍后由一条由FinalizerThread线程从队列中获取对象,然后执行对象的finalize方法,在对象第二次被回收时,该对象才真正的被回收。在这个过程中可以在finalize方法中再将自身对象使用强引用关联上,但是不建议这样做。
下面的代码仅仅是为了面试,工作中不会写出这种代码
package chapter04.finalreference;/*** 终结器引用案例*/
public class FinalizeReferenceDemo {public static FinalizeReferenceDemo reference = null;public void alive() {System.out.println("当前对象还存活");}@Overrideprotected void finalize() throws Throwable {try{System.out.println("finalize()执行了...");// 调用finalize的时候,设置强引用自救,让对象不被回收reference = this;}finally {super.finalize();}}public static void main(String[] args) throws Throwable {// 设置强引用reference = new FinalizeReferenceDemo();test();test();}private static void test() throws InterruptedException {// 去除强引用reference = null;// 回收对象,回收的时候,finalize方法会被终结器线程调用一次System.gc();// 执行finalize方法的优先级比较低,休眠500ms等待一下Thread.sleep(500);if (reference != null) {reference.alive();} else {System.out.println("对象已被回收");}}
}
【运行】


垃圾回收算法
Java是如何实现垃圾回收的呢?简单来说,垃圾回收算法要做的有两件事:
- 找到内存中存活的对象
- 释放不再存活对象的内存,使得程序能再次利用这部分空间

垃圾回收算法的历史和分类
- 1960年John McCarthy发布了第一个GC算法:标记-清除算法。
- 1963年Marvin L. Minsky 发布了复制算法。
本质上后续所有的垃圾回收算法,都是在上述两种算法的基础上优化而来。

垃圾回收算法的评价标准
Java垃圾回收过程会通过单独的GC线程来完成,但是不管使用哪一种GC算法,都会有部分阶段需要停止所有的用户线程。这个过程被称之为Stop The World简称STW,如果STW时间过长(系统假死)则会影响用户的使用。
如下图,用户代码执行和垃圾回收执行让用户线程停止执行(STW)是交替执行的。

交替执行过程可以通过如下代码验证:
package chapter04.gc;import lombok.SneakyThrows;import java.util.LinkedList;
import java.util.List;/*** STW测试*/
public class StopWorldTest {public static void main(String[] args) {new PrintThread().start();new ObjectThread().start();}
}/*** 打印线程*/
class PrintThread extends Thread{@SneakyThrows@Overridepublic void run() {//记录开始时间long last = System.currentTimeMillis();while(true){long now = System.currentTimeMillis();// 如果不是垃圾回收影响,这里每次都应该是输出100System.out.println(now - last);last = now;Thread.sleep(100);}}
}/*** 创建对象线程*/
class ObjectThread extends Thread{@SneakyThrows@Overridepublic void run() {List<byte[]> bytes = new LinkedList<>();while(true){// 最多存放8g,然后删除强引用,垃圾回收时释放8gif(bytes.size() >= 80){// 清空集合,强引用去除,垃圾回收器就会去回收对象bytes.clear();}bytes.add(new byte[1024 * 1024 * 100]);Thread.sleep(10);}}
}
代码运行之前,设置如下JVM参数


所以判断GC算法是否优秀,可以从三个方面来考虑:
- 吞吐量
吞吐量指的是 CPU 用于执行用户代码的时间与 CPU 总执行时间的比值,即吞吐量 = 执行用户代码时间 /(执行用户代码时间 + GC时间)。吞吐量数值越高,垃圾回收的效率就越高。

- 最大暂停时间
最大暂停时间指的是所有在垃圾回收过程中的STW时间最大值。比如如下的图中,黄色部分的STW就是最大暂停时间,显而易见上面的图比下面的图拥有更少的最大暂停时间。最大暂停时间越短,用户使用系统时受到的影响就越短。

- 堆使用效率
不同垃圾回收算法,对堆内存的使用方式是不同的。比如标记清除算法,可以使用完整的堆内存。而复制算法会将堆内存一分为二,每次只能使用一半内存。从堆使用效率上来说,标记清除算法要优于复制算法。

上述三种评价标准:堆使用效率、吞吐量,以及最大暂停时间不可兼得。
一般来说,堆内存越大,回收对象就越多,最大暂停时间就越长。想要减少最大暂停时间,就要减少堆内存,少量多次,因为每次清理有一些准备工作,因此垃圾回收总时间会上升,吞吐量会降低。
没有一个垃圾回收算法能兼顾上述三点评价标准,所以不同的垃圾回收算法它的侧重点是不同的,适用于不同的应用场景(即垃圾回收算法没有好与坏,只有是否适合)
- 秒杀场景,购买只有很少的时间,最大暂停时间越短越好
- 有的场景,程序就在后台处理数据,暂停时间长一点无所谓,目标是吞吐量高一点
标记清除算法
标记清除算法的核心思想分为两个阶段:
- 标记阶段,将所有存活的对象进行标记。Java中使用可达性分析算法,从GC Root开始通过引用链遍历出所有存活对象。
- 清除阶段,从内存中删除没有被标记也就是非存活对象。
第一个阶段,从GC Root对象开始扫描,将对象A、B、C在引用链上的对象标记出来:

第二个阶段,将没有标记的对象清理掉,所以对象D就被清理掉了。

优缺点
优点:实现简单,只需要在第一阶段给每个对象维护标志位(在引用链上,标记为1),第二阶段删除标记值为0的对象即可。
缺点:
- 碎片化问题:由于内存是连续的,所以在对象被删除之后,内存中会出现很多细小的可用内存单元。如果我们需要的是一个比较大的空间,很有可能这些内存单元的大小过小无法进行分配。如下图,红色部分已经被清理掉了,总共回收了9个字节,但是每个都是一个小碎片,无法为5个字节的对象分配空间。

- 分配速度慢。由于内存碎片的存在,需要维护一个空闲链表,极有可能发生每次需要遍历到链表的最后才能获得合适的内存空间。我们需要用一个链表来维护,哪些空间可以分配对象,很有可能需要遍历这个链表到最后,才能发现这块空间足够我们去创建一个对象。如下图,遍历到最后才发现有足够的空间分配3个字节的对象了。如果链表很长,遍历也会花费较长的时间。

复制算法
复制算法的核心思想是:
- 准备两块空间From空间和To空间,每次在对象分配阶段,只能使用其中一块空间(From空间)。
对象A首先分配在From空间:

- 在垃圾回收GC阶段,将From中的存活对象复制到To空间。
在垃圾回收阶段,如果对象A存活,就将其复制到To空间。然后将From空间直接清空。

- 将两块空间的From和To名字互换,下次依然在From空间上创建对象。

完整的复制算法的例子:
1、将堆内存分割成两块From空间 To空间,对象分配阶段,创建对象。

2、GC阶段开始,将GC Root搬运到To空间

3、将GC Root关联的对象,搬运到To空间

4、清理From空间,并把名称互换

优缺点
优点:
- 吞吐量高,复制算法只需要遍历一次存活对象复制到To空间即可,比
标记-整理算法少了一次遍历的过程,因而性能较好;但是性能不如标记-清除算法,因为标记清除算法不需要进行对象的移动 - 不会发生碎片化,复制算法在复制之后就会将对象按顺序放入To空间中,所以对象以外的区域都是可用空间,不存在碎片化内存空间。
缺点:
- 内存使用效率低,每次只能让一半的内存空间来给创建对象使用。
标记整理算法(标记压缩算法)
标记整理算法是对标记清理算法中容易产生内存碎片问题的一种解决方案。
核心思想分为两个阶段:
- 标记阶段,将所有存活的对象进行标记。Java中使用可达性分析算法,从GC Root开始通过引用链遍历出所有存活对象。
- 整理阶段,将存活对象移动到堆的一端。清理掉存活对象的内存空间。

优缺点
优点:
- 内存使用效率高,整个堆内存都可以使用,不像复制算法只能使用半个堆内存
- 不会发生碎片化,在整理阶段可以将对象往内存的一侧进行移动,剩下的空间都是可以分配对象的有效空间
缺点:
- 整理阶段的效率不高,需要遍历多次对象,还需要移动对象。整理算法有很多种,比如Lisp2整理算法需要对整个堆中的对象搜索3次,整体性能不佳。可以通过Two-Finger、表格算法、ImmixGC等高效的整理算法优化此阶段的性能。
分代垃圾回收算法(常用)
现代优秀的垃圾回收算法,会将上述描述的垃圾回收算法组合进行使用,其中应用最广的就是分代垃圾回收算法(Generational GC)。分代垃圾回收将整个内存区域划分为两块大区:年轻代、老年代:

- Eden区:对象刚被创建出来的时候放到的地方
- 幸存者区-S0、幸存者区-S1:用来实现复制算法
可以通过arthas来验证下内存划分的情况:
- 在JDK8中,添加
-XX:+UseSerialGC参数使用分代回收的垃圾回收器,运行程序。 - 在arthas中使用memory命令查看内存,显示出三个区域的内存情况。

- Eden + survivor 这两块区域组成了年轻代。
- tenured_gen指的是晋升区域,其实就是老年代。
JVM参数设置
可以设置的虚拟机参数如下
| 参数名 | 参数含义 | 示例 |
|---|---|---|
| -Xms | 设置堆的最小和初始大小,必须是1024倍数且大于1MB | 比如初始大小6MB的写法: -Xms6291456 -Xms6144k -Xms6m |
| -Xmx | 设置最大堆的大小,必须是1024倍数且大于2MB | 比如最大堆80 MB的写法: -Xmx83886080 -Xmx81920k -Xmx80m |
| -Xmn | 新生代的大小 | 新生代256 MB的写法: -Xmn256m -Xmn262144k -Xmn268435456 |
| -XX:SurvivorRatio | 伊甸园区和幸存区的比例,默认为8:如新生代有1g内存,则伊甸园区800MB,S0和S1各100MB | 比例调整为4的写法:-XX:SurvivorRatio=4 |
| -XX:+PrintGCDetailsverbose:gc | 打印GC日志 | 无 |
老年代大小不需要设置,因为新生代设置完之后,老年代的大小就确定了(总的堆内存-新生代内存)
注:如果使用其他版本的JDK,或者使用其他回收器,上面的部分参数可能就不会生效
使用Arthas查看内存分区
代码:
package chapter04.gc;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;/*** 垃圾回收器案例1*/
//-XX:+UseSerialGC -Xms60m -Xmn20m -Xmx60m -XX:SurvivorRatio=3 -XX:+PrintGCDetails
public class GcDemo0 {public static void main(String[] args) throws IOException {List<Object> list = new ArrayList<>();int count = 0;while (true){System.in.read();System.out.println(++count);//每次添加1m的数据list.add(new byte[1024 * 1024 * 1]);}}
}
使用arthas的memory展示出来的效果:

heap展示的是可用堆。
垃圾回收执行流程
1、分代回收时,创建出来的对象,首先会被放入Eden伊甸园区。

2、随着对象在Eden区越来越多,如果Eden区满,新创建的对象已经无法放入,就会触发年轻代的GC,称为Minor GC或者Young GC。Minor GC会把需要eden中和From需要回收的对象回收,把没有回收的对象放入To区(算法使用的是复制算法)。Minor GC结束之后**,**Eden区会被清空,后面创建的对象又可以放到Eden区。

3、接下来,S0会变成To区,S1变成From区。当eden区满时再往里放入对象,依然会发生Minor GC。

此时会回收eden区和S1(from)中的对象,并把eden和from区中存活的对象放入S0。
注意:每次Minor GC中都会为对象记录他的年龄,初始值为0,每次GC完加1。

4、如果Minor GC后对象的年龄达到阈值(最大15,默认值和垃圾回收器有关),对象就会被晋升至老年代。


5、当老年代中空间不足,无法放入新的对象时,先尝试minor gc(为啥?**因为young满了之后,部分对象年龄没有到15,也被放在了老年区,**minor gc可以清理young区来放新对象)。如果空间还是不足,就会触发Full GC(停顿时间较长),Full GC会对整个堆进行垃圾回收。如果Full GC依然无法回收掉老年代的对象,那么当对象继续放入老年代时,就会抛出Out Of Memory异常。

下图中的程序为什么会出现OutOfMemory?

从上图可以看到,Full GC无法回收掉老年代的对象,那么当对象继续放入老年代时,就会抛出Out Of Memory异常。
【测试代码】
//-XX:+UseSerialGC -Xms60m -Xmn20m -Xmx60m -XX:SurvivorRatio=3 -XX:+PrintGCDetails
public class GcDemo0 {public static void main(String[] args) throws IOException {List<Object> list = new ArrayList<>();int count = 0;while (true){System.in.read();System.out.println(++count);//每次添加1m的数据list.add(new byte[1024 * 1024 * 1]);}}
}
结果如下:

老年代已经满了,而且垃圾回收无法回收掉对象,如果还想往里面放就发生了OutOfMemoryError。

分代GC算法内存为什么分年轻代、老年代
为什么分代GC算法要把堆分成年轻代和老年代?首先我们要知道堆内存中对象的特性:
- 系统中的大部分对象,都是创建出来之后很快就不再使用可以被回收,比如用户获取订单数据,订单数据返回给用户之后就可以释放了。
- 老年代中会存放长期存活的对象,比如Spring的大部分bean对象,在程序启动之后就不会被回收了。
- 在虚拟机的默认设置中,新生代大小要远小于老年代的大小。
分代GC算法将堆分成年轻代和老年代主要原因有:
- 可以通过调整年轻代和老年代的比例来适应不同类型的应用程序,提高内存的利用率和性能。
- 新生代和老年代使用不同的垃圾回收算法,新生代一般选择
复制算法;老年代可以选择标记-清除和标记-整理算法,由程序员来选择灵活度较高。 - 分代的设计中允许只回收新生代(minor gc),如果能满足对象分配的要求就不需要对整个堆进行回收(full gc),STW时间就会减少。(尽可能做minor gc,少做full gc,尽量降低垃圾回收对程序运行的影响)
垃圾回收器(垃圾回收算法实现)
垃圾回收器是垃圾回收算法的具体实现。由于垃圾回收器分为年轻代和老年代,除了G1(既能管控新生代,也可以管控老年代)之外,新生代、老年代的垃圾回收器必须按照hotspot的要求成对组合进行使用(需要根据JDK的版本来选择相应的组合)
具体的组合关系如下:

JVM底层源码中,在某些特殊情况,CMS回收器会调用Serial Old回收器
Arthas查看所使用的垃圾回收器
不能直接看到使用了什么垃圾回收器,只能根据算法来推断

年轻代-Serial垃圾回收器
Serial是一种单线程串行回收年轻代的垃圾回收器。

回收年代和算法
- 年轻代
- 复制算法
优点
单CPU处理器下吞吐量非常出色
缺点
多CPU下吞吐量不如其他垃圾回收器(单线程,只使用了一个CPU),堆如果偏大会让用户线程处于长时间的等待
适用场景
Java编写的客户端程序或者硬件配置有限(CPU核数不多)的场景
如何使用
-XX:+UseSerialGC:新生代、老年代都使用串行回收器。
老年代-SerialOld垃圾回收器
SerialOld是Serial垃圾回收器的老年代版本,采用单线程串行回收

回收年代和算法
- 老年代
- 标记-整理算法
优点
单CPU处理器下吞吐量非常出色
缺点
多CPU下吞吐量不如其他垃圾回收器,堆如果偏大会让用户线程处于长时间的等待
适用场景
与Serial垃圾回收器搭配使用,或者在CMS特殊情况下使用
如何使用
-XX:+UseSerialGC:新生代、老年代都使用串行回收器。
年轻代-ParNew垃圾回收器
ParNew垃圾回收器本质上是对Serial在多CPU下的优化,使用多线程进行垃圾回收

回收年代和算法:
- 年轻代
- 复制算法
优点
- 多CPU处理器下停顿时间较短
缺点
- 吞吐量和停顿时间不如G1,所以在JDK9之后不建议使用
适用场景
- JDK8及之前的版本中,与CMS老年代垃圾回收器搭配使用
如何使用
-XX:+UseParNewGC:新生代使用ParNew回收器, 老年代使用串行回收器

老年代-CMS(Concurrent Mark Sweep)垃圾回收器
CMS垃圾回收器关注的是系统的暂停时间(尽量减少STW,优化用户体验),允许用户线程和垃圾回收线程在某些步骤中同时执行,减少了用户线程的等待时间。
回收年代和算法
- 老年代
- 标记清除算法
优点
- 系统由于垃圾回收出现的停顿时间较短,用户体验好
缺点
1、内存碎片问题
2、退化问题(在某些特定情况,会退化为SerialOld这种单线程回收器)
3、浮动垃圾问题(回收过程,有的垃圾回收不掉)
适用场景
大型的互联网系统中用户请求数据量大、频率高的场景,比如订单接口、商品接口等
使用
XX:+UseConcMarkSweepGC,可以分别设置年轻代和老年代的回收器


CMS执行步骤
- 初始标记,用极短的时间标记出GC Roots能直接关联到的对象。
- 并发标记, 标记所有的对象,用户线程不需要暂停。(虽然并发标记是和用户线程一起执行,但是如果并发标记占用的资源较高,也会影响用户线程)
- 重新标记(并发),由于并发标记阶段有些对象会发生了变化,存在错标(用的对象本来是存活的,标记之后,用户线程把它变得不存活了,导致错标)、漏标(因为是并发的,可能有的对象是用户线程刚刚创建出来的,就会导致漏标)等情况,需要重新标记。
- 并发清理,清理死亡的对象,用户线程不需要暂停。
注:只有初始标记、重新标记阶段会出现STW

缺点:
1、CMS使用了标记-清除算法,在垃圾收集结束之后会出现大量的内存碎片,为了不影响对象的分配,CMS会在Full GC时进行碎片的整理。这样会导致用户线程暂停,可以使用-XX:CMSFullGCsBeforeCompaction=N 参数(默认0)调整N次Full GC之后再整理。
2.、无法处理在并发清理过程中产生的“浮动垃圾”,不能做到完全的垃圾回收(在本次清理的过程中,用户线程并发创建了一些对象,但是很快没有再使用,这些对象在这次清理中没有得到回收,需要等到下一次清理,所以称这些为浮动垃圾)。
3、如果老年代内存不足无法分配对象,CMS就会退化成Serial Old单线程回收老年代。
并发线程数:
在CMS中并发阶段运行时的线程数可以通过-XX:ConcGCThreads参数设置,由系统计算得出,计算公式为(-XX:ParallelGCThreads定义的线程数 + 3) / 4, ParallelGCThreads是STW停顿之后的并行线程数
ParallelGCThreads是由处理器核数决定的:
1、当cpu核数小于8时,ParallelGCThreads = CPU核数
2、否则 ParallelGCThreads = 8 + (CPU核数 – 8 )*5/8
我的电脑上逻辑处理器有12个,所以ParallelGCThreads = 8 + (12 - 8)* 5/8 = 10,ConcGCThreads = (-XX:ParallelGCThreads定义的线程数 + 3) / 4 = (10 + 3) / 4 = 3

最终可以得到这张图:

并发标记和并发清理阶段,会使用3个线程并行处理。重新标记阶段会使用10个线程处理。由于CPU的核心数有限,并发阶段会影响用户线程执行的性能。

年轻代-Parallel Scavenge垃圾回收器
Parallel Scavenge是JDK8默认的年轻代垃圾回收器,多线程并行回收,关注的是系统的吞吐量。为了拉高吞吐量,PS会自动调整堆内存大小(调整新生代、老年代内存大小、晋升的阈值)。

回收年代和算法
- 年轻代
- 复制算法
优点
- 吞吐量高,而且支持手动设置参数控制吞吐量。为了提高吞吐量,虚拟机会动态调整堆的参数(用户只需要设置吞吐量,不需要设置内存大小等其他参数)
缺点
- 不能保证单次的停顿时间,但是支持设置STW时间
适用场景
- 后台任务,不需要与用户交互,并且容易产生大量的对象。比如:大数据的处理,大文件导出
常用参数
Parallel Scavenge允许手动设置最大暂停时间和吞吐量。Oracle官方建议在使用这个组合时,不要设置堆内存的最大值,垃圾回收器会根据最大暂停时间和吞吐量自动调整内存大小。
- 最大暂停时间,
-XX:MaxGCPauseMillis=n设置每次垃圾回收时的最大停顿毫秒数 - 吞吐量,
-XX:GCTimeRatio=n设置吞吐量为n(用户线程执行时间 = n/(n + 1)) - 自动调整内存大小,
-XX:+UseAdaptiveSizePolicy设置可以让垃圾回收器根据吞吐量和最大停顿的毫秒数自动调整内存大小,这个参数默认是开启的(Oracle建议使用PS组合的时候,不要设置堆内存的最大值,让垃圾回收器自动调整)
注:最大暂停时间和吞吐量这两个指标是冲突的,垃圾回收器会尽量满足最大暂停时间(有时候设置得太小,是没办法满足的,会超出所设置得最大暂停时间),牺牲吞吐量。如果要同时设置最大暂停时间和吞吐量,要多做测试,让它们比较协调
老年代-Parallel Old垃圾回收器
Parallel Old是为Parallel Scavenge收集器设计的老年代版本,利用多线程并发收集。

回收年代和算法
- 老年代
- 标记-整理算法(其实是标记+清除+整理)
优点
- 并发收集,在多核CPU下效率较高
缺点
- 暂停时间会比较长
适用场景
- 与Parallel Scavenge配套使用
如何使用
JDK8设置参数,就是默认使用该回收器
参数:-XX:+UseParallelGC 或 -XX:+UseParallelOldGC可以使用Parallel Scavenge + Parallel Old这种组合。


测试
-XX:+PrintFlagsFinal:可以在程序启动的时候打印所有配置项的最终值,可以看看自动调整功能有没有开启




import java.io.IOException;
import java.util.ArrayList;
import java.util.List;/*** 垃圾回收器案例3*/
//-XX:+UseSerialGC -Xmn1g -Xmx16g -XX:SurvivorRatio=8 -XX:+PrintGCDetails -verbose:gc -XX:+PrintFlagsFinal
//-XX:+UseParNewGC -Xmn1g -Xmx16g -XX:SurvivorRatio=8 -XX:+PrintGCDetails -verbose:gc
//-XX:+UseConcMarkSweepGC
//-XX:+UseG1GC -Xmn8g -Xmx16g -XX:SurvivorRatio=8 -XX:+PrintGCDetails -verbose:gc MaxGCPauseMillis
//-XX:+PrintFlagsFinal -XX:GCTimeRatio = 19 -XX:MaxGCPauseMillis=10 -XX:+UseAdaptiveSizePolicy
public class GcDemo2 {public static void main(String[] args) throws IOException {int count = 0;List<Object> list = new ArrayList<>();while (true){//System.out.println(++count);if(count++ % 10240 == 0){list.clear();}
// byte[] bytes = new byte[1024 * 1024 * 1];list.add(new byte[1024 * 1024 * 1 / 2]);
// System.gc();}}
}
【测试最大暂停时间=10】

内存大小如下:

【测试最大暂停时间=1】


结论:堆内存越小,垃圾回收暂停时间越短
G1(Garbage First)垃圾回收器(极力推荐)
JDK9之后默认的垃圾回收器是G1(Garbage First)垃圾回收器。
- Parallel Scavenge关注吞吐量,允许用户设置最大暂停时间 ,但是会减少年轻代可用空间的大小。
- CMS关注暂停时间,但是吞吐量方面会下降。
- 而G1设计目标就是将上述两种垃圾回收器的优点融合:
JDK9之后强烈建议使用G1垃圾回收器。(在JDK7、8上,G1可能不是很成熟,要慎重考虑)
G1出现之前的垃圾回收器,年轻代和老年代一般是连续的,如下图:

G1内存结构发生了变化:G1的整个堆会被划分成多个大小相等的区域,称之为区Region,区域不要求是连续的。分为Eden、Survivor、Old区。Region的大小通过堆空间大小/2048计算得到,也可以通过参数-XX:G1HeapRegionSize=32m指定(其中32m指定region大小为32M),Region size必须是2的指数幂,取值范围从1M到32M。

G1垃圾回收有两种方式
1、年轻代回收(Young GC)
2、混合回收(Mixed GC)
年轻代回收(Young GC)
只回收年轻代,回收Eden区和Survivor区中不用的对象。会导致STW,G1中可以通过参数
-XX:MaxGCPauseMillis=n(默认200) 设置每次垃圾回收时的最大暂停时间毫秒数,G1垃圾回收器会尽可能地保证暂停时间。
【Young GC步骤】
1、新创建的对象会存放在Eden区。当G1判断年轻代区不足(max默认60%,如果年轻代的内存占了总堆的60%以上,就要Young GC),无法分配对象时需要回收时会执行Young GC。

2、标记出Eden和Survivor区域中的存活对象,
3、根据配置的**最大暂停时间选择某些区域(和其他回收器的区别:其他回收器会回收负责的所有区域)**将存活对象复制到一个新的Survivor区中(年龄+1)(使用复制算法,不会产生内存碎片),清空这些区域。


G1在进行Young GC的过程中会去记录每次垃圾回收时每个Eden区和Survivor区的平均耗时,以作为下次回收时的参考依据。这样就可以根据配置的最大暂停时间计算出本次回收时最多能回收多少个Region区域了。比如-XX:MaxGCPauseMillis=n(默认200),每个Region回收耗时40ms,那么这次回收最多只能回收4个Region。
4、后续Young GC时与之前相同,只不过Survivor区中存活对象会被搬运到另一个Survivor区。


5、当某个存活对象的年龄到达阈值(默认15),将被放入老年代。原来的Survivor中年龄没有到达15的对象,还是会迁移到新的Survivor中。

6、部分对象如果大小超过Region的一半,会直接放入老年代,这类老年代被称为Humongous(翻译:巨大的)区。比如堆内存是4G,每个Region是2M,只要一个大对象超过了1M就被放入Humongous区,如果对象过大会横跨多个Region(一个Region放不完)。

7、多次回收之后,会出现很多Old老年代区,此时总堆占有率达到阈值时
(-XX:InitiatingHeapOccupancyPercent默认45%)会触发混合回收Mixed GC,回收所有年轻代和部分老年代的对象以及大对象区。采用复制算法来完成。


混合回收(Mixed GC)
混合回收分为如下步骤,看起来和CMS差不多,但是步骤里面都是有区别的:
- 初始标记(initial mark)
- 并发标记(concurrent mark)
- 最终标记(remark或者Finalize Marking):只管漏标,不管新创建、不再关联的对象。这里使用的算法远比CMS的快
- 并发清理(cleanup):G1对老年代的清理会选择存活度最低的区域来进行回收(A区:100个对象只存活1个;B区:100个对象存活99个;G1选择回收A区),这样可以保证回收效率最高,这也是G1(Garbage first)名称的由来。最后清理阶段使用复制算法,不会产生内存碎片。


注意:**如果清理过程中发现没有足够的空Region存放转移的对象,会出现Full GC,**单线程执行标记-整理算法,此时会导致用户线程的暂停,影响用户的正常使用。所以尽量保证应该用的堆内存有一定多余的空间,如果堆内存的占用比较高,就要考虑优化。

如何使用G1垃圾回收器
参数1: -XX:+UseG1GC 打开G1的开关,JDK9之后默认不需要打开
参数2:-XX:MaxGCPauseMillis=毫秒值 最大暂停的时
回收年代和算法
- 年轻代+老年代
- 复制算法
优点
- 支持巨大的堆空间回收,并有较高的吞吐量。对比较大的堆延迟可控,如超过6G的堆回收时
- 不会产生内存碎片
- 并发标记的SATB算法效率高,比CMS的算法效率高
- 支持多CPU并行垃圾回收
- 允许用户设置最大暂停时间
缺点
- JDK8的早期版本还不够成熟
适用场景
- JDK8最新版本、JDK9之后建议默认使用
测试
使用以下代码测试g1垃圾回收器,打印出每个阶段的时间:

package chapter04.gc;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;/*** 垃圾回收器案例3*/
//-XX:+UseG1GC -Xmn8g -Xmx16g -XX:SurvivorRatio=8 -XX:+PrintGCDetails -verbose:gc
public class GcDemo2 {public static void main(String[] args) throws IOException {int count = 0;List<Object> list = new ArrayList<>();while (true){//System.out.println(++count);if(count++ % 10240 == 0){list.clear();}
// byte[] bytes = new byte[1024 * 1024 * 1];list.add(new byte[1024 * 1024 * 1 / 2]);
// System.gc();}}
}
每个region大小为2m,一共有84个young区,26个幸存者区。

初始标记花了0.0478秒,初始标记是伴随着年轻代回收的,0.0478秒是两个操作的总时间


并发标记总共耗时10ms,不会产生STW。

最终标记,效率较高

清理阶段

垃圾回收器总结
垃圾回收器的组合关系虽然很多,但是针对几个特定的版本,比较好的组合选择如下:
- JDK8及之前:
- ParNew + CMS(关注暂停时间)
- Parallel Scavenge + Parallel Old (关注吞吐量)
- G1(JDK8之前不建议,较大堆并且关注暂停时间)
- JDK9之后:G1(默认)。从JDK9之后,由于G1日趋成熟,JDK默认的垃圾回收器已经修改为G1,所以强烈建议在生产环境上使用G1。G1的实现原理将在《原理篇》中介绍,更多前沿技术ZGC(最新的垃圾回收器)、GraalVM将在《高级篇》中介绍。
几个问题
Java中有哪几块内存需要垃圾回收?

方法区回收,Java程序员少关注


有哪几种常见的引用类型?
- 强引用,最常见的引用方式,由可达性分析算法来判断
- 软引用,对象在没有强引用情况下,内存不定时会回收
- 弱引用,对象在没有强引用情况下,会直接回收
- 虚引用,通过虚引用知道对象被回收了
- 终结器引用,对象回收时可以自救,不建议使用
有哪几种常见的垃圾回收算法?

常见的垃圾回收器有哪些?
Serial+Serial Old:单线程回收,适用于单核CPU场景ParNew+CMS:暂停时间较短,适用于大型互联网应用中与用户交互的部分Paraller Scavenge+Parallel Old:吞吐量高,适用于后台进行大量数据操作G1:适用于较大堆,具有可控暂停时间
文章说明
该文章是本人学习 黑马程序员 的学习笔记,文章中大部分内容来源于 黑马程序员 的视频黑马程序员JVM虚拟机入门到实战全套视频教程,java大厂面试必会的jvm一套搞定(丰富的实战案例及最热面试题),也有部分内容来自于自己的思考,发布文章是想帮助其他学习的人更方便地整理自己的笔记或者直接通过文章学习相关知识,如有侵权请联系删除,最后对 黑马程序员 的优质课程表示感谢。
相关文章:
【JVM基础篇】垃圾回收
文章目录 垃圾回收常见内存管理方式手动回收:C内存管理自动回收(GC):Java内存管理自动、手动回收优缺点 应用场景垃圾回收器需要对哪些部分内存进行回收?不需要垃圾回收器回收需要垃圾回收器回收 方法区的回收代码测试手动调用垃圾回收方法Sy…...
Spark join数据倾斜调优
Spark中常见的两种数据倾斜现象如下 stage部分task执行特别慢 一般情况下是某个task处理的数据量远大于其他task处理的数据量,当然也不排除是程序代码没有冗余,异常数据导致程序运行异常。 作业重试多次某几个task总会失败 常见的退出码143、53、137…...

YOLOv5初学者问题——用自己的模型预测图片不画框
如题,我在用自己的数据集训练权重模型的时候,在训练完成输出的yolov5-v5.0\runs\train\exp2目录下可以看到,在训练测试的时候是有输出描框的。 但是当我引用训练好的best.fangpt去进行预测的时候, 程序输出的图片并没有描框。根据…...
【linux学习---1】点亮一个LED---驱动一个GPIO
文章目录 1、原理图找对应引脚2、IO复用3、IO配置4、GPIO配置5、GPIO时钟使能6、总结 1、原理图找对应引脚 从上图 可以看出, 蜂鸣器 接到了 BEEP 上, BEEP 就是 GPIO5_IO05 2、IO复用 查找IMX6UL参考手册 和 STM32一样,如果某个 IO 要作为…...

Redis分布式锁代码实现详解
引言 在分布式系统中,资源竞争和数据一致性问题常常需要通过锁机制来解决。Redis作为一个高性能的键值存储系统,因其提供的原子操作、丰富的数据结构以及网络延迟低等特点,成为了实现分布式锁的理想选择。本文将详细介绍如何使用Redis来实现…...
Day01-02-gitlab
Day01-02-gitlab 1. 什么是gitlab2. Gitlab vs Github/Gitee3. Gitlab 应用场景4. 架构5. Gitlab 快速上手指南5.0 安装要求5.1 安装Gitlab组件5.3 配置访问url5.6 初始化5.8 登录与查看5.9 汉化5.10 设置密码5.11 目录结构5.12 删除5.13 500 vs 5025.14 重置密码 6. Gitlab用户…...

PyCharm远程开发配置(2024以下版本)
目录 PyCharm远程开发配置 1、清理远程环境 1.1 点击Setting 1.2 进入Interpreter 1.3 删除远程环境 1.4 删除SSH 2、连接远程环境 2.1 点击Close Project 2.2 点击New Project 2.3 项目路径设置 2.4 SSH配置 2.5 选择python3解释器在远程环境的位置 2.6 配置远程…...

解决Ucharts在小程序上的层级过高问题
<qiun-wx-ucharts canvas2d"{{true}}" type"pie" opts"{{rectificationRateOpts}}" chartData"{{rectificationRateData}}" /> 开启2d渲染即可解决(在小程序开发工具上看着层级还是高,但是在手机上是正常…...

重保期间的网站安全防护:网站整站锁的应用与实践
标题:重保期间的网站安全防护:网站整站锁的应用与实践 一、引言 在重大活动或事件(通常被称为“重保”)期间,网站的安全问题尤为突出。由于此时网站的访问量和关注度可能达到高峰,因此也成为了黑客攻击的…...

Qt自定义类型
概述 在使用Qt创建用户界面时,特别是那些具有特殊控件和特性的界面时,开发人员有时需要创建新的数据类型,以便与Qt现有的值类型集一起使用或代替它们。 QSize、QColor和QString等标准类型都可以存储在QVariant对象中,作为基于qo…...
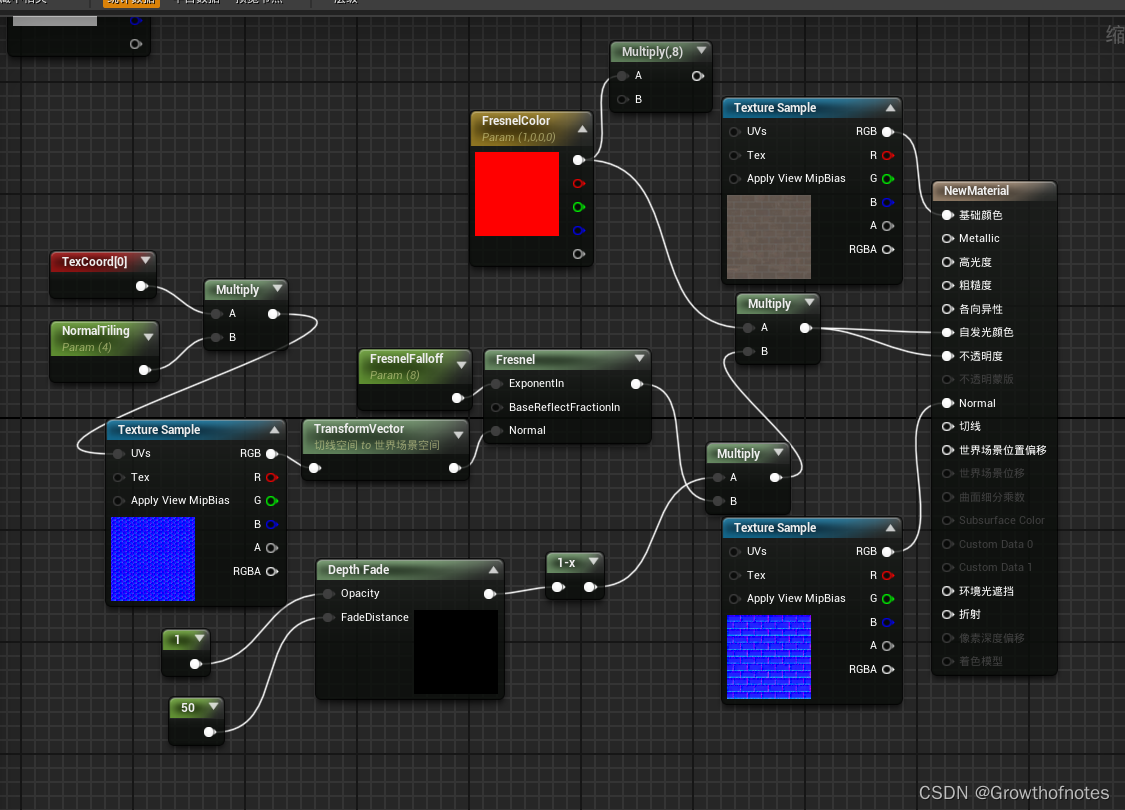
UE4_材质_材质节点_DepthFade
一、DepthFade参数 DepthFade(深度消退)表达式用来隐藏半透明对象与不透明对象相交时出现的不美观接缝。 项目说明属性消退距离(Fade Distance)这是应该发生消退的全局空间距离。未连接 FadeDistance(FadeDistance&a…...
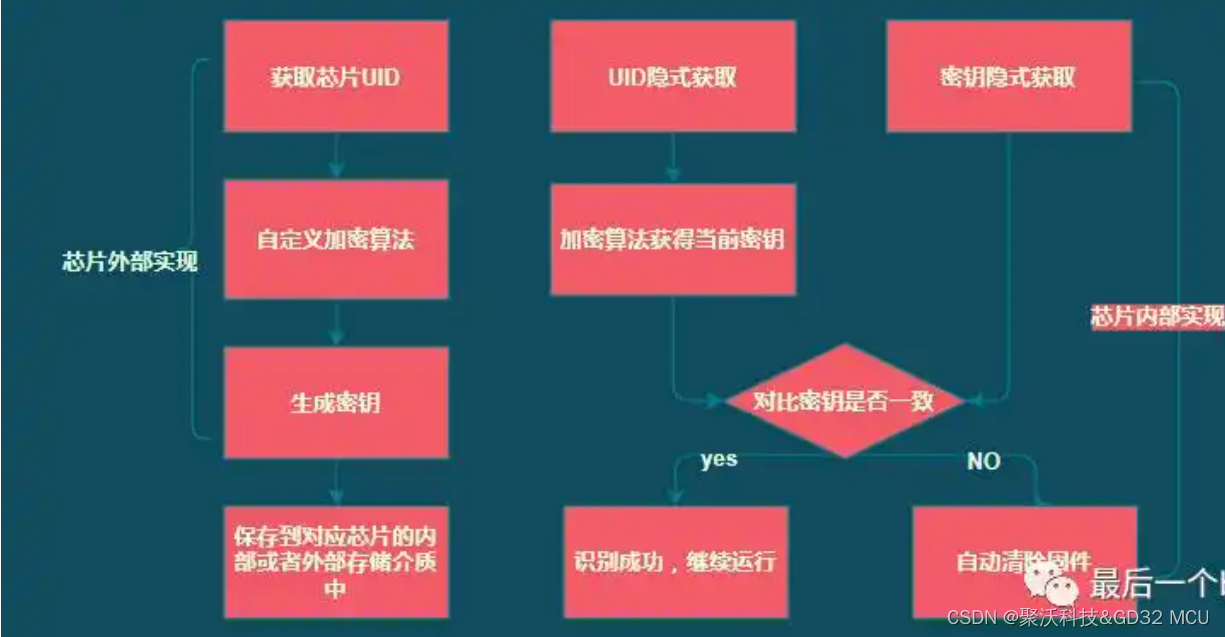
如何对GD32 MCU进行加密?
GD32 MCU有哪些加密方法呢?大家在平时项目开发的过程中,最后都可能会面临如何对出厂产品的MCU代码进行加密,避免产品流向市场被别人读取复制。 下面为大家介绍GD32 MCU所支持的几种常用的加密方法: 首先GD32 MCU本身支持防硬开盖…...
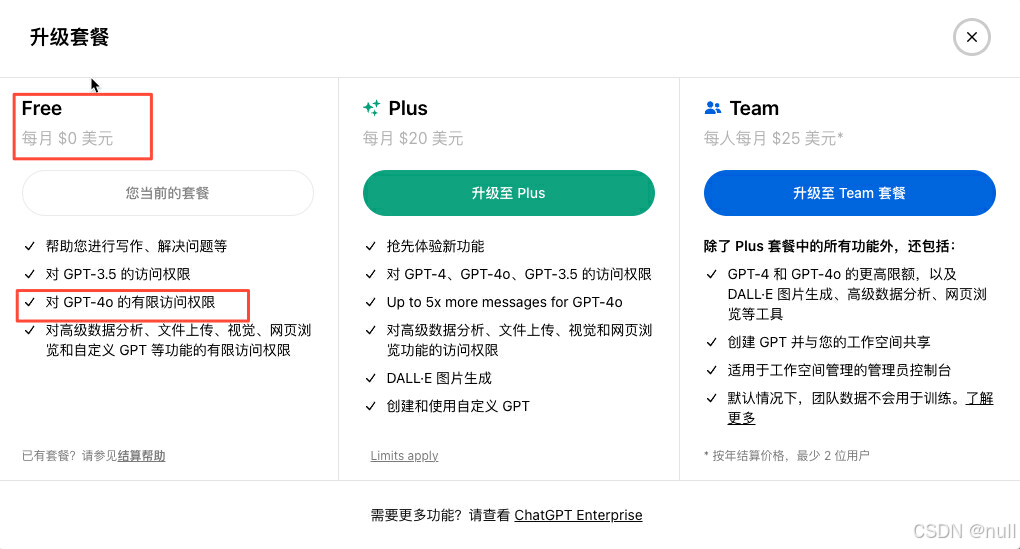
快速了解GPT-4o和GPT-4区别
GPT-4o简介 在5月14日的OpenAI举行春季发布会上,OpenAI在活动中发布了新旗舰模型“GPT-4o”!据OpenAI首席技术官穆里穆拉蒂(Muri Murati)介绍,GPT-4o在继承GPT-4强大智能的同时,进一步提升了文本、图像及语…...

周末休息日也能及时回应客户消息!微信自动回复神器太就好用啦!
无论是在忙碌时,还是在周末休息日,如果没能及时回应客户,很可能会造成客户流失。 今天,我要为大家介绍一个多微管理神器——个微管理系统,它可以帮助你实现自动回复,提高回复效率。 自动通过好友请求 在…...

力扣404周赛 T1/T2/T3 枚举/动态规划/数组/模拟
博客主页:誓则盟约系列专栏:IT竞赛 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 3200.三角形的最大高度【简单】 题目: 给你两个整数 red 和 b…...

Taurus 性能测试工具详解
文章目录 简介原理安装编写测试配置运行测试集成其他工具结果分析优点与缺点优点缺点 参考资料总结 简介 Taurus 是一个开源的自动化测试工具,用于简化和增强性能测试流程。与其他性能测试工具不同,Taurus 旨在通过友好的 YAML 配置文件和对多种负载测试…...
)
天猫商品详情API接口(店铺|标题|主图|价格|SKU属性等)
天猫商品详情API接口为开发者提供了获取天猫商品详细信息的能力,包括店铺信息、商品标题、主图、价格、SKU属性等。以下是该接口的使用过程和相关技术要点: 注册账号并创建应用 注册账号:需要在天猫开放平台注册一个开发者账号。创建应用&a…...
双向广搜——AcWing 190. 字串变换
双向广搜 定义 双向广度优先搜索(Bi-directional Breadth-First Search, Bi-BFS)是一种在图或树中寻找两点间最短路径的算法。与传统的单向广度优先搜索相比,它从起始点和目标点同时开始搜索,从而有可能显著减少搜索空间&#x…...

工商业光伏项目如何快速开发?
一、前期调研与规划 1、屋顶资源评估:详细测量屋顶面积、承重能力及朝向,利用光伏业务管理软件进行日照分析和发电量预测,确保项目可行性。 2、政策与补贴研究:深入了解当地政府对工商业光伏项目的政策支持和补贴情况࿰…...
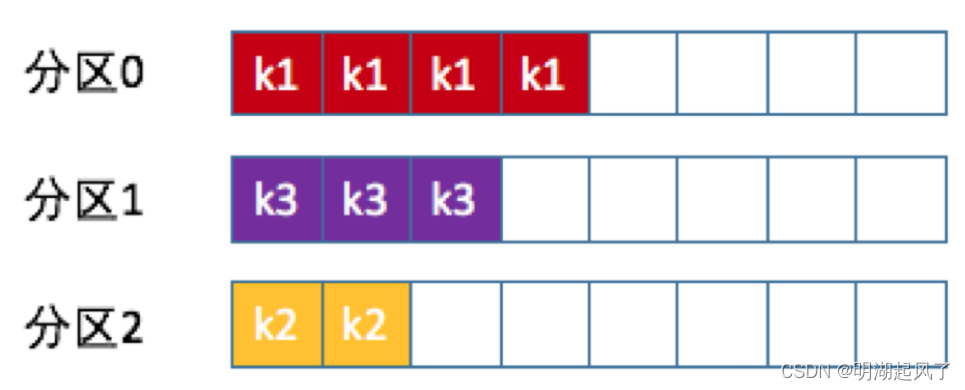
Kafka入门-分区及压缩
一、生产者消息分区 Kafka的消息组织方式实际上是三级结构:主题-分区-消息。主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份。 分区的作用就是提供负载均衡的能力,或者说对数据进行分区的主要原因,就是为…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...
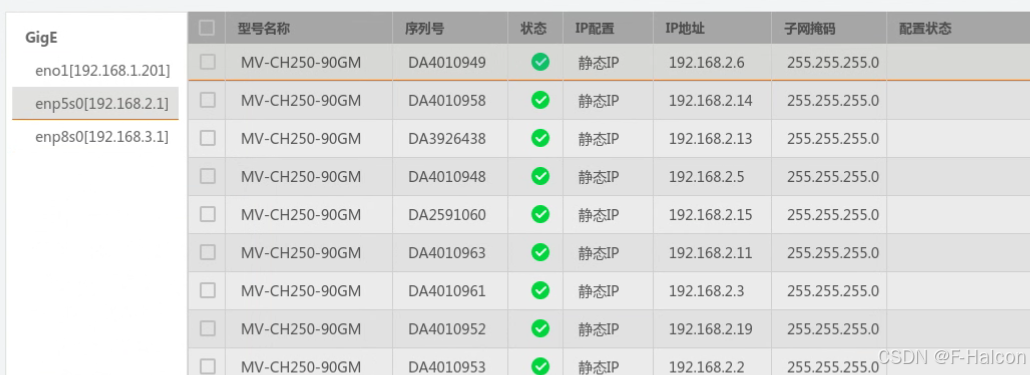
Ubuntu系统多网卡多相机IP设置方法
目录 1、硬件情况 2、如何设置网卡和相机IP 2.1 万兆网卡连接交换机,交换机再连相机 2.1.1 网卡设置 2.1.2 相机设置 2.3 万兆网卡直连相机 1、硬件情况 2个网卡n个相机 电脑系统信息,系统版本:Ubuntu22.04.5 LTS;内核版本…...