机器学习--特征工程常用API
1. DictVectorizer - 字典特征提取
DictVectorizer 是一个用于将字典(如Python中的字典对象)转换为稀疏矩阵的工具,常用于处理类别型特征。
DictVectorizer(sparse=True, sort=True, dtype=<class 'numpy.float64'>)
- 参数:
sparse:布尔值,默认值为True。如果为True,输出是稀疏矩阵;如果为False,输出是密集的Numpy数组。sort
当 sort=True 时,特征名称按字母顺序排序。
当 sort=False 时,特征名称的顺序是其在字典中首次出现的顺序。dtype:输出数据类型,默认为numpy.float64。
2. CountVectorizer - 文本特征提取
CountVectorizer 是一种用于将文本数据转换为词频向量的工具。
- 主要参数:
max_df:浮点数或整数,表示在文档中出现频率超过这个比例(浮点数)或超过这个绝对次数(整数)的词语将被忽略,默认值为1.0。min_df:浮点数或整数,表示在文档中出现频率低于这个比例(浮点数)或低于这个绝对次数(整数)的词语将被忽略,默认值为1。max_features:整数,选择出现频率最高的max_features个特征。stop_words:字符串或列表,指定忽略的停用词,可以选择'english'或自定义停用词列表。ngram_range:元组,表示词组的范围,如(1, 2)表示一元词和二元词。binary:布尔值,是否只考虑词是否出现(即词频为1还是0),默认值为False。
from sklearn.feature_extraction.text import CountVectorizer# 示例文本数据
corpus = ['This is the first document.','This document is the second document.','And this is the third one.','Is this the first document?',
]# 初始化CountVectorizer
vectorizer = CountVectorizer(stop_words=["you","this"])# 转换为词频向量
X = vectorizer.fit_transform(corpus)#得到稀疏矩阵# 输出特征名称和词频向量
print(vectorizer.get_feature_names_out())
print(X.toarray())#转换为矩阵
print(X)
结果:
['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third']
[[0 1 1 1 0 0 1 0][0 2 0 1 0 1 1 0][1 0 0 1 1 0 1 1][0 1 1 1 0 0 1 0]](0, 3) 1(0, 6) 1(0, 2) 1(0, 1) 1(1, 3) 1(1, 6) 1(1, 1) 2(1, 5) 1(2, 3) 1(2, 6) 1(2, 0) 1(2, 7) 1(2, 4) 1(3, 3) 1(3, 6) 1(3, 2) 1(3, 1) 1
2.1 中文文本提取
jieba是一个广泛使用的中文分词库,适用于中文文本处理和特征提取。jieba提供了高效的中文分词功能,可以帮助将中文文本转换为词语列表,从而用于机器学习模型和文本分析。
安装 jieba
你可以通过以下命令安装 jieba:
pip install jieba
基本用法
以下是一些使用 jieba 进行中文文本提取的常见操作示例:
1. 基础分词
import jieba# 示例文本
text = "我爱自然语言处理"# 使用jieba进行分词
words = jieba.cut(text)# 输出分词结果
print("/ ".join(words))
2. 精确模式和全模式
- 精确模式:试图将句子最精确地切开,适合文本分析。
- 全模式:将句子中所有可能的词语都找出来,适合用于词云展示等。
import jieba# 示例文本
text = "我爱自然语言处理"# 精确模式
words = jieba.cut(text, cut_all=False)
print("精确模式: " + "/ ".join(words))# 全模式
words = jieba.cut(text, cut_all=True)
print("全模式: " + "/ ".join(words))
结果:
精确模式: 我/ 爱/ 自然语言/ 处理
全模式: 我/ 爱/ 自然/ 自然语言/ 语言/ 处理
3. 关键词提取
jieba 还提供了关键词提取功能,基于 TF-IDF 算法或者 TextRank 算法。需要额外安装 jieba 的 jieba.analyse 模块。
import jieba.analyse# 示例文本
text = "我爱自然语言处理。自然语言处理是计算机科学领域和人工智能领域中的一个重要方向。"# 提取关键词
keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=False)print("关键词: " + "/ ".join(keywords))
结果:
关键词: 自然语言/ 领域/ 处理/ 计算机科学/ 人工智能
4. 自定义词典
如果你有一些专有名词或者行业术语,jieba 允许你使用自定义词典来提高分词的准确性。
import jieba# 加载自定义词典
jieba.load_userdict('userdict.txt')# 示例文本
text = "我在腾讯工作"# 使用自定义词典进行分词
words = jieba.cut(text)
print("/ ".join(words))
自定义词典 userdict.txt 的格式如下:
腾讯 10 n
其中,每行包含一个词汇,词汇后面的数字表示词频(可选),词性(可选)。
3. TfidfVectorizer - TF-IDF文本特征提取
TfidfVectorizer 用于计算词语的TF-IDF(词频-逆文档频率)特征,衡量词语在文档中的重要性。
TfidfVectorizer 是 scikit-learn 提供的一个工具,用于将文本数据转换为 TF-IDF 特征矩阵。TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征表示方法,用于衡量词语在文档中的重要性。下面是 TfidfVectorizer 的工作原理及其详细解释:
TF-IDF 原理
-
Term Frequency (TF)
-
定义:词频,衡量词语在某个文档中出现的频率。

-
解释:词频越高,说明该词在该文档中越重要。
-
-
Inverse Document Frequency (IDF)
-
定义:逆文档频率,衡量词语在所有文档中出现的稀有程度。

-
解释:出现频率较低的词语(即少数文档中出现的词语)会有较高的 IDF 值,从而提高其在文档中的权重。
-
-
TF-IDF Score
-
定义:词语在文档中的 TF-IDF 权重,结合了词频和逆文档频率。

-
解释:通过 TF-IDF 评分,重要的词语(即在该文档中频繁出现而在其他文档中不常见的词语)会得到较高的权重。
-
-
主要参数:
max_df:同CountVectorizer。min_df:同CountVectorizer。max_features:同CountVectorizer。stop_words:同CountVectorizer。ngram_range:同CountVectorizer。use_idf:布尔值,是否启用逆文档频率(IDF)加权,默认值为True。smooth_idf:布尔值,是否加1平滑IDF,默认值为True。norm:字符串,表示归一化方法,'l1'或'l2',默认值为'l2'。
-
适用场景:适用于文本数据中特征词重要性分析,更适合文本分类任务。
代码示列:
from sklearn.feature_extraction.text import TfidfVectorizer# 示例文本数据
corpus = ['This is the first document.','This document is the second document.','And this is the third one.','Is this the first document?',
]# 初始化TfidfVectorizer
vectorizer = TfidfVectorizer()# 转换为TF-IDF特征向量
X = vectorizer.fit_transform(corpus)# 输出特征名称和TF-IDF向量
print(vectorizer.get_feature_names_out())
print(X.toarray())
结果:
['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third' 'this']
[[0. 0.46979139 0.58028582 0.38408524 0. 0.0.38408524 0. 0.38408524][0. 0.6876236 0. 0.28108867 0. 0.538647620.28108867 0. 0.28108867][0.51184851 0. 0. 0.26710379 0.51184851 0.0.26710379 0.51184851 0.26710379][0. 0.46979139 0.58028582 0.38408524 0. 0.0.38408524 0. 0.38408524]]
4. MinMaxScaler - 归一化
MinMaxScaler 将特征缩放到给定的最小值和最大值之间,通常是缩放到 [0, 1]。
MinMaxScaler 是一种常用的数据预处理方法,其主要目的是将数据的特征缩放到指定的范围(通常是 ([0, 1]))。这样做的目的是为了消除不同特征值之间量级上的差异,从而避免因不同特征值的范围差异对模型训练产生不良影响。
MinMaxScaler的数学原理
假设我们有一个一维的特征向量 (X = {x_1, x_2, \dots, x_n}),其中每个 (x_i) 表示第 (i) 个样本的特征值。
1. 计算原始数据的最小值和最大值
首先,找到特征向量 (X) 中的最小值 (X_{\text{min}}) 和最大值 (X_{\text{max}}),即:
X min = min ( X ) X max = max ( X ) X_{\text{min}} = \min(X) X_{\text{max}} = \max(X) Xmin=min(X)Xmax=max(X)
2. 应用缩放公式
接下来,使用以下公式将每个数据点 (x_i) 映射到目标范围 ([a, b]) 中(默认为 ([0, 1])):
x i ′ = x i − X min X max − X min × ( b − a ) + a x_i' = \frac{x_i - X_{\text{min}}}{X_{\text{max}} - X_{\text{min}}} \times (b - a) + a xi′=Xmax−Xminxi−Xmin×(b−a)+a
- (x_i’) 是缩放后的值。
- (a) 和 (b) 是目标范围的下限和上限,默认是 (a = 0) 和 (b = 1)。
- (X_{\text{min}}) 和 (X_{\text{max}}) 分别是原始数据的最小值和最大值。
3. 线性变换过程
公式中的变换可以分为两个步骤:
-
标准化:先减去最小值,然后除以原始数据的范围(最大值减去最小值),即:
x i ∗ = x i − X min X max − X min x_i^* = \frac{x_i - X_{\text{min}}}{X_{\text{max}} - X_{\text{min}}} xi∗=Xmax−Xminxi−Xmin
这一步骤将 (x_i) 变换到 ([0, 1]) 的范围内。 -
线性扩展:将标准化后的值 (x_i^
$$
扩展到目标范围 (a, b):x_i’ = x_i^* \times (b - a) + a
$$
这一步将数据映射到我们希望的范围内。
示例详解
假设有一个简单的数据集: X = [2, 4, 6, 8, 10] ,目标范围是 ([0, 1])。
-
计算 ( X_{\text{min}} = 2 ) 和 ( X_{\text{max}} = 10 )。
-
使用公式计算每个 ( x_i ) 的缩放值 ( x_i’ ):
-
对于 ( x = 2 ):
x ′ = 2 − 2 10 − 2 × ( 1 − 0 ) + 0 = 0 x' = \frac{2 - 2}{10 - 2} \times (1 - 0) + 0 = 0 x′=10−22−2×(1−0)+0=0 -
对于 ( x = 4 ):
x ′ = 4 − 2 10 − 2 × ( 1 − 0 ) + 0 = 0.25 x' = \frac{4 - 2}{10 - 2} \times (1 - 0) + 0 = 0.25 x′=10−24−2×(1−0)+0=0.25 -
对于 ( x = 6 ):
x ′ = 6 − 2 10 − 2 × ( 1 − 0 ) + 0 = 0.5 x' = \frac{6 - 2}{10 - 2} \times (1 - 0) + 0 = 0.5 x′=10−26−2×(1−0)+0=0.5 -
对于 ( x = 8 ):
x ′ = 8 − 2 10 − 2 × ( 1 − 0 ) + 0 = 0.75 x' = \frac{8 - 2}{10 - 2} \times (1 - 0) + 0 = 0.75 x′=10−28−2×(1−0)+0=0.75 -
对于 ( x = 10 ):
x ′ = 10 − 2 10 − 2 × ( 1 − 0 ) + 0 = 1 x' = \frac{10 - 2}{10 - 2} \times (1 - 0) + 0 = 1 x′=10−210−2×(1−0)+0=1
-
转换后的数据集为 ([0, 0.25, 0.5, 0.75, 1])。
-
主要参数:
feature_range:元组,表示缩放后的特征范围,默认值为(0, 1)。clip:布尔值,是否将数据截断到指定范围内,默认值为False。
-
适用场景:适用于需要将特征值缩放到相同范围的情况,特别是当模型对特征的范围敏感时,如在神经网络中。
代码示列:
from sklearn.preprocessing import MinMaxScaler# 示例数据
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]# 初始化MinMaxScaler
scaler = MinMaxScaler()# 转换数据
scaled_data = scaler.fit_transform(data)# 输出归一化后的数据
print(scaled_data)
结果:
[[0. 0. ][0.25 0.25][0.5 0.5 ][1. 1. ]]




5. StandardScaler - 标准化
StandardScaler 将特征进行标准化,使其均值为0,方差为1。
-
主要参数:
with_mean:布尔值,是否将特征均值设为0,默认值为True。with_std:布尔值,是否将特征方差设为1,默认值为True。
-
适用场景:适用于需要将特征缩放到标准正态分布的场景,常用于线性模型和基于距离的模型。
代码示列:
from sklearn.preprocessing import StandardScaler# 示例数据
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]# 初始化StandardScaler
scaler = StandardScaler()# 转换数据
scaled_data = scaler.fit_transform(data)# 输出标准化后的数据
print(scaled_data)
结果:
[[-1.18321596 -1.18321596][-0.50709255 -0.50709255][ 0.16903085 0.16903085][ 1.52127766 1.52127766]]
StandardScaler 是一种常用的数据预处理方法,其主要目的是对数据进行标准化处理,使得数据的均值为0,标准差为1。通过标准化,StandardScaler 可以消除不同特征之间的量纲差异,并且使数据更适合于一些基于距离度量的机器学习算法,如SVM、KNN等。
StandardScaler的数学原理
StandardScaler 的标准化过程涉及两个步骤:
- 中心化:将数据的均值调整为0。
- 缩放:将数据的标准差调整为1。
对于一个给定的数据集
X = { x 1 , x 2 , … , x n } X = \{x_1, x_2, \dots, x_n\} X={x1,x2,…,xn}
(假设这里的数据是单个特征的值),StandardScaler 的标准化公式如下:
x i ′ = x i − μ σ x_i' = \frac{x_i - \mu}{\sigma} xi′=σxi−μ
其中:
- $$
- x_i 是原始数据中的某个数据点。
- \mu 是原始数据的均值。
- \sigma 是原始数据的标准差。
- x_i’ 是标准化后的数据。
$$
步骤 1:计算均值和标准差
1. 计算均值
μ \mu μ
均值 μ 是所有数据点的平均值,可以通过以下公式计算: μ = 1 n ∑ i = 1 n x i 均值 \mu 是所有数据点的平均值,可以通过以下公式计算: \mu = \frac{1}{n} \sum_{i=1}^{n} x_i 均值μ是所有数据点的平均值,可以通过以下公式计算:μ=n1i=1∑nxi
2.
计算标准差 σ 计算标准差 \sigma 计算标准差σ
标准差 σ 是数据点到均值的平均偏离程度的平方根,可以通过以下公式计算: σ = 1 n ∑ i = 1 n ( x i − μ ) 2 标准差 \sigma 是数据点到均值的平均偏离程度的平方根,可以通过以下公式计算: \sigma = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (x_i - \mu)^2} 标准差σ是数据点到均值的平均偏离程度的平方根,可以通过以下公式计算:σ=n1i=1∑n(xi−μ)2
步骤 2:应用标准化公式
计算出均值 μ 和标准差 σ 之后,对每个数据点 x i 使用以下公式进行标准化处理: x i ′ = x i − μ σ 计算出均值 \mu 和标准差 \sigma 之后,对每个数据点 x_i 使用以下公式进行标准化处理: x_i' = \frac{x_i - \mu}{\sigma} 计算出均值μ和标准差σ之后,对每个数据点xi使用以下公式进行标准化处理:xi′=σxi−μ
6. VarianceThreshold - 底方差过滤降维
VarianceThreshold 是一种简单的特征选择方法,通过移除方差低于某个阈值的特征来进行降维。
4.底方差过滤(Variance Thresholding)的数学原理可以通过以下几个步骤详细解释:
1. 方差定义
方差是用来衡量数据分布的离散程度的统计量。对于给定的特征 X (假设是一个向量),其方差 σ 2 可以通过以下公式计算: 方差是用来衡量数据分布的离散程度的统计量。对于给定的特征 X (假设是一个向量),其方差 \sigma^2 可以通过以下公式计算: 方差是用来衡量数据分布的离散程度的统计量。对于给定的特征X(假设是一个向量),其方差σ2可以通过以下公式计算:
σ X 2 = 1 N ∑ i = 1 N ( x i − x ˉ ) 2 \sigma^2_X = \frac{1}{N} \sum_{i=1}^{N} (x_i - \bar{x})^2 σX2=N1i=1∑N(xi−xˉ)2
其中:
- $$
- N 是样本的总数,
- x_i 是特征 X 的第 i 个样本,
- \bar{x} 是特征 X 的均值。
$$
2. 方差计算过程
假设我们有一个数据矩阵 X (大小为 m × n ,其中 m 是样本数, n 是特征数),我们可以对每一个特征列 X j 计算方差。对于特征 X j ,其方差可以表示为 假设我们有一个数据矩阵 X (大小为 m \times n ,其中m是样本数,n是特征数),我们可以对每一个特征列 X_j 计算方差。对于特征X_j,其方差可以表示为 假设我们有一个数据矩阵X(大小为m×n,其中m是样本数,n是特征数),我们可以对每一个特征列Xj计算方差。对于特征Xj,其方差可以表示为
:
σ X j 2 = 1 m ∑ i = 1 m ( X i j − X j ˉ ) 2 \sigma^2_{X_j} = \frac{1}{m} \sum_{i=1}^{m} (X_{ij} - \bar{X_j})^2 σXj2=m1i=1∑m(Xij−Xjˉ)2
其中:
- $$
- X_{ij}是第i个样本的第j个特征值,
- \bar{X_j}是第j个特征的均值。
$$
3. 设置方差阈值
为了进行特征选择,我们需要设置一个方差阈值 ( \tau )。这个阈值可以是固定的,也可以根据数据集的统计特性(例如方差的均值或标准差)来设定。常见的选择方法包括:
-
选择一个绝对阈值,例如
τ = 0.01 \tau = 0.01 τ=0.01 -
选择一个相对阈值,例如选取方差在所有特征方差中的某个百分位(如前 50%)。
-
主要参数:
threshold:浮点数,表示方差阈值,默认值为0.0(即移除所有方差为零的特征)。
-
适用场景:适用于删除对模型贡献较小的低方差特征,通常是为了减少噪音和维度。
代码示列:
import numpy as np
from sklearn.feature_selection import VarianceThreshold# 创建一个示例数据集 (m样本, n特征)
X = np.array([[1, 2, 3, 4],[2, 2, 3, 4],[3, 2, 3, 4],[4, 2, 3, 4]
])print("原始数据集:")
print(X)# 设置方差阈值 (0.1)
threshold = 0.1# 初始化 VarianceThreshold 对象
selector = VarianceThreshold(threshold=threshold)# 拟合并转换数据
X_reduced = selector.fit_transform(X)print("\n经过底方差过滤后的数据集:")
print(X_reduced)
结果:
原始数据集:
[[1 2 3 4][2 2 3 4][3 2 3 4][4 2 3 4]]经过底方差过滤后的数据集:
[[1][2][3][4]]
7. PCA - 主成分分析降维
-
主成分分析(Principal Component Analysis, PCA)是一种用于降维的线性变换方法,主要目的是通过构造一组新的变量(称为主成分),这些主成分是原始数据中方差最大的方向上的线性组合。PCA可以最大限度地保留数据的方差信息,同时减少数据的维度,通过线性变换将高维数据映射到低维空间,同时尽量保留数据的方差。。
-
主要参数:
n_components:整数或浮点数,指定保留的主成分数。如果是浮点数,则表示保留的方差比例。如果未指定,则保留所有成分。whiten:布尔值,是否将成分向量标准化为单位方差,默认值为False。svd_solver:字符串,指定奇异值分解的算法,可以选择'auto'、'full'、'arpack'、或'randomized'。tol:浮点数,svd_solver=’arpack’时使用的容差,默认值为0.0。random_state:整数或None,指定随机数生成器的种子。
-
适用场景:适用于数据降维、去噪和可视化,同时保留数据的主要信息。
import numpy as np
from sklearn.decomposition import PCA
data = np.array([[2.5, 2.4],[0.5, 0.7],[2.2, 2.9],[1.9, 2.2],[3.1, 3.0],[2.3, 2.7],[2, 1.6],[1, 1.1],[1.5, 1.6],[1.1, 0.9]
])# 初始化PCA并指定主成分数
pca = PCA(n_components=2)# 降维
reduced_data = pca.fit_transform(data)print("降维后的数据:\n", reduced_data)
相关文章:
机器学习--特征工程常用API
1. DictVectorizer - 字典特征提取 DictVectorizer 是一个用于将字典(如Python中的字典对象)转换为稀疏矩阵的工具,常用于处理类别型特征。 DictVectorizer(sparseTrue, sortTrue, dtype<class numpy.float64>)参数: spar…...

块级LoRA:个性化与风格化在文本到图像生成中的新突破
人工智能咨询培训老师叶梓 转载标明出处 文本到图像生成技术的核心目标是教会预训练模型根据输入的文本提示生成具有特定主题和风格的新颖图像。尽管已有多种微调技术被提出,但它们在同时处理个性化和风格化方面仍存在不足,导致生成的图像在个人身份和风…...
)
redis的数据结构——压缩表(Ziplist)
压缩表(Ziplist)是Redis中一种紧凑的数据结构,主要用于节省内存。它通常被用于存储少量的字符串或小整数,尤其在列表类型(List)和哈希类型(Hash)中。当数据量较小或数据本身占用内存较少时,Redis会选择用压缩表来存储数据,以减少内存开销。 压缩表的基本结构 压缩表…...

探索未知,悦享惊喜 —— 您的专属盲盒一番赏小程序盛大开启
在这个充满奇遇与惊喜的时代,每一份未知都蕴藏着无限可能。为了将这份独特的乐趣带到您的指尖,我们精心打造了“悦赏盲盒”小程序,一个集潮流、趣味、收藏于一体的全新互动平台,让每一位用户都能享受到拆盲盒的乐趣,发…...

dompdf导出pdf中文乱码显示问号?
环境:PHP 8.0 框架:ThinkPHP 8 软件包:phpoffice/phpword 、dompdf/dompdf 看了很多教程(包括GitHub的issue、stackoverflow)都没有解决、最终找到解决问题的根本! 背景:用Word模板做转PDF…...

韩顺平Java-第二十四章:MYSQL基础篇
一 数据库 1 数据库简单原理图 2 使用命令行窗口连接MYSQL数据库 (1)mysql -h 主机名 -P 端口 -u 用户名 -p密码; (2)登录前,保证服务启动。 3 MySQL三层结构 (1)所谓安装MySQL数…...

【动态规划算法题记录】最长/最大 问题汇总 (leetcode)
目录 32. 最长有效括号思路代码 300. 最长递增子序列思路代码 674. 最长连续递增序列思路1:双指针代码1:双指针思路2:dp代码2:dp 718. 最长重复子数组思路1:dp代码1:dp思路2:dp优化代码2&#x…...

2020 位示图
2020年网络规划设计师上午真题解析36-40_哔哩哔哩_bilibili 假设某计算机的字长为32位,该计算机文件管理系统磁盘空间管理采用位示图(bitmap),记录磁盘的使用情况。若磁盘的容量为300GB,物理块的大小为4MB,…...

富格林:防止陷入黑幕欺诈平台
富格林指出,不少投资者因未做好投资准备而不慎误入黑幕欺诈平台,造成了不必要的亏损。投资者在投资前,需要时刻保持警惕,根据市场行情,作出有依据的投资决定,而不是依赖黑幕欺诈平台的噱头进行投资。建议投…...

Cookie、Session 、token
Cookie 优点: 简单易用: 浏览器自动管理 Cookie 的发送和接收。持久性: 可以设置过期时间,使其可以在浏览器关闭后依旧存在。广泛支持: 所有现代浏览器都支持 Cookie。 缺点: 安全性问题: 存储在客户端,容易被查看和篡改。敏感信息不应直接存储在 Co…...

Json-类型映射使用TypeFactory或者TypeReference
当你需要将JSON数据转换为Java中的复杂类型时,可以使用Jackson库中的TypeFactory或 者TypeReference。这两种方式可以帮助你处理复杂的泛型类型,例如 List<Map<String, Object>> 或者 Map<String, List<Object>>。 示例 1: 使用 TypeFactory 和 T…...
Linux shell编程学习笔记73:sed命令——沧海横流任我行(上)
0 前言 在大数据时代,我们要面对大量数据,有时需要对数据进行替换、删除、新增、选取等特定工作。 在Linux中提供很多数据处理命令,如果我们要以行为单位进行数据处理,可以使用sed。 1 sed 的帮助信息,功能ÿ…...

内网渗透之icmp隧道传输
原理 # 为什么要建立隧道 在实际的网络中,通常会通过各种边界设备软/硬件防火墙、入侵检测系统来检查对外连接的情况,如果发现异常,会对通信进行阻断。 # 什么是隧道 就是一种绕过端口屏蔽的方式,防火墙两端的数据包通过防火墙…...

【C++ 第十五章】map 和 set 的封装(封装红黑树)
1. map 和 set 的介绍 ⭐map 与 set 分别是STL中的两种序列式容器; 它们是一种树形数据结构的容器,且其的底层构造为一棵红黑树; 而在上一篇文章中提到,其实红黑树本身就是一棵二叉搜索树,是基于二叉搜索树的性质对其增加了平衡的属性来提高其综合性能 ⭐当然也…...

LIN通讯
目录 1 PLinApi.h 2 TLINFrameEntry 结构体 3 自定义函数getTLINFrameEntry 4 TLINScheduleSlot 结构体 5 自定义函数 getTLINScheduleSlot 6 自定义LIN_SetScheduleInit函数 7 自定义 LIN_StartSchedule 8 发送函数 9 线程接收函数 1 PLinApi.h 这是官方头文件 ///…...
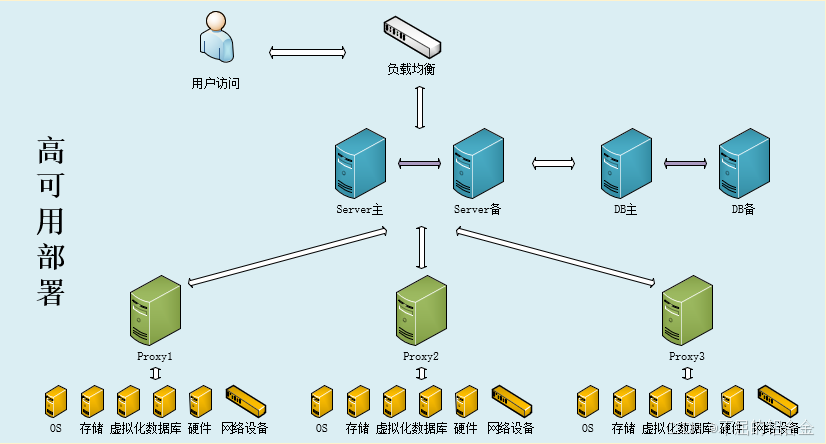
zabbix常见架构及组件
Zabbix作为一个开源的、功能全面的监控解决方案,广泛应用于各类组织中,以实现对网络、服务器、云服务及应用程序性能的全方位监控。部署架构灵活性高,可支持从小型单一服务器环境到大型分布式系统的多种场景。基本架构通常包括监控端…...
plsql表格怎么显示中文 plsql如何导入表格数据
在Oracle数据库开发中,PL/SQL Developer是一款广泛使用的集成开发环境(IDE),它提供了丰富的功能来帮助开发人员高效地进行数据库开发和管理。在使用PL/SQL Developer时,许多用户会遇到表格显示中文的问题,以…...

chromedriver下载地址大全(包括124.*后)以及替换exe后仍显示版本不匹配的问题
Chrome for Testing availability CNPM Binaries Mirror 若已经更新了系统环境变量里的chromdriver路径下的exe,仍显示版本不匹配: 则在cmd界面输入 chromedriver 会跳出version verison与刚刚下载好的exe不匹配,则再输入: w…...

拦截器实现 Mybatis Plus 打印含参数的 SQL 语句
1.实现拦截器 package com.sample.common.interceptor;import com.baomidou.mybatisplus.extension.plugins.inner.InnerInterceptor; import lombok.extern.slf4j.Slf4j; import org.apache.ibatis.executor.Executor; import org.apache.ibatis.mapping.BoundSql; import or…...

Oracle Subprogram即Oracle子程序
Oracle Subprogram,即Oracle子程序,是Oracle数据库中存储的过程(Procedures)和函数(Functions)的统称。这些子程序是存储在数据库中的PL/SQL代码块,用于执行特定的任务或操作。下面详细介绍Orac…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...
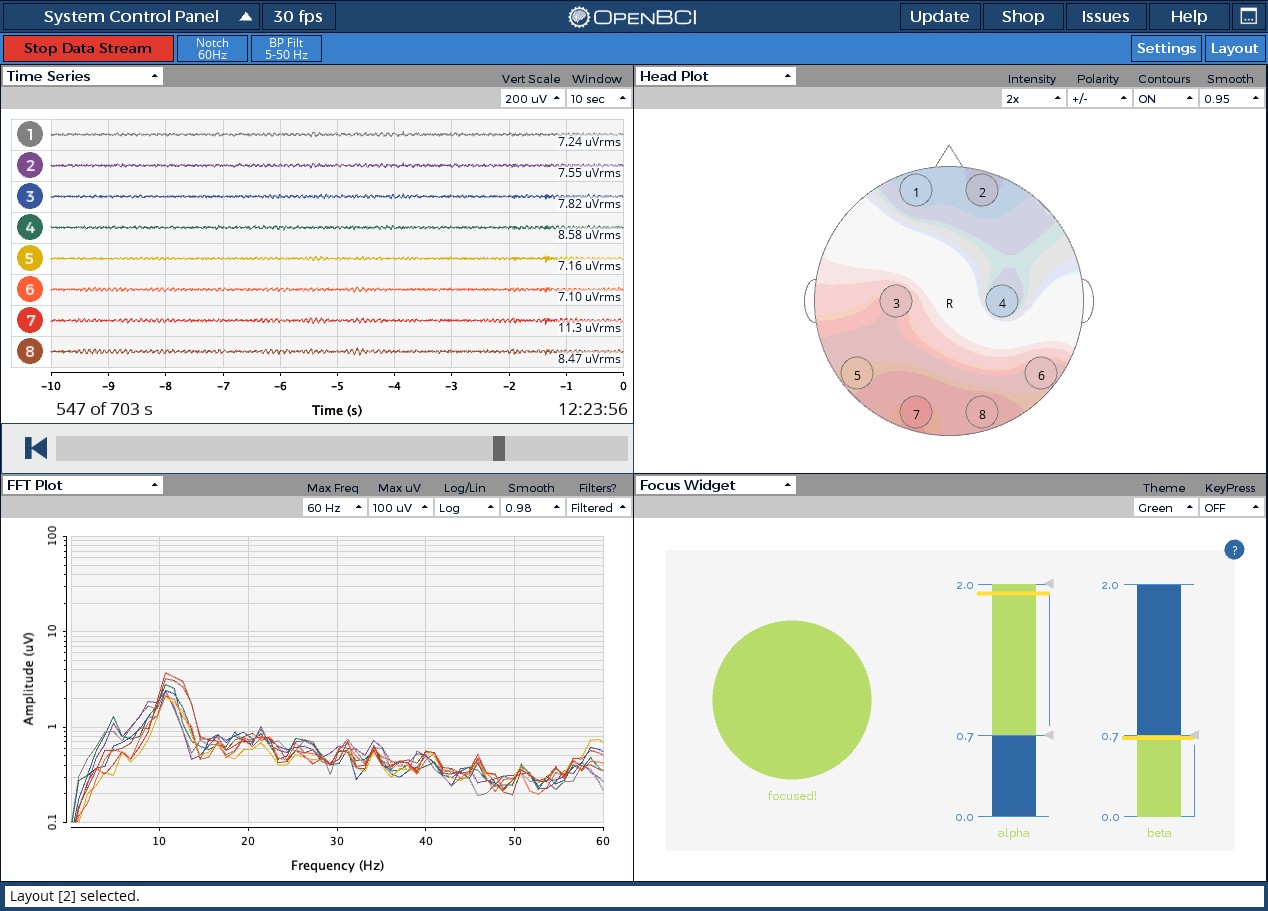
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...
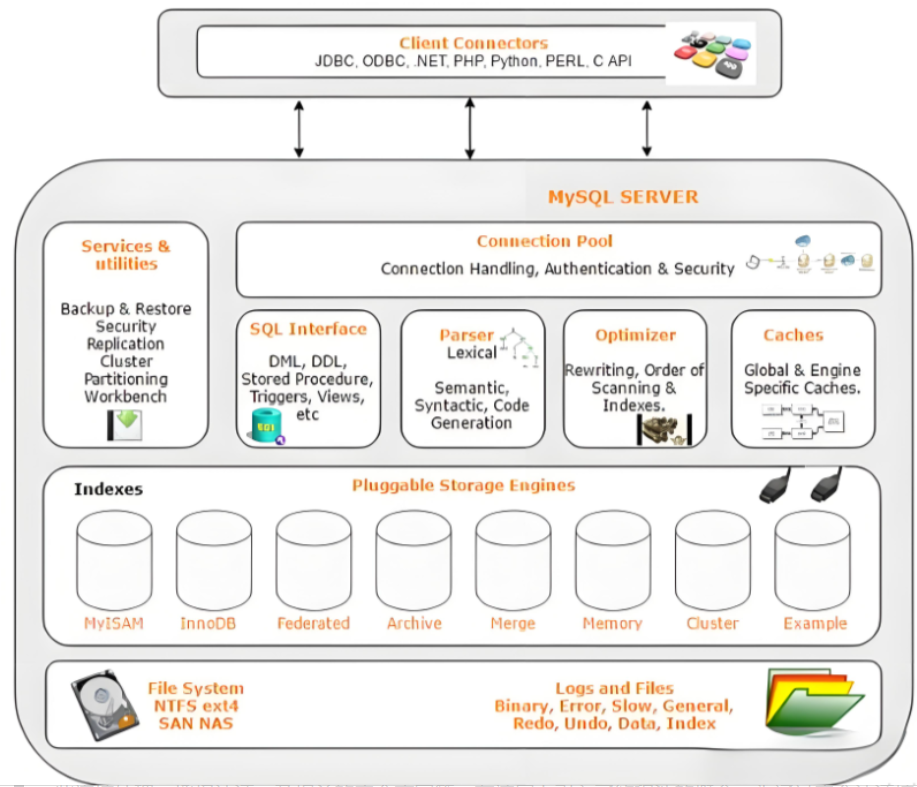
Mysql故障排插与环境优化
前置知识点 最上层是一些客户端和连接服务,包含本 sock 通信和大多数jiyukehuduan/服务端工具实现的TCP/IP通信。主要完成一些简介处理、授权认证、及相关的安全方案等。在该层上引入了线程池的概念,为通过安全认证接入的客户端提供线程。同样在该层上可…...