车道线检测CondLaneNet论文和源码解读
CondLaneNet: a Top-to-down Lane Detection Framework Based on Conditional Convolution
Paper:https://arxiv.org/pdf/2105.05003.pdf
code:GitHub - aliyun/conditional-lane-detection
论文解读:
一、摘要

这项工作作为车道线检测任务,比较新颖的是检测头head。并不同于常规的基于bbox进行目标检测,这项工作采用的是检测关键点构造mask,输出形式类似instance segmentation。
二、网络结构

- backbone采用的是普通的CNN,比如ResNet;
- neck采用的是TransformerFPN,实际上就是考虑到车道线比较长,需要全局注意力,因此就在基础FPN构造金字塔之前对backbone输出的feature进行了Transformer的self-attention操作

- head分为两部分:
- Proposal head用于检测车道线实例,并为每个实例生成动态的卷积核参数;
- Conditional shape head利用Proposal head步骤生成的动态卷积核参数和conditional卷积确定车道线的point set。然后根据这些point set进行连线得到最后的车道线结果。
代码解析:
代码基于mmdetection框架(v2.0.0)开发。在config/condlanenet/里可以看到有三个文件夹,分别对应作者在三个数据集CurveLanes、CULane、TuSimple上的配置。它们之间最大的区别在于针对CurveLanes设计了RIM。下面我重点分析一下它们共同的一些模块:
backbone
采用的是resnet,根据模型的大小可能选择resnet18到resnet101不等
neck
这里采用的是TransConvFPN,在mmdet/models/necks/trans_fpn.py
跟FPN不同点主要在于多了个transformer操作。动机是觉得车道线比较细长,需要有self-attention这样non-local的结构。
也就是在resnet和FPN的中间多了一个transformer模块。
## TransConvFPN 不重要的代码部分已省略def forward(self, src):assert len(src) >= len(self.in_channels)src = list(src)if self.attention:trans_feat = self.trans_head(src[self.trans_idx])else:trans_feat = src[self.trans_idx]inputs = src[:-1]inputs.append(trans_feat)if len(inputs) > len(self.in_channels):for _ in range(len(inputs) - len(self.in_channels)):del inputs[0]## 下面内容跟FPN一致# build lateralslaterals = [lateral_conv(inputs[i + self.start_level])for i, lateral_conv in enumerate(self.lateral_convs)]## 省略 ## 在TransConvFPN的__init__里
if self.attention:self.trans_head = TransConvEncoderModule(**trans_cfg)class TransConvEncoderModule(nn.Module):def __init__(self, in_dim, attn_in_dims, attn_out_dims, strides, ratios, downscale=True, pos_shape=None):super(TransConvEncoderModule, self).__init__()if downscale:stride = 2else:stride = 1# self.first_conv = ConvModule(in_dim, 2*in_dim, kernel_size=3, stride=stride, padding=1)# self.final_conv = ConvModule(attn_out_dims[-1], attn_out_dims[-1], kernel_size=3, stride=1, padding=1)attn_layers = []for dim1, dim2, stride, ratio in zip(attn_in_dims, attn_out_dims, strides, ratios):attn_layers.append(AttentionLayer(dim1, dim2, ratio, stride))if pos_shape is not None:self.attn_layers = nn.ModuleList(attn_layers)else:self.attn_layers = nn.Sequential(*attn_layers)self.pos_shape = pos_shapeself.pos_embeds = []if pos_shape is not None:for dim in attn_out_dims:pos_embed = build_position_encoding(dim, pos_shape).cuda()self.pos_embeds.append(pos_embed)def forward(self, src):# src = self.first_conv(src)if self.pos_shape is None:src = self.attn_layers(src)else:for layer, pos in zip(self.attn_layers, self.pos_embeds):src = layer(src, pos.to(src.device))# src = self.final_conv(src)return srcclass AttentionLayer(nn.Module):""" Position attention module"""def __init__(self, in_dim, out_dim, ratio=4, stride=1):super(AttentionLayer, self).__init__()self.chanel_in = in_dimnorm_cfg = dict(type='BN', requires_grad=True)act_cfg = dict(type='ReLU')self.pre_conv = ConvModule(in_dim,out_dim,kernel_size=3,stride=stride,padding=1,norm_cfg=norm_cfg,act_cfg=act_cfg,inplace=False)self.query_conv = nn.Conv2d(in_channels=out_dim, out_channels=out_dim // ratio, kernel_size=1)self.key_conv = nn.Conv2d(in_channels=out_dim, out_channels=out_dim // ratio, kernel_size=1)self.value_conv = nn.Conv2d(in_channels=out_dim, out_channels=out_dim, kernel_size=1)self.final_conv = ConvModule(out_dim,out_dim,kernel_size=3,padding=1,norm_cfg=norm_cfg,act_cfg=act_cfg)self.softmax = nn.Softmax(dim=-1)self.gamma = nn.Parameter(torch.zeros(1))def forward(self, x, pos=None):"""inputs :x : inpput feature maps( B X C X H X W)returns :out : attention value + input featureattention: B X (HxW) X (HxW)"""x = self.pre_conv(x)m_batchsize, _, height, width = x.size()if pos is not None:x += posproj_query = self.query_conv(x).view(m_batchsize, -1,width * height).permute(0, 2, 1)proj_key = self.key_conv(x).view(m_batchsize, -1, width * height)energy = torch.bmm(proj_query, proj_key)attention = self.softmax(energy)attention = attention.permute(0, 2, 1)proj_value = self.value_conv(x).view(m_batchsize, -1, width * height)out = torch.bmm(proj_value, attention)out = out.view(m_batchsize, -1, height, width)proj_value = proj_value.view(m_batchsize, -1, height, width)out_feat = self.gamma * out + xout_feat = self.final_conv(out_feat)return out_feathead
用的是CondLaneHead,在mmdet/models/dense_heads/condlanenet_head.py
需要重点分析,跟一般的检测任务差别很大:
首先这个CondLaneHead类的forward方法是直接调用了forward_test,因此要从model去看到neck输出后具体调用的是head的什么函数
# mmdet/models/detectors/condlanenet.pydef forward(self, img, img_metas=None, return_loss=True, **kwargs):...if img_metas is None:return self.test_inference(img)elif return_loss:return self.forward_train(img, img_metas, **kwargs)else:return self.forward_test(img, img_metas, **kwargs)def forward_train(self, img, img_metas, **kwargs):...if self.head:outputs = self.bbox_head.forward_train(output, poses, num_ins)...def forward_test(self,img,img_metas,benchmark=False,hack_seeds=None,**kwargs):...if self.head:seeds, hm = self.bbox_head.forward_test(output, hack_seeds,kwargs['thr'])...所以实际上head的forward是没用到的,直接去看head的forward_train和forward_test就行
forward_train
# mmdet/models/dense_heads/condlanenet_head.pydef forward_train(self, inputs, pos, num_ins):# x_list是backbone+neck输出后的multi level feature mapx_list = list(inputs)# 这里根据hm_idx参数来取某个level 的feature map,用它去生成heat_map# mask同理f_hm = x_list[self.hm_idx]f_mask = x_list[self.mask_idx]m_batchsize = f_hm.size()[0]# f_maskz = self.ctnet_head(f_hm)hm, params = z['hm'], z['params']h_hm, w_hm = hm.size()[2:]h_mask, w_mask = f_mask.size()[2:]params = params.view(m_batchsize, self.num_classes, -1, h_hm, w_hm)mask_branch = self.mask_branch(f_mask)reg_branch = mask_branch# reg_branch = self.reg_branch(f_mask)params = params.permute(0, 1, 3, 4,2).contiguous().view(-1, self.num_gen_params)pos_tensor = torch.from_numpy(np.array(pos)).long().to(params.device).unsqueeze(1)pos_tensor = pos_tensor.expand(-1, self.num_gen_params)mask_pos_tensor = pos_tensor[:, :self.num_mask_params]reg_pos_tensor = pos_tensor[:, self.num_mask_params:]if pos_tensor.size()[0] == 0:masks = Nonefeat_range = Noneelse:mask_params = params[:, :self.num_mask_params].gather(0, mask_pos_tensor)masks = self.mask_head(mask_branch, mask_params, num_ins)if self.regression:reg_params = params[:, self.num_mask_params:].gather(0, reg_pos_tensor)regs = self.reg_head(reg_branch, reg_params, num_ins)else:regs = masks# regs = regs.view(sum(num_ins), 1, h_mask, w_mask)feat_range = masks.permute(0, 1, 3,2).view(sum(num_ins), w_mask, h_mask)feat_range = self.mlp(feat_range)return hm, regs, masks, feat_range, [mask_branch, reg_branch]forward_test
# mmdet/models/dense_heads/condlanenet_head.pydef forward_test(self,inputs,hack_seeds=None,hm_thr=0.3,):def parse_pos(seeds, batchsize, num_classes, h, w, device):pos_list = [[p['coord'], p['id_class'] - 1] for p in seeds]poses = []for p in pos_list:[c, r], label = ppos = label * h * w + r * w + cposes.append(pos)poses = torch.from_numpy(np.array(poses, np.long)).long().to(device).unsqueeze(1)return poses# with Timer("Elapsed time in stage1: %f"): # ignorex_list = list(inputs)f_hm = x_list[self.hm_idx]f_mask = x_list[self.mask_idx]m_batchsize = f_hm.size()[0]f_deep = f_maskm_batchsize = f_deep.size()[0]# with Timer("Elapsed time in ctnet_head: %f"): # 0.3msz = self.ctnet_head(f_hm)h_hm, w_hm = f_hm.size()[2:]h_mask, w_mask = f_mask.size()[2:]hm, params = z['hm'], z['params']hm = torch.clamp(hm.sigmoid(), min=1e-4, max=1 - 1e-4)params = params.view(m_batchsize, self.num_classes, -1, h_hm, w_hm)# with Timer("Elapsed time in two branch: %f"): # 0.6msmask_branch = self.mask_branch(f_mask)reg_branch = mask_branch# reg_branch = self.reg_branch(f_mask)params = params.permute(0, 1, 3, 4,2).contiguous().view(-1, self.num_gen_params)batch_size, num_classes, h, w = hm.size()# with Timer("Elapsed time in ct decode: %f"): # 0.2msseeds = self.ctdet_decode(hm, thr=hm_thr)if hack_seeds is not None:seeds = hack_seeds# with Timer("Elapsed time in stage2: %f"): # 0.08mspos_tensor = parse_pos(seeds, batch_size, num_classes, h, w, hm.device)pos_tensor = pos_tensor.expand(-1, self.num_gen_params)num_ins = [pos_tensor.size()[0]]mask_pos_tensor = pos_tensor[:, :self.num_mask_params]if self.regression:reg_pos_tensor = pos_tensor[:, self.num_mask_params:]# with Timer("Elapsed time in stage3: %f"): # 0.8msif pos_tensor.size()[0] == 0:return [], hmelse:mask_params = params[:, :self.num_mask_params].gather(0, mask_pos_tensor)# with Timer("Elapsed time in mask_head: %f"): #0.3msmasks = self.mask_head(mask_branch, mask_params, num_ins)if self.regression:reg_params = params[:, self.num_mask_params:].gather(0, reg_pos_tensor)# with Timer("Elapsed time in reg_head: %f"): # 0.25msregs = self.reg_head(reg_branch, reg_params, num_ins)else:regs = masksfeat_range = masks.permute(0, 1, 3,2).view(sum(num_ins), w_mask, h_mask)feat_range = self.mlp(feat_range)for i in range(len(seeds)):seeds[i]['reg'] = regs[0, i:i + 1, :, :]m = masks[0, i:i + 1, :, :]seeds[i]['mask'] = mseeds[i]['range'] = feat_range[i:i + 1]return seeds, hm可以发现,这部分的操作跟论文中描述的差不多。
(等我具体有时间再慢慢弄来看,最近很忙)
相关文章:
车道线检测CondLaneNet论文和源码解读
CondLaneNet: a Top-to-down Lane Detection Framework Based on Conditional Convolution Paper:https://arxiv.org/pdf/2105.05003.pdf code:GitHub - aliyun/conditional-lane-detection 论文解读: 一、摘要 这项工作作为车道线检测任…...

vue3的插槽slots
文章目录普通插槽Test.vueFancyButton.vue具名插槽Test.vueBaseLayout.vue作用域插槽默认插槽Test.vueBaseLayout.vue具名作用域插槽Test.vueBaseLayout.vue普通插槽 父组件使用子组件时,在子组件闭合标签中提供内容模板,插入到子组件定义的出口的地方 …...

docker学校服务器管理
docker 学校服务器管理使用docker,docker使用go语言编写。对于docker的理解,需要知道几个关键字docker, scp,images, container。 docker-码头工人scp-传输命令images/repository-镜像container-容器 docker是码头工人,scp相当…...
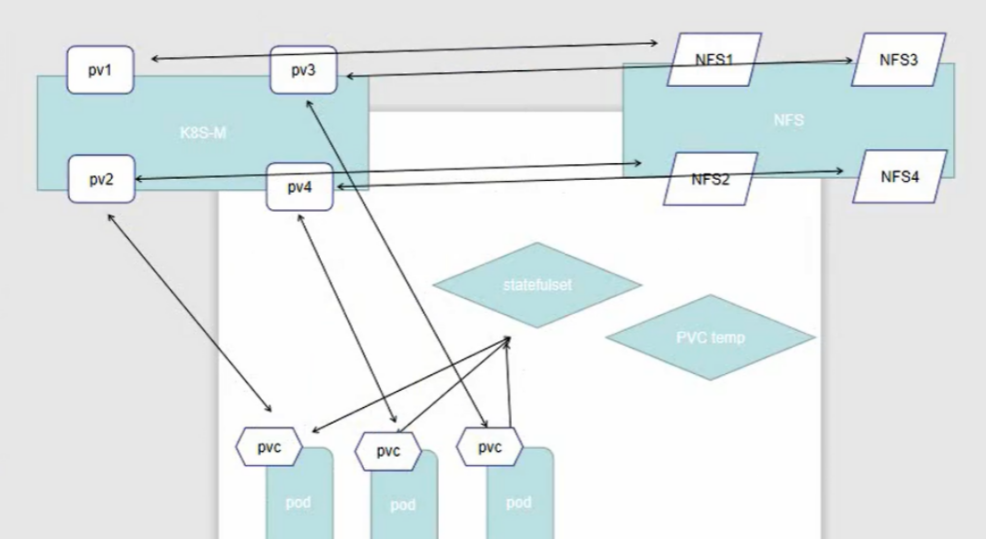
pv和pvc
一、PV和PVC详解当前,存储的方式和种类有很多,并且各种存储的参数也需要非常专业的技术人员才能够了解。在Kubernetes集群中,放了方便我们的使用和管理,Kubernetes提出了PV和PVC的概念,这样Kubernetes集群的管理人员就…...

k8s篇之Pod 干预与 PDB
文章目录自愿干预和非自愿干预PDBPDB 示例分离集群所有者和应用程序所有者角色如何在集群上执行中断操作自愿干预和非自愿干预 Pod 不会消失,除非有人(用户或控制器)将其销毁,或者出现了不可避免的硬件或软件系统错误。 我们把这…...
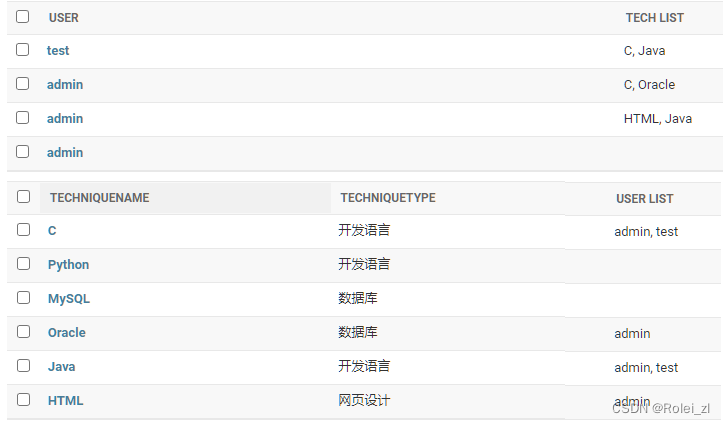
Django学习17 -- ManytoManyField
1. ManyToManyField (参考:Django Documentation Release 4.1.4) 类定义 class ManyToManyField(to, **options)使用说明 A many-to-many relationship. Requires a positional argument: the class to which the model is related, which w…...

既然有MySQL了,为什么还要有Redis?
目录专栏导读一、同样是缓存,用map不行吗?二、Redis为什么是单线程的?三、Redis真的是单线程的吗?四、Redis优缺点1、优点2、缺点五、Redis常见业务场景六、Redis常见数据类型1、String2、List3、Hash4、Set5、Zset6、BitMap7、Bi…...
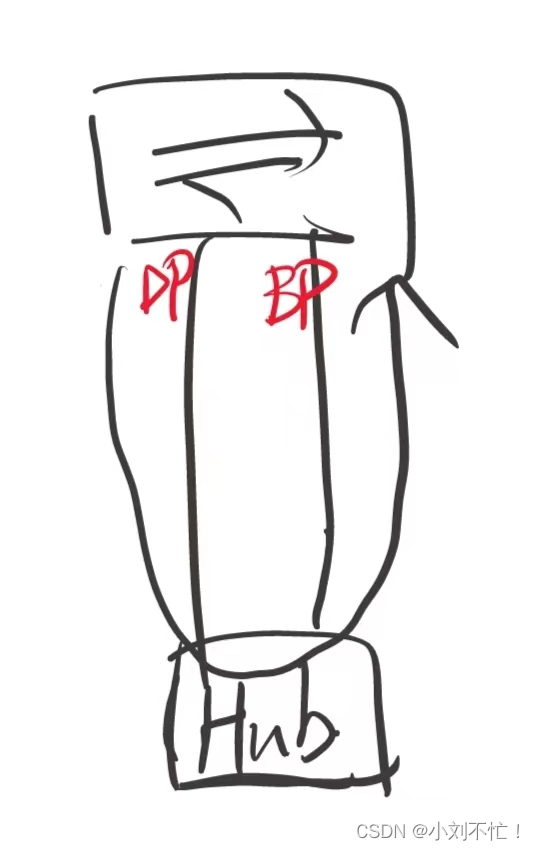
RSTP基础要点(上)
RSTP基础RSTP引入背景STP所存在的问题RSTP对于STP的改进端口角色重新划分端口状态重新划分快速收敛机制:PA机制端口快速切换边缘端口的引入RSTP引入背景 STP协议虽然能够解决环路问题,但是由于网络拓扑收敛较慢,影响了用户通信质量ÿ…...
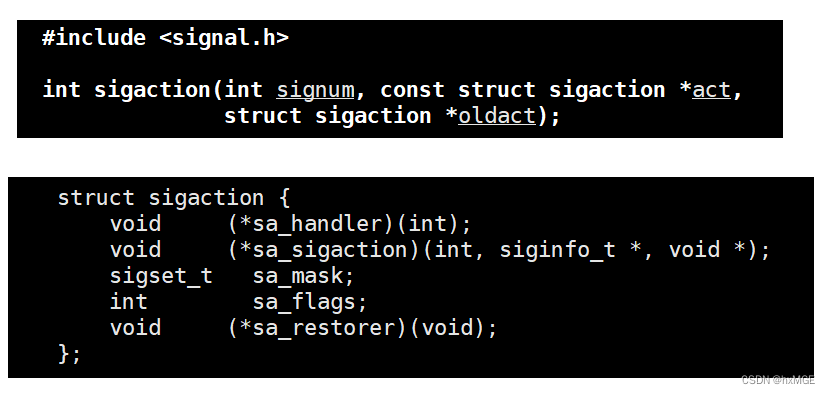
Linux操作系统学习(信号处理)
文章目录进程信号信号的产生方式(信号产生前)1. 硬件产生2.调用系统函数向进程发信号3.软件产生4.定位进程崩溃的代码(进程异常退出产生信号)信号保存的方式(信号产生中)获取pending表&&修改block表…...
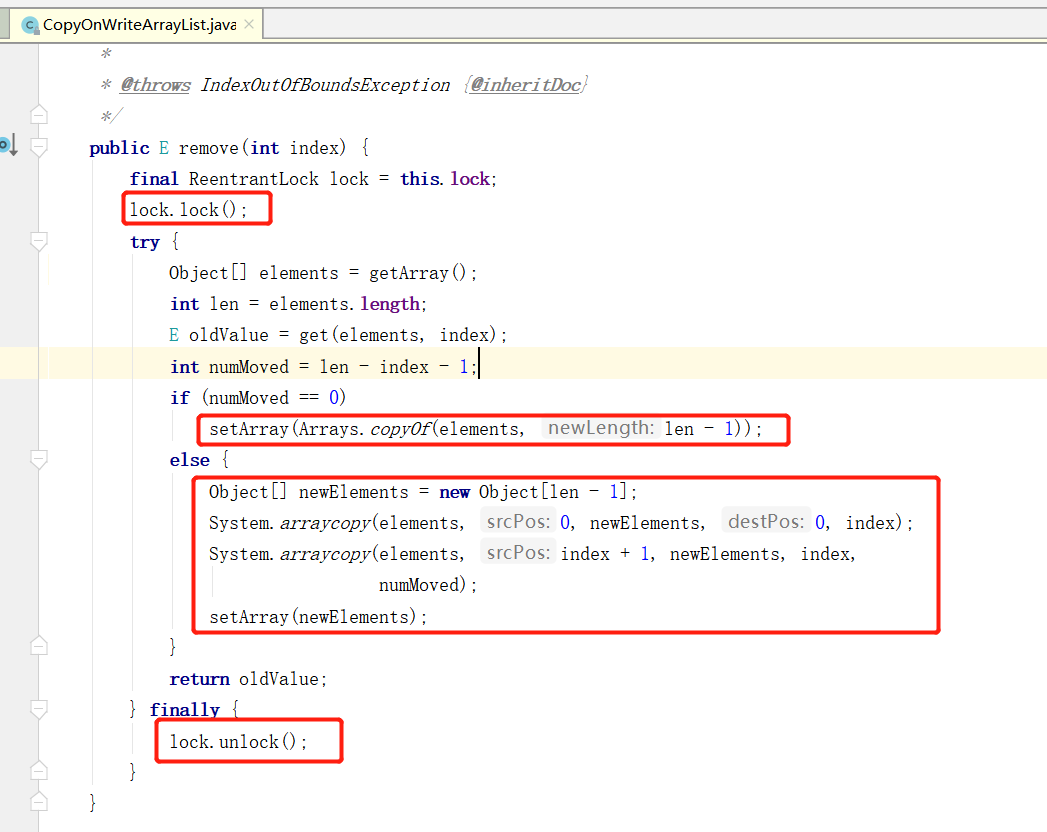
CopyOnWriteArrayList 源码解读
一、CopyOnWriteArrayList 源码解读 在 JUC 中,对于 ArrayList 的线程安全用法,比较推崇于使用 CopyOnWriteArrayList ,那 CopyOnWriteArrayList是怎么解决线程安全问题的呢,本文带领大家一起解读下 CopyOnWriteArrayList 的源码…...

方法
方法方法(函数)一、课前问答二、方法和函数三、方法的参数3.1 单个参数3.2 多个参数四、方法的返回值五、方法的多级调用六、递归方法(函数) 一、课前问答 1、break和continue的区别 2、嵌套循环的执行流程 3、二进制有哪些运算&…...
C/C++实现发送邮件功能(附源码)
C++常用功能源码系列 本文是C/C++常用功能代码封装专栏的导航贴。部分来源于实战项目中的部分功能提炼,希望能够达到你在自己的项目中拿来就用的效果,这样更好的服务于工作实践。 专栏介绍:专栏讲本人近10年后端开发常用的案例,以高质量的代码提取出来,并对其进行了介绍。…...

Java虚拟机JVM-运行时数据区域说明
及时编译器 HotSpot虚拟机中含有两个即时编译器,分别是编译耗时短但输出代码优化程度较低的客户端编译器(简称为C1)以及编译耗时长但输出代码优化质量也更高的服务端编译器(简称为C2),通常它们会在分层编译…...

修复电子管
年前在咸鱼捡漏买到了10根1G4G电子管,这是一种直热三极管,非常的少见。买回来的时候所有的灯丝都是通的,卖家说都是新的,库存货,但是外观实在是太糟糕了,看着就像被埋在垃圾场埋了几十年的那种,…...
【Java】反射机制和代理机制
目录一、反射1. 反射概念2. 反射的应用场景3. 反射机制的优缺点4. 反射实战获取 Class 对象的四种方式二、代理机制1. 代理模式2. 静态代理3. 动态代理3.1 JDK动态代理机制1. 介绍2.JDK 动态代理类使用步骤3. 代码示例3.2 CGLIB 动态代理机制1.介绍2.CGLIB 动态代理类使用步骤3…...

synchronized底层
Monitor概念一、Java对象头二、Monitor2.1、Monitor—工作原理2.2、Monitor工作原理—字节码角度2.2、synchronized进阶原理(优化)2.3、synchronized优化原理——轻量级锁2.4、synchronized优化原理——锁膨胀2.5、synchronized优化原理——自旋优化2.6、…...

数据结构:复杂度的练习(笔记)
数据结构:复杂度的练习(笔记) 例题一: 可以先给数组排序,然后再创建一个i值,让他循环一次一次,遍历这个排序后的数组,但如果用qsort函数进行排序,时间复杂度就和题目要求…...

JAVA练习69- 从前序与中序遍历序列构造二叉树
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 前言 提示:这里可以添加本文要记录的大概内容: 3月5日练习内容 提示:以下是本篇文章正文内容,下面案例可供参考 一、题目-从…...

brew安装问题
最近使用mac安装了Python和PyCharm,使用python中的绘制图像的turtle库后,执行报错: import _tkinter # If this fails your Python may not be configured for Tk ModuleNotFoundError: No module named _tkinter 查询后需在mac 命令行执行&…...
【数据挖掘与商务智能决策】第一章 数据分析与三重工具
numpy基础 numpy与数组 import numpy as np # 用np代替numpy,让代码更简洁 a [1, 2, 3, 4] # 创建列表a b np.array([1, 2, 3, 4]) #从列表ach print(a) print(b) print(type(a)) #打印a类型 print(type(b)) #打印b类型[1, 2, 3, 4] [1 2 3 4] <class ‘list’>…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...