JavaSE(十四)——文件操作和IO
文章目录
- 文件操作和IO
- 文件相关概念
- Java操作文件
- 文件系统操作
- 文件内容操作
- 字节流
- FileOutputStream
- FileInputStream
- 代码演示
- 字符流
- FileWriter
- FileReader
- 代码演示
- 缓冲流
- 转换流
- 案例练习
文件操作和IO
文件相关概念
文件 通常指的是包含用户数据的文件,如文本文件、图像文件、音频文件等。这些文件有具体的扩展名,存储实际的数据内容。
如下图:

上面描述的其实是狭义的文件,更广义的文件可以指代任何可以通过文件系统接口进行操作的资源(“一切皆文件”),在此描述下例如设备文件、管道、套接字等都被视为文件。
但是我们这里涉及的讨论主要还是针对狭义的文件。接下来,我们会介绍两个后续不断会提到的概念:目录 和 路径。
-
目录
- 概念:目录是文件系统的组织结构,用于存储文件和其他目录。目录其实就是文件夹。
- 目录是文件吗? 目录被视为文件,只不过它的内容是目录项而不是用户数据,目录实际上是一个包含目录项的特殊文件。
-
路径
-
概念:用于描述文件系统中从根目录或当前目录到某个特定文件或目录的地址。路径可以用来区分或识别文件,例如某个路径:
C:\Program Files\Java\jdk-17 -
分类:路径分为绝对路径 和 相对路径 两种类型。
-
绝对路径:从根目录开始到目标文件或目录的完整路径。
一个文件的绝对路径是唯一的,在大多数操作系统中,绝对路径总是以根目录(如Windows中的驱动器字母)开始。例如:
C:\Users\dell\text.txt就是text.txt文件的绝对路径 -
相对路径:相对路径是相对于当前工作目录的路径,它不从根目录开始。
准确来说,相对路径需要一个基准路径,只不过这个基准路径通常是当前工作目录的路径,正因为如此,相对路径是非唯一的。
-
-
举个例子,详细解释一下相对路径:C:\Users\dell\text.txt中text.txt的相对路径是什么,这要取决于基准路径的选择:
.表示当前所在的目录位置;..表示上一级目录
- 基准路径是
C:\Users\dell:- 相对路径:
text.txt或者.\text.txt - 解释:从
C:\Users\dell开始,text.txt就在当前目录下
- 相对路径:
- 基准路径是
C:\Users:- 相对路径:
dell\text.txt或者.\dell\text.txt - 解释:从
C:\Users开始,需要进入dell子目录才能找到text.txt
- 相对路径:
- 基准路径是
C:\:- 相对路径:
Users\dell\text.txt或者.\Users\dell\text.txt - 解释:从
C:\开始,需要依次进入Users、dell才能找到text.txt
- 相对路径:
- 基准路径是
C:\Users\dell\subdir:- 相对路径:
..\text.txt - 解释:从
C:\Users\dell\subdir开始,需要返回上一级目录C:\Users\dell才能找到text.txt
- 相对路径:
有关路径分隔符使用
/(斜杠)还是\(反斜杠)的问题:
/是通用的,大多数操作系统都将它作为路径分隔符
\是Windows操作系统特有的,并且通常是默认的(作者笔记本就是Windows操作系统,所以上面的介绍都采用了\)。Windows。同时,Windows也是支持
/。
为什么Windows会默认将
\作为默认路径分隔符呢?这其实是一个历史遗留问题,Windows的前身是DOS,DOS采用
\作为路径分隔符,所以这个习惯就被保留下来了。
我们平时描述路径时尽量还是使用
/(斜杠)作为路径分隔符,因为这是通用的,同时在许多现代编程语言中\作为转义字符,\\才能表示反斜杠,这是不方便的。
从开发的角度看,文件可以简单分为 文本文件 和 二进制文件。
所有的文件最终都是以二进制形式存储的。在这些文件中,有些文件的二进制数据可以按照特定的字符编码标准(如ASCII、UTF-8、UTF-16等)被解释为字符。当二进制数据恰好符合这些字符编码标准时,这些文件被称为文本文件;剩下的文件中的二进制数据不能直接被解释为字符,或者即使能被解释为字符,这些字符也没有意义,这些文件就是所谓的二进制文件。
两者具体的对比:
| 文本文件 | 二进制文件 | |
|---|---|---|
| 可读性 | 人类可读,可以直接用记事本查看和编辑 | 人类不可读,需要特定的程序或工具来解析 |
| 文件大小 | 通常较大,因为字符编码占用空间 | 通常较小,因为直接存储原始数据 |
| 效率 | 较低,需要更多的字节表示相同的信息 | 较高,因为减少了编码解码的步骤 |
| 用途 | 源代码文件(如.c、.java)、日志文件(如.log)、配置文件(如.ini)等 | 编译后的文件(如.class、.exe)、库文件(如.so)、数据文件(如.bin)等 |
Java操作文件
在介绍文件操作前,我们必须先简单理解几个概念及其它们的关系,这些概念包括:IO、流、
IO 是一个比较广泛的概念,指计算机的输入和输出操作。流 是处理数据传输的一种抽象机制,分为字节流 和 字符流。流实际上是对IO的进一步抽象。
- 字节流是用于处理二进制数据的流。字节流每次读取一个字节,适用于处理图片、音频等二进制文件。字符集不涉及字符编码转换,因此可以处理任何形式的二进制数据。
- 字符流是用于处理字符数据的流。每次读写一个字符(通常是Unicode字符),适用于处理文本文件。字符流自动处理字符编码的转换,使得处理文本数据十分方便。
字节流和字符流并不严格对应二进制文件和文本文件,而是根据数据的处理方式区分的。
例如,要复制一个文本文件,在这个场景下,我们并不关心文本文件的内容,因此直接使用字节流完成复制任务即可。
文件只是IO的一个应用领域,Java中有关文件的操作涉及到两个包java.io和java.nio,它们适合不同的应用场景,我们要介绍的是java.io中的一些常用组件。
文件系统操作
文件系统操作指的是创建文件、删除文件、移动文件、对文件重命名等不涉及文件内容的操作。File类是java.io包中唯一代表磁盘文件本身的组件,它定义了一系列文件系统操作方法。因此这一部分围绕 File 类展开。
构造方法
常见构造方法:
| 构造方法 | 说明 |
|---|---|
| File(String pathname) | 根据文件路径创建一个File实例,路径可以是绝对路径,也可以是相对路径 |
| File(String parent, String child) | 将父路径字符串和子路径字符串组合起来,创建一个File实例 |
| File(File parent, String child) | 将抽象的父路径和子路径字符串组合,创建一个File实例 |
- 通过上述构造方法只是实例化了一个代表某个文件的File实例,并不会创建文件。 实例化File对象时,这个文件可以存在也可以不存在
//绝对路径创建File实例
File file1 = new File("C:/Demo/test1.txt");
//相对路径创建File实例
File file2 = new File("./test2.txt");
- 根据相对路径创建的File实例默认选中当前工作目录,当前工作目录是由启动程序的方式决定的。 例如,如果采用IDEA启动,后续通过代码创建的文件会在项目目录中。
常用方法
| 方法 | 说明 |
|---|---|
| String getParent() | 返回 File 对象的父目录文件路径 |
| String getName() | 返回 File 对象的纯文件名词 |
| String getPath() | 返回 File 对象的文件路径 |
| String getAbsolutePath() | 返回 File 对象的绝对路径 |
| String getCanonicalPath() | 返回 File 对象的修饰过的路径 |
| ——————————(分隔线) | |
| boolean exists() | 判断 File 对象描述的文件是否真实存在 |
| boolean isDirectory() | 判断 File 对象代表的文件是否是一个已存在目录 |
| boolean isFile() | 判断 File 对象代表的文件是否是一个已存在的普通文件 |
| boolean createNewFile() | 根据 File 对象,创建一个文件。成功创建后返回true,如果文件已经存在,返回false |
| boolean delete() | 根据 File 对象,删除文件或空目录。如果目录中包含文件或其他子目录,delete() 方法将返回 false,表示删除操作失败。 |
| void deleteOnExit() | 根据 File 对象,标注文件将被删除,删除行为会在JVM运行结束时进行 |
| File createTempFile(String prefix, String suffix) | 根据prefix前缀字符串和suffix后缀字符串创建一个新的空文件,该文件在默认临时文件目录中。需要手动删除 |
| ——————————(分隔线) | |
| String[] list() | 返回 File 对象代表的目录下的所有文件名,如果代表的不是目录,返回null |
| String[] list(FilenameFilter filter) | 返回指定目录中符合 FilenameFilter 过滤条件的所有文件名。 |
| File[] listFiles() | 返回 File 对象代表的目录下的所有文件的File对象,如果代表的不是目录,返回null |
| File[] listFiles(FilenameFilter filter) | 返回指定目录中符合 FilenameFilter 过滤条件的所有文件的File对象。 |
| boolean mkdir() | 创建 File 对象代表的目录,如果代表的不是目录,返回false,代表创建失败 |
| boolean mkdirs() | 创建 File 对象代表的目录,如果必要,会创建中间目录 |
| boolean renameTo(File dest) | 对 File 对象代表的文件重命名,dest代表新的文件或目录的 File 对象,类似于剪切、粘贴操作 |
| boolean canRead() | 判断用户是否对文件有可读权限 |
| boolean canWrite() | 判断用户是否对文件有可写权限 |
- 如表格演示,将常用方法分成三部分,演示时也会分成三部分。
【第一部分演示】
public class Demo5 {public static void main(String[] args) throws IOException {File file1 = new File("C:/Demo/test1.txt");File file2 = new File("./test2.txt");System.out.println("fil1的打印演示:");System.out.println(file1.getParent());System.out.println(file1.getName());System.out.println(file1.getPath());System.out.println(file1.getAbsolutePath());System.out.println(file1.getCanonicalPath());System.out.println();System.out.println("file2的打印演示:");System.out.println(file2.getParent());System.out.println(file2.getName());System.out.println(file2.getPath());System.out.println(file2.getAbsolutePath());System.out.println(file2.getCanonicalPath());}
}
- 通过打印结果可以看出:
getParent()返回的父路径形式与构造File对象时的参数有关,如file2的返回值是.getName()返回的就是文件名getPath()返回的结果也与构造File对象的参数有关getAbsolutePath()返回绝对路径,但仍可能存在符号链接、相对路径以及.、..等getCanonicalPath()返回规范路径,消除了符号链接、相对路径、.、..等,同时如果文件不存在或路径无效,可能会抛出IOException异常。
【第二部分演示】
public class Demo6 {public static void main(String[] args) throws IOException {File file = new File("C:/Demo/test.txt");//判断是否真实存在System.out.println(file.exists());//创建出来file.createNewFile();//判断类型System.out.println(file.isFile());System.out.println(file.isDirectory());//删除并判断是否成功file.delete();System.out.println(file.exists());}
}

delete()方法只能删除普通文件和空目录,如果不是空目录,将无法删除。 如果想要删除一个非空目录,必须递归逐个删除。
private static void deleteDir(File dir) {if(!dir.isDirectory()) {return;}File[] files = dir.listFiles();//空目录if(files == null) {dir.delete();}else {for(int i = 0; i < files.length; i++) {if(files[i].isFile()) {files[i].delete();}else {deleteDir(files[i]);}}}//删除自己dir.delete();}
deleteOnExit()方法 和 createTempFile(String prefix, String suffix)通常配合使用,以确保临时文件在程序退出时自动删除。
public class Demo8 {public static void main(String[] args) throws IOException {//创建临时文件File tempFile = File.createTempFile("test", ".txt");//查看是否创建成功System.out.println(tempFile.exists());//设置JVM运行结束后删除tempFile.deleteOnExit();//判断JVM结束前,deleteOnExit()后,是否存在System.out.println(tempFile.exists());}
}

【第三部分演示】
list()、listFiles()以及它们的重载版本都不会递归地返回子目录的内容,只返回当前目录下的文件和子目录的列表。
list()和listFiles()的带参数的重载版本list(FilenameFilter filter)和listFiles(FilenameFilter filter)中的FilenameFilter是一个函数式接口,称为文件过滤器。只有一个抽象方法boolean accept(File dir, String name),用来指定文件名的过滤规则,符合条件的(规则下返回true)文件名将被保留,不符合过滤条件的(规则下返回false)的文件将被过滤掉,带FilenameFilter文件过滤器类型参数的list()或listFiles()方法最终会返回符合过滤条件的所有文件名或者文件的File对象。
public class Demo9 {public static void main(String[] args) {File file = new File("C:/Demo");//使用没有文件过滤器的list方法返回C:/Demo目录下的所有文件名String[] files1 = file.list();//使用带有文件过滤器的list方法过滤出名字包含"test"的文件名String[] files2 = file.list((dir, name) -> name.contains("test"));//打印查看效果System.out.println(Arrays.toString(files1));System.out.println(Arrays.toString(files2));}
}

前面的删除非空目录的代码中其实已经包含了遍历目录中所有文件的操作,就是利用listFiles()拿到所有的文件对象数组,然后遍历对象数组,如果是目录,就递归遍历这个目录,整体就是一个递归方法,这里不再演示。
public class Demo10 {public static void main(String[] args) {File dir = new File("C:/Demo/newSubDemo1");//这个File实例代表的文件的中间目录Demo已经存在File dirs = new File("C:/Demo/newSubDemo2/newSubDemo3");//这个File实例代表的文件的中间目录newSubDemo2不存在System.out.println("Demo目录是否存在:" + dir.getParentFile().exists());System.out.println("newSubDemo2目录是否存在:" + dirs.getParentFile().exists());System.out.println("newSubDemo1目录是否存在:" + dir.exists());System.out.println("newSubDemo3目录是否存在:" + dirs.exists());System.out.println("使用mkdir创建中间目录均存在的目录,是否成功:" + dir.mkdir());System.out.println("使用mkdir创建中间目录不存在的目录,是否成功:" + dirs.mkdir());System.out.println("使用mkdirs创建中间目录不存在的目录,是否成功:" + dirs.mkdirs());}
}

- 上述代码验证了:
mkdir()和mkdirs()方法均能创建目录,但mkdir()方法不能创建中间目录不存在的目录,而mkdirs()方法在必要时能够创建中间目录。
public class Demo11 {public static void main(String[] args) {File srcFile = new File("C:/Demo/demo1.txt");File dstFile = new File("C:/Demo/newDemo1.txt");System.out.println(srcFile.exists());System.out.println(dstFile.exists());System.out.println(srcFile.renameTo(dstFile));}
}

-
renameTo(File dest)方法的调用者代表的文件 和 参数代表的文件的关系:调用者:表示要被重命名的源文件或目录。
参数:表示新的文件名或者路径。
-
如果调用者代表的文件不存在,则方法直接返回
false -
如果参数代表的文件已经存在,在Windows系统下不会覆盖已有文件,即方法返回
false -
明确
renameTo()方法不只是重命名,它有类似于剪切粘贴的功能
文件内容操作
文件内容操作即对文件的内容进行操作,包括读写文件。对文件内容的操作是通过流实现的,可以通过字节流 或 字符流操作文件内容,同时使用缓冲流提高读写效率,还可以使用转换流实现字节流和字符流的转换。因此我们将讨论java.io中与这四种流相关的组件。
在开始介绍前,我们得先理解什么是输入什么是输出,输入和输出是站在CPU的角度考虑的,而不是站在我们的角度,因此:
- 读文件是输入
- 写文件是输出
字节流
InputStream 和 OutputStream 类是 java.io 包中与字节流相关的所有组件的基类。这两个类是抽象类,提供了处理字节流的基本方法和框架。与文件相关的字节流类主要是 FileInputStream 和 FileOutputStream。这两个类分别用于从文件中读取字节和将字节写入文件。
为了方便演示,我们会在介绍完FileInputStream和FileOutputStream后一起演示。
FileOutputStream
常用构造方法
| 构造方法 | 说明 |
|---|---|
| FileOutputStream(String name) | 根据字符串构造,默认的覆盖写入模式 |
| FileOutputStream(String name, boolean append) | 根据字符串构造,可以指定模式:true(追加模式);false(覆盖写入模式) |
| FileOutputStream(File file) | 根据File对象构造,默认的覆盖写入模式 |
| FileOutputStream(File file, boolean append) | 根据File对象构造,可以指定模式:true(追加模式);false(覆盖写入模式) |
- 如果用于构造
FileOutputStream的字符串或File对象所指向的文件不存在,那么在第一次尝试写入时,Java 会自动创建这个文件。 - 如果文件已经存在,并且是覆盖写入模式,那么文件中的原有内容将被删除,新的内容将从头开始写入;如果是追加模式,那么新写入的数据将会被添加到文件的末尾,原有的内容将被保留。
- 如果试图使用
FileOutputStream写入一个目录而不是一个文件,Java 将抛出一个FileNotFoundException异常。
常用方法
| 方法 | 说明 |
|---|---|
| void write(int b) | 写入最低的8位(即最低的一个字节) |
| void write(byte b[]) | 将 b 字节数组中的数据全部写入 |
| void write(byte b[], int off, intlen) | 将 b 字节数组中从 off 开始的 len 个数据写入 |
| void close() | 关闭字节流 |
| void flush() | 立即刷新输出流,将缓冲区中的数据立即写入 |
-
完成文件操作后一定要调用
close()方法释放资源,否则可能会出现文件资源泄露的问题。 -
实际情况中很少使用
flush()方法,flush()方法一般在close()时自动调用。 -
FileOutputStream类(包括后面的FileInputStream等类)代表字节流,但为什么write(int b)需要一个int类型的参数?-
表示范围和返回值
采用
int类型可以确保方法能够处理更大的范围,尽管write(int b)只会写入最低位的一个字节。同时,某些情况下write方法可能需要返回值来表示写入操作的结果,尽管实际上write方法没有返回值,但这种设计为未来的扩展留下了空间 -
历史遗留
Java的I/O流设计借鉴了C语言的I/O库。C语言习惯使用
int类型。
-
-
write(byte b[])比write(int b)更常用,因为前者的字节数组一次可以写入多个字节,减少了系统调用次数,提高了写入效率;字节数组作为缓存,批量写入数据,减少了文件I/O次数,提高了I/O操作的性能;处理更复杂的数据,例如从网络接收的数据通常都是以字节数组的方式存在的。
浅谈文件资源泄露问题:
每个进程都会有一个PCB来描述进程中的某些属性,其中就包含文件描述符表。每当打开一个文件,都会申请一个表项,如果我们打开了大量的文件但是不关闭释放资源时,文件描述符表就会爆满进而发生错误,即出现了严重的文件资源泄露问题。
tip: 文件描述符表不会自动扩容。这是因为:
- 操作系统有资源限制,不允许单个进程申请过多的资源。
- 文件描述符表是操作系统内核的一部分,内核空间的内存管理十分严格,不允许随意扩展。
- 另外,如果允许一个文件描述符表过大,那么整个表的查找和管理性能就会大打折扣。
FileInputStream
常用构造方法
| 构造方法 | 说明 |
|---|---|
| FileInputStream(String name) | 根据文件路径构造文件输入流 |
| FileInputStream(File file) | 根据 File 对象构造文件输入流 |
- 如果所指向的文件不存在 或者 文件存在但是一个目录,Java将会抛出
FileNotFoundException异常
常用方法
| 方法 | 说明 |
|---|---|
| int read() | 从输入流中读取一个字节的数据,返回 -1 表示读完 |
| int read(byte b[]) | 从输入流中最多读取 b.length 个字节的数据到字节数组b中,返回实际读取的数量, -1 代表读完 |
| int read(byte b[], int off, int len) | 从输入流中读取最多 len 个字节的数据,读到的数据存放到字符数组b中,从off位置开始存,方法返回实际读取的数量,-1 代表读完 |
| void close() | 关闭字节流 |
-
有参数的
read方法读到的数据都存放在参数byte b[]字符数组中,即b数组既作为参数,又用于“返回值”,这种参数我们称之为 输出型参数。之所以可以这么做,是因为数组类型实际上是一个引用类型。可以这么理解输出型参数:字符数组想象成一个饭盒,
read方法想象成餐厅,我们将饭盒给餐厅(打饭阿姨),餐厅就会还给我们一个盛满饭的饭盒。 -
一次读取多个字节的
read方法会更常用,原因是字节数组可以作为缓存数组,同上介绍。 -
读操作执行完毕后及时
close()
代码演示
Java 7引入了
try-with-resources语法,旨在简化资源管理,特别是对于那些必须显式关闭以防止资源泄漏的对象,如我们接下来要讲的文件输入输出流。
try-with-resources语法特性:
使用方法:
try后的括号内实例化资源对象,仍可以使用catch捕获异常以及finally语句。同时,try括号内可以声明多个资源,每个资源之间用分号隔开。try (ResourceType resource = new ResourceType()) {// 使用资源的代码 } catch (ExceptionType1 e1) {// 处理异常 } finally {// 可选的finally块 }使用条件:
- 资源对象必须在
try括号内初始化(创建)- 必须实现
AutoCloseable接口(意味着包括所有实现了Closeable接口的类)使用优势:自动关闭资源而不需要手动调用
close方法,资源(对象)会在try代码块结束时自动关闭,不论是否发生异常。这减少了由于关闭资源而造成的潜在错误或内存泄漏风险,使得程序员可以更专注于业务逻辑。
public class Demo14 {public static void main(String[] args) throws FileNotFoundException {//写文件try(FileOutputStream outputStream = new FileOutputStream("D:/DemoFile/INNER/demo.txt")) {outputStream.write(97);outputStream.write(98);outputStream.write('B');outputStream.write(new byte[]{'a', 'b', 'c'});outputStream.write('难');} catch (IOException e) {e.printStackTrace();}//读文件try(FileInputStream inputStream = new FileInputStream("D:/DemoFile/INNER/demo.txt")) {while(true) {byte[] buf = new byte[1024];int r = inputStream.read(buf);if(r == -1) {break;}for(int i = 0; i < r; i++) {System.out.println(buf[i]);}}} catch (IOException e) {e.printStackTrace();}}
}

-
这段代码使用
try-with-resources语法同时演示了FileOutputStream和FileInputStream,以覆盖写入的方式尝试写入:97、98、‘B’、‘a’、‘b’、‘c’、‘难’,读文件并打印结果如图。前6行打印分别对应97、98、‘B’、‘a’、‘b’、‘c’,而最后一行打印的结果是-66(对应尝试写入’难’),具体原因是:
汉字字符通常占2~4个字节,而
write(int b)方法实际只会写入最低的8位(一个字节),这就导致汉字字符的数据写入不完整,只写入了最低的一个字节,因此打印时只打印出一个字节的内容,-66就是汉字的最低8位的内容,这块内容是没有任何实际意义的。 -
列举一种正确写入汉字字符的方法:
public class Demo15 {public static void main(String[] args) {//向文件写入汉字字符try(FileOutputStream fileOutputStream = new FileOutputStream("D:/DemoFile/INNER/demo.txt")) {String test = "你好";byte[] data = test.getBytes();fileOutputStream.write(data);} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}//读文件并以十六进制打印try(FileInputStream fileInputStream = new FileInputStream("D:/DemoFile/INNER/demo.txt")) {while(true) {byte[] buf = new byte[1024];int r = fileInputStream.read(buf);if(r == -1) {break;}for(int i = 0; i < r; i++) {System.out.printf("%x\n", buf[i]);}}} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}} }
针对汉字(或包含汉字)字符串,使用
getBytes()得到对应的字节数组,再利用write(byte b[])方法写入文件,此时就不会发生数据写入不完整的问题了;打印时采用十六进制的方式打印结果如上图,e4、bd、a0 代表 ‘你’,e5、a5、bd 代表 ‘好’,这里采用了UTF-8的编码方式,我们可以从编码转换网站中验证一下:
字符流
前面提到,采用字节流的方式省去了编码解码的过程,性能相对较快,但是我们发现如果以字节流的方式读取文件,得到的结果是不可读的,需要手动查询,如果想要程序返回可读结果,我们还需要手动编写解码程序,解码工作是相对复杂且难以理解的 并降低了开发效率。因此,实际情况下我们更常用字符流的方式读文件,解码和编码的转换工作会由底层封装的逻辑自动进行。
接下来我们开始介绍字符流相关API:Writer 和 Reader 类是 java.io 包中与字符流相关的所有组件的基类。这两个类是抽象类,提供了处理字符流的基本方法和框架。与文件相关的字符流类主要是 FileReader 和 FileWriter。这两个类用于以字符为单位进行文件读写操作。
FileWriter
常用构造方法
| 构造方法 | 说明 |
|---|---|
| FileWriter(String fileName) | 根据字符串构造,默认的覆盖写入模式 |
| FileWriter(String fileName, boolean append) | 根据字符串构造,可以指定模式:true(追加模式);false(覆盖写入模式) |
| FileWriter(File file) | 根据File对象构造,默认的覆盖写入模式 |
| FileWriter(File file, boolean append) | 根据File对象构造,可以指定模式:true(追加模式);false(覆盖写入模式) |
- 注意问题与
FileOutputStream类相同(FileWriter内部使用了FileOutputStream):自动创建、追加模式和覆盖写入模式、异常的抛出。
常用方法
| 方法 | 说明 |
|---|---|
| void write(int c) | 接受一个 int 类型,将其转换为字符后写入文件 |
| void write(String str) | 将整个字符串写入文件 |
| void write(char[] cbuf) | 将字符数组中的所有元素写入文件 |
| void write(String str, int off, int len) | 从 off 位置开始,将字符串 str 写入文件,共写入 len 个字符 |
| void write(char[] cbuf, int off, int len) | 从 off 位置开始,将字符数组写入文件,共写入 len 个元素(字符) |
| void close() | 关闭字符流 |
| void flush() | 立即刷新输出流,将缓冲区中的数据立即写入 |
- 同样的注意问题:
- 及时
close释放资源,避免文件资源泄露 - 通常使用一次性写入多个字符的
write方法,原因就在于减少系统调用次数并有缓存作用
- 及时
FileReader
常用构造方法
| 构造方法 | 说明 |
|---|---|
| FileReader(String fileName) | 根据文件路径构造文件输入流 |
| FileReader(File file) | 根据 File 对象构造文件输入流 |
常用方法
| 方法 | 说明 |
|---|---|
| int read() | 从输入流中读取一个字符并返回其Unicode编码形式的 int 值,如果到达文件末尾,则返回 -1 |
| int read(char[] cbuf) | 从输入流中读取字符并尽量填满 cbuf 数组,方法返回实际读取的数量,到达文件末尾返回 -1 |
| int read(CharBuffer target) | 从输入流中读取字符放进 target 缓冲区中,返回实际读取的字符数量,到达文件末尾时返回 -1 |
| int read(char[] cbuf, int off, int len) | 从输入流中最多读入 len 个字符,读取到的字符从 cbuf 的 off 位置开始放,返回实际读取的字符数量,到达文件末尾时返回 -1 |
| void close() | 关闭字符流 |
CharBuffer类相当于对char[]进行了封装,可以保存字符数据,实际上是一个缓冲区。- 及时
close释放资源
代码演示
public class Demo15 {public static void main(String[] args) throws IOException {//写文件try(FileWriter writer = new FileWriter("D:/DemoFile/INNER/newDemo.txt")) {writer.write("你好,字符流");writer.write(new char[]{'h', 'e', 'l', 'l', 'o'});}//读文件try(FileReader reader = new FileReader("D:/DemoFile/INNER/newDemo.txt")) {while(true) {char[] cBuf = new char[100];int r = reader.read(cBuf);if(r == -1) {break;}for(int i = 0; i < r; i++) {System.out.print(cBuf[i]);}}}}
}

-
前面按照字节流读取一个汉字是3个字节,而现在却“变成”2个字节,其实这两种方式都是正确的。
字节流读取的是原始数据即3个字节;而字符流在读取的时候会根据文件的内容编码格式进行解析,返回时针对3个字节进行了转码(用这三个字节查询到其指代的汉字,又将汉字的unicode编码值查询出来),最终将编码值返回到char变量(2个字节)中。
缓冲流
缓冲流 是一种用于提高输入输出操作效率的流。缓冲流通过在内存中维护一个缓冲区,减少了对底层系统调用的次数,从而提高了 I/O 操作的性能。Java 提供了多种缓冲流,包括字节缓冲流(BufferedInputStream、BufferedOutputStream)和字符缓冲流(BufferedReader、BufferedWriter)。
缓冲流可以显著提高 Java 程序在处理大量数据或频繁进行 I/O 操作时的性能,但是对于小文件就没有必要使用缓冲流了,因为性能提升效果不明显,甚至可能引入额外的开销。
四个缓冲流相关的类上面已经提到,分别对应到上面介绍的四个类,那具体如何使用呢?我们先介绍一下它们的构造方法(四个类的构造方法十分相似,我们放在一个表格里):
| 构造方法 | 说明 |
|---|---|
| BufferedInputStream(InputStream in) | 创建一个新的字节缓冲输入流 |
| BufferedInputStream(InputStream in, int size) | 创建一个新的字节缓冲输入流,并指定缓冲区大小 |
| BufferedOutputStream(OutputStream out) | 创建一个新的字节缓冲输出流 |
| BufferedOutputStream(OutputStream out, int size) | 创建一个新的字节缓冲输出流,并指定缓冲区大小 |
| BufferedReader(Reader in) | 创建一个新的字符缓冲输入流 |
| BufferedReader(Reader in, int sz) | 创建一个新的字符缓冲输入流,并指定缓冲区大小 |
| BufferedWriter(Writer out) | 创建一个新的字符缓冲输出流 |
| BufferedWriter(Writer out, int sz) | 创建一个新的字符缓冲输出流,并指定缓冲区大小 |
若想要使用缓冲流对文件执行读写操作,读写方法不变,只是需要套个壳而已, 即:将FileInputStream、FileOutputStream、FileReader、FileWriter这四个类的对象传入对应的缓冲流构造方法,构造出一个缓冲流对象,用这个对象调用之前的读或写方法。
不过需要注意的是,缓冲流也需要及时关闭释放资源,即:需要将构造对象放到try括号里。
【具体演示】
public class Demo16 {public static void main(String[] args) {//写文件try(FileOutputStream outputStream = new FileOutputStream("D:/DemoFile/INNER/IN/demo1.txt");BufferedOutputStream bufferedOutput = new BufferedOutputStream(outputStream)) {for(int i = 97; i <= 122; i++) {bufferedOutput.write(i);}} catch (IOException e) {e.printStackTrace();}//读文件try(FileReader reader = new FileReader("D:/DemoFile/INNER/IN/demo1.txt");BufferedReader bufferedReader = new BufferedReader(reader)) {while(true) {char[] cBuf = new char[100];int r = bufferedReader.read(cBuf);if(r == -1) {break;}for(int i = 0; i < r; i++) {System.out.print(cBuf[i]);}}} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}
}

- 代码中使用了缓冲流的方式读写文件,但是后续的案例练习不会使用缓冲流,这是因为我们不涉及大文件,如果使用也就直接套个壳即可。
转换流
转换流(InputStreamReader 和 OutputStreamWriter)在 Java 中用于在字节流和字符流之间进行转换。它们特别适用于处理涉及字符编码的输入输出操作。
转换流的使用场景:
-
文件操作:在处理文本文件时,特别是需要指定字符编码的场景下,使用转换流是常见的做法。
举例解释:当文件编码与平台默认编码不一致,此时采用
FileReader读取文件,会出现乱码。 -
网络通信:在网络通信中,为了确保数据的正确性和一致性,使用转换流是必要的。
-
多语言和国际化:在处理多语言和国际化数据时,使用转换流是必不可少的。
如果平台默认编码与文件编码不一致,
FileOutputStream、FileWriter、FileInputStream、FileReader都会出现乱码情况。
FileWriter:使用平台默认的字符编码来写入文件。如果文件需要使用特定的字符编码(例如 UTF-8),而平台默认编码不同(例如 GBK),则会导致乱码。FileOutputStream:写入字节数据。如果你直接写入字符串而不指定字符编码,也会导致乱码。String.getBytes()方法在没有指定字符编码时,会使用平台默认编码。FileReader:使用平台默认的字符编码来读取文件。如果文件的实际编码与平台默认编码不同,读取时会出现乱码。FileInputStream:读取的是字节数据,不会直接处理字符编码问题。但如果你直接将字节数据转换为字符串而不指定字符编码,也会导致乱码。基于这样的场景,我们就需要转换流来指定需要的编码方式。
根据使用场景不难理解,对于我们初学者/学生来说很少用到转换流,关于两个类:
InputStreamReader:将字节输入流转换为字符输入流OutputStreamWriter:将字符输出流转换为字节输出流
【构造方法】
| 构造方法 | 说明 |
|---|---|
| InputStreamReader(InputStream in) OutputStreamWriter(OutputStream out) | 使用平台默认字符编码 |
| InputStreamReader(InputStream in, Charset cs) OutputStreamWriter(OutputStream out, Charset cs) | 使用指定的字符编码 |
| InputStreamReader(InputStream in, String charsetName) OutputStreamWriter(OutputStream out, String charsetName) | 使用指定的字符编码名称 |
- 当采用只有一个参数构造方法时,效果和直接使用
FileReader等类一致,都使用平台默认编码。
这里只演示了构造方法,具体如何使用,与缓冲流类似,也是套个壳,然后指定一下字符编码即可,具体参照接下来的演示代码理解。
【具体演示】
文件读写场景:
- 读取文本文件:特别是当文件的编码不是平台默认编码时,使用
InputStreamReader可以确保正确读取文件内容。 - 写入文本文件:同样,当需要写入特定编码的文件时,使用
OutputStreamWriter可以确保数据的正确性。
// 写文件,指定 UTF-8 编码
try (FileOutputStream fos = new FileOutputStream("example.txt");OutputStreamWriter osw = new OutputStreamWriter(fos, StandardCharsets.UTF_8);BufferedWriter bw = new BufferedWriter(osw)) {String content = "Hello, World!";bw.write(content);
} catch (IOException e) {e.printStackTrace();
}// 读文件,指定 UTF-8 编码
try (FileInputStream fis = new FileInputStream("example.txt");InputStreamReader isr = new InputStreamReader(fis, StandardCharsets.UTF_8);BufferedReader br = new BufferedReader(isr)) {String line;while ((line = br.readLine()) != null) {System.out.println(line);}
} catch (IOException e) {e.printStackTrace();
}
- 代码举例演示了以
UTF-8的方式读写文件。
总之,当平台默认编码与文件编码不一致时,为了避免乱码问题,你需要确保在读取和写入文件时使用与文件实际编码相同的编码。(使用转换流)
案例练习
结束了文件系统操作和文件内容操作后,我们实现几个小案例巩固一下。
【案例一】
扫描指定目录,并找到名称中包含指定字符的所有普通文件(不包含目录),并且后续询问用户是否要删除该文件
public class Demo2 {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.println("请输入您要扫描的目录:");String scanDir = scanner.next();File dir = new File(scanDir);if(!dir.isDirectory()) {System.out.println("您输入的不是目录");return;}System.out.println("请输入您要查找的关键字:");String keyWord = scanner.next();scanFiles(dir, keyWord);}private static void scanFiles(File scanDir, String keyWord) {File[] files = scanDir.listFiles();for(int i = 0; i < files.length; i++) {if(files[i].isFile()) {if(files[i].getName().contains(keyWord)) {dealFile(files[i]);}}else {scanFiles(files[i], keyWord);}}}private static void dealFile(File file) {System.out.println("找到文件" + file.getAbsolutePath() + "是否删除?(y/n)");Scanner scanner = new Scanner(System.in);while(true) {String input = scanner.next();if(input.equals("y")) {file.delete();return;}else if(input.equals("n")) {return;}else {System.out.println("输入非法!请输入y/n");}}}
}
- 与之前递归删除非空目录的思想差不多:列出目录下的所有文件,遍历,如果是普通文件判断是否包含指定字符串;如果是目录,则递归。
【案例二】
进行普通文件的复制(注意是复制而不是剪切粘贴)
public class Demo3 {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.println("请输入源文件路径:");String srcPath = scanner.next();File src = new File(srcPath);if(!src.isFile()) {System.out.println("路径错误!非文件!");return;}System.out.println("请输入目标文件路径:");String dstPath = scanner.next();File dst = new File(dstPath);if(!new File(dst.getParent()).isDirectory()) {System.out.println("目标路径错误!");return;}try(InputStream inputStream = new FileInputStream(src); OutputStream outputStream = new FileOutputStream(dst)) {byte[] buf = new byte[1024];while(true) {int n = inputStream.read(buf);if(n == -1) {break;}outputStream.write(buf, 0, n);}} catch (IOException e) {e.printStackTrace();}}
}
- 判断输入合法,文件内容操作,边读边写
【案例三】
扫描指定目录,并找到名称或者内容中包含指定字符的所有普通文件(不包含目录)
public class Demo4 {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.println("请输入要搜索的路径: ");String rootPath = scanner.next();File rootFile = new File(rootPath);if (!rootFile.isDirectory()) {System.out.println("输入的路径不是目录!");return;}System.out.println("请输入要搜索的关键字: ");String keyword = scanner.next();scanDir(rootFile, keyword);}private static void scanDir(File rootFile, String keyword) {// 1. 列出当前目录下所有的内容File[] files = rootFile.listFiles();if (files == null) {// 当前目录为空, 直接返回return;}// 2. 遍历当前目录下所有的文件for (File file : files) {if (file.isFile()) {// 是普通文件dealFile(file, keyword);} else {// 是目录, 递归调用scanDir(file, keyword);}}}private static void dealFile(File file, String keyword) {// 1. 判定文件名是否包含关键字if (file.getName().contains(keyword)) {// 包含关键字, 打印文件名System.out.println("文件名包含关键字:" + file.getAbsolutePath());return;}// 2. 判定文件内容是否包含. 由于 keyword 是字符串. 就按照字符流的方式来处理.StringBuilder stringBuilder = new StringBuilder();try (Reader reader = new FileReader(file)) {while (true) {char[] chars = new char[1024];int n = reader.read(chars);if (n == -1) {break;}stringBuilder.append(chars, 0, n);}} catch (IOException e) {e.printStackTrace();}// 3. 判定 stringBuilder 是否包含关键字if (stringBuilder.indexOf(keyword) >= 0) {// 包含关键字System.out.println("文件内容包含关键字: " + file.getAbsolutePath());}return;}
}
- 注意:现在的方案性能较差,尽量不要在太复杂的目录下或者大文件下实现
完
相关文章:
JavaSE(十四)——文件操作和IO
文章目录 文件操作和IO文件相关概念Java操作文件文件系统操作文件内容操作字节流FileOutputStreamFileInputStream代码演示 字符流FileWriterFileReader代码演示 缓冲流转换流 案例练习 文件操作和IO 文件相关概念 文件 通常指的是包含用户数据的文件,如文本文件、…...

【视觉SLAM】4b-特征点法估计相机运动之PnP 3D-2D
文章目录 0. 前言1. PnP求解1.1 直接线性变换DLT1.2 P3P1.3 光束平差法BA2. 实现0. 前言 透视n点(Perspective-n-Point,PnP)问题是计算机视觉领域的经典问题,用于求解3D-2D的点运动。换句话说,当知道 N N N个世界坐标系中3D空间点的坐标以及它们在图像上的投影点像素坐标…...
Asan 内存检测工具)
android 性能分析工具(04)Asan 内存检测工具
1 Asan工具简介 1.1 Asan工具历史背景 AddressSanitizer(ASan)最初由Google开发,并作为LLVM项目的一部分。ASan的设计目的是帮助开发者检测并修复内存错误,如堆栈和全局缓冲区溢出、使用已释放的内存等,这些问题可能…...

html中select标签的选项携带多个值
搜索参考资料:SELECT标签中的选项可以携带多个值吗? 【摘抄】: 它可能有一个select选项中的多个值,如下所示。 <select id"ddlEmployee" class"form-control"> <option value"">-- S…...

Lambda表达式如何进行调试
一、概述 Java8提供了lambda表达式,方便我们对数据集合进行操作,我们使用lambda表达式的时候,是不是有这样的疑问,如何对执行过程中的中间数据进行调试呢? 二、例子 在下面的例子中,我们实现随机最多生成…...

C++ —— 剑斩旧我 破茧成蝶—C++11
江河入海,知识涌动,这是我参与江海计划的第2篇。 目录 1. C11的发展历史 2. 列表初始化 2.1 C98传统的{} 2.2 C11中的{} 2.3 C11中的std::initializer_list 3. 右值引用和移动语义 3.1 左值和右值 3.2 左值引用和右值引用 3.3 引用延长生命周期…...

HTML5好看的音乐播放器多种风格(附源码)
文章目录 1.设计来源1.1 音乐播放器风格1效果1.2 音乐播放器风格2效果1.3 音乐播放器风格3效果1.4 音乐播放器风格4效果1.5 音乐播放器风格5效果 2.效果和源码2.1 动态效果2.2 源代码 源码下载万套模板,程序开发,在线开发,在线沟通 作者&…...

C++设计模式行为模式———迭代器模式中介者模式
文章目录 一、引言二、中介者模式三、总结 一、引言 中介者模式是一种行为设计模式, 能让你减少对象之间混乱无序的依赖关系。 该模式会限制对象之间的直接交互, 迫使它们通过一个中介者对象进行合作。 中介者模式可以减少对象之间混乱无序的依赖关系&…...

FFmpeg 4.3 音视频-多路H265监控录放C++开发十五,解码相关,将h264文件进行帧分隔变成avpacket
前提 前面我们学习了 将YUV数据读取到AVFrame,然后将AVFrame通过 h264编码器变成 AVPacket后,然后将avpacket直接存储到了本地就变成了h264文件。 这一节课,学习解码的一部分。我们需要将 本地存储的h264文件进行帧分隔,也就是变…...

力扣 LeetCode 104. 二叉树的最大深度(Day7:二叉树)
解题思路: 采用后序遍历 首先要区别好什么是高度,什么是深度 最大深度实际上就是根节点的高度 高度的求法是从下往上传,从下往上传实际上就是左右中(后序遍历) 深度的求法是从上往下去寻找 所以采用从下往上 本…...
如何高效实现汤臣倍健营销云数据集成到SQLServer
新版订单同步-(Life-Space)江油泰熙:汤臣倍健营销云数据集成到SQL Server 在企业信息化建设中,数据的高效集成和管理是提升业务运营效率的关键。本文将分享一个实际案例——如何通过新版订单同步方案,将汤臣倍健营销云…...

Vue3中使用:deep修改element-plus的样式无效怎么办?
前言:当我们用 vue3 :deep() 处理 elementui 中 el-dialog_body和el-dislog__header 的时候样式一直无法生效,遇到这种情况怎么办? 解决办法: 1.直接在 dialog 上面增加class 我试过,也不起作用,最后用这种…...

具身智能之Isaac Gym使用
0. 简介 Isaac Gym 是由 NVIDIA 提供的一个高性能仿真平台,专门用于大规模的机器人学习和强化学习(RL)任务。它结合了物理仿真、GPU加速、深度学习框架互操作性等特点,使得研究人员和开发者可以快速进行复杂的机器人仿真和训练。…...

【大数据学习 | Spark】spark-shell开发
spark的代码分为两种 本地代码在driver端直接解析执行没有后续 集群代码,会在driver端进行解析,然后让多个机器进行集群形式的执行计算 spark-shell --master spark://nn1:7077 --executor-cores 2 --executor-memory 2G sc.textFile("/home/ha…...

《Python制作动态爱心粒子特效》
一、实现思路 粒子效果: – 使用Pygame模拟粒子运动,粒子会以爱心的轨迹分布并运动。爱心公式: 爱心的数学公式: x16sin 3 (t),y13cos(t)−5cos(2t)−2cos(3t)−cos(4t) 参数 t t 的范围决定爱心形状。 动态效果: 粒子…...
Jmeter 如何导入证书并调用https请求
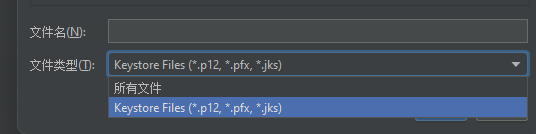
Jmeter 如何导入证书并调用https请求 通过SSL管理器添加证书文件 支持添加的文件为.p12,.pfx,.jks 如何将pem文件转换为pfx文件? 在公司内部通常会提供3个pem文件。 ca.pem:可以理解为是根证书,用于验证颁发的证…...

Python程序15个提速优化方法
目录 Python程序15个提速优化方法1. 引言2. 方法一:使用内建函数代码示例:解释: 3. 方法二:避免使用全局变量代码示例:解释: 4. 方法三:使用局部变量代码示例:解释: 5. 方…...

足球虚拟越位线技术FIFA OT(二)
足球虚拟越位线技术FIFA OT(二) 在FIFA认证测试过程中,留给VAR系统绘制越位线的时间只有90秒(在比赛中时间可能更短),那么90秒内要做什么事呢,首先场地上球员做出踢球动作,然后VAR要…...

centos7.9单机版安装K8s
1.安装docker [rootlocalhost ~]# hostnamectl set-hostname master [rootlocalhost ~]# bash [rootmaster ~]# mv /etc/yum.repos.d/* /home [rootmaster ~]# curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo [rootmaster ~]# cu…...

图像编辑一些概念:Image Reconstruction与Image Re-generation
图像编辑本质上是在“图像重建”(image reconstruction)和“图像再生成”(image re-generation)之间寻找平衡。 1. Image Reconstruction(图像重建) 定义:图像重建通常是指从已有的图像中提取信…...

新手福音:无需github,在快马平台轻松入门第一个web应用
最近在学前端开发时,发现很多教程都推荐从GitHub克隆项目来练习,但GitHub经常访问不稳定,对新手特别不友好。好在发现了InsCode(快马)平台,不用折腾GitHub就能直接上手写代码,特别适合我这种刚入门的小白。今天就用它做…...

剑指offer-58、对称二叉树
题⽬描述 请实现⼀个函数,⽤来判断⼀棵⼆叉树是不是对称的。注意,如果⼀个⼆叉树同此⼆叉树的镜像是同样 的,定义其为对称的。 例如:下⾯这棵⼆叉树是对称的 下⾯这个就不是对称的: 示例1 输⼊:{8,6,6,5…...
TransCAD新手必看:如何用表格链接快速创建矩阵OD并生成期望线(附详细步骤图)
TransCAD实战指南:从表格链接到期望线可视化的全流程解析 引言 在交通规划与空间分析领域,TransCAD作为一款专业的GIS软件,其强大的数据处理和可视化能力一直备受推崇。对于初学者而言,掌握表格链接创建矩阵OD并生成期望线的技巧&…...

AssetRipper终极指南:如何免费快速提取Unity游戏资源
AssetRipper终极指南:如何免费快速提取Unity游戏资源 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper AssetRipper是一款强…...

Chrome密码一键提取:3分钟找回所有浏览器保存的密码
Chrome密码一键提取:3分钟找回所有浏览器保存的密码 【免费下载链接】chromepass Get all passwords stored by Chrome on WINDOWS. 项目地址: https://gitcode.com/gh_mirrors/chr/chromepass 你是否曾经因为忘记某个重要网站的登录密码而感到焦虑ÿ…...

Springboot 整合 SaToken 实现高效鉴权与动态路由拦截实战
1. 为什么选择SaToken做权限管理? 第一次接触SaToken是在去年重构一个内部管理系统时。当时项目用的是Spring Security,配置繁琐不说,光是解决一个"记住我"功能就折腾了两天。后来偶然发现这个国产框架,只用三行代码就实…...

3月31枚举
...

实战分享:如何用Altium Designer高效搞定PCB的定位孔、散热孔和屏蔽孔?
Altium Designer实战:PCB定位孔、散热孔与屏蔽孔的高效设计指南 在PCB设计领域,机械孔的设计往往被工程师视为"简单任务"而草率处理,直到量产时才发现定位偏差、散热不足或EMI超标等问题。作为从业十年的硬件设计师,我曾…...

N8N不只是工作流工具:手把手教你把它变成双向MCP网关,连接百度地图和AI Agent
N8N架构实战:构建双向MCP网关连接百度地图与AI Agent生态 在AI Agent技术栈中,协议桥接能力正成为系统设计的核心挑战。当Claude需要调用地图服务、Cursor尝试接入CRM数据时,传统API集成方式往往需要编写大量适配代码。而N8N通过独特的双向MC…...

阿里内部强推性能优化全栈小册,Java程序员必备!
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代…...