大数据-214 数据挖掘 机器学习理论 - KMeans Python 实现 算法验证 sklearn n_clusters labels
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(正在更新…)
章节内容
上节我们完成了如下的内容:
- KMeans Python 实现
- 距离计算函数
- 质心函数
- 聚类函数

算法验证
函数编写完成后,先以 testSet 数据集测试模型运行效果(为了可以直观看出聚类效果,此处采用一个二维数据集进行验证)。testSet 数据集是一个二维数据集,每个观测值都只有两个特征,且数据之间采用空格进行分隔,因此可以使用 pd.read_table() 函数进行读取。
testSet = pd.read_table('testSet.txt', header=None)
testSet.head()
testSet.shape
执行结果如下图是:

然后利用二维平面图观察其分布情况:
plt.scatter(testSet.iloc[:,0], testSet.iloc[:,1]);
执行结果如下图所示:

可以大概看出数据大概分布在空间的四个角上,后续我们对此进行验证。然后利用我们刚才编写的 K-Means 算法对其进行聚类,在执行算法之前需要添加一列虚拟标签列(算法是从倒数第二列开始计算特征值,因此这里需要人为增加多一列到最后)
label = pd.DataFrame(np.zeros(testSet.shape[0]).reshape(-1, 1))
test_set = pd.concat([testSet, label], axis=1, ignore_index = True)
test_set.head()
执行结果如下图所示:

带入算法进行计算,根据二维平面坐标点的分布特征,我们可以考虑设置四个质心,即将其分为四个簇,并简单的查看运算结果:
test_cent, test_cluster = kMeans(test_set, 4)
test_cent
test_cluster.head()
执行结果如下图所示:

将分类结果进行可视化展示,使用 scatter 函数绘制不同分类点不同颜色的散点图,同时将质心也放入同一张图中进行观察:
import matplotlib.pyplot as plt# 绘制聚类点
plt.scatter(test_cluster.iloc[:, 0], test_cluster.iloc[:, 1], c=test_cluster.iloc[:, -1], cmap='viridis')# 绘制聚类中心
plt.scatter(test_cent[:, 0], test_cent[:, 1], color='red', marker='x', s=100)# 设置图形的标题和轴标签
plt.title('Cluster Plot with Centroids')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')# 显示图形
plt.show()执行结果如下图所示:

生成的图片如下所示:

sklearn实现 K-Means
from sklearn.cluster import KMeans# KMeans 初始化示例
kmeans = KMeans(n_clusters=8, # 聚类数量init='k-means++', # 初始化质心的方法n_init=10, # KMeans 算法重新运行的次数(初始质心选择不同)max_iter=300, # 最大迭代次数tol=0.0001, # 容忍度,控制收敛的阈值verbose=0, # 控制输出日志的详细程度random_state=None, # 随机种子控制聚类的随机性copy_x=True, # 是否复制 X 数据algorithm='auto' # 使用的 KMeans 算法,'auto' 已弃用,建议使用 'lloyd'
)# 执行示例数据集上的 KMeans
# 例如,假设你有一个数据集 X:
# kmeans.fit(X)n_clusters
n_clusters 是 K-Means 中的 k ,表示着我们告诉模型我们要分几类,这是 K-Means当中唯一一个必填的参数,默认为 8 类,但通常我们聚类结果是一个小于 8 的结果,通常,在开始聚类的之前,我们并不知道 n_clusters 究竟是多少,因此我们要对它进行探索。
当我们拿到一个数据集,如果可能的话,我们希望能够通过绘图先观察一下这个数据集的数据分布,以此来为我们聚类时输入的 n_clusters 做一个参考。
首先,我们来自己创建一个数据集,这样的数据集是我们自己创建的,所以是有标签的。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs# 创建数据集
X, y = make_blobs(n_samples=500, n_features=2, centers=4, random_state=1)# 可视化数据集
plt.figure(figsize=(6, 6))
plt.scatter(X[:, 0], X[:, 1], marker='o', s=8) # s=8 表示点的大小
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Scatter plot of generated blobs')
plt.show()对应结果如下图所示:

生成的图片如下所示:

查看分布的情况:
import matplotlib.pyplot as plt# 查看数据分布
color = ["red", "pink"]
for i in range(2): # 由于 y 只有 0 和 1 两类,因此只需要两个循环plt.scatter(X[y == i, 0], X[y == i, 1], marker='o', # 点的形状s=8, # 点的大小c=color[i]) # 颜色plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Scatter Plot of Two Classes')
plt.show()执行结果如下图所示:

对应的图片如下所示:

基于这个分布,我们来使用 K-Means 进行聚类。
首先,我们要猜测一下,这个数据中有几个簇?
cluster.labels
重要属性 labels_,查看聚好的类别,每个样本所对应的类
from sklearn.cluster import KMeans
from sklearn.datasets import load_breast_cancer
import numpy as np# 加载数据集
data = load_breast_cancer()
X = data.data# 定义聚类的簇数
n_clusters = 3# 使用KMeans进行聚类
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)# 获取聚类结果的标签
y_pred = cluster.labels_# 输出聚类的标签
print(y_pred)- K-Means 因此并不需要建立模型或者预测结果,因此我们只需要 fit 就能够得到聚类结果了
- K-Means 也有接口 predict 和 fit_predict
- predict 表示学习数据 X 并对 X 的类进行预测(对分类器 fit 之后,再预测)
- fit_predict 不需要分类器.fit()之后都可以预测
- 对于全数据而言,分类器 fit().predict 的结果 = 分类器.fit_predict(X) = cluster.labels
执行结果如下图所示:

我们什么时候需要 predict?当数据量太大的时候,当我们数据量非常大,我们可以使用部分数据来帮助我们确认质心。
剩下的数据的聚类结果,使用 predict 来调用:
cluster_smallsub = KMeans(n_clusters=3, random_state=0).fit(X[:200])
sample_pred = cluster_smallsub.predict(X)
y_pred == sample_pred
执行结果如下图所示:

但这样的结果,肯定与直接 fit 全部数据会不一致,有时候,当我们不要求那么精确,或者我们的数据量实在太大,那我们可以使用这样的做法。
相关文章:
大数据-214 数据挖掘 机器学习理论 - KMeans Python 实现 算法验证 sklearn n_clusters labels
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

算法通关(3) -- kmp算法
KMP算法的原理 从题目引出 有两个字符串s1和s2,判断s1字符串是否包含s2字符串,如果包含返回s1包含s2的最左开头位置,不包含返回-1,如果是按照暴力的方法去匹配,以s1的每个字符作为开头,用s2的整体去匹配,…...

5G网卡network connection: disconnected
日志 5G流程中没有报任何错误,但是重新拿地址了,感觉像是驱动层连接断开了,dmesg中日志如下: [ 1526.558377] ippassthrough:set [ ip10.108.40.47 mask27 ip_net10.108.40.32 router10.108.40.33 dns221.12.1.227 221.12.33.227] br-lan […...

微积分复习笔记 Calculus Volume 1 - 4.9 Newton’s Method
4.9 Newton’s Method - Calculus Volume 1 | OpenStax...

Flutter自定义矩形进度条实现详解
在Flutter应用开发中,进度条是一个常见的UI组件,用于展示任务的完成进度。本文将详细介绍如何实现一个支持动画效果的自定义矩形进度条。 功能特点 支持圆角矩形外观平滑的动画过渡效果可自定义渐变色可配置边框宽度和颜色支持进度更新动画 实现原理 …...

如何设置 TORCH_CUDA_ARCH_LIST 环境变量以优化 PyTorch 性能
引言 在深度学习领域,PyTorch 是一个广泛使用的框架,它允许开发者高效地构建和训练模型。为了充分利用你的 GPU 硬件,正确设置 TORCH_CUDA_ARCH_LIST 环境变量至关重要。这个变量告诉 PyTorch 在构建过程中应该针对哪些 CUDA 架构版本进行优…...

CSS的三个重点
目录 1.盒模型 (Box Model)2.位置 (position)3.布局 (Layout)4.低代码中的这些概念 在学习CSS时,有三个概念需要重点理解,分别是盒模型、定位、布局 1.盒模型 (Box Model) 定义: CSS 盒模型是指每个 HTML 元素在页面上被视为一个矩形盒子。…...

【笔记】前后端互通中前端登录无响应
后来的前情提要 : 后端的ip地址在本地测试阶段应该设置为localhost 前端中写cors的配置 后端也要写cors的配置 且两者的url都要为localhost 前端写的baseUrl是指定对应的后端的ip地址以及端口号 很重要 在本地时后端的IP的地址也必须为本地的 F12的网页报错是&a…...

AI引领PPT创作:迈向“免费”时代的新篇章?
AI引领PPT创作:迈向“免费”时代的新篇章? 在信息爆炸的时代,演示文稿(PPT)作为传递信息和展示观点的重要工具,其制作效率和质量直接关系到演讲者的信息传递效果。随着人工智能(AI)…...

HTB:Perfection[WriteUP]
目录 连接至HTB服务器并启动靶机 1.What version of OpenSSH is running? 使用nmap对靶机TCP端口进行开放扫描 2.What programming language is the web application written in? 使用浏览器访问靶机80端口页面,并通过Wappalyzer查看页面脚本语言 3.Which e…...

鸿蒙next打包流程
目录 下载团结引擎 添加开源鸿蒙打包支持 打包报错 路径问题 安装DevEcoStudio 可以在DevEcoStudio进行打包hap和app 包结构 没法直接用previewer运行 真机运行和测试需要配置签名,DevEcoStudio可以自动配置, 模拟器安装hap提示报错 安装成功,但无法打开 团结1.3版本新增工具…...

uni-app 实现自定义底部导航
原博:https://juejin.cn/post/7365533404790341651 在开发微信小程序,通常会使用uniapp自带的tabBar实现底部图标和导航,但现实有少量应用使用uniapp自带的tabBar无法满足需求,这时需要自定义底部tabBar功能。 例如下图的需求&am…...

Vue前端开发:animate.css第三方动画库
在实际的项目开发中,如果自定义元素的动画,不仅效率低下,代码量大,而且还存在浏览器的兼容性问题,因此,可以借助一些优秀的第三动画库来协助完成动画的效果,如animate.css和gsap动画库ÿ…...

Java中的I/O模型——BIO、NIO、AIO
1. BIO(Blocking I/O) 1. 1 BIO(Blocking I/O)模型概述 BIO,即“阻塞I/O”(Blocking I/O),是一种同步阻塞的I/O模式。它的主要特点是,当程序发起I/O请求(比如…...
)
【软考知识】敏捷开发与统一建模过程(RUP)
敏捷开发模式 概述敏捷开发的主要特点包括:敏捷开发的常见实践包括:敏捷开发的优势:敏捷开发的挑战:敏捷开发的方法论: ScrumScrum 的核心概念Scrum 的执行过程Scrum 的适用场景 极限编程(XP)核…...
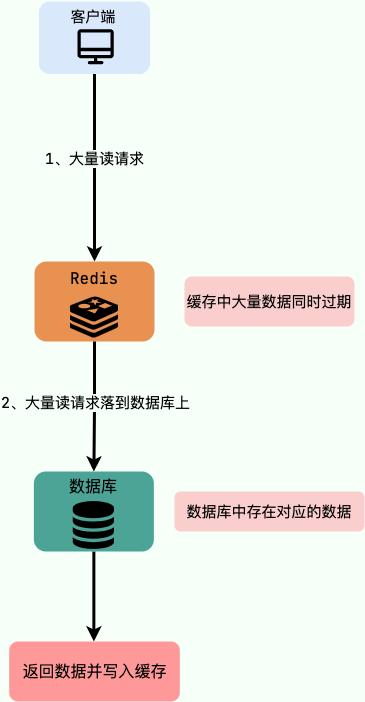
Redis常见面试题(二)
Redis性能优化 Redis性能测试 阿里Redis性能优化 使用批量操作减少网络传输 Redis命令执行步骤:1、发送命令;2、命令排队;3、命令执行;4、返回结果。其中 1 与 4 消耗时间 --> Round Trip Time(RTT,…...
业务模块部署
一、部署前端 1.1 window部署 下载业务模块前端包。 (此包为耐威迪公司发布,请联系耐威迪客服或售后获得) 包名为:业务-xxxx-business (注:xxxx为发布版本号) 此文件部署位置为:……...

【LeetCode】【算法】48. 旋转图像
LeetCode 48. 旋转图像 题目描述 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 思路 思路:再次拜见K神…...

【STM32F1】——9轴姿态模块JY901与串口通信(上)
【STM32F1】——9轴姿态模块JY901与串口通信(上) 一、简介 本篇主要对调试JY901模块的过程进行总结,实现了以下功能。 串口普通收发:使用STM32F103C8T6的USART2实现9轴姿态模块JY901串口数据的读取,并利用USART1发送到串口助手。 串口DMA收发:使用STM32F103C8T6的USART…...

Docker网络概述
1. Docker 网络概述 1.1 网络组件 Docker网络的核心组件包括网络驱动程序、网络、容器以及IP地址管理(IPAM)。这些组件共同工作,为容器提供网络连接和通信能力。 网络驱动程序:Docker支持多种网络驱动程序,每种驱动程…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...