Flink中普通API的使用
本篇文章从Source、Transformation(转换因子)、sink这三个地方进行讲解
Source:
- 创建DataStream
- 本地文件
- Socket
- Kafka
Transformation(转换因子):
- map
- FlatMap
- Filter
- KeyBy
- Reduce
- Union和connect
- Side Outputs
sink:
- print 打印
- writerAsText 以文本格式输出
- writeAsCsv 以csv格式输出
- 输出到MySQL
- 输出到kafka
- 自定义输出
先准备一个模板方便后续使用
#if (${PACKAGE_NAME} && ${PACKAGE_NAME} != "")package ${PACKAGE_NAME};#end
#parse("File Header.java")
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**@基本功能:@program:${PROJECT_NAME}@author: ${USER}@create:${YEAR}-${MONTH}-${DAY} ${HOUR}:${MINUTE}:${SECOND}**/
public class ${NAME} {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据//3. transformation-数据处理转换//4. sink-数据输出//5. execute-执行env.execute();
}
}Source:
预定义source
创建DataStream(四种)
- 使用env.fromElements:类型要一致
- 使用env.fromcollections:支持多种collection的具体类型
- 使用env.generateSequence()方法创建基于Sequence的DataStream --已经废弃了
- 使用env.fromSequence()方法创建基于开始和结束的DataStream
package com.bigdata.source;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;public class _01YuDingYiSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 各种获取数据的SourceDataStreamSource<String> dataStreamSource = env.fromElements("hello world txt", "hello nihao kongniqiwa");dataStreamSource.print();// 演示一个错误的//DataStreamSource<Object> dataStreamSource2 = env.fromElements("hello", 1,3.0f);//dataStreamSource2.print();DataStreamSource<Tuple2<String, Integer>> elements = env.fromElements(Tuple2.of("张三", 18),Tuple2.of("lisi", 18),Tuple2.of("wangwu", 18));elements.print();// 有一个方法,可以直接将数组变为集合 复习一下数组和集合以及一些非常常见的APIString[] arr = {"hello","world"};System.out.println(arr.length);System.out.println(Arrays.toString(arr));List<String> list = Arrays.asList(arr);System.out.println(list);env.fromElements(Arrays.asList(arr),Arrays.asList(arr),Arrays.asList(arr)).print();// 第二种加载数据的方式// Collection 的子接口只有 Set 和 ListArrayList<String> list1 = new ArrayList<>();list1.add("python");list1.add("scala");list1.add("java");DataStreamSource<String> ds1 = env.fromCollection(list1);DataStreamSource<String> ds2 = env.fromCollection(Arrays.asList(arr));// 第三种DataStreamSource<Long> ds3 = env.fromSequence(1, 100);ds3.print();// execute 下面的代码不运行,所以,这句话要放在最后。env.execute("获取预定义的Source");}
}
本地文件
File file = new File("datas/wc.txt");File file2 = new File("./");System.out.println(file.getAbsoluteFile());System.out.println(file2.getAbsoluteFile());DataStreamSource<String> ds1 = env.readTextFile("datas/wc.txt");ds1.print();// 还可以获取hdfs路径上的数据DataStreamSource<String> ds2 = env.readTextFile("hdfs://bigdata01:9820/home/a.txt");ds2.print();Socket
linux(socket命令)
下载:yum install -y nc
nc -lk 8888 --向8888端口发送消息,这个命令先运行,如果先运行java程序,会报错!
如果端口被占用就换一个端口本地(socket命令)
nc -lp 8888
或者 nc -l -p 8888
如果不是在exe端打开的用 -l -p 8888java代码
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);Word Count案例
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class SourceDemo02_Socket {public static void main(String[] args) throws Exception {//TODO 1.env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//TODO 2.source-加载数据DataStream<String> socketDS = env.socketTextStream("bigdata01", 8889);//TODO 3.transformation-数据转换处理//3.1对每一行数据进行分割并压扁DataStream<String> wordsDS = socketDS.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}});//3.2每个单词记为<单词,1>DataStream<Tuple2<String, Integer>> wordAndOneDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}});//3.3分组KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordAndOneDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});//3.4聚合SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedDS.sum(1);//TODO 4.sink-数据输出result.print();//TODO 5.execute-执行env.execute();}
}JDBC
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/flink", "root", "root");PreparedStatement preparedStatement = connection.prepareStatement("select monitor_id,speed_limit from t_monitor_info group by monitor_id, speed_limit");ResultSet resultSet = preparedStatement.executeQuery();ArrayList<Tuple2<String,Double>> arr = new ArrayList<>();while (resultSet.next()){String monitor_id = resultSet.getString("monitor_id");Double speed_limit = resultSet.getDouble("speed_limit");Tuple2 tuple2 = new Tuple2(monitor_id, speed_limit);arr.add(tuple2);}Kafka
添加依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>${flink.version}</version>
</dependency>package com.bigdata.day02;import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class KafkaSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties properties = new Properties();properties.setProperty("bootstrap.servers", "bigdata01:9092");properties.setProperty("group.id", "g1");FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("topic1",new SimpleStringSchema(),properties);DataStreamSource<String> dataStreamSource = env.addSource(kafkaSource);// 以下代码跟flink消费kakfa数据没关系,仅仅是将需求搞的复杂一点而已// 返回true 的数据就保留下来,返回false 直接丢弃dataStreamSource.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String word) throws Exception {// 查看单词中是否包含success 字样return word.contains("success");}}).print();env.execute();}
}自定义source
SourceFunction:非并行数据源(并行度只能=1) --接口
RichSourceFunction:多功能非并行数据源(并行度只能=1) --类
ParallelSourceFunction:并行数据源(并行度能够>=1) --接口
RichParallelSourceFunction:多功能并行数据源(并行度能够>=1) --类 【建议使用的】
package com.bigdata.day02;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;import java.util.Random;
import java.util.UUID;/*** 需求: 每隔1秒随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳)* 要求:* - 随机生成订单ID(UUID)* - 随机生成用户ID(0-2)* - 随机生成订单金额(0-100)* - 时间戳为当前系统时间*/@Data // set get toString
@AllArgsConstructor
@NoArgsConstructor
class OrderInfo{private String orderId;private int uid;private int money;private long timeStamp;
}
// class MySource extends RichSourceFunction<OrderInfo> {
//class MySource extends RichParallelSourceFunction<OrderInfo> {
class MySource implements SourceFunction<OrderInfo> {boolean flag = true;@Overridepublic void run(SourceContext ctx) throws Exception {// 源源不断的产生数据Random random = new Random();while(flag){OrderInfo orderInfo = new OrderInfo();orderInfo.setOrderId(UUID.randomUUID().toString());orderInfo.setUid(random.nextInt(3));orderInfo.setMoney(random.nextInt(101));orderInfo.setTimeStamp(System.currentTimeMillis());ctx.collect(orderInfo);Thread.sleep(1000);// 间隔1s}}// source 停止之前需要干点啥@Overridepublic void cancel() {flag = false;}
}
public class CustomSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);// 将自定义的数据源放入到env中DataStreamSource dataStreamSource = env.addSource(new MySource())/*.setParallelism(1)*/;System.out.println(dataStreamSource.getParallelism());dataStreamSource.print();env.execute();}}如果代码换成ParallelSourceFunction,每次生成12个数据,假如是12核数的话(有多少核就生成多少个数据)。
Rich 类型的Source可以比非Rich的多出有:
- open方法,实例化的时候会执行一次,多个并行度会执行多次的哦(因为是多个实例了)
- close方法,销毁实例的时候会执行一次,多个并行度会执行多次的哦
- getRuntimeContext 方法可以获得当前的Runtime对象(底层API)
rich模板
/*** 自定义一个RichParallelSourceFunction的实现*/
public class CustomerRichSourceWithParallelDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> mySource = env.addSource(new MySource()).setParallelism(6);mySource.print();env.execute();}/*Rich 类型的Source可以比非Rich的多出有:- open方法,实例化的时候会执行一次,多个并行度会执行多次的哦(因为是多个实例了)- close方法,销毁实例的时候会执行一次,多个并行度会执行多次的哦- getRuntime方法可以获得当前的Runtime对象(底层API)*/public static class MySource extends RichParallelSourceFunction<String> {@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);System.out.println("open......");}@Overridepublic void close() throws Exception {super.close();System.out.println("close......");}@Overridepublic void run(SourceContext<String> ctx) throws Exception {ctx.collect(UUID.randomUUID().toString());}@Overridepublic void cancel() {}}
}Transformation(转换因子):
map算子(一变多)
package com.bigdata.day02;import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.text.SimpleDateFormat;
import java.util.Date;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2024-05-13 11:40:37**/
@Data
@AllArgsConstructor
class LogBean{private String ip; // 访问ipprivate int userId; // 用户idprivate long timestamp; // 访问时间戳private String method; // 访问方法private String path; // 访问路径
}
public class Demo04 {// 将数据转换为javaBeanpublic static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStreamSource<String> streamSource = env.readTextFile("datas/a.log");//3. transformation-数据处理转换SingleOutputStreamOperator<LogBean> map = streamSource.map(new MapFunction<String, LogBean>() {@Overridepublic LogBean map(String line) throws Exception {String[] arr = line.split("\\s+");//时间戳转换 17/05/2015:10:06:53String time = arr[2];SimpleDateFormat format = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss");Date date = format.parse(time);long timeStamp = date.getTime();return new LogBean(arr[0],Integer.parseInt(arr[1]),timeStamp,arr[3],arr[4]);}});//4. sink-数据输出map.print();//5. execute-执行env.execute();}
}FlatMap算子(类似于炸裂函数)
数据
张三,苹果手机,联想电脑,华为平板
李四,华为手机,苹果电脑,小米平板
package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2023-11-21 09:51:59**/
public class FlatMapDemo {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据//2. source-加载数据DataStream<String> fileStream = env.readTextFile("F:\\BD230801\\FlinkDemo\\datas\\flatmap.log");//3. transformation-数据处理转换DataStream<String> flatMapStream = fileStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {//张三,苹果手机,联想电脑,华为平板String[] arr = line.split(",");String name = arr[0];for (int i = 1; i < arr.length; i++) {String goods = arr[i];collector.collect(name+"有"+goods);}}});//4. sink-数据输出flatMapStream.print();//5. execute-执行env.execute();}
}Filter(过滤)
package com.bigdata.day03;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.lang3.time.DateUtils;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Date;/*** @基本功能:* @program:FlinkDemo* @author: zxx* @create:2023-11-21 09:10:30**/public class FilterDemo {@Data@AllArgsConstructor@NoArgsConstructorstatic class LogBean{String ip; // 访问ipint userId; // 用户idlong timestamp; // 访问时间戳String method; // 访问方法String path; // 访问路径}public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStream<String> fileStream = env.readTextFile("F:\\BD230801\\FlinkDemo\\datas\\a.log");//3. transformation-数据处理转换// 读取第一题中 a.log文件中的访问日志数据,过滤出来以下访问IP是83.149.9.216的访问日志DataStream<String> filterStream = fileStream.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String line) throws Exception {String ip = line.split(" ")[0];return ip.equals("83.149.9.216");}});//4. sink-数据输出filterStream.print();//5. execute-执行env.execute();}
}KeyBy(分组)
元组
//用字段位置
wordAndOne.keyBy(0, 1);//用KeySelector
wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> getKey(Tuple2<String, Integer> value) throws Exception {return Tuple2.of(value.f0, value.f1);}
});POJO (Plain Old Java Object):普通Java对象
public class PeopleCount {private String province;private String city;private Integer counts;public PeopleCount() {}//省略其他代码。。。
}多个字段keyBy
source.keyBy(new KeySelector<PeopleCount, Tuple2<String, String>>() {@Overridepublic Tuple2<String, String> getKey(PeopleCount value) throws Exception {return Tuple2.of(value.getProvince(), value.getCity());}
});Reduce --sum的底层是reduce(聚合)
// [ ("10.0.0.1",1),("10.0.0.1",1),("10.0.0.1",1) ]keyByStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {// t1 => ("10.0.0.1",10)// t2 => ("10.0.0.1",1)return Tuple2.of(t1.f0, t1.f1 + t2.f1);}}).print();union和connect-合并和连接
Union
union可以合并多个同类型的流
将多个DataStream 合并成一个DataStream
connect
connect可以连接2个不同类型的流(最后需要处理后再输出)
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化【一国两制】,两个流相互独立, 作为对比Union后是真的变成一个流了。
和union类似,但是connect只能连接两个流,两个流之间的数据类型可以不同,对两个流的数据可以分别应用不同的处理逻辑.
package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;/*** @基本功能:* @program:FlinkDemo* @author: zxx* @create:2023-11-21 11:40:12**/
public class UnionConnectDemo {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStreamSource<String> stream1 = env.fromElements("hello", "nihao", "吃甘蔗的人");DataStreamSource<String> stream2 = env.fromElements("hello", "kong ni qi wa", "看电子书的人");DataStream<String> unionStream = stream1.union(stream2);unionStream.print();DataStream<Long> stream3 = env.fromSequence(1, 10);// stream1.union(stream3); 报错//3. transformation-数据处理转换ConnectedStreams<String, Long> connectStream = stream1.connect(stream3);// 此时你想使用这个流,需要各自重新处理// 处理完之后的数据类型必须相同DataStream<String> mapStream = connectStream.map(new CoMapFunction<String, Long, String>() {// string 类型的数据@Overridepublic String map1(String value) throws Exception {return value;}// 这个处理long 类型的数据@Overridepublic String map2(Long value) throws Exception {return Long.toString(value);}});//4. sink-数据输出mapStream.print();//5. execute-执行env.execute();}
}package com.bigdata.transforma;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;/*** @基本功能:* @program:FlinkDemo* @author: zxx* @create:2024-11-22 10:50:13**/
public class _08_两个流join {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);DataStreamSource<String> ds1 = env.fromElements("bigdata", "spark", "flink");DataStreamSource<String> ds2 = env.fromElements("python", "scala", "java");DataStream<String> ds3 = ds1.union(ds2);ds3.print();// 接着演示 connectDataStreamSource<Long> ds4 = env.fromSequence(1, 10);ConnectedStreams<String, Long> ds5 = ds1.connect(ds4);ds5.process(new CoProcessFunction<String, Long, String>() {@Overridepublic void processElement1(String value, CoProcessFunction<String, Long, String>.Context ctx, Collector<String> out) throws Exception {System.out.println("String流:"+value);out.collect(value);}@Overridepublic void processElement2(Long value, CoProcessFunction<String, Long, String>.Context ctx, Collector<String> out) throws Exception {System.out.println("Long流:"+value);out.collect(String.valueOf(value));}}).print("合并后的打印:");//2. source-加载数据//3. transformation-数据处理转换//4. sink-数据输出//5. execute-执行env.execute();}
}Side Outputs侧道输出(侧输出流) --可以分流
举例说明:对流中的数据按照奇数和偶数进行分流,并获取分流后的数据
package com.bigdata.day02;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;/*** @基本功能:* @program:FlinkDemo* @author: zxx* @create:2024-05-13 16:19:56**/
public class Demo11 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 侧道输出流DataStreamSource<Long> streamSource = env.fromSequence(0, 100);// 定义两个标签OutputTag<Long> tag_even = new OutputTag<Long>("偶数", TypeInformation.of(Long.class));OutputTag<Long> tag_odd = new OutputTag<Long>("奇数", TypeInformation.of(Long.class));//2. source-加载数据SingleOutputStreamOperator<Long> process = streamSource.process(new ProcessFunction<Long, Long>() {@Overridepublic void processElement(Long value, ProcessFunction<Long, Long>.Context ctx, Collector<Long> out) throws Exception {// value 代表每一个数据if (value % 2 == 0) {ctx.output(tag_even, value);} else {ctx.output(tag_odd, value);}}});// 从数据集中获取奇数的所有数据DataStream<Long> sideOutput = process.getSideOutput(tag_odd);sideOutput.print("奇数:");// 获取所有偶数数据DataStream<Long> sideOutput2 = process.getSideOutput(tag_even);sideOutput2.print("偶数:");//3. transformation-数据处理转换//4. sink-数据输出//5. execute-执行env.execute();}
}sink:
print 打印
writerAsText 以文本格式输出
dataStreamSource.writeAsText("F:\\BD230801\\FlinkDemo\\datas\\result", FileSystem.WriteMode.OVERWRITE);writerAsText 以文本格式输出
DataStreamSource<Tuple2<String, Integer>> streamSource = env.fromElements(Tuple2.of("篮球", 1),Tuple2.of("篮球", 2),Tuple2.of("篮球", 3),Tuple2.of("足球", 3),Tuple2.of("足球", 2),Tuple2.of("足球", 3));// writeAsCsv 只能保存 tuple类型的DataStream流,因为如果不是多列的话,没必要使用什么分隔符streamSource.writeAsCsv("datas/csv", FileSystem.WriteMode.OVERWRITE).setParallelism(1);
输出到MySQL
JdbcConnectionOptions jdbcConnectionOptions = new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withDriverName("com.mysql.cj.jdbc.Driver").withUrl("jdbc:mysql://localhost:3306/zuoye").withUsername("root").withPassword("123456").build();studentDataStreamSource.addSink(JdbcSink.sink("insert into stu values(?,?,?)",new JdbcStatementBuilder<Student>() {@Overridepublic void accept(PreparedStatement preparedStatement, Student student) throws SQLException {preparedStatement.setInt(1,student.getId());preparedStatement.setString(2,student.getName());preparedStatement.setInt(3,student.getAge());}},jdbcConnectionOptions));
输出到kafka
FlinkKafkaProducer kafkaProducer = new FlinkKafkaProducer<String>("topic2",new SimpleStringSchema(),properties);filterStream.addSink(kafkaProducer);自定义Sink--模拟jdbcSink的实现
package com.bigdata.day03;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;/*** @基本功能:* @program:FlinkDemo* @author: zxx* @create:2023-11-21 16:08:04**/public class CustomJdbcSinkDemo {@Data@AllArgsConstructor@NoArgsConstructorstatic class Student{private int id;private String name;private int age;}static class MyJdbcSink extends RichSinkFunction<Student> {Connection conn =null;PreparedStatement ps = null;@Overridepublic void open(Configuration parameters) throws Exception {// 这个里面编写连接数据库的代码Class.forName("com.mysql.jdbc.Driver");conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test1", "root", "123456");ps = conn.prepareStatement("INSERT INTO `student` (`id`, `name`, `age`) VALUES (null, ?, ?)");}@Overridepublic void close() throws Exception {// 关闭数据库的代码ps.close();conn.close();}@Overridepublic void invoke(Student student, Context context) throws Exception {// 将数据插入到数据库中ps.setString(1,student.getName());ps.setInt(2,student.getAge());ps.execute();}}public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<Student> studentStream = env.fromElements(new Student(1, "马斯克", 51));studentStream.addSink(new MyJdbcSink());env.execute();}
}相关文章:

Flink中普通API的使用
本篇文章从Source、Transformation(转换因子)、sink这三个地方进行讲解 Source: 创建DataStream本地文件SocketKafka Transformation(转换因子): mapFlatMapFilterKeyByReduceUnion和connectSide Outpu…...

高性能 ArkUI 应用开发:复杂 UI 场景中的内存管理与 XML 优化
本文旨在深入探讨华为鸿蒙HarmonyOS Next系统(截止目前API12)的技术细节,基于实际开发实践进行总结。 主要作为技术分享与交流载体,难免错漏,欢迎各位同仁提出宝贵意见和问题,以便共同进步。 本文为原创内容,任何形式的转载必须注明出处及原作者。 在开发高性能 ArkUI 应…...

用天翼云搭建一个HivisionIDPhoto证件照处理网站
世人不必记我,我不记世人。 HivisionIDPhoto证件照处理网站 世人不必记我,我不记世人。项目地址项目搭建与修改前端后端遇到的坑 成果图 前段时间工作需要频繁处理证件照,当时同事推荐一个证件照小程序(要看广告)&…...

【算法一周目】滑动窗口(2)
目录 水果成篮 解题思路 代码实现 找到字符串中所有字母异位词 解题思路 代码实现 串联所有单词的子串 解题思路 代码实现 最小覆盖子串 解题思路 代码实现 水果成篮 题目链接:904. 水果成篮 题目描述: 你正在探访一家农场,农场…...

Zustand:一个轻量级的React状态管理库
文章目录 前言一、安装Zustand二、使用Zustand三、实际案例结语 前言 在现代Web开发中,状态管理是一个常见的需求,特别是在构建大型或复杂的单页面应用程序(SPA)时。React等框架虽然提供了基本的状态管理功能,但对于复…...

C++练级计划->《单例模式》懒汉和饿汉
目录 单例模式是什么? 单例模式的应用: 饿汉单例模式: 1.实现: 2.理解: 懒汉单例模式: 1.实现: 2.理解: 懒汉和饿汉的优缺点 饿汉模式的优点: 饿汉模式的缺点&a…...

SQL for XML
关系数据模型与SQL SQL for XML 模式名功能RAW返回的行作为元素,列值作为元素的属性AUTO返回表名对应节点名称的元素,每列的属性作为元素的属性输出输出,可形成简单嵌套结构EXPLICIT通过SELECT语法定义输出XML结构PATH列名或列别名作为XPAT…...
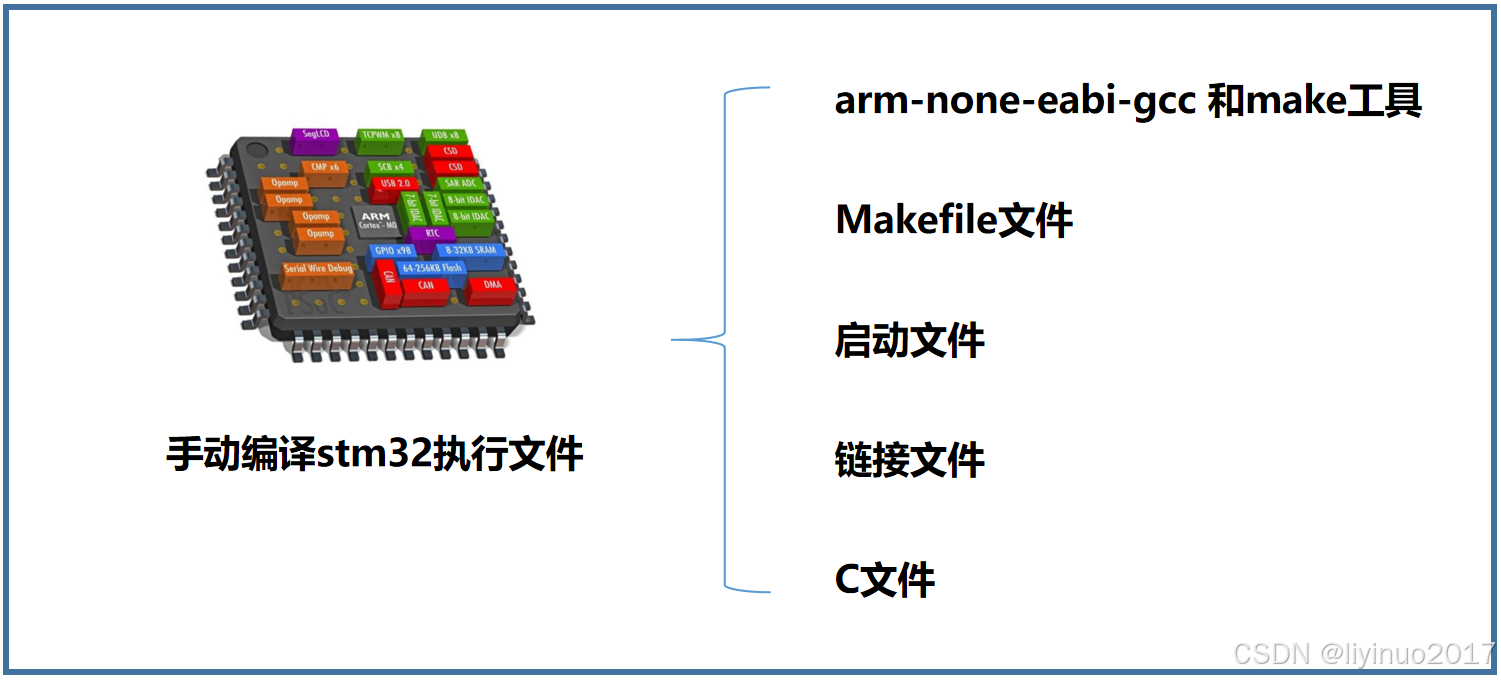
如何使用GCC手动编译stm32程序
如何不使用任何IDE(集成开发环境)编译stm32程序? 集成开发环境将编辑器、编译器、链接器、调试器等开发工具集成在一个统一的软件中,使得开发人员可以更加简单、高效地完成软件开发过程。如果我们不使用KEIL,IAR等集成开发环境,…...

在线绘制Nature Communication同款双色、四色火山图,突出感兴趣的基因
导读:火山图通常使用三种颜色分别表示显著上调,显著下调和不显著。通过为特定的数据点添加另一种颜色,可以创建双色或四色火山图,从而更直观地突出感兴趣的数据点。 《Nature Communication》文章“Molecular and functional land…...

C语言:C语言实现对MySQL数据库表增删改查功能
基础DOME可以用于学习借鉴; 具体代码 #include <stdio.h> #include <mysql.h> // mysql 文件,如果配置ok就可以直接包含这个文件//宏定义 连接MySQL必要参数 #define SERVER "localhost" //或 127.0.0.1 #define USER "roo…...

C++ 二叉搜索树(Binary Search Tree, BST)深度解析与全面指南:从基础概念到高级应用、算法优化及实战案例
🌟个人主页:落叶 🌟当前专栏: C专栏 目录 ⼆叉搜索树的概念 ⼆叉搜索树的性能分析 ⼆叉搜索树的插⼊ ⼆叉搜索树的查找 二叉搜索树中序遍历 ⼆叉搜索树的删除 cur的左节点为空的情况 cur的右节点为空的情况 左,右节点都不为…...

刷题日常(移动零,盛最多水的容器,三数之和,无重复字符的最长子串)
移动零 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 俩种情况: 1.当nums[i]为0的时候 直接i 2.当nums[i]不为0的时候 此时 …...

深入了解决策树---机器学习中的经典算法
引言 决策树(Decision Tree)是一种重要的机器学习模型,以直观的分层决策方式和简单高效的特点成为分类和回归任务中广泛应用的工具。作为解释性和透明性强的算法,决策树不仅适用于小规模数据,也可作为复杂模型的基石&…...

Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
大家好,我是锋哥。今天分享关于【Elasticsearch对于大数据量(上亿量级)的聚合如何实现?】面试题。希望对大家有帮助; Elasticsearch对于大数据量(上亿量级)的聚合如何实现? 1000道 …...

深度学习模型:循环神经网络(RNN)
一、引言 在深度学习的浩瀚海洋里,循环神经网络(RNN)宛如一颗独特的明珠,专门用于剖析序列数据,如文本、语音、时间序列等。无论是预测股票走势,还是理解自然语言,RNN 都发挥着举足轻重的作用。…...

前端---HTML(一)
HTML_网络的三大基石和html普通文本标签 1.我们要访问网络,需不需要知道,网络上的东西在哪? 为什么我们写,www.baidu.com就能找到百度了呢? 我一拼ping www.baidu.com 就拼到了ip地址: [119.75.218.70]…...

SQL 复杂查询
目录 复杂查询 一、目的和要求 二、实验内容 (1)查询出所有水果产品的类别及详情。 查询出编号为“00000001”的消费者用户的姓名及其所下订单。(分别采用子查询和连接方式实现) 查询出每个订单的消费者姓名及联系方式。 在…...

银河麒麟桌面系统——桌面鼠标变成x,窗口无关闭按钮的解决办法
银河麒麟桌面系统——桌面鼠标变成x,窗口无关闭按钮的解决办法 1、支持环境2、详细操作说明步骤1:用root账户登录电脑步骤2:导航到kylin-wm-chooser目录步骤3:编辑default.conf文件步骤4:重启电脑 3、结语 Ὁ…...

抓包之使用chrome的network面板
写在前面 本文看下工作中非常非常常用的chrome的network面板功能。 官方介绍:地址。 1:前置 1.1:打开 右键-》检查,或者F12。 1.2:组成部分 2:控制器常用功能 详细如下图: 接着我们挑选其…...

避坑ffmpeg直接获取视频fps不准确
最近在做视频相关的任务,调试代码发现一个非常坑的点,就是直接用ffmpeg获取fps是有很大误差的,如下: # GPT4o generated import ffmpegprobe ffmpeg.probe(video_path, v"error", select_streams"v:0", sho…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...