Python最新面试题汇总及答案
一、基础部分
1、什么是Python?为什么它会如此流行?Python是一种解释的、高级的、通用的编程语言。Python的设计理念是通过使用必要的空格与空行,增强代码的可读性。它之所以受欢迎,就是因为它具有简单易用的语法
2、为什么Python执行速度慢,我们如何改进它?Python代码执行缓慢的原因,是因为它是一种解释型语言。它的代码在运行时进行解释,而不是编译为本地语言。为了提高Python代码的速度,我们可以使用CPython、Numba,或者我们也可以对代码进行一些修改。1. 减少内存占用。2. 使用内置函数和库。3. 将计算移到循环外。4. 保持小的代码库。5. 避免不必要的循环3、Python有什么特点?1. 易于编码2. 免费和开源语言3. 高级语言4. 易于调试5. OOPS支持6. 大量的标准库和第三方模块7. 可扩展性(我们可以用C或C++编写Python代码)8. 用户友好的数据结构4、Python有哪些应用?1. Web开发2. 桌面GUI开发3. 人工智能和机器学习4. 软件开发5. 业务应用程序开发6. 基于控制台的应用程序7. 软件测试8. Web自动化9. 基于音频或视频的应用程序10. 图像处理应用程序5、Python的局限性?1. 速度2. 移动开发3. 内存消耗(与其他语言相比非常高)4. 两个版本的不兼容(2,3)5. 运行错误(需要更多测试,并且错误仅在运行时显示)6. 简单性
6、如何在Python中管理内存?Python内存由Python的私有headspace管理。所有的Python对象和数据结构都位于一个私有堆中。私用堆的分配由Python内存管理器负责。Python还内置了一个的垃圾收集器,可以回收未使用的内存并释放内存,使其可用于headspace。7、解释Python的内置数据结构?Python中主要有四种类型的数据结构列表:列表是从整数到字符串甚至另一个列表的异构数据项的集合。列表是可变的。列表完成了其他语言中大多数集合数据结构的工作。列表在[ ]方括号中定义。例如:a = [1,2,3,4]集合:集合是唯一元素的无序集合。集合运算如联合|,交集&和差异,可以应用于集合。{}用于表示一个集合。例如:a = {1,2,3,4}元组:Python元组的工作方式与Python列表完全相同,只是它们是不可变的。()用于定义元组。例如:a =(1,2,3,4)字典:字典是键值对的集合。它类似于其他语言中的hash map。在字典里,键是唯一且不可变的对象。例如:a = {'number':[1,2,3,4]}
8、Python中的单引号和双引号有什么区别?在Python中使用单引号(' ')或双引号(" ")是没有区别的,都可以用来表示一个字符串。这两种通用的表达方式,除了可以简化程序员的开发,避免出错之外,还有一种好处,就是可以减少转义字符的使用,使程序看起来更简洁,更清晰。
9、Python中append,insert和extend的区别?append:在列表末尾添加新元素。insert:在列表的特定位置添加元素。extend:通过添加新列表来扩展列表。
10、break、continue、pass是什么?break:在满足条件时,它将导致程序退出循环。continue:将返回到循环的开头,它使程序在当前循环迭代中的跳过所有剩余语句。pass:使程序传递所有剩余语句而不执行。
11、区分Python中的remove,del和pop?remove:将删除列表中的第一个匹配值,它以值作为参数。del:使用索引删除元素,它不返回任何值。pop:将删除列表中顶部的元素,并返回列表的顶部元素。12、==和is的区别是?==比较两个对象或值的相等性。is运算符用于检查两个对象是否属于同一内存对象。list1=[1,2,3,4]list2=[1,2,3,4]print(id(list1))print(id(list2))print(list1==list2)print("*"*50)print(list1 is list2)"""140105464266496140105464277120True**************************************************False"""
13、!=和is not运算符的区别?!=如果两个变量或对象的值不相等,则返回true。is not是用来检查两个对象是否属于同一内存对象。14、什么是lambda函数?Lambda函数是不带名称的单行函数,可以具有n个参数,但只能有一个表达式。也称为匿名函数。eg: a=lambda x,y:x+yprint(a(5,6))>1115、 Python中的Map Function是什么?map函数在对可迭代对象的每一项应用特定函数后,会返回map对象。16、如何使用索引来反转Python中的字符串?str="hello"print(str[::-1])17、类和对象有什么区别?类(Class)被视为对象的蓝图。类中的第一行字符串称为doc字符串,包含该类的简短描述。在Python中,使用class关键字可以创建了一个类。一个类包含变量和成员组合,称为类成员。对象(Object)是真实存在的实体。在Python中为类创建一个对象,我们可以使用obj = CLASS_NAME()例如:obj = num()使用类的对象,我们可以访问类的所有成员,并对其进行操作。
18、你对Python类中的self有什么了解?self表示类的实例。通过使用self关键字,我们可以在Python中访问类的属性和方法。注意,在类的函数当中,必须使用self,因为类中没有用于声明变量的显式语法。19、Python中OOPS是什么?面向对象编程,抽象(Abstraction)、封装(Encapsulation)、继承(Inheritance)、多态(Polymorphism)抽象(Abstraction):将一个对象的本质或必要特征向外界展示,并隐藏所有其他无关信息的过程。封装(Encapsulation)意味着将数据和成员函数包装在一起成为一个单元。它还实现了数据隐藏的概念。多态(Polymorphism):子类可以定义自己的独特行为,并且仍然共享其父类/基类的相同功能或行为。
20、Python支持多重继承吗?Python可以支持多重继承。多重继承意味着,一个类可以从多个父类派生。
21、Python中使用的zip函数是什么?zip函数获取可迭代对象,将它们聚合到一个元组中,然后返回结果。zip()函数的语法是zip(*iterables)numbers = [1, 2, 3]string = ['one', 'two', 'three'] result = zip(numbers,string)print(set(result))-------------------------------------{(3, 'three'), (2, 'two'), (1, 'one')}
**22、Python中的装饰器是什么?**面试几乎必问之一,要求能手写装饰器装饰器(Decorator)是Python中一个有趣的功能。它用于向现有代码添加功能。这也称为元编程,因为程序的一部分在编译时会尝试修改程序的另一部分。def addition(func):def inner(a,b):print("numbers are",a,"and",b)return func(a,b)return inner@additiondef add(a,b):print(a+b)add(5,6)---------------------------------numbers are 5 and 6sum: 11
23、用一行Python代码,从给定列表中取出所有的偶数和奇数?a = [1,2,3,4,5,6,7,8,9,10]odd, even = [el for el in a if el % 2==1], [el for el in a if el % 2==0]print(odd,even)> ([1, 3, 5, 7, 9], [2, 4, 6, 8, 10])24、谈下python的GIL?GIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大25、、简述面向对象中__new__和__init__区别?__init__是初始化方法,创建对象后,就立刻被默认调用了,可接收参数1、__new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别2、__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类(通过super(当前类名, cls))__new__出来的实例,或者直接是object的__new__出来的实例3、__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值4、如果__new__创建的是当前类的实例,会自动调用__init__函数,通过return语句里面调用的__new__函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的__init__函数,也不会调用其他类的__init__函数。26、字典根据键从小到大排序dic={"name":"zs","age":18,"city":"深圳","tel":"1362626627"}print(dict(sorted(dic.items(),key=lambda x:x[0],reverse=False)))
27、[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]列表推导式:print([j for i in li for j in i])numpy方法import numpy as npprint(np.array(li).flatten().tolist())
28、遇到bug如何处理?1、细节上的错误,通过print()打印,能执行到print()说明一般上面的代码没有问题,分段检测程序是否有问题,如果是js的话可以alert或console.log2、如果涉及一些第三方框架,会去查官方文档或者一些技术博客。3、对于bug的管理与归类总结,一般测试将测试出的bug用teambin等bug管理工具进行记录,然后我们会一条一条进行修改,修改的过程也是理解业务逻辑和提高自己编程逻辑缜密性的方法,我也都会收藏做一些笔记记录。4、导包问题、城市定位多音字造成的显示错误问题
**29、写一个单例模式**因为创建对象时__new__方法执行,并且必须return 返回实例化出来的对象所cls.__instance是否存在,不存在的话就创建对象,存在的话就返回该对象,来保证只有一个实例对象存在(单列),打印ID,值一样,说明对象同一个class Singleton(object):__instance=Nonedef __new__(cls, *args, **kwargs):if cls.__instance is None:cls.__instance =object.__new__(cls)return cls.__instancea=Singleton(18,'A')b=Singleton(22,'B')print(id(a))print(id(b))
30 python 内存泄漏Python 有自动垃圾回收但还是会有内存泄漏的情况,现在总结一下三种常见的内存泄漏场景。1、无穷大导致内存泄漏如果把内存泄漏定义成只申请不释放,那么借着 Python 中整数可以无穷大的这个特点,我们一行代码就可以完成内存泄漏了。i = 1024 ** 1024 ** 10242、循环引用导致内存泄漏引用记数器 是 Python 垃圾回收机制的基础,如果一个对象的引用数量不为 0 那么是不会被垃圾回收的,我们可以通过 sys.getrefcount 来得到给定对象的引用数量。3、外面库导致内存泄漏这种情况我也只遇到过一次,之前 mysql-connector-python 的内存泄漏,导致我的程序跑着跑着占用的内存就越来越大;最后我们返的 C 语言扩展禁用之后就没有问题了。
31、内存泄漏和内存溢出的区别内存溢出是指向JVM申请内存空间时没有足够的可用内存了,就会抛出OOM即内存溢出。内存泄漏是指,向JVM申请了一块内存空间,使用完后没有释放,由于没有释放,这块内存区域其他类加载的时候无法申请,同时当前类又没有这块内存空间的内存地址了也无法使用,相当于丢了一块内存,这就是内存泄漏。值得注意的是内存泄漏最终会导致内存溢出,很好理解,内存丢了很多最后当然内存不够用了。
32、Python 字典实现 对象.属性 调用class dict(dict):def __new__(cls, *args, **kwargs):return super().__new__(cls)def __getattr__(self, name):if name.startswith('__'):raise AttributeErrorreturn self.get(name)def __setattr__(self, name, val):self[name] = valdef __hash__(self):return id(self)**33、多线程、多进程和协程的区别与联系**多线程:线程是进程的一个实体,是CPU进行调度的最小单位,他是比进程更小能独立运行的基本单位。线程基本不拥有系统资源,只占用一点运行中的资源(如程序计数器,一组寄存器和栈),但是它可以与同属于一个进程的其他线程共享全部的资源。提高程序的运行速率,上下文切换快,开销比较少,但是不够稳定,容易丢失数据,形成死锁。多进程:进程是系统进行资源分配的最小单位,每个进程都有自己的独立内存空间,不用进程通过进程间通信来通信。但是进程占据独立空间,比较重量级,所以上下文进程间的切换开销比较大,但是比较稳定安全。协程:协程:是更小的执行单位,是一种轻量级的线程,协程的切换只是单纯的操作CPU的上下文,所以切换速度特别快,且耗能小。gevent是第三方库,通过greenlet实现协程,其基本思想是:当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
**34、元组是不可变的,元组中存一个列表,列表中元素是否可以改变?可以**
35、浅拷贝与深拷贝的区别?浅拷贝:创建新对象,其内容是原对象的引用,只拷贝一层。深拷贝:和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。深拷贝出来的对象是一个全新的对象,不再与原来的对象有任何关联。
36、什么是RESTful?REST:指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是RESTful。37、如何设计 restful API ?1、协议:API与用户的通信协议,总是使用HTTPs协议。2、域名:应该尽量将API部署在专用域名之下3、版本:应该将API的版本号放入URL。4、路径:路径又称"终点"(endpoint),表示API的具体网址。在RESTful架构中,每个网址代表一种资源(resource),所以网址中不能有动词,只能有名词,而且所用的名词往往与数据库的表格名对应。一般来说,数据库中的表都是同种记录的"集合"(collection),所以API中的名词也应该使用复数。5、http 动词:常用的HTTP动词有下面五个GET(SELECT):从服务器取出资源(一项或多项)。POST(CREATE):在服务器新建一个资源。PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。DELETE(DELETE):从服务器删除资源。6、过滤信息:如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。7、状态码:服务器向用户返回的状态码和提示信息8、错误处理:如果状态码是4xx,就应该向用户返回出错信息9、返回结果:针对不同操作,服务器向用户返回的结果应该符合以下规范。GET /collection:返回资源对象的列表(数组)GET /collection/resource:返回单个资源对象POST /collection:返回新生成的资源对象PUT /collection/resource:返回完整的资源对象PATCH /collection/resource:返回完整的资源对象DELETE /collection/resource:返回一个空文档10、Hypermedia API:RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。11、其他:服务器返回的数据格式,应该尽量使用JSON,避免使用XML38、python 中字典的底层实现原理?在Python中,字典是通过散列表(哈希表)实现的。字典也叫哈希数组或关联数组,,所以其本质是数组。
39、如何解决哈希碰撞或者哈希冲突?1、开放寻址法2、再哈希法3、链地址法4、公共溢出区5、装填因子
40、python 装饰器函数装饰器与类装饰器函数装饰器:函数能作为参数传递给其他函数,可以被赋值给其他变量,可以作为返回值,可以被定义在另外一个函数内;类装饰器:类具有__call__方法,当使用 @ 形式将装饰器附加到函数上时,就会调用此方法; 应用场景: 插入日志、性能测试、事务处理、缓存、权限校验等
41 token和jwt-token存在什么区别?
相同: 都是访问资源的令牌, 都可以记录用户信息,都是只有验证成功后
不同点:服务端验证客户端发来的token信息要进行数据的查询操作;JWT验证客户端发来的token信息就不用, 在服务端使用密钥校验就可以,不用数据库的查询。
42、浏览器请求相应全过程详解
- 在浏览器中输入URL 或者IP 或者域名
- 如果输入的是域名就需要进行DNS解析成IP地址,通过IP来确认是哪个服务器
- 建立TCP 请求(即三次握手)
- 发送http请求
- 服务器处理请求,并将处理结果返回给浏览器
- 最后断开连接(即四次挥手)
- 浏览器根据返回结果进行处理以及页面渲染
43、为什么是三次握手 而不是两次呢?
防止出现请求超时脏链接
44、python 常见的魔法方法__init____new____call____str____repr__
45、python slots 在类中的作用?主要用于避免动态创建属性,它用于节省对象中的内存空间。静态结构不允许在任何时候动态创建对象,而是在初始创建之后不允许这样做。 如果要实例化(数百个,数千个)同一类的对象,则 需要使用 `__slots__` 。`__slots__` 仅作为内存优化工具存在。**警告:**不幸的是插槽有副作用。 不要过早优化并在各处使用它! 它对代码维护不是很好,它实际上只有在拥有数千个实例时才能为您节省二、数据库部分
## mysql 相关1、数据库优化查询方法外键、索引、联合查询、选择特定字段等等
2、简述mysql和redis区别redis: 内存型非关系数据库,数据保存在内存中,速度快mysql:关系型数据库,数据保存在磁盘中,检索的话,会有一定的Io操作,访问速度相对慢
3、列出常见MYSQL数据存储引擎InnoDB:支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。MyISAM:插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比 较低,也可以使用。MEMORY:所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择MEMOEY。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。
4、日常工作中你是怎么优化SQL的?加索引--避免返回不必要的数据--适当分批量进行--优化sql结构--分库分表--读写分离
5、说说分库与分表的设计水平分库:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中水平分表:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。垂直分表:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
6、事务的隔离级别有哪些?MySQL的默认隔离级别是什么?读未提交(Read Uncommitted)读已提交(Read Committed)可重复读(Repeatable Read)串行化(Serializable)Mysql默认的事务隔离级别是可重复读(Repeatable Read),其他数据库一般默认为读已提交。(我们可以把mysql的默认隔离级别修改为读已提交,这句话面试官不问不要说,不要给自己挖坑)
7、什么是幻读,脏读,不可重复读呢?事务A、B交替执行,事务A被事务B干扰到了,因为事务A读取到事务B未提交的数据,这就是脏读在一个事务范围内,两个相同的查询,读取同一条记录,却返回了不同的数据,这就是不可重复读。事务A查询一个范围的结果集,另一个并发事务B往这个范围中插入/删除了数据,并静悄悄地提交,然后事务A再次查询相同的范围,两次读取得到的结果集不一样了,这就是幻读。
**8、说一下数据库的三大范式**第一范式:数据表中的每一列(每个字段)都不可以再拆分第二范式:在第一范式的基础上,分主键列完全依赖于主键,而不能是依赖于主键的一部分第三范式:在满足第二范式的基础上,表中的非主键只依赖于主键,而不依赖于其他非主键
**9、索引有哪几种类型?**主键索引: 数据列不允许重复,不允许为NULL,一个表只能有一个主键。唯一索引: 数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。普通索引: 基本的索引类型,没有唯一性的限制,允许为NULL值。全文索引:是目前搜索引擎使用的一种关键技术,对文本的内容进行分词、搜索覆盖索引:查询列要被所建的索引覆盖,不必读取数据行组合索引:多列值组成一个索引,用于组合搜索,效率大于索引合并
10、创建索引有什么原则呢?最左前缀匹配原则频繁作为查询条件的字段才去创建索引频繁更新的字段不适合创建索引索引列不能参与计算,不能有函数操作优先考虑扩展索引,而不是新建索引,避免不必要的索引在order by或者group by子句中,创建索引需要注意顺序区分度低的数据列不适合做索引列(如性别)定义有外键的数据列一定要建立索引。对于定义为text、image数据类型的列不要建立索引。删除不再使用或者很少使用的索引
11、什么是数据库事务?数据库事务(简称:事务),是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。
12、mysql 事务的特性,ACID原子性、一致性、隔离性、持久性
13、B树和B+树的区别?1、B-树是一类树,包括B-树、B+树、B*树等,是一棵自平衡的搜索树,它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。
B-树是专门为外部存储器设计的,如磁盘,它对于读取和写入大块数据有良好的性能,所以一般被用在文件系统及数据库中。2、B+树是B-树的变体,也是一种多路搜索树, 它与 B- 树的不同之处在于:所有关键字存储在叶子节点出现,内部节点(非叶子节点并不存储真正的 data)为所有叶子结点增加了一个链指针因为内节点并不存储 data,所以一般B+树的叶节点和内节点大小不同,而B-树的每个节点大小一般是相同的,为一页
14、mysql 行锁MySQL的行锁又分为共享锁(S锁)和排他锁(X锁)。一般普通的select语句,InnoDB不加任何锁,我们称之为快照读select * from test;通过加S锁和X锁的select语句或者插入/更新/删除操作,我们称之为当前读select * from test lock in share mode;select * from test for update;insert into test values(…);update test set …;delete from test …;以上的当前读,读取的都是记录的最新版本。对读取记录都会加锁,除了第一条语句lock in share mode是对记录加S锁(共享锁)外,其他的操作都是加X锁(排他锁)。
15、什么是死锁?怎么解决?
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象
常见的解决死锁的方法如果不同程序会并发存取多个表, 尽量约定以相同的顺序访问表,可以大大降低死锁机会。
在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;16、什么是脏读?幻读?不可重复读?
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据, 由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致, 这可能是两次查询过程中间插入了一个事务更新的原有的数据。幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致, 例如有一个事务查询了几列(Row)数据, 而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中, 就会发现有几列数据是它先前所没有的。17、索引有哪些使用场景
1)、应该创建索引的场景主键应该创建主键索引。
频繁作为查询条件的字段应该创建索引。
查询中需要与其他表进行关联的字段应该创建索引。
需要排序的字段应该创建索引。
需要统计或分组的字段应该创建索引。
优先考虑创建复合索引。
2)、不应创建索引的场景
数据记录较少的表。
经常需要增删改操作的字段。
数据记录重复较多且分布平均的字段(如性别、状态等)。## redis 相关
1、redis 是单线程还是多线程?
大家所熟知的 Redis 确实是单线程模型,指的是执行 Redis 命令的核心模块是单线程的,而不是整个 Redis 实例就一个线程,Redis 其他模块还有各自模块的线程的
2、Redis 不仅仅是单线程
一般来说 Redis 的瓶颈并不在 CPU,而在内存和网络。如果要使用 CPU 多核,可以搭建多个 Redis 实例来解决。
其实,Redis 4.0 开始就有多线程的概念了,比如 Redis 通过多线程方式在后台删除对象、以及通过 Redis 模块实现的阻塞命令等。
3、Redis系列 | 缓存穿透、击穿、雪崩、预热、更新、降级
缓存穿透
当查询Redis中没有的数据时,该查询会下沉到数据库层,同时数据库层也没有该数据,当这种情况大量出现或被恶意攻击时,接口的访问全部透过Redis访问数据库,而数据库中也没有这些数据,我们称这种现象为"缓存穿透"。
解决方案:
在接口访问层对用户做校验,如接口传参、登陆状态、n秒内访问接口的次数;
利用布隆过滤器,将数据库层有的数据key存储在位数组中,以判断访问的key在底层数据库中是否存在;
缓存击穿
缓存击穿和缓存穿透从名词上可能很难区分开来,它们的区别是:穿透表示底层数据库没有数据且缓存内也没有数据,击穿表示底层数据库有数据而缓存内没有数据。当热点数据key从缓存内失效时,大量访问同时请求这个数据,就会将查询下沉到数据库层,此时数据库层的负载压力会骤增,我们称这种现象为"缓存击穿"。
解决方案:
延长热点key的过期时间或者设置永不过期,如排行榜,首页等一定会有高并发的接口;
利用互斥锁保证同一时刻只有一个客户端可以查询底层数据库的这个数据,一旦查到数据就缓存至Redis内,避免其他大量请求同时穿过Redis访问底层数据库;
缓存雪崩
缓存雪崩是缓存击穿的"大面积"版,缓存击穿是数据库缓存到Redis内的热点数据失效导致大量并发查询穿过redis直接击打到底层数据库,而缓存雪崩是指Redis中大量的key几乎同时过期,然后大量并发查询穿过redis击打到底层数据库上,此时数据库层的负载压力会骤增,我们称这种现象为"缓存雪崩"。
解决方案:
在可接受的时间范围内随机设置key的过期时间,分散key的过期时间,以防止大量的key在同一时刻过期;
对于一定要在固定时间让key失效的场景(例如每日12点准时更新所有最新排名),可以在固定的失效时间时在接口服务端设置随机延时,将请求的时间打散,让一部分查询先将数据缓存起来;
延长热点key的过期时间或者设置永不过期,这一点和缓存击穿中的方案一样;
缓存预热
缓存预热如字面意思,当系统上线时,缓存内还没有数据,如果直接提供给用户使用,每个请求都会穿过缓存去访问底层数据库,如果并发大的话,很有可能在上线当天就会宕机,因此我们需要在上线前先将数据库内的热点数据缓存至Redis内再提供出去使用,这种操作就成为"缓存预热"。
缓存预热的实现方式有很多,比较通用的方式是写个批任务,在启动项目时或定时去触发将底层数据库内的热点数据加载到缓存内。
缓存更新
缓存服务(Redis)和数据服务(底层数据库)是相互独立且异构的系统,在更新缓存或更新数据的时候无法做到原子性的同时更新两边的数据,因此在并发读写或第二步操作异常时会遇到各种数据不一致的问题。
缓存更新的设计模式有四种:
Cache aside:查询:先查缓存,缓存没有就查数据库,然后加载至缓存内;更新:先更新数据库,然后让缓存失效;或者先失效缓存然后更新数据库;
Read through:在查询操作中更新缓存,即当缓存失效时,Cache Aside 模式是由调用方负责把数据加载入缓存,而 Read Through 则用缓存服务自己来加载;
Write through:在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后由缓存自己更新数据库;
Write behind caching:俗称write back,在更新数据的时候,只更新缓存,不更新数据库,缓存会异步地定时批量更新数据库;
缓存降级
缓存降级是指当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,即使是有损部分其他服务,仍然需要保证主服务可用。可以将其他次要服务的数据进行缓存降级,从而提升主服务的稳定性。Redis 能够处理速度快的原因主要有以下几个方面:1、内存数据库:Redis是一种内存数据库,数据存储在内存中,因此读写速度非常快。2、单线程:Redis是单线程的,避免了多线程带来的上下文切换和锁竞争的开销,因此可以更高效地利用CPU资源。3、非阻塞式IO:Redis使用了非阻塞式IO,当执行一个IO操作时,它不会被阻塞,而是会立即返回,这样就可以执行其他操作,提高了Redis的响应速度。4、基于事件驱动:Redis采用了基于事件驱动的模型,通过监听socket事件,当事件发生时,执行相应的操作,避免了轮询的开销,提高了Redis的性能。5、轻量级:Redis的代码量相对较小,且没有复杂的依赖关系,因此它的启动速度非常快,这也是它处理速度快的重要原因之一。综上所述,Redis之所以能够处理速度快,是因为它采用了多种优化策略和技术,从而实现了高效的数据存储和快速的读写操作。三、数据结构与算法
1、基本的算法有哪些,怎么评价一个算法的好坏?基本的算法有: 排序算法(简单排序, 快速排序, 归并排序), 搜索(二分搜索), 对于其他基本数 据结构, 栈, 队列,树,都有一些基本的操作。评价算法的好坏一般有两种: 时间复杂度和空间复杂度。时间复杂度:同样的输入规模(问题规模)花费多少时间。空间复杂度:同样的输入规模花费多少空间(主要是内存)。以上两点越小越好。稳定性:不会引文输入的不同而导致不稳定的情况发生。算法的思路是否简单:越简单越容易实现的越好。
2、斐波那契数列斐波那契数列:简单地说,起始两项为 0 和 1,此后的项分别为它的前两项之和。def fibo(num):numList = [0, 1]for i in range(num - 2):numList.append(numList[-2] + numList[-1])return numList四、web框架
1、Django 的生命周期?
- 前端发起请求
- nginx
- uwsgi
- 中间件
- URL
- view视图
- 通过orm与model层进行数据交互
- 拿到数据返回给view
- 试图将数据渲染到模板中拿到字符串
- 中间件
- uwsgi
- nginx
- 前端渲染
2、中间件的五种方法?
- process_request
- process_response
- Process_view
- Process_exception
- Process_render_template
3、django 自带的中间件?
- SecurityMiddleware
- SessionMiddleware
- CommmonMiddleware
- CsrfViewMiddleware
- AuthenticationMiddleware
- MessageMiddleware
- XFrameOptionMiddleware
4、csrf 攻击、危害与防御
csrf 攻击全称为Cross-site request forgery 中文名称 跨站请求伪造 也被称为“One Click Attack”或者“Session Riding”,通常缩写为CSRF或者XSRF,是一种对网站的恶意利用。
XSS主要是利用站点内的信任用户,而CSRF则通过伪装来自受信任用户的请求,来利用受信任的网站。与XSS相比,CSRF更具危险性。
主要的危害来自于攻击者盗用用户身份,发送恶意请求。比如:模拟用户发送邮件,发消息,以及支付、转账等。
如何防御CSRF攻击?
1、重要数据交互采用POST进行接收,当然POST也不是万能的,伪造一个form表单即可破解。
2、使用验证码,只要是涉及到数据交互就先进行验证码验证,这个方法可以完全解决CSRF。
3、出于用户体验考虑,网站不能给所有的操作都加上验证码,因此验证码只能作为一种辅助手段,不能作为主要解决方案。
4、验证HTTP Referer字段,该字段记录了此次HTTP请求的来源地址,最常见的应用是图片防盗链。
5、为每个表单添加令牌token并验证。
相关文章:

Python最新面试题汇总及答案
一、基础部分 1、什么是Python?为什么它会如此流行?Python是一种解释的、高级的、通用的编程语言。Python的设计理念是通过使用必要的空格与空行,增强代码的可读性。它之所以受欢迎,就是因为它具有简单易用的语法 2、为什么Pytho…...

设计模式(单例模式,工厂模式),线程池
目录 什么是设计模式? 单例模式 饿汉模式 懒汉模式 工厂模式 线程池 线程池种类 ThreadPoolExcutor的构造方法: 手动实现一个线程池 什么是设计模式? 计算机行业程序员水平层次不齐,为了让所有人都能够写出规范的代码,于是就有了设计模式,针对一些典型的场景,给出一…...

在mybatis中的mapper.xml中如何使用parameterType实现方法单个传参,对象传参,多参数传参.
在MyBatis的mapper.xml文件中,可以使用parameterType属性来指定方法的参数类型。parameterType属性用于指定传递给映射方法的参数类型,这将影响到MyBatis在映射方法执行时如何处理参数。 以下是三种不同情况下如何在mapper.xml中使用parameterType实现方…...

No120.精选前端面试题,享受每天的挑战和学习
文章目录 浏览器强制缓存和协商缓存cookie,localStorage、sessionStoragejs闭包,原型,原型链箭头函数和普通函数的区别promise的状态扭转 浏览器强制缓存和协商缓存 浏览器缓存是浏览器用于提高网页加载速度的一种机制。浏览器缓存分为强制缓…...

c# 访问sqlServer数据库时的连接字符串
//sql server 身份验证的场合, 连接字符串 private string ConnstrSqlServer "server服务器名称;uid登录名称;pwd登录密码;database数据库名称"; //windows 身份验证连接字符串 private string ConnstrWindows "server服务器名称;database数据库…...

排序算法概述
1.排序算法分类 **比较类算法排序:**通过比较来决定元素的时间复杂度的相对次序,由于其时间复杂度不能突破 O ( n l o g n ) O(nlogn) O(nlogn),因此也称为非线性时间比较类算法 **非比较类算法排序:**不通过比较来决定元素间的…...

ChatGPT在高等教育中的应用利弊探讨
人工智能在教育领域的应用日益广泛。2022年11月OpenAI开发的聊天机器人ChatGPT在全球范围内流传开来,其中用户数量最多的国家是美国(15.22%)。由于ChatGPT应用广泛,具有类似人类回答问题的能力,它正在成为许多学生和教育工作者的可信赖伙伴…...

Java之API详解之Runtime的详细解析
3.1 概述 Runtime表示Java中运行时对象,可以获取到程序运行时设计到的一些信息 3.2 常见方法 常见方法介绍 我们要学习的Object类中的常见方法如下所示: public static Runtime getRuntime() //当前系统的运行环境对象 public void exit(int statu…...

机器学习之softmax
Softmax是一个常用于多类别分类问题的激活函数和归一化方法。它将一个向量的原始分数(也称为 logits)转换为概率分布,使得每个类别的概率值在0到1之间,同时确保所有类别的概率之和等于1。Softmax函数的定义如下: 对于…...

npm script命令
1 串行/并行执行命令 //串行 npm-run-all text test npm run text && npm run test //并行改成& npm-run-all --parallel text test npm run text & npm run test2 传递参数 {"lint": "eslint js/*.js","lint:fix":…...

【力扣周赛】第360场周赛
【力扣周赛】第360场周赛 8015.距离原点最远的点题目描述解题思路 8022. 找出美丽数组的最小和题目描述解题思路 8015.距离原点最远的点 题目描述 描述:给你一个长度为 n 的字符串 moves ,该字符串仅由字符 ‘L’、‘R’ 和 ‘_’ 组成。字符串表示你在…...

php环境变量的配置步骤
要配置PHP的环境变量,以便在命令行中直接使用php命令,以下是一般的步骤: Windows 操作系统 下载和安装PHP:首先,你需要从PHP官方网站(https://www.php.net/downloads.php)下载适用于你的操作系…...

Kdtree
Kdtree kdtree 就是在 n 维空间对数据点进行二分;具体先确定一个根,然后小于在这个维度上的根的节点在左边,大于的在右边,再进行下一个维度的划分。直到维度结束,再重复,或者直到达到了结束条件࿱…...
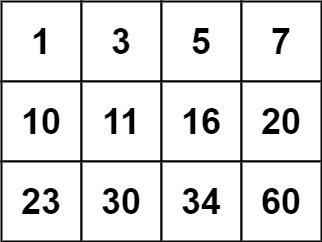
算法leetcode|74. 搜索二维矩阵(rust重拳出击)
文章目录 74. 搜索二维矩阵:样例 1:样例 2:提示: 分析:题解:rust:go:c:python:java: 74. 搜索二维矩阵: 给你一个满足下述两条属性的…...

element浅尝辄止7:InfiniteScroll 无限滚动
滚动加载:滚动至底部时,加载更多数据。 1.如何使用? //在要实现滚动加载的列表上上添加v-infinite-scroll,并赋值相应的加载方法, //可实现滚动到底部时自动执行加载方法。<template><ul class"infinit…...

Day05-Vue基础
Day05-Vue基础 一、单向数据流 父子组件通信。会在父组件中定义好数据,将数据传递给子组件,可以使用这个数据 Vue中针对props这个属性提出了一个单向数据流的概念。 Vue针对props做了一些限制,可以接受值,使用这个值,规范中不要去直接修改这个值 目的是为了对数据流进…...
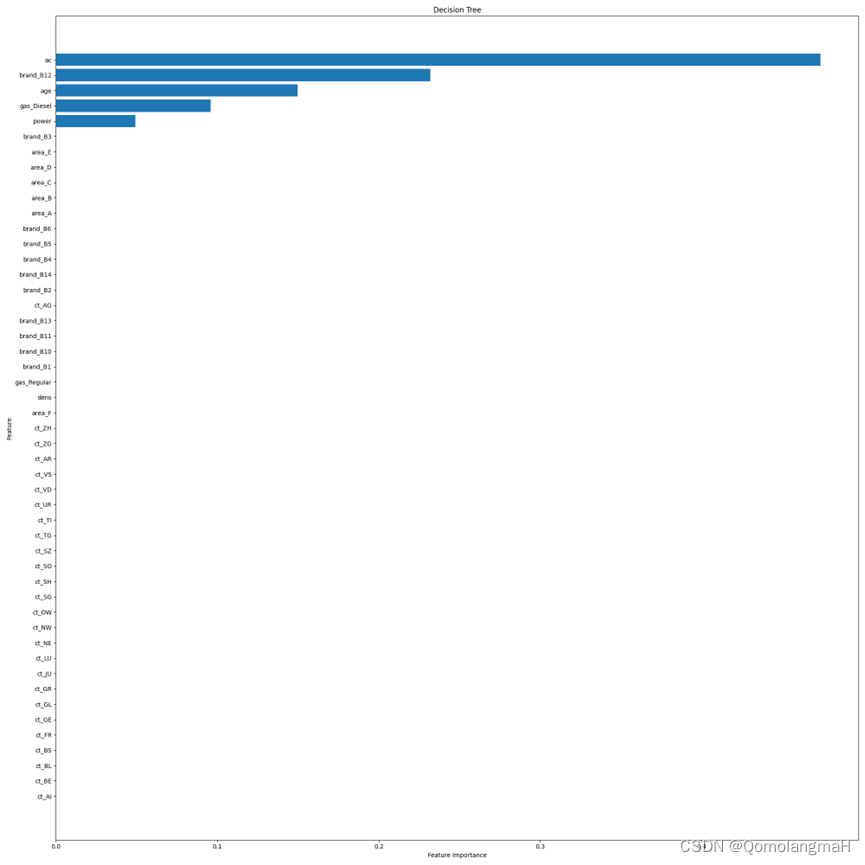
《机器学习在车险定价中的应用》实验报告
目录 一、实验题目 机器学习在车险定价中的应用 二、实验设置 1. 操作系统: 2. IDE: 3. python: 4. 库: 三、实验内容 实验前的猜想: 四、实验结果 1. 数据预处理及数据划分 独热编码处理结果(以…...
14. Docker中实现CI和CD
目录 1、前言 2、什么是CI/CD 3、部署Jenkins 3.1、下载Jenkins 3.2、启动Jenkins 3.3、访问Jenkins页面 4、Jenkins部署一个应用 5、Jenkins实现Docker应用的持续集成和部署 5.1、创建Dockerfile 5.2、集成Jenkins和Docker 6、小结 1、前言 持续集成(CI/CD)是一种…...

【多思路解决喝汽水问题】1瓶汽水1元,2个空瓶可以换一瓶汽水,给20元,可以喝多少汽水
题目内容 喝汽水问题 喝汽水,1瓶汽水1元,2个空瓶可以换一瓶汽水,给20元,可以喝多少汽水(编程实现)。 题目分析 数学思路分析 根据给出的问题和引用内容,我们可以得出答案。 首先ÿ…...
)
P1591 阶乘数码(Java高精度)
题目描述 求 n ! n! n! 中某个数码出现的次数。 输入格式 第一行为 t ( t ≤ 10 ) t(t \leq 10) t(t≤10),表示数据组数。接下来 t t t 行,每行一个正整数 n ( n ≤ 1000 ) n(n \leq 1000) n(n≤1000) 和数码 a a a。 输出格式 对于每组数据&a…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...
Xcode 16 集成 cocoapods 报错
基于 Xcode 16 新建工程项目,集成 cocoapods 执行 pod init 报错 ### Error RuntimeError - PBXGroup attempted to initialize an object with unknown ISA PBXFileSystemSynchronizedRootGroup from attributes: {"isa">"PBXFileSystemSynchro…...