社畜大学生的Python之pandas学习笔记,保姆入门级教学
接上期,上篇介绍了 NumPy,本篇介绍 pandas。
目录
- pandas 入门
- pandas 的数据结构介绍
- 基本功能
- 汇总和计算描述统计
- 处理缺失数据
- 层次化索引
pandas 入门
Pandas 是基于 Numpy 构建的,让以 NumPy 为中心的应用变的更加简单。
Pandas是基于Numpy的专业数据分析工具, 可以灵活高效的处理各种数据集
它提供了的数据结构有DataFrame和Series等
我们可以简单粗的把DataFrame理解为Excel里面的一张表,而Series就是表中的某一列
pandas 的数据结构介绍
1、Series
由一组数据(各种 NumPy 数据类型)和一组索引组成:
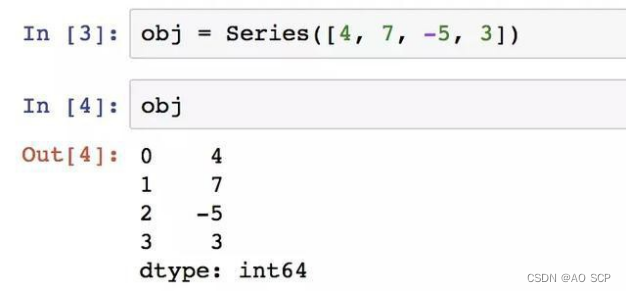
Values 和 index 属性:

给所创建的 Series 带有一个可以对各个数据点进行标记的索引:
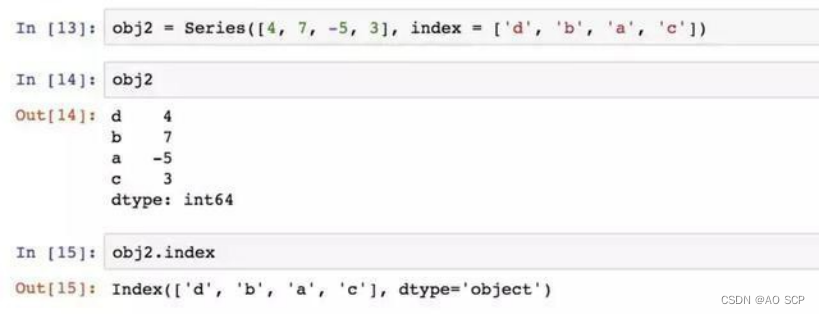
与普通 NumPy 数组相比,可以通过索引的方式选取 Series 中的单个或一组值:

可将 Series 看成是一个定长的有序字典,它是索引值到数据值的一个映射(它可以用在许多原本需要字典参数的函数中)。
如果数据被存放在一个 python 字典中,可以直接通过这个字典来创建 Series:
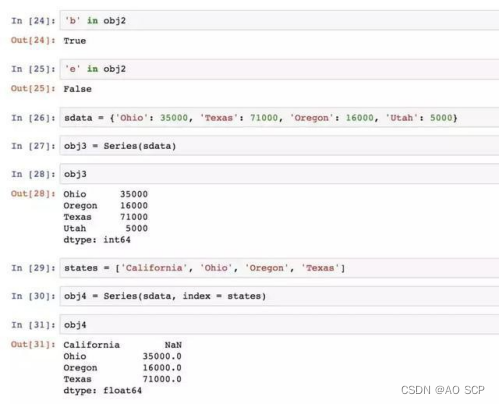
如果只传入一个字典,则结果 Series 中的索引就是原字典的键(有序排列),上面的 states。
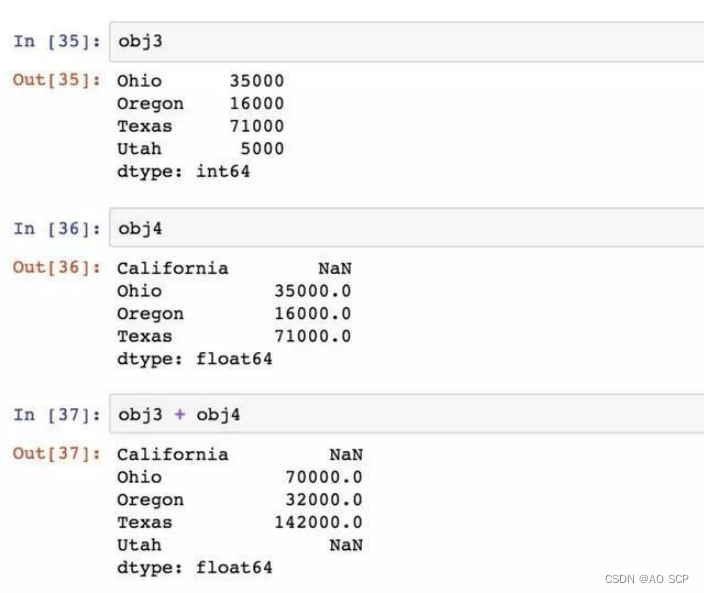
Series 最重要的一个功能是在算数运算中自动对齐不同索引的数据:
Series 对象本身及其索引都有一个 name 属性:
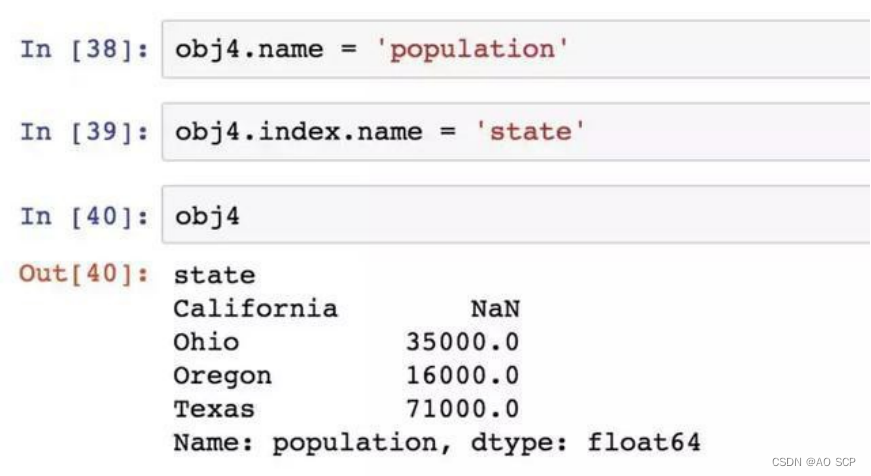
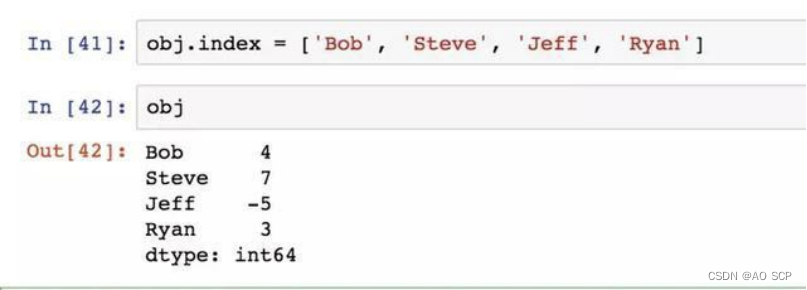
Series 的索引可以通过赋值的方式就地修改:
2、DataFrame
是一个表格型的数据结构。既有行索引也有列索引。DataFrame 中面向行和面向列的操作基本是平衡的。DataFrame 中的数据是以一个或多个二维块存放的。用层次化索引,将其表示为更高维度的数据。
构建 DataFrame:直接传入一个由等长列表或 NumPy 数组组成的字典。
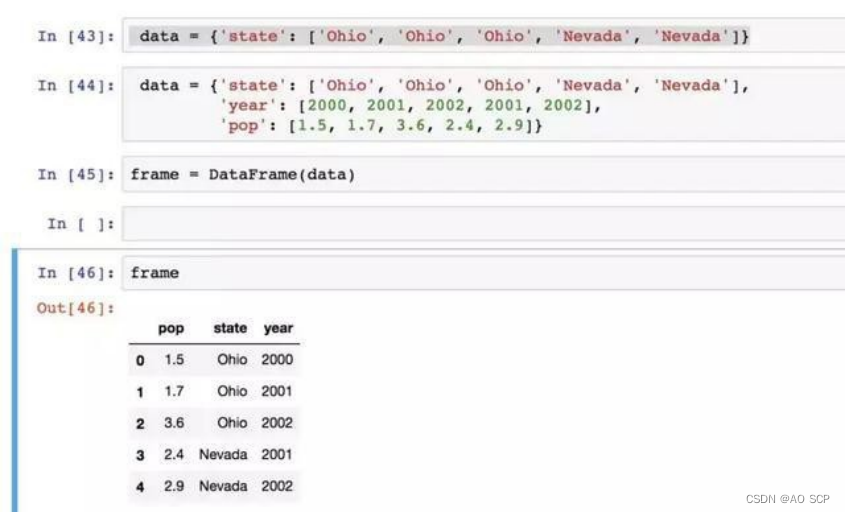
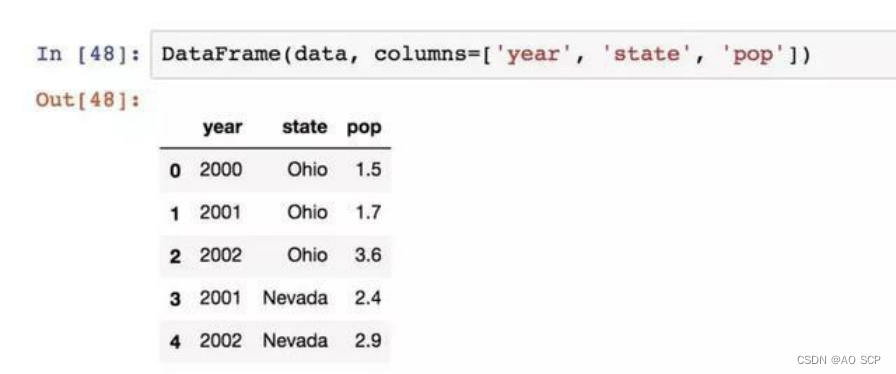
会自动加上索引,但指定列序列,则按指定顺序进行排列:
和 Series 一样,如果传入的列在数据中找不到,就会产生 NA 值:
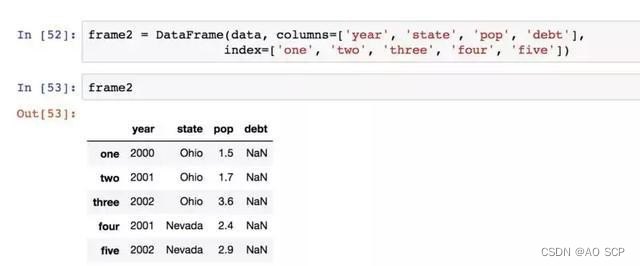
通过赋值的方式进行修改:
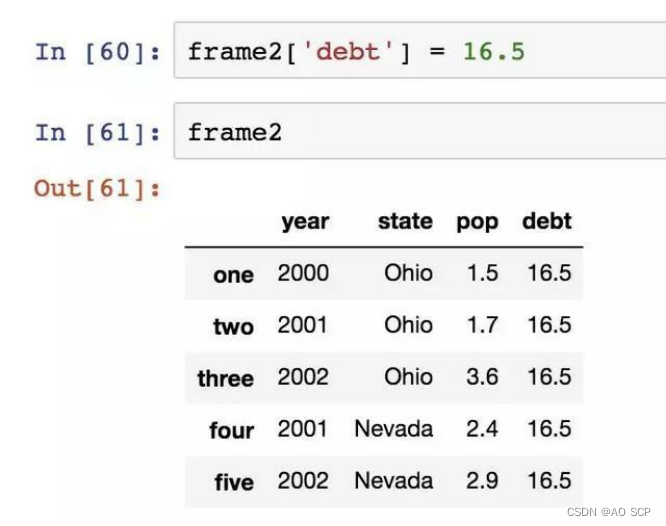
通过类似字典标记的方式或属性的方式,可以将 DataFrame 的列获取为一个Series:
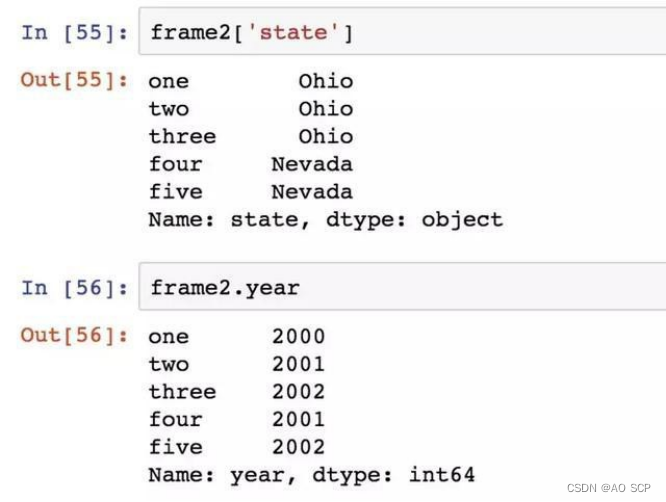
行也可以通过位置或名称的方式进行获取,比如用索引字段 ix。
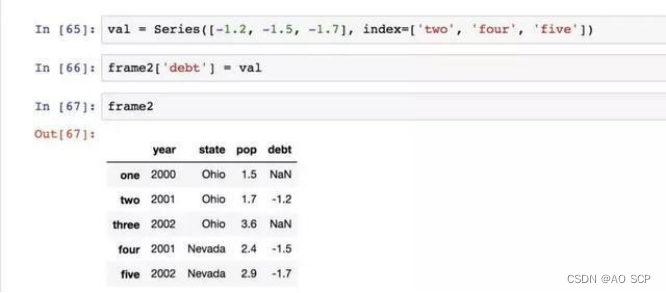
将列表或数组赋值给某个列时,其长度必须跟 DataFrame 的长度相匹配。如果赋值的是一个 Series,就会精确匹配 DataFrame 的索引,所有的空位都将被填上缺失值:
给不存在的列赋值会创建出一个新列,关键字 del 用于删除列:
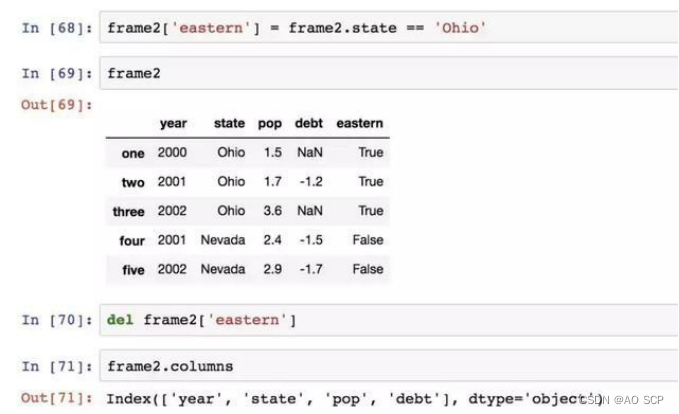
通过索引方式返回的列是相应数据的视图,并不是副本,对返回的 Series 做的任何修改都会反映到源 DataFrame 上,通过 series 的 copy 方法即可显式地复制列。
另一种常见的数据形式是嵌套字典,如果将它传给 DataFrame,解释为——外层字典的键作为列,内层键作为行索引。
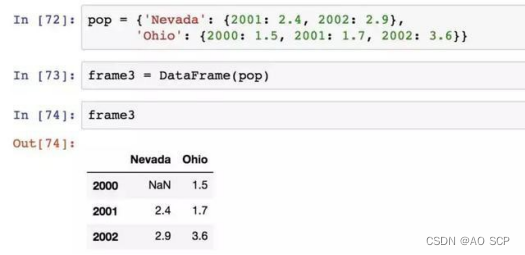
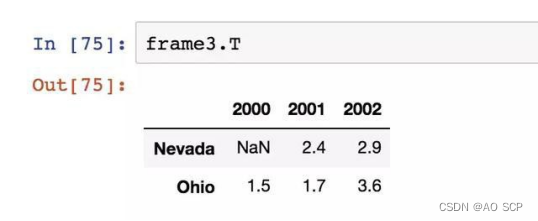
对结果进行转置:
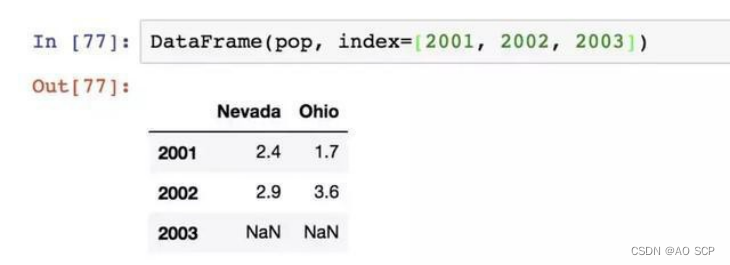
指定索引按序列:
由 Series 组成的字典差不多也是一样的用法:
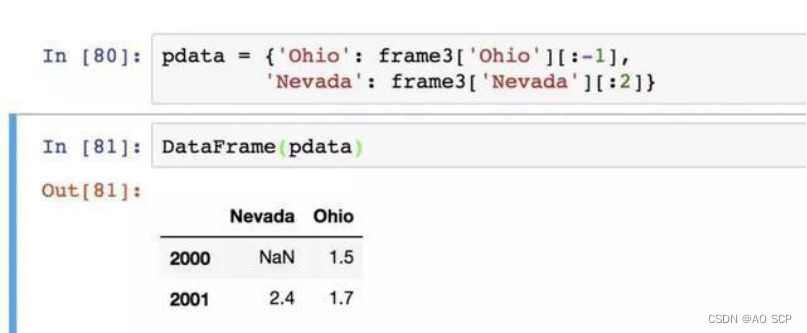
设置了 DataFrame 的 index 和 columns 的 name 属性,这些信息也会被显示,
values 属性以二维 ndarray 的形式返回 DataFrame 中的数据:
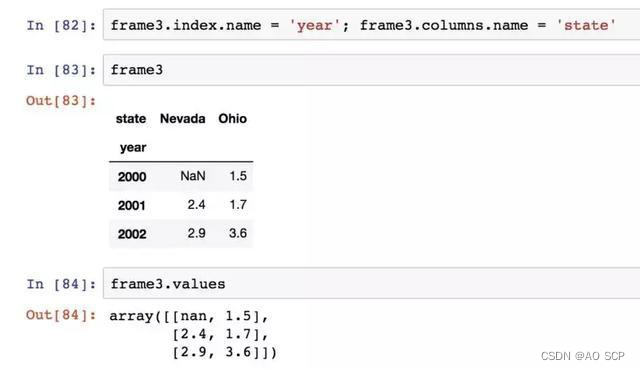
如果 DataFrame 各列的数据类型不同,值数组的数据类型就会选用能兼容所有列的数据类型(如 dtype = object)。
3、索引对象
pandas 的索引对象,管理轴标签和其他元数据(如轴名称等)。
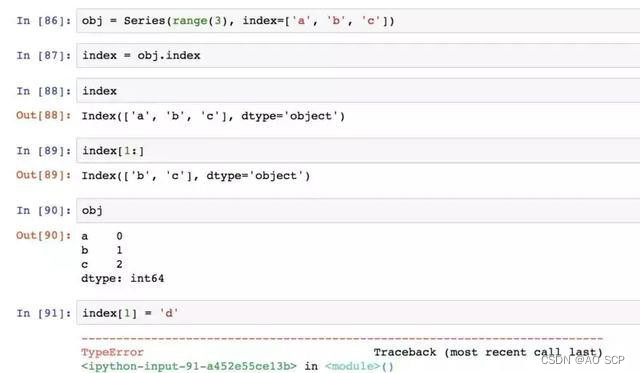
构建 Series 或 DataFrame 时,所用到的任何数组或其他序列的标签都会被转换成一个 Index,且 Index 对象是不可修改的:
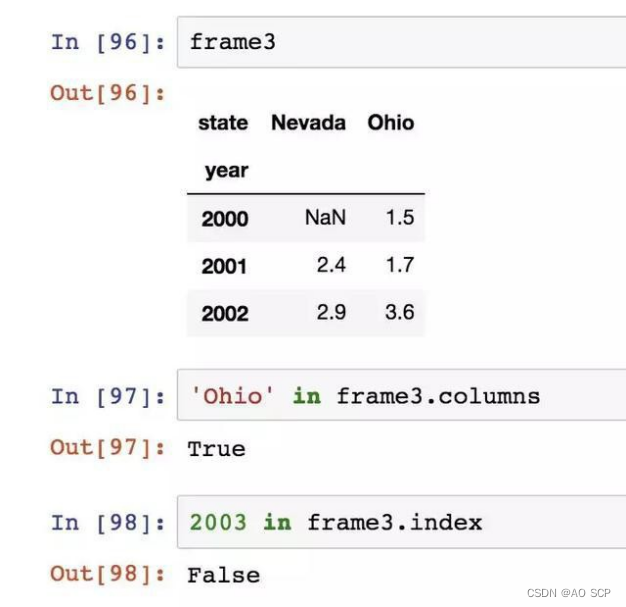
Index 的功能类似一个固定大小的集合:
基本功能
**1、重新索引**方法 reindex:创建一个适应新索引的新对象。
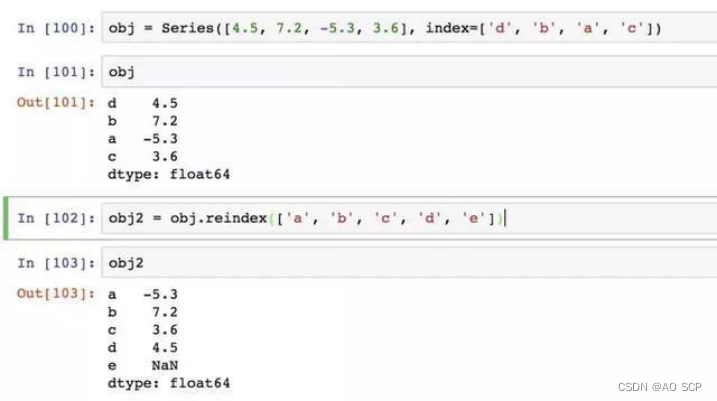
调用该 Series 的 reindex 将会根据新索引进行重排。如果某个索引值当前不存在, 就引入缺失值。
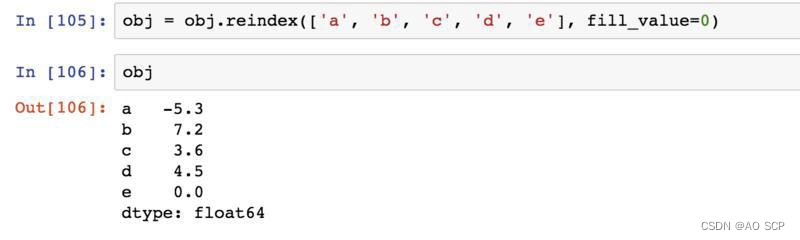
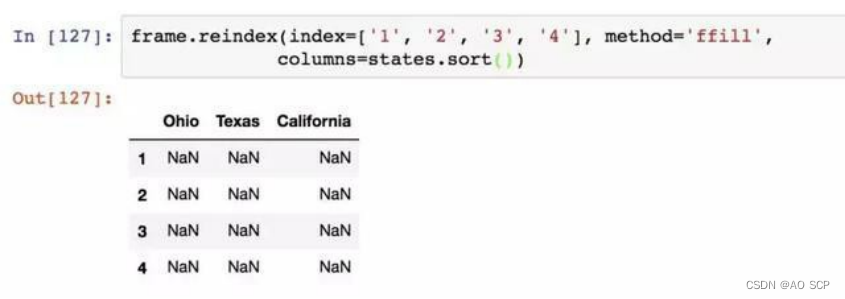
对于时间序列这样的有序数据,重新索引时可能需要做一些差值处理:
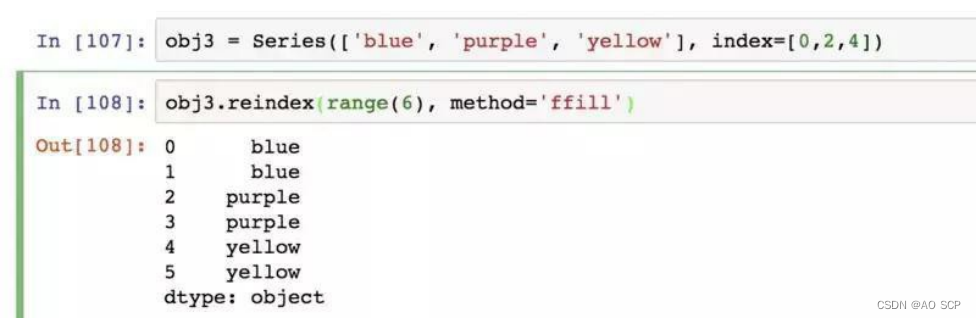
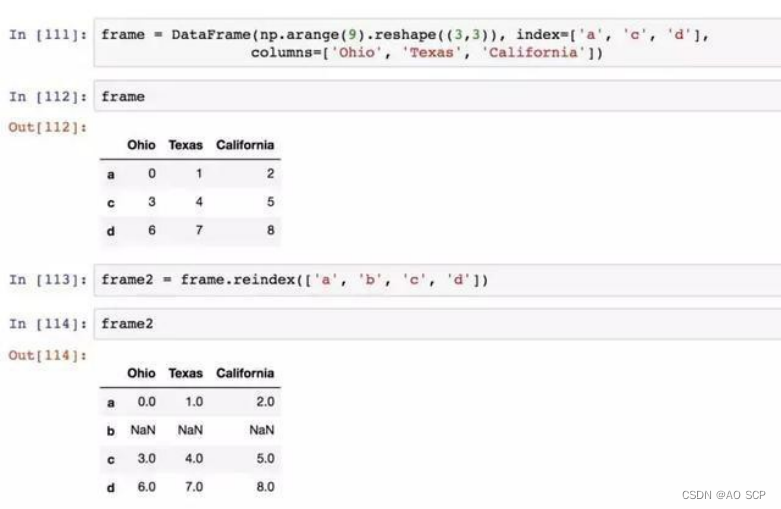
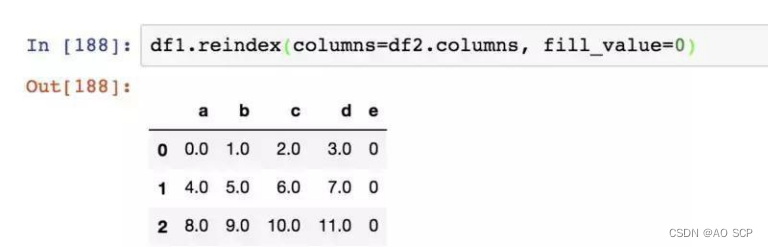
对于 DataFrame ,reindex 可以修改行、列索引,或两个都修改。如果仅传入一列,则会重新索引行:
使用 columns 关键字可重新索引列:
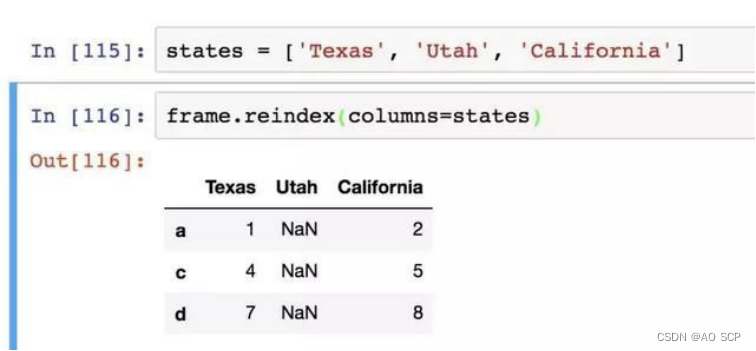
同时对行、列进行索引:
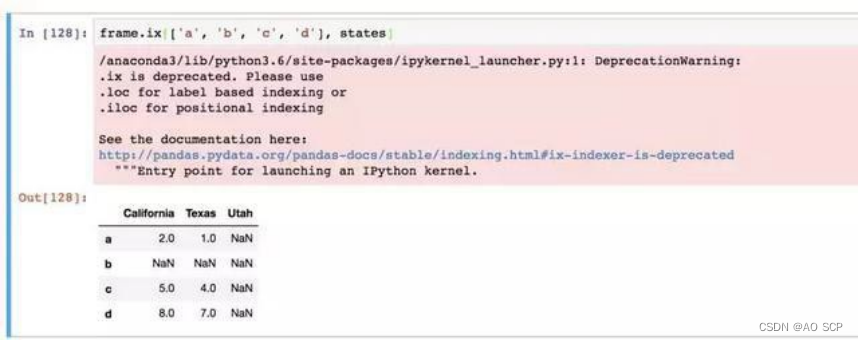
ix 标签索引功能:
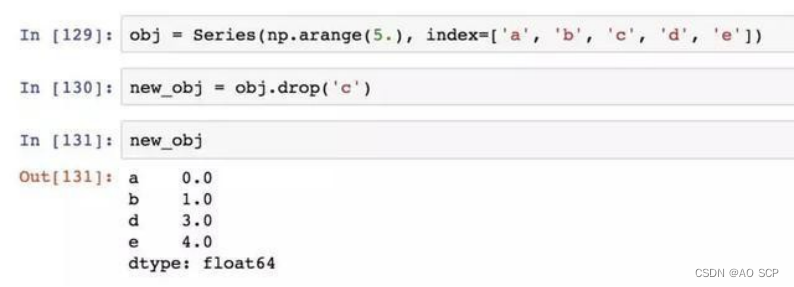
丢弃制定轴上的项
drop 方法返回的是一个在指定轴上删除了指定值的新对象:
对于 DataFrame,可以删除任意轴上的索引值:
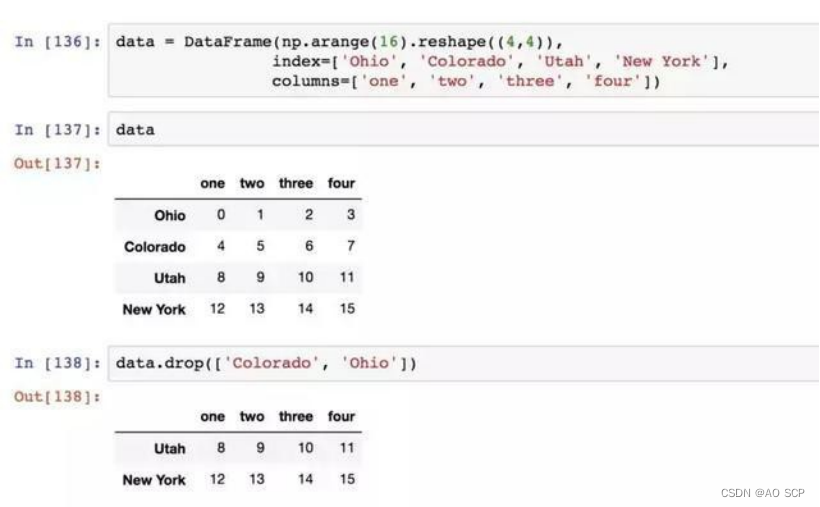
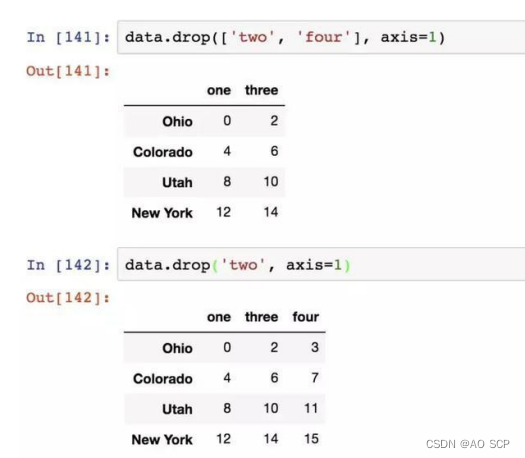
2、索引、选取和过滤
Series 索引的工作方式类似于NumPy 数组的索引,但Series 的索引值不只是整数:
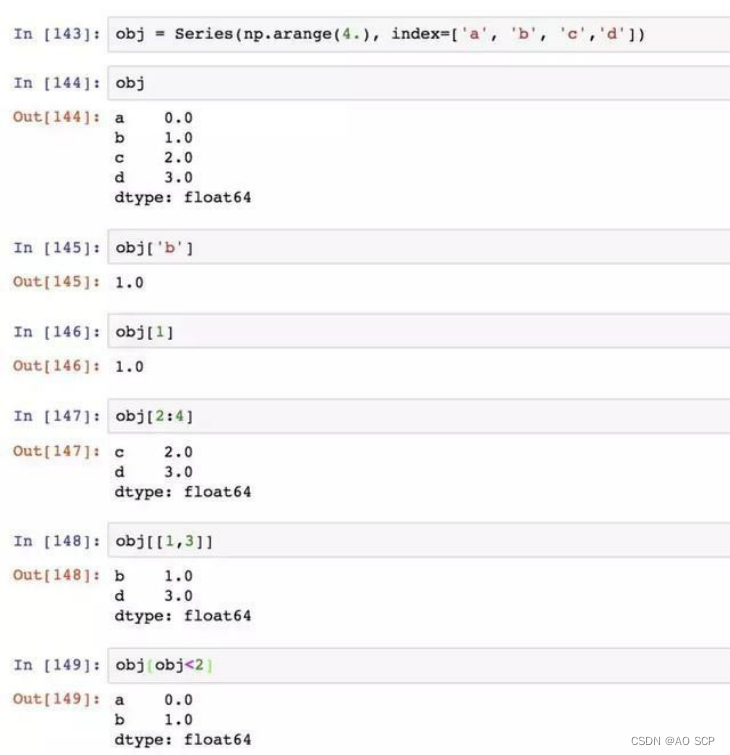
利用标签的切片运算,其包含闭区间(与普通Python的切片运算不同):

对 DataFrame 进行索引就是获取一个列:
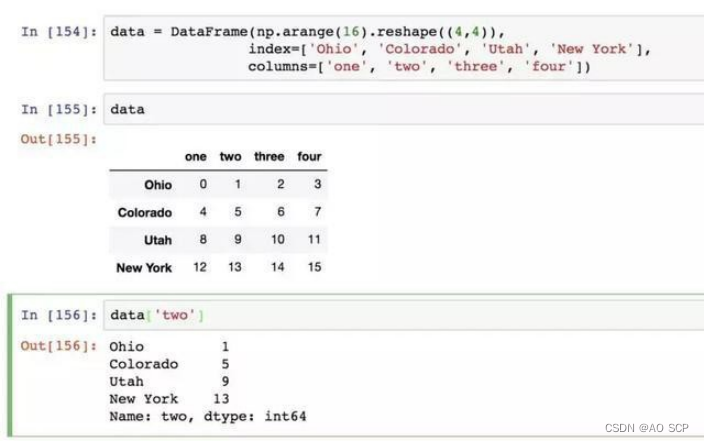
或多个列:

这种索引方式的特殊情况:通过切片或布尔型数组选取行。
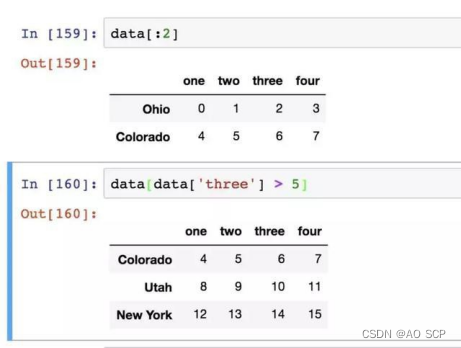
另一种用法是通过布尔型 DataFrame 进行索引(在语法上更像 ndarray):
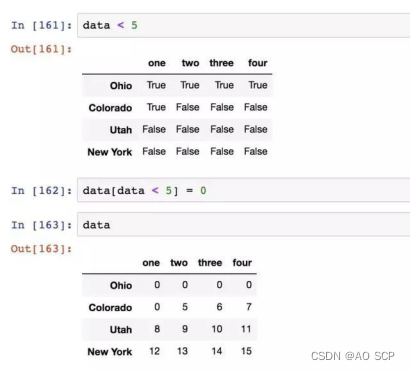
专门的索引字段 ix,是一种重新索引的简单手段:
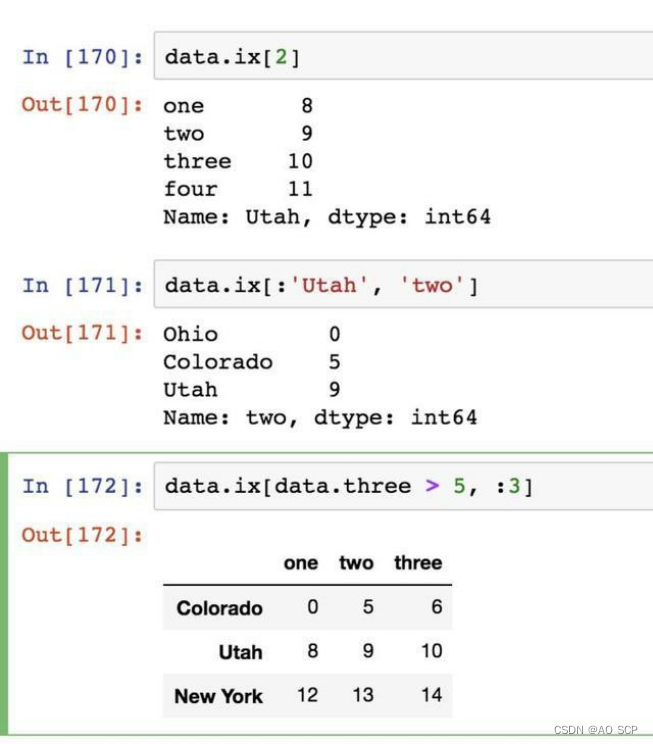
3、算术运算和数据对齐
pandas 最重要的一个功能是对不同索引的对象进行算术运算。对不同的索引对,取并集:
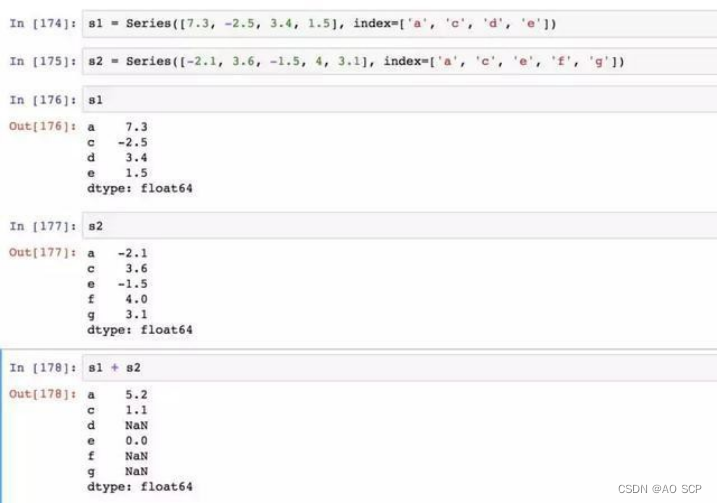
自动的数据对齐操作在不重叠的索引出引入了 NA 值,即一方有的索引,另一方没有,运算后该处索引的值为缺失值。
对 DataFrame,对齐操作会同时发生在行和列上。
4、在算术方法中填充值
对运算后的 NA 值处填充一个特殊值(比如 0):

否则 e 列都是 NaN 值。
类似,在对 Series 和 DataFrame 重新索引时,也可以指定一个填充值:
用这几个特定字的,叫算术方法:add/ sub/ div/ mul ,即:加/减/除/乘。
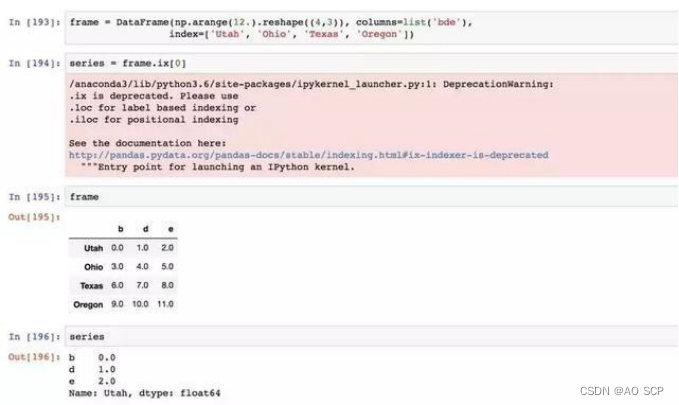
5、DataFrame 和 Series 之间的运算
计算一个二维数组与其某行之间的差:

这个就叫做广播,下面的每行都做这个运算了。
默认情况下,DataFrame 和 Series 之间的算术运算会将 Series 的索引匹配到
DataFrame 的列,然后沿着行一直向下广播:
得到
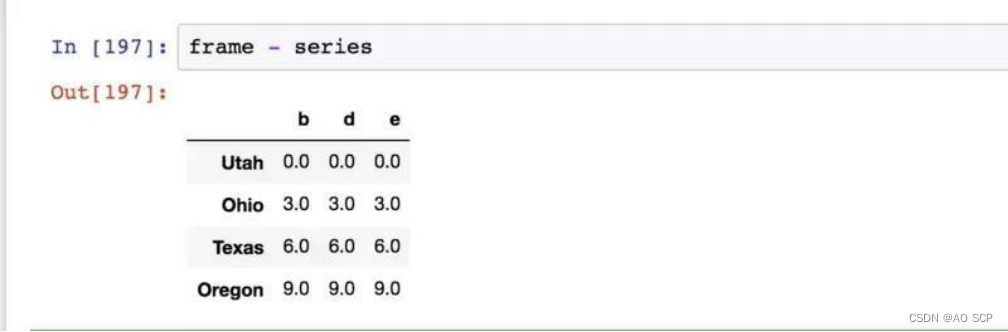
做加法 frame+series2,找不到的值就并集为 NaN。
如果你希望匹配行,且在列上广播,则必须使用算术运算方法:
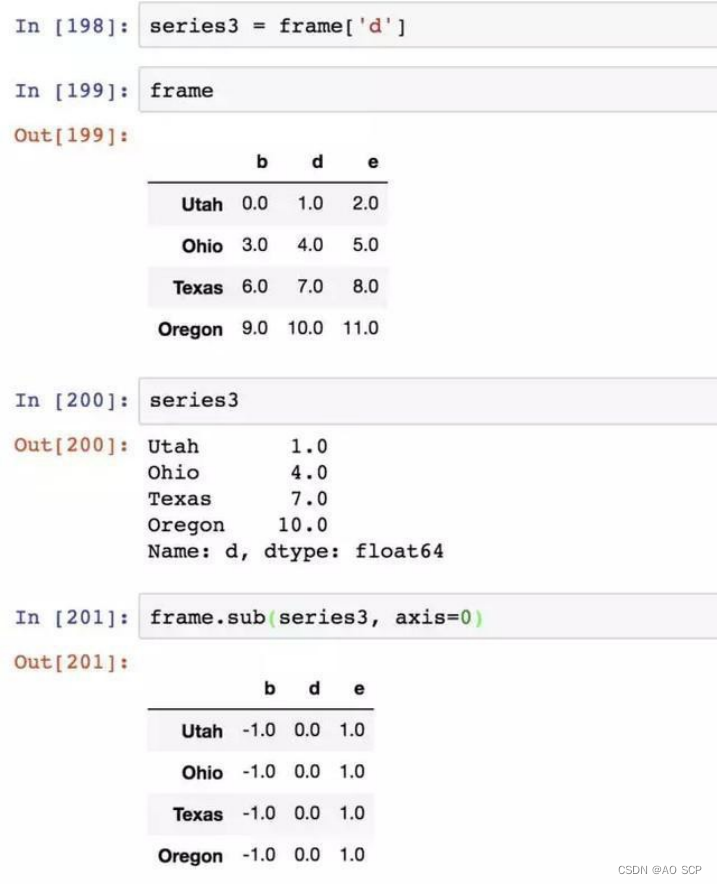
传入的轴号就是希望匹配的轴。
6、函数的应用和映射
NumPy 的 ufuncs 可用于操作 pandas 对象,以 abs 为例:
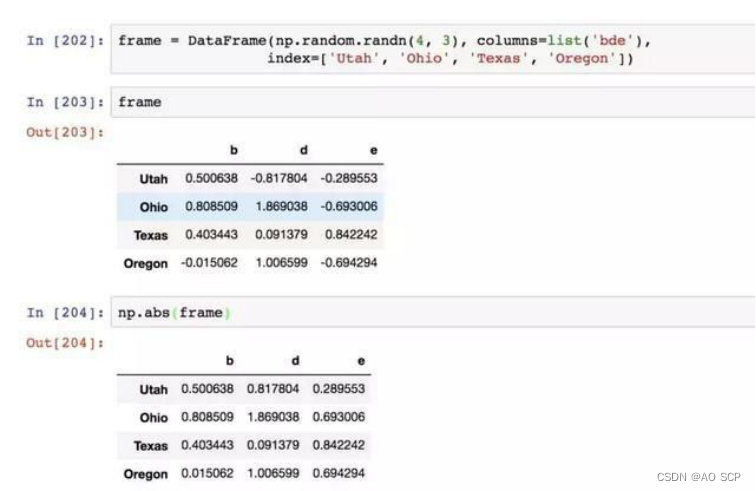
DataFrame 的 apply 方法:将函数应用到各列或行所形成的一维数组上:
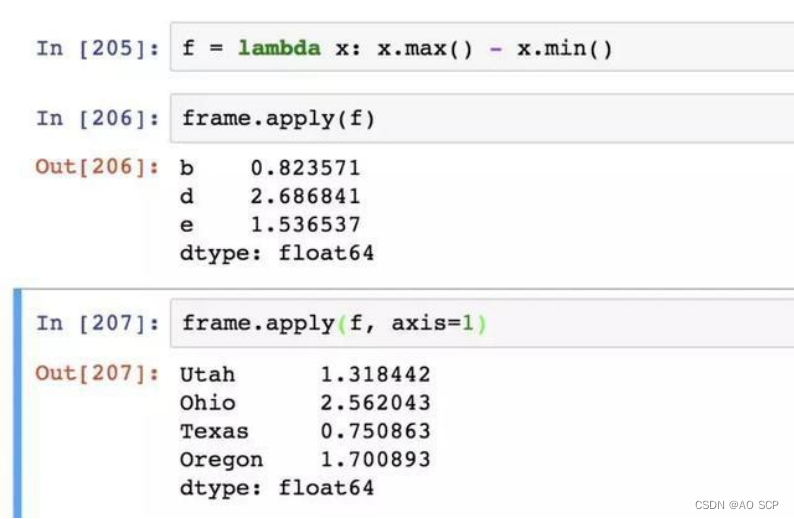
许多最为常见的数据统计功能都被封装为 DataFrame 的方法,无需使用 apply 方法。
除标量值外,传递给 apply 的函数还可以返回由多个值组成的 Series:

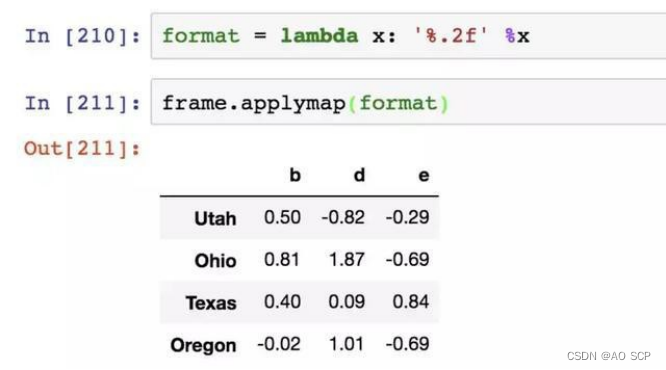
用 applymap 得到 frame 中各个浮点值的格式化字符串:
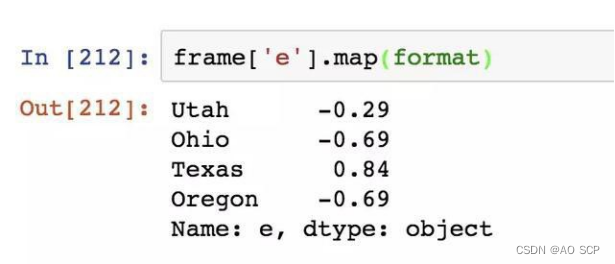
Series 有一个用于应用元素级函数的 map 方法:
7、排序和排名
sort_index 方法:返回一个已排序的新对象

对于 DataFrame,可以根据任意一个轴上的索引进行排序:
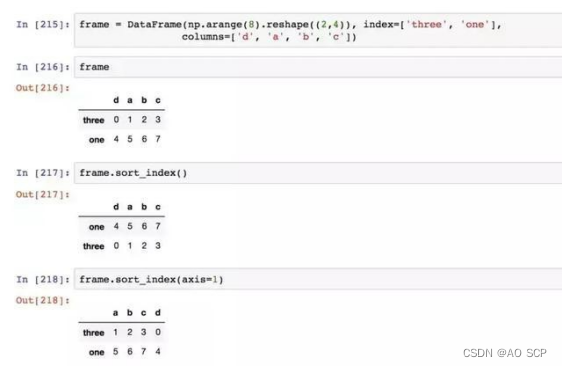
指定了 axis=1,是对列进行排序。
默认按升序,降序用 ascending=False:

对 Series 进行排序,可用方法 sort_values():
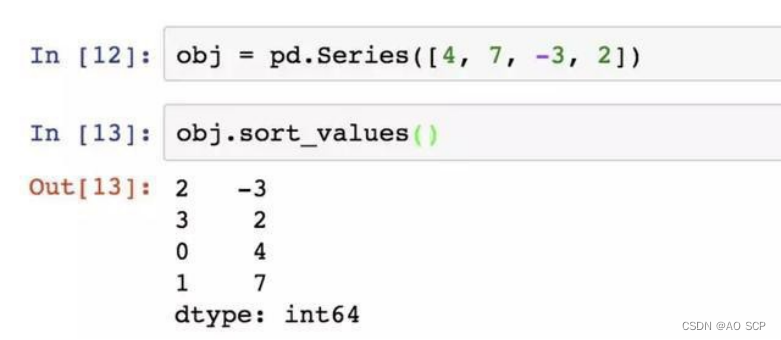
在排序时,任何缺失值默认都会被放到 Series 末尾。在 DataFrame 上,用 by 根据列的值进行排序:
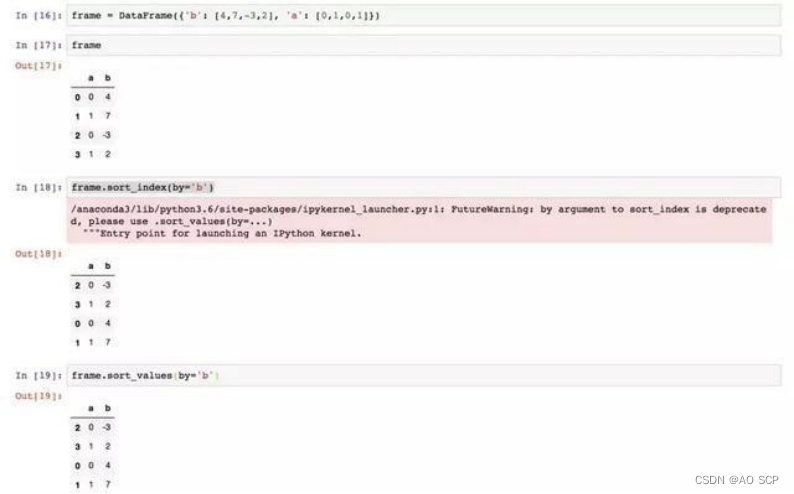
根据多个列:

rank 方法:默认情况下,rank 是通过“为各组分配一个平均排名”的方式破坏平级关系的。
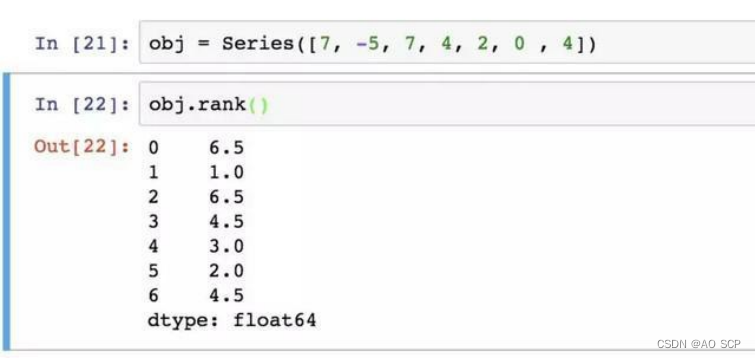
根据值在原数据中出现的顺序给出排名:
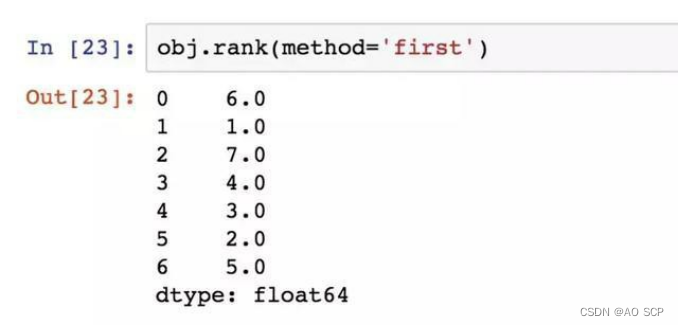
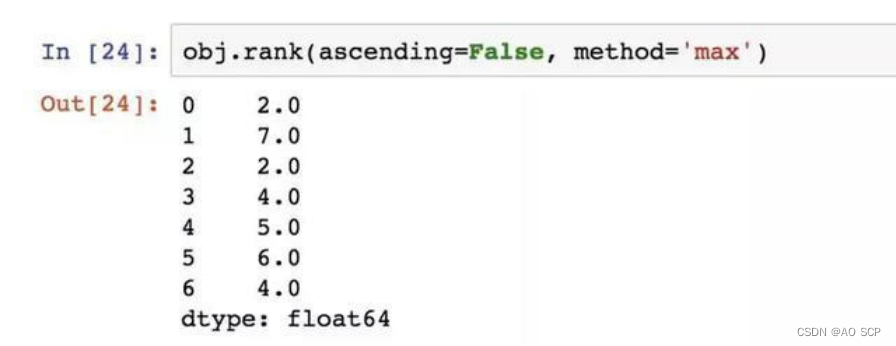
按降序进行排名:
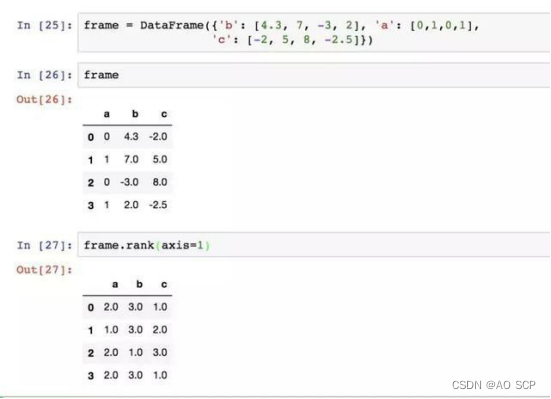
DataFrame 可以在行或列上计算排名:
8、带有重复值的轴索引
虽然许多 pandas 函数都要求标签唯一(如 reindex),但这不是强制性的。带有重复索引的 Series:
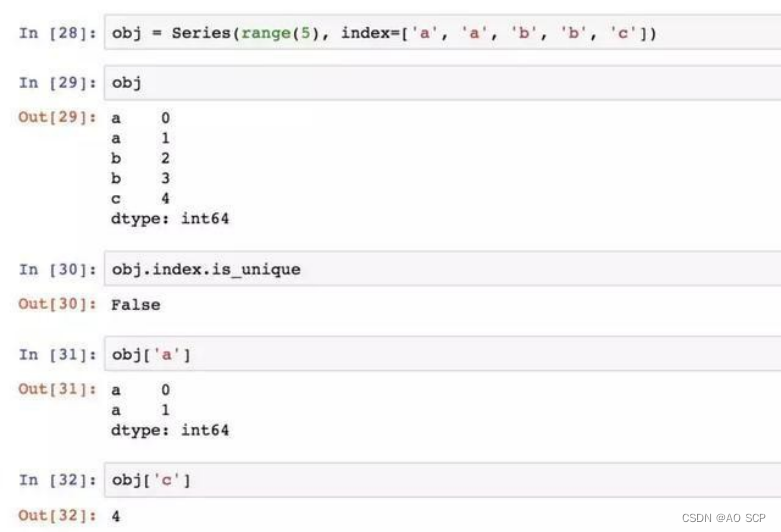
索引的 is_unique 属性可以判断它的值是否唯一。带有重复索引的 DataFrame:
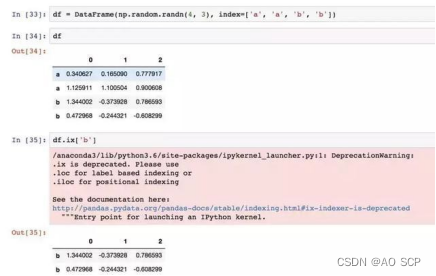
在 Pandas 中,DataFrame.ix[i] 和 DataFrame.iloc[i] 都可以选取 DataFrame 中第
i 行的数据,那么这两个命令的区别在哪里呢?
ix 可以通过行号和行标签进行索引,而 iloc 只能通过行号索引,即 ix 可以看做是
loc 和 iloc 的综合。

汇总和计算描述统计
pandas 对象拥有一组常用的数学和统计方法:用于从 Series 中提取单个值,或从
DataFrame 的行或列中提取一个 Series。
跟 Numpy 数组方法相比,它们都是基于没有缺失数据的假设而构建的。
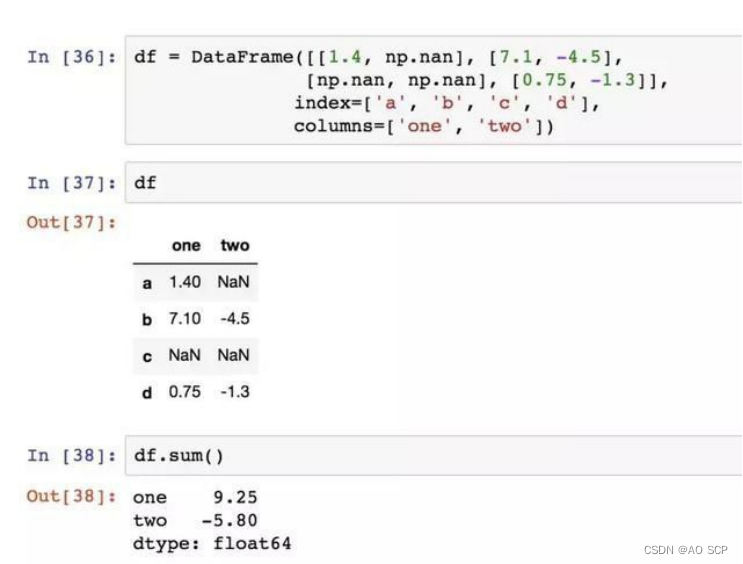
传入 axis=1 将会按行进行求和运算:

NA 值会自动被排除,如 1.40+NaN=1.40, NaN+NaN=0.00。
通过 skipna 选项可以禁用该功能:(得到 1.40+NaN=NaN, NaN+NaN=NaN)
返回间接统计(输出了值所在的行名):
累计型的(样本值的累计和):

一次性产生多个汇总统计:
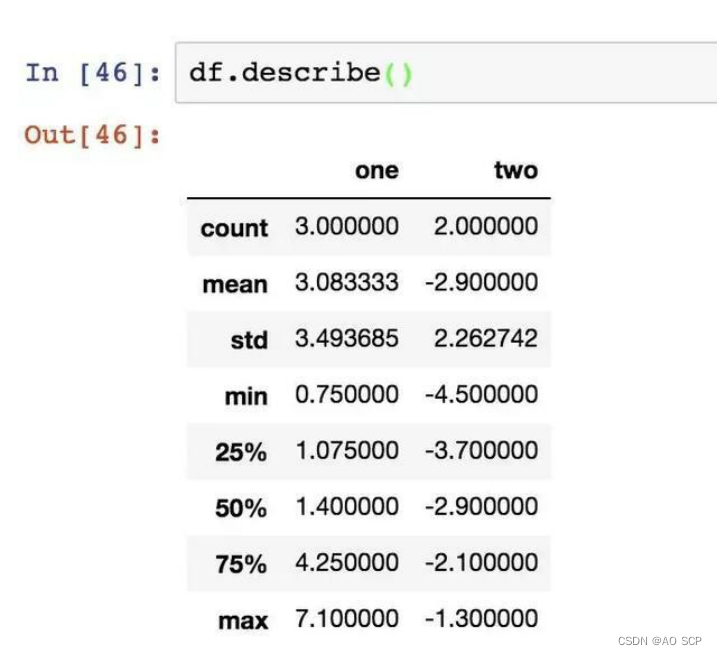
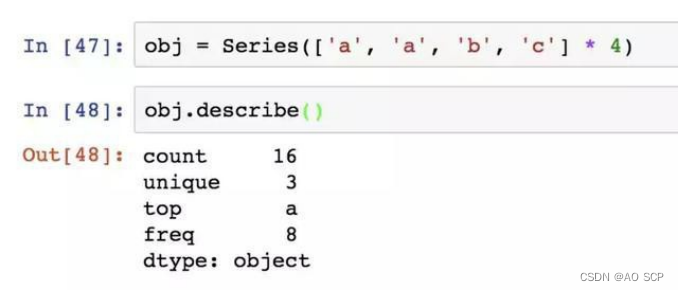
对于非数值型数据,describe 会产生另外一种汇总统计:
1、相关系数与协方差
Series 和 DataFrame:
- corr 方法: 相关系数
- cov 方法:协方差
DataFrame 的 corrwith 方法:计算其列或行跟另一个 Series 或 DataFrame 之间的相关系数。传入一个 DataFrame 计算按列名配对的相关系数,传入 axis=1 即可按行进行计算。
2、唯一值、值计数以及成员资格从一维 Series 的值中抽取信息。
unique 函数:得到 Series 中的唯一值数组

value_counts:用于计算一个 Series 中各值出现的频率:
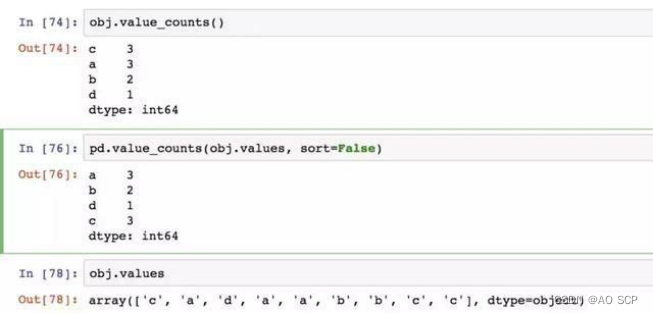
Series 按降序排列。value_counts 是一个顶级 pandas 方法,可用于任何数组或序列。
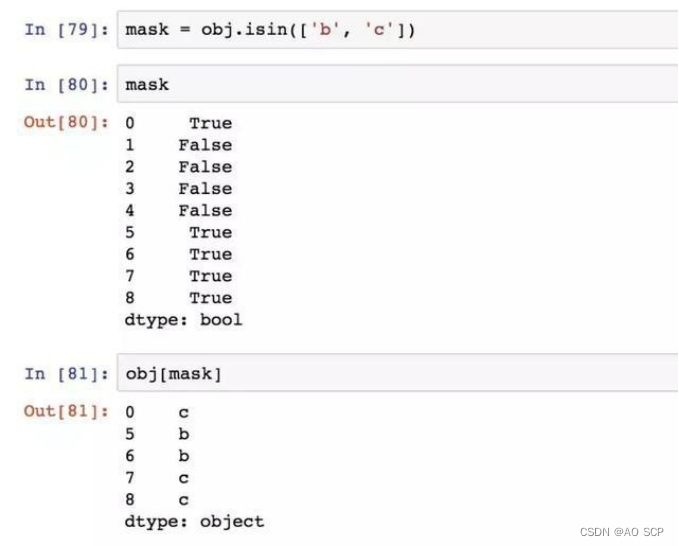
isin:用于判断矢量化集合的成员资格,可用于选取 Series 或 DataFrame 列中数据的子集:
处理缺失数据
pandas 的设计目标之一就是让缺失数据的处理任务尽量轻松。
pandas 使用浮点值 NaN(Not a Number) 表示浮点和非浮点数组中的缺失数据。它只是一个便于被检测出来的标记而已。
python 内置的 None 值也会被当做 NA 处理(如 string_data[0]=None)。
1、滤掉缺失数据
对于一个 Series, dropna 返回一个仅含非空数据和索引值的 Series:
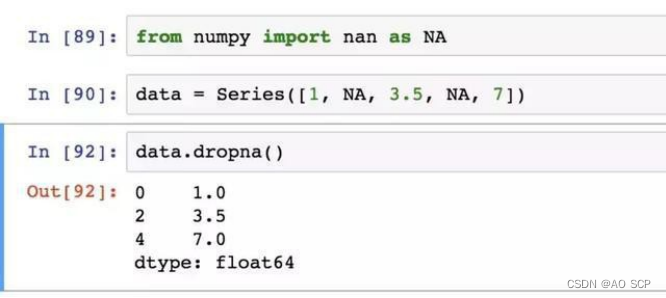
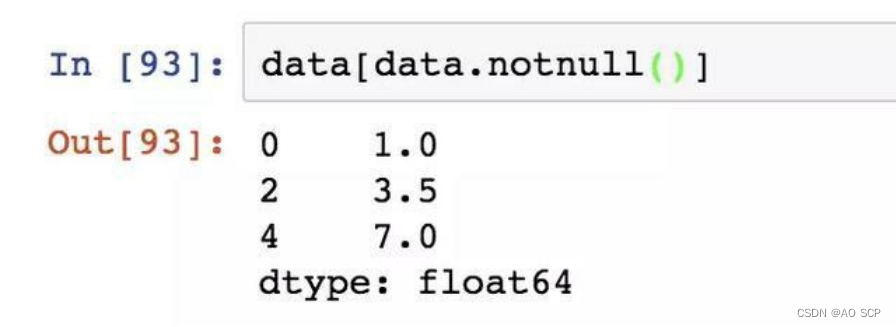
通过布尔型索引也可以达到这个目的:
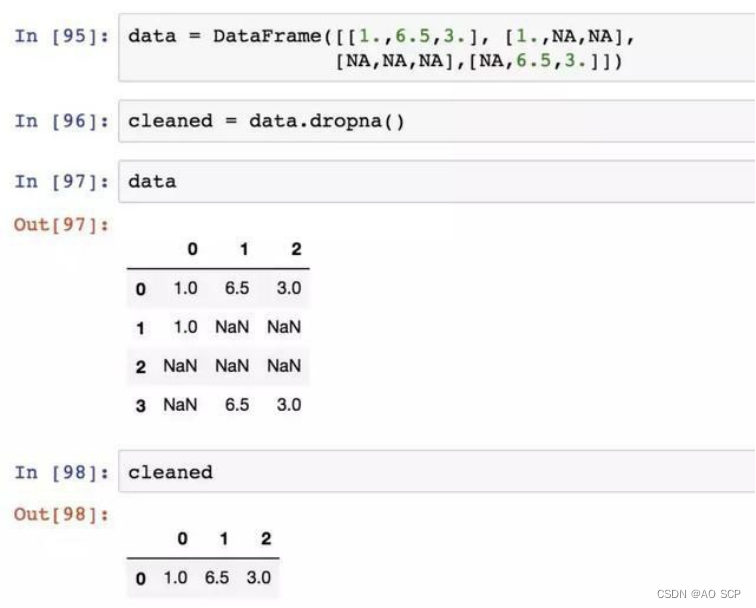
对于 DataFrame 对象,dropna 默认丢弃任何含有缺失值的行:
丢弃全为 NA 的那些行,axis=1 则丢弃列:
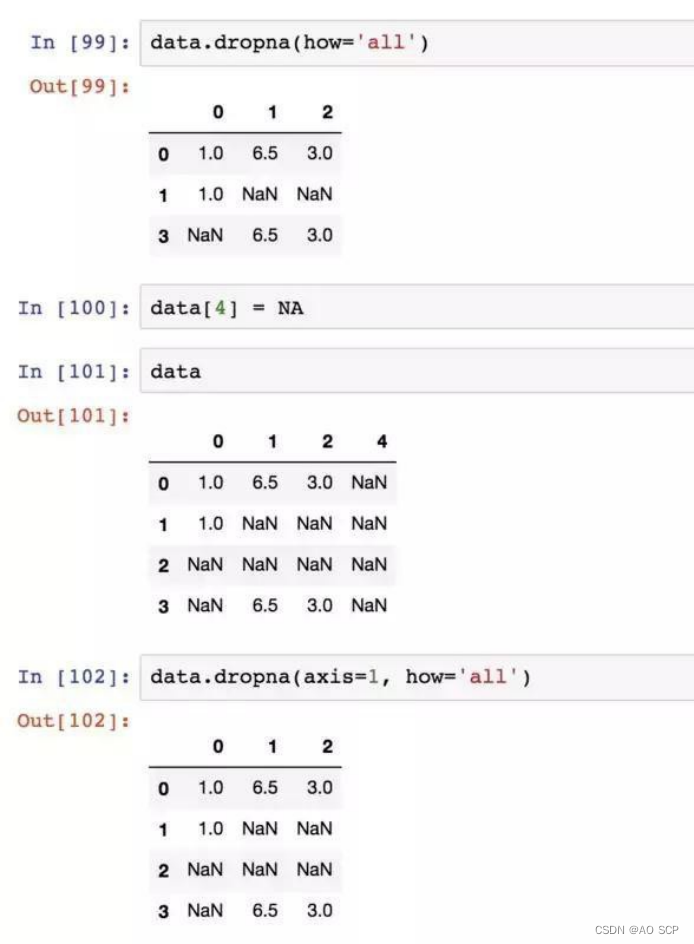
只想留下一部分参数,用 thresh 参数:
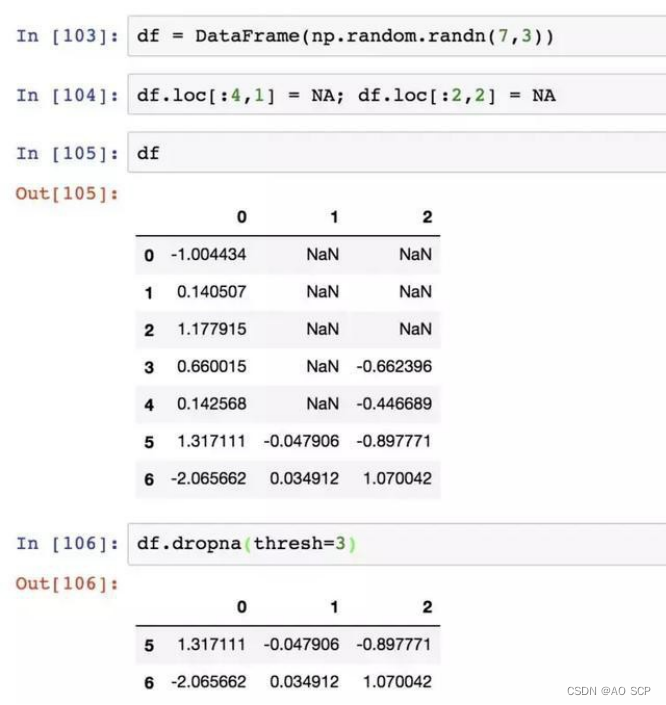
thresh=3:保留至少 3 个非空值的行,即一行中有 3 个值是非空的就保留.
2、填充缺失数据
fillna 方法:通过一个常数调用 fillna 就会将缺失值替换为那个常数值。
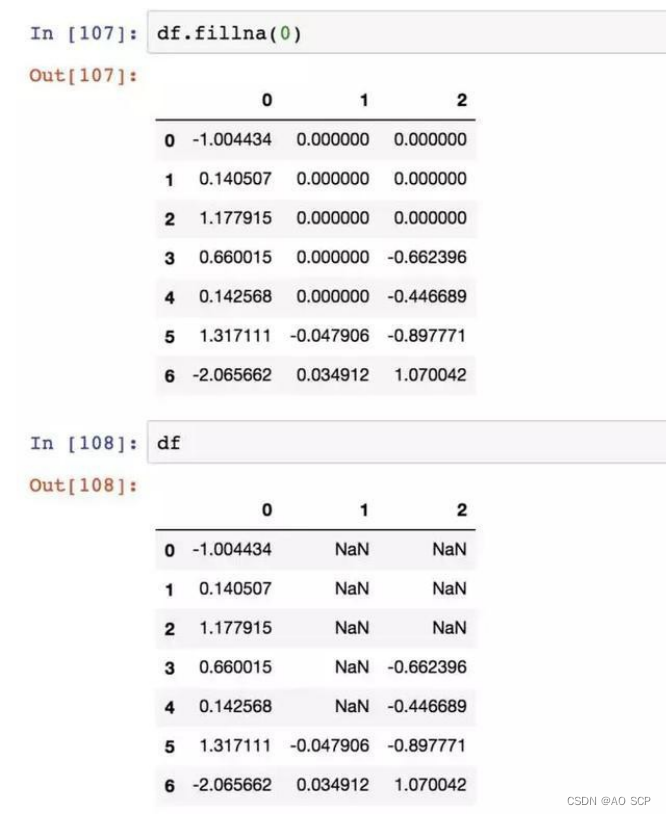
通过一个字典调用 fillna,可以实现对不同的列填充不同的值:
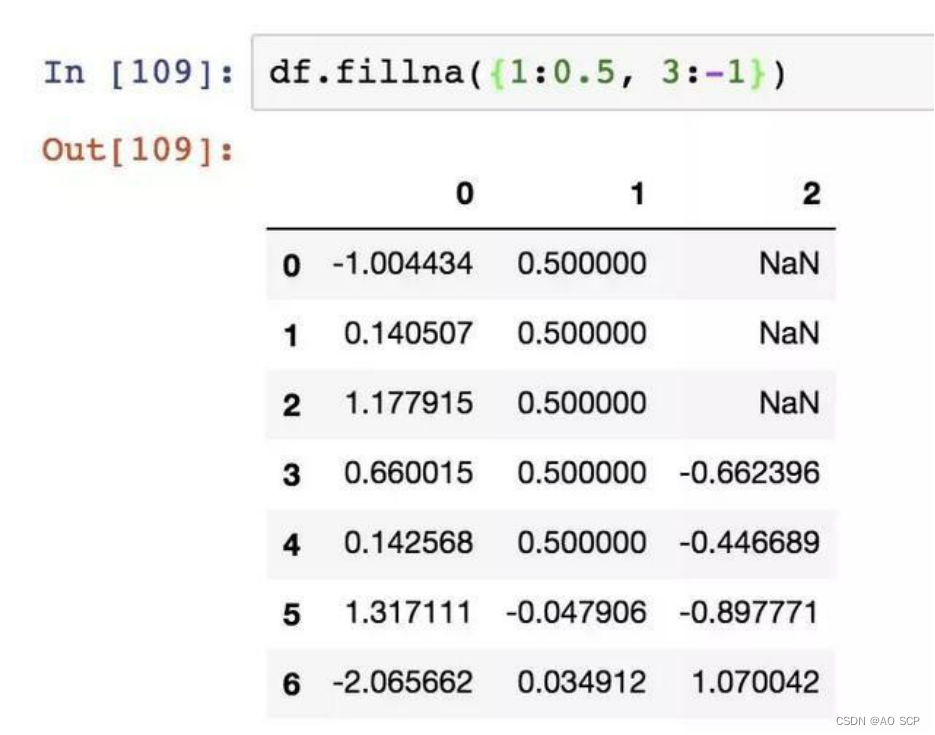
fillna 默认会返回新对象(副本),但也可以对现有对象进行就地修改:
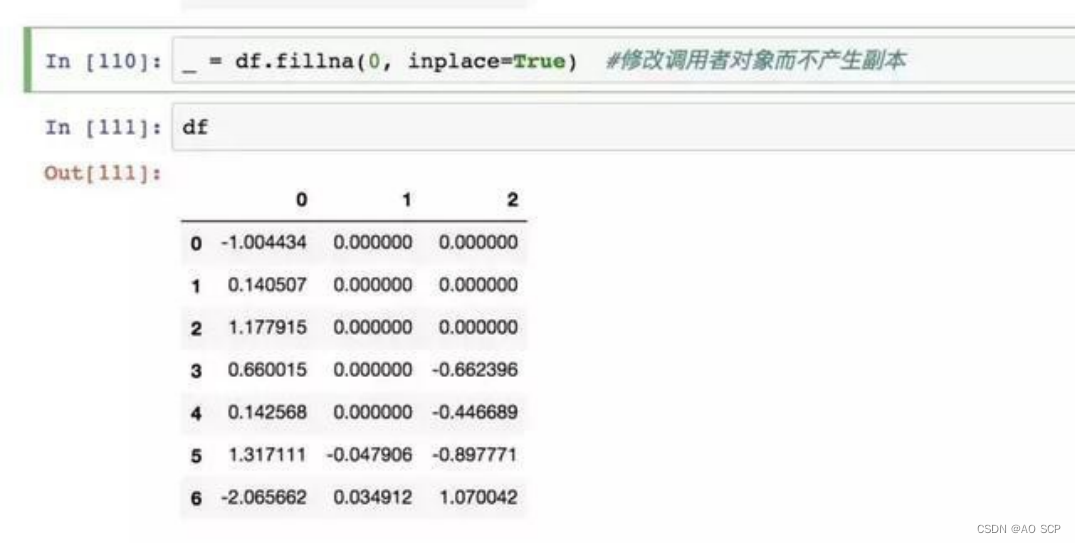
插值方法(对 reindx 有效的也可用于 fillna):
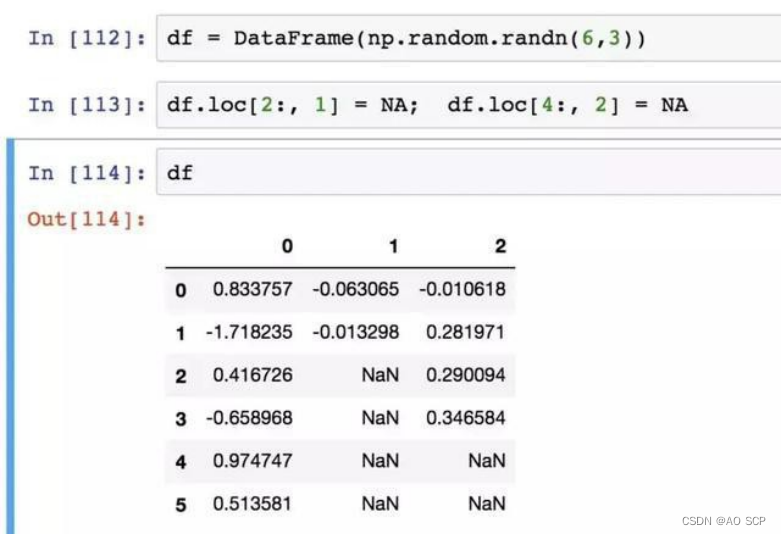
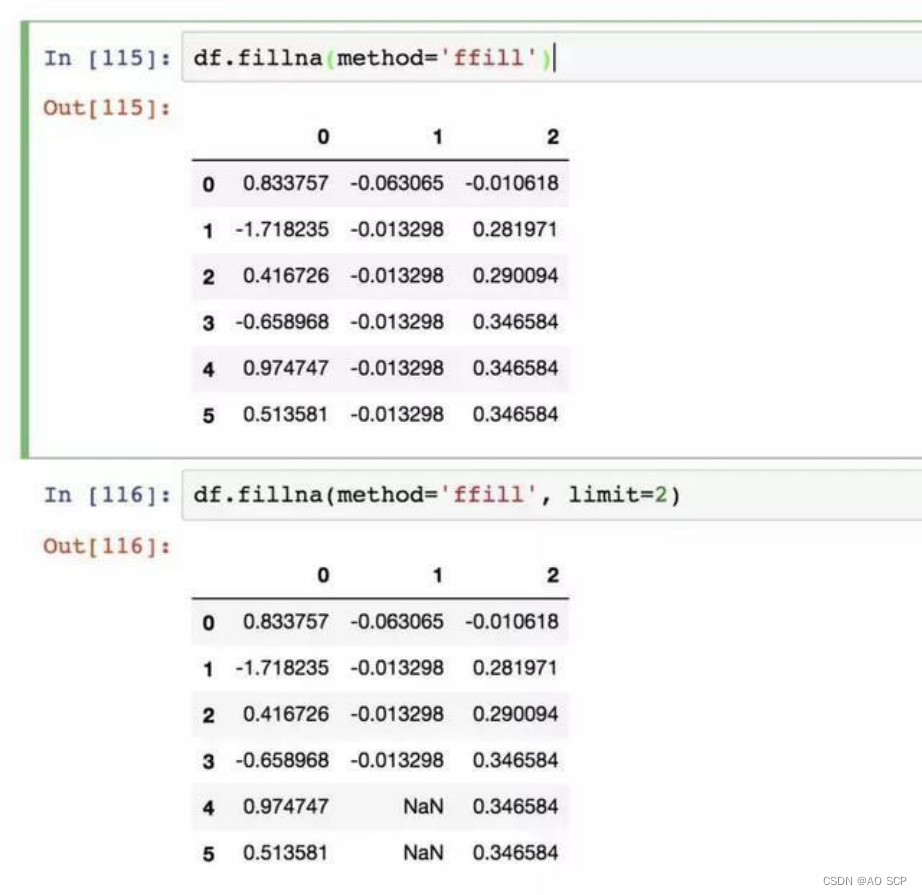
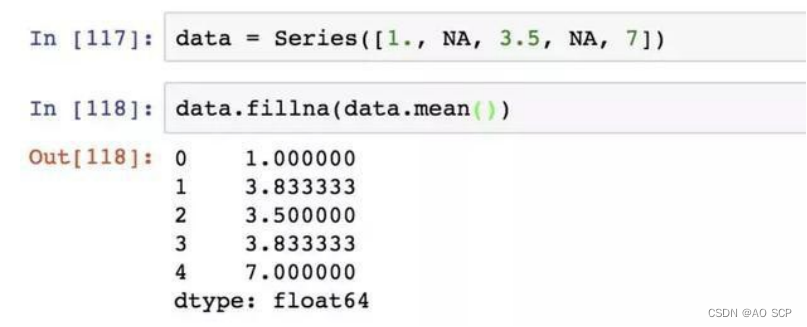
你可以用 fillna 实现许多别的功能,比如传入 Series 的平均值或中位数:
层次化索引
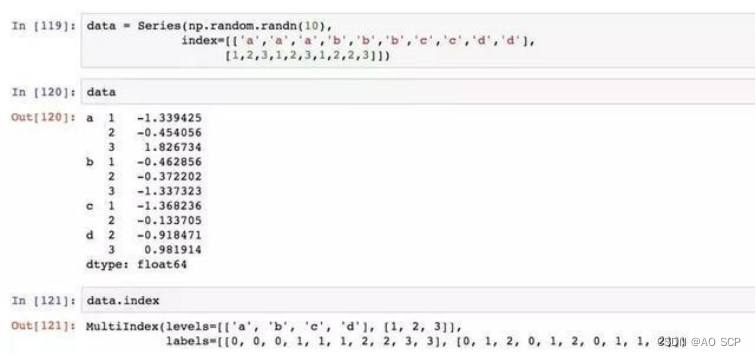
在一个轴上用多个(2 个以上)索引级别,即以低维度形式处理高维度数据。MultiIndex 索引的 Series 的格式化输出形式:
选取数据子集:
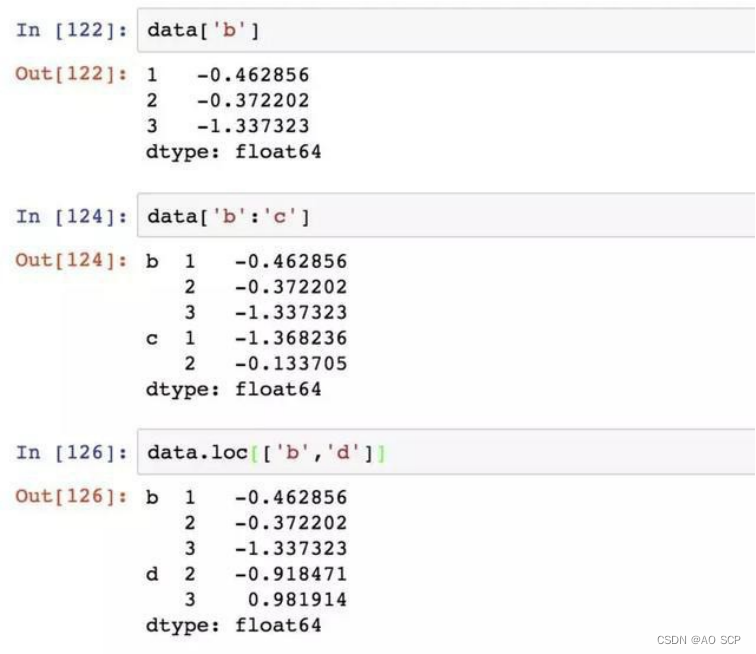
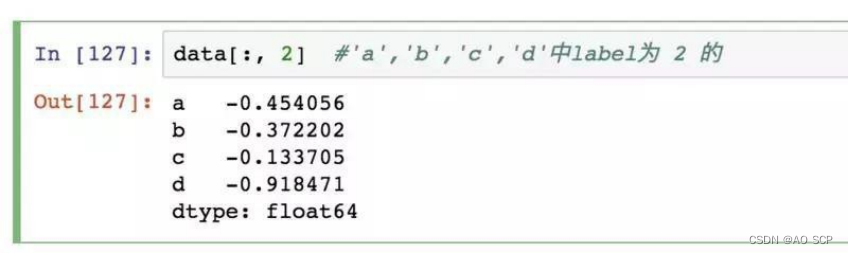
在“内层”中进行选取:
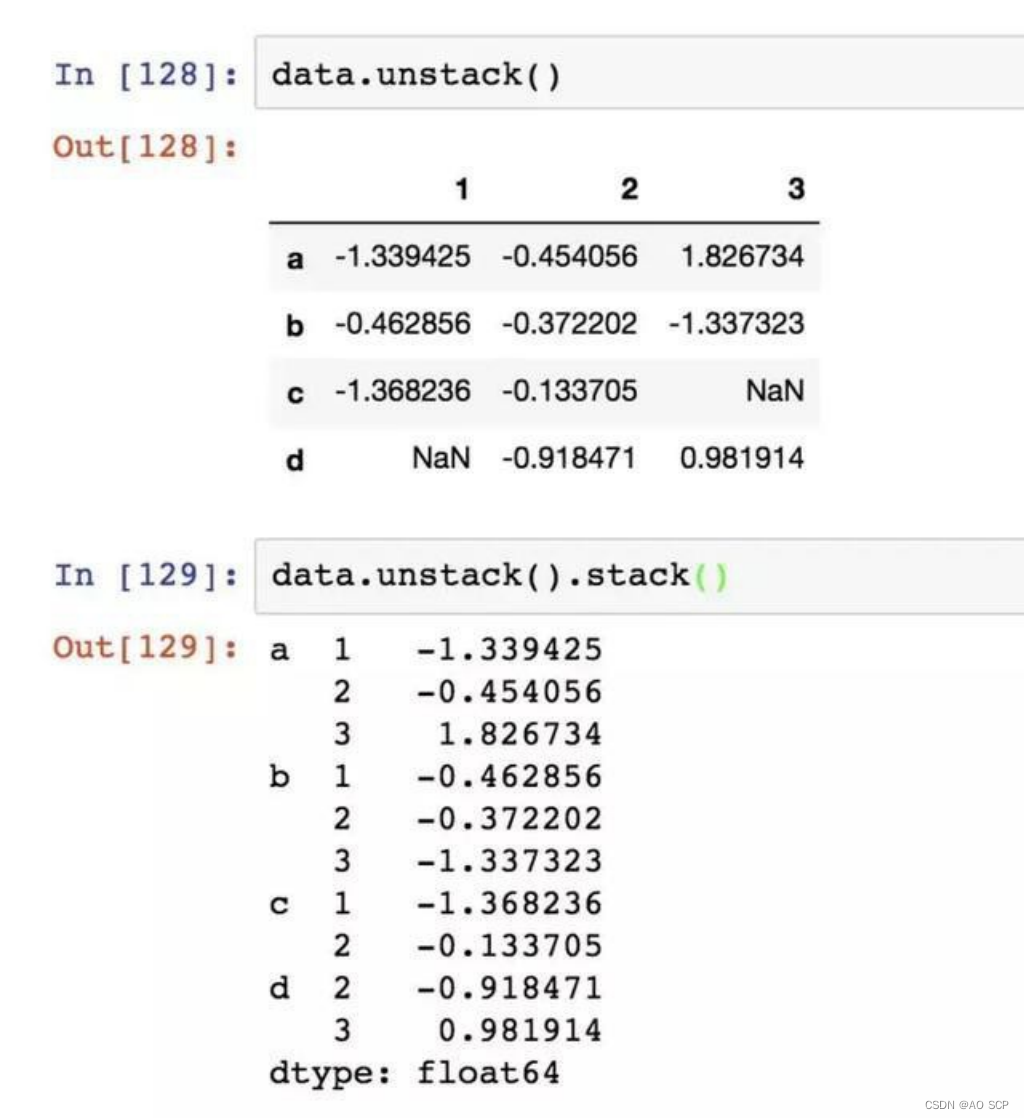
层次化索引在数据重塑和基于分组的操作中很重要。比如说,上面的数据可以通过其 unstack 方法被重新安排到一个 DataFrame 中,它的逆运算是 stack:
对于一个 DataFrame,每条轴都可以有分层索引:
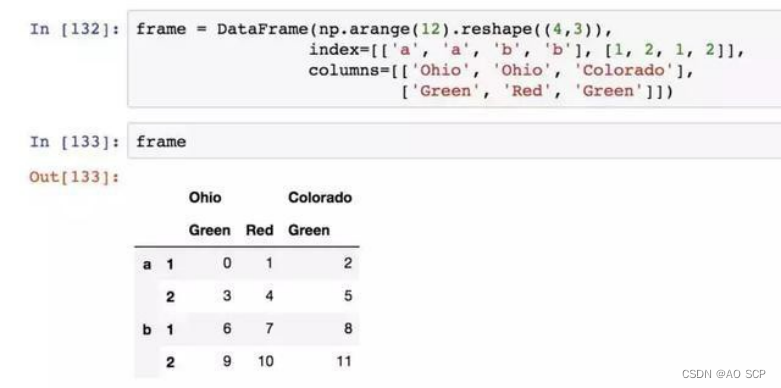
各层都可以有名字(可以是字符串,也可以是别的 Python 对象)。注意不要将索引名称跟轴标签混为一谈。
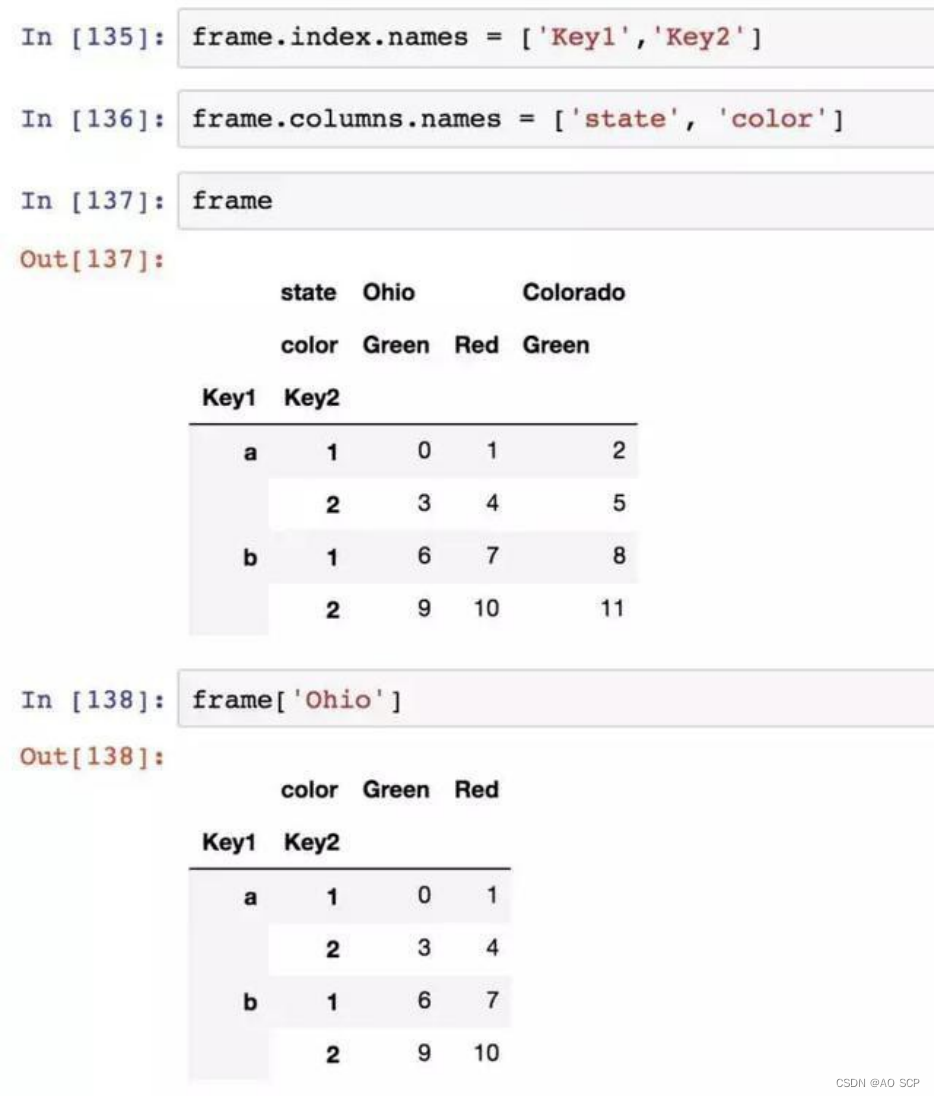
有了分部的列索引,可以轻松选取列分组。
可以单独创建 MultiIndex 然后复用。上面的 DataFrame 中的分级列可以这样创建:

1、重排分级顺序
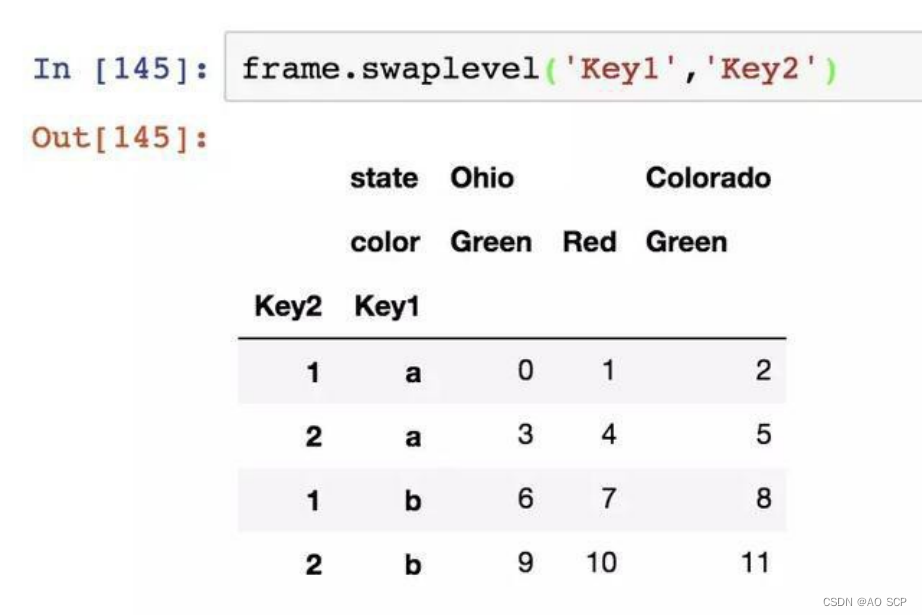
重新调整某条轴上各级别的顺序,或根据指定级别上的值对数据进行排序。
swaplevel:接受两个级别编号或名称,返回一个互换了级别的新对象,数据不发生改变: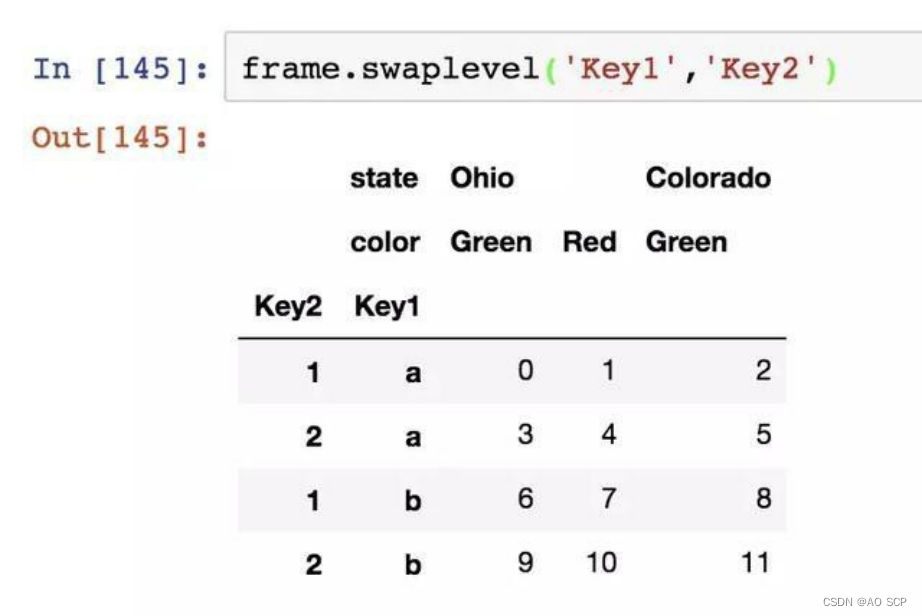
sortlevel:根据单个级别中的值对数据进行排序(得到的最终结果是有序的)
2、根据级别汇总统计
level 选项:用于指定在某条轴上求和的级别。
如下所示,分别根据行或列上的级别来对行、对列进行求和:

3、使用 DataFrame 的列
将DataFrame 的一个或多个列当做行索引来用,或将行索引变成DataFrame 的列:
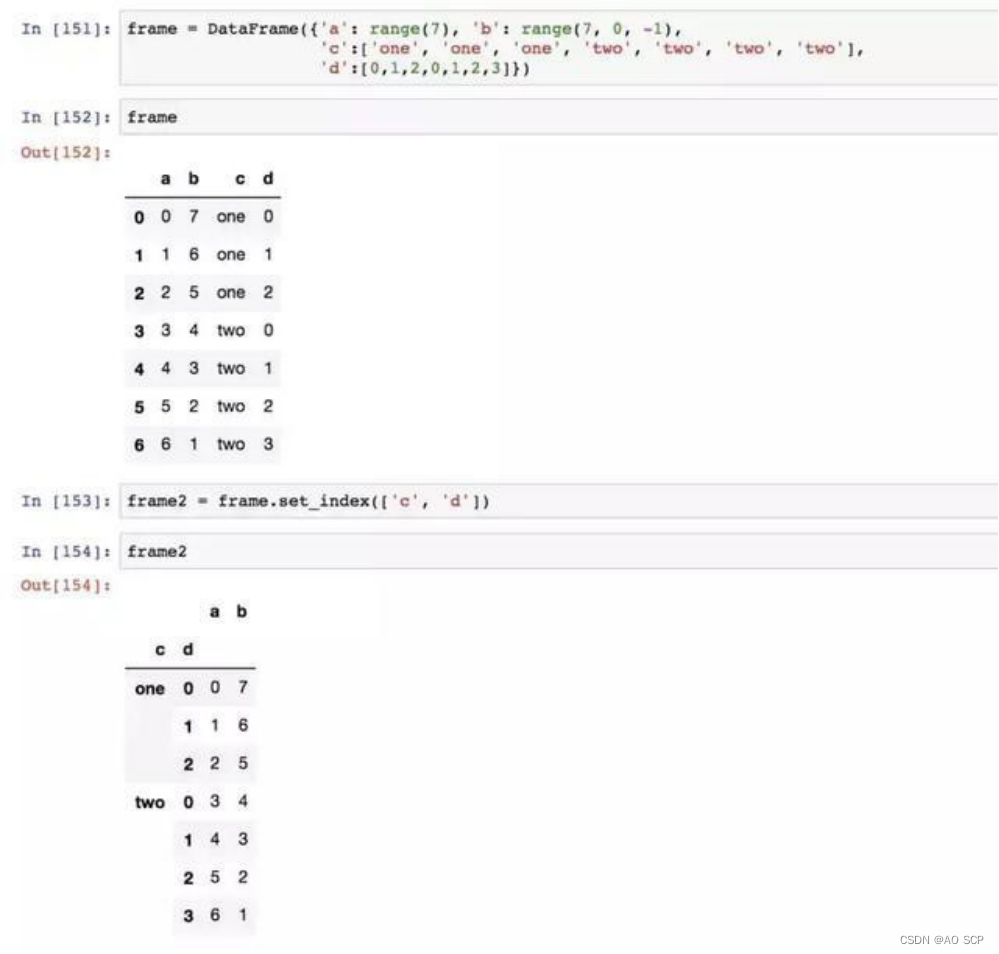
set_index 函数:将其一个或多个列转换为行索引,并创建一个新的 DataFrame。默认情况下,那些列会从 DataFrame 中移除,也可以将其保留下来:

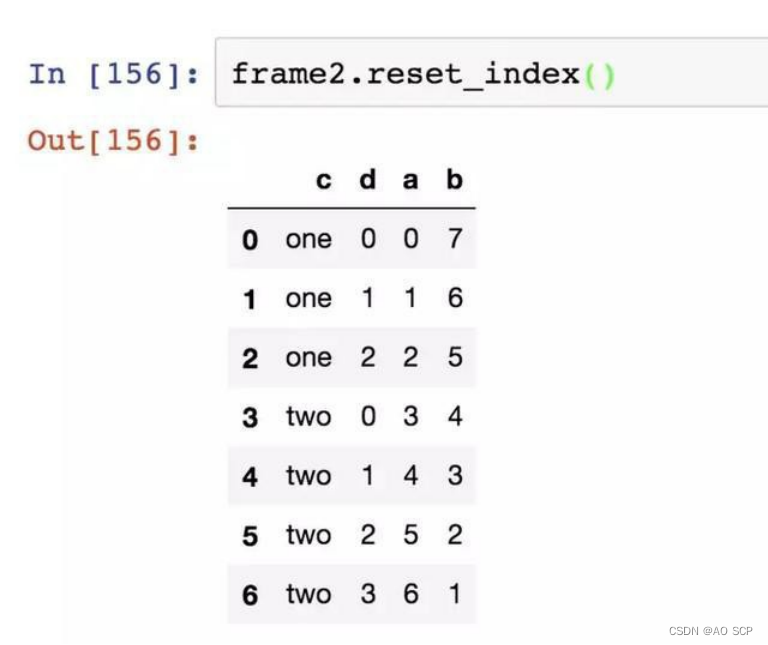
reset_index:将层次化索引的级别转移到列里面(和 set_index 相反)
不足之处,欢迎指正。
相关文章:
社畜大学生的Python之pandas学习笔记,保姆入门级教学
接上期,上篇介绍了 NumPy,本篇介绍 pandas。 目录 pandas 入门pandas 的数据结构介绍基本功能汇总和计算描述统计处理缺失数据层次化索引 pandas 入门 Pandas 是基于 Numpy 构建的,让以 NumPy 为中心的应用变的更加简单。 Pandas是基于Numpy…...
20_FreeRTOS低功耗模式
目录 低功耗模式简介 STM32低功耗模式 Tickless模式详解 Tickless模式相关配置 实验源码 低功耗模式简介 很多应用场合对于功耗的要求很严格,比如可穿戴低功耗产品、物联网低功耗产品等。 一般MCU都有相应的低功耗模式,裸机开发时可以使用MCU的低功耗模式。 FreeRTOS也…...

Hive的使用方式
操作Hive可以在Shell命令行下操作,或者是使用JDBC代码的方式操作 针对命令行这种方式,其实还有两种使用 第一个是使用bin目录下的hive命令,这个是从hive一开始就支持的使用方式 后来又出现一个beeline命令,它是通过HiveServer2服…...

Flume三大核心组件
Flume的三大核心组件: Source:数据源 Channel:临时存储数据的管道 Sink:目的地 Source:数据源:通过source组件可以指定让Flume读取哪里的数据,然后将数据传递给后面的 channel Flume内置支持读…...
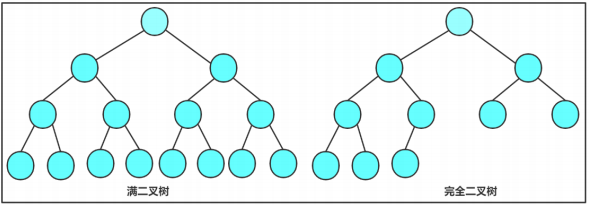
数据结构(六)二叉树
一、树形结构概念树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:1、有一个…...
Docker buildx 的跨平台编译
docker buildx 默认的 docker build 命令无法完成跨平台构建任务,我们需要为 docker 命令行安装 buildx 插件扩展其功能。buildx 能够使用由 Moby BuildKit 提供的构建镜像额外特性,它能够创建多个 builder 实例,在多个节点并行地执行构建任…...

【java基础】方法重载和方法重写
文章目录方法重载方法重写方法重载 方法重载就是可以在一个类里面定义多个相同名称的方法,只需要参数列表的个数或者类型不同就行。 public class Overload {public int add(int a, int b) {return a b;}public double add(double a, double b) {return a b;}}对…...
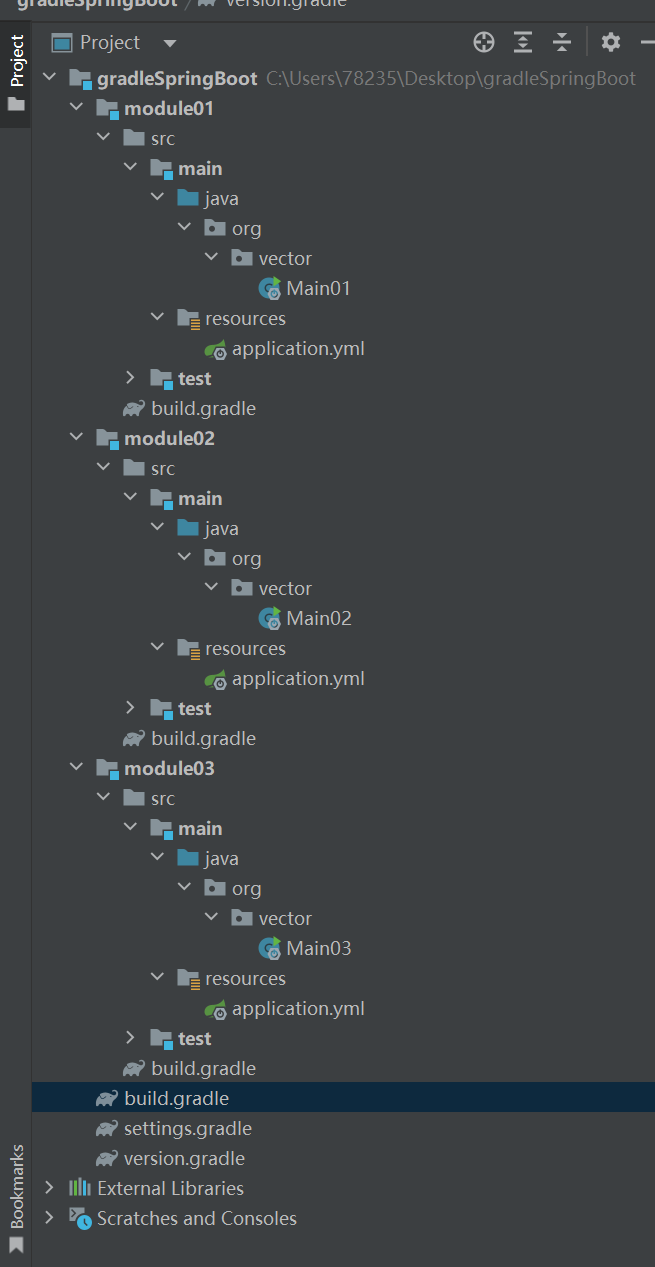
Gradle7.4安装与基本使用
文章目录一.前言二.下载Gradle三.Gradle镜像源-全局级配置四.配置Gradle wrapper-项目级配置五.Gradle对测试的支持五.生命周期5.1 settings文件六.Gradle任务入门6.1 任务行为6.2 任务依赖方式七. Dependencies依赖引入7.1 依赖冲突及解决方案八.Gradle整合多模块SpringBoot九…...

[系统安全] 虚拟化安全之虚拟化概述
本文为笔者从零基础学习系统安全相关内容的笔记,如果您对系统安全、逆向分析等内容感兴趣或者想要了解一些内容,欢迎关注。本系列文章将会随着笔者在未来三年的读研过程中持续更新,由于笔者现阶段还处于初学阶段,不可避免参照复现各类书籍内容,如书籍作者认为侵权请告知,…...

如何从零开始系统的学习项目管理?
经常会有人问,项目管理到底应该学习一些什么?学习考证之后能得到什么价值? 以下我就总结一下内容 一,学习项目管理有用吗? 有效的项目管理带来的益处大致包括以下几个方面:更有效达成业务目标、满足相关…...

面试题-----
面试题---- 一.HTML 1.常用哪些浏览器进行测试,对应有哪些内核? ①IE------------------->Trident ②Chrome---------->以前是Webkit现在是Blink ③Firefox------------>Gecko ④Safari-------------->Webkit ⑤Opera--------------&…...
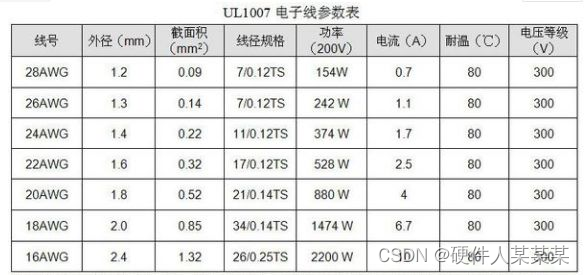
线材-电子线载流能力
今天来讲的是关于电子线的一个小知识,可能只做板子的工程师遇到此方面的问题会比较少,做整机的工程师则必然会遇到此方面问题,那就是线材问题。 下面主要说下电子线的过电流能力。(文末有工具下载)电子线(h…...
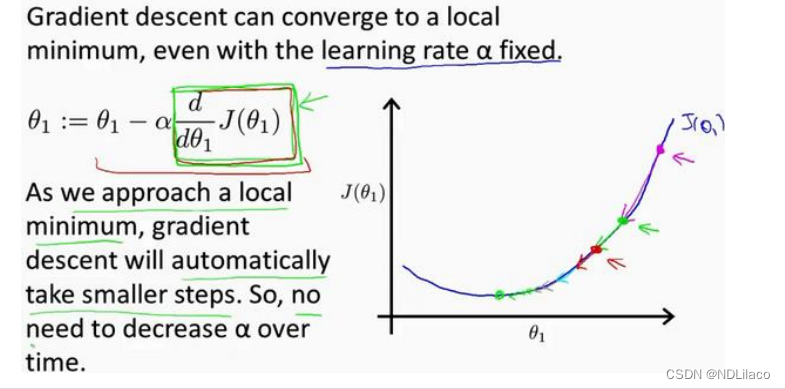
单变量回归问题
单变量回归问题 对于某房价问题,x为房屋大小,h即为预估房价,模型公式为: hθ(x)θ0θ1xh_{\theta}(x)\theta_{0}\theta_{1}x hθ(x)θ0θ1x 要利用训练集拟合该公式(主要是计算θ0、θ1\theta_{0}、\theta_{1}θ…...
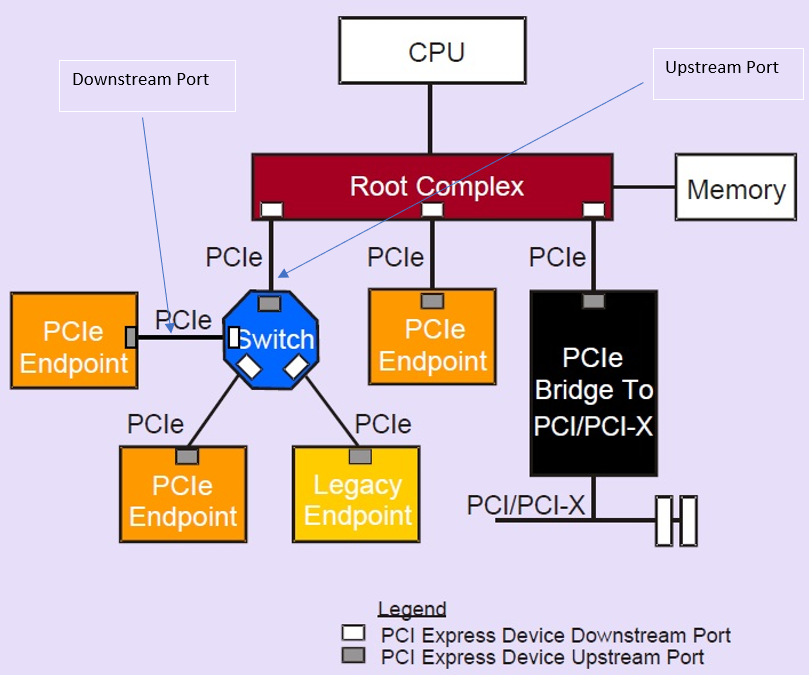
ubuntu/linux系统知识(36)linux网卡命名规则
文章目录背景命名规范系统默认命名规则优势背景 很久以前Linux 操作系统的网卡设备的传统命名方式是 eth0、eth1、eth2等,属于biosdevname 命名规范。 服务器通常有多块网卡,有板载集成的,同时也有插在PCIe插槽的。Linux系统的命名原来是et…...
java的一些冷知识
接口并没有继承Object类首先接口是一种特殊的类,理由就是将其编译后是一个class文件大家都知道java类都继承自Object,但是接口其实是并没有继承Object类的 可以自己写代码测试: 获取接口类的class对象后遍历它的methods,可以发现是不存在Obje…...

java代理模式
代理模式 为什么要学习代理模式?因为这是SpringAOP的底层! 【SpringAOP和SpingMVC}】 代理模式的分类: 静态代理 动态代理 代理就像这里的中介,帮助你去做向房东租房,你不能直接解出房东,而房东和中介…...
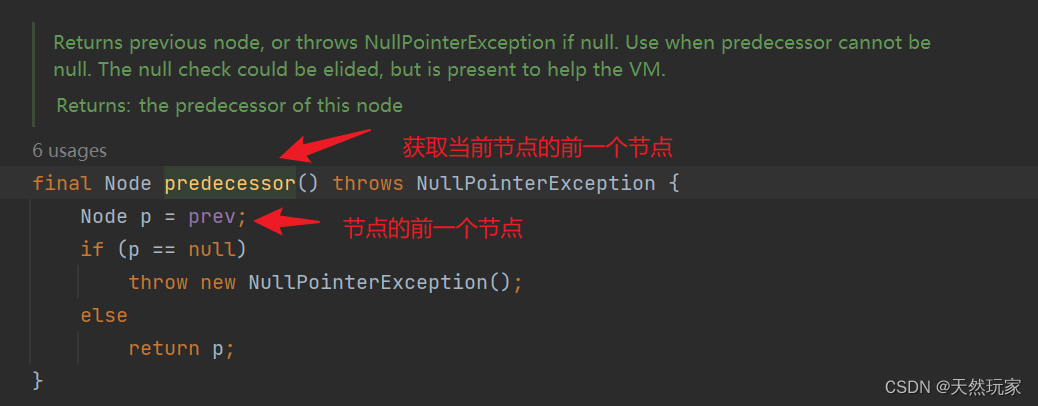
JUC包:CountDownLatch源码+实例讲解
1 缘起 有一次听到同事谈及AQS时,我有很多点懵, 只知道入队和出队,CLH(Craig,Landin and Hagersten)锁,并不了解AQS的应用, 同时结合之前遇到的多线程等待应用场景,发现…...

Log4j2基本使用
文章目录1. Log4j2入门2. Log4j2配置3. Log4j2异步日志4. Log4j2的性能Apache Log4j 2是对Log4j的升级版,参考了logback的一些优秀的设计,并且修复了一些问题,因此带 来了一些重大的提升,主要有: 异常处理,…...

A2L在CAN FD总线的使用
文章目录 前言CAN时间参数BTL CyclesTime Quantum时间份额SWJ同步跳转宽度波特率计算采样点计算CAN FD的第二采样点SSP推荐配置A2L配置总结前言 A2L作为XCP标定协议的载体,包括了总线信息的定义。本文介绍如何将基于CAN总线的A2L扩展为支持CAN-FD的A2L CAN时间参数 在介绍配…...

Android JetPack之启动优化StartUp初始化组件的详解和使用
一、背景 先看一下Android系统架构图 在Android设备中,设备先通电(PowerManager),然后加载内核层,内核走完,开始检查硬件,以及为硬件提供的公开接口,然后进入到库的加载。库挂载后开…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...