利用Python高效处理大规模词汇数据
在本篇博客中,我们将探讨如何使用Python及其强大的库来处理和分析大规模的词汇数据。我们将介绍如何从多个.pkl文件中读取数据,并应用一系列算法来筛选和扩展一个核心词汇列表。这个过程涉及到使用Pandas、Polars以及tqdm等库来实现高效的数据处理。
引言
词汇数据的处理是自然语言处理(NLP)领域中的一个常见任务。无论是构建词典、进行文本分类还是情感分析,都需要对大量的词汇数据进行预处理和分析。本文将演示一种方法,该方法不仅能够有效地管理词汇数据,还能够在处理过程中保持数据的一致性和准确性。
数据准备
首先,我们需要加载初始的词汇数据集,这些数据以.pkl格式存储,并且包含了词汇及其出现的频率。我们选择了一个名为voc_26B.pkl的文件,它包含了所有需要处理的词汇信息。
import os
import pandas as pd
from glob import glob
import polars as pl
from tqdm import tqdm# 加载并排序词汇数据
voc = pd.read_pickle("voc_26B.pkl")
voc = voc.sort_values("count", ascending=False)
voc = voc["voc"].values.tolist()
接下来,我们收集所有需要分析的路径,这里假设所有的.pkl文件都位于E:/voc_voc/目录下。
# 获取所有路径
paths = glob("E:/voc_voc/*.pkl")
new_voc = set()
数据处理与优化
在这个阶段,我们将遍历每个词汇项,并根据其前缀匹配规则,查找并合并相关的词汇条目。为了确保效率,我们采用了tqdm库来显示进度条,这对于我们了解程序执行进度非常有帮助。
for voc_data in tqdm(voc):if voc_data in new_voc:continuenew_voc.update(set([voc_data]))idex = 0data = ""# 循环查找直到找到非空数据while len(data) == 0:data = pd.read_pickle(paths[idex], compression="zip")data1 = pl.DataFrame({"voc": data.keys(), "value": data.values()})data = {k: v for k, v in data.items() if voc_data == k[:len(voc_data)]}idex += 1# 转换为DataFrame并排序data = pd.DataFrame({"voc": data.keys(), "value": data.values()})data = data.sort_values("value", ascending=False).head()# 更新词汇集合data = data["voc"].str[len(voc_data) + 1:].values.tolist()if voc_data in data:data.remove(voc_data)new_voc.update(set(data))# 进一步扩展词汇data3 = []for i in tqdm(set(data)):data2 = [k[len(i) + 1:] for k, v indata1.filter(data1["voc"].str.contains(i + "_")).sort("value", descending=True).to_numpy() ifi == k[:len(i)]][:5]new_voc.update(set(data2))data3 += data2# 深度扩展词汇for i in tqdm(set(data3)):try:data2 = [k[len(i) + 1:] for k, v indata1.filter(data1["voc"].str.contains(i + "_")).sort("value", descending=True).to_numpy() ifi == k[:len(i)]][:5]new_voc.update(set(data2))except:pass# 当词汇数量达到一定规模时保存结果if len(new_voc) > 8192:pd.to_pickle(new_voc, "voc_{}_voc.pkl".format(len(new_voc)))
结果保存
最后,当整个词汇扩展过程完成后,我们将最终的词汇集合保存到一个新的.pkl文件中。
pd.to_pickle(new_voc, "voc_{}_voc.pkl".format(len(new_voc)))
总结
通过上述步骤,我们可以看到,Python及其丰富的库使得处理大规模词汇数据变得既简单又高效。特别是tqdm的进步条功能,极大地提升了用户体验,让用户可以直观地了解数据处理的进度。同时,结合使用Pandas和Polars,可以在保证数据处理速度的同时,也确保了代码的简洁性和可读性。
希望这篇博客能为您提供有价值的参考,并激发您在自己的项目中尝试类似的解决方案。如果您有任何问题或想要分享您的经验,请随时留言讨论!
相关文章:

利用Python高效处理大规模词汇数据
在本篇博客中,我们将探讨如何使用Python及其强大的库来处理和分析大规模的词汇数据。我们将介绍如何从多个.pkl文件中读取数据,并应用一系列算法来筛选和扩展一个核心词汇列表。这个过程涉及到使用Pandas、Polars以及tqdm等库来实现高效的数据处理。 引…...

【PyQt】超级超级笨的pyqt计算器案例
计算器 1.QT Designer设计外观 1.pushButton2.textEdit3.groupBox4.布局设计 2.加载ui文件 导入模块: sys:用于处理命令行参数。 QApplication:PyQt5 应用程序类。 QWidget:窗口基类。 uic:用于加载 .ui 文件。…...

Git 的起源与发展
序章:版本控制的前世今生 在软件开发的漫长旅程中,版本控制犹如一位忠诚的伙伴,始终陪伴着开发者们。它的存在,解决了软件开发过程中代码管理的诸多难题,让团队协作更加高效,代码的演进更加有序。 简单来…...

预防和应对DDoS的方法
DDoS发起者通过大量的网络流量来中断服务器、服务或网络的正常运行,通常由多个受感染的计算机或联网设备(包括物联网设备)发起。 换种通俗的说法,可以将其想象成高速公路上的一次突然的大规模交通堵塞,阻止了正常的通勤…...

51单片机开发:独立按键实验
实验目的:按下键盘1时,点亮LED灯1。 键盘原理图如下图所示,可见,由于接GND,当键盘按下时,P3相应的端口为低电平。 键盘按下时会出现抖动,时间通常为5-10ms,代码中通过延时函数delay…...

02.04 数据类型
请写出以下几个数据的类型: 整数 a ----->int a的地址 ----->int* 存放a的数组b ----->int[] 存放a的地址的数组c ----->int*[] b的地址 ----->int* c的地址 ----->int** 指向printf函数的指针d ----->int (*)(const char*, ...) …...

FPGA学习篇——开篇之作
今天正式开始学FPGA啦,接下来将会编写FPGA学习篇来记录自己学习FPGA 的过程! 今天是大年初六,简单学一下FPGA的相关概念叭叭叭! 一:数字系统设计流程 一个数字系统的设计分为前端设计和后端设计。在我看来࿰…...

【Cadence仿真技巧学习笔记】求解65nm库晶体管参数un, e0, Cox
在设计放大器的第一步就是确定好晶体管参数和直流工作点的选取。通过阅读文献,我了解到L波段低噪声放大器的mos器件最优宽度计算公式为 W o p t . p 3 2 1 ω L C o x R s Q s p W_{opt.p}\frac{3}{2}\frac{1}{\omega LC_{ox}R_{s}Q_{sp}} Wopt.p23ωLCoxRs…...

【RocketMQ】RocketMq之IndexFile深入研究
一:RocketMq 整体文件存储介绍 存储⽂件主要分为三个部分: CommitLog:存储消息的元数据。所有消息都会顺序存⼊到CommitLog⽂件当中。CommitLog由多个⽂件组成,每个⽂件固定⼤⼩1G。以第⼀条消 息的偏移量为⽂件名。 ConsumerQue…...

小白零基础--CPP多线程
进程 进程就是运行中的程序线程进程中的进程 1、C11 Thread线程库基础 #include <iostream> #include <thread> #include<string>void printthread(std::string msg){std::cout<<msg<<std::endl;for (int i 0; i < 1000; i){std::cout<…...

利用deepseek参与软件测试 基本架构如何 又该在什么环节接入deepseek
利用DeepSeek参与软件测试,可以考虑以下基本架构和接入环节: ### 基本架构 - **数据层** - **测试数据存储**:用于存放各种测试数据,包括正常输入数据、边界值数据、异常数据等,这些数据可以作为DeepSeek的输入&…...
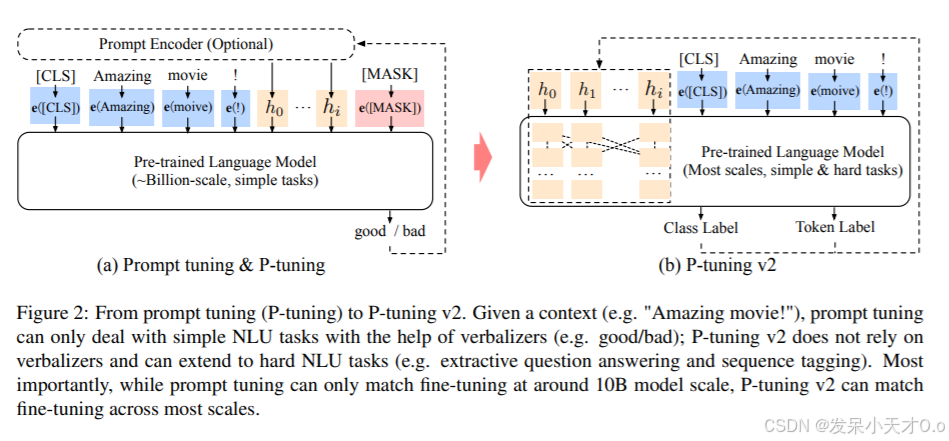
大模型微调技术总结及使用GPU对VisualGLM-6B进行高效微调
1. 概述 在深度学习中,微调(Fine-tuning)是一种重要的技术,用于改进预训练模型的性能。在预训练模型的基础上,针对特定任务(如文本分类、机器翻译、情感分析等),使用相对较小的有监…...

WPF进阶 | WPF 样式与模板:打造个性化用户界面的利器
WPF进阶 | WPF 样式与模板:打造个性化用户界面的利器 一、前言二、WPF 样式基础2.1 什么是样式2.2 样式的定义2.3 样式的应用 三、WPF 模板基础3.1 什么是模板3.2 控件模板3.3 数据模板 四、样式与模板的高级应用4.1 样式继承4.2 模板绑定4.3 资源字典 五、实际应用…...

Java 大视界 -- Java 大数据在自动驾驶中的数据处理与决策支持(68)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...
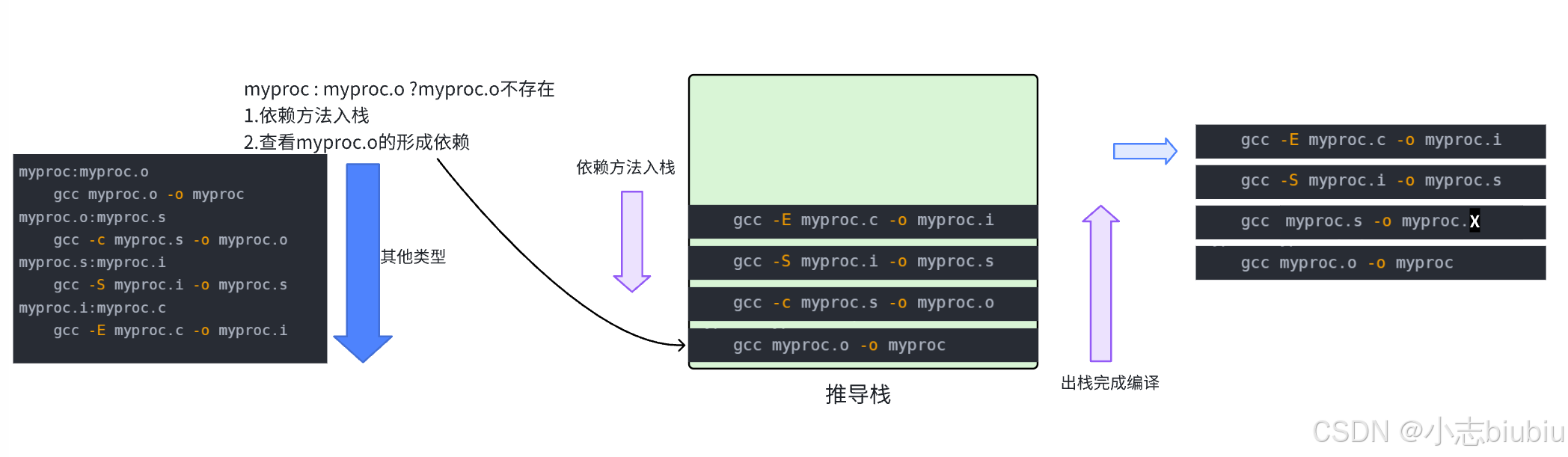
自动化构建-make/Makefile 【Linux基础开发工具】
文章目录 一、背景二、Makefile编译过程三、变量四、变量赋值1、""是最普通的等号2、“:” 表示直接赋值3、“?” 表示如果该变量没有被赋值,4、""和写代码是一样的, 五、预定义变量六、函数**通配符** 七、伪目标 .PHONY八、其他常…...

python学opencv|读取图像(五十二)使用cv.matchTemplate()函数实现最佳图像匹配
【1】引言 前序学习了图像的常规读取和基本按位操作技巧,相关文章包括且不限于: python学opencv|读取图像-CSDN博客 python学opencv|读取图像(四十九)原理探究:使用cv2.bitwise()系列函数实现图像按位运算-CSDN博客…...
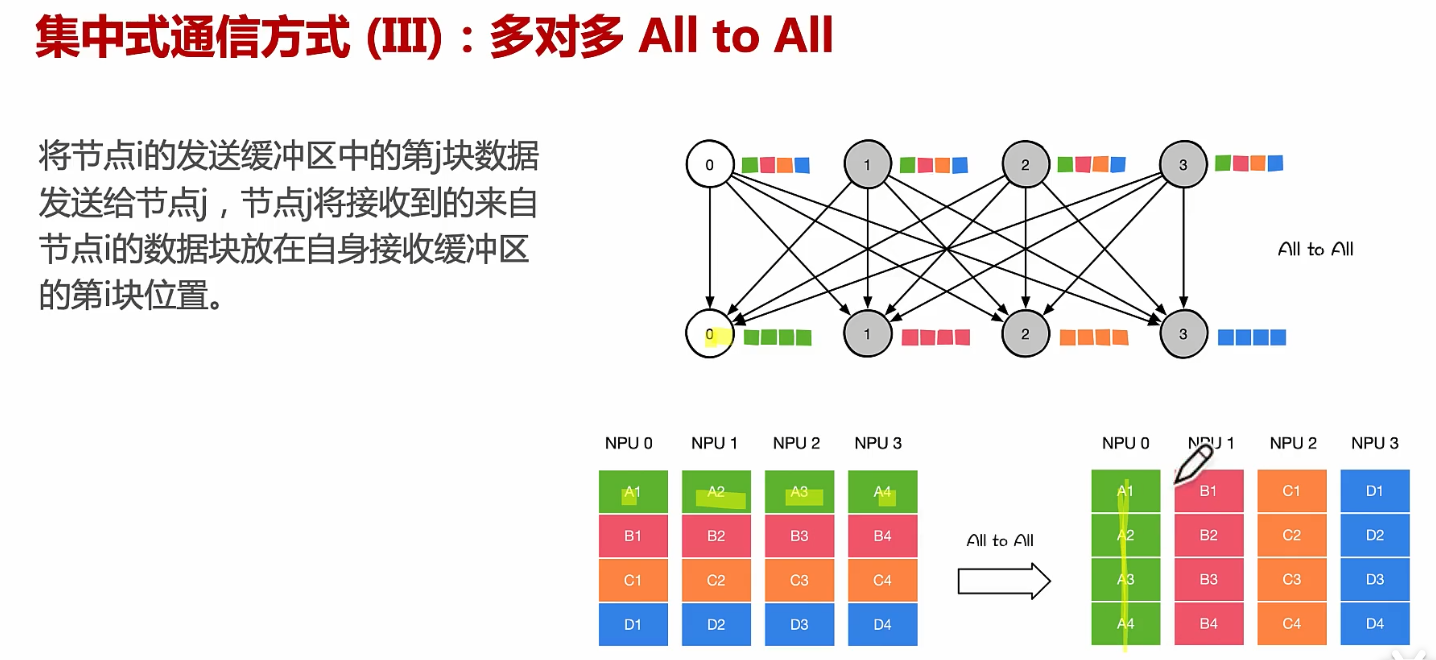
通信方式、点对点通信、集合通信
文章目录 从硬件PCIE、NVLINK、RDMA原理到通信NCCL、MPI原理!通信实现方式:机器内通信、机器间通信通信实现方式:通讯协调通信实现方式:机器内通信:PCIe通信实现方式:机器内通信:NVLink通信实现…...

TCP编程
1.socket函数 int socket(int domain, int type, int protocol); 头文件:include<sys/types.h>,include<sys/socket.h> 参数 int domain AF_INET: IPv4 Internet protocols AF_INET6: IPv6 Internet protocols AF_UNIX, AF_LOCAL : Local…...

OpenAI 实战进阶教程 - 第七节: 与数据库集成 - 生成 SQL 查询与优化
内容目标 学习如何使用 OpenAI 辅助生成和优化多表 SQL 查询了解如何获取数据库结构信息并与 OpenAI 结合使用 实操步骤 1. 创建 SQLite 数据库示例 创建数据库及表结构: import sqlite3# 连接 SQLite 数据库(如果不存在则创建) conn sq…...

Apache Iceberg数据湖技术在海量实时数据处理、实时特征工程和模型训练的应用技术方案和具体实施步骤及代码
Apache Iceberg在处理海量实时数据、支持实时特征工程和模型训练方面的强大能力。Iceberg支持实时特征工程和模型训练,特别适用于需要处理海量实时数据的机器学习工作流。 Iceberg作为数据湖,以支持其机器学习平台中的特征存储。Iceberg的分层结构、快照…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...