python监控ES索引数量变化
文章目录
- 1, datafram根据相同的key聚合
- 2, 数据合并:获取采集10,20,30分钟es索引数据
- 脚本测试验证
1, datafram根据相同的key聚合
# 创建df1 ==> json {'key':'A', 'value':1 } {'key':'B', 'value':2 }
data1 = {'key': ['A', 'B'],
'value': [1, 2]}
df1 = pd.DataFrame(data1)# 创建df2 ==> {'key':'A', 'value':11 } {'key':'B', 'value':22 }
data2 = {'key': ['A', 'B'],
'value': [11, 22]}
df2 = pd.DataFrame(data2)# 创建df3 ==>{'key':'A', 'value':111 } {'key':'B', 'value':222 } {'key':'C', 'value':333 }
data3 = {'key': ['A', 'B', 'c'],
'value': [111, 222, 333]}
df3 = pd.DataFrame(data3)#### 聚合两个dataframe
#==> {'key':'A', 'value_x':1, 'value_y':11 } {'key':'B', 'value_x':2, 'value_y':22 }
>>> mdf1=pd.merge(df1, df2, on='key')
>>> mdf1key value_x value_y
0 A 1 11
1 B 2 22
#### 再聚合两个dataframe
#==> {'key':'A', 'value_x':1, 'value_y':11 , 'value':111 } {'key':'B', 'value_x':2, 'value_y':22 , 'value':222 }
mdf = pd.merge(pd.merge(df1, df2, on='key'), df3, on='key')
>>> mdf2=pd.merge(mdf1, df3, on='key')
>>> mdf2key value_x value_y value
0 A 1 11 111
1 B 2 22 222
2, 数据合并:获取采集10,20,30分钟es索引数据
[root@localhost ] # cat es-indices-monitor.py
import json
import time
import requests
import os
import sys
import glob
import pandas as pddef deloldfile(workdir):# 获取目录下所有的文件all_files = glob.glob(os.path.join(workdir, '*'))# 将文件名和访问时间存入列表file_list = []for file in all_files:file_list.append((file, os.path.getatime(file)))# 根据访问时间排序file_list.sort(key=lambda x: x[1], reverse=False)# 删除旧文件,只保留最新的文件for file in file_list[:-3]: # 排除最后三个文件,因为它是最新的os.remove(file[0])def createfile(workdir,fileName):if not os.path.exists(workdir):os.makedirs(workdir)#os.system("find {}/*.json -type f -ctime +1 -delete".format(workdir) )#for fileName in os.listdir(workdir):file=open(workdir+fileName,'w',encoding="utf-8")return filedef readfile(workdir):if not os.path.exists(workdir):os.makedirs(workdir)# 获取目录下所有的文件all_files = glob.glob(os.path.join(workdir, '*'))# 将文件名和访问时间存入列表file_list = []for file in all_files:file_list.append((file, os.path.getatime(file)))# 根据访问时间排序files=[]file_list.sort(key=lambda x: x[1], reverse=False)for file in file_list: # 排除最后两个文件,因为它是最新的files.append(file[0])return filesdef writejson(file,jsonArr):for js in jsonArr:jstr=json.dumps(js)+"\n"file.write(jstr)file.close()#3,json转字符串
def getdata(domain,password):url = "http://"+domain+"/_cat/indices?format=json"# 设置认证信息auth = ('elastic', password)# 发送GET请求,并在请求中添加认证信息response = requests.get(url, auth=auth)# 检查响应状态码,如果成功则打印响应内容if response.status_code == 200:#遍历返回的json数组,提取需要的字段jsonArr=json.loads(response.text)df = pd.json_normalize(jsonArr)dfnew = df.drop(["uuid","docs.deleted"], axis=1)#print(dfnew)#保存_cat/es/indices数据到json文件workdir="/data/es-indices/"workdir_tmp=workdir+"tmp/"f_time = time.strftime("%Y-%m-%d_%H-%M-%S",time.localtime())filename="es-data-{}.json".format(f_time)filename_tmp="tmp-{}.json".format(f_time)file=createfile(workdir_tmp,filename_tmp)writejson(file,jsonArr)#删除旧文件,只保留2个最新的deloldfile(workdir_tmp)deloldfile(workdir)files=readfile(workdir_tmp)#df1=pd.read_json(files[0],lines=True,convert_dates=False)if len(files) > 1:print(files[0])print(files[1])df1=pd.read_json(files[0],lines=True)df2=pd.read_json(files[1],lines=True)#"health","status","index","uuid","pri","rep","docs.count","docs.deleted","store.size","pri.store.size"df1 = df1.drop(["health","status","uuid","pri","rep","docs.deleted","store.size","pri.store.size"], axis=1)df2 = df2.drop(["health","status","uuid","pri","rep","docs.deleted","store.size","pri.store.size"], axis=1)mdf = pd.merge(df1, df2, on='index', how='outer')#print(df1)else:mdf=dfnew#聚合3条数据,查看索引文档数量是否变化: 近10分钟的数量为doc.count, 前10分钟的数量为doc.count_x, 前20分钟的数量为doc.count_y, #print(mdf) mdf2 = pd.merge(dfnew, mdf, on='index', how='outer')mdf2 = mdf2.rename(columns={"docs.count_x":"docs.count_30", "docs.count_y":"docs.count_20"})#print(mdf2) file=createfile(workdir,filename)for idx,row in mdf2.iterrows():jstr=row.to_json()file.write(jstr+"\n")file.close()else:print('请求失败,状态码:', response.status_code)domain="196.1.0.106:9200"
password="123456"
getdata(domain,password)
脚本测试验证
[root@localhost] # python3 es-indices-monitor.py
/data/es-indices/tmp/tmp-2023-09-28_13-56-12.json
/data/es-indices/tmp/tmp-2023-09-28_14-11-47.json#查看结果
[root@localhost] # /appset/ldm/script # ll /data/es-indices/
total 148
-rw------- 1 root root 46791 Sep 28 13:56 es-data-2023-09-28_13-56-12.json
-rw------- 1 root root 46788 Sep 28 14:11 es-data-2023-09-28_14-11-47.json
-rw------- 1 root root 46788 Sep 28 14:12 es-data-2023-09-28_14-12-07.json
drwx------ 2 root root 4096 Sep 28 14:12 tmp
[root@localhost] # /appset/ldm/script # ll /data/es-indices/tmp/
total 156
-rw------- 1 root root 52367 Sep 28 13:56 tmp-2023-09-28_13-56-12.json
-rw------- 1 root root 52364 Sep 28 14:11 tmp-2023-09-28_14-11-47.json
-rw------- 1 root root 52364 Sep 28 14:12 tmp-2023-09-28_14-12-07.json#核对文档数量
[root@localhost] # /appset/ldm/script # head -n 2 /data/es-indices/es-data-2023-09-28_13-56-12.json |grep 2023_09 |grep count
{"health":"green","status":"open","index":"test_2023_09","pri":"3","rep":"1","docs.count":"14393","store.size":"29.7mb","pri.store.size":"13.9mb","docs.count_30":14391.0,"docs.count_20":14393.0}[root@localhost] # /appset/ldm/script # head -n 2 /data/es-indices/es-data-2023-09-28_14-11-47.json |grep 2023_09 |grep count
{"health":"green","status":"open","index":"test_2023_09","pri":"3","rep":"1","docs.count":"14422","store.size":"33.5mb","pri.store.size":"15.8mb","docs.count_30":14391.0,"docs.count_20":14393.0}[root@localhost] # /appset/ldm/script # head -n 2 /data/es-indices/es-data-2023-09-28_14-12-07.json |grep 2023_09 |grep count
{"health":"green","status":"open","index":"test_2023_09","pri":"3","rep":"1","docs.count":"14427","store.size":"33.5mb","pri.store.size":"15.8mb","docs.count_30":14393.0,"docs.count_20":14422.0}

相关文章:
python监控ES索引数量变化
文章目录 1, datafram根据相同的key聚合2, 数据合并:获取采集10,20,30分钟es索引数据脚本测试验证 1, datafram根据相同的key聚合 # 创建df1 > json {key:A, value:1 } {key:B, value:2 } data1 {key: [A, B], value: [1, 2]} df1 pd.DataFrame(data1)# 创建d…...

MySQL explain SQL分析工具详解与最佳实践
目录 一、explain工具介绍二、添加示例表和数据用于后续演示三、explain中的列3.1、id列3.2、select_type列3.3、table列3.4、partitions列3.5、type列NULLsystemconsteq_refrefrangeindexALL 3.6、possible_keys列3.7、key列3.8、key_len列3.9、ref列3.10、rows列3.11、filter…...
)
【2023年11月第四版教材】第16章《采购管理》(第一部分)
第16章《采购管理》(第一部分) 1 章节内容2 管理基础3 管理过程4 采购管理ITTO汇总 1 章节内容 【本章分值预测】大部分内容不变,细节有一些变化,预计选择题考3-4分,案例和论文 都有可能考;是需要重点学习…...
矢量图形编辑软件illustrator 2023 mac软件特点
illustrator 2023 mac是一款矢量图形编辑软件,用于创建和编辑排版、图标、标志、插图和其他类型的矢量图形。 illustrator mac软件特点 矢量图形:illustrator创建的图形是矢量图形,可以无限放大而不失真,这与像素图形编辑软件&am…...

前端架构师之01_JavaScript_Ajax
1 Web基础知识 1.1 Web服务器 Web服务器又称为网站服务器,主要用于提供网上信息浏览服务。常见的Web服务器软件有Apache HTTP Server(简称Apache)、Nginx等。 浏览器与服务器交互 在Web服务器中,请求资源又分为静态资源和动态…...

Java Spring Boot 目录结构介绍
Java Spring Boot 是一个用于简化Java应用程序开发的框架,它提供了一套灵活、易用的开发工具和约定,帮助开发者更快速地构建各种类型的Java应用程序。Spring Boot 的目录结构是一个重要的组成部分,它规定了如何组织和管理项目代码和资源文件。…...
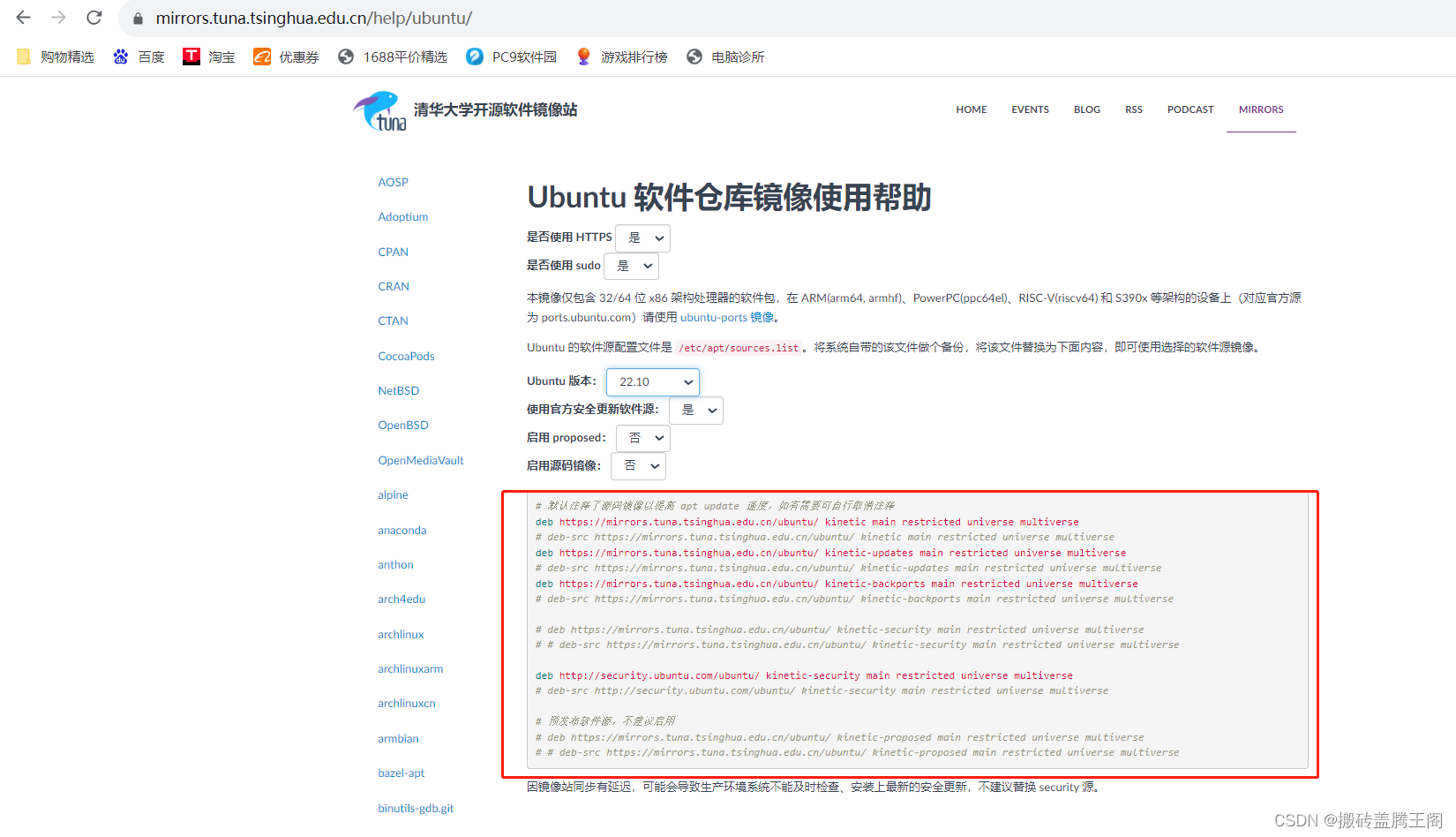
ubuntu apt工具软件操作
apt工具 -----> 网关 国内网络(仓库源) 美国网络(仓库源)/etc/apt/sources.list https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/sudo apt-get update sudo apt install sl 安装包 sudo apt-cache show sl 查看包信…...

【论文阅读】UniDiffuser: Transformer+Diffusion 用于图、文互相推理
而多模态大模型将能够打通各种模态能力,实现任意模态之间转化,被认为是通用式生成模型的未来发展方向。 最近看到不少多模态大模型的工作,有医学、金融混合,还有CV&NLP。 今天介绍: One Transformer Fits All Di…...

Python爬虫教程——解析网页中的元素
前言: 嗨喽~大家好呀,这里是小曼呐 ~ 在我们理解了网页中标签是如何嵌套,以及网页的构成之后, 我们就是可以开始学习使用python中的第三方库BeautifulSoup筛选出一个网页中我们想要得到的数据。 接下来我们了解一下爬取网页信息…...
BiMPM实战文本匹配【上】
引言 今天来实现BiMPM模型进行文本匹配,数据集采用的是中文文本匹配数据集。内容较长,分为上下两部分。 数据准备 数据准备这里和之前的模型有些区别,主要是因为它同时有字符词表和单词词表。 from collections import defaultdict from …...
【C++】构造函数和析构函数第二部分(拷贝构造函数)--- 2023.9.28
目录 什么是拷贝构造函数?编译器默认的拷贝构造函数构造函数的分类及调用结束语 什么是拷贝构造函数? 用一句话来描述为拷贝构造即 “用一个已知的对象去初始化另一个对象” 具体怎么使用我们直接看代码,代码如下: class Maker…...

现在学RPA,还有前途吗,会不会太卷?
RPA是机器人流程自动化的缩写,是一种通过软件机器人模拟人类操作计算机的技术。随着人工智能和自动化技术的不断发展,RPA已经成为了企业数字化转型的重要工具之一。那么,现在学习RPA还有前途吗?会不会太卷? 一、RPA的…...

Vue的详细教程--用Vue-cli搭建SPA项目
Vue的详细教程--用Vue-cli搭建SPA项目 1.Vue-cli是什么2.什么是SPA项目1.vue init webpack spa2.一问一答模式2:运行完上面的命令后,我们需要将当前路径改变到SPA这个文件夹内,然后安装需要的模块此步骤可理解成:maven的web项目创…...

openldap访问控制
系统:debian12 /etc/ldap/slapd.d/cnconfig目录下 包含以下三个数据库: dn: olcDatabase{-1}frontend,cnconfig dn: olcDatabase{0}config,cnconfig dn: olcDatabase{1}mdb,cnconfigolcDatabase: [{\<index\>}]\<type\>数据库条目必须具有…...

阿里云服务器技术创新、网络技术和数据中心技术说明
阿里云服务器技术创新、网络技术创新、数据中心技术创新和智能运维:云服务器方升架构、自研硬件、自研存储硬件AliFlash和异构计算加速平台,以及全自研网络系统技术创新和数据中心巴拿马电源、液冷技术等技术创新说明,阿里云百科分享阿里云服…...

华为智能高校出口安全解决方案(2)
本文承接: https://qiuhualin.blog.csdn.net/article/details/131475315?spm1001.2014.3001.5502 重点讲解华为智能高校出口安全解决方案的基础网络安全&业务部署与优化的部署流程。 华为智能高校出口安全解决方案(2) 课程地址基础网络…...

【AI绘画】Stable Diffusion WebUI
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kuan 的首页,持续学…...

html、css学习记录【uniapp前奏】
Html 声明:该学习笔记源于菜鸟自学网站,特此记录笔记。很多示例源于此官网,若有侵权请联系删除。 文章目录 Html声明: CSS 全称 Cascading Style Sheets,层叠样式表。是一种用来为结构化文档(如 HTML 文档…...
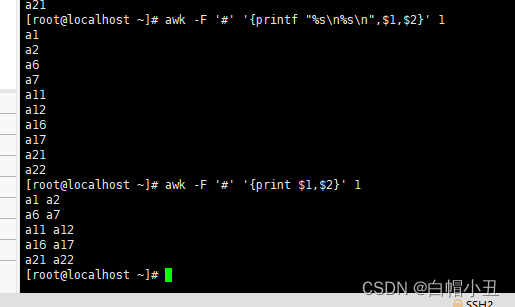
Linux-正则三剑客
目录 一、正则简介 1.正则表达式分两类: 2.正则表达式的意义 二、Linux三剑客简介 1.文本处理工具,均支持正则表达式引擎 2.正则表达式分类 3.基本正则表达式BRE集合 4.扩展正则表达式ere集合 三、grep 1.简介 2.实践 3.贪婪匹配 四、sed …...

Zilliz@阿里云:大模型时代下Milvus Cloud向量数据库处理非结构化数据的最佳实践
大模型时代下的数据存储与分析该如何处理?有没有已经落地的应用实践? 为探讨这些问题,近日,阿里云联合 Zilliz 和 Doris 举办了一场以《大模型时代下的数据存储与分析》为主题的技术沙龙,其中,阿里云对象存储 OSS 上拥有海量的非结构化数据,Milvus(Zilliz)作为全球最有…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...
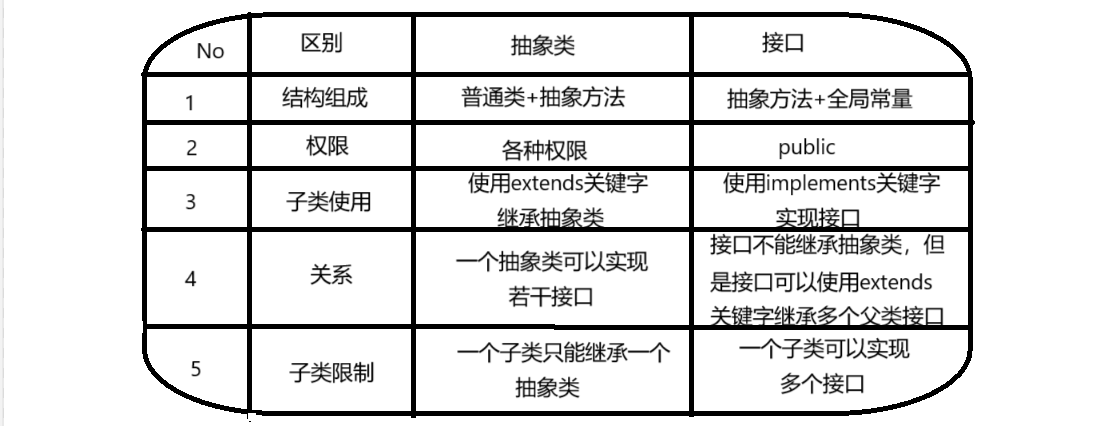
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...