Hbase
java客户端
导入maven依赖
| XML |
获取hbase的连接,list出所有的表
| Java |
获取到所有的命名空间
| Java |
创建一个命名空间
| Java |
创建带有多列族的表
| Java |
向表中添加数据
| Java |
get表中的数据
| Java |
scan表中的数据
| Java |
删除一行数据
| Java |
原理加强
数据存储
行式存储
传统的行式数据库将一个个完整的数据行存储在数据页中
列式存储
列式数据库是将同一个数据列的各个值存放在一起
| 传统行式数据库的特性如下: 列式数据库的特性如下: |
列族式存储
列族式存储是一种非关系型数据库存储方式,按列而非行组织数据。它的数据模型是面向列的,即把数据按照列族的方式组织,将属于同一列族的数据存储在一起。每个列族都有一个唯一的标识符,一般通过列族名称来表示。它具有高效的写入和查询性能,能够支持极大规模的数据
- 如果一个表有多个列族, 每个列族下只有一列, 那么就等同于列式存储。
- 如果一个表只有一个列族, 该列族下有多个列, 那么就等同于行式存储.
hbase的存储路径:
在conf目录下的hbase-site.xml文件中配置了数据存储的路径在hdfs上
| XML |
region
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。
Region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。
region的分配
一个表中可以包含一个或多个Region。
每个Region只能被一个RS(RegionServer)提供服务,RS可以同时服务多个Region,来自不同RS上的Region组合成表格的整体逻辑视图。
regionServer其实是hbase的服务,部署在一台物理服务器上,region有一点像关系型数据的分区,数据存放在region中,当然region下面还有很多结构,确切来说数据存放在memstore和hfile中。我们访问hbase的时候,先去hbase 系统表查找定位这条记录属于哪个region,然后定位到这个region属于哪个服务器,然后就到哪个服务器里面查找对应region中的数据
Memstore Flush流程
flus流程分为三个阶段:
- prepare阶段:遍历当前 Region中所有的 MemStore ,将 MemStore 中当前数据集 CellSkpiListSet 做一个快照 snapshot;然后再新建一个 CellSkipListSet。后期写入的数据都会写入新的 CellSkipListSet 中。prepare 阶段需要加一把 updataLock 对写请求阻塞,结束之后会释放该锁。因为此阶段没有任何费时操作,因此锁持有时间很短
- flush阶段:遍历所有 MemStore,将 prepare 阶段生成的snapshot 持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及到磁盘 IO 操作,因此相对耗时
- commit阶段:遍历所有 MemStore,将flush阶段生成的临时文件移动到指定的 ColumnFamily 目录下,针对 HFile生成对应的 StoreFile 和 Reader,把 StoreFile 添加到 HStore 的 storefiles 列表中,最后再清空 prepare 阶段生成的 snapshot快照
Compact 合并机制
hbase中的合并机制分为自动合并和手动合并
自动合并:
- minor compaction 小合并
- major compacton 大合并
minor compaction(小合并)
将 Store 中多个 HFile 合并为一个相对较大的 HFile 过程中会选取一些小的、相邻的 StoreFile 将他们合并成一个更大的 StoreFile,对于超过 TTL 的数据、更新的数据、删除的数据仅仅只是做了标记,并没有进行物理删除。一次 minor compaction 过后,storeFile会变得更少并且更大,这种合并的触发频率很高
小合并的触发方式:
memstore flush会产生HFile文件,文件越来越多就需要compact.每次执行完Flush操作之后,都会对当前Store中的文件数进行判断,一旦文件数大于配置3,就会触发compaction。compaction都是以Store为单位进行的,而在Flush触发条件下,整个Region的所有Store都会执行compact
后台线程周期性检查
检查周期可配置:
hbase.server.thread.wakefrequency/默认10000毫秒)*hbase.server.compactchecker.interval.multiplier/默认1000
CompactionChecker大概是2hrs 46mins 40sec 执行一次
| XML |
major compaction(大合并)
合并 Store 中所有的 HFile 为一个 HFile,将所有的 StoreFile 合并成为一个 StoreFile,这个过程中还会清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。合并频率比较低,默认7天执行一次,并且性能消耗非常大,建议生产关闭(设置为0),在应用空间时间手动触发。一般是可以手动控制进行合并,防止出现在业务高峰期。
| XML |
手动合并
一般来讲,手动触发compaction通常是为了执行major compaction,一般有这些情况需要手动触发合并是因为很多业务担心自动maior compaction影响读写性能,因此会选择低峰期手动触发也有可能是用户在执行完alter操作之后希望立刻生效,执行手动触发maiorcompaction:
造数据
| Shell |
| Shell |
region的拆分
region中存储的是一张表的数据,当region中的数据条数过多的时候,会直接影响查询效率。当region过大的时候,region会被拆分为两个region,HMaster会将分裂的region分配到不同的regionserver上,这样可以让请求分散到不同的RegionServer上,已达到负载均衡 , 这也是HBase的一个优点
1region的拆分策略
1. ConstantSizeRegionSplitPolicy:0.94版本前,HBase region的默认切分策略
| 当region中最大的store大小超过某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。 但是在生产线上这种切分策略却有相当大的弊端(切分策略对于大表和小表没有明显的区分):
|
2. IncreasingToUpperBoundRegionSplitPolicy:0.94版本~2.0版本默认切分策略
| 总体看和ConstantSizeRegionSplitPolicy思路相同,一个region中最大的store大小大于设置阈值就会触发切分。 但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系. region split阈值的计算公式是:
例如:
特点
|
3. SteppingSplitPolicy:2.0版本默认切分策略
| 相比 IncreasingToUpperBoundRegionSplitPolicy 简单了一些 region切分的阈值依然和待分裂region所属表在当前regionserver上的region个数有关系
这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region,而是适可而止。 |
4. KeyPrefixRegionSplitPolicy
| 根据rowKey的前缀对数据进行分区,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在相同的region中 |
5. DelimitedKeyPrefixRegionSplitPolicy
| 保证相同前缀的数据在同一个region中,例如rowKey的格式为:userid_eventtype_eventid,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。 按照分隔符进行切分,而KeyPrefixRegionSplitPolicy是按照指定位数切分 |
6. BusyRegionSplitPolicy
| 按照一定的策略判断Region是不是Busy状态,如果是即进行切分 如果你的系统常常会出现热点Region,而你对性能有很高的追求,那么这种策略可能会比较适合你。它会通过拆分热点Region来缓解热点Region的压力,但是根据热点来拆分Region也会带来很多不确定性因素,因为你也不知道下一个被拆分的Region是哪个 |
7. DisabledRegionSplitPolicy:不启用自动拆分, 需要指定手动拆分
手动合并拆分egion
手动合并
| Shell |
手动拆分
| Shell |
bulkLoad实现批量导入
bulkloader : 一个用于批量快速导入数据到hbase的工具/方法
用于已经存在一批巨量静态数据的情况!如果不用bulkloader工具,则只能用rpc请求,一条一条地通过rpc提交给regionserver去插入,效率极其低下
相比较于直接写HBase,BulkLoad主要是绕过了写WAL日志这一步,还有写Memstore和Flush到磁盘,从理论上来分析性能会比Put快!
BulkLoad实战示例1:importTsv工具
原理:
Importtsv是hbase自带的一个 csv文件--》HFile文件 的工具,它能将csv文件转成HFile文件,并发送给regionserver。它的本质,是内置的一个将csv文件转成hfile文件的mr程序!
案例演示:
| Shell |
| ImportTsv命令的参数说明如下: -Dimporttsv.skip.bad.lines=false - 若遇到无效行则失败 -Dimporttsv.separator=, - 使用特定分隔符,默认是tab也就是\t -Dimporttsv.timestamp=currentTimeAsLong - 使用导入时的时间戳 -Dimporttsv.mapper.class=my.Mapper - 使用用户自定义Mapper类替换TsvImporterMapper -Dmapreduce.job.name=jobName - 对导入使用特定mapreduce作业名 -Dcreate.table=no - 避免创建表,注:如设为为no,目标表必须存在于HBase中 -Dno.strict=true - 忽略HBase表列族检查。默认为false -Dimporttsv.bulk.output=/user/yarn/output 作业的输出目录 |
示例演示:
| Plain Text |
相关文章:

Hbase
java客户端 导入maven依赖 XML<dependencies> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.6</version> </dependency>…...
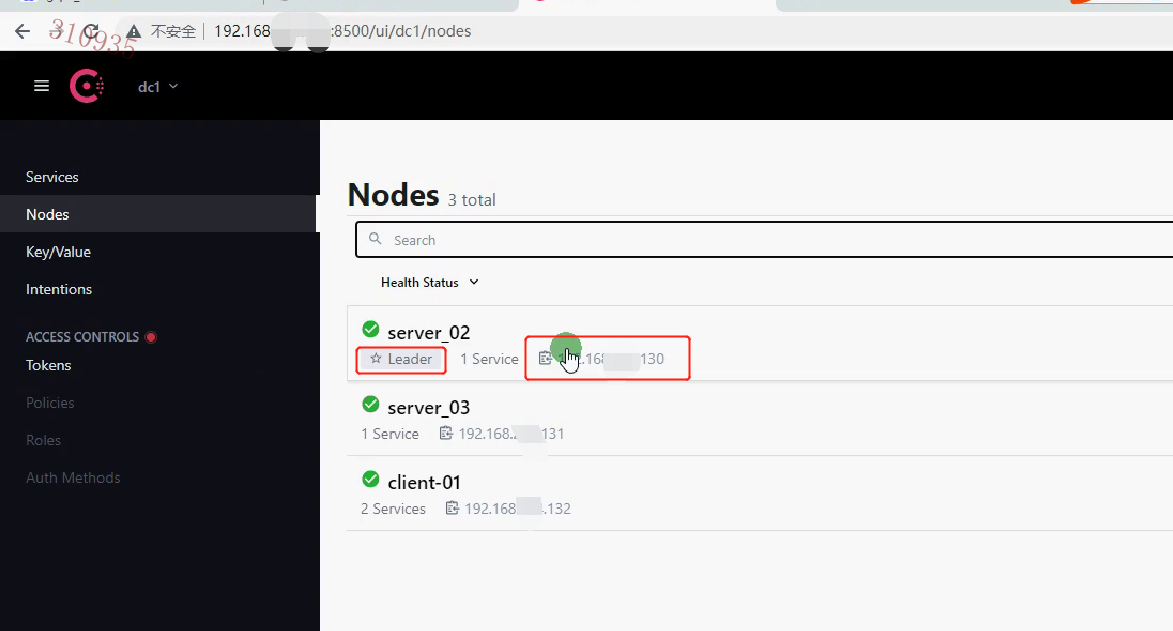
[golang 微服务] 5. 微服务服务发现介绍,安装以及consul的使用,Consul集群
一.服务发现介绍 引入 上一节讲解了使用 gRPC创建微服务,客户端的一个接口可能需要调用 N个服务,而不同服务可能存在 不同的服务器,这时,客户端就必须知道所有服务的 网络位置(ipport),来进行连接服务器操作,如下图所示: 以往的做…...

【数据结构】哈希应用
目录 一、位图 1、位图概念 2、位图实现 2.1、位图结构 2.2、比特位置1 2.3、比特位置0 2.4、检测位图中比特位 3、位图例题 3.1、找到只出现一次的整数 3.2、找到两个文件交集 3.3、找到出现次数不超过2次的所有整数 二、布隆过滤器 1、布隆过滤器提出 2、布隆过…...
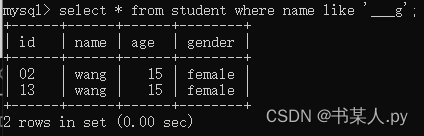
【 Python 全栈开发 - WEB开发篇 - 31 】where条件查询
文章目录 一、where条件查询1.关系运算符查询2.IN关键字查询3.BETWEEN AND关键字查询4.空值查询5.AND关键字查询6.OR关键字查询7.LIKE关键字查询普通字符串含有%通配的字符串含有_通配的字符串 一、where条件查询 MySQL 的 where 条件查询是指在查询数据时,通过 wh…...

Android系统的Ashmem匿名共享内存子系统分析(5)- 实现共享的原理
声明 其实对于Android系统的Ashmem匿名共享内存系统早就有分析的想法,记得2019年6、7月份Mr.Deng离职期间约定一起对其进行研究的,但因为我个人问题没能实施这个计划,留下些许遗憾…文中参考了很多书籍及博客内容,可能涉及的比较…...

谈一谈冷门的C语言爬虫
C语言可以用来编写爬虫程序,但是相对于其他编程语言,C语言的爬虫开发可能会更加复杂和繁琐。因为C语言本身并没有提供现成的爬虫框架和库,需要自己编写网络请求、HTML解析等功能。 不过,如果你对C语言比较熟悉,也可以…...

基于状态的维护(CBM)如何推动设备效率提高?
基于状态的维护(Condition-Based Maintenance,CBM)是一种先进的维护策略,通过实时监测和分析设备的状态数据,预测设备故障并采取相应的维护措施。CBM基于数据驱动的方法,能够提高设备的可用性、降低维修成本…...
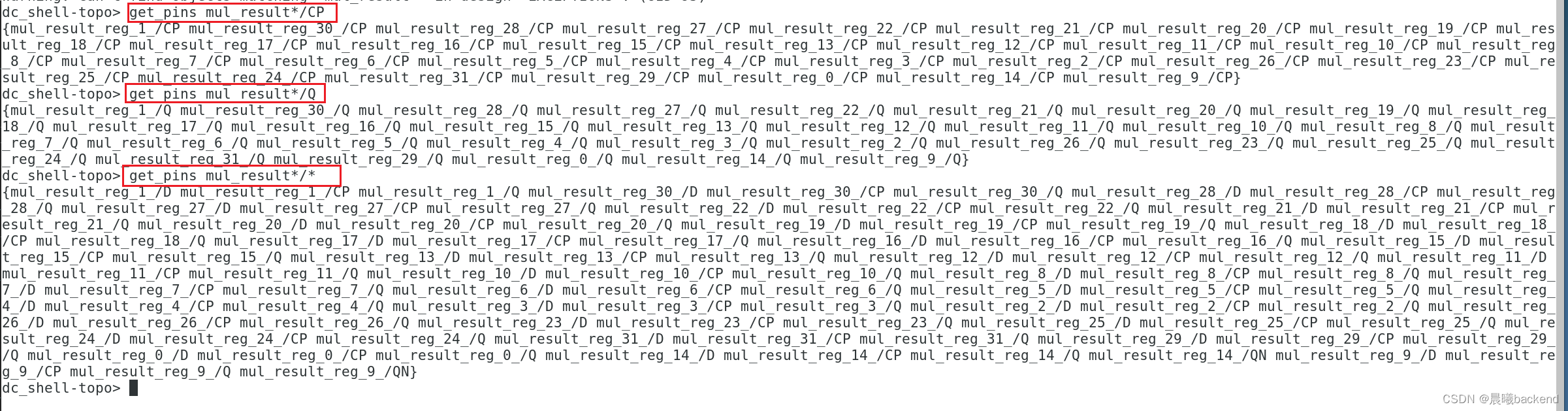
DC LAB8SDC约束四种时序路径分析
DC LAB 1.启动DC2.读入设计3. 查看所有违例的约束报告3.1 report_constraint -all_violators (alias rc)3.2 view report_constraint -all_violators -verbose -significant_digits 4 (打印详细报告) 4.查看时序报告 report_timing -significant_digits 45. 约束组合逻辑(adr_i…...

学生考试作弊检测系统 yolov8
学生考试作弊检测系统采用yolov8网络模型人工智能技术,学生考试作弊检测系统过在考场中安装监控设备,对学生的作弊行为进行实时监测。当学生出现作弊行为时,学生考试作弊检测系统将自动识别并记录信息。YOLOv8 算法的核心特性和改动可以归结为…...

【基于容器的部署、扩展和管理】 3.2 基于容器的应用程序部署和升级
往期回顾: 第一章:【云原生概念和技术】 第二章:【容器化应用程序设计和开发】 第三章:【3.1 容器编排系统和Kubernetes集群的构建】 3.2 基于容器的应用程序部署和升级 3.2 基于容器的应用程序部署和升级 3.2 基于容器的应用程…...

Jmeter 实现 grpc服务 压测
一、Jmeter安装与配置 网上有很多安装与配置文章,在此不做赘述 二、Jmeter gRPC Request 插件安装 插件下载地址:JMeter Plugins :: JMeter-Plugins.org 将下载文件解压后放到Jmeter安装目录下 /lib/ext 然后在终端输入Jmeter即可打开 Jmeter GUI界面…...
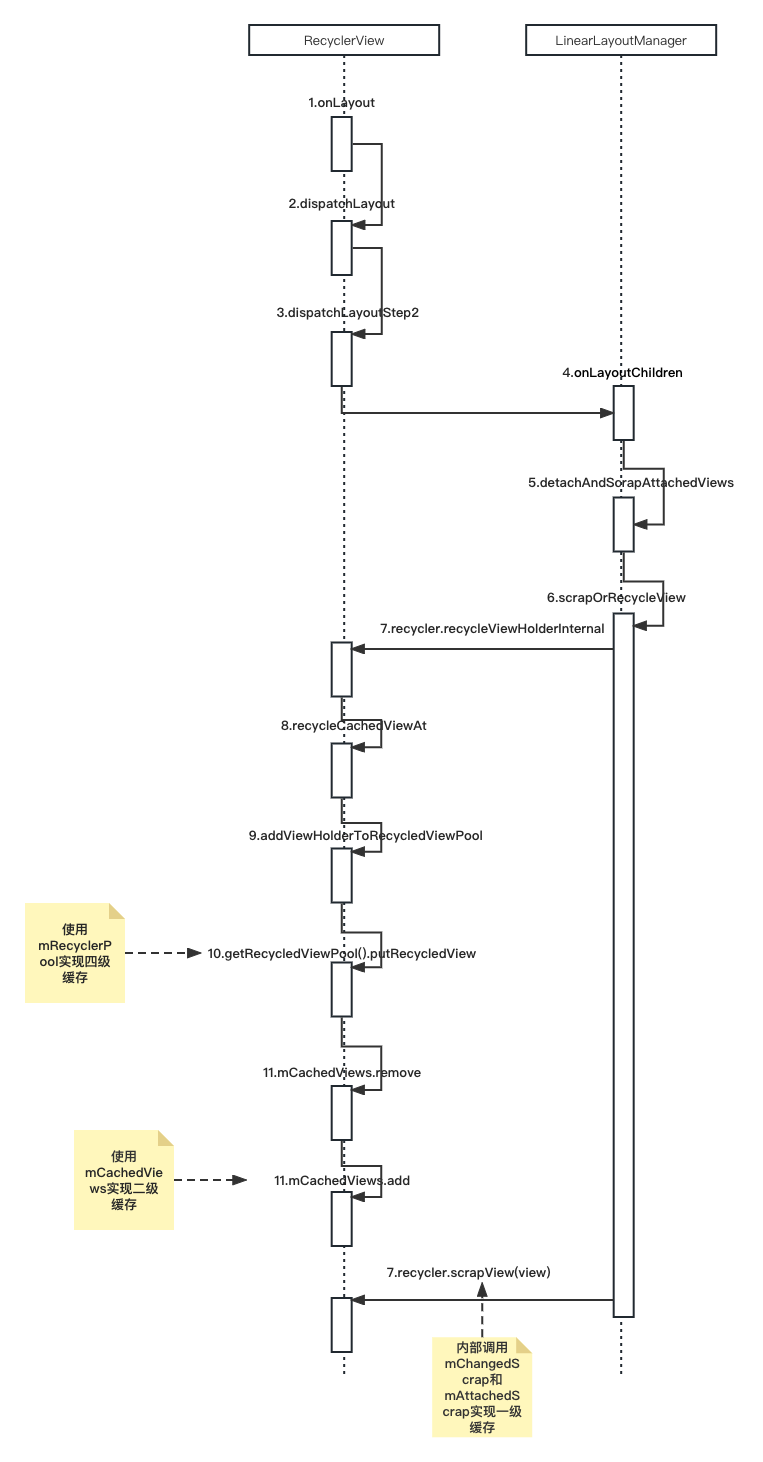
深入源码分析RecyclerView缓存复用原理
文章目录 前言四级缓存 源码分析缓存一级缓存(mChangedScrap和mChangedScrap)二级缓存(mCachedViews)三级缓存(ViewCacheExtension)四级缓存(mRecyclerPool)缓存池mRecyclerPool结构…...

内网隧道代理技术(一)之内网隧道代理概述
内网隧道代理技术 内网转发 在渗透测试中,当我们获得了外网服务器(如web服务器,ftp服务器,mali服务器等等)的一定权限后发现这台服务器可以直接或者间接的访问内网。此时渗透测试进入后渗透阶段,一般情况…...

设计图形用户界面的原则
1) 一般性原则:界面要具有一致性、常用操作要有快捷方式、 提供简单的错误处理、对操作人员的重要操作要有信息反馈、操作可 逆、设计良好的联机帮助、合理划分并高效地使用显示屏、保证信息 显示方式与数据输入方式的协调一致 2) 颜色的使用:颜色…...

1:操作系统导论
1.1操作系统的定义 •Anoperatingsystemactsanintermediarybetweenuserofacomputerandthecomputer hardware. ◦ 操作系统充当计算机⽤⼾和计算机硬件之间的中介 •Thepurposeofanoperatingsystemistoprovideanenvironmentinwhichausercanexecute programsinaconvenientandeff…...

什么是微软的 Application Framework?
我是荔园微风,作为一名在IT界整整25年的老兵,今天来看一下什么是微软的 Application Framework? 到底什么是 Application Framework? 还没有真正掌握任何一套Application Framework的使用之前,就来研究这个真的不是很…...

一个关于宏定义的问题,我和ChatGPT、NewBing、Google Bard、文心一言 居然全军覆没?
文章目录 一、问题重述二、AI 解题2.1 ChatGPT2.2 NewBing2.3 Google Bard2.4 文心一言2.5 小结 一、问题重述 今天在问答模块回答了一道问题,要睡觉的时候,又去看了一眼,发现回答错了。 问题描述:下面的z的值是多少。 #define…...

【服务器数据恢复】断电导致RAID无法找到存储设备的数据恢复案例
服务器数据恢复环境: HP EVA存储,6块SAS硬盘组建的raid5磁盘阵列。上层操作系统是WINDOWS SERVER。该存储为公司内部文件服务器使用。 服务器故障&分析: 在遭遇两次意外断电后,设备重启时raid提示“无法找到存储设备”。管理员…...
Windows上不可或缺的5款宝藏软件,工作效率拉满!
职场小白与大牛的区别:小白需要耗费大半天琢磨的事情,而大牛可以只花5分钟就能处理。 “牛人”,即拥有过人之处,专业、经验、技术等等,学会灵活运用高效率的工具也是关键的一点。工具找得好,运用得快&#…...
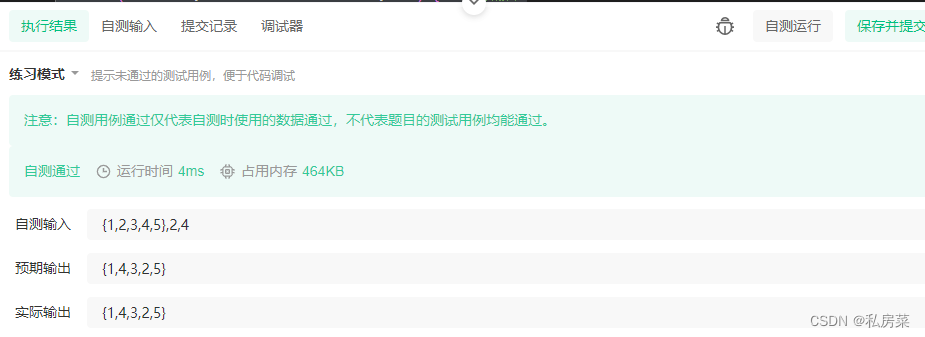
链表内指定区间反转
题目: 将一个节点数为 size 链表 m 位置到 n 位置之间的区间反转,要求时间复杂度 O(n),空间复杂度 O(1)。 例如: 给出的链表为 1→2→3→4→5→NULL,m2,n4 返回 1→4→3→2→5→NULL 数据范围ÿ…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

掌握 HTTP 请求:理解 cURL GET 语法
cURL 是一个强大的命令行工具,用于发送 HTTP 请求和与 Web 服务器交互。在 Web 开发和测试中,cURL 经常用于发送 GET 请求来获取服务器资源。本文将详细介绍 cURL GET 请求的语法和使用方法。 一、cURL 基本概念 cURL 是 "Client URL" 的缩写…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...
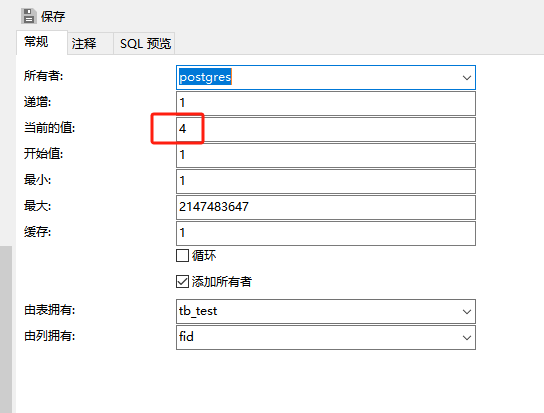
pgsql:还原数据库后出现重复序列导致“more than one owned sequence found“报错问题的解决
问题: pgsql数据库通过备份数据库文件进行还原时,如果表中有自增序列,还原后可能会出现重复的序列,此时若向表中插入新行时会出现“more than one owned sequence found”的报错提示。 点击菜单“其它”-》“序列”,…...

Python爬虫(52)Scrapy-Redis分布式爬虫架构实战:IP代理池深度集成与跨地域数据采集
目录 一、引言:当爬虫遭遇"地域封锁"二、背景解析:分布式爬虫的两大技术挑战1. 传统Scrapy架构的局限性2. 地域限制的三种典型表现 三、架构设计:Scrapy-Redis 代理池的协同机制1. 分布式架构拓扑图2. 核心组件协同流程 四、技术实…...