MySQL InnoDB表的碎片量化和整理(data free能否用来衡量碎片?)
网络上有很多MySQL表碎片整理的问题,大多数是通过demo一个表然后参考data free来进行碎片整理,这种方式对myisam引擎或者其他引擎可能有效(本人没有做详细的测试).
对Innodb引擎是不是准确的,或者data free是不是可以参考,还是值得商榷的。
本文基于MySQL的Innodb存储引擎,数据库版本是8.0.18,对碎片(fragment)做一个简单的分析,来说明如何量化表的碎片化程度。
涉及的参数
1,information_schema_stats_expiry
information_schema是一个基于共享表空间的虚拟数据库,存储的是一些系统元数据信息,某些系统表的数据并不是实时更新的,具体更新是基于参数information_schema_stats_expiry。
information_schema_stats_expiry默认值是86400秒,也就是24小时,意味着24小时刷新一次information_schema中的数据,做测试的时候可以设置为0,实时刷新information_schema中的元数据信息。
2,innodb_fast_shutdown
因为要基于磁盘做一些统计,需要将缓存或者redo log中的数据在重启实例的时候实时刷入磁盘,这里设置为0,在重启数据库的时候将缓存或者redo log实时写入表的物理文件。
3,innodb_stats_persistent_sample_pages
因为涉及一些系统数据更新时对page的采样比例,这里设置为一个较大的值,为100000,尽可能高比例采样来生成系统数据。
4,innodb_flush_log_at_trx_commit sync_binlog
因为涉及大量数据的写操作,为加快测试,关闭double 1模式。
5,innodb_fill_factor
页面填充率保留默认的设置,默认值是100
以上涉及的参数仅针对本测试,并不一定代表最优,同时测试过程中(数据写入或者删除后)会不断地重启实例,以刷新相对应的物理文件。
碎片的概念
数据存储在文件系统上的时候,总是不能100%利用分配给它的物理空间:
比如删除数据会在页面上留下一些”空洞”,或者随机写入(聚集索引非线性增加)会导致页分裂,页分裂导致页面的利用空间少于50%;
另外对表进行增删改会引起对应的二级索引值的随机的增删改,也会导致索引结构中的数据页面上留下一些“空洞”;
虽然这些空洞有可能会被重复利用,但终究会导致部分物理空间未被使用,也就是碎片。
同时,即便是设置了填充因子为100%,Innodb也会主动留下page页面1/16的空间作为预留使用(An innodb_fill_factor setting of 100 leaves 1/16 of the space in clustered index pages free for future index growth.)。
关系数据库的存储结构原理上是类似的,理论上很简单,就不过多啰嗦了。碎片是一个客观存在的事实。
创建测试表以及数据
做个简单的测试,表结构如下,

CREATETABLE `fragment_test` (
`id` INTNOTNULL AUTO_INCREMENT,
`c1` INTNULLDEFAULTNULL,
`c2` INTNULLDEFAULTNULL,
`c3` VARCHAR(50) NULLDEFAULTNULL,
`c4` DATETIME(6) NULLDEFAULTNULL,
PRIMARYKEY (`id`)
);
CREATEINDEX idx_c1 ON fragment_test(c1);
CREATEINDEX idx_c2 ON fragment_test(c2);
CREATEINDEX idx_c3 ON fragment_test(c3);

生成200W测试数据(CALL test_insertdata(2000000);)

CREATE DEFINER=`root`@`%` PROCEDURE `test_insertdata`(
IN `loopcount` INT
)
BEGINdeclare v_uuid varchar(50);
while loopcount>0 do
set v_uuid = uuid();
INSERTINTO fragment_test(c1,c2,c3,c4) VALUES (RAND()*200000000,RAND()*200000000,UUID(),NOW(6));
set loopcount = loopcount -1;
endwhile;
END

查询语句,参考自最后的链接中的文章

SELECT NAME,
TABLE_ROWS,
UPDATE_TIME,
format_bytes(t.data_length) DATA_SIZE,
format_bytes(t.index_length) INDEX_SIZE,
format_bytes(t.data_length+t.index_length) TOTAL_SIZE,
format_bytes(t.data_free) DATA_FREE,
format_bytes(it.FILE_SIZE) FILE_SIZE,
format_bytes((it.FILE_SIZE/10- (t.data_length/10+ t.index_length/10))*10) WASTED_SIZE
FROM information_schema.TABLES as t
JOIN information_schema.INNODB_TABLESPACES as it
ON it.name = concat(table_schema,"/",table_name)
WHERE TABLE_NAME ='fragment_test';

碎片的量化
上面说到数据在存储的时候,总是无法100%利用物理存储空间,Innodb甚至会自己主动预留一部分空闲的空间(1/16),那么如何衡量一个表究竟有多少尚未利用的空间?
这里从系统表information_schema.tables和information_schema.innodb_tablespaces,来对比实际使用空间和已分配空间来对比,来间接量化碎片或者说未利用空间的程度。
然后观察数据空间的分配情况,尽管系统表中的数据不是完全准确的,但是也比较接近实际的200W,系统表显示1971490,暂时抛开这一小点误差。
可以很清楚地看到,数据和索引的空间是329MB,文件空间是344MB,DATA_FREE空间是6MB。

随机删除1/4的数据,也就是50W行(DELETE FROM fragment_test ORDER BY RAND() LIMIT 500000;)
然后重启实例,并执行分析表(analyze table),继续来观察这个空间的分配,这里看到,
1,系统表显示150000行,跟表中的数据完全一致(尽管更多的时候这个值是一个大概的值,并不一定准确,严格说可能非常不准确,这里归因于innodb_stats_persistent_sample_pages的设置)。
2,数据文件空间没有增加(344MB),可以理解,因为这里是删数据操作,所以不用申请空间。
3,删除了1/4的数据,数据和索引的的大小基本上不变,这里就开始有疑问了,为什么没有成比例减少?
4,data_free增加了3MB,显然这不是跟删除的数据成比例增加的
那么怎么理解碎片?DATA_FREE怎么理解?碎片或者说可用空间又怎么衡量?
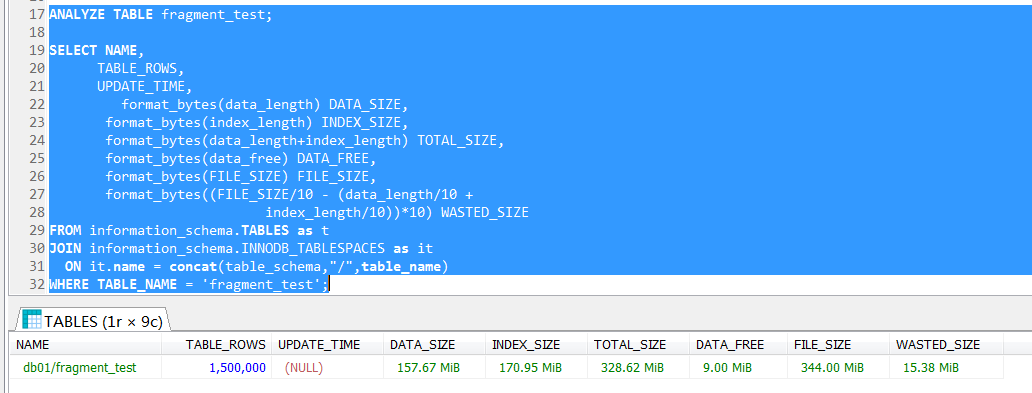
从200W数据中随机删除50W,也就是1/4,表的空间没有变化,可以肯定的是现在存在大量的碎片或者说可用空间,但是表的总的大小没变化,data_free也基本上没有变化到这里就有点说不通了。
那么data free到底是怎么计算的,看官方的解释:
The number of allocated but unused bytes.
InnoDB tables report the free space of the tablespace to which the table belongs. For a table located in the shared tablespace, this is the free space of the shared tablespace.
If you are using multiple tablespaces and the table has its own tablespace, the free space is for only that table.
Free space means the number of bytes in completely free extents minus a safety margin. Even if free space displays as 0, it may be possible to insert rows as long as new extents need not be allocated.
data_free的计算方式或者说条件,是完全空闲的区(extents,每个区1MB,64个连续的16 kb 大小的page),只有一个完全没有使用的区,才统计为data_free,因此data_free并不能反映出来真正的空闲空间。
同时测试中发现,performance_schema.tables中的table_rows会受到innodb_stats_persistent_sample_pages的影响,但是data_length和index_length看起来是不会受innodb_stats_persistent_sample_pages的影响的
这里采样比例已经足够大,尽管table_rows已经是一个完全准确的数字了,但是data_length和index_length却仍旧是一个误差非常大的数字。
说到这里,那么这个碎片问题如何衡量?如果只是看performance_schema.tables或者information_schema.INNODB_TABLESPACES,其实依旧是一个无解的问题,因为无法通过这些信息,得到一个相对准确的碎片化程度。
其实在这里(参考链接)的评论中也提到这个问题,我是比较赞同的。

如果要真正得到碎片程度,其实还是需要重建表来对比实现,这里删除了1/4的数据,理论上就有大概1/4的可用空间,但是上面的查询结果并不能给出一个明确的答案,怎么验证这个答案呢?
这里就要粗暴地优化表了(optimize table fragment_test+analyze table),优化表只是“重整”了碎片,但是系统表的数据并没有更新,因此必须要再执行一次分析表 analyze table来更新元数据信息
其实这里也能说明,analyze table只是更新元数据,如果存储空间没有更新(recreated),单纯地analyze table也是没有用的。
对标进行optimize和anlayze之后,这里可以看到,物理空间确实减少了大概1/4的量。

这里其实就是为了说明一个问题:Innodb表无法通过data free来判断表的碎片化程度。
然而这里(参考链接)的测试说明删除数据后data free有明显的变化,这个又是为什么,刚特么说无法通过data free来判断表的碎片化程度,现在又说删除数据后data free有明显的变化???
其实(参考链接)中有另外一个比较有意思的测试,相对用随机删除的方式,采用连续删除的时候(或者是整个表的数据全部删除),这个data free确实会相对准确地体现出来删除数据后表size的变化情况。
这又是为什么?其实不难理解,上面已经说了,data free的计算方式,是按照完全“干净”的区(extent)来做统计的,
如果按照聚集索引连续的方式删除(相对随机删除),那些存储连续数据的区(extent)是可以完全释放出来的,这些区的空间释放出来之后,会被认为是data free,所以data free此时又是相对来说准确的。
因此,很多测试,如果想到得到客观的数据,需要尽可能多地考虑到对应的场景和测试数据情况。
碎片的衡量
实际业务中,对表的删除或者增删改,很少是按照聚集索引进行批量删除,或者说一旦存在随机性的删除或者更新(页分裂),都会造成一定程度的碎片,而这个碎片化的程度是无法通过data free来衡量的。
那么又如何衡量这个碎片程度呢?
1,自己根据业务进行预估,在可接受程度内进行optimize table,记录optimize table之后的table size变化程度,来衡量一个表在一定时间操作后的碎片化程度,从而来指导是否,或者多久对该表再次进行optimize table
2,采用上述连接中提到的innodb_ruby 这个工具,直接解析表的物理文件,这种方式相对来说更加直接。不过这个工具本人没来得及测试,理论上是没有问题的。
这里盗用上述链接中的图片,绿色的是实际使用的空间,中间的黑块就是所谓的碎片或者说是空洞。

补充:
早上起来,又想到了另外一种case,就是说随机删除后,剩余空间中出现了“空洞”,这些空洞在写数据的时候,会不会被再次利用?
验证其实很简单,写入200W数据,随机删除50W后,analyze table更新performance_schema,然后继续再写入50W行的数据,如果会利用之前随机删除的空洞空间,那么就不会重新分配物理空间,否则就会重新分配物理空间。
因为聚集索引的Id是自增的,相当于顺序写入,理论上是不会重用之前删除留下的空洞的,测试的结果还是在预期之内的,重新写入50W数据后,表对应的物理文件会有一个很明显的增加。
相关文章:
MySQL InnoDB表的碎片量化和整理(data free能否用来衡量碎片?)
网络上有很多MySQL表碎片整理的问题,大多数是通过demo一个表然后参考data free来进行碎片整理,这种方式对myisam引擎或者其他引擎可能有效(本人没有做详细的测试).对Innodb引擎是不是准确的,或者data free是不是可以参…...
Leetcode-每日一题1250. 检查「好数组」(裴蜀定理)
题目链接:https://leetcode.cn/problems/check-if-it-is-a-good-array/description/ 思路 方法:数论 题目意思很简单,让你在数组 nums中选取一些子集,可以不连续,子集中的每个数再乘以任意的数的和是否为1ÿ…...
OpenStack手动分布式部署环境准备【Queens版】
目录 1.基础环境准备(两个节点都需要部署) 1.1关闭防火墙 1.2关闭selinux 1.3修改主机名 1.4安装ntp时间服务器 1.5修改域名解析 1.6添加yum源 2.数据库安装配置 2.1安装数据库 2.2修改数据库 2.3重启数据库 2.4初始化数据库 3.安装RabbitMq…...

Web自动化测试——selenium的使用
⭐️前言⭐️ 本篇文章就进入了自动化测试的章节了,如果作为一名测试开发人员,非常需要掌握自动化测试的能力,因为它不仅能减少人力的消耗,还能提升测试的效率。 🍉欢迎点赞 👍 收藏 ⭐留言评论 …...

虚拟交换单元技术
支持VSU(Virtual Switch Unit)即虚拟交换单元技术。通过聚合链路连接,将多台物理设备虚拟为一台逻辑上统一的设备,使其能够实现统一的运行,利用单一IP 地址、单一Telnet 进程、单一命令行接口(CLI)、自动版本检查、自动…...
【STM32笔记】HAL库外部定时器、系统定时器阻塞、非阻塞延时
【STM32笔记】HAL库外部定时器、系统定时器阻塞、非阻塞延时 外部定时器 采用定时器做延时使用时 需要计算好分频和计数 另外还要配置为不进行自动重载 对于50MHz的工作频率 分频为50-1也就是50M/501M 一次计数为1us 分频为50000-1也就是1k 一次计数为1ms 我配置的是TIM6 只…...

[Springboot 单元测试笔记] - Mock 和 spy的使用
Springboot单元测试 - 依赖类mock测试 通常单元测试中,我们会隔离依赖对于测试类的影响,也就是假设所有依赖的一定会输出理想结果,在测试中可以通过Mock方法来确保输出结果,这也就引入另一个测试框架Mockito。 Mockito框架的作用…...

互联网新时代要来了(二)什么是AIGC?
什么是AIGC? 最近,又火了一个词“**AIGC”**2022年被称为是AIGC元年。那么我们敬请期待,AIGC为我们迎接人工智能的下一个时代。 TIPS:内容来自百度百科、知乎、腾讯、《AIGC白皮书》等网页 什么是AIGC?1.什么是AIGC?…...

75V的TVS二极管有哪些型号?常用的
瞬态抑制TVS二极管工作峰值反向电压最低3.3V,最高可达513V,甚至更高。很多电子工程师都知道,TVS二极管在实际应用选型过程中,第一步要确认的就是其工作峰值反向电压。2023年春节已过,东沃电子正月初八就开工了…...

测试开发之Django实战示例 第十章 创建在线教育平台
第十章 创建在线教育平台在上一章,我们为电商网站项目添加了国际化功能,还创建了优惠码和商品推荐系统。在本章,会建立一个新的项目:一个在线教育平台,并创内容管理系统CMS(Content Management System&…...
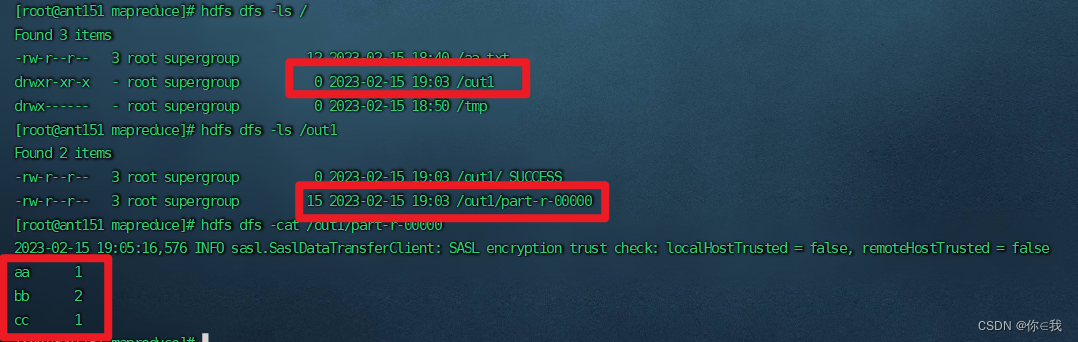
Hadoop高可用搭建(二)
目录 解压Hadoop 改名 更改配置文件 workers hdfs-site.xml core-site.xml hadoop-env.sh mapred-site.xml yarn-site.xml 设置环境变量 启动集群 启动zk集群 启动journalnode服务 格式化hfds namenode 启动namenode 同步namenode信息 查看namenode节点状态 …...

如何用企微SCRM管理系统发掘老客户的新增长点?
如何用企微SCRM管理系统发掘老客户的新增长点? 一直做投放拉新,很快营销成本会难以支撑,如果在私域运营中始终留不下老用户,那么运营也是失败的。 开发老客户的成本只需新客户成本的1/6,但很多企业对老客户都忽视了&…...

我用python疯狂爬取公司数据
我是半路从一个纯小白学过来的,学习途中也掉过许多坑,在这里建议新手要先把基础打扎实,然后再去学习自己需要的内容,不要想着全部学完再用,那样你是永远学不完的,用哪方面就学习哪方面的内容,不…...

EMR集群运行TPC-DS在云盘和OSS中的对比
1.简介 TPC-DS是大数据领域最为知名的Benchmark标准。本文介绍使用阿里云EMR集群运行TPC-DS在云盘和OSS中的表现对比。 2.环境准备 1.创建EEMR-5.10.1集群 1个master,2个core,3台机器都s是4c16g。 2.安装Git和Maven sudo yum install -y git maven3.下载TPC-DS Benchmark工…...
菜鸟在 windows 下 python 中安装 jupyter 踩坑要点 、被神化的 VsCode
我平时用不到 python ,更没用过 jupyter ,因此我的 python知识仅限于知道有 python 这么个编程语言,会写个 print("Hello World!!!") 而已,完全没听过 jupyter ,因为某些原因今天需要安装下 jupyter 看看&am…...

k8s简单搭建
前言 最近学习k8s,跟着网上各种教程搭建了简单的版本,一个master节点,两个node节点,这里记录下防止以后忘记。 具体步骤 准备环境 用Oracle VM VirtualBox虚拟机软件安装3台虚拟机,一台master节点,两台…...

计算机SCI期刊审稿人,一般关注论文的那些问题? - 易智编译EaseEditing
编辑主要关心: (1)文章内容是否具有足够的创新性? (2)文章主题是否符合期刊的受众读者? (3)文章方法学是否合理,数据处理是否充分? (…...

Docker迁移以及环境变量问题
问题一描述将docker容器通过docker export命令打包,传输到另外的服务器,再通过docker import命令导入后,发现原来docker容器中的环境变量失效了。解决方案1. 【无效方案】直接在docker容器中通过export命令设置环境变量。export LD_LIBRARY_P…...
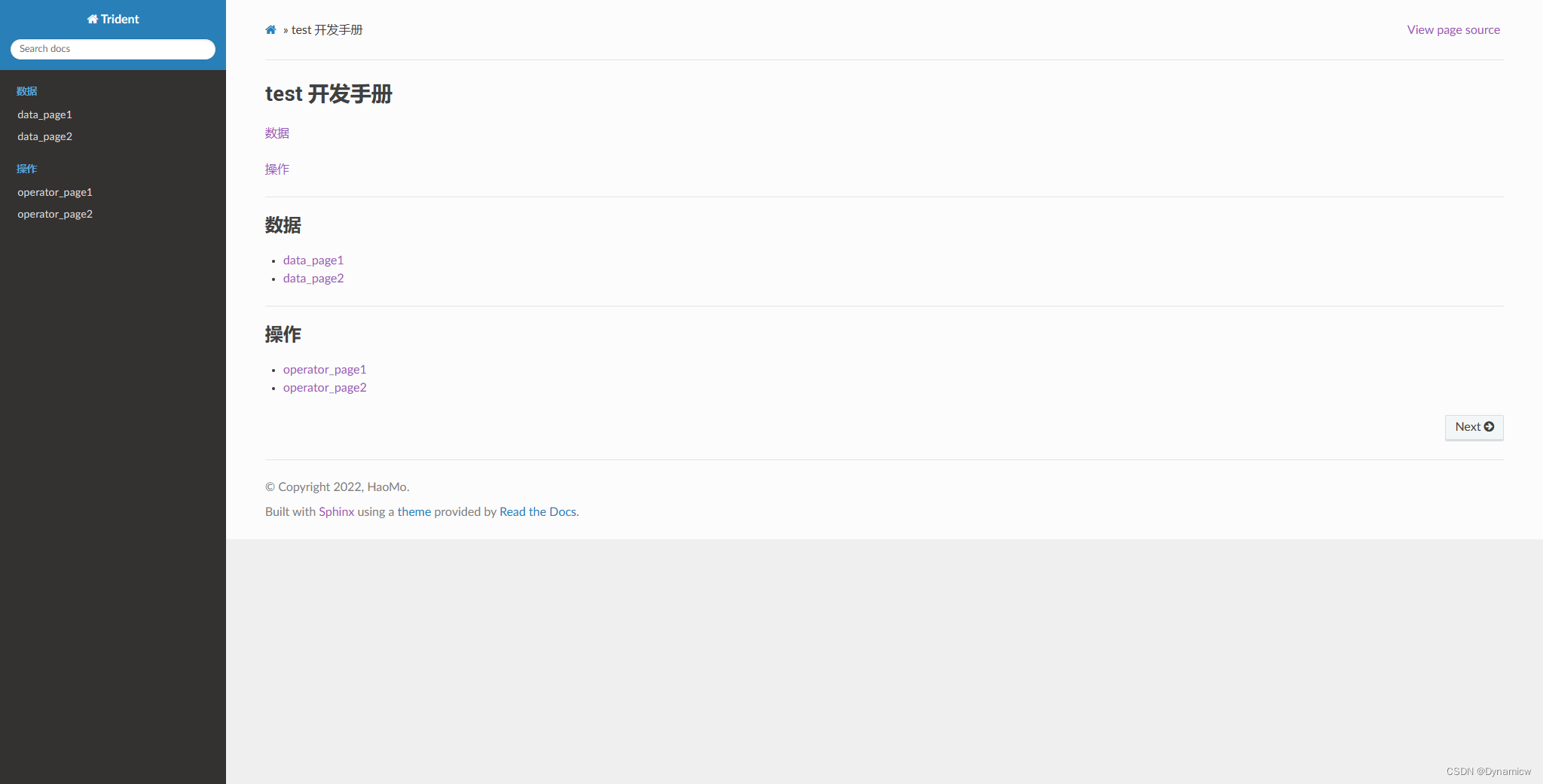
Sphinx文档生成工具(二)
rst语法 官方的语法手册 行内的样式: #斜体 *message* #粗体 **message** #等宽 不能有换行 message标题 一级标题 ^^^^^^^^ 二级标题 --------- 三级标题 >>>>>>>>> 四级标题 ::::::::: 五级标题六级标题 """"…...

Python快速上手系列--JSON--入门篇
本章我们来看看json的一些应用。简单易懂还实用。一起来看看数据类型以及一些语法规则吧1、数字(整数或浮点数) 如:{"age":18, "score":70.5} 注意,数字直接写,不需要带任何符号2、字符串…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...