NL2SQL进阶系列(1):DB-GPT-Hub、SQLcoder、Text2SQL开源应用实践详解
1. MindSQL(库)
MindSQL 是一个 Python RAG(检索增强生成)库,旨在仅使用几行代码来简化用户与其数据库之间的交互。 MindSQL 与 PostgreSQL、MySQL、SQLite 等知名数据库无缝集成,还通过扩展核心类,将其功能扩展到 Snowflake、BigQuery 等主流数据库。 该库利用 GPT-4、Llama 2、Google Gemini 等大型语言模型 (LLM),并支持 ChromaDB 和 Fais 等知识库。
官方链接:https://pypi.org/project/mindsql/
https://github.com/Mindinventory/MindSQL
- 使用案例
代码语言:javascript
复制
#!pip install mindsqlfrom mindsql.core import MindSQLCore
from mindsql.databases import Sqlite
from mindsql.llms import GoogleGenAi
from mindsql.vectorstores import ChromaDB#Add Your Configurations
config = {"api_key": "YOUR-API-KEY"}#Choose the Vector Store. LLM and DB You Want to Work With And
#Create MindSQLCore Instance With Configured Llm, Vectorstore, And Database
minds = MindSQLCore(llm=GoogleGenAi(config=config),vectorstore=ChromaDB(),database=Sqlite()
)#Create a Database Connection Using The Specified URL
connection = minds.database.create_connection(url="YOUR_DATABASE_CONNECTION_URL")#Index All Data Definition Language (DDL) Statements in The Specified Database Into The Vectorstore
minds.index_all_ddls(connection=connection, db_name='NAME_OF_THE_DB')#Index Question-Sql Pair in Bulk From the Specified Example Path
minds.index(bulk=True, path="your-qsn-sql-example.json")#Ask a Question to The Database And Visualize The Result
response = minds.ask_db(question="YOUR_QUESTION",connection=connection,visualize=True
)#Extract And Display The Chart From The Response
chart = response["chart"]
chart.show()#Close The Connection to Your DB
connection.close()
2.DB-GPT-Hub:利用LLMs实现Text-to-SQL微调
DB-GPT-Hub是一个利用LLMs实现Text-to-SQL解析的实验项目,主要包含数据集收集、数据预处理、模型选择与构建和微调权重等步骤,通过这一系列的处理可以在提高Text-to-SQL能力的同时降低模型训练成本,让更多的开发者参与到Text-to-SQL的准确度提升工作当中,最终实现基于数据库的自动问答能力,让用户可以通过自然语言描述完成复杂数据库的查询操作等工作。
2.1、数据集
本项目案例数据主要以Spider数据集为示例 :
- Spider: 一个跨域的复杂text2sql数据集,包含了10,181条自然语言问句、分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同的领域。下载链接
其他数据集:
- WikiSQL: 一个大型的语义解析数据集,由80,654个自然语句表述和24,241张表格的sql标注构成。WikiSQL中每一个问句的查询范围仅限于同一张表,不包含排序、分组、子查询等复杂操作。
- CHASE: 一个跨领域多轮交互text2sql中文数据集,包含5459个多轮问题组成的列表,一共17940个<query, SQL>二元组,涉及280个不同领域的数据库。
- BIRD-SQL:数据集是一个英文的大规模跨领域文本到SQL基准测试,特别关注大型数据库内容。该数据集包含12,751对文本到SQL数据对和95个数据库,总大小为33.4GB,跨越37个职业领域。BIRD-SQL数据集通过探索三个额外的挑战,即处理大规模和混乱的数据库值、外部知识推理和优化SQL执行效率,缩小了文本到SQL研究与实际应用之间的差距。
- CoSQL:是一个用于构建跨域对话文本到sql系统的语料库。它是Spider和SParC任务的对话版本。CoSQL由30k+回合和10k+带注释的SQL查询组成,这些查询来自Wizard-of-Oz的3k个对话集合,查询了跨越138个领域的200个复杂数据库。每个对话都模拟了一个真实的DB查询场景,其中一个工作人员作为用户探索数据库,一个SQL专家使用SQL检索答案,澄清模棱两可的问题,或者以其他方式通知。
- 按照NSQL的处理模板,对数据集做简单处理,共得到约20w条训练数据
2.2、基座模型
DB-GPT-HUB目前已经支持的base模型有:
- CodeLlama
- Baichuan2
- LLaMa/LLaMa2
- Falcon
- Qwen
- XVERSE
- ChatGLM2
- ChatGLM3
- internlm
- Falcon
- sqlcoder-7b(mistral)
- sqlcoder2-15b(starcoder)
模型可以基于quantization_bit为4的量化微调(QLoRA)所需的最低硬件资源,可以参考如下:
| 模型参数 | GPU RAM | CPU RAM | DISK |
|---|---|---|---|
| 7b | 6GB | 3.6GB | 36.4GB |
| 13b | 13.4GB | 5.9GB | 60.2GB |
其中相关参数均设置的为最小,batch_size为1,max_length为512。根据经验,如果计算资源足够,为了效果更好,建议相关长度值设置为1024或者2048。
2.3 快速使用
- 环境安装
代码语言:javascript
复制
git clone https://github.com/eosphoros-ai/DB-GPT-Hub.git
cd DB-GPT-Hub
conda create -n dbgpt_hub python=3.10
conda activate dbgpt_hub
pip install poetry
poetry install
2.3.1 数据预处理
DB-GPT-Hub使用的是信息匹配生成法进行数据准备,即结合表信息的 SQL + Repository 生成方式,这种方式结合了数据表信息,能够更好地理解数据表的结构和关系,适用于生成符合需求的 SQL 语句。
从spider数据集链接 下载spider数据集,默认将数据下载解压后,放在目录dbgpt_hub/data下面,即路径为dbgpt_hub/data/spider。
数据预处理部分,只需运行如下脚本即可:
代码语言:javascript
复制
##生成train数据 和dev(eval)数据,
poetry run sh dbgpt_hub/scripts/gen_train_eval_data.sh
在dbgpt_hub/data/目录你会得到新生成的训练文件example_text2sql_train.json 和测试文件example_text2sql_dev.json ,数据量分别为8659和1034条。 对于后面微调时的数据使用在dbgpt_hub/data/dataset_info.json中将参数file_name值给为训练集的文件名,如example_text2sql_train.json。
生成的json中的数据形如:
代码语言:javascript
复制
{"db_id": "department_management","instruction": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n\n","input": "###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","output": "SELECT count(*) FROM head WHERE age > 56","history": []},
项目的数据处理代码中已经嵌套了chase 、cosql、sparc的数据处理,可以根据上面链接将数据集下载到data路径后,在dbgpt_hub/configs/config.py中将 SQL_DATA_INFO中对应的代码注释松开即可。
2.3.2 快速开始
首先,用如下命令安装dbgpt-hub:
pip install dbgpt-hub
然后,指定参数并用几行代码完成整个Text2SQL fine-tune流程:
代码语言:javascript
复制
from dbgpt_hub.data_process import preprocess_sft_data
from dbgpt_hub.train import start_sft
from dbgpt_hub.predict import start_predict
from dbgpt_hub.eval import start_evaluate#配置训练和验证集路径和参数
data_folder = "dbgpt_hub/data"
data_info = [{"data_source": "spider","train_file": ["train_spider.json", "train_others.json"],"dev_file": ["dev.json"],"tables_file": "tables.json","db_id_name": "db_id","is_multiple_turn": False,"train_output": "spider_train.json","dev_output": "spider_dev.json",}
]#配置fine-tune参数
train_args = {"model_name_or_path": "codellama/CodeLlama-13b-Instruct-hf","do_train": True,"dataset": "example_text2sql_train","max_source_length": 2048,"max_target_length": 512,"finetuning_type": "lora","lora_target": "q_proj,v_proj","template": "llama2","lora_rank": 64,"lora_alpha": 32,"output_dir": "dbgpt_hub/output/adapter/CodeLlama-13b-sql-lora","overwrite_cache": True,"overwrite_output_dir": True,"per_device_train_batch_size": 1,"gradient_accumulation_steps": 16,"lr_scheduler_type": "cosine_with_restarts","logging_steps": 50,"save_steps": 2000,"learning_rate": 2e-4,"num_train_epochs": 8,"plot_loss": True,"bf16": True,
}#配置预测参数
predict_args = {"model_name_or_path": "codellama/CodeLlama-13b-Instruct-hf","template": "llama2","finetuning_type": "lora","checkpoint_dir": "dbgpt_hub/output/adapter/CodeLlama-13b-sql-lora","predict_file_path": "dbgpt_hub/data/eval_data/dev_sql.json","predict_out_dir": "dbgpt_hub/output/","predicted_out_filename": "pred_sql.sql",
}#配置评估参数
evaluate_args = {"input": "./dbgpt_hub/output/pred/pred_sql_dev_skeleton.sql","gold": "./dbgpt_hub/data/eval_data/gold.txt","gold_natsql": "./dbgpt_hub/data/eval_data/gold_natsql2sql.txt","db": "./dbgpt_hub/data/spider/database","table": "./dbgpt_hub/data/eval_data/tables.json","table_natsql": "./dbgpt_hub/data/eval_data/tables_for_natsql2sql.json","etype": "exec","plug_value": True,"keep_distict": False,"progress_bar_for_each_datapoint": False,"natsql": False,
}#执行整个Fine-tune流程
preprocess_sft_data(data_folder = data_folder,data_info = data_info
)start_sft(train_args)
start_predict(predict_args)
start_evaluate(evaluate_args)
2.3.3、模型微调
本项目微调不仅能支持QLoRA和LoRA法,还支持deepseed。 可以运行以下命令来微调模型,默认带着参数--quantization_bit 为QLoRA的微调方式,如果想要转换为lora的微调,只需在脚本中去掉quantization_bit参数即可。
默认QLoRA微调,运行命令:
代码语言:javascript
复制
poetry run sh dbgpt_hub/scripts/train_sft.sh
微调后的模型权重会默认保存到adapter文件夹下面,即dbgpt_hub/output/adapter目录中。
如果使用多卡训练,想要用deepseed ,则将train_sft.sh中默认的内容进行更改,
调整为:
代码语言:javascript
复制
CUDA_VISIBLE_DEVICES=0 python dbgpt_hub/train/sft_train.py \--quantization_bit 4 \...
更改为:
代码语言:javascript
复制
deepspeed --num_gpus 2 dbgpt_hub/train/sft_train.py \--deepspeed dbgpt_hub/configs/ds_config.json \--quantization_bit 4 \...
如果需要指定对应的显卡id而不是默认的前两个如3,4,可以如下
代码语言:javascript
复制
deepspeed --include localhost:3,4 dbgpt_hub/train/sft_train.py \--deepspeed dbgpt_hub/configs/ds_config.json \--quantization_bit 4 \...
其他省略(…)的部分均保持一致即可。 如果想要更改默认的deepseed配置,进入 dbgpt_hub/configs 目录,在ds_config.json 更改即可,默认为stage2的策略。
脚本中微调时不同模型对应的关键参数lora_target 和 template,如下表:
| 模型名 | lora_target | template |
|---|---|---|
| LLaMA-2 | q_proj,v_proj | llama2 |
| CodeLlama-2 | q_proj,v_proj | llama2 |
| Baichuan2 | W_pack | baichuan2 |
| Qwen | c_attn | chatml |
| sqlcoder-7b | q_proj,v_proj | mistral |
| sqlcoder2-15b | c_attn | default |
| InternLM | q_proj,v_proj | intern |
| XVERSE | q_proj,v_proj | xverse |
| ChatGLM2 | query_key_value | chatglm2 |
| LLaMA | q_proj,v_proj | - |
| BLOOM | query_key_value | - |
| BLOOMZ | query_key_value | - |
| Baichuan | W_pack | baichuan |
| Falcon | query_key_value | - |
train_sft.sh中其他关键参数含义:
quantization_bit:是否量化,取值为4或者8 model_name_or_path: LLM模型的路径 dataset: 取值为训练数据集的配置名字,对应在dbgpt_hub/data/dataset_info.json 中外层key值,如example_text2sql。 max_source_length: 输入模型的文本长度,如果计算资源支持,可以尽能设大,如1024或者2048。 max_target_length: 输出模型的sql内容长度,设置为512一般足够。 output_dir : SFT微调时Peft模块输出的路径,默认设置在dbgpt_hub/output/adapter/路径下 。 per_device_train_batch_size : batch的大小,如果计算资源支持,可以设置为更大,默认为1。 gradient_accumulation_steps : 梯度更新的累计steps值 save_steps : 模型保存的ckpt的steps大小值,默认可以设置为100。 num_train_epochs : 训练数据的epoch数
2.3.4、模型预测
项目目录下./dbgpt_hub/下的output/pred/,此文件路径为关于模型预测结果默认输出的位置(如果没有则建上)。
预测运行命令:
代码语言:javascript
复制
poetry run sh ./dbgpt_hub/scripts/predict_sft.sh
脚本中默认带着参数--quantization_bit 为QLoRA的预测,去掉即为LoRA的预测方式。
其中参数predicted_input_filename 为要预测的数据集文件, --predicted_out_filename 的值为模型预测的结果文件名。默认结果保存在dbgpt_hub/output/pred目录。
2.3.5、模型权重
可以从Huggingface查看社区上传的第二版Peft模块权重huggingface地址 (202310) ,在spider评估集上的执行准确率达到0.789。
- 模型和微调权重合并 如果你需要将训练的基础模型和微调的Peft模块的权重合并,导出一个完整的模型。则运行如下模型导出脚本:
代码语言:javascript
复制
poetry run sh ./dbgpt_hub/scripts/export_merge.sh
注意将脚本中的相关参数路径值替换为你项目所对应的路径。
2.3.6、模型评估
对于模型在数据集上的效果评估,默认为在spider数据集上。
运行以下命令来:
代码语言:javascript
复制
poetry run python dbgpt_hub/eval/evaluation.py --plug_value --input Your_model_pred_file
你可以在这里找到最新的评估和实验结果。
注意: 默认的代码中指向的数据库为从Spider官方网站下载的大小为95M的database,如果你需要使用基于Spider的test-suite中的数据库(大小1.27G),请先下载链接中的数据库到自定义目录,并在上述评估命令中增加参数和值,形如--db Your_download_db_path。
2.4 小结
整个过程会分为三个阶段:
- 阶段一:
代码语言:txt
复制
- 搭建基本框架,基于数个大模型打通从数据处理、模型SFT训练、预测输出和评估的整个流程 现在支持- CodeLlama- Baichuan2- LLaMa/LLaMa2- Falcon- Qwen- XVERSE- ChatGLM2- ChatGLM3- internlm- sqlcoder-7b(mistral)- sqlcoder2-15b(starcoder)阶段二:
代码语言:txt
复制
- 优化模型效果,支持更多不同模型进行不同方式的微调。
- 对`prompt`优化
- 放出评估效果,和优化后的还不错的模型,并且给出复现教程(见微信公众号EosphorosAI)阶段三:
代码语言:txt
复制
- 推理速度优化提升
- 业务场景和中文效果针对性优化提升
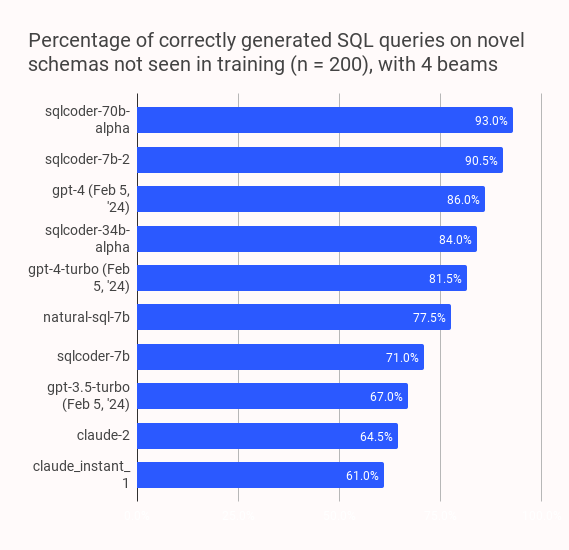
3.sqlcoder
官方链接:https://github.com/defog-ai/sqlcoder
Defog组织提出的先进的Text-to-SQL的大模型,表现亮眼,效果优于GPT3.5、wizardcoder和starcoder等,仅次于GPT4。
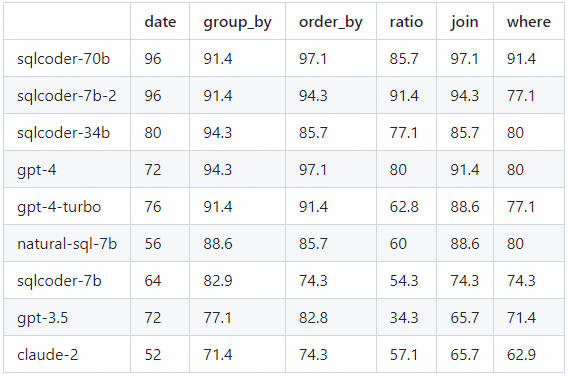
将每个生成的问题分为6类。该表显示了每个模型正确回答问题的百分比,并按类别进行了细分。
4.modal_finetune_sql
项目基于LLaMa 2 7b模型进行Text-to-SQL微调,有完整的训练、微调、评估流程。
链接:https://github.com/run-llama/modal_finetune_sql
5.LLaMA-Efficient-Tuning
这是一个易于使用的LLM微调框架,支持LLaMA-2、BLOOM、Falcon、Baichuan、Qwen、ChatGLM2等。
链接:https://github.com/hiyouga/LLaMA-Factory/tree/main
- 多种模型:LLaMA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
- 集成方法:(增量)预训练、指令监督微调、奖励模型训练、PPO 训练、DPO 训练和 ORPO 训练。
- 多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
- 先进算法:GaLore、DoRA、LongLoRA、LLaMA Pro、LoRA+、LoftQ 和 Agent 微调。
- 实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
- 极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
- 训练方法
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| 预训练 | ✔ | ✔ | ✔ | ✔ |
| 指令监督微调 | ✔ | ✔ | ✔ | ✔ |
| 奖励模型训练 | ✔ | ✔ | ✔ | ✔ |
| PPO 训练 | ✔ | ✔ | ✔ | ✔ |
| DPO 训练 | ✔ | ✔ | ✔ | ✔ |
| ORPO 训练 | ✔ | ✔ | ✔ | ✔ |
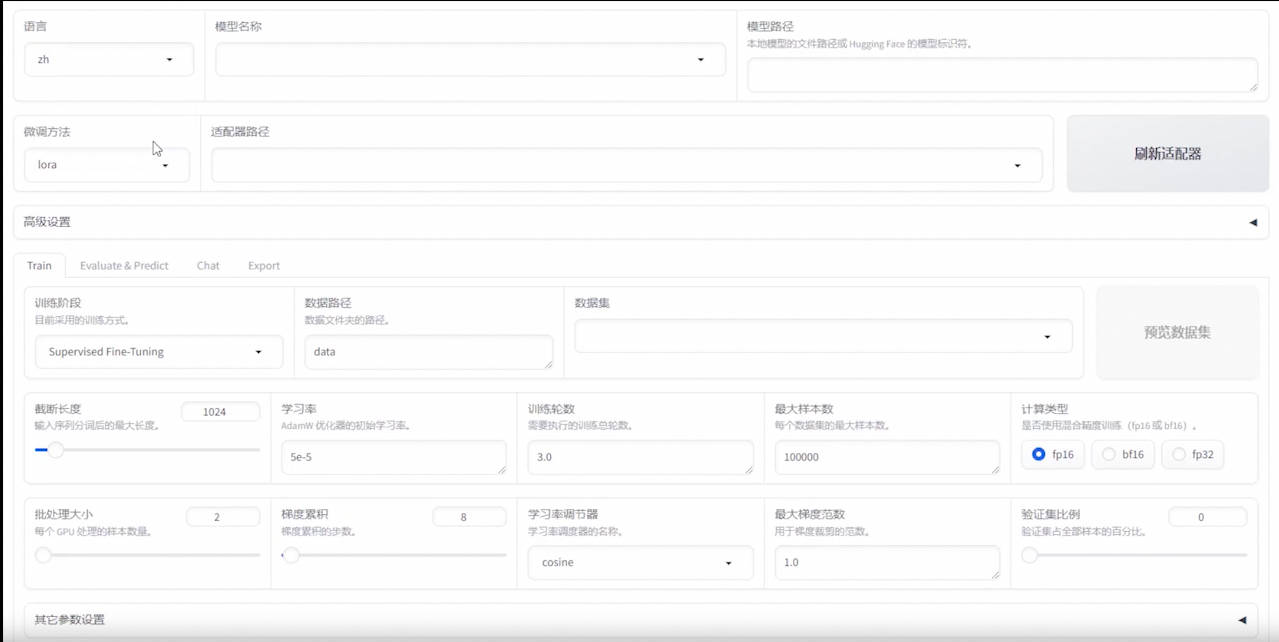
- 可视化使用教学

相关文章:
NL2SQL进阶系列(1):DB-GPT-Hub、SQLcoder、Text2SQL开源应用实践详解
1. MindSQL(库) MindSQL 是一个 Python RAG(检索增强生成)库,旨在仅使用几行代码来简化用户与其数据库之间的交互。 MindSQL 与 PostgreSQL、MySQL、SQLite 等知名数据库无缝集成,还通过扩展核心类,将其功能扩展到 Sn…...
)
OpenGL3.3_C++_Windows(15)
理解glad: OpenGL只是一个标准/规范,具体的实现是由驱动开发商针对特定显卡实现的,由于OpenGL驱动版本众多,它大多数函数的位置都无法在编译时确定下来,需要在运行时查询,因此开发者需要在运行时获取函数…...

NeRF从入门到放弃5: Neurad代码实现细节
Talk is cheap, show me the code。 CNN Decoder 如patch设置为32x32,patch_scale设置为3,则先在原图上采样96x96大小的像素块,然后每隔三个取一个像素,降采样成32x32的块。 用这32x32个像素render feature,再经过CNN反卷积预测…...

【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【11】ElasticSearch
持续学习&持续更新中… 守破离 【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【11】ElasticSearch 简介基本概念ElasticSearch概念-倒排索引安装基本命令Mapping-映射ElasticSearch7-去掉type概念Es-数组(数组装着Object)的扁平化处理ik 分词…...

Pip换源详解
Pip换源是指将pip(Python的包管理工具)的默认源更改为其他源。以下是关于Pip换源的详细说明: 一、Pip换源的原因 访问被阻止的源:在某些地区或网络环境下,直接访问官方的Python Package Index (PyPI) 可能受到限制或…...

【Docker】——安装镜像和创建容器,详解镜像和Dockerfile
前言 在此记录一下docker的镜像和容器的相关注意事项 前提条件:已安装Docker、显卡驱动等基础配置 1. 安装镜像 网上有太多的教程,但是都没说如何下载官方的镜像,在这里记录一下,使用docker安装官方的镜像 Docker Hub的官方链…...
利用LinkedHashMap实现一个LRU缓存
一、什么是 LRU LRU是 Least Recently Used 的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。 简单的说就是,对于一组数据,例如:int[] a {1,2,3,4,5,6},…...

git-pull详解
NAME git-pull - Fetch from and integrate with another repository or a local branch SYNOPSIS git pull [<options>] [<repository> [<refspec>…]] DESCRIPTION Incorporates changes from a remote repository into the current branch. If the…...
、count(*) 与 count(列名) 的区别)
【SQL】count(1)、count(*) 与 count(列名) 的区别
在 SQL 中,COUNT 函数用于计算查询结果集中的行数。COUNT(1)、COUNT(*) 和 COUNT(列名) 都可以用来统计行数,但它们在实现细节和使用场景上有一些区别。以下是详细的解释: 1. COUNT(1) 定义: COUNT(1) 计算查询结果集中的行数。实现: 在执行…...

03-ES6新语法
1. ES6 函数 1.1 函数参数的扩展 1.1.1 默认参数 function fun(name,age17){console.log(name","age); } fn("张美丽",18); // "张美丽",18 fn("张美丽",""); // "张美丽" fn("张美丽"); // &…...

Linux中的文本编辑器vi与vim
摘要: 本文将深入探讨VI和VIM编辑器的基本概念、特点、使用方法以及它们在Linux环境中的重要性。通过对这两款强大的文本编辑器的详细分析,读者将能够更全面地理解它们的功能,并掌握如何有效地使用它们进行日常的文本编辑和处理任务。 引言&…...
)
MATLAB基础应用精讲-【数模应用】三因素方差(附R语言、MATLAB和python代码实现)
目录 几个高频面试题目 群体分布是否服从高斯分布? 数据是否不匹配? “误差”是否独立存在? 您是否真的想比较平均值? 是否存在三项因素? 这三项因素是否均属于“固定因素”,而非“随机因素”? 算法原理 EXCEL spss三因素方差分析步骤 一、spss三因素…...
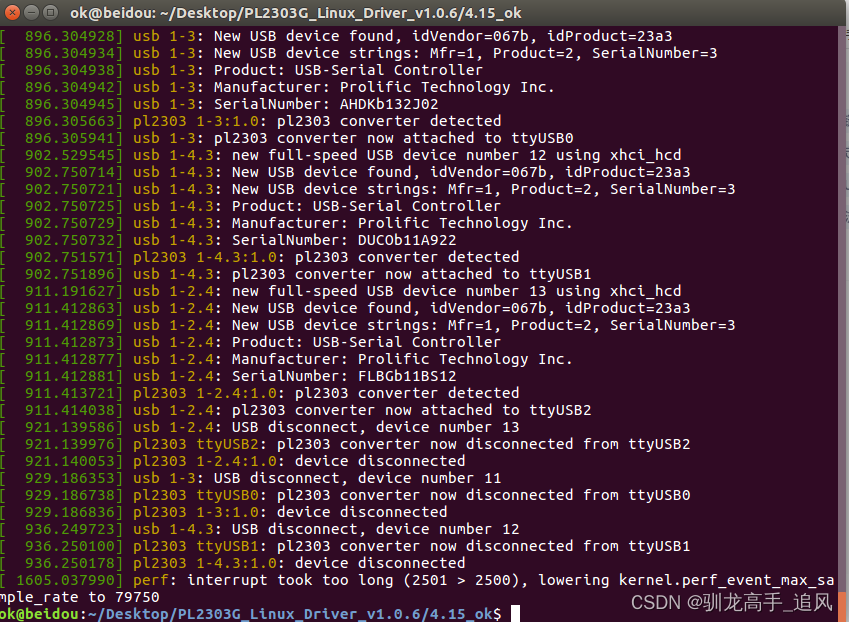
Linux ubuntu安装pl2303USB转串口驱动
文章目录 1.绿联PL2303串口驱动下载2.驱动安装3.验证方法 1.绿联PL2303串口驱动下载 下载地址:https://www.lulian.cn/download/16-cn.html 也可以直接通过CSDN下载:https://download.csdn.net/download/Axugo/89447539 2.驱动安装 下载后解压找到Lin…...
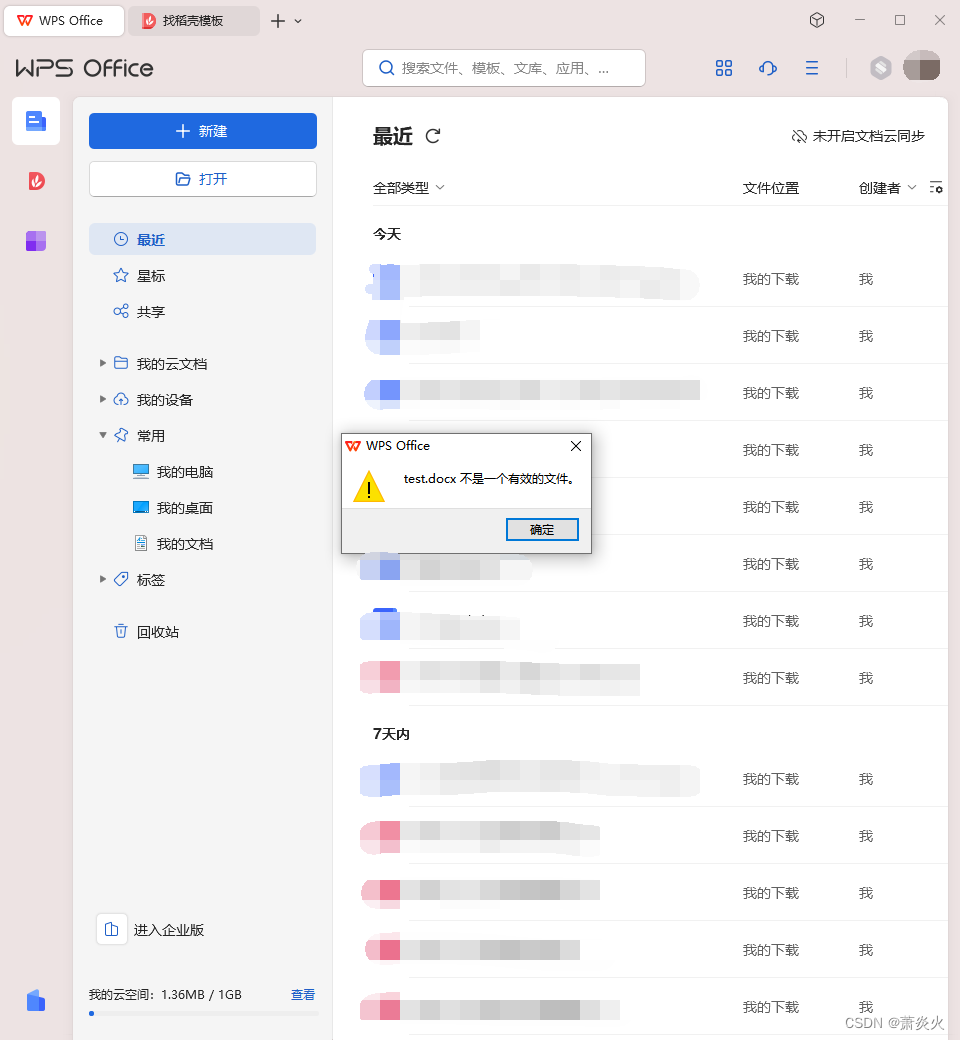
关于使用命令行打开wps word文件
前言 在学习python-docx时,想在完成运行时使用命令行打开生成的docx文件。 总结 在经过尝试后,得出以下代码: commandrstart "C:\Users\86136\AppData\Local\Kingsoft\WPS Office\12.1.0.16929\office6\wps.exe" "./result…...
将Vite添加到您现有的Web应用程序
Vite(发音为“veet”)是一个新的JavaScript绑定器。它包括电池,几乎不需要任何配置即可使用,并包括大量配置选项。哦——而且速度很快。速度快得令人难以置信。 本文将介绍将现有项目转换为Vite的过程。我们将介绍别名、填充webp…...

Apache Kafka与Spring整合应用详解
引言 Apache Kafka是一种高吞吐量的分布式消息系统,广泛应用于实时数据处理、日志聚合和事件驱动架构中。Spring作为Java开发的主流框架,通过Spring Kafka项目提供了对Kafka的集成支持。本文将深入探讨如何使用Spring Kafka整合Apache Kafka,…...
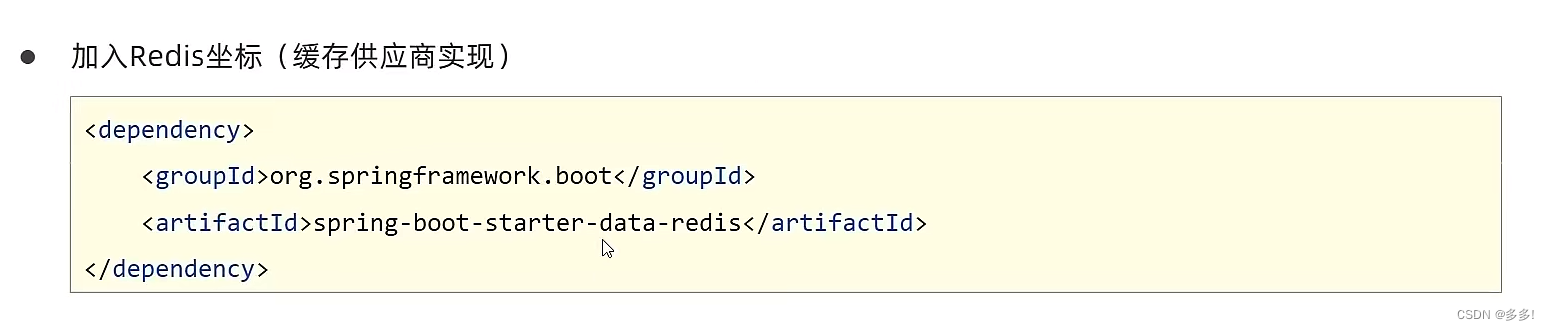
SpringBoot配置第三方专业缓存技术Redis
Redis缓存技术 Redis(Remote Dictionary Server)是一个开源的内存中数据结构存储系统,通常用作数据库、缓存和消息中间件。它支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等,并提供了丰富的功能和灵活的…...
以及使用)
javascript的toFixed()以及使用
toFixed() 是 JavaScript 中数字类型(Number)的一个方法,用来将数字转换为指定小数位数的字符串表示形式。 使用方式和示例: let num 123.45678; let fixedNum num.toFixed(2); console.log(fixedNum); // 输出 "123.46&qu…...

软件功能测试和性能测试包括哪些测试内容?又有什么联系和区别?
软件功能测试和性能测试是保证软件质量和稳定性的重要手,无论是验证软件的功能正确性,还是评估软件在负载下的性能表现,这些测试都是必不可少的。 一、软件功能测试 软件功能测试是指对软件的各项功能进行验证和确认,确保软件…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...