电力需求预测挑战赛笔记 Task3 #Datawhale AI 夏令营
上文:
电力需求预测挑战赛笔记 Task2 #Datawhale AI 夏令营-CSDN博客文章浏览阅读80次。【代码】电力需求预测挑战赛笔记 Task2。https://blog.csdn.net/qq_23311271/article/details/140360632
前面我们介绍了如何使用经验模型以及常见的lightgbm决策树模型来解决本次时间序列问题。
这里继续根据时间序列预测特征提取和分析方法
时间序列的进阶特征提取与分析

-
日期变量:时间序列数据通常包含日期或时间信息。这可以细分为不同的时间尺度,如年、月、周、日、小时、分钟等。在特征提取时,可以将这些日期变量转换为数值型特征,以便于模型处理。
-
周期性:许多时间序列数据表现出周期性,例如,一天中的小时数、一周中的天数、一年中的月份等。识别并利用这些周期性特征可以帮助模型捕捉数据的内在规律。
-
趋势性:趋势性是指时间序列数据随时间推移呈现的上升或下降的总体模式。这可以通过诸如移动平均或线性回归等方法来提取,并作为特征输入模型。
-
距离某天的时间差:这涉及到从特定日期(如产品发布日、重要事件日等)计算时间差。这种特征可以帮助模型了解数据点与特定事件的相对位置。
-
时间特征组合:将不同的时间单位组合起来(如年和周、月和日)可以提供更丰富的时间上下文信息,有助于揭示数据中的复杂模式。
-
特殊日期:识别时间序列中的特殊日期或事件(如节假日、促销活动等)并将其作为特征,可以帮助模型解释与这些事件相关的数据波动。
-
异常点:时间序列中可能存在异常点,这些点与其他数据点显著不同。正确识别并处理这些异常点对于提高预测精度至关重要。
-
时序相关特征:
-
历史平移:将过去的值作为当前值的函数,例如,使用前一天的值来预测后一天的值。
-
滑窗统计:使用时间窗口内的统计数据(如平均值、中位数、标准差等)作为特征,这有助于捕捉局部时间范围内的数据特性。
-
-
强相关特征:识别与目标变量强烈相关的特征,并利用这些特征来构建预测模型。
关于时间序列预测中构建关键特征的要点

强相关性特征
强相关性特征是指特征之间存在明显的相关性,可以通过统计分析或者机器学习算法得到的相关系数来衡量。这些特征之间的相关性可以帮助我们理解数据的关联性,以及它们对目标变量的影响程度。
构建方法
滞后特征:使用过去的值作为当前预测的特征,例如,使用前一天的销售数据来预测后一天的销售。
滚动统计特征:计算时间序列的滚动窗口内的统计量,如平均值、最大值、最小值、总和等。
趋势性特征
趋势性特征是指随着时间推移,数据呈现出一定的趋势或者变化模式。这种特征常见于时间序列数据,可以通过使用趋势线或者回归分析来观察和预测数据的趋势。
构建方法
时间戳转换:将时间戳转换为数值,如从时间戳中提取年份、月份、星期等。
移动平均:使用时间序列的移动平均值来平滑短期波动,突出长期趋势。
多项式拟合:拟合一个多项式模型来捕捉趋势。
周期性特征
周期性特征是指数据具有明显的重复周期性变化。这种特征常见于季节性数据,如气象数据、销售数据等。周期性特征可以帮助我们发现数据的周期性规律,并据此进行预测和决策。
构建方法
时间戳的周期性转换:将时间戳转换为周期性变量,如一周中的星期几、一月中的日子等。
季节性分解:使用季节性分解方法来识别和提取时间序列的季节性成分。
周期性函数:使用正弦和余弦函数来模拟周期性变化。
异常点特征
(噪声)
异常点特征是指数据集中存在的与其他数据点明显不同的数据。这些异常点可能是由于测量误差、数据录入错误或者真实世界中的异常情况所导致。异常点特征的发现和处理对于数据分析和模型训练非常重要,可以帮助我们准确地理解数据的特性和规律。
构建方法
简单标注:在数据集中标记异常点,以便在分析时考虑。
剔除:从数据集中删除异常点,特别是在它们可能影响模型训练的情况下。
修正:更正异常点,如果它们是由于可识别的错误造成的。
特殊事件特征:
特殊事件如“双十一”、“618”、“春节”等,会在时间序列中产生显著的峰值。
构建特殊事件特征的方法包括:
事件指示器:创建一个二进制特征,当时间序列中的点与特殊事件对应时,该特征值为1,否则为0。
事件前后的时间窗口:考虑事件前后的时间窗口,以捕捉事件的影响。
上下时段信息:
- 上下时段信息指的是在时间序列中,特定时间段之前或之后的数据点。
- 这可以通过创建特征来表示数据点与特定时间段的距离来实现。
存在峰值与峰值距离:
- 识别时间序列中的峰值点,并计算其他数据点与这些峰值点的距离,可以作为特征输入模型。
时间尺度特征:
据需要预测的时间尺度(如1天、3天、5天等),创建相应的滞后特征和滚动统计特征。
优化过程

加入更多特征值
(1)历史平移特征:通过历史平移获取上个阶段的信息;
(2)差分特征:可以帮助获取相邻阶段的增长差异,描述数据的涨减变化情况。在此基础上还可以构建相邻数据比值变化、二阶差分等;
(3)窗口统计特征:窗口统计可以构建不同的窗口大小,然后基于窗口范围进统计均值、最大值、最小值、中位数、方差的信息,可以反映最近阶段数据的变化情况。
# 合并训练数据和测试数据
data = pd.concat([train, test], axis=0).reset_index(drop=True)
data = data.sort_values(['id','dt'], ascending=False).reset_index(drop=True)# 历史平移
for i in range(10,36):data[f'target_shift{i}'] = data.groupby('id')['target'].shift(i)# 历史平移 + 差分特征
for i in range(1,4):data[f'target_shift10_diff{i}'] = data.groupby('id')['target_shift10'].diff(i)# 窗口统计
for win in [15,30,50,70]:data[f'target_win{win}_mean'] = data.groupby('id')['target'].rolling(window=win, min_periods=3, closed='left').mean().valuesdata[f'target_win{win}_max'] = data.groupby('id')['target'].rolling(window=win, min_periods=3, closed='left').max().valuesdata[f'target_win{win}_min'] = data.groupby('id')['target'].rolling(window=win, min_periods=3, closed='left').min().valuesdata[f'target_win{win}_std'] = data.groupby('id')['target'].rolling(window=win, min_periods=3, closed='left').std().values# 历史平移 + 窗口统计
for win in [7,14,28,35,50,70]:data[f'target_shift10_win{win}_mean'] = data.groupby('id')['target_shift10'].rolling(window=win, min_periods=3, closed='left').mean().valuesdata[f'target_shift10_win{win}_max'] = data.groupby('id')['target_shift10'].rolling(window=win, min_periods=3, closed='left').max().valuesdata[f'target_shift10_win{win}_min'] = data.groupby('id')['target_shift10'].rolling(window=win, min_periods=3, closed='left').min().valuesdata[f'target_shift10_win{win}_sum'] = data.groupby('id')['target_shift10'].rolling(window=win, min_periods=3, closed='left').sum().valuesdata[f'target_shift10win{win}_std'] = data.groupby('id')['target_shift10'].rolling(window=win, min_periods=3, closed='left').std().values
模型融合
进行模型融合的前提是有多个模型的输出结果,比如使用catboost、xgboost和lightgbm三个模型分别输出三个结果,这时就可以将三个结果进行融合,最常见的是将结果直接进行加权平均融合。
下面我们构建了cv_model函数,内部可以选择使用lightgbm、xgboost和catboost模型,可以依次跑完这三个模型,然后将三个模型的结果进行取平均进行融合。
对于每个模型均选择经典的K折交叉验证方法进行离线评估,大体流程如下:
1、K折交叉验证会把样本数据随机的分成K份;
2、每次随机的选择K-1份作为训练集,剩下的1份做验证集;
3、当这一轮完成后,重新随机选择K-1份来训练数据;
模型融合可以在不增加模型复杂度的情况下显著提高预测性能。
然而,它也需要谨慎使用,以确保融合后的模型不会过拟合训练数据。
这些变量的详细描述如下:
clf:是一个用于调用模型的变量,它可以用来对训练数据进行训练并进行预测。train_x:是训练数据,包含了一组特征值,用于训练模型。train_y:是训练数据对应的标签,即每个训练样本对应的目标变量的值。test_x:是测试数据,用于对模型进行测试和评估。clf_name:是选择使用的模型的名称,可以根据需要从可用模型中选择合适的模型。seed:是随机种子,用于生成随机数,可以通过设置相同的随机种子来保证每次运行的结果相同。
from sklearn.model_selection import StratifiedKFold, KFold, GroupKFold
import lightgbm as lgb
import xgboost as xgb
from catboost import CatBoostRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error
def cv_model(clf, train_x, train_y, test_x, clf_name, seed = 2024):folds = 5kf = KFold(n_splits=folds, shuffle=True, random_state=seed)oof = np.zeros(train_x.shape[0])test_predict = np.zeros(test_x.shape[0])cv_scores = []for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):print('************************************ {} ************************************'.format(str(i+1)))trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]if clf_name == "lgb":train_matrix = clf.Dataset(trn_x, label=trn_y)valid_matrix = clf.Dataset(val_x, label=val_y)params = {'boosting_type': 'gbdt','objective': 'regression','metric': 'mae','min_child_weight': 6,'num_leaves': 2 ** 6,'lambda_l2': 10,'feature_fraction': 0.8,'bagging_fraction': 0.8,'bagging_freq': 4,'learning_rate': 0.1,'seed': 2023,'nthread' : 16,'verbose' : -1,}model = clf.train(params, train_matrix, 1000, valid_sets=[train_matrix, valid_matrix],categorical_feature=[], verbose_eval=200, early_stopping_rounds=100)val_pred = model.predict(val_x, num_iteration=model.best_iteration)test_pred = model.predict(test_x, num_iteration=model.best_iteration)if clf_name == "xgb":xgb_params = {'booster': 'gbtree', 'objective': 'reg:squarederror','eval_metric': 'mae','max_depth': 5,'lambda': 10,'subsample': 0.7,'colsample_bytree': 0.7,'colsample_bylevel': 0.7,'eta': 0.1,'tree_method': 'hist','seed': 520,'nthread': 16}train_matrix = clf.DMatrix(trn_x , label=trn_y)valid_matrix = clf.DMatrix(val_x , label=val_y)test_matrix = clf.DMatrix(test_x)watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]model = clf.train(xgb_params, train_matrix, num_boost_round=1000, evals=watchlist, verbose_eval=200, early_stopping_rounds=100)val_pred = model.predict(valid_matrix)test_pred = model.predict(test_matrix)if clf_name == "cat":params = {'learning_rate': 0.1, 'depth': 5, 'bootstrap_type':'Bernoulli','random_seed':2023,'od_type': 'Iter', 'od_wait': 100, 'random_seed': 11, 'allow_writing_files': False}model = clf(iterations=1000, **params)model.fit(trn_x, trn_y, eval_set=(val_x, val_y),metric_period=200,use_best_model=True, cat_features=[],verbose=1)val_pred = model.predict(val_x)test_pred = model.predict(test_x)oof[valid_index] = val_predtest_predict += test_pred / kf.n_splitsscore = mean_absolute_error(val_y, val_pred)cv_scores.append(score)print(cv_scores)return oof, test_predict# 选择lightgbm模型
lgb_oof, lgb_test = cv_model(lgb, train[train_cols], train['target'], test[train_cols], 'lgb')
# 选择xgboost模型
xgb_oof, xgb_test = cv_model(xgb, train[train_cols], train['target'], test[train_cols], 'xgb')
# 选择catboost模型
cat_oof, cat_test = cv_model(CatBoostRegressor, train[train_cols], train['target'], test[train_cols], 'cat')# 进行取平均融合
final_test = (lgb_test + xgb_test + cat_test) / 3stacking融合
一种分层模型集成框架。
以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为特征加入训练集进行再训练,从而得到完整的 stacking 模型。
第一层:(类比cv_model函数)
- 将训练数据划分为K折(例如5折),每次选择其中四份作为训练集,一份作为验证集。
- 对于每个模型(例如随机森林RF、Extra Trees ET、梯度提升机GBDT、XGBoost XGB),分别进行K次训练。
- 每次训练时,保留一份样本作为验证集,训练完成后对验证集和测试集进行预测。
- 对于测试集,每个模型会产生K个预测结果,将这些结果取平均值作为最终的测试集预测结果。
- 对于验证集,每个模型经过K次交叉验证后,所有验证集数据都会有一个预测标签。
此步骤结束后,对于训练集中的每条数据,在四个模型下分别有一个预测标签,测试集中的每条数据也会有四个模型的预测标签。
第二层:(类比stack_model函数)
- 将训练集中的四个模型的预测标签加上真实标签,共五列特征,作为新的训练集。选择一个新的训练模型,根据这个新的训练集进行训练。
- 使用测试集中四个模型的预测标签组成的新测试集进行预测,得到最终的预测结果。
这个过程首先通过交叉验证对多个基础模型进行训练和预测,然后将这些模型的预测结果作为新的特征,加上原始特征,用于训练一个新的模型。
这种方法称为模型堆叠(model stacking),可以提高模型的预测性能,尤其是在数据集较大、特征较多的情况下。通过这种方式,可以将不同模型的优点结合起来,提高整体的预测能力。
def stack_model(oof_1, oof_2, oof_3, predictions_1, predictions_2, predictions_3, y):'''输入的oof_1, oof_2, oof_3可以对应lgb_oof,xgb_oof,cat_oofpredictions_1, predictions_2, predictions_3对应lgb_test,xgb_test,cat_test'''# 将三个模型的oof预测结果合并为一个训练集train_stack = pd.concat([oof_1, oof_2, oof_3], axis=1)# 将三个模型的测试集预测结果合并为一个测试集test_stack = pd.concat([predictions_1, predictions_2, predictions_3], axis=1)# 初始化oof和预测结果数组oof = np.zeros((train_stack.shape[0],))predictions = np.zeros((test_stack.shape[0],))scores = [] # 用于存储每次交叉验证的评分# 使用RepeatedKFold进行交叉验证,重复2次,共10折from sklearn.model_selection import RepeatedKFoldfolds = RepeatedKFold(n_splits=5, n_repeats=2, random_state=2021)# 开始交叉验证for fold_, (trn_idx, val_idx) in enumerate(folds.split(train_stack, train_stack)): print("fold n°{}".format(fold_+1))# 划分训练集和验证集trn_data, trn_y = train_stack.loc[trn_idx], y[trn_idx]val_data, val_y = train_stack.loc[val_idx], y[val_idx]# 使用Ridge回归作为元模型clf = Ridge(random_state=2021)clf.fit(trn_data, trn_y)# 预测验证集并存储结果oof[val_idx] = clf.predict(val_data)# 累加测试集的预测结果,后续求平均值predictions += clf.predict(test_stack) / (5 * 2)# 计算并打印当前折的评分score_single = mean_absolute_error(val_y, oof[val_idx])scores.append(score_single)print(f'{fold_+1}/{5}', score_single)# 打印平均评分print('mean: ',np.mean(scores))# 返回oof和测试集的预测结果return oof, predictions# 调用stack_model函数进行模型融合
stack_oof, stack_pred = stack_model(pd.DataFrame(lgb_oof), pd.DataFrame(xgb_oof), pd.DataFrame(cat_oof), pd.DataFrame(lgb_test), pd.DataFrame(xgb_test), pd.DataFrame(cat_test), train['target'])
使用深度学习方案
构建基于 LSTM 的深度学习模型
导入必要的库
numpy和pandas用于数据处理。MinMaxScaler用于数据标准化。Sequential、LSTM、Dense、RepeatVector和TimeDistributed用于构建Keras模型。Adam是一种优化算法,用于模型训练。
读取训练和测试数据集
train.csv和test.csv应该是包含时间序列数据的CSV文件。
数据预处理函数 preprocess_data
- 此函数按
id对数据进行分组,并为每个id构建序列。- 对于每个
id,函数构建5个长度为look_back的序列,作为输入X,并提取相应的目标值Y。- 函数还准备了一个外推(Out-of-Time)测试数据集
OOT,用于模型预测。
模型构建函数 build_model
此函数创建一个Sequential模型,包含一个LSTM层,一个RepeatVector层,另一个LSTM层,以及一个TimeDistributed(Dense)层。
模型使用均方误差损失函数和Adam优化器进行编译。
构建和训练模型
定义序列长度
look_back,特征数量n_features和预测步长n_output。使用
preprocess_data函数预处理训练数据。使用
build_model函数构建模型。使用
model.fit方法训练模型,进行10个周期的训练。
进行预测
使用训练好的模型对
OOT数据集进行预测,得到预测值predicted_values。
实现代码
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense, RepeatVector, TimeDistributed
from keras.optimizers import Adamtrain = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')# 数据预处理
def preprocess_data(df, look_back=100):# 将数据按照id进行分组grouped = df.groupby('id')datasets = {}for id, group in grouped:datasets[id] = group.values# 准备训练数据集X, Y = [], []for id, data in datasets.items():for i in range(10, 15): # 每个id构建5个序列a = data[i:(i + look_back), 3]a = np.append(a, np.array([0]*(100-len(a))))X.append(a[::-1])Y.append(data[i-10:i, 3][::-1])# 准备测试数据集OOT = []for id, data in datasets.items():a = data[:100, 3]a = np.append(a, np.array([0]*(100-len(a))))OOT.append(a[::-1])return np.array(X, dtype=np.float64), np.array(Y, dtype=np.float64), np.array(OOT, dtype=np.float64)# 定义模型
def build_model(look_back, n_features, n_output):model = Sequential()model.add(LSTM(50, input_shape=(look_back, n_features)))model.add(RepeatVector(n_output))model.add(LSTM(50, return_sequences=True))model.add(TimeDistributed(Dense(1)))model.compile(loss='mean_squared_error', optimizer=Adam(0.001))return model# 构建和训练模型
look_back = 100 # 序列长度
n_features = 1 # 假设每个时间点只有一个特征
n_output = 10 # 预测未来10个时间单位的值# 预处理数据
X, Y, OOT = preprocess_data(train, look_back=look_back)# 构建模型
model = build_model(look_back, n_features, n_output)# 训练模型
model.fit(X, Y, epochs=10, batch_size=64, verbose=1)# 进行预测
predicted_values = model.predict(OOT)- 从 CSV 文件中读取训练集和测试集数据。
- 实现了数据预处理的函数 preprocess_data,将原始数据处理成适合模型训练和预测的格式。
- 定义了一个 LSTM 模型,包括 LSTM 层、重复向量层和时间分布层。
- 使用均方误差作为损失函数,Adam 优化器进行模型的编译。
- 训练模型并进行预测。
深度学习的优化思路
数据预处理
确保数据集的质量和多样性,包括清洗数据、处理缺失值、标准化数据等。这可以提高模型的稳定性和性能。
模型选择
选择适合问题的深度学习模型架构。可以尝试不同的模型,如卷积神经网络(CNN)、循环神经网络(RNN)等。
超参数调整
调整模型的超参数,如学习率、批量大小、正则化参数等。可以使用交叉验证或网格搜索等方法进行优化。
正则化技术
使用正则化技术来防止模型过拟合。常见的正则化技术包括 L1 和 L2 正则化、Dropout 等。
批标准化
对输入数据进行标准化,以减少内部协变量偏移并加速训练收敛速度。
数据增强
通过对数据进行变换和扩充来增加数据集的样本多样性,提高模型的泛化能力。
提前停止训练
监控模型在验证集上的性能,并在性能不再提升时提前停止训练,以避免过拟合。
迁移学习
利用预训练的模型在新的任务上进行迁移学习,可以加快模型训练的速度和提高性能。
模型集成
结合多个训练好的模型,如投票、平均等方式,以获得更好的性能。
硬件优化
利用 GPU 或 TPU 等硬件加速深度学习模型的训练和推理过程。
相关文章:
电力需求预测挑战赛笔记 Task3 #Datawhale AI 夏令营
上文: 电力需求预测挑战赛笔记 Task2 #Datawhale AI 夏令营-CSDN博客文章浏览阅读80次。【代码】电力需求预测挑战赛笔记 Task2。https://blog.csdn.net/qq_23311271/article/details/140360632 前面我们介绍了如何使用经验模型以及常见的lightgbm决策树模型来解决…...

Promise 详解(原理篇)
目录 什么是 Promise 实现一个 Promise Promise 的声明 解决基本状态 添加 then 方法 解决异步实现 解决链式调用 完成 resolvePromise 函数 解决其他问题 添加 catch 方法 添加 finally 方法 添加 resolve、reject、race、all 等方法 如何验证我们的 Promise 是否…...

动态内存经典笔试题分析
目录 1.题目一 2.题目二 3.题目三 4.题目四 1.题目一 #include<stdlib.h> #include<stdio.h> #include<string.h> void GetMemory(char* p) {p (char*)malloc(100); } void Test(void) {char* str NULL;GetMemory(str);strcpy(str, "hello world…...
单例模式)
JS设计模式(一)单例模式
注释很详细,直接上代码 本文建立在已有JS面向对象基础的前提下,若无,请移步以下博客先行了解 JS面向对象(一)类与对象写法 特点和用途: 全局访问点:通过单例模式可以在整个应用程序中访问同一个…...

uniapp动态计算并设置元素高度
<template><view><scroll-view id"sv-box" :scroll-y"true" :style"{height:navHeightpx}"></scroll-view><view id"btn-box"><button>取消</button><button>确认</button><…...

直播架构如何设计核心节点和边缘节点
在直播架构中,核心节点和边缘节点的分工及主要服务是确保直播服务稳定、高效和可扩展的关键。以下是对这些节点的详细描述: 核心节点 核心节点通常位于数据中心,负责处理直播的主要逻辑和数据处理。其主要服务包括: 直播管理后…...
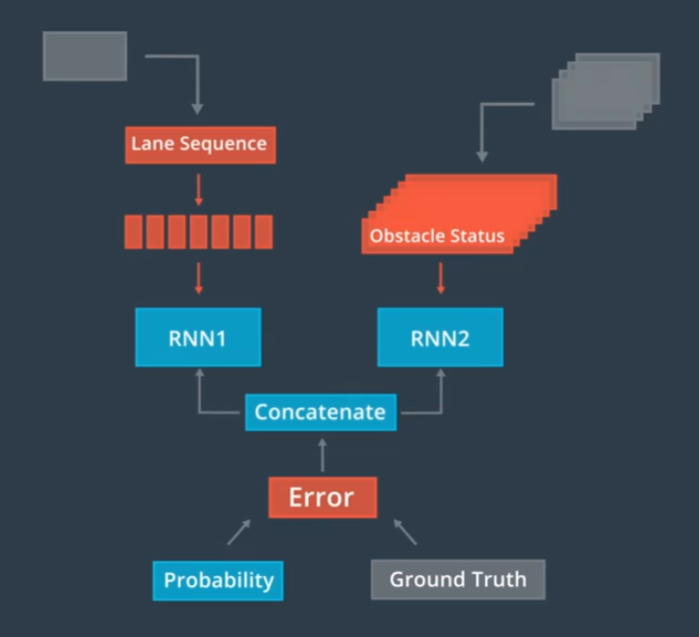
自动驾驶-预测概览
通过生成一条路径来预测一个物体的行为,在每一个时间段内,为每一辆汽车重新计算预测他们新生成的路径,这些预测路径为规划阶段做出决策提供了必要信息 预测路径有实时性的要求,预测模块能够学习新的行为。我们可以使用多源的数据…...

基于PSO算法优化PID参数的一些问题
目录 前言 Q1:惯性权重ω如何设置比较好?学习因子C1和C2如何设置? Q2:迭代速度边界设定一定能够遍历(/覆盖)整个PID参数二维空间范围吗?还是说需要与迭代次数相关?迭代次数越高&a…...

什么是决策树?
1. 什么是决策树? 决策树(Decision Tree)是一种常用的机器学习算法,用于解决分类和回归问题。它通过构建树结构来表示决策过程,分支节点表示特征选择,叶节点表示类别或回归值。 2. 决策树的组成部分 决策…...

ASP 快速参考
ASP 快速参考 概述 ASP(Active Server Pages)是一种由微软开发的服务器端脚本环境,用于动态网页设计和开发。它允许开发者创建和运行动态交互性网页,如访问数据库、发送电子邮件等。ASP页面通常以.asp为文件扩展名,并…...

(二)原生js案例之数码时钟计时
原生js实现的数字时间上下切换显示时间的效果,有参考相关设计,思路比较难,代码其实很简单 效果 代码实现 必要的样式 <style>* {padding: 0;margin: 0;}.content{/* text-align: center; */display: flex;align-items: center;justif…...

[CSS] 浮动布局的深入理解与应用
文章目录 浮动的简介元素浮动后的特点解决浮动产生的影响浮动后的影响解决浮动产生的影响 浮动相关属性实际应用示例示例1:图片与文字环绕示例2:多列布局示例3:响应式布局 总结 浮动布局是CSS中一种非常强大的布局方式,最初设计用…...

Linux云计算 |【第一阶段】ENGINEER-DAY2
主要内容: 磁盘空间管理fdisk、parted工具、开机自动挂载、文件系统、交换空间 KVM虚拟化 实操前骤: 1)添加一块硬盘(磁盘),需要关机才能进行操作,点击左下角【添加硬件】 2)选择2…...
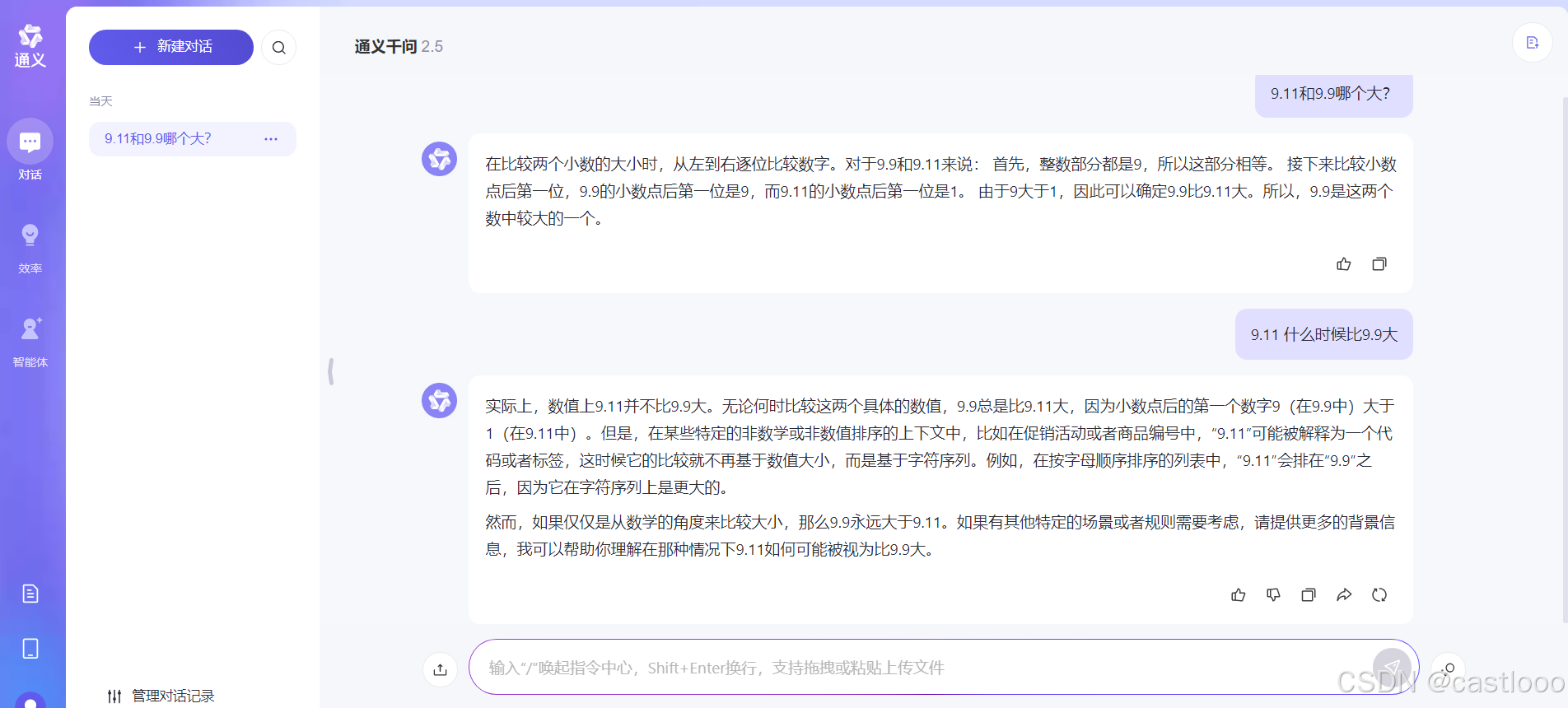
9.11和9.9哪个大?
没问题 文心一言 通义千问...
:C语言中的二进制原理及应用)
学懂C语言(十二):C语言中的二进制原理及应用
目录 1. 二进制原理 1.1 什么是二进制? 1.2 如何在C语言中表示二进制? 2. 二进制的表示 2.1 二进制和其他进制的转换 2.2 C语言中的二进制表示 3. 二进制运算 3.1 位运算符 3.2 计算过程示例 4. 应用示例 4.1 使用位运算实现开关 5. 总结 C语…...
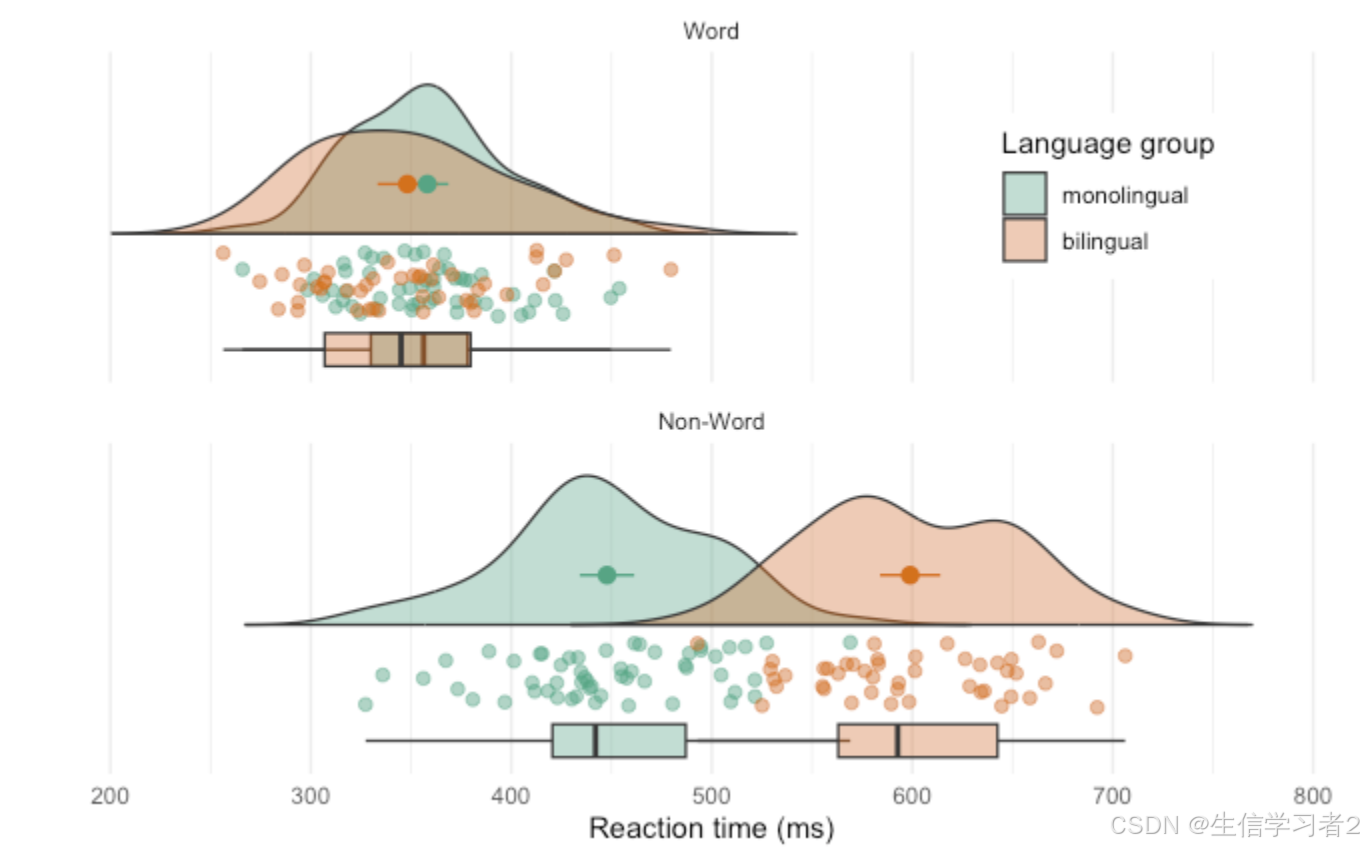
科研绘图系列:R语言雨云图(Raincloud plot)
介绍 雨云图(Raincloud plot)是一种数据可视化工具,它结合了多种数据展示方式,旨在提供对数据集的全面了解。雨云图通常包括以下几个部分: 密度图(Density plot):表示数据的分布情况,密度图的曲线可以展示数据在不同数值区间的密度。箱线图(Box plot):显示数据的中…...
优化教学流程和架构:构建高效学习环境的关键步骤
在教育领域,设计和优化教学流程和架构是提高学习效果和学生参与度的关键。本文将探讨如何通过合理的教学流程和有效的架构来构建一个高效的学习环境。 ### 1. 理解教学流程和架构的重要性 教学流程指的是教学活动的组织和顺序,而教学架构则是指支持教学…...

js | this 指向问题
https://juejin.cn/post/6844904083707396109 任何函数运行的时候,都会创建一个context对象,context对象有一个this对象,在运行的时候决定。任何函数都对应一个reference类结构体(具体叫啥有点忘了),简单就…...

《昇思 25 天学习打卡营第 15 天 | 基于MindNLP+MusicGen生成自己的个性化音乐 》
《昇思 25 天学习打卡营第 15 天 | 基于MindNLPMusicGen生成自己的个性化音乐 》 活动地址:https://xihe.mindspore.cn/events/mindspore-training-camp 签名:Sam9029 MusicGen概述 MusicGen是由Meta AI的Jade Copet等人提出的一种基于单个语言模型&…...
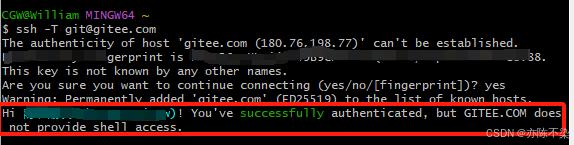
Gitee 使用教程1-SSH 公钥设置
一、生成 SSH 公钥 1、打开终端(Windows PowerShell 或 Git Bash),通过命令 ssh-keygen 生成 SSH Key: ssh-keygen -t ed25519 -C "Gitee SSH Key" 随后摁三次回车键(Enter) 2、查看生成的 SSH…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...