深度学习8:详解生成对抗网络原理
目录
大纲
生成随机变量
可以伪随机生成均匀随机变量
随机变量表示为操作或过程的结果
逆变换方法
生成模型
我们试图生成非常复杂的随机变量……
…所以让我们使用神经网络的变换方法作为函数!
生成匹配网络
培养生成模型
比较基于样本的两个概率分布
反向传播分布匹配错误
生成性对抗网络
“间接”训练方法
理想的情况:完美的发电机和鉴别器
近似:对抗性神经网络
关于GAN的数学细节
生成性对抗网络属于一组生成模型。这意味着他们能够生成/生成(我们将看到如何)新内容。为了说明这种“生成模型”的概念,我们可以看一些用GAN获得的结果的众所周知的例子。

这些是由Generative Adversarial Networks在对两个数据集进行训练后生成的样本:MNIST和TFD。对于两者,最右边的列包含与直接相邻生成的样本最接近的真实数据。这向我们展示了生成的数据是真正生成的,而不仅仅是由网络记忆。
大纲
在下面的第一节中,我们将讨论从给定分布生成随机变量的过程。然后,在第2节中,我们将通过一个例子展示GAN试图解决的问题可以表示为随机变量生成问题。在第3节中,我们将讨论基于匹配的生成网络,并展示它们如何回答第2节中描述的问题。最后在第4节中,我们将介绍GAN。更具体地说,我们将展示具有其损失功能的一般架构,并且我们将与之前的所有部分建立链接。
生成随机变量
我们提醒一些现有方法,尤其是逆变换方法,它允许从简单的均匀随机变量生成复杂的随机变量。尽管所有这些看起来与我们的物质主题GAN相差甚远
可以伪随机生成均匀随机变量
计算机基本上是确定性的。因此,从理论上讲,生成真正随机的数字是不可能的(即使我们可以说“真正的随机性是什么?”这个问题很困难)。但是,可以定义生成数字序列的算法,其特性非常接近理论随机数序列的属性。特别是,计算机能够使用伪随机数生成器生成一系列数字,这些数字近似地遵循0和1之间的均匀随机分布。统一的情况是一个非常简单的情况,可以在其上建立更复杂的随机变量不同的方法。
随机变量表示为操作或过程的结果
存在旨在产生更复杂的随机变量的不同技术。其中我们可以找到,例如,逆变换方法,拒绝抽样,Metropolis-Hasting算法等。所有这些方法都依赖于不同的数学技巧,这些技巧主要在于表示我们想要生成的随机变量作为操作(通过更简单的随机变量)或过程的结果。
拒绝抽样表示随机变量是一个过程的结果,该过程不是从复杂分布中采样,而是从众所周知的简单分布中采样,并根据某些条件接受或拒绝采样值。重复此过程直到采样值被接受,我们可以证明,在正确接受条件下,有效采样的值将遵循正确的分布。
在Metropolis-Hasting算法中,想法是找到马尔可夫链(MC),使得该MC的静态分布对应于我们想要对随机变量进行采样的分布。一旦这个MC发现,我们可以在这个MC上模拟足够长的轨迹来考虑我们已经达到稳定状态,然后我们以这种方式获得的最后一个值可以被认为是从感兴趣的分布中得出的。
我们不会再进一步了解拒绝抽样和Metropolis-Hasting的细节,因为这些方法不会引导我们遵循GAN背后的概念(尽管如此,感兴趣的读者可以参考指向的维基百科文章及其中的链接) 。但是,让我们更多地关注逆变换方法。
逆变换方法
逆变换方法的想法只是为了表示我们的复杂性 – 在本文中,“复杂”应该始终被理解为“不简单”而不是数学意义 – 随机变量作为应用于函数的函数的结果统一随机变量我们知道如何生成。
我们在下面的一个例子中考虑。设X是我们想要采样的复杂随机变量,U是[0,1]上的均匀随机变量,我们知道如何从中采样。我们提醒随机变量由其累积分布函数(CDF)完全定义。随机变量的CDF是从随机变量的定义域到区间[0,1]的函数,并且在一个维度中定义,使得
![]()
在我们的均匀随机变量U的特定情况下,我们有
![]()
为简单起见,我们在此假设函数CDF_X是可逆的并且表示其反函数

(通过使用函数的广义逆,可以很容易地将该方法扩展到不可逆的情况,但它实际上不是我们想要关注的主要点)。然后,如果我们定义

我们有

我们可以看到,Y和X具有相同的CDF,然后定义相同的随机变量。因此,通过如上定义Y(作为均匀随机变量的函数),我们设法定义了具有目标分布的随机变量。
总而言之,逆变换方法是通过使均匀随机变量经过精心设计的“变换函数”(逆CDF)来生成遵循给定分布的随机变量的方式。事实上,这种“逆变换方法”的概念可以扩展到“变换方法”的概念,“变换方法”更广泛地说,它是由一些较简单的随机变量生成随机变量(不一定是均匀的,然后变换函数是不再是逆CDF)。从概念上讲,“变换函数”的目的是使初始概率分布变形/重塑:变换函数从初始分布与目标分布相比过高,并将其置于过低的位置。

逆变换方法的图示。蓝色:均匀分布在[0,1]上。橙色:标准高斯分布。灰色:从均匀到高斯分布的映射(逆CDF)。
生成模型
我们试图生成非常复杂的随机变量……
假设我们有兴趣生成大小为n乘n像素的狗的黑白方形图像。我们可以将每个数据重新整形为N = n×n维向量(通过将列堆叠在彼此之上),使得狗的图像可以由向量表示。然而,这并不意味着所有的矢量都代表一只狗形状回到正方形!因此,我们可以说,有效地给出看起来像狗的东西的N维向量根据整个N维向量空间上的非常特定的概率分布来分布(该空间的某些点很可能代表狗,而它是对其他人来说极不可能)。同样的精神,在这个N维向量空间上存在猫,鸟等图像的概率分布。
然后,生成狗的新图像的问题等同于在N维向量空间上生成跟随“狗概率分布”的新向量的问题。事实上,我们面临着针对特定概率分布生成随机变量的问题。
在这一点上,我们可以提到两件重要的事情。首先,我们提到的“狗概率分布”是在非常大的空间上非常复杂的分布。其次,即使我们可以假设存在这样的基础分布(实际上存在看起来像狗的图像而其他图像看起来不像),我们显然不知道如何明确地表达这种分布。之前的两点都使得从该分布生成随机变量的过程非常困难。然后让我们尝试解决以下两个问题。
…所以让我们使用神经网络的变换方法作为函数!
当我们尝试生成狗的新图像时,我们的第一个问题是N维向量空间上的“狗概率分布”是一个非常复杂的问题,我们不知道如何直接生成复杂的随机变量。然而,正如我们非常清楚如何生成N个不相关的均匀随机变量,我们可以使用变换方法。为此,我们需要将N维随机变量表示为应用于简单N维随机变量的非常复杂函数的结果!
在这里,我们可以强调这样的事实:找到变换函数并不像我们在描述逆变换方法时所做的那样只采用累积分布函数(我们显然不知道)的闭式逆。转换函数无法明确表达,因此,我们必须从数据中学习它。
在这些情况下,大多数情况下,非常复杂的功能自然意味着神经网络建模。然后,我们的想法是通过一个神经网络对变换函数进行建模,该神经网络将一个简单的N维均匀随机变量作为输入,并作为输出返回另一个N维随机变量,在训练之后,该随机变量应遵循正确的“狗概率分布” 。一旦设计了网络架构,我们仍然需要对其进行培训。在接下来的两节中,我们将讨论培训这些生成网络的两种方法,包括GAN背后的对抗训练的想法!

使用神经网络的生成模型概念的插图。显然,我们真正谈论的维度远高于此处所表示的维度。
生成匹配网络
免责声明:“生成匹配网络”的名称不是标准的。但是,我们可以在文献中找到,例如,“Generative Moments Matching Networks”或“Generative Features Matching Networks”。我们只是想在这里使用稍微更一般的面额来描述我们所描述的内容。
培养生成模型
到目前为止,我们已经证明了我们生成狗的新图像的问题可以被重新描述为在N维向量空间中生成跟随“狗概率分布”的随机向量的问题,并且我们建议使用变换方法,用神经网络来模拟变换函数。
现在,我们仍然需要训练(优化)网络来表达正确的变换功能。为此,我们可以建议两种不同的训练方法:直接训练方法和间接训练方法。直接训练方法包括比较真实和生成的概率分布,并通过网络反向传播差异(误差)。这是规则生成匹配网络(GMNs)的想法。对于间接训练方法,我们不直接比较真实和生成的分布。相反,我们通过使这两个分布经过选择的下游任务来训练生成网络,使得生成网络相对于下游任务的优化过程将强制生成的分布接近真实分布。最后一个想法是生成对抗网络(GAN)背后的一个,我们将在下一节中介绍。但就目前而言,让我们从直接方法和GMN开始。
比较基于样本的两个概率分布
如上所述,GMN的想法是通过直接将生成的分布与真实分布进行比较来训练生成网络。但是,我们不知道如何明确表达真正的“狗概率分布”,我们也可以说生成的分布过于复杂而无法明确表达。因此,基于显式表达式的比较是不可能的。但是,如果我们有一种比较基于样本的概率分布的方法,我们可以使用它来训练网络。实际上,我们有一个真实数据的样本,我们可以在训练过程的每次迭代中生成生成数据的样本。
虽然理论上可以使用任何能够有效比较基于样本的两个分布的距离(或相似性度量),但我们可以特别提到最大均值差异(MMD)方法。MMD定义了可以基于这些分布的样本计算(估计)的两个概率分布之间的距离。虽然它不完全超出了本文的范围,但我们决定不再花费更多时间来描述MDD。但是,我们的项目很快就会发布一篇文章,其中将包含有关它的更多详细信息。想要了解MMD的更多信息的读者可以参考这些幻灯片,本文或本文。
反向传播分布匹配错误
因此,一旦我们定义了一种基于样本比较两种分布的方法,我们就可以定义GMN中生成网络的训练过程。给定具有均匀概率分布的随机变量作为输入,我们希望所生成的输出的概率分布是“狗概率分布”。然后,GMN的想法是通过重复以下步骤来优化网络:
- 产生一些统一的输入
- 使这些输入通过网络并收集生成的输出
- 比较真实的“狗概率分布”和基于可用样本生成的一个(例如计算真实狗图像样本与生成的样本的样本之间的MMD距离)
- 使用反向传播来进行梯度下降的一个步骤,以降低真实分布和生成分布之间的距离(例如MMD)
如上所述,当遵循这些步骤时,我们在网络上应用梯度下降,其具有损失函数,该函数是当前迭代中的真实分布与生成分布之间的距离。

生成匹配网络采用简单的随机输入,生成新数据,直接比较生成数据的分布与真实数据的分布,并反向传播匹配误差以训练网络。
生成性对抗网络
“间接”训练方法
上面提出的“直接”方法在训练生成网络时直接比较生成的分布与真实分布。规则GAN的好主意在于用间接的替代方式替换这种直接比较,后者采用这两种分布的下游任务的形式。然后对该任务进行生成网络的训练,使得它迫使所生成的分布越来越接近真实分布。
GAN的下游任务是真实样本和生成样本之间的歧视任务。或者我们可以说“非歧视”任务,因为我们希望歧视尽可能地失败。因此,在GAN架构中,我们有一个鉴别器,它可以获取真实数据和生成数据的样本,并尝试尽可能地对它们进行分类,以及一个经过培训的发生器,以尽可能地欺骗鉴别器。让我们看一个简单的例子,为什么我们提到的直接和间接方法理论上应该导致相同的最优生成器。
理想的情况:完美的发电机和鉴别器
为了更好地理解为什么训练生成器以欺骗鉴别器将导致与直接训练生成器以匹配目标分布相同的结果,让我们采用简单的一维示例。我们暂时忘记了如何表示生成器和鉴别器,并将它们视为抽象概念(将在下一小节中指定)。而且,两者都被认为是“完美的”(具有无限的容量),因为它们不受任何类型(参数化)模型的约束。
假设我们有一个真正的分布,例如一维高斯分布,并且我们想要一个从这个概率分布中采样的生成器。我们所谓的“直接”训练方法将包括迭代地调整生成器(梯度下降迭代)以校正真实分布和生成分布之间的测量差异/误差。最后,假设优化过程完美,我们应该最终得到与真实分布完全匹配的生成分布。

直接匹配方法的概念的例证。蓝色的分布是真实的,而生成的分布用橙色表示。通过迭代迭代,我们比较两个分布并通过梯度下降步骤调整网络权重。这里比较是在均值和方差上进行的(类似于截断矩匹配方法)。请注意(显然)这个例子非常简单,不需要迭代方法:目的只是为了说明上面给出的直觉。
对于“间接”方法,我们还必须考虑一个鉴别器。我们现在假设这个鉴别器是一种oracle,它确切知道什么是真实和生成的分布,并且能够根据这些信息预测任何给定点的类(“真”或“生成”)。如果这两个分布很明显,那么鉴别器将能够轻松地进行分类,并且可以高度自信地将我们呈现给它的大多数点分类。如果我们想欺骗鉴别器,我们必须使生成的分布接近真实的分布。当两个分布在所有点上相等时,鉴别器将最难预测类:在这种情况下,

针对对抗方法的直觉。蓝色分布是真实的,橙色是生成的。在灰色中,右边有相应的y轴,如果它选择每个点中密度较高的类(假设“真”和“生成”数据的比例相等),我们就会显示鉴别器的真实概率。两个分布越接近,鉴别器就越错误。训练时,目标是将“绿色区域”(生成的分布太高)移向红色区域(生成的分布太低)。
在这一点上,似乎有理由怀疑这种间接方法是否真的是一个好主意。实际上,它似乎更复杂(我们必须基于下游任务而不是直接基于分布来优化生成器)并且它需要我们在此认为是给定oracle的鉴别器,但实际上,它既不是已知的也不完美。对于第一点,直接比较基于样本的两个概率分布的难度抵消了间接方法的明显更高的复杂性。对于第二点,很明显,鉴别器是未知的。但是,它可以学到!
近似:对抗性神经网络
现在让我们描述采用GANs架构中的生成器和鉴别器的具体形式。生成器是一个模拟转换函数的神经网络。它将一个简单的随机变量作为输入,并且必须在训练后返回一个跟随目标分布的随机变量。由于它非常复杂和未知,我们决定用另一个神经网络对鉴别器进行建模。该神经网络模拟判别函数。它将一个点(在我们的狗示例中为N维向量)作为输入,并将该点的概率作为输出返回为“真”。
请注意,我们现在强加一个参数化模型来表达生成器和鉴别器(而不是前一小节中的理想化版本)的事实,实际上并没有对上面给出的理论论证/直觉产生巨大影响:我们只是然后,在一些参数化空间而不是理想的全空间中工作,因此,在理想情况下我们应达到的最佳点可以被视为由参数化模型的精确容量“舍入”。
一旦定义,两个网络就可以联合(同时)进行相反的目标训练:
- 生成器的目标是欺骗鉴别器,因此训练生成神经网络以最大化最终分类错误(真实数据和生成数据之间)
- 鉴别器的目标是检测伪造的数据,因此训练判别神经网络以最小化最终的分类错误
因此,在训练过程的每次迭代中,更新生成网络的权重以增加分类错误(错误梯度上升到生成器的参数),同时更新判别网络的权重以减少此错误(误差梯度下降超过鉴别器的参数)。

生成性对抗网络表示。生成器将简单随机变量作为输入并生成新数据。鉴别器采用“真实”和“生成”数据并尝试区分它们,构建分类器。生成器的目标是欺骗鉴别器(通过将尽可能多的生成数据与真实数据混合来增加分类错误),并且鉴别器的目标是区分真实数据和生成数据。
这些相反的目标和两个网络的对抗性训练的隐含概念解释了“对抗性网络”的名称:两个网络都试图相互击败,这样做,它们都变得越来越好。他们之间的竞争使这两个网络在各自的目标方面“进步”。从博弈论的角度来看,我们可以将此设置视为极小极大双玩家游戏,其中均衡状态对应于发生器从精确目标分布生成数据并且鉴别器预测“真实”或“生成”的情况“它接收的任何一点的概率为1/2。
关于GAN的数学细节
注意:本节更具技术性,对于全面了解GAN并非绝对必要。所以,现在不想读一些数学的读者可以暂时跳过这一部分。对于其他人,让我们看看上面给出的直觉是如何在数学上形式化的。
放弃:下面的等式不是Ian Goodfellow的文章。我们在这里提出另一个数学形式化有两个原因:第一,保持更接近上面给出的直觉,第二,因为原始论文的方程已经非常清楚,只是重写它们是没有用的。另请注意,我们绝对不会参与与不同可能的损失函数相关的实际考虑(消失梯度或其他)。我们强烈建议读者也要看看原始论文的方程式:主要区别在于Ian Goodfellow和共同作者使用交叉熵误差而不是绝对误差(正如我们所做的那样)。此外,在下文中我们假设具有无限容量的发生器和鉴别器。
神经网络建模本质上需要定义两件事:架构和损失函数。我们已经描述了Generative Adversarial Networks的架构。它包含两个网络:
- 生成网络G(。),其采用密度为p_z的随机输入z,并返回输出x_g = G(z),该输出应遵循(训练后)目标概率分布
- 一个判别网络D(。),它取一个可以是“真”的输入x(x_t,其密度用p_t表示)或“生成”的一个(x_g,其密度p_g是由密度p_z引起的密度通过G)并将x的概率D(x)返回为“真实”数据
现在让我们仔细看看GAN的“理论”损失函数。如果我们以相同的比例向鉴别器“真实”和“生成”数据发送,则鉴别器的预期绝对误差可以表示为

生成器的目标是欺骗鉴别器,其目标是能够区分真实数据和生成数据。因此,在训练生成器时,我们希望最大化此错误,同时我们尝试将其最小化以用于鉴别器。它给了我们

对于任何给定的发生器G(以及诱导概率密度p_g),最佳可能的鉴别器是最小化的鉴别器

为了最小化(相对于D)这个积分,我们可以最小化x的每个值的积分内的函数。然后,它为给定的发电机定义最佳可能的鉴别器
![]()
(事实上,最好的因为x值,使得p_t(x)= p_g(x)可以用另一种方式处理,但对于后面的内容并不重要)。然后我们搜索G最大化

同样,为了最大化(相对于G)这个积分,我们可以最大化x的每个值的积分内的函数。由于密度p_t独立于发电机G,我们不能比设置G更好
![]()
当然,由于p_g是应该与1整合的概率密度,我们必然拥有最佳的G
![]()
因此,我们已经证明,在具有无限容量发生器和鉴别器的理想情况下,对抗性设置的最佳点使得发生器产生与真密度相同的密度,并且鉴别器不能比真实的更好。一个案例中有两个,就像直觉告诉我们的那样。最后,还要注意G最大化
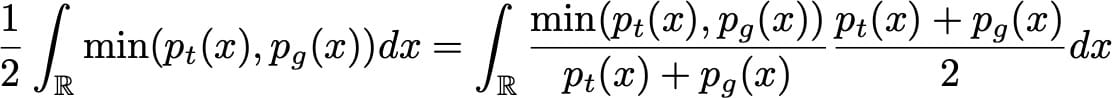
在这种形式下,我们最好看到G想要最大化鉴别器出错的预期概率。
本文的主要内容是:
- 计算机基本上可以生成简单的伪随机变量(例如,它们可以生成非常接近均匀分布的变量)
- 存在不同的方法来生成更复杂的随机变量,包括“变换方法”的概念,其包括将随机变量表示为一些更简单的随机变量的函数。
- 在机器学习中,生成模型试图从给定(复杂)概率分布生成数据
- 深度学习生成模型被建模为神经网络(非常复杂的函数),它将一个简单的随机变量作为输入,并返回一个跟随目标分布的随机变量(“变换方法”)
- 这些生成网络可以“直接”训练(通过比较生成数据与真实分布的分布):这就是生成匹配网络的思想
- 这些生成网络也可以“间接”训练(通过试图欺骗同时训练的另一个网络来区分“生成的”数据和“真实”数据):这就是生成对抗网络的想法
相关文章:
深度学习8:详解生成对抗网络原理
目录 大纲 生成随机变量 可以伪随机生成均匀随机变量 随机变量表示为操作或过程的结果 逆变换方法 生成模型 我们试图生成非常复杂的随机变量…… …所以让我们使用神经网络的变换方法作为函数! 生成匹配网络 培养生成模型 比较基于样本的两个概率分布 …...

sql入门-多表查询
案例涉及表 ----------------------------------建表语句之前翻看之前博客文章 多表查询 -- 学生表 create table studen ( id int primary key auto_increment comment id, name varchar(50) comment 姓名, no varchar(10) comment 学号 ) comment 学生表; insert…...

软考A计划-网络工程师-必考知识点-上
点击跳转专栏>Unity3D特效百例点击跳转专栏>案例项目实战源码点击跳转专栏>游戏脚本-辅助自动化点击跳转专栏>Android控件全解手册点击跳转专栏>Scratch编程案例点击跳转>软考全系列点击跳转>蓝桥系列 👉关于作者 专注于Android/Unity和各种游…...
seekToBeginning的用法)
kafka复习:(17)seekToBeginning的用法
从分区的开始进行消费,因为kafka会定期清理历史数据,所以分区开始的位移不一定为0。seekToBeginning只是从目前保留的数据中最小的offset进行消费 package com.cisdi.dsp.modules.metaAnalysis.rest.kafka2023;import org.apache.kafka.clients.consume…...
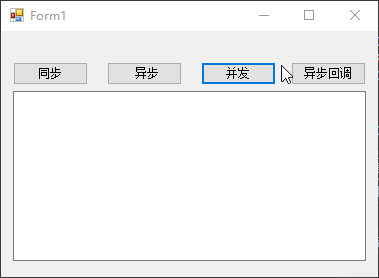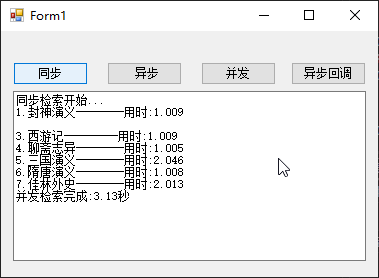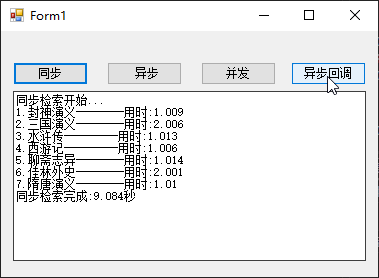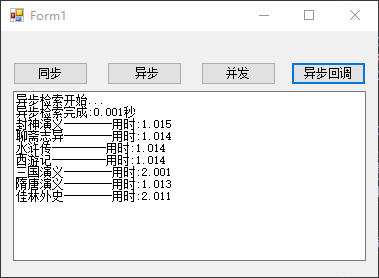
C# textBox1.Text=““与textBox1.Clear()的区别
一、区别 textbox.Text "" 和 textbox.Clear() 都可以用于清空文本框的内容,但它们之间有一些细微的区别。 textbox.Text "": 这种方式会将文本框的 Text 属性直接设置为空字符串。这样会立即清除文本框的内容,并将文本框显示为空…...

CnetSDK .NET OCR SDK Crack
CnetSDK .NET OCR SDK Crack CnetSDK.NET OCR库SDK是一款高度准确的.NET OCR扫描仪软件,用于使用手写、文本和其他符号等图像进行字符识别。它是一款.NET OCR库软件,使用Tesseract OCR引擎技术,可将字符识别准确率提高99%。通过将此.NET OCR扫…...

Python最新面试题汇总及答案
一、基础部分 1、什么是Python?为什么它会如此流行?Python是一种解释的、高级的、通用的编程语言。Python的设计理念是通过使用必要的空格与空行,增强代码的可读性。它之所以受欢迎,就是因为它具有简单易用的语法 2、为什么Pytho…...

设计模式(单例模式,工厂模式),线程池
目录 什么是设计模式? 单例模式 饿汉模式 懒汉模式 工厂模式 线程池 线程池种类 ThreadPoolExcutor的构造方法: 手动实现一个线程池 什么是设计模式? 计算机行业程序员水平层次不齐,为了让所有人都能够写出规范的代码,于是就有了设计模式,针对一些典型的场景,给出一…...

在mybatis中的mapper.xml中如何使用parameterType实现方法单个传参,对象传参,多参数传参.
在MyBatis的mapper.xml文件中,可以使用parameterType属性来指定方法的参数类型。parameterType属性用于指定传递给映射方法的参数类型,这将影响到MyBatis在映射方法执行时如何处理参数。 以下是三种不同情况下如何在mapper.xml中使用parameterType实现方…...

No120.精选前端面试题,享受每天的挑战和学习
文章目录 浏览器强制缓存和协商缓存cookie,localStorage、sessionStoragejs闭包,原型,原型链箭头函数和普通函数的区别promise的状态扭转 浏览器强制缓存和协商缓存 浏览器缓存是浏览器用于提高网页加载速度的一种机制。浏览器缓存分为强制缓…...

c# 访问sqlServer数据库时的连接字符串
//sql server 身份验证的场合, 连接字符串 private string ConnstrSqlServer "server服务器名称;uid登录名称;pwd登录密码;database数据库名称"; //windows 身份验证连接字符串 private string ConnstrWindows "server服务器名称;database数据库…...

排序算法概述
1.排序算法分类 **比较类算法排序:**通过比较来决定元素的时间复杂度的相对次序,由于其时间复杂度不能突破 O ( n l o g n ) O(nlogn) O(nlogn),因此也称为非线性时间比较类算法 **非比较类算法排序:**不通过比较来决定元素间的…...

ChatGPT在高等教育中的应用利弊探讨
人工智能在教育领域的应用日益广泛。2022年11月OpenAI开发的聊天机器人ChatGPT在全球范围内流传开来,其中用户数量最多的国家是美国(15.22%)。由于ChatGPT应用广泛,具有类似人类回答问题的能力,它正在成为许多学生和教育工作者的可信赖伙伴…...

Java之API详解之Runtime的详细解析
3.1 概述 Runtime表示Java中运行时对象,可以获取到程序运行时设计到的一些信息 3.2 常见方法 常见方法介绍 我们要学习的Object类中的常见方法如下所示: public static Runtime getRuntime() //当前系统的运行环境对象 public void exit(int statu…...

机器学习之softmax
Softmax是一个常用于多类别分类问题的激活函数和归一化方法。它将一个向量的原始分数(也称为 logits)转换为概率分布,使得每个类别的概率值在0到1之间,同时确保所有类别的概率之和等于1。Softmax函数的定义如下: 对于…...

npm script命令
1 串行/并行执行命令 //串行 npm-run-all text test npm run text && npm run test //并行改成& npm-run-all --parallel text test npm run text & npm run test2 传递参数 {"lint": "eslint js/*.js","lint:fix":…...

【力扣周赛】第360场周赛
【力扣周赛】第360场周赛 8015.距离原点最远的点题目描述解题思路 8022. 找出美丽数组的最小和题目描述解题思路 8015.距离原点最远的点 题目描述 描述:给你一个长度为 n 的字符串 moves ,该字符串仅由字符 ‘L’、‘R’ 和 ‘_’ 组成。字符串表示你在…...

php环境变量的配置步骤
要配置PHP的环境变量,以便在命令行中直接使用php命令,以下是一般的步骤: Windows 操作系统 下载和安装PHP:首先,你需要从PHP官方网站(https://www.php.net/downloads.php)下载适用于你的操作系…...

Kdtree
Kdtree kdtree 就是在 n 维空间对数据点进行二分;具体先确定一个根,然后小于在这个维度上的根的节点在左边,大于的在右边,再进行下一个维度的划分。直到维度结束,再重复,或者直到达到了结束条件࿱…...
算法leetcode|74. 搜索二维矩阵(rust重拳出击)
文章目录 74. 搜索二维矩阵:样例 1:样例 2:提示: 分析:题解:rust:go:c:python:java: 74. 搜索二维矩阵: 给你一个满足下述两条属性的…...

Live Server深度解析:如何用实时重载技术提升前端开发效率300%
Live Server深度解析:如何用实时重载技术提升前端开发效率300% 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-se…...

城通网盘直连解析终极解决方案:告别限速,实现全速下载的完整指南
城通网盘直连解析终极解决方案:告别限速,实现全速下载的完整指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘的龟速下载而烦恼吗?每次下载大文件都…...

可穿戴设备电池选型与电源管理实战指南
1. 项目概述:为什么可穿戴设备的电池选型是个技术活 做可穿戴电子项目,无论是智能手环、发光服饰还是互动饰品,最让人头疼的往往不是代码和电路,而是最后那一步: 怎么给它供电 。你可能花了好几天调通了传感器和灯带…...

如何在不同终端里面使用claude code并使用不同模型
在使用 Claude Code 开发项目时,我们可能会遇到这样的需求:一个终端使用速度更快、成本更低的模型处理日常代码修改,另一个终端使用推理能力更强的模型处理复杂问题。比如:一个终端用 deepseek-v4-pro[1m],另一个终端用…...

东南亚1.5亿数字钱包用户如何覆盖?Antom收单解决方案拆解
在东南亚,很多用户第一次完成线上付款可能不是通过信用卡,而是通过自己熟悉的本地电子钱包。从印尼的GoPay、DANA,到菲律宾的GCash,再到泰国的TrueMoney、马来西亚的Touch ‘n Go,电子钱包已经深度融入当地人的日常消费…...

别再硬啃英文文档了!手把手教你给Vue2项目里的DHTMLX Gantt甘特图做中文汉化
Vue2项目深度汉化DHTMLX Gantt甘特图实战指南 在项目管理工具中,甘特图因其直观的时间轴展示方式而备受青睐。DHTMLX Gantt作为一款功能强大的甘特图组件,却在中文环境下存在明显的本地化短板。本文将彻底解决这一问题,从界面文本到日期格式…...

Python视频自动化处理:基于FFmpeg与OpenCV的编程式剪辑框架实践
1. 项目概述与核心价值最近在折腾视频剪辑自动化流程,发现了一个挺有意思的开源项目AmitDigga/fabric-video-editor。这名字一看就带着点“缝合怪”的味道,fabric这个词在编程领域通常指代一个框架或结构,而video-editor则直指视频编辑。简单…...

用STM32F103和AD9833制作一个简易信号源:从电路搭建、驱动编写到波形测试全记录
用STM32F103和AD9833打造高精度信号发生器:硬件设计、固件开发与波形优化全解析 在电子工程和嵌入式开发领域,信号发生器是不可或缺的基础工具。无论是测试滤波器响应、校准传感器,还是验证通信协议,一个稳定可靠的信号源都能显著…...

深入RISC-V链接脚本:从.lds文件看C程序的内存‘出生’与‘搬家’全过程
深入RISC-V链接脚本:从.lds文件看C程序的内存‘出生’与‘搬家’全过程 在嵌入式开发的世界里,一个C程序从源代码到最终在硬件上运行,经历了编译、链接和加载三个关键阶段。这个过程就像一个人的生命历程:编译是"出生"&…...

解放双手!绝区零智能自动化工具让你的游戏体验翻倍升级
解放双手!绝区零智能自动化工具让你的游戏体验翻倍升级 【免费下载链接】ZenlessZoneZero-OneDragon 绝区零 一条龙 | 全自动 | 自动闪避 | 自动每日 | 自动空洞 | 支持手柄 项目地址: https://gitcode.com/gh_mirrors/ze/ZenlessZoneZero-OneDragon 还在为《…...